この記事のポイント
 画像認識の総合力ではChatGPT(GPT-4o以上)を第一候補にすべき。MMMUベンチマークでGPT-5.1が85.4%で首位、無料版でも実用的な精度
画像認識の総合力ではChatGPT(GPT-4o以上)を第一候補にすべき。MMMUベンチマークでGPT-5.1が85.4%で首位、無料版でも実用的な精度- 製造業の品質検査にはAzure Custom Visionを選ぶべき。トヨタは見逃し率ゼロ化、日本精工は精度99.9%を達成しており実績が圧倒的
- プログラミング不要で画像認識を試すならChatGPTにアップロードするだけで十分。服装認識・表情分析・OCRまで自然言語の指示だけで実行できる
- データの外部送信が許されない業務にはCopilotを選ぶべき。Microsoft 365のセキュリティ基盤上で動作し、データが再学習に使われない
- 国内製造業の87%がAIパイロットを開始済み。画像認識は導入ハードルが低く最初のAI施策として最適なため、検討段階なら即座に着手すべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AI画像認識技術は2026年、コンピュータビジョン市場が349億ドル規模に到達し、企業での導入が急速に進んでいます。特にChatGPTやGeminiといったマルチモーダルAIの進化により、テキスト指示だけで高精度な画像認識が可能になりました。
本記事では、ChatGPT、Gemini、Claude、Microsoft Copilotの画像認識機能を比較し、認識精度・マルチモーダル対応・コスト・セキュリティの観点からランキング形式で紹介します。さらに、Amazon Goの無人店舗やGEヘルスケアの医用画像解析など、実際に成果を上げている企業の導入事例も解説します。
製造業では87%の企業がAIパイロットプロジェクトを開始しており、画像認識による品質検査の自動化が本格化しています。自社に最適なAI画像認識サービスの選定と導入を検討している方に向けて、実践的な指針を提供します。
目次
AI画像認識サービスとは(2026年最新ガイド)

AI画像認識は、人工知能が画像や映像の中の情報を自動的に理解・解析し、さまざまな形で応答やアクションを行う技術です。2026年時点で、コンピュータビジョン市場は349億ドル規模に達しており、アジア太平洋地域が28.9%のシェアを持つ最も成長が速い市場となっています。特にマルチモーダルAIの進化により、テキスト指示だけで画像を解析できるサービスが急速に普及し、専門知識がなくても高度な画像認識が利用可能になりました。
AI画像認識には複数の技術領域があり、用途によって使い分ける必要があります。以下の表で主要な6つの機能を整理しました。この表を参照しながら、自社のニーズに最適な機能を特定してください。
| 機能 | 概要 | 主な活用シーン |
|---|---|---|
| 物体検出 | 画像内の物体や人物を特定し位置を検出 | 自動運転、監視カメラ、物流ロボット |
| 画像分類 | 画像を特定カテゴリに自動分類 | ECサイトの商品分類、医療診断支援 |
| 画像セグメンテーション | ピクセル単位で物体や領域を分割して認識 | 自動運転の精密視覚、医療画像解析 |
| 顔認識 | 画像・映像から人間の顔を検出し個人を識別 | 入退場管理、スマホ認証、感情分析 |
| OCR(文字認識) | 画像内のテキストを検出し文字データに変換 | 書類デジタル化、名刺管理、翻訳アプリ |
| 異常検知 | 正常パターンからの逸脱を自動検出 | 製造ラインの品質管理、インフラ点検 |
実務で特に需要が高いのは物体検出とOCRです。物体検出は製造業の品質検査や自動運転で不可欠な技術であり、OCRは金融業界の書類処理自動化で年間数千万円規模のコスト削減効果が報告されています。画像セグメンテーションは医療画像の解析で特に重要であり、MRIやCTスキャンの病変検出に貢献しています。

マルチモーダルAIの進化と2026年の画像認識トレンド
2026年時点では、GPT-4oやClaude、Gemini 3 Proといったマルチモーダルモデルが画像認識の主力となっています。これらのモデルはテキストと画像を統合的に処理でき、「この画像に写っている物体を説明してください」といった自然言語での指示だけで高精度な認識結果を返します。LM Councilのベンチマークによると、MMMU(大規模マルチモーダル理解)テストではGPT-5.1が85.4%、Gemini 3 Proが81.0%、Claude Opus 4.5が80.7%のスコアを記録しています。
2026年の画像認識分野で注目すべきトレンドは3つあります。第1にエッジAIの普及です。エッジデバイス上で推論処理を完結させることで、クラウドへのデータ送信が不要になりレイテンシが大幅に低減します。第2にマルチモーダル基盤モデルの高度化です。テキスト、画像、音声、動画を横断的に処理できるモデルが標準となり、従来は別々のシステムが必要だったタスクを単一のAPIで処理できるようになっています。第3にAzure AI servicesやAzure Custom VisionなどのクラウドAPIと生成AIの融合が進んでおり、企業独自のデータでファインチューニングした画像認識モデルの構築が容易になっています。Azure Machine Learningを活用すれば、独自の画像分類モデルをノーコードで開発することも可能です。
おすすめAI画像認識サービス比較
ここからは、文章で指示を書くだけで簡単に使える生成系AIサービスの画像認識機能を比較します。今回はChatGPT、Gemini、Claude、Microsoft Copilotの4サービスを対象に、認識精度、マルチモーダル対応、使いやすさ、コスト、セキュリティの5つの観点で評価しました。

以下の表で各サービスの選定基準を整理しました。サービスによって強みが異なるため、自社の用途に応じた選択が重要です。
| 評価基準 | 評価のポイント |
|---|---|
| 認識精度 | ベンチマーク結果と実用タスクでの正確性 |
| マルチモーダル対応 | テキスト・画像・音声など複数データ形式の処理能力 |
| 使いやすさ | 直感的なUI、ドキュメントの充実度 |
| コスト | 無料枠の範囲と有料プランのコストパフォーマンス |
| セキュリティ | データ処理方針、再学習への利用有無 |
| 会社名 | 商品名 | 順位 | サイトリンク | ポイント | 詳細情報 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 初期費用 | ターゲット | 月額 | オプション価格 | お試し | 外部機器連携 | オプション価格詳細 | 追加オプション | 画像1 | 画像2 | 画像3 | |||||
| OpenAI | ChatGPT | 1 | 公式サイト | ChatGPTは、AIを駆使して人と対話することができるサービスです。簡単な質問に答えるだけでなく、文章の作成や要約、コードの生成にも対応しており、多岐にわたる応用が期待されています。 | 無料 | ChatGPTを活用したい方はもちろんのこと、これからAIを初めて利用する方 | 月額20ドル | API料金あり | 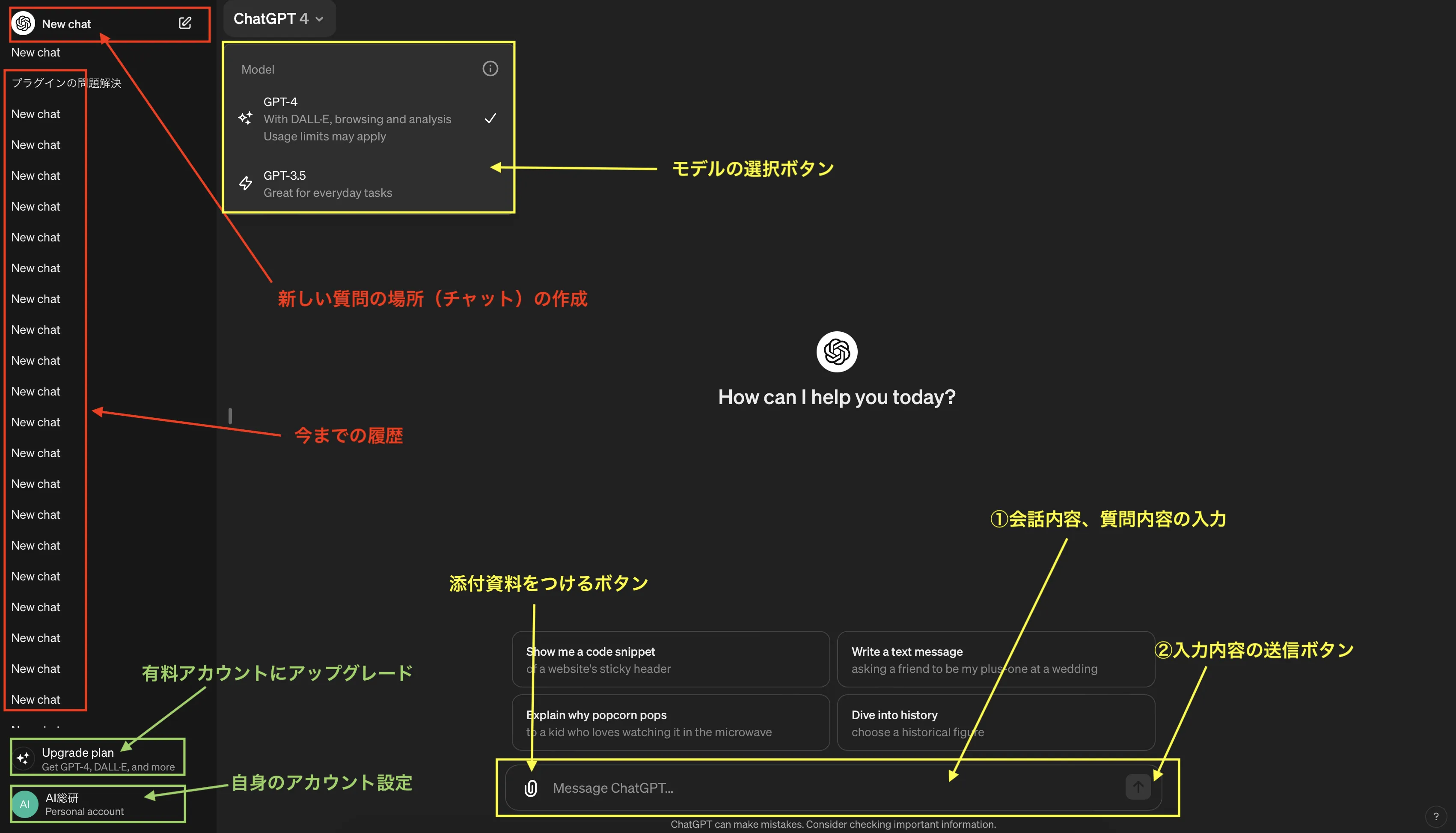 |  |  |
||||
| Anthropic | Claude | 2 | 公式サイト | Claudeは、洗練された言語能力と豊富な知識を備えており、会話や文章作成、プログラミングなど幅広いタスクに対応可能です。また、2024年6月に発表されたClaude 3.5 Sonnetは主要なベンチマーク評価において競合モデルを凌駕しています。 | 無料 | 「Claude」の高度な言語能力を活かしたタスクを実行したい方。 | 月額20ドル | API料金あり |  |  | 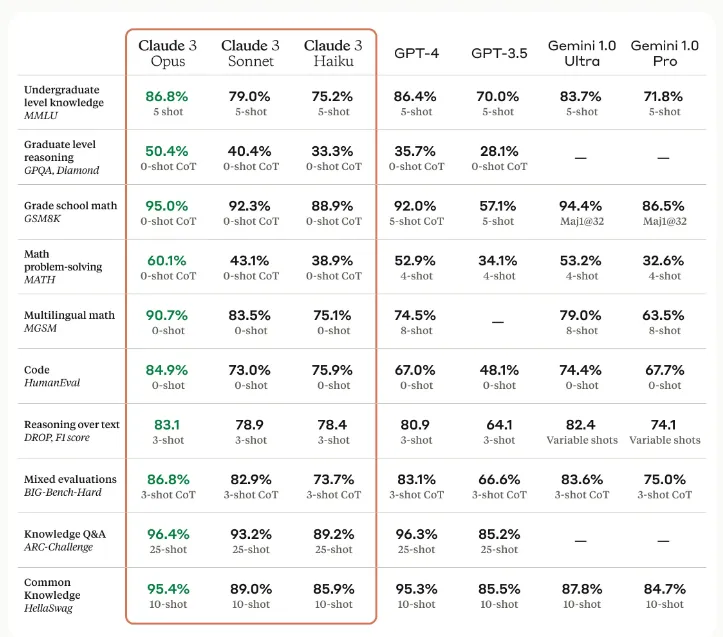 |
||||
| Microsoft | Microsoft 365 Copilot | 3 | 公式サイト | Microsoft Copilot(コパイロット)とは、Microsoft社が提供する生成AIサービスで、OpenAI社が開発した「GPT-4」とMicrosoftが従来提供していた検索エンジン「Bing」を組み合わせたものになっています。 | 無料 | Microsoft製品の使用が主な方。データの安全性を確保しつつ、業務に合わせたコンテンツ生成などをしたい方。 | 月額3,200円 | あり |  |  |  |
||||
| Gemini | 4 | 公式サイト | Gemini(旧称:Bard)は、Googleが開発した対話型AIチャットボットで、会話式インターフェース、言語の多様性、リアルタイムの情報取得、複雑なタスクへの柔軟な対応、モバイルフレンドリーなど様々な特徴が魅力です。 | 無料 | Googleの使用がメインの方。Imagen3やVeoなど最新のAI技術をUI上で試してみたい方。 | 月額 $19.99(Ultra) | あり |  | 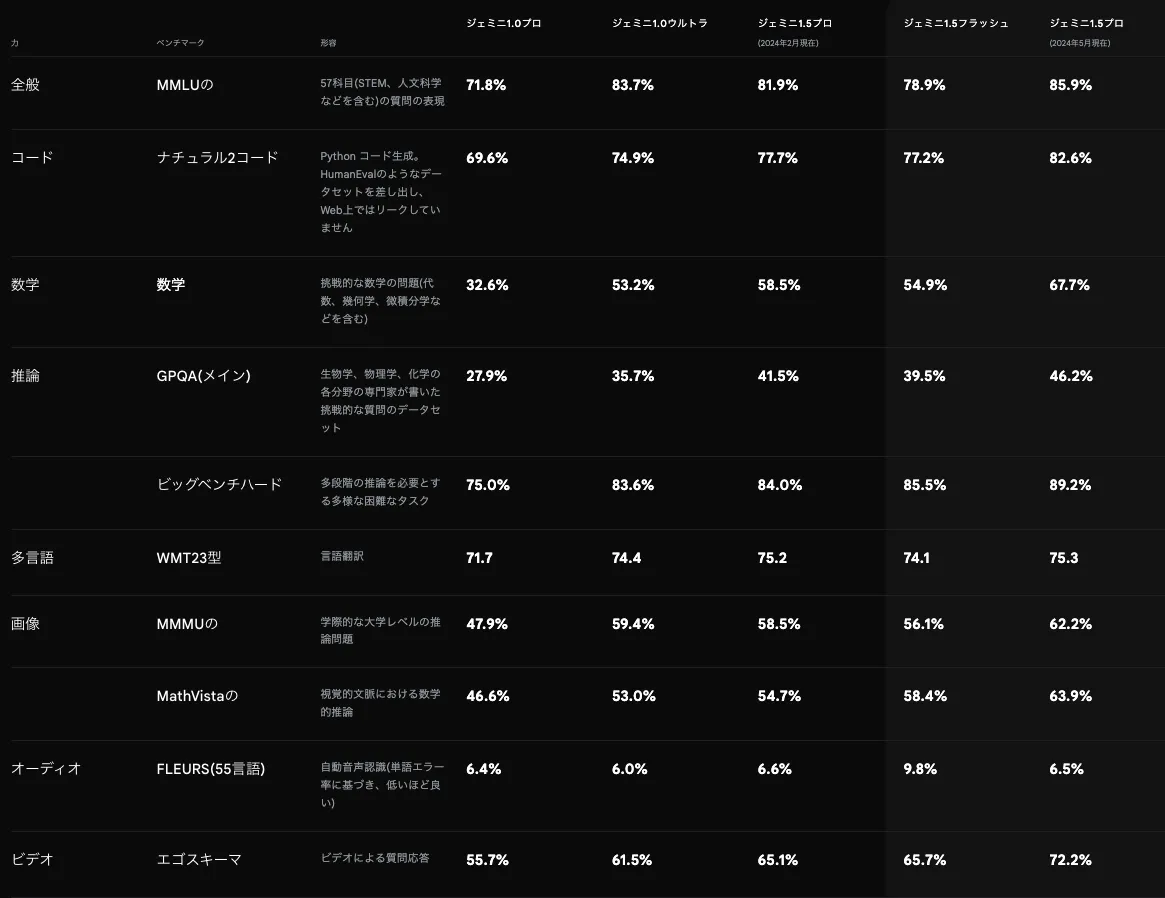 |  |
|||||
各サービスの詳細は以下のとおりです。
-
1位
ChatGPT
ChatGPTは、AIを駆使して人と対話することができるサービスです。簡単な質問に答えるだけでなく、文章の作成や要約、コードの生成にも対応しており、多岐にわたる応用が期待されています。
- 初期費用
- 無料
- ターゲット
- ChatGPTを活用したい方はもちろんのこと、これからAIを初めて利用する方
- 月額
- 月額20ドル
- オプション価格
- API料金あり
- お試し
- 外部機器連携
- オプション価格詳細
- 追加オプション
-
2位
Claude
Claudeは、洗練された言語能力と豊富な知識を備えており、会話や文章作成、プログラミングなど幅広いタスクに対応可能です。また、2024年6月に発表されたClaude 3.5 Sonnetは主要なベンチマーク評価において競合モデルを凌駕しています。
- 初期費用
- 無料
- ターゲット
- 「Claude」の高度な言語能力を活かしたタスクを実行したい方。
- 月額
- 月額20ドル
- オプション価格
- API料金あり
- お試し
- 外部機器連携
- オプション価格詳細
- 追加オプション
-
3位
Microsoft 365 Copilot
Microsoft Copilot(コパイロット)とは、Microsoft社が提供する生成AIサービスで、OpenAI社が開発した「GPT-4」とMicrosoftが従来提供していた検索エンジン「Bing」を組み合わせたものになっています。
- 初期費用
- 無料
- ターゲット
- Microsoft製品の使用が主な方。データの安全性を確保しつつ、業務に合わせたコンテンツ生成などをしたい方。
- 月額
- 月額3,200円
- オプション価格
- あり
- お試し
- 外部機器連携
- オプション価格詳細
- 追加オプション
-
4位
Gemini
Gemini(旧称:Bard)は、Googleが開発した対話型AIチャットボットで、会話式インターフェース、言語の多様性、リアルタイムの情報取得、複雑なタスクへの柔軟な対応、モバイルフレンドリーなど様々な特徴が魅力です。
- 初期費用
- 無料
- ターゲット
- Googleの使用がメインの方。Imagen3やVeoなど最新のAI技術をUI上で試してみたい方。
- 月額
- 月額 $19.99(Ultra)
- オプション価格
- あり
- お試し
- 外部機器連携
- オプション価格詳細
- 追加オプション
ChatGPTの無料版と有料版の違いについては別記事で詳しく解説しています。無料プランでもGPT-4oによる画像認識は利用可能ですが、GPT-4o miniモデルでは認識精度が異なる場合があります。ChatGPTの商用利用を検討する場合は、ビジネス向けプランのデータ保護方針を確認することを推奨します。
ChatGPTを使った画像認識の実践手順
実際にChatGPTの画像認識機能を試してみましょう。ここではGPT-4oモデルを使用した3つの認識タスクを紹介します。2026年時点ではo3やGPT-5.2など最新モデルも利用可能ですが、画像認識の基本操作はGPT-4oで十分な精度が得られます。操作手順は、OpenAIの公式サイトにアクセスしてサインイン後、クリップマークから画像ファイルをアップロードし、認識してほしいタスクをテキストで入力するだけです。
chatGPTにアクセス
以下の2枚の写真を使って、服装認識、表情認識、OCRの3つのタスクを実行しました。


1枚目の写真に対して「この写真の人たちの服装を教えてください」と入力したところ、4人の人物を正確に認識し、ネクタイやシャツの柄といった細かい部分まで正しく言及しました。

服装の認識結果
同じ写真で「この写真の人物はどのような表情をしていますか」と質問すると、各人物の表情を的確に分析し、写真全体の文脈を読み取ったコメントも返してくれました。

表情の認識結果
2枚目の手書き写真に対しては「この画像に書かれている日本語を文字起こししてください」と指示しました。手書きの文章を一字一句正確に認識でき、紙面の書類をデジタル化する際に非常に実用的です。

OCR結果
このように、生成系AIのマルチモーダル機能を使えば、プログラミング知識がなくてもテキスト指示だけで物体認識、表情分析、OCRなど多様な画像認識タスクを実行できます。ChatGPTのAPIを活用すれば、こうした画像認識機能を自社のシステムに組み込むことも可能です。
業界別活用事例と導入効果
AI画像認識は多くの業界で業務効率化とコスト削減に貢献しています。国内製造業の約87%がAIパイロットプロジェクトを開始しており、本格導入に向けた動きが加速しています。以下の表で主要6業界の活用状況を整理しました。
| 業界 | 主な活用領域 | 代表的な効果 |
|---|---|---|
| 製造業 | 品質管理・外観検査・異常検知 | 検査時間40%削減、見逃し率ゼロ化 |
| 小売業 | 顧客動線分析・在庫管理・無人レジ | 在庫補充の最適化、レジ待ち時間解消 |
| 医療 | 医用画像解析・病変検出・診断支援 | 診断時間の短縮、早期発見率向上 |
| 自動車 | 自動運転・運転者モニタリング・製造検査 | 安全性向上、居眠り運転検知 |
| セキュリティ | 顔認証・監視映像解析・不審行動検知 | リアルタイム侵入検知、入退場自動化 |
| 金融 | 書類OCR・本人確認・請求書処理 | データ入力の自動化、入力ミス削減 |
製造業で特に注目されるのは、トヨタ自動車がAI画像検査の導入により見逃し率をゼロ化した事例です。日本精工では検査精度99.9%を達成し、ヨシズミプレスは直径5mmのレーザーダイオード部品の検査時間を40%削減しました。こうした成果は、業務効率化だけでなく品質向上にも直結しています。
以下では、異なる業界で実際にAI画像認識を導入し成果を上げている3つの企業事例を詳しく紹介します。

Amazon Go 参考:Amazon
Amazonが2018年にオープンした「Amazon Go」無人店舗では、AI画像認識とセンサーフュージョンを組み合わせた「Just Walk Out」技術により、レジなしで買い物が完了します。店内のカメラとセンサーが顧客の動きをリアルタイムで追跡し、商品を手に取ったり棚に戻したりする動作をAIが瞬時に判別します。これにより店舗スタッフの削減、リアルタイムの在庫管理、顧客の購買行動分析が実現し、小売業における画像認識活用の代表的な成功事例となっています。

GEヘルスケア 参考:GEヘルスケア
GEヘルスケアの「Edison AI」プラットフォームは、MRI、CTスキャン、X線などの医療画像をAIが解析し、医師の診断を支援します。特に肺がんの早期発見や脳卒中のリスク評価において優れた性能を発揮し、従来数時間から数日かかっていた診断が数分で完了するケースもあります。AIが微細な異常を自動マーキングすることで、医師の見落としを防ぎつつ負担を軽減しています。fcuro社の全身検索型画像診断AI「ERATS」も、全身CT画像を10秒以内に解析して病変箇所を抽出できるなど、医療AIの進化は著しいものがあります。

みずほ銀行 参考:PRIMES
みずほ銀行では、OCR技術を導入して紙ベースの書類処理を自動化しています。申請書や契約書、本人確認書類をスキャンし、AIが内容を読み取ってデジタル化することで、手動データ入力にかかる時間を大幅に短縮しました。手書き文字やフォーマットの異なる書類にも対応でき、入力ミスの削減と顧客対応のスピードアップを実現しています。ChatGPTの業務効率化を参考にすれば、OCRと生成AIを組み合わせたさらに高度な書類処理の自動化も可能です。
企業の導入成果と最新データ
2026年時点のAI画像認識市場は、画像認識単体で56.8億ドル規模と推計されており、2031年までに年平均成長率で拡大を続ける見込みです。アジア太平洋地域の成長率は15.61%と世界で最も高く、日本を含む地域での導入加速が顕著です。ハードウェアセグメントが市場の62.2%を占めている点は、エッジデバイスでの推論処理需要の高さを反映しています。
ChatGPTの活用事例としても、画像認識は最も導入が進んでいる分野のひとつです。特にLangChainなどのフレームワークを活用すれば、GPT-4oの画像認識機能と自社データベースを連携させたカスタムアプリケーションを比較的短期間で構築できます。大阪王将(イートアンドホールディングス)では、AI画像認識による餃子12個入りパックの検品を約1秒で完了するシステムを導入しており、食品業界でも導入効果が実証されています。

導入時の注意点と選び方ガイド

AI画像認識サービスの導入にあたっては、技術的な性能だけでなくセキュリティやコスト面も含めた総合的な判断が必要です。画像データには個人情報や機密情報が含まれることが多いため、セキュリティリスクへの対策は特に重要です。以下の表で導入時に確認すべき5つのポイントを整理しました。
| 確認項目 | 確認内容 | 対応策 |
|---|---|---|
| データの取扱い | アップロード画像がモデル再学習に使用されるか | エンタープライズプランまたはAPI利用を選択 |
| 認識精度 | 自社のデータで必要な精度が得られるか | PoCで実データによる精度検証を実施 |
| コスト構造 | 無料枠の上限と有料プランの料金体系 | 処理量を見積もり月額コストを試算 |
| コンプライアンス | 個人情報保護法やGDPRへの準拠状況 | プライバシーポリシーとデータ処理地域を確認 |
| 拡張性 | API連携や独自モデルの構築が可能か | 将来的な自動化パイプラインを見据えて選定 |
コスト面では、ChatGPTのAPIを使った画像認識はトークン単位の従量課金となり、画像サイズによって消費トークン数が変動します。大量の画像を処理する場合は、APIコストが想定以上に膨らむことがあるため、事前に処理量の見積もりを行うことが重要です。一方、Azure Custom VisionのようなPaaS型サービスは月額固定の予測コストが立てやすく、大規模運用に適しています。
導入ステップとよくある質問
AI画像認識の導入は、以下の3ステップで進めることを推奨します。第1ステップとして、まず無料プランや無料枠を使って自社の画像データでPoCを実施し、必要な認識精度が得られるかを検証します。第2ステップでは、PoCの結果をもとにサービスとプランを確定し、小規模な業務プロセスへの組み込みを行います。第3ステップで、運用実績を踏まえて全社展開と自動化パイプラインの構築に進みます。
導入を検討する際によくある質問として、「専門知識がなくても使えるのか」という点があります。2026年の生成系AIサービスは、テキストで指示を入力するだけで画像認識が完了するため、プログラミング知識は不要です。ただし、企業システムへの組み込みや大量処理の自動化にはプログラミングスキルが必要になる場合があります。OCRの認識精度については、高品質な画像であれば手書き文字も高精度で認識可能ですが、画像がぼやけている場合や特殊なフォントでは精度が低下することがあります。セキュリティ面では、多くのサービスがアップロード画像を処理後に保存しない設計になっていますが、利用するサービスのプライバシーポリシーを必ず確認し、機密情報を含む画像の取扱いには十分注意してください。

AI総合研究所
画像認識AIをはじめとするAI技術のビジネス導入をご検討の方は、AI総合研究所のご相談・お問い合わせフォームからお気軽にご相談ください。

画像認識AIの知見を組織導入に発展させる
AI画像認識サービスの比較評価で培った技術選定力は、組織としてAIを業務全体に導入する際の基盤になります。画像認識のパイロットで得た成果を、他の業務領域にも段階的に展開していくことが次のステップです。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に進めるための220ページの実践ガイドを無料で提供しています。AI総合研究所の専任チームが、AI技術の評価力を全社的な導入ロードマップに落とし込むところまで支援します。
画像認識AIの知見を組織導入に発展させる

AI技術評価から全社の業務設計へ
AI画像認識サービスの比較評価で培った技術選定力を、組織としてAIを業務に組み込む段階設計に活かしませんか。220ページの実践ガイドで段階的な導入の進め方を解説しています。
まとめ
AI画像認識サービスは2026年、コンピュータビジョン市場349億ドル規模の中で急速に進化し、マルチモーダルAIの登場によりテキスト指示だけで高精度な画像認識が可能になっています。ChatGPT、Gemini、Claude、Copilotといった主要サービスはそれぞれ異なる強みを持ち、用途に応じた使い分けが重要です。
製造業での品質検査自動化(検査時間40%削減、見逃し率ゼロ化)、医療分野での診断時間短縮、金融業界でのOCRによる書類処理自動化など、AI画像認識の導入効果は業界を問わず実証されています。国内製造業の87%がAIパイロットプロジェクトを開始しており、画像認識はAI導入の最も実用的な入口のひとつとなっています。
まずは無料プランで自社の画像データを使ったPoCから始めてみてください。認識精度とコストを検証した上で、小規模な業務プロセスへの組み込みから段階的に拡大していくことで、着実な導入効果を得ることができます。










