この記事のポイント
 テーブルデータの予測にはXGBoostかランダムフォレストを選ぶべき。精度と解釈性のバランスが最も優れている
テーブルデータの予測にはXGBoostかランダムフォレストを選ぶべき。精度と解釈性のバランスが最も優れている- 画像認識ならCNN、自然言語処理ならTransformer、画像生成なら拡散モデルが2026年の最適解
- 初学者はscikit-learnから始め、ディープラーニングに進む段階でPyTorchを選ぶのが学習効率で合理的
- アルゴリズム選択の判断基準は「データの種類×タスクの性質×説明可能性の要件」の3軸で決めるべき
- 自社にML専門人材がいない場合はAzure MLやVertex AIなどのクラウドMLプラットフォームでAutoMLから始めるのが現実的

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AIアルゴリズムとは、人工知能がデータを分析し、パターンを学習して予測や分類を行うための手順や規則のことです。
世界のAI市場は2025年に約2,794億ドルに達し、2030年にかけて年平均成長率(CAGR)36.6%で拡大が見込まれています。
本記事では、教師あり学習・教師なし学習・強化学習・自己教師あり学習の4分類から、CNN・Transformer・拡散モデルといった主要アーキテクチャ、ビジネス・医療・教育での活用事例、そしてAI開発ツールの料金比較まで網羅的に解説します。
目次
AIアルゴリズムとは
AIアルゴリズムとは、人工知能(AI)が問題を解決するために使用する一連の手順や規則のことです。データを分析し、パターンを学習することで、人間の脳が行うような判断や予測を模倣します。

AIアルゴリズムの基本的な定義と概念
AI技術の根底には、機械学習やディープラーニングといったアルゴリズムがあります。これらの技術は大量のデータから自律的にパターンを発見し、精度を継続的に向上させることができます。
世界のAI市場は急速に拡大しており、Grand View Researchの調査によると、2025年の市場規模は約2,794億ドルに達し、2030年にかけてCAGR 36.6%で成長すると予測されています。この成長を支える基盤技術がAIアルゴリズムです。
AIアルゴリズムの進化は、大きく4つの段階を経てきました。1950年代のルールベース型(人間が規則を手動で記述)から、2000年代の機械学習(データからパターンを自動学習)、2010年代のディープラーニング(深層ニューラルネットワークによる高精度学習)、そして2020年代以降の基盤モデル(Transformerベースの大規模モデル)へと進化しています。2026年現在、GPT-5.2やGemini 3.1 Proといった大規模言語モデルが産業応用を牽引しており、アルゴリズムの選択は企業のAI戦略において重要な意思決定となっています。

AIアルゴリズムの種類と特徴
AIアルゴリズムは大きく分けて4つのカテゴリに分類されます。以下の表で各分類の特性を整理しました。
| 分類 | 学習データ | 代表的アルゴリズム | 主な用途 |
|---|---|---|---|
| 教師あり学習 | ラベル付きデータ | 線形回帰、決定木、SVM、ランダムフォレスト | 分類・回帰(売上予測、スパム検出等) |
| 教師なし学習 | ラベルなしデータ | k-means、階層的クラスタリング、PCA | クラスタリング・次元削減(顧客セグメンテーション等) |
| 強化学習 | 環境との相互作用 | Q学習、DQN、PPO、A3C | 意思決定・制御(自動運転、ゲームAI等) |
| 自己教師あり学習 | ラベルなし大規模データ | BERT、GPT、MAE | 事前学習・基盤モデル(LLM、画像認識等) |
この4分類は互いに排他的ではなく、実際のシステムでは組み合わせて使われることも多くあります。たとえばGPT-5.2は、自己教師あり学習で事前学習し、教師あり学習でファインチューニングし、強化学習(RLHF)で人間の好みに合わせるという3段階のプロセスを経ています。それぞれの分類について、代表的なアルゴリズムを見ていきましょう。
教師あり学習のアルゴリズム一覧
教師あり学習は、ラベル付けされたトレーニングデータを用いてモデルを学習させる方法です。入力データとそれに対応する正解データのセットを使い、モデルが正解を予測する方法を学習します。教師あり学習は、分類と回帰の2つのタスクに大別されます。
| アルゴリズム | タイプ | 特徴と用途 |
|---|---|---|
| 線形回帰 | 回帰 | 連続値の予測に使用。住宅価格予測、売上予測など。計算が高速で結果の解釈が容易 |
| ロジスティック回帰 | 分類 | 二値分類に適している。スパム検出、疾患の有無判定など。出力を確率として解釈できる |
| 決定木 | 回帰・分類 | ツリー構造で判断を可視化できる。結果の説明がしやすく、ビジネス用途に適する |
| ランダムフォレスト | 回帰・分類 | 複数の決定木を組み合わせて精度を向上。過学習に強く、汎用性が高い |
| サポートベクターマシン(SVM) | 分類 | 高次元データの分類に強い。テキスト分類や画像認識の初期段階で活用 |
| 勾配ブースティング(XGBoost等) | 回帰・分類 | Kaggleコンペティションで高い実績。テーブルデータの予測タスクに優れる |
教師あり学習のアルゴリズム選択では、データの量・次元数・解釈性の要件が判断基準になります。たとえばデータが少なくモデルの判断根拠を説明する必要がある場合は決定木が適しており、大量のテーブルデータから高精度な予測を求める場合はXGBoostやランダムフォレストが有力な選択肢です。
教師なし学習のアルゴリズム一覧
教師なし学習は、ラベル付けされていないデータからパターンや構造を発見する手法です。データの自然なグループ分けや特徴の圧縮に利用されます。
| アルゴリズム | タイプ | 特徴と用途 |
|---|---|---|
| k-means | クラスタリング | データをk個のグループに分割。顧客セグメンテーション、市場分析に活用 |
| 階層的クラスタリング | クラスタリング | 木構造でデータの類似性を段階的に把握。クラスタ数を事前に決めなくてよい |
| DBSCAN | クラスタリング | 密度ベースのクラスタ形成。ノイズのあるデータや不規則な形状のクラスタに強い |
| 主成分分析(PCA) | 次元削減 | 高次元データの主要な構造を捉える低次元表現を生成。可視化やノイズ除去に活用 |
| t-SNE / UMAP | 次元削減・可視化 | 高次元データのクラスタ構造を2次元・3次元にマッピング。探索的データ分析に有用 |
教師なし学習はデータの前処理や探索的分析の段階で特に威力を発揮します。たとえばECサイトの購買データにk-meansを適用して顧客をセグメント化し、各セグメントに最適なマーケティング施策を打つといった活用が一般的です。
強化学習のアルゴリズム一覧
強化学習は、エージェントが環境と相互作用しながら、報酬を最大化する行動を学習するプロセスです。自動運転、ゲームAI、ロボット制御などの領域で活用されています。
| アルゴリズム | 特徴 |
|---|---|
| Q学習(Q-Learning) | 状態と行動のペアに対する価値を学習。状態遷移が不確定な環境にも適用可能 |
| DQN(Deep Q-Network) | Q学習をディープラーニングで拡張。高次元の入力(画像等)を直接処理できる |
| PPO(Proximal Policy Optimization) | 学習の安定性と効率性を両立する政策勾配法。ChatGPTのRLHFにも採用 |
| A3C | 複数エージェントが非同期で並列学習し効率を高める手法 |
| SARSA | 現在の方策に基づく行動選択が特徴。安全性が重視される環境に適する |
強化学習はChatGPTやClaude等の大規模言語モデルにおいて、人間のフィードバックから学習するRLHF(Reinforcement Learning from Human Feedback)として重要な役割を果たしています。PPOはその代表的なアルゴリズムであり、生成AIの品質向上に不可欠な技術となっています。
半教師あり学習と自己教師あり学習
半教師あり学習は、少量のラベル付きデータと大量のラベルなしデータを組み合わせて学習する手法です。ラベル付け作業のコスト削減と精度向上を両立できるため、実務で重宝されています。
自己教師あり学習は、2026年現在のAI技術を牽引する最も重要なパラダイムです。データ自体から学習目標を自動生成するこの手法は、GPT-5.2(次の単語を予測)やBERT(マスクされた単語を予測)、MAE(マスクされた画像パッチを復元)などの基盤モデルの事前学習に使われています。
自己教師あり学習が注目される理由は、ラベル付けなしに大規模データから汎用的な知識を獲得できる点にあります。インターネット上のテキストや画像を大量に学習することで、特定のタスクに依存しない「基盤的な理解力」を獲得し、少量のラベル付きデータによるファインチューニングで多様なタスクに適応できます。
機械学習の代表的な手法一覧では、これらのアルゴリズムの選び方をフローチャートで解説しています。
ディープラーニングの主要アーキテクチャ
ディープラーニングは、複雑なパターンやデータ構造を学習する機械学習の一分野です。人間の脳が情報を処理する方法に着想を得た多層のニューラルネットワークを用いて、画像認識・自然言語処理・音声認識などの高度なタスクを解決します。
ニューラルネットワークのイメージ
ニューラルネットワークは、入力層・隠れ層(1つまたは複数)・出力層から構成されます。各層は複数のニューロンで構成され、重みを持つ接続を介して情報を伝達します。学習プロセスでは誤差逆伝播法を通じてこれらの重みが最適化され、モデルの予測精度が向上します。
以下の表で、2026年現在の主要なディープラーニングアーキテクチャを比較しました。
| アーキテクチャ | 主な用途 | 代表的モデル | 特徴 |
|---|---|---|---|
| CNN | 画像認識・物体検出 | ResNet、EfficientNet、YOLO | 画像の空間的特徴を階層的に抽出 |
| RNN・LSTM | 時系列分析・音声認識 | LSTM、GRU | 時間的な依存関係を保持して処理 |
| Transformer | 自然言語処理・マルチモーダル | GPT-5.2、Gemini、Claude | セルフアテンションで長距離依存を直接モデル化 |
| 拡散モデル | 画像生成・動画生成 | Stable Diffusion、DALL-E、Sora | ノイズ除去プロセスで高品質な生成を実現 |
| GAN | 画像生成・データ拡張 | StyleGAN、CycleGAN | 生成器と識別器の競争で本物同様のデータを生成 |
2026年現在、最も広く使われているアーキテクチャはTransformerです。もともと機械翻訳のために開発されたTransformerは、セルフアテンション機構によってシーケンス内の任意の位置間の関係を直接モデル化できるため、自然言語処理だけでなく画像認識やマルチモーダルAIにも応用が広がっています。
CNN(畳み込みニューラルネットワーク)
CNNは、畳み込み層・プーリング層・全結合層から構成される画像処理に特化したアーキテクチャです。画像から局所的な特徴(エッジ、テクスチャ、形状)を抽出し、それらを組み合わせて複雑なパターンを認識します。医療画像診断、自動運転の物体検出、製造業の外観検査など、視覚的な判断が求められるタスクで広く活用されています。
RNN・LSTM(再帰型ニューラルネットワーク)
RNNは、前のステップの出力を次のステップの入力として利用し、時間的な情報を保持できるアーキテクチャです。しかしRNNは長いシーケンスで勾配消失問題が発生するため、LSTM(Long Short-Term Memory)がその改良版として開発されました。LSTMはゲート機構で情報の流れを制御し、必要な情報を長期間保持しながら不要な情報を忘れる能力を持ちます。株価予測、音声認識、異常検知などの時系列データ分析に活用されています。
Transformer
Transformerは、2017年にGoogleが発表した論文「Attention Is All You Need」で提案されたアーキテクチャで、2026年現在のAI技術の中核をなしています。セルフアテンション機構により、RNNのように逐次処理する必要がなく、シーケンス全体を並列に処理できるため、計算効率と学習速度が大幅に向上しました。
GPT-5.2、Gemini 3.1 Pro、Claude Opus 4.6といった最新の大規模言語モデルはすべてTransformerアーキテクチャをベースとしています。さらに、Vision Transformer(ViT)は画像認識にもTransformerを適用し、従来のCNNに匹敵する性能を達成しています。
拡散モデル(Diffusion Model)
拡散モデルは、データにノイズを段階的に加えるプロセスとその逆(ノイズを除去して元データを復元するプロセス)を学習することで、高品質なデータ生成を実現するアーキテクチャです。Stable DiffusionやDALL-E、Soraなどの画像・動画生成AIの基盤技術であり、テキストから高精細な画像を生成できる点が特徴です。
GAN(敵対的生成ネットワーク)
GANは、生成器(Generator)と識別器(Discriminator)の2つのネットワークが互いに競争しながら学習を進めるアーキテクチャです。生成器は本物のようなデータを生成しようとし、識別器は本物と偽物を区別しようとします。この競争的プロセスを通じて、非常にリアルな画像やデータを生成する能力を獲得します。2026年現在は拡散モデルに主流の座を譲りつつありますが、リアルタイム画像変換やデータ拡張の分野では依然として活用されています。
AIアルゴリズムの選び方と実践
AIアルゴリズムを選択する際には、解決したい問題の性質・データの量と種類・精度の要件・計算リソースなど複数の要因を考慮する必要があります。以下の表で、タスク別の推奨アルゴリズムを整理しました。
| タスク | 推奨アルゴリズム | 適するデータ |
|---|---|---|
| 売上・需要予測 | 線形回帰、XGBoost、LSTM | テーブルデータ、時系列データ |
| 顧客分類・セグメンテーション | ランダムフォレスト、k-means | テーブルデータ |
| 画像認識・分類 | CNN(ResNet、EfficientNet) | 画像データ |
| テキスト分類・要約 | Transformer(BERT、GPT) | テキストデータ |
| 異常検知 | オートエンコーダ、Isolation Forest | 時系列データ、ログデータ |
| 画像・動画生成 | 拡散モデル、GAN | 画像データ |
| 対話・文章生成 | Transformer(GPT-5.2等) | テキストデータ |
| ロボット制御 | PPO、DQN | シミュレーション環境 |
実務でのアルゴリズム選択では、まずデータの形式(テーブル、画像、テキスト、時系列)でカテゴリを絞り、次にタスクの種類(分類、回帰、生成、制御)で候補を特定するアプローチが効率的です。
アルゴリズム選択にあたっては、以下の課題にも留意する必要があります。
-
過学習と汎化
訓練データに過剰に適合してしまう過学習は、未知のデータに対する性能を低下させます。正則化手法やドロップアウト、交差検証によって汎化能力を確保することが重要です。
-
特徴選択と次元の呪い
不要な特徴量を含めるとモデルのパフォーマンスが低下するため、関連性の高い特徴量を選択する必要があります。特徴量の数が増えるほど必要なデータ量が指数関数的に増加する「次元の呪い」にも注意が求められます。
-
計算コストとモデルの複雑さ
高精度なディープラーニングモデルは大量の計算リソースを必要とします。ビジネス要件として精度とコストのバランスを取り、軽量モデル(蒸留やプルーニング)の活用も検討すべきです。
ChatGPTを活用したデータ分析の実践
ChatGPTのデータ分析機能を使えば、プログラミングの専門知識がなくても機械学習アルゴリズムを実践的に体験できます。ここでは、Kaggleのデータセットを用いた分析例を紹介します。
Kaggleのデータセット
国の健康動向データセットをChatGPTにアップロードし、「平均余命、出生率、人口規模の関係を調査し、相関分析と回帰分析を行ってください」と指示すると、AIが自動でデータを処理し、以下のような結果を出力します。
分析では、平均余命と出生率の間に強い負の相関(-0.81)が明らかになり、平均余命が高い国は出生率が低いという関係が示されました。一方、人口規模はこれらの変数に直接的な影響を及ぼさないことも判明しています。
結果をヒートマップで視覚化すると、変数間の相関関係がより直感的に把握できます。
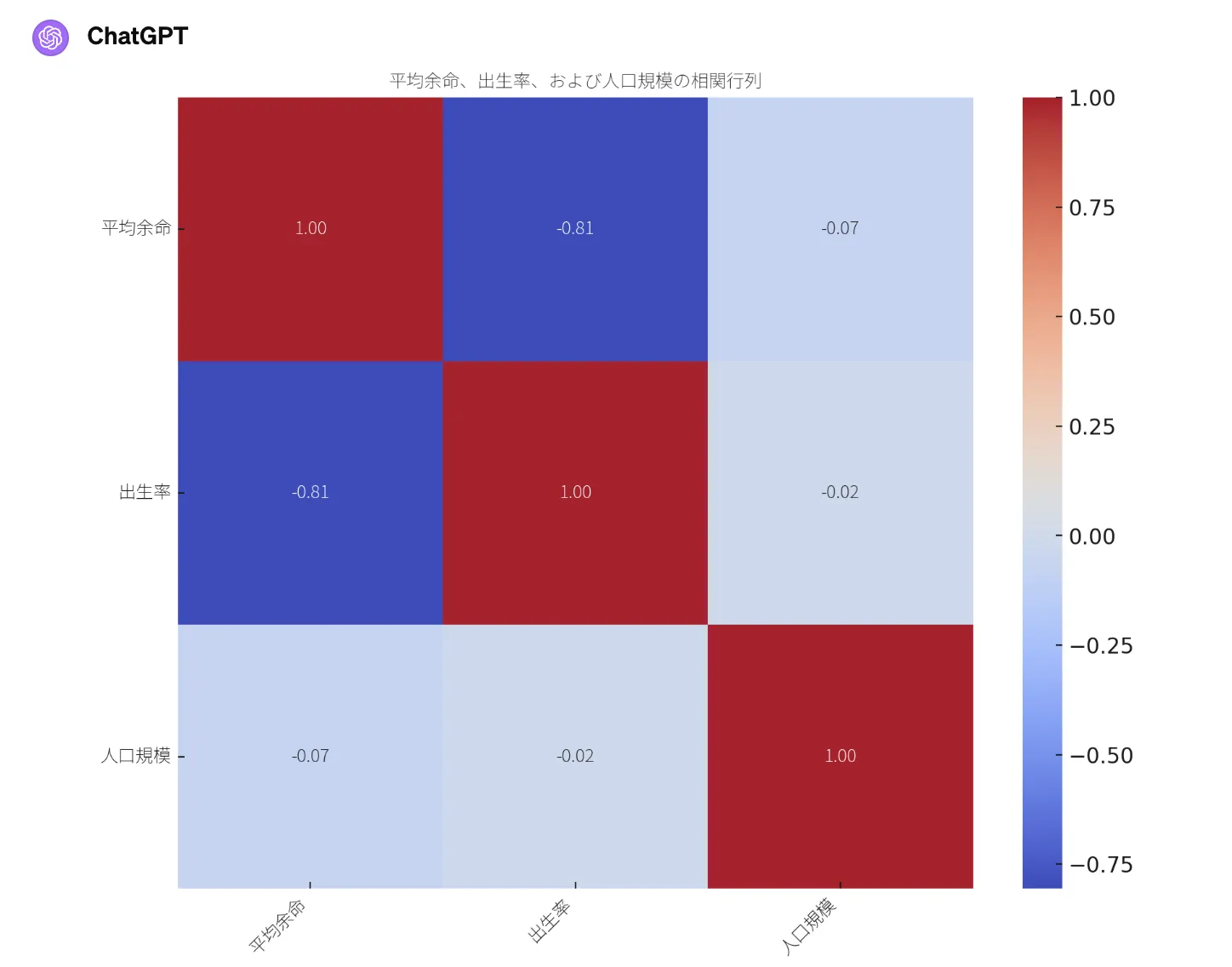
ChatGPTでデータの視覚化:相関分析
さらにCNNを用いた予測タスクも実行可能です。Netflix株の終値データをChatGPTにアップロードし、畳み込みニューラルネットワークによる予測モデルの構築を指示すると、モデルの設計・訓練・評価までを一括で実行し、実際の終値と予測値のプロットを出力します。
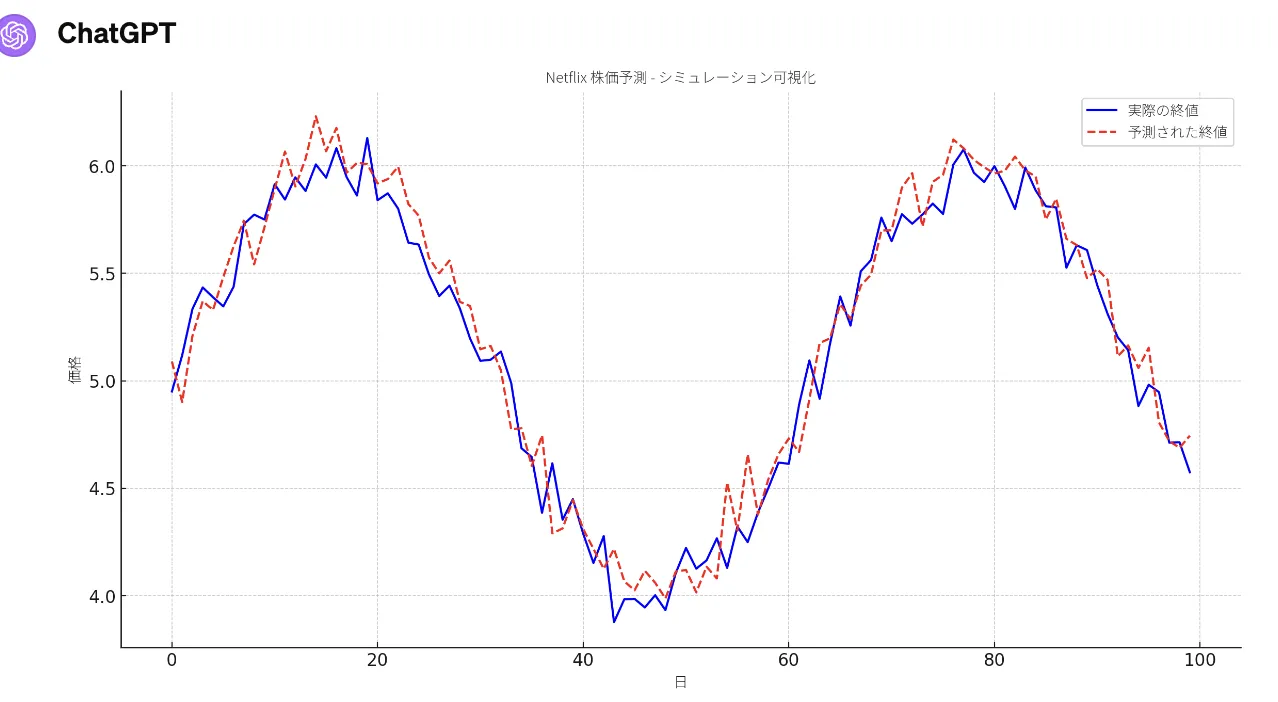
NetFlixの実際の終値と予測された終値のプロット
このようにChatGPTのデータ分析機能は、アルゴリズムの動作原理を理解するための実験環境としても活用できます。ただし、機密情報を含むデータの取り扱いには注意が必要です。

AIアルゴリズムの活用事例
AIアルゴリズムはビジネス・医療・教育などさまざまな分野で革新をもたらしています。ここでは日本のAI導入状況を踏まえ、具体的な事例を紹介します。
ビジネスでの活用事例
ビジネスにおけるAIアルゴリズムの活用は、顧客サービス・在庫管理・マーケティングの3つの領域で特に進んでいます。
顧客サービス
ビーウィズ株式会社はコールセンター向けクラウド型PBX「Omnia LINK」に生成AIを活用した要約機能を搭載しています。

ビーウィズ株式会社のコールセンター向け顧客管理システム (出典:Omnia LINK 生成AI対応プレスリリース(2024年4月))
通話終了後約30秒でシステムに要約が反映され、その精度は90%以上を達成しています。終話後の後処理時間の短縮により、1通話あたり約30%の生産性改善が見込まれています。自然言語処理アルゴリズムとTransformerベースの要約モデルが組み合わされた実用例です。
在庫管理
株式会社そごう・西武は、画像認識AIを活用した単品在庫管理システムを導入しました。CNNベースの画像認識アルゴリズムを組み込んだ業務アプリにより、バーコードの有無にかかわらず商品の在庫管理が可能になっています。
実証実験では発注・検品・納品の作業時間33%削減を実現し、画像認識AIの検知率は約99%に到達しています。削減できた時間は接客などの顧客満足度向上業務に充てられるようになりました(出典:そごう・西武×Ridgelinez プレスリリース)。
マーケティング
カスタマーエンゲージメントプラットフォームのBraze社は、機械学習アルゴリズムを活用したパーソナライズ機能群を提供しています。各ユーザーの嗜好に合わせた商品提案や、最適なタイミングでのメッセージ送信により、マーケティングの収益最大化を支援しています。
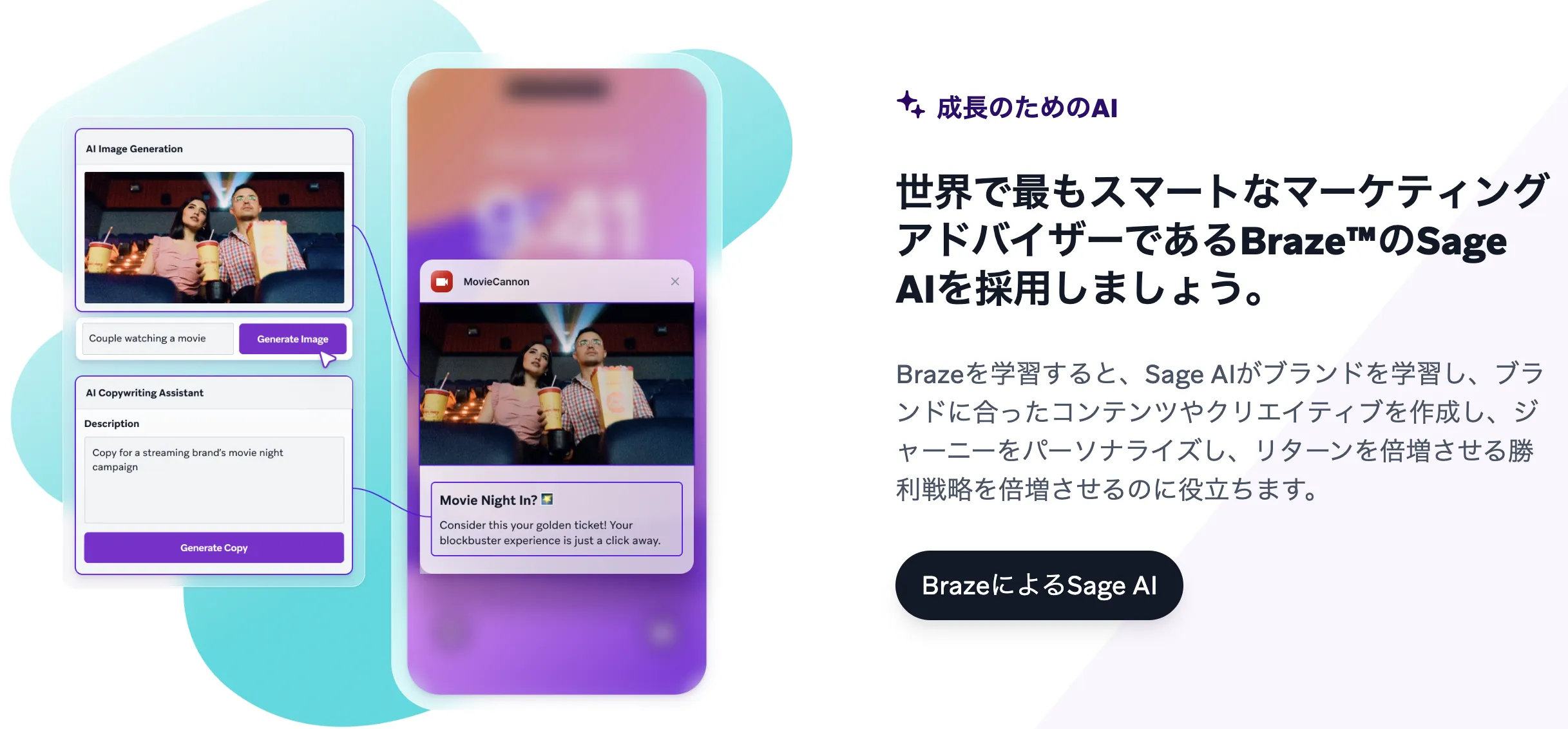
参考:Braze
リアルタイムのデータ分析とレコメンデーションアルゴリズムにより、パーソナライズされたユーザー体験の大規模な提供が実現しています。
医療分野での活用事例
医療分野でのAIアルゴリズム活用は、特に画像診断と創薬の2領域で大きな進展が見られます。医療領域での生成AI活用は今後さらに拡大すると見込まれています。
画像診断
医療画像診断では、CNNベースのアルゴリズムが医師の診断を支援するシステムとして実用化されています。CTやMRI画像をAIが自動解析し、病気の疑いのある場所を検出して医師に提示するCAD(Computer-Aided Diagnosis)システムの研究開発が進んでいます。
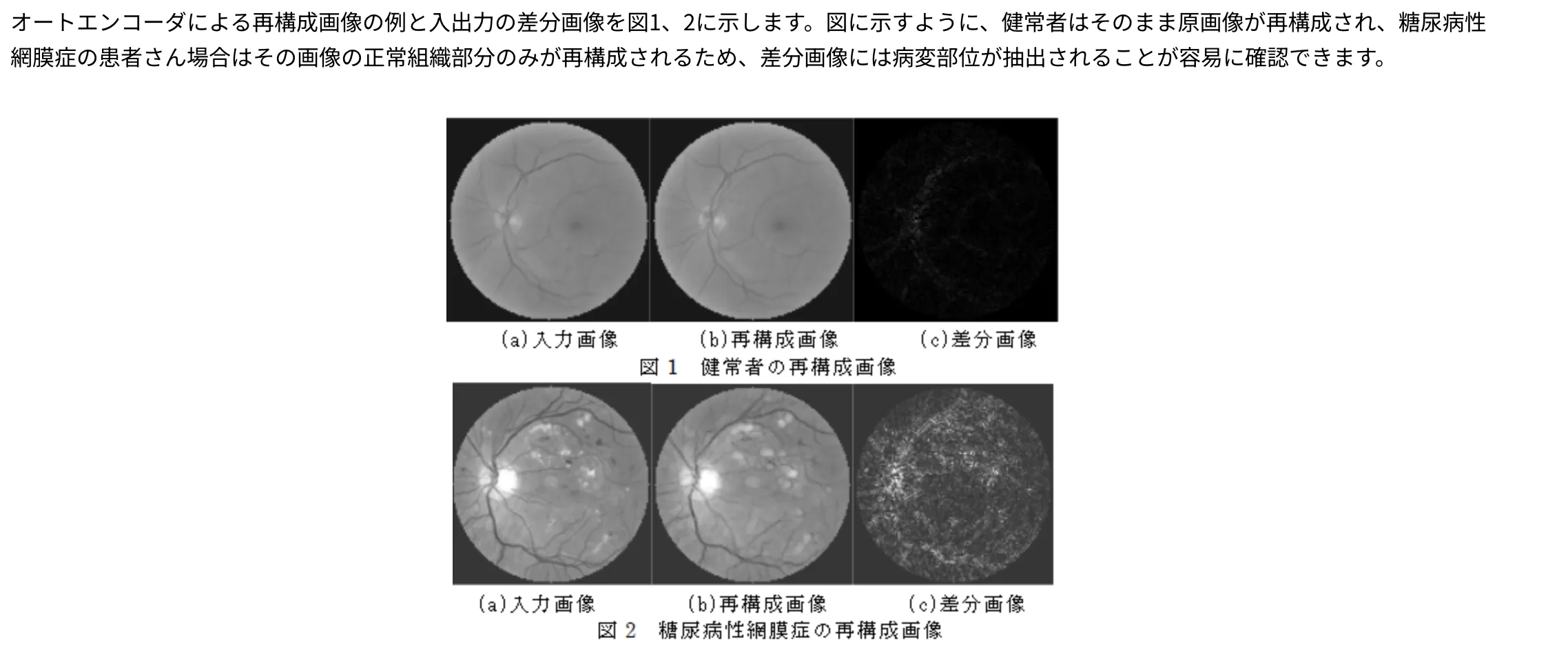
オートエンコーダ技術と深層学習を組み合わせた診断支援は、レントゲン・CT・MRI・超音波・眼底画像など幅広い医用画像に適用されており、早期発見率の向上に貢献しています。
創薬
中外製薬株式会社は、AIアルゴリズムを活用した創薬プロセスの革新に取り組んでいます。

中外製薬のAI創薬の取り組みを以下の表で整理しました。
| 取り組み | 内容 |
|---|---|
| 創薬プロセスの革新 | 疾患ターゲット探索や医薬品分子デザインへのAI活用による創薬期間の大幅短縮と成功確率向上 |
| 成功確率の向上 | 対象患者集団の特定や高精度なヒトにおける動態予測による早期開発の成功確率向上 |
| プロセスの効率化 | 創薬プロセスとデータの統合による自動化、ロボット導入等による開発期間の短縮 |
年々増大する新薬開発の期間と費用に対して、AIアルゴリズムの導入が創薬開発の成功確率を高める鍵として期待されています。
教育分野での活用事例
教育分野ではパーソナライズ学習と自動評価の2つの領域で、AIアルゴリズムが活用されています。
MagniLearn(マグニラーン)は、AIを活用した英語学習のオンライン演習サポートシステムです。
機械学習アルゴリズムが生徒の正解・不正解に応じて一人ひとりに合った出題を行い、パーソナライズされたカリキュラムを自動生成します。教師も生徒もダッシュボードで学習状況をリアルタイムに確認でき、的確なサポートが可能になります。
第一生命研究所のレポートによると、AIが学生のレポートを公平かつ一貫性のある基準で評価し、具体的な改善点を提示できることに教育現場からの期待が高まっています。ただし、教員自身による最終的なチェックと補足は不可欠とされており、AIと人間の協働が導入成功の鍵です。
AIアルゴリズム導入のメリットと課題
AIアルゴリズムの導入は企業に大きなメリットをもたらしますが、同時に対処すべき課題も存在します。ここではAI導入がもたらす変化を踏まえ、両面を整理します。

AIアルゴリズムの倫理と将来の課題
AIアルゴリズム導入の主なメリットは以下の5点です。
-
業務効率化と自動化
定型的な分析・判断業務をアルゴリズムに任せることで、人間はより創造的な業務に集中できます。ビーウィズ社の事例では通話要約の自動化により30%の生産性改善を達成しています。
-
データに基づく意思決定
大量のデータから客観的なパターンを発見し、直感や経験則では見落としがちなインサイトを提供します。需要予測や顧客セグメンテーションなど、ビジネス判断の精度向上に直結します。
-
新たなサービスの創出
画像生成AI、対話AI、レコメンデーションAIなど、アルゴリズムの進化によって従来不可能だったサービスが実現しています。
-
コスト削減
そごう・西武の在庫管理事例のように、作業時間33%削減といった定量的な効果が報告されています。長期的には人件費・エラーコスト・機会損失の低減につながります。
-
スケーラビリティ
一度構築したモデルは、データ量の増加に対して比較的低コストでスケールさせることができます。24時間365日稼働する点も人的リソースに対する優位性です。
一方で、AI導入には以下の課題があります。社内にデータサイエンスの知見を持つ人材がいない、導入したいがどのアルゴリズムを選べばよいかわからない——そうした状況は多くの企業に共通しています。
-
データ品質とバイアス
アルゴリズムの精度はデータの品質に直結します。偏ったデータで学習したモデルは、意図せず差別的な判断を下す可能性があります。AI倫理のガイドラインに従ったデータ管理が不可欠です。
-
ブラックボックス問題
ディープラーニングモデルの判断過程は人間にとって解釈が困難な場合があります。医療や金融など説明責任が求められる分野では、説明可能AI(XAI)の導入を検討する必要があります。
-
計算コスト
大規模モデルの訓練や推論には高性能なGPUが必要であり、クラウドコンピューティングの利用料が経営上の負担となる場合があります。モデルの軽量化や効率的なインフラ選択が重要です。
-
人材不足
AIアルゴリズムを適切に選択・実装・運用できる人材の確保は、多くの企業にとって課題です。リスキリングによる社内育成と外部専門家の活用を組み合わせた体制構築が求められます。
-
セキュリティとプライバシー
学習データや推論結果に個人情報が含まれる場合、データの保護と適切なアクセス制御が必須です。特に医療や金融分野では、各業界の規制に準拠したデータガバナンス体制の整備が求められます。
AI開発ツールの料金比較(2026年3月版)
AIアルゴリズムの開発・実行には、フレームワークとクラウドプラットフォームの選択が必要です。ここでは2026年3月時点の主要ツールと料金体系を比較します。
まず、AIアルゴリズムの実装に使用される主要フレームワークの特徴を以下の表で整理しました。
| フレームワーク | 開発元 | ライセンス | 特徴 | 適するユースケース |
|---|---|---|---|---|
| PyTorch | Meta(旧Facebook) | 無料(BSD) | 研究コミュニティで最も普及。直感的なデバッグ、動的計算グラフ | 研究開発・プロトタイピング |
| TensorFlow | 無料(Apache 2.0) | 本番環境での安定運用に強み。TensorFlow Serving等のデプロイツール充実 | 大規模本番システム | |
| scikit-learn | コミュニティ | 無料(BSD) | 従来型機械学習アルゴリズムが充実。学習コストが低い | テーブルデータの分析・予測 |
| JAX | 無料(Apache 2.0) | 高速な自動微分とJITコンパイル。TPUとの親和性が高い | 大規模研究・科学計算 | |
| Hugging Face Transformers | Hugging Face | 無料(Apache 2.0) | 事前学習済みモデルのハブ。10万以上のモデルを利用可能 | NLP・生成AI活用 |
フレームワーク自体はすべて無料で利用できます。ただし、大規模なモデルの訓練や推論にはGPU等の計算リソースが必要であり、その調達にコストが発生します。
計算リソースの調達にはクラウドMLプラットフォームを利用するのが一般的です。以下の表で主要3社のサービスと料金体系を比較しました。
| プラットフォーム | 提供元 | GPU時間単価(目安) | 特徴 |
|---|---|---|---|
| Azure Machine Learning | Microsoft | NVIDIA A100: 約$3.67/時間(Japan East) | エンタープライズ統合、Azure OpenAI Serviceとの連携 |
| Vertex AI | NVIDIA A100: 約$3.67/時間 | Google検索・YouTube等のデータ連携、TPU利用可 | |
| SageMaker | AWS | NVIDIA A100: 約$4.10/時間 | 幅広いインスタンス選択肢、SageMaker JumpStartで事前学習済みモデル活用 |
上記の料金はオンデマンド利用時の参考価格であり、リザーブドインスタンスやスポットインスタンスの活用で30〜70%のコスト削減が可能です。小規模な実験であればGoogle Colabの無料枠(GPU利用に制限あり)や、各クラウドの無料クレジット枠を活用して始めることができます。
AI開発ツールの選択に迷った場合は、まずscikit-learnで従来型機械学習を試し、ディープラーニングが必要になった段階でPyTorchに移行するのがスムーズです。

AIアルゴリズムの選定力を業務設計に転用
教師あり学習からTransformerまでAIアルゴリズムの全体像を把握した方は、業務課題に対して「どのAI手法が最適か」を判断できる力を持っています。その技術選定力を、組織全体のAI業務自動化の段階設計に活かすことが次のステップです。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に進めるための220ページの実践ガイドを無料で提供しています。AI総合研究所の専任チームが、技術評価から導入設計まで一貫して伴走します。
AIアルゴリズムの選定力を業務設計に転用

技術理解から組織のAI導入ロードマップへ
AIアルゴリズムの全体像を理解した方は、業務課題に最適なAI手法を選定できる力を持っています。その力を組織のAI導入設計に活かすための実践ガイドを無料で提供しています。
まとめ
AIアルゴリズムは、教師あり学習・教師なし学習・強化学習・自己教師あり学習の4つに大別され、それぞれ異なるタスクに適した特性を持っています。2026年現在、Transformerアーキテクチャを基盤とした大規模言語モデルや拡散モデルが産業応用を牽引していますが、テーブルデータの分析にはランダムフォレストやXGBoostが、時系列予測にはLSTMが依然として有力な選択肢です。
ビジネス・医療・教育の各分野でAIアルゴリズムの導入が進んでおり、コールセンターの生産性30%改善や在庫管理の作業時間33%削減といった定量的な成果が報告されています。一方で、データ品質・ブラックボックス問題・計算コスト・人材不足といった課題にも対処が必要です。
まずはscikit-learnやGoogle Colabの無料枠を使って、自社の業務データで小規模な実験を始めてみてください。アルゴリズムの選択に迷った場合は、テーブルデータならXGBoost、テキストデータならTransformerベースのモデルを出発点にするのが効率的です。










