この記事のポイント
 自社専用の画風・キャラクターを再現したいなら、フルファインチューニングよりLoRAを第一候補にすべき。コスト10分の1以下で同等品質が出せる
自社専用の画風・キャラクターを再現したいなら、フルファインチューニングよりLoRAを第一候補にすべき。コスト10分の1以下で同等品質が出せる- GPU予算が限られる個人・中小企業はLoRA一択。VRAM 12GBのローカル環境でも独自モデルを学習可能
- タスクごとにLoRAモジュールを切り替える運用設計が最適。1つの基盤モデルで複数用途に対応でき、ストレージも軽量
- Kohya_ss GUIを使えばコーディング不要で学習可能。まず20〜30枚の画像で小規模PoCから始めるのが有効
- 商用利用時は学習データの権利処理と生成物の類似性チェックを必ず実施すべき。著作権リスクを放置したまま運用するのは避けるべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
2025年現在、AIモデルの効率的なカスタマイズ手法として「LoRA (Low-Rank Adaptation)」が、LLMのみならず画像生成AIの分野でも標準的な技術として定着しています。フルファインチューニングに比べて計算コストやメモリ消費を大幅に削減できるため、個人開発者からエンタープライズまで幅広く採用が進んでいます。
本記事では、LoRAの技術的な仕組みからメリット、Stable Diffusion WebUIを用いた具体的な導入・学習手順、そして商用利用における著作権リスクと対策までを体系的に解説します。
目次
LoRA(Low-Rank Adaptation)とファインチューニングの違い
<br>こうしたメリットにより、LoRAは 「大規模モデル時代の現実的な落としどころ」 として、多くの画像生成ワークフローに組み込まれています。
ステップ2: Stable Diffusion WebUIの起動
医療画像診断(MeLo:Medical image Low-rank adaptation)
LoRA(Low-Rank Adaptation)とは?

LoRAとは
LoRA(Low-Rank Adaptation)は、もともと 大規模言語モデル(LLM)を効率的に特定タスクへ適応させるため に提案された手法です。その後、Stable Diffusion のような画像生成モデルにも広く応用され、現在では「LLM用のテクニック」と「画像生成AI向けの拡張」が両方の文脈で語られるようになっています。
ここでは、とくに 画像生成AIにおけるLoRA を軸にしつつ、元々のアイデアも含めて整理していきます。
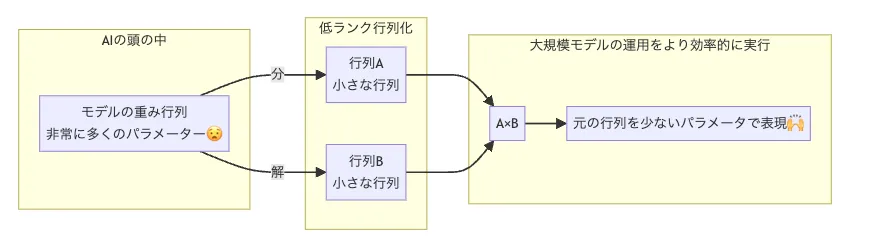
低ランク行列を使ってモデルの効率性を向上させる仕組み
LoRAでは、モデルの重み行列(パラメータ行列)に対して 「低ランク行列」を追加で学習する** というアプローチを取ります。イメージとしては、次のような流れです。
- もともとの重み行列 W₀ はそのまま固定しておく
- そこに、低ランク行列 A と B の積で表現される差分 ΔW = B A を足し合わせる
- 学習時には W₀ は更新せず、A と B(=ΔWの部分)だけを学習 する
このようにすることで、元のモデル全体をフルで学習し直すことなく、ごく一部の追加パラメータだけでモデルを「カスタマイズ」できる のがLoRAの特徴です。

LoRA(Low-Rank Adaptation)とファインチューニングの違い
LoRAと、従来型の「フルファインチューニング」の主な違いは、どのパラメータをどこまで更新するか です。
以下の表では、LoRAとフルファインチューニングを、パラメータの更新範囲・コスト・運用のしやすさといった観点で比較します。
| 項目 | LoRA | ファインチューニング |
|---|---|---|
| パラメータ更新 | 追加の低ランク行列のみ更新(元の重みは凍結) 全体のごく一部(1%未満〜1/10000程度)の更新で済むケースが多い |
モデルの全パラメータを更新(数億〜数千億パラメータ規模をすべて学習し直す) |
| 計算コスト | 学習するパラメータが少ないため軽い 単一GPU・短時間で終わるケースも多い |
パラメータ数に比例して重い 大規模GPUクラスタ・長時間の学習が必要になりがち |
| メモリ使用量 | 追加の低ランク部分+中間結果のみ保持で済む フルFTと比べてGPUメモリを大きく節約可能 |
モデル全体を更新・保持する必要があるため、大きなGPUメモリが必要 |
| タスク切り替え | LoRAモジュール(差分部分)を差し替えるだけで、タスクごとの個性を切り替えられる | タスクごとにフルモデルを別々に持つ必要があり、切り替え・配布ともに重い |
| 適応環境 | ローカルPCや小〜中規模サーバーでも運用しやすい | 高性能サーバーやクラウドGPU前提になりやすい |
HuらのLoRA論文では、GPT-3 175Bのような巨大LLMに対して、学習パラメータを最大1/10000まで削減しつつ、GPUメモリを約1/3程度に抑えられた と報告されています。
この「ごく一部だけを学習する」という発想が、そのままStable Diffusionなどの画像生成モデルにも応用されている、というイメージです。
LoRAの特徴
LoRAは、少ないリソースで効率的にモデルを調整できる ことから、個人開発〜企業利用まで幅広いシーンで活用されています。
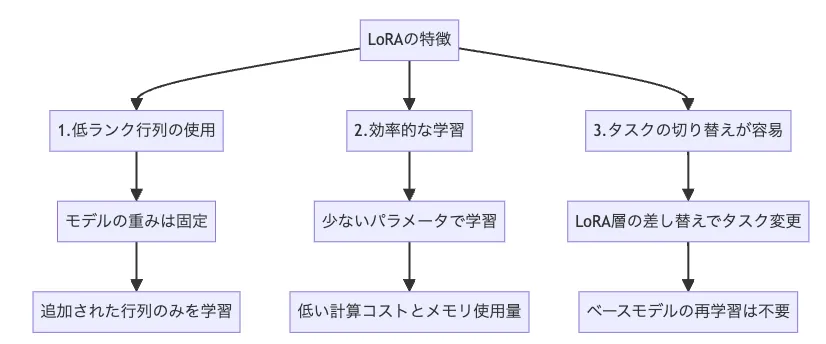
LoRAの特徴
-
低ランク行列の使用
モデルの重み行列に、低ランクの行列(A・B)からなる差分 ΔW を追加します。
元の重み W₀ は凍結したまま、追加分だけを学習する ことで、学習対象のパラメータ数を大幅に削減できます。
-
効率的な学習
学習するパラメータが少ないため、計算コスト・メモリ使用量ともに抑えられます。
その結果、これまではクラウドGPUが必須だったようなタスクも、ローカル環境や比較的小さなGPUで扱いやすくなる 場合があります。 -
タスクの切り替えが容易
ベースモデルを固定したまま、LoRA層(差分部分)を差し替えるだけでタスクを切り替えられるため、- 「キャラクターA用LoRA」
- 「水彩画スタイル用LoRA」
のように、用途ごとに軽量なモジュールを増やしていく運用がしやすくなります。
ファインチューニングの特徴
一方で、従来型のフルファインチューニングは、依然として強力な手法 です。
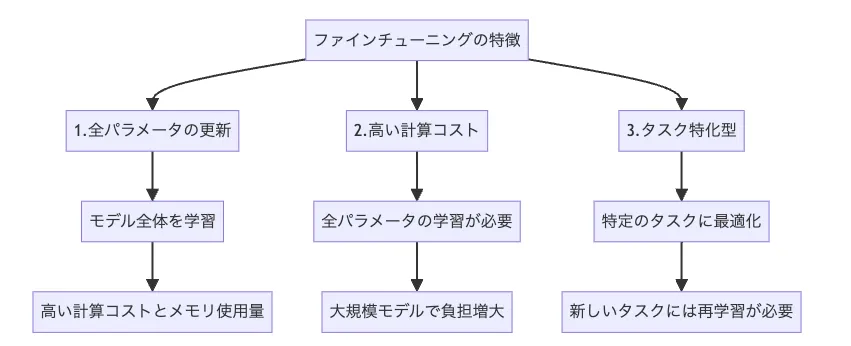
ファインチューニングの特徴
-
全パラメータの更新
モデルのすべてのパラメータを更新するため、特定タスクに対して非常に高い適合度を得やすい一方、計算コスト・メモリ使用量は大きくなります。 -
高い計算コスト
大規模モデルでは、フルファインチューニングを行うために複数GPU・長時間の学習が必要になることも多く、
個人や小規模チームにはハードルが高くなりがちです。 -
タスク特化型になりやすい
一つのタスクに強く最適化される反面、別タスクに転用する際には、再度フルファインチューニングが必要になります。
そのため「タスクごとに巨大なモデルを何個も抱える」構成になり、運用・保守の面でコストがかさみます。

画像生成AIにおけるLoRAの役割
ここからは、Stable Diffusionなどの 画像生成AIにおけるLoRAの役割 に絞って整理します。
LoRAを画像生成AIに導入する主なメリットは次のとおりです。
-
低コストでのファインチューニング
- 少ないデータ・短時間でモデルをチューニングできるため、個人開発者やスタートアップでも扱いやすい
- 「とりあえずLoRAで試してみる」→「必要なら別の手法も検討」というステップが踏みやすい
-
画像生成のクオリティ向上
- 特定のキャラクター・作風・ブランドカラーなどをLoRAに落とし込むことで、
好みに合わせた画像生成 がしやすくなります。
- 特定のキャラクター・作風・ブランドカラーなどをLoRAに落とし込むことで、
-
同一人物・キャラクターの一貫した生成
- 一度LoRAを作ってしまえば、「同じキャラクターをポーズ違いで量産する」「同じブランドキャラクターを様々なシーンに登場させる」といったことが容易になります。
- 一度LoRAを作ってしまえば、「同じキャラクターをポーズ違いで量産する」「同じブランドキャラクターを様々なシーンに登場させる」といったことが容易になります。
-
特定スタイルへの適応
- 水彩画・アニメ風・写真風など、特定スタイル専用のLoRAを用意しておくことで、
プロンプトから簡単にスタイルを切り替えられます。
- 水彩画・アニメ風・写真風など、特定スタイル専用のLoRAを用意しておくことで、
-
計算資源の節約
- LoRAはあくまで「ベースモデルに足す差分」なので、
- 保存するファイルサイズ
- 学習や推論で使うGPUメモリ
をコンパクトに抑えられます。
- LoRAはあくまで「ベースモデルに足す差分」なので、
こうしたメリットにより、LoRAは 「大規模モデル時代の現実的な落としどころ」 として、多くの画像生成ワークフローに組み込まれています。
LoRAの作り方
LoRAを自前で作成・利用する方法は、ざっくり分けると次の5パターンがあります。
それぞれの方式を、初期設定の難易度・コスト・リソースなどの観点から比較してみましょう。
| 指標 | 1.ローカル環境でおこなう | 2.Google Colabを使用する | 3.クラウド (AWS, Azure, etc.)を使用する | 4.Hugging Face Spacesを使用する | 5.Kaggle Notebooksを使用する |
|---|---|---|---|---|---|
| 初期設定の難易度 | 高: ハードウェア設定や依存関係のインストールが必要 | 低: 比較的簡単に設定可能 | 中: クラウド設定やコスト管理が必要 | 低: ノーコードで簡単にデプロイ可能 | 低: 事前設定された環境が利用可能 |
| コスト | 既存のハードウェアを使用 | ¥1,179~/月 (Colab Pro) | 使った分だけ料金が発生 | 無料 (制限あり) | 無料 (制限あり) |
| リソースのパワー | ハードウェアに依存 | 中程度: 高性能なGPUが利用可能 | 高: 必要なリソースに応じてスケール可能 | 低: 制限されたリソースを使用 | 中程度: 無料でGPUを利用可能 |
| 継続性 | 高 | 低: セッション時間制限や切断のリスクあり | 高: 常時利用可能 | 低: 無料枠でリソースが限られる | 低: セッションごとの制限あり |
| 学習パラメータの管理 | 高: 自分で完全に制御可能 | 中: セッションごとにリセットのリスクあり | 高: 完全にカスタマイズ可能 | 低: 既定の設定で動作 | 低: 自動設定に依存 |
この記事では、このうち 「ローカル環境で学習するパターン」 を例に、Mac環境での導入手順を説明していきます。
【使用したPC】
MacBook Air
チップ:Apple M2
OS:Sonoma14.6.1
下準備編

LoRAをローカル環境に導入する下準備
ここからは、Macローカル環境に
- Homebrew
- Stable Diffusion Web UI(AUTOMATIC1111)
- Kohya's GUI
を順に導入していきます。
1. Homebrewのインストール
- まず、ターミナルを開き、以下のコードを貼り付けて Homebrew をインストールします。
ターミナルは Finder の「ユーティリティ」フォルダ内にあります。

このコードをターミナルに貼り付けます
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
パスワードを求められた場合は、Macのロック解除に使用するパスワードを入力します(入力中の文字は表示されませんが、正常に入力されています)。
- 次に、以下のコマンドを実行してパスを設定します。
export PATH="$PATH:/opt/homebrew/bin/"
- インストールが完了したかどうかを確認するには、以下のコマンドをターミナルに入力します。
brew --version
- 「Homebrew 4.3.1」のようにバージョンが表示されれば、インストール成功です🍺
2. Stable Diffusion Web UI(AUTOMATIC1111)のインストール
続いて、Stable Diffusion WebUI をローカルに導入します。
- 以下のコマンドで必要なライブラリをインストールします。
brew install cmake protobuf rust python@3.10 git wget
- Stable Diffusion Web UIのリポジトリをローカルPCにクローンします。
以下のコードをターミナルで実行してください。
GitHubからStableDiffusionをクローン
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
- Stable Diffusion WebUI がインストールされているディレクトリに移動します。
cd ~/stable-diffusion-webui
- WebUI を起動するためのコマンドを実行します。
./webui.sh
-
ターミナルに表示された URL(通常は
http://127.0.0.1:7860のような形)をブラウザに入力してアクセスします。
これで、Stable Diffusion WebUI を利用できます。 -
動作確認として、
txt2imgに「a dog, wearing a hat」(帽子を被った犬)などのプロンプトを入力してみましょう。
「Generate」をクリックし、右下に画像が出力されればOKです。
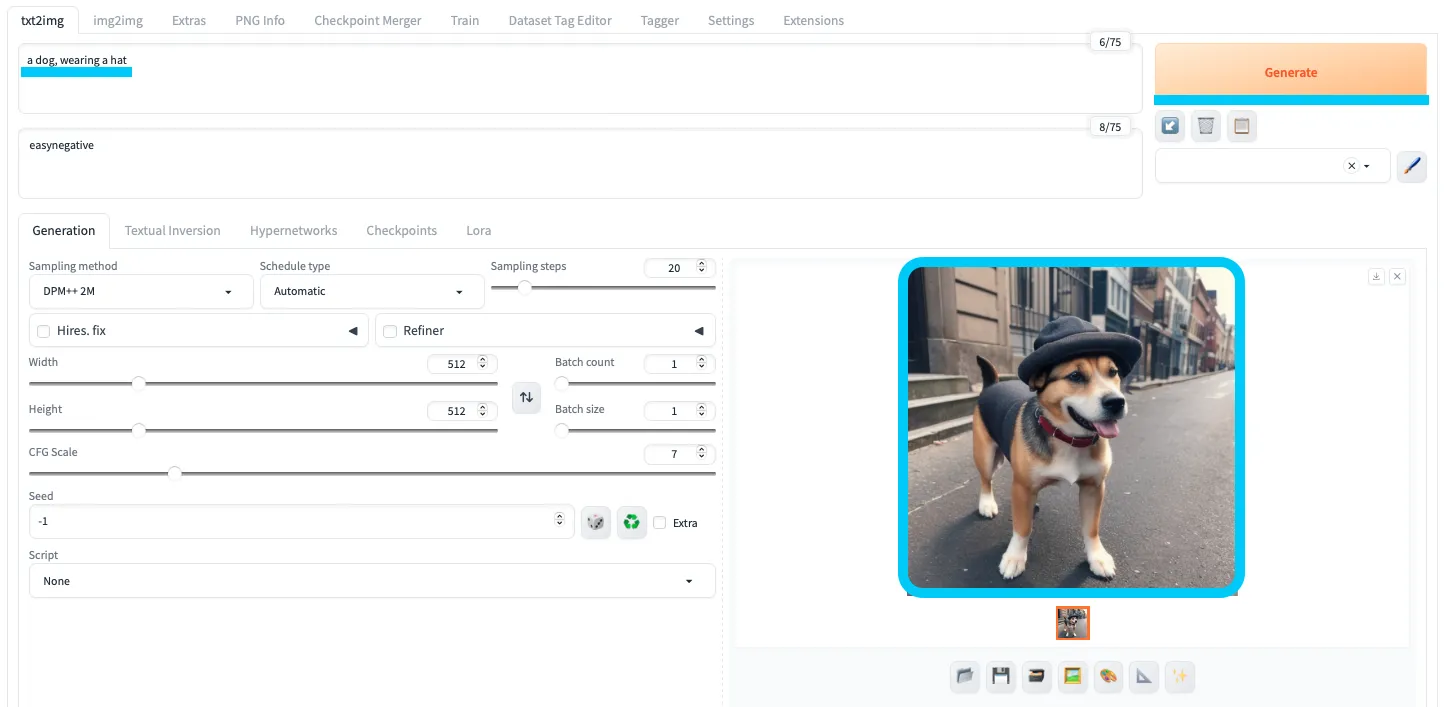
Stable Diffusion Web UIでの画像生成を確認
ここまでで、Web UIのセットアップは完了です。
3. Kohya's GUIのインストール
まずはPython環境を整え、Kohya_ss GUIをセットアップします。
下準備
Kohya_ss GUIを実行するには、Python 3.10.9以上、3.11.0未満のバージョンが必要です。
ターミナルで python --version と入力するとバージョン確認が可能です。必要に応じて再インストールしてください。
仮想環境の有効化
python -m venv venv
source venv/bin/activate
インストール手順
Kohya_ss GUIをインストールします。
git clone https://github.com/bmaltais/kohya_ss.git
cd kohya_ss
セットアップを開始するには、次のコマンドを実行します。
./setup.sh
続いて、必要なPythonモジュールを一括インストールします。
pip install -U -r requirements.txt
その後、以下のコマンドでKohya's GUIが立ち上がるか確認します。
./gui.sh
リンクをクリック
ブラウザが立ち上がり、Kohya_ss GUIの画面が表示されれば準備完了です。
LoRAの作成方法
ここまでで環境準備が整いました。
次は、実際に LoRAを学習させるためのデータ準備〜学習実行 の流れを見ていきます。
全体のステップは次の2つです。
Stable Diffusionで学習用データを用意する
1. 学習用画像の用意
まず、Kohyaのディレクトリ内に学習用フォルダを作成します。
例として、以下のようなディレクトリ構成を目指します。
Kohya/
├── outputs/
├── training/
│ └── 20_robot/
│ ├── robot_1.png
│ ├── robot_1.txt
│ ├── robot_2.png
│ ├── robot_2.txt
│ ├── robot_3.png
│ ├── robot_3.txt
│ ├── robot_4.png
│ └── robot_4.txt
└── training_archive/
今回は 20_robot というフォルダを作成し、その中に学習させる画像を格納していきます。
処理負荷とのバランスを考えると、20〜30枚程度 がひとつの目安です。
画像のサイズ・縦横比はバラバラでも構いませんが、連番のファイル名に変更しておく ことをおすすめします。
これはLoRAがトレーニング画像を正しく読み込むための実務上のコツです。
2. 拡張機能の使用
Stable Diffusion Web UIは拡張機能を追加することで、学習用データの準備を効率化できます。
ここでは、次の2つの拡張機能を使います。
それぞれの役割は次のとおりです。
【Tagger】
- 画像から自動的にプロンプト(タグ)を生成してくれるツールです。
- 画像に対して一からタグを付ける手間を省き、LoRA学習用のテキストデータを一気に用意できます。
【Dataset Tag Editor】
- Taggerで生成されたプロンプトを手動で編集するためのツールです。
- 不要なタグの削除・有用なタグの追加など、微調整によるデータ品質アップ に役立ちます。
「自動生成プロンプトでほぼ十分」というケースではTaggerだけでも構いませんが、
高品質なLoRAを目指す場合は、Dataset Tag Editorと組み合わせて使うのがおすすめです🙆♂️
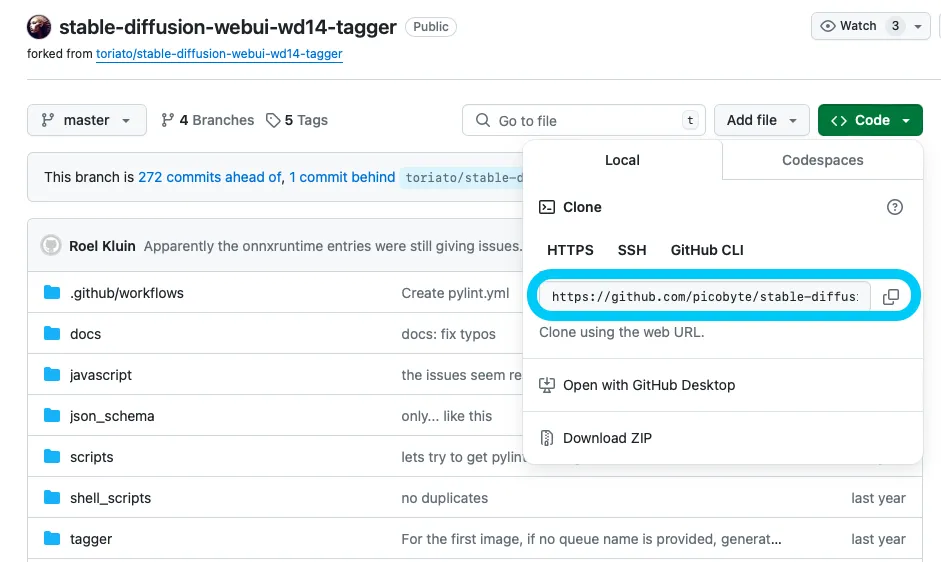
GitのURLはここ
「URL for extension’s git repository」にGitのURLを入力し、「Install」を押します。
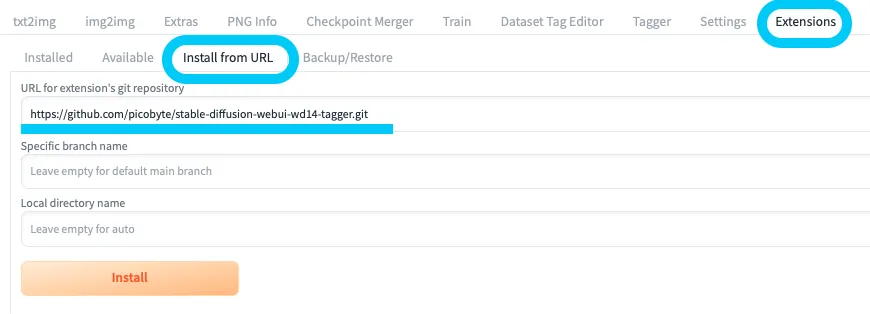
ここにURLを入力
その後、「Installed」タブに戻り、拡張機能が反映されていることを確認したうえで「Apply and restart UI」をクリックします。
Tagger と Dataset Tag Editor それぞれに対して同じ操作を行います。
Apply and restart UIをクリックして完了
【Taggerの使い方】
Taggerのインストールが完了したら、先ほどの学習画像フォルダに対して自動タグ付けを行います。
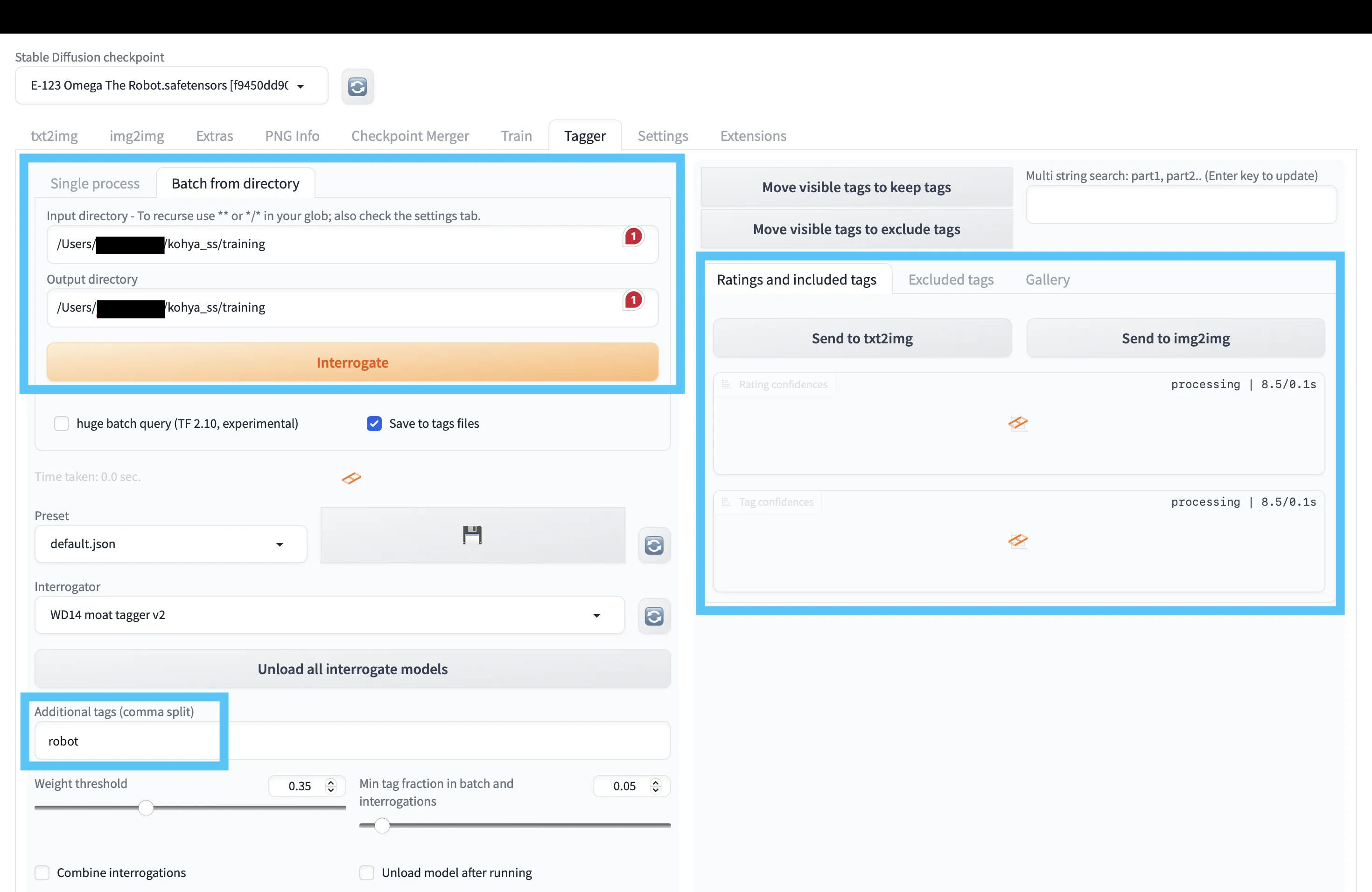
Taggerの設定を行う
- 「Batch from directory」で「Input directory」「Output directory」に、学習画像を格納したフォルダのパスを設定します。
- 画面下部の「Additional tags (comma split)」には、
[学習の繰り返し回数]_[トリガープロンプト]に含めた トリガープロンプト を入力します。
設定ができたら Interrogate をクリックし、処理が完了するまで待てばOKです。
【Dataset Tag Editorの使い方】
続いて、Dataset Tag Editor を使ってタグの微調整を行います。
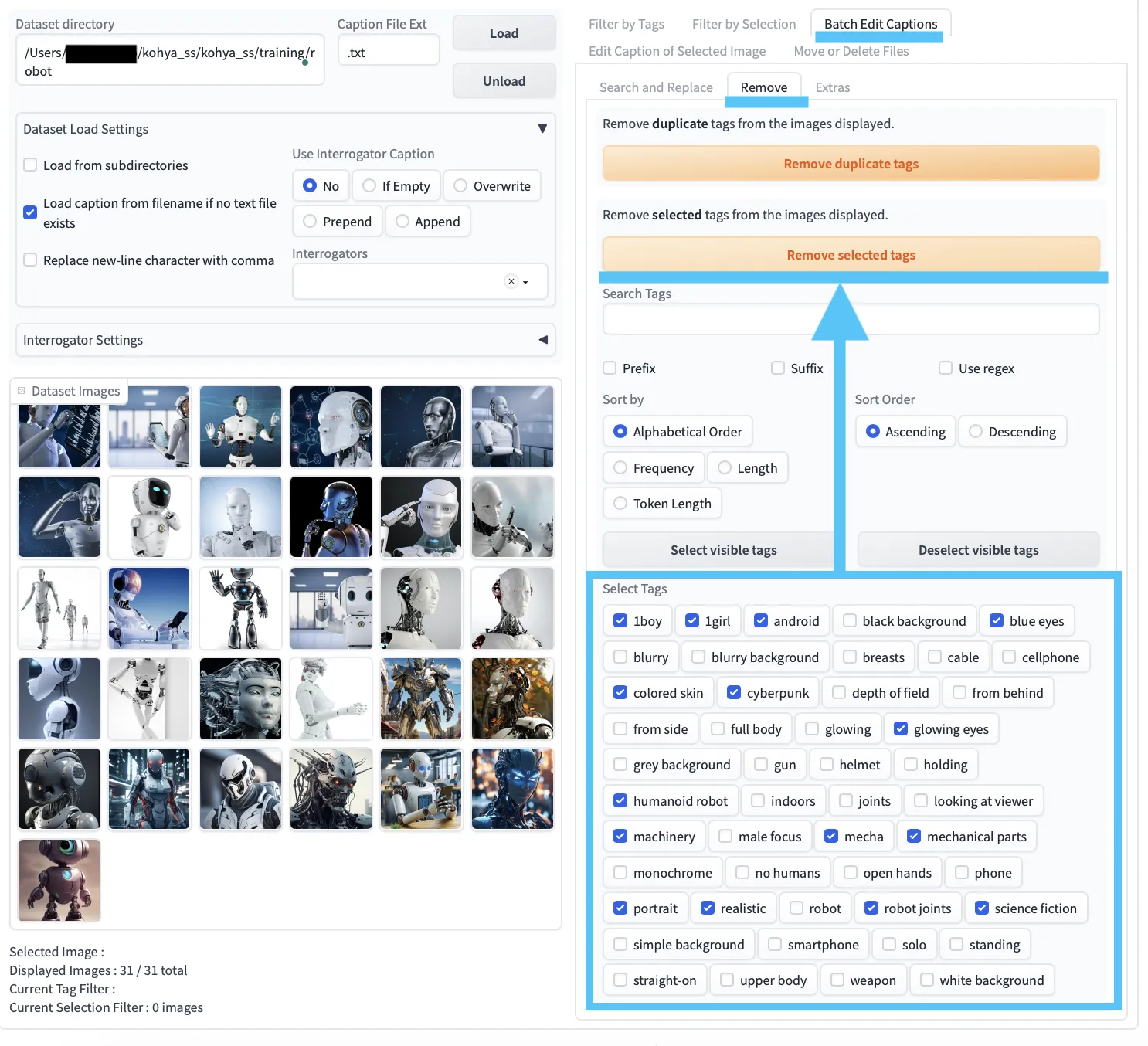
学習してほしいタグにチェックをつけて、Remove selected tagsをクリック
操作の流れは次の通りです。
- 「Dataset directory」に、Taggerで処理した学習画像フォルダを指定し、「Load」をクリックします。
Batch Edit Captions > Removeで削除対象のタグを選び、「Remove selected tags」をクリックします。
ここまでで、LoRA学習用の画像データ・キャプション準備は完了です。
KohyaでLoRAを作成する
続いて、Kohya_ss GUI側の設定を行い、LoRAの学習を実行します。
1. 「LoRA > Training」タブの選択
LoRAタブを開きます
Kohyaの最上部メニューから「LoRA > Training」を選択します。
誤って「DreamBooth」タブで設定しないよう注意しましょう。
2. Accelerate launch設定
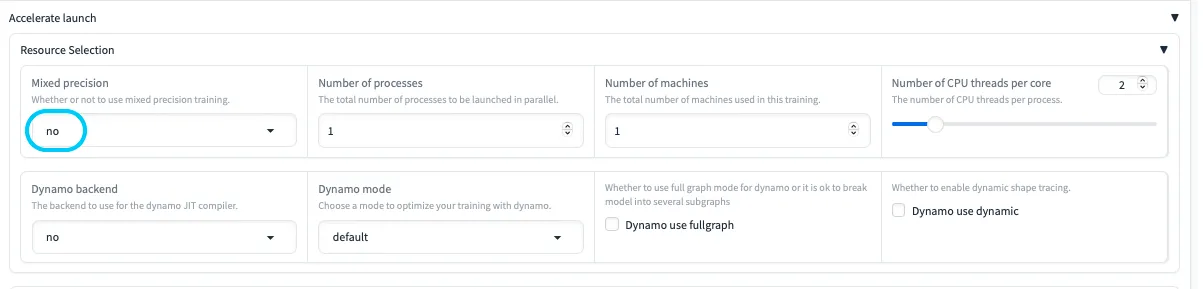
デフォルトはfp16になっているので注意
Mac(MPS)環境では、mixed precision(fp16など)まわりでエラーが出やすいため、
Mixed Precision を no に設定するのが無難です。
| 設定項目 | 説明 |
|---|---|
| Mixed precision | 半精度演算によるメモリ削減・高速化。MPS環境では no 推奨。 |
| Number of processes | 同時実行プロセス数。増やすと高速化するがCPU負荷が増える。 |
| Number of machines | 分散学習用のマシン数。通常1でOK。 |
| Number of CPU threads per core | 各プロセスに割り当てるCPUスレッド数。 |
| Dynamo backend / mode | PyTorchのDynamo JIT最適化に関する設定。互換性に注意。 |
3. Models設定
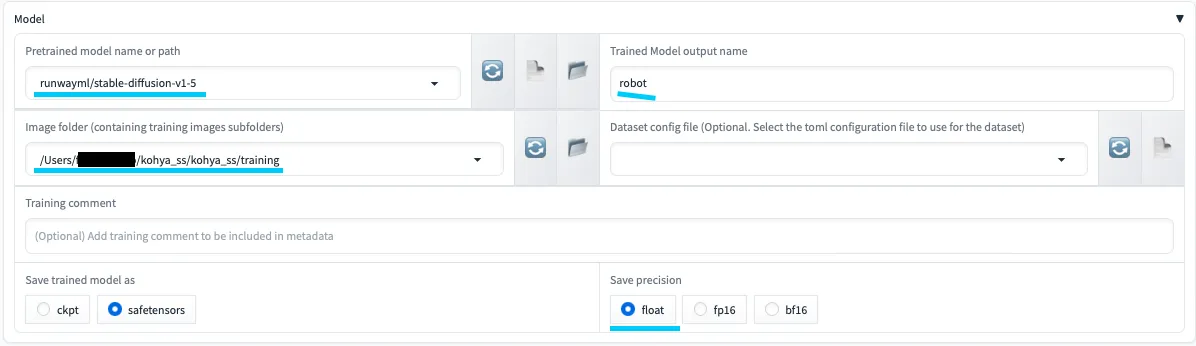
Models設定
ここでは、学習のベースとなるStable Diffusionモデルを選択します。
⭐️付きのモデルは、比較的軽く、Mac環境でも動作しやすいものを目安にしています。
| 用途 | モデル | GPU推奨度 | ローカルでの使用 |
|---|---|---|---|
| 高品質な画像生成・修正 | stabilityai/stable-diffusion-xl-base-1.0 stabilityai/stable-diffusion-xl-refiner-1.0 |
高(ハイエンドGPU推奨) | 可能だがリソース消費大 |
| 512x512サイズの画像生成 ⭐️ | stabilityai/stable-diffusion-2-1-base/blob/main/v2-1_512-ema-pruned | 中 | ○ |
| 一般的な用途 ⭐️ | stabilityai/stable-diffusion-2-1-base stabilityai/stable-diffusion-2-base stabilityai/stable-diffusion-2 |
中 | ○ |
| 768x768サイズの高解像度画像生成 | stabilityai/stable-diffusion-2-1/blob/main/v2-1_768-ema-pruned | 高 | 可能だがリソース消費大 |
| 多用途・高品質な画像生成 | stabilityai/stable-diffusion-2-1 | 高 | リソースに余裕があれば検討 |
| 軽量で高速な画像生成 ⭐️ | runwayml/stable-diffusion-v1-5 | 低〜中 | ◎ |
| 設定項目 | 説明 | 注意点 |
|---|---|---|
| Pretrained model name or path | 使用する事前学習済みモデルの名前またはパスを指定。 | Mac環境では⭐️付きの比較的軽いモデル推奨。 |
| Image folder | トレーニングに使用する画像フォルダのパス。 | 日本語パス・特殊文字を避けるとトラブルが減る。 |
| Trained Model output name | 学習後のLoRAファイル名。 | 後から見て分かりやすい名前を付ける。 |
| Dataset config file (Optional) | .toml 形式のデータセット設定ファイル。 |
必須ではないため、まずは空欄でOK。 |
| Save trained model as | 保存形式(safetensors など)。 |
Macでは safetensors 推奨。 |
| Save precision | 保存時の精度(float / fp16 など)。 |
MPS環境では float のほうが無難。 |
特に重要なのが Image folder (containing training images subfolders) の設定です。
class1,class2など複数のクラスフォルダがある場合も、
必ずその親フォルダ(例:/training)を指定する ようにします。- Kohya_ssは、親フォルダ配下のサブフォルダと画像を自動的に認識してくれます。
4. Folders・Dataset Preparation設定
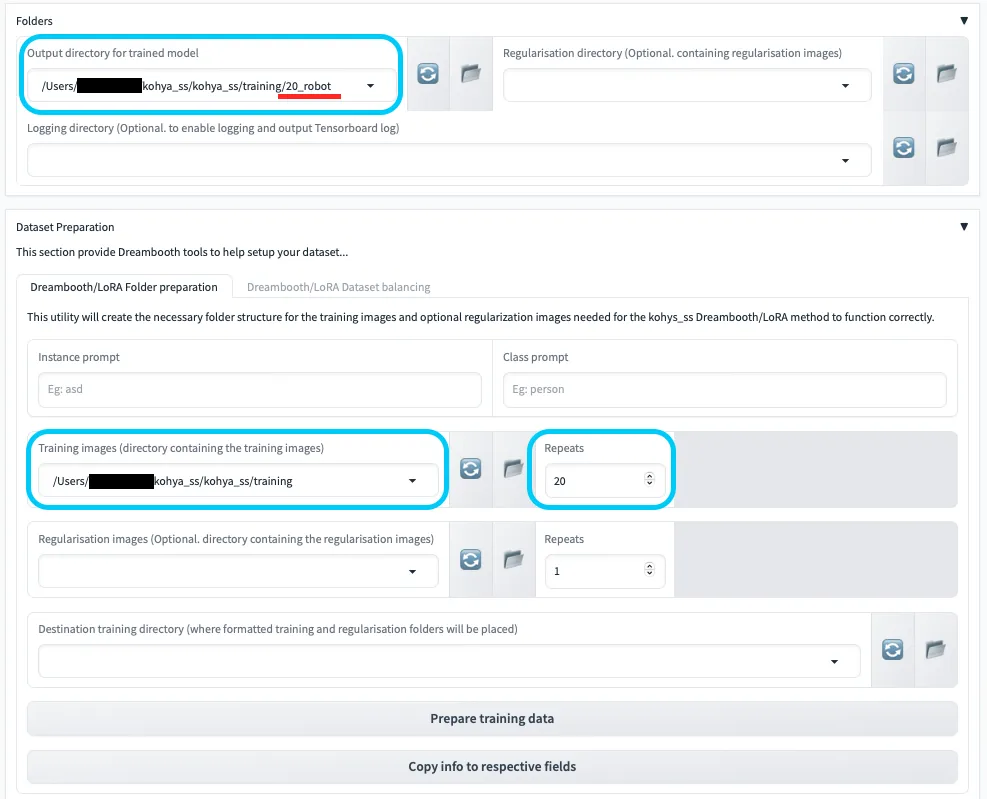
Folders・Dataset Preparation設定
LoRA学習で生成されるファイルの保存先や、トレーニング画像の場所をここで指定します。
| 設定項目 | 説明 | 注意点 |
|---|---|---|
| Output directory for trained model | 学習済みLoRAモデル(.safetensors)の出力先ディレクトリ。 |
事前に作成した outputs/20_robot など、識別しやすいフォルダを指定。 |
| Training images | トレーニング画像が含まれている親フォルダを指定。 | サブフォルダ単体ではなく、必ず親フォルダを指定する。パスにスペース・特殊文字がないか確認。 |
| Regularisation images (Optional) | 正則化画像の保存先(オプション)。 | 特に必要がなければ空欄のままでOK。 |
| Destination training directory | トレーニングデータ一式が保存される最終的なディレクトリ。 | 出力ディレクトリとの整合性に注意。 |
5. Parameters設定
最後に、学習の細かいパラメータを設定します。
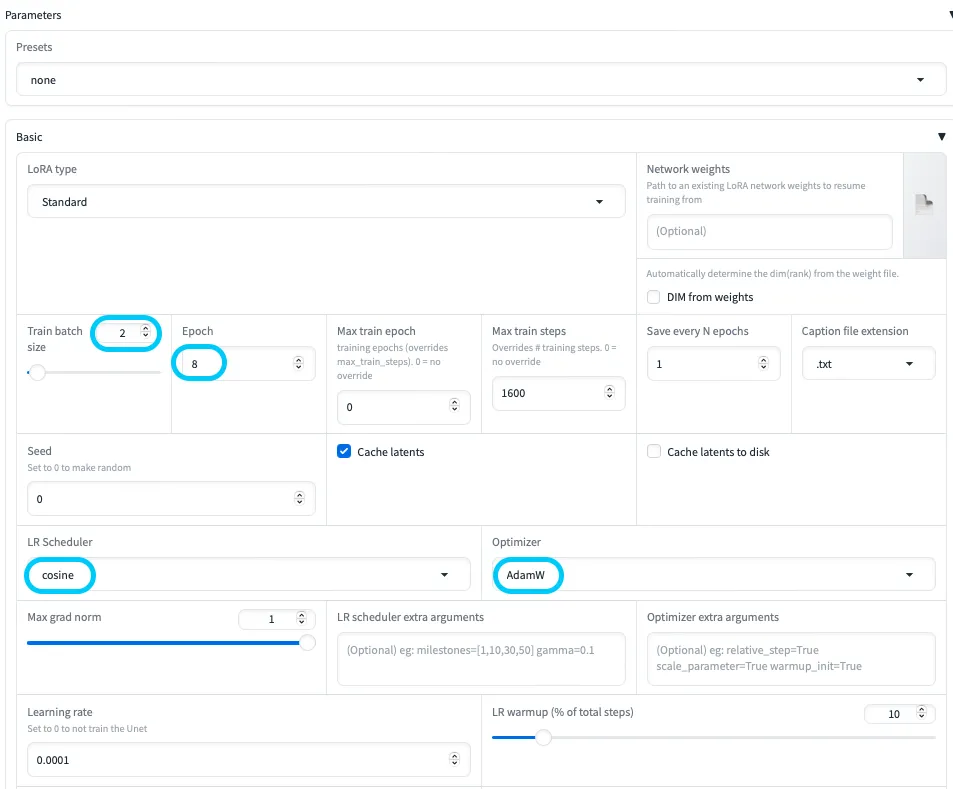
Parameters設定1
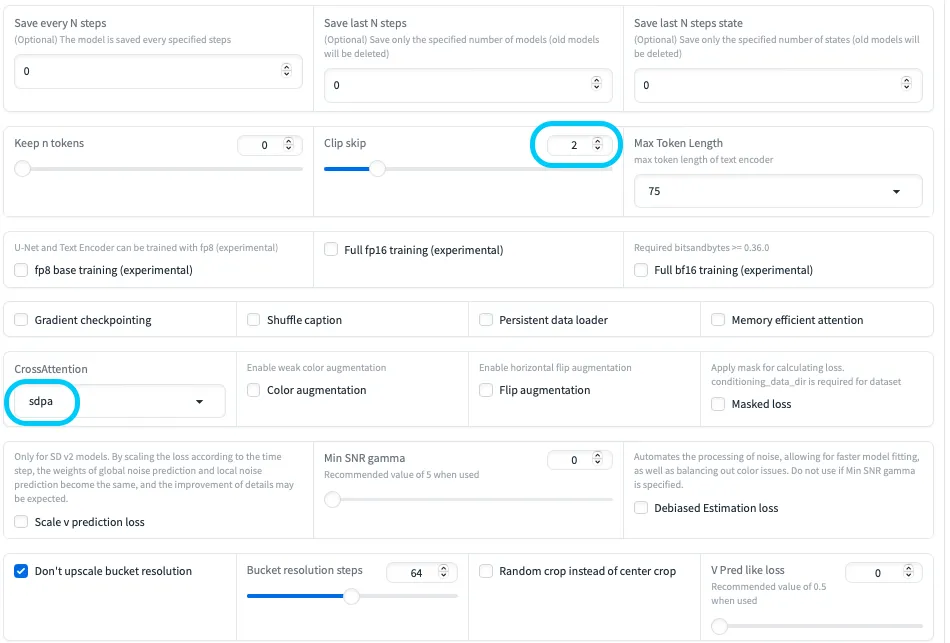
Parameters設定2
代表的な項目だけ抜き出すと、次のようなイメージです。
| 設定項目 | 説明 | 推奨設定の目安 |
|---|---|---|
| LoRA type | LoRAのタイプ。 | 一般的には「Standard」。 |
| Train batch size | 一度に処理する画像枚数。 | 2〜4程度から試し、VRAMに余裕があれば増やす。 |
| Epoch | データセット全体を何周学習するか。 | まずは 2〜10 くらいを目安に、必要に応じて調整。 |
| Seed | 乱数シード。 | 固定すると再現性が得られる。0にするとランダム。 |
| Cache latents | 潜在表現のキャッシュ有無。 | 有効にすると高速化できるが、メモリ不足時は無効化も検討。 |
| LR Scheduler | 学習率スケジューラ。 | 「cosine」などがよく使われる。 |
| Optimizer | 最適化アルゴリズム。 | 「AdamW」など標準的なものが無難。bitsandbytes 系はMacでは非対応に注意。 |
| Learning rate | 学習率。 | 例として 1e-4 前後から開始し、結果に応じて上下させる。 |
| Max resolution | 学習画像の最大解像度。 | 512x512〜640x640あたりから試す。あまり大きくしすぎるとメモリ負荷が大きくなる。 |
| Enable buckets | 異なるアスペクト比の画像をバケット分割して扱う機能。 | 有効にすると柔軟だが、不安定な場合は固定解像度での学習も検討。 |
パラメータが設定できたら、実際に学習を開始します。
学習が完了すると、指定した出力ディレクトリに .safetensors 形式のLoRAファイルが生成されます。
StableDiffusionでのLoRAの使い方
続いて、作成したLoRAを実際の画像生成に使う手順を確認していきます。
ここでの流れは次の通りです。
- 必要なファイル(VAE・EasyNegative・ベースモデル・LoRA)の配置
- Stable Diffusion WebUIの起動
- VAE・ベースモデル・LoRAの選択
- プロンプトや生成設定の調整
- 画像生成
ステップ1: 必要なファイルの準備
1. VAEファイル(vae.safetensors)
VAEファイルは、Stable Diffusionの models/VAE フォルダに置きます。
VAE(Variational Autoencoder)は、生成される画像の色合いや階調に大きく影響するコンポーネントです。
今回は、vae-ft-mse-840000-ema-pruned を例として使用しています。
2. EasyNegativeファイル(easynegative.safetensors)
EasyNegativeファイルは models/embeddings フォルダに配置します。
EasyNegative は Textual Inversion の技術を使った「ネガティブプロンプト用Embedding」で、
- 低品質な出力
- 不自然な手や指の本数
など、避けたい特徴を抑制するのに役立ちます。
3. ベースモデル(例:beautifulRealistic_v7.safetensors)
ベースモデルは models/Stable-diffusion フォルダに配置します。
ここでは Civitai に公開されている
beautifulRealistic_v7.safetensors を例にしています。
4. LoRAファイル(例:robot_lora.safetensors)
Kohya_ss GUIで学習したLoRAファイルは、Stable Diffusion の models/Lora フォルダに配置します。
ステップ2: Stable Diffusion WebUIの起動
- ターミナルから Stable Diffusion WebUI のディレクトリに移動し、次のコマンドで起動します。
./webui.sh
- ブラウザで表示されたURL(例:
http://127.0.0.1:7860)にアクセスします。
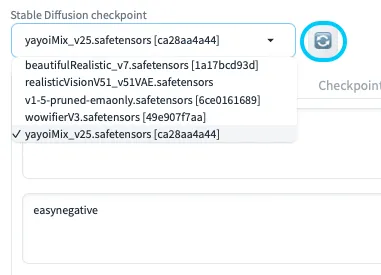
ベースモデルの選択
WebUIが起動したら、「Checkpoint」一覧から使用したいベースモデル(例:beautifulRealistic_v7.safetensors)を選択します。
ステップ3: VAEの設定
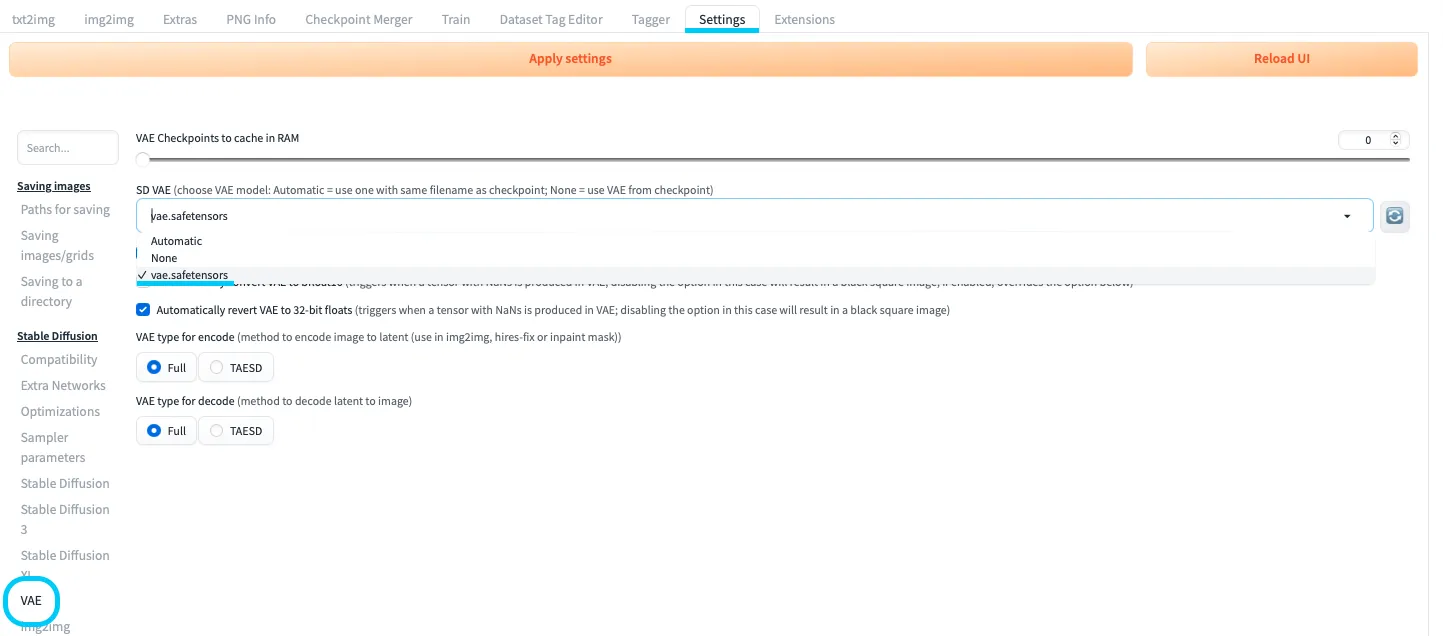
VAEの設定
Settingsの「VAE」関連の項目、または拡張機能からvae.safetensorsを選択します。- 設定を保存後、必要に応じてWebUIを再起動します。
ステップ4: EasyNegativeの適用
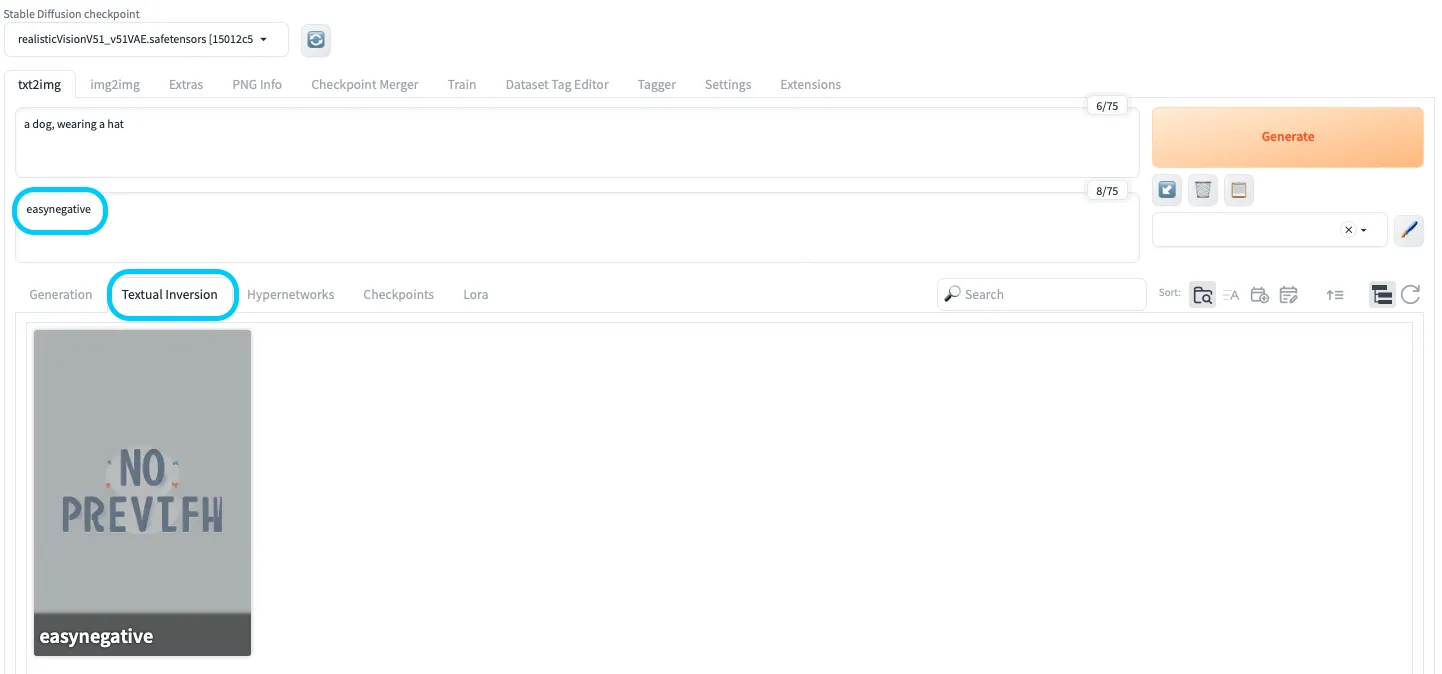
EasyNegativeの適用
txt2imgやimg2imgタブから「Textual Inversion」タブを開き、easynegativeを選択します。- ネガティブプロンプト欄に
easynegativeを含めておくことで、不要な特徴を抑えやすくなります。
ステップ5: LoRAの適用
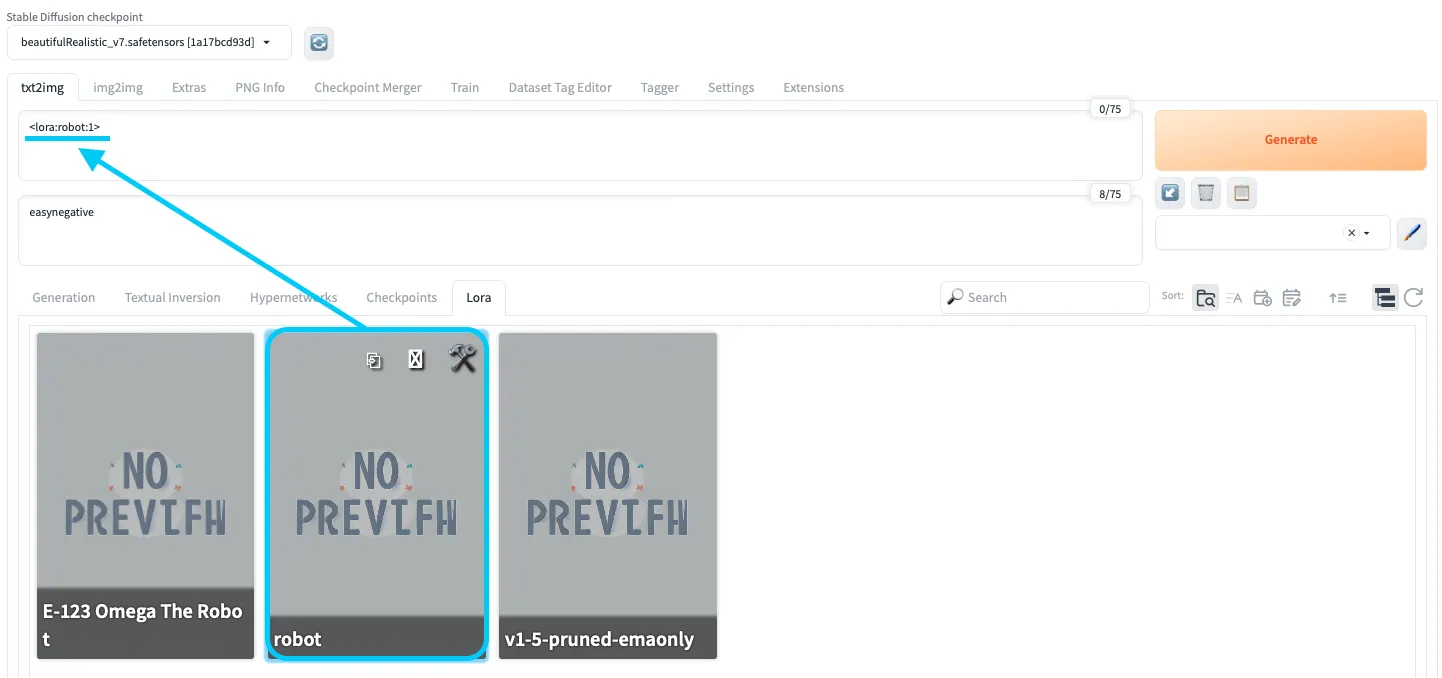
LoRAの選択
LoRAは、プロンプト内で次のような形式で指定します。
<lora:robot_lora:1>
robot_lora部分はLoRAファイル名に対応します。- 最後の
:1はLoRAの強度(重み)で、0.6〜1.0程度から試して、結果を見ながら調整していきます。
続いて、LoRAを適用した状態で実際のプロンプトを入力します。
<lora:robot_lora:1> A beautiful woman with a stunning, realistic face, combined with advanced, sleek white armor that reflects the intricate design learned by the LoRA.
ステップ6: 生成設定の調整
画像生成のクオリティを安定させるため、サンプリング設定やCFGスケールなども調整しておきましょう。
-
Sampling Method / Steps
- Sampling Method:
DPM++ 2Mなどから試す - Sampling Steps:20〜50ステップ程度から始め、必要に応じて増減
- Sampling Method:
-
CFG Scale
- 7〜10程度を目安に、プロンプトへの忠実度と自由度のバランスを取ります。
-
解像度(Width / Height)
- まずは 512x512 付近から試し、必要に応じて 768x768 や 1024x1024 に引き上げます。
- 解像度を上げるほど、VRAM負荷と生成時間は増えます。
ステップ7: 画像の生成
設定が整ったら、「Generate」ボタンをクリックして画像生成を実行します。
結果を確認しながら
- プロンプトの文言
- LoRAの強度(
<lora:...:0.8>など) - CFG Scale や Steps
を微調整して、自分の狙いに近い出力を追い込んでいきます。

LoRA学習で生成した画像
LoRAの活用方法
ここからは、LoRAの具体的な活用イメージをいくつかピックアップして紹介します。
高品質な実写寄り生成
FLUXシリーズは、Stable Diffusionチームに関わったメンバーが立ち上げた Black Forest Labs による画像生成モデルです。2024年以降、オープンウェイトの FLUX.1 dev / FLUX.1 schnell などが公開され、2025年11月には後継となる FLUX.2 ファミリー(dev/pro/flex など)も発表されました。
これらは高い写実性やプロンプト忠実度で注目を集めています。
https://x.com/majed_9_4/status/1825194322528231674
上記のように、LoRAとFLUX.1を組み合わせることで、
- 現実の写真と見まがうような質感
- LoRAで学習した固有スタイル・アイテム
を同時に反映した画像生成が可能になります。
【関連記事】
https://www.ai-souken.com/article/what-is-grok-flux
イラストと実写のハイブリッド
イラスト調と実写調の中間のような表現も、LoRAとFLUX.1の組み合わせで狙うことができます。
https://x.com/satori_sz9/status/1825066492800491586
このような例では、
- ベースモデル(FLUX.1)の写実的な光・影
- LoRAで学習したイラスト寄りのライン・色味
がミックスされ、「イラストだけど空気感は写真寄り」といったハイブリッド表現が実現できます。
旅行風フォトの大量生成
LoRAで特定の人物やスタイルを学習し、FLUX.1側でロケーション・時間帯などを変えていくと、
まるで「世界中を旅した写真集」のような画像群を量産できます。
https://x.com/venturetwins/status/1824857288806633815
- 同じキャラクターが
- 世界各地のような背景で
- 一貫したトーン/スタイルで
登場するため、SNS運用やプロモーション用途との相性も良いパターンです。
医療画像診断(MeLo:Medical image Low-rank adaptation)
LoRAの思想は、医療画像診断の領域にも応用されています。
MeLo(Medical image Low-rank adaptation)は、Vision Transformer(ViT)ベースの医療画像診断モデルに対して、フルファインチューニングの代わりに低ランク適応を用いる手法です。
論文では、
- 胸部X線・マンモグラフィ・血液細胞識別など複数の医療画像タスクにおいて
- 従来のフルファインチューニングと同等レベルの性能を
- 約0.17%というごく少量の学習パラメータ で実現した
と報告されています。
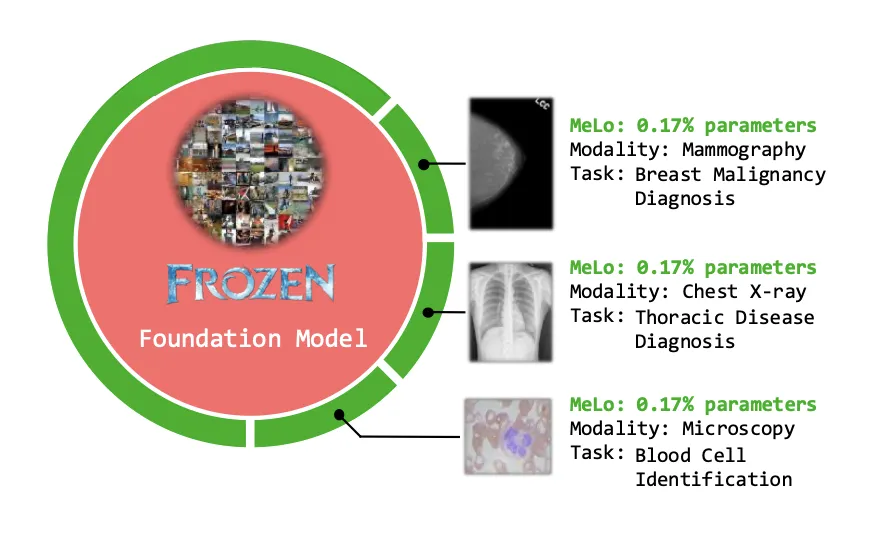
MeLoは元のモデルに対して大幅な変更を加えずに、少量の追加パラメータで異なる医療診断タスクに適応できる 参考:MELO: LOW-RANK ADAPTATION IS BETTER THAN FINE-TUNING FOR MEDICAL IMAGE DIAGNOSIS
このように、LoRA的な発想は
- モデル切り替えの容易さ
- GPUメモリ削減
- デプロイの軽量化
といった点から、実務の現場でも注目されています。
水彩画・イラストスタイルへの特化
水彩画風・アニメ風など、特定の作風に特化したLoRAを作ることで、プロンプトから簡単に「その画風」を呼び出せるようになります。
https://x.com/fladdict/status/1642579117014134784
- ベースモデル:汎用的なStable Diffusion
- LoRA:水彩画風のタッチに特化
という構成にしておくと、
- 商業イラスト
- 書籍の挿絵
- WebバナーやLP用のイラスト
など、特定のテイストで量産したいシーンで強力な武器になります。
LoRAと著作権の関係
LoRAを実務や商用利用に活用するうえで、著作権との関係 は無視できません。
ここでは、日本の著作権法および文化庁の整理をベースに、ざっくりとした考え方を確認します。
大きく分けると、
- AI開発・学習段階(学習データとして著作物を使うフェーズ)
- 生成・利用段階(生成物を利用・提供するフェーズ)
の2つの局面があります。
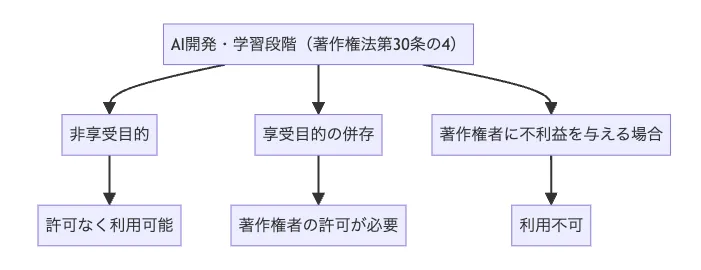
1. AI開発・学習段階(著作権法第30条の4)
著作物に表現された思想又は感情の享受を目的としない利用
第三十条の四
著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
(以下略)
開発・学習段階のLoRAと著作権の関係
LoRAの学習に既存の著作物(イラストや写真など)を使う場合、ポイントは次の3つです。
-
非享受目的かどうか
「著作物から知的・感情的な満足を得ることを目的とせず、機械学習の入力データとして統計的な特徴を抽出する」といった利用は、一定の条件下で柔軟に認められる余地があります。
-
享受目的の併存
「特定の作品の画風やキャラクターを忠実に模倣させる」ような学習は、著作物の享受や商業的価値の利用と評価される可能性があり、前述の非享受目的から外れてしまうリスクがあります。
-
著作権者の利益を不当に害しないか
利用態様によっては、著作権者の市場や収益に大きなマイナスを与えかねません。こうした場合は、第30条の4の枠組みを超えてしまう可能性がある、と整理されています。
【補足】享受目的の具体例
享受目的とみなされやすい例としては、例えば次のようなケースが挙げられます。
-
特定作品を忠実に再現させる学習
- 有名キャラクターや特定アーティストの画風を、意図的に真似させる
- ほぼ同じ構図・表現の画像を大量に出力させる
-
商業利用を前提とした模倣的な生成
- 既存ブランドのデザインをベースにした商品画像を生成し、
スタジオ撮影の代替として大量利用する、といったケース。
- 既存ブランドのデザインをベースにした商品画像を生成し、
-
研究・教育の域を超えた利用
- 表向きは研究・教育目的であっても、その成果物をそのまま商品化し販売する場合など。
これらは状況によって判断が変わり得ますが、「元作品の魅力をそのまま借りてきていないか」 を意識することが重要です。
2. 生成・利用段階
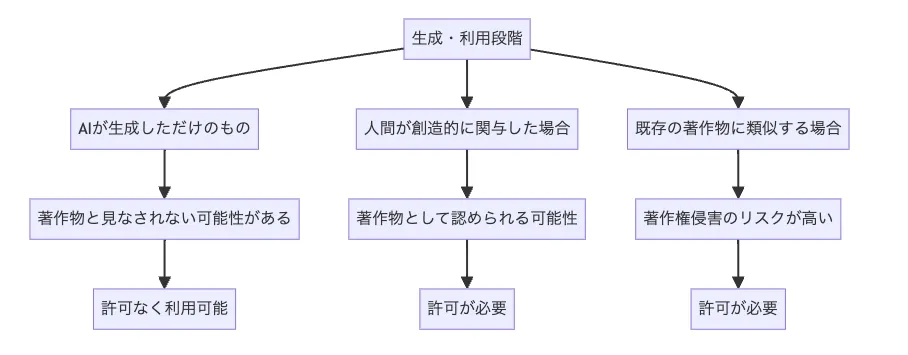
生成・利用段階のLoRAと著作権の関係
生成段階では、次の2点が問題になります。
生成物の著作物性
AIが自動生成しただけの画像が著作物と認められるかどうかは、
* 人間の創作的関与がどの程度あるか
* 指示内容がどれほど具体的で個性的か
などを踏まえて個別に判断されます。
既存著作物との類似(依拠性)
生成物が既存作品に酷似し、「その作品を下敷きに作られた」と評価される場合には、著作権侵害とみなされる可能性があります。特に、LoRAで特定作品の画風・構図・キャラクターを強く模倣している場合、依拠性の判断が問題になりやすくなります。
2024年3月、文化庁の文化審議会 著作権分科会 法制度小委員会は「AIと著作権に関する考え方について」を公表し、
- 学習段階
- 生成物の利用段階
を分けて整理したうえで、現時点の基本的な考え方を示しています(ただし報告書自体に法的拘束力はありません)。
【関連記事】
https://www.ai-souken.com/article/ai-generated-copyright-explanation
LoRAを商用利用する際の注意点
LoRA技術を商用利用する際には、以下のポイントを意識しておくとリスク低減につながります。
1. 学習データの著作権チェック
学習に使用するデータが、
- 権利者から適切に許諾を得ているか
- 第30条の4の枠組みに無理なく収まる利用形態か
を確認することが重要です。
2. 類似性リスクの管理
生成物が既存作品とあまりに似すぎている場合、依拠性が認められ、著作権侵害の可能性が高まります。
社内レビューやツールを活用し、類似度をチェックする運用を検討しましょう。
3. 技術的な制限の実装
特定のプロンプトを禁止したり、明らかに既存キャラクター・ロゴに似すぎた出力をブロックするなど、技術的な制約をシステム側に実装することも有効です。
4. 最新ガイドライン・法令のフォロー
AIと著作権を巡る議論は継続中であり、各国でルールの更新が行われています。
日本では文化庁の「AIと著作権について」ページなどを定期的に確認し、最新動向をキャッチアップすることが重要です。
5. 契約上の責任範囲の明確化
LoRAを含む生成AIをクライアントに提供する場合、
- 生成物の著作権の帰属
- 権利侵害が発生した場合の責任範囲
を契約で明確にしておくことが求められます。
LoRAについて学ぶためのリソース紹介
最後に、LoRA(Low-Rank Adaptation)をさらに深く学ぶためのリソースを紹介します。
SNSなどで最新情報をキャッチアップしつつ、以下のサイト・資料を併せて読むと理解が一層深まります。
1. GitHub(microsoft/LoRA)
- LoRAのPyTorch実装(loralib)
- Hugging Face系モデルへの組み込み例
などが提供されています。LLM向けのLoRA実装ですが、低ランク適応の基本的な考え方をコードレベルで学ぶのに最適です。
2. Hugging Face(PEFTライブラリ)
Hugging Faceの PEFT(Parameter-Efficient Fine-Tuning) は、
LoRAを含む各種パラメータ効率化手法を統一的に扱えるライブラリです。
- LoRA
- Prefix Tuning
- AdaLoRA
など、複数の手法を抽象化して使えるようになっており、コード例も豊富です。
3. Civitai
Civitai には、
- LoRAファイルの配布
- ベースモデルとの組み合わせ例
- 実際に使ったユーザーのサンプル画像・レビュー
が多数集まっています。実務・創作の現場で「どのようにLoRAが使われているか」を知るのに適しています。
4. Kohya_ss GitHub
本記事でも利用した Kohya_ssのGitHubリポジトリ では、
- LoRA学習スクリプト
- さまざまな学習設定例
- 日本語ドキュメント
などが公開されています。とくにStable Diffusion系のLoRAを自前で学習したい場合の「実践的な教科書」として役立ちます。

AIファインチューニングの理解から組織のAI活用の視野を広げる
LoRAの仕組みと活用方法を学んだことで、AIモデルのカスタマイズが身近な技術であることが見えてきたのではないでしょうか。次のステップは、こうしたAI技術の知見を組織の業務改善にどう活かすかを設計することです。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に進める実践ガイド(220ページ)を無料で提供しています。AI技術の業務適用に必要なPoC設計から全社展開まで、部門別のBefore/After付きで解説しています。
AI総合研究所が、AI技術への理解を組織の業務自動化の可能性へと広げるきっかけを提供します。
LoRAの知識を組織のAI導入設計に活かす

段階的なAI導入の実践ガイド(220p)
LoRAによる画像生成AIカスタマイズを理解した次は、AIを業務の中でどう運用するかの段階設計です。Microsoft環境を前提にAI業務自動化を段階的に進める220ページの実践ガイドで、組織導入の道筋をご確認ください。
まとめ
ここまで、LoRAの基礎から具体的な導入手順、画像生成AIでの活用例、著作権まわりの注意点、学習リソースまで一通り見てきました。
改めてポイントを整理すると、LoRAは次のような特徴を持つ技術です。
- 大規模モデルを「差分だけ」学習することで、計算コストとメモリを大幅に削減できる
- Stable DiffusionやFLUX.1などの画像生成モデルでも広く利用され、
キャラクター・画風・ブランドスタイルの再現に強みを発揮する - 医療画像診断やエンタープライズ用途など、高い精度と運用コストの両立が求められる分野 でも応用が進んでいる
- 著作権との関係では、学習段階と生成・利用段階を分けて考え、
学習データの選定や生成物の利用方法に配慮することが重要
本記事を足がかりに、ぜひ実際にLoRAを動かしながら、
- 自分の用途に合った学習パラメータ
- ベースモデルとLoRAの組み合わせ
- ワークフローへの組み込み方
を試行錯誤してみてください。
LoRAは、画像生成AI・LLMのどちらにおいても、「大規模モデル時代の現実的な武器」 になりうる技術です。
この記事が、LoRA技術に興味がある方の一歩目を後押しできていれば幸いです🙌







