この記事のポイント
 社内RAG構築にはAzure AI Searchのハイブリッド検索(ベクトル+キーワード)が第一候補。ベクトル検索単体よりも検索精度が大幅に向上する
社内RAG構築にはAzure AI Searchのハイブリッド検索(ベクトル+キーワード)が第一候補。ベクトル検索単体よりも検索精度が大幅に向上する- 統合ベクトル化を使い、チャンク分割と埋め込み生成をAzure側に任せるべき。自前パイプライン構築は運用コストが高く避けるべき
- LLMエージェントとの連携にはAgentic Retrievalが最適。Foundry Agent Serviceと統合すれば、マルチクエリの自動分解で複雑な質問にも対応できる
- Basicティアは検証用、本番にはS1以上が必須。ベクトルインデックスのサイズ制限を超えるとスケールアウトが必要になるため、データ量を事前に見積もるべき
- HNSWのパラメータm値を上げすぎるとインデックスサイズが肥大化する。精度とコストのバランスはm=4、efConstruction=400から始めて調整するのが有効

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Azure AI Searchは、Microsoftが提供するクラウドベースの検索プラットフォームです。
その中核機能であるベクトル検索は、テキストや画像を数値ベクトルに変換し、意味的な類似性に基づいて情報を検索する技術です。
本記事では、Azure AI Searchのベクトル検索機能について、HNSWアルゴリズムや統合ベクトル化の仕組みから、ポータルでの実装手順、2026年に新たに登場したエージェント検索、料金体系までを網羅的に解説します。
Azureの基本知識や料金体系についてはこちらの記事で詳しく解説しています。
Microsoft Azureとは?できることや各種サービスを徹底解説
Microsoft 365 Copilotの最新エージェント機能「Copilot Cowork」については、以下の記事をご覧ください。
Copilot Coworkとは?機能や料金、Claude Coworkとの違いを解説
目次
統合ベクトル化(Integrated Vectorization)
Azure AI Searchのエージェント検索(Agentic Retrieval)
Azure AI Searchのベクトル検索とは
Azure AI Search
Azure AI Searchは、Microsoftが提供するクラウドベースの検索プラットフォームです。大規模言語モデルとエンタープライズデータを組み合わせて、豊かな検索エクスペリエンスと生成AIアプリケーションを構築できます。
Azure AI Searchにおけるベクトル検索は、テキスト・画像・音声などのコンテンツを数値ベクトル(埋め込み)に変換し、ベクトル同士の類似性に基づいて情報を検索する機能です。従来のキーワード検索が文字列の一致に依存するのに対し、ベクトル検索はコンテンツの「意味」や「コンテキスト」を理解したマッチングを実現します。
ベクトル検索は、Azure AI Servicesのエコシステムの一部として提供されています。Azure OpenAI Serviceの埋め込みモデルと組み合わせることで、エンタープライズデータからの知識を会話形式で活用するRAG(検索拡張生成)アプリケーションを構築できます。

Azure AI サービスの主要サービス
公式ドキュメントによると、ベクトル検索はすべてのリージョンとすべてのティアで追加料金なしで利用できます。2024年4月3日以降に作成されたサービスでは、ベクトルインデックスの容量が大幅に拡張されています。

埋め込みベクトル化の仕組み
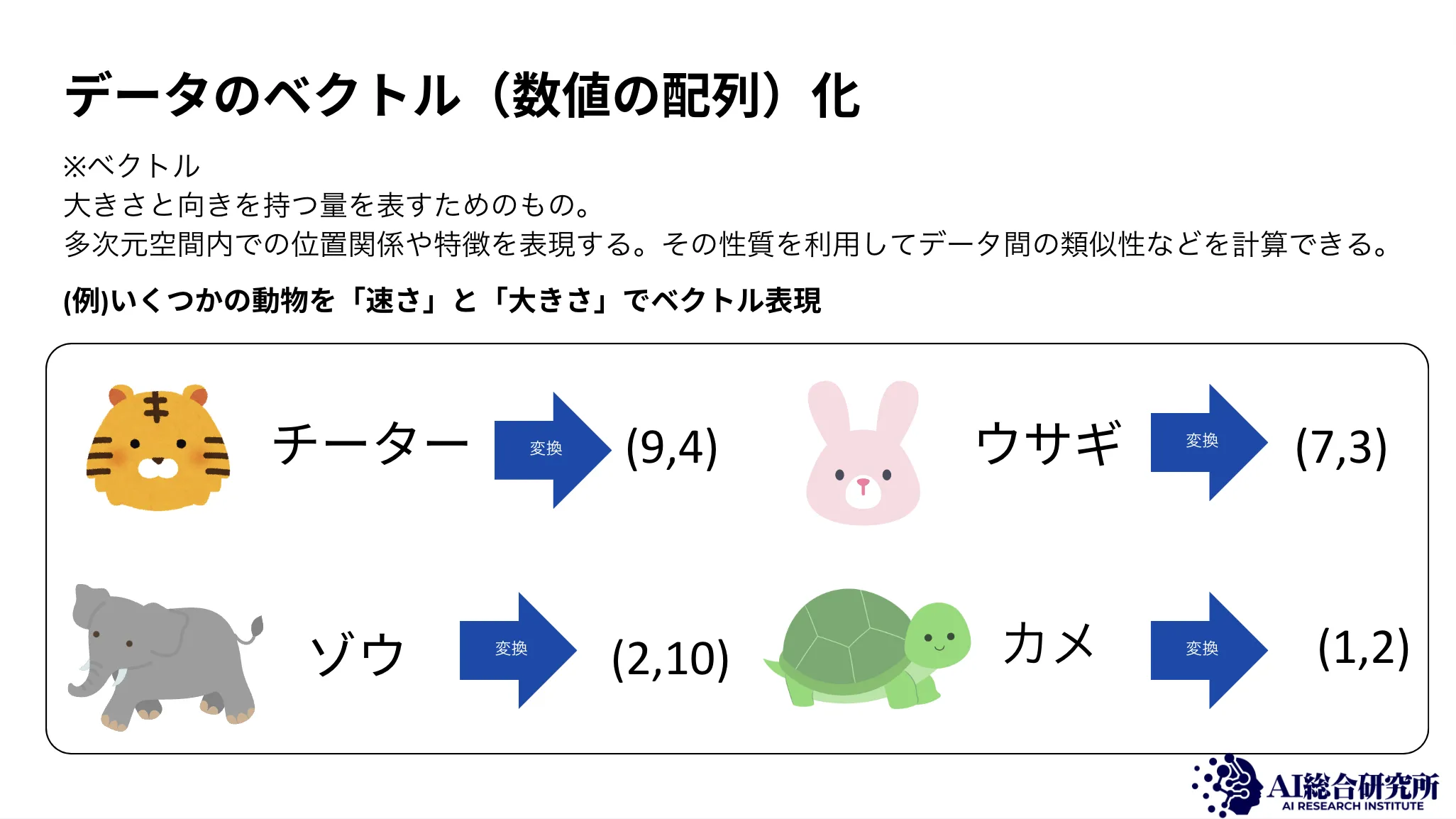
埋め込みベクトル化イメージ
埋め込みベクトル化とは、テキスト・画像・音声などのデータを多次元の実数ベクトル空間にマッピングするプロセスです。データの「意味」や「内容」を数値ベクトルとして表現することで、コンピュータが意味的な類似性を計算できるようになります。
ベクトル化は以下のステップで行われます。
- 前処理
データを標準化し、モデルが処理しやすい形式に変換します。テキストの場合はトークン化や正規化が含まれます。
- モデル選択
埋め込みを生成するためのモデルを選択します。Azure OpenAIのtext-embedding-ada-002やtext-embedding-3-smallなどの事前学習済みモデルが一般的に使用されます。
- ベクトル変換
選択したモデルを使用して、データを多次元空間上のベクトルに変換します。たとえばtext-embedding-ada-002では1,536次元、text-embedding-3-smallでは1,536次元のベクトルが生成されます。
このベクトル化プロセスにより、データの意味的な特性がベクトルの形で数値化され、後続の検索や分析に利用できるようになります。
埋め込み空間による類似性検索
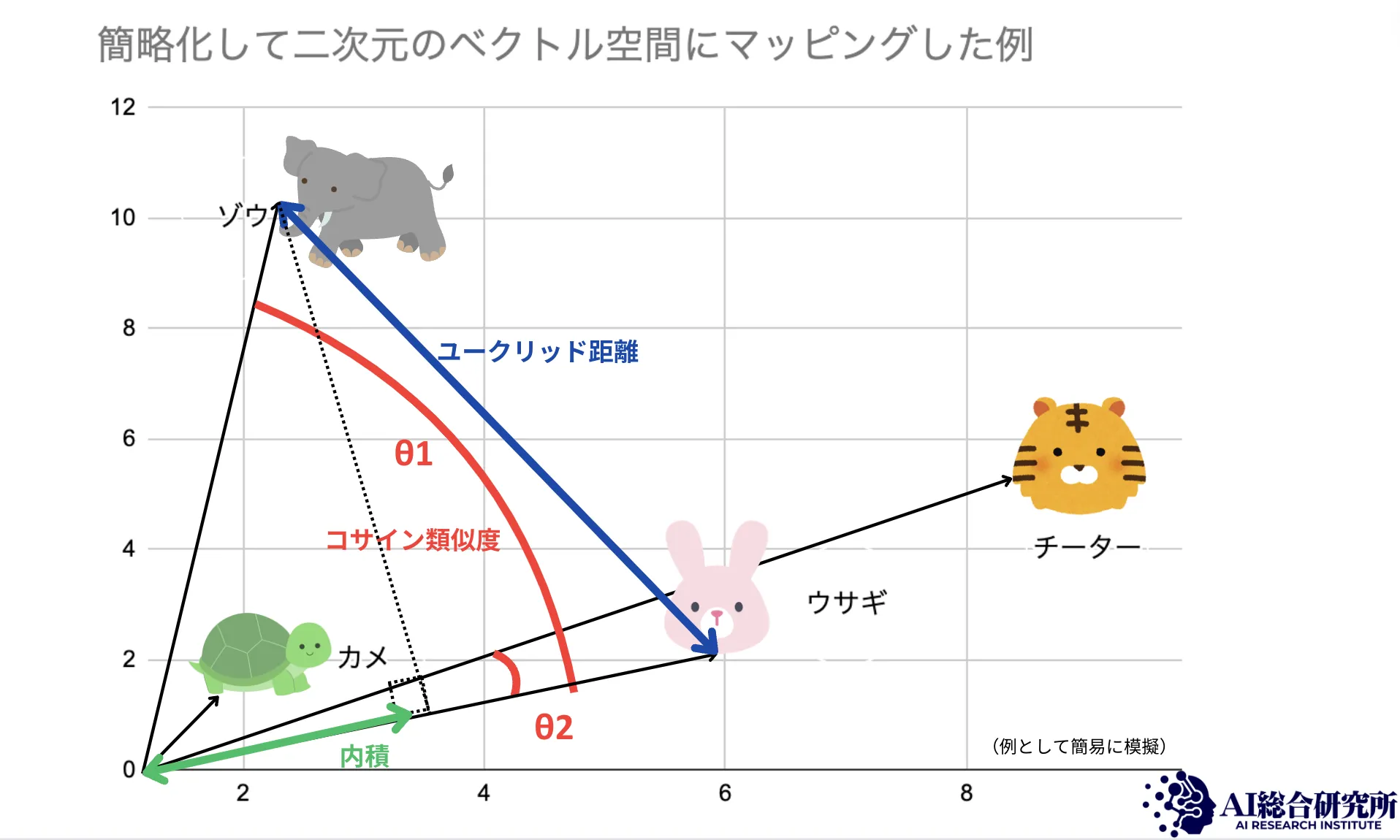
埋め込み空間イメージ
埋め込み空間とは、データがベクトル化された後に存在する多次元の実数ベクトル空間です。この空間では、ベクトル間の距離や角度が元のデータ項目間の意味的な類似性を反映します。
埋め込み空間における主要な概念を整理します。
- 次元
ベクトルの特徴量の数を指します。高次元(数百〜数千次元)の空間はデータの複雑な特徴を捉えられますが、計算コストも増大します。Azure AI Searchではベクトルフィールドあたり最大4,096次元をサポートしています。
- 類似性の測定
ベクトル間の距離(コサイン類似度やユークリッド距離など)を使って、データ項目間の類似性を測定します。距離が近いベクトル同士は、意味的に類似していると判断されます。
- 検索の実行
ユーザーのクエリも同じプロセスでベクトル化され、埋め込み空間内で最も近いデータベクトルを見つけることで、関連性の高い検索結果を返します。
埋め込み空間はデータ項目間の複雑な関係を捉えるための基盤であり、キーワードの一致だけでは見つけられない意味的に関連するコンテンツを発見できます。
ベクトル検索を利用する理由
ベクトル検索は、キーワード検索を超えた高度な情報検索を実現します。主な利用理由を以下にまとめます。
- 意味的な理解によるマッチング
単語の表面的な一致ではなく、クエリとドキュメントの意味的な類似性に基づいて検索します。「犬」と「ペット」のように異なる表現でも関連するコンテンツを発見できます。
- 多言語対応
言語に依存しないベクトル表現により、異なる言語間での検索が可能です。英語で検索してドイツ語のドキュメントを見つけるといった使い方ができます。
- マルチモーダル対応
テキストだけでなく、画像・音声・ビデオなどの非テキストデータにも適用できます。テキストクエリで関連する画像を検索するといったシナリオに対応します。
- 曖昧なクエリへの対応
ユーザーが正確なキーワードを知らない場合でも、意味的に関連するコンテンツを発見できます。これは学術研究や製品探索で特に有効です。
ベクトル検索はこれらの能力により、従来のキーワード検索よりも柔軟で高精度な検索体験を提供します。特に生成AIアプリケーションのRAG(検索拡張生成)パターンでは、ベクトル検索による意味的な検索がナレッジベースからの情報取得の精度を大きく向上させます。
Azure AI Searchの検索アルゴリズムと手法
Azure AI Searchでは、データセットの規模や精度要件に応じて複数の検索アルゴリズムと手法を使い分けられます。ここでは、ベクトル検索の中核となるアルゴリズムと、実務で活用される代表的な検索手法を解説します。
HNSWとKNN
Azure AI Searchのベクトル検索は、2つのアルゴリズムをサポートしています。
以下の表で、各アルゴリズムの特性を比較します。
| 項目 | 完全KNN(Exhaustive KNN) | HNSW(Approximate Nearest Neighbor) |
|---|---|---|
| 検索方式 | ベクトル空間全体を総当たりで検索 | 階層的グラフ構造を使った近似検索 |
| 精度 | 厳密な最近傍を保証 | 近似値(高い再現率) |
| 速度 | データ量に比例して遅くなる | 大規模データでも高速 |
| メモリ | ベクトルインデックスサイズのクォータを消費しない | クォータを消費する |
| 適用場面 | 小〜中規模データ、精度優先 | 大規模データ、速度と精度のバランス |
HNSWは公式ドキュメントで説明されている通り、階層的なグラフ構造を構築してデータポイントを整理します。インデックス作成時にはデータポイントが多層グラフに配置され、クエリ時にはグラフの上位層から下位層へとナビゲーションすることで、効率的に最近傍を探索します。
HNSWの主要パラメータは3つあります。
- m
各ノードが接続する近傍ノードの最大数です。値を大きくするとグラフが密になり再現率が向上しますが、インデックスサイズとビルド時間が増加します。
- efConstruction
インデックス構築時に候補として検討するデータポイント数です。デフォルトは400で、100〜1,000の範囲で設定できます。高い値ほどグラフの品質が向上しますが、構築時間が長くなります。
- efSearch
クエリ実行時に探索する候補ノード数です。値を大きくすると精度が上がりますが、レイテンシも増加します。
多くのシナリオではHNSWが推奨されますが、ベンチマーク評価用に正確な最近傍セットを構築する場合や、小規模データセットではKNNが適しています。
距離メトリクス
ベクトル間の類似性を測定するために、Azure AI Searchは3種類の距離メトリクスをサポートしています。
| メトリクス | 特徴 | 推奨される場面 |
|---|---|---|
| cosine | 2つのベクトルの角度を測定。ベクトルの長さの違いに影響されない | Azure OpenAIの埋め込みモデルを使用する場合(推奨) |
| dotProduct | ベクトルの大きさと角度の両方を測定。正規化済みベクトルではcosineと同等だがわずかに高速 | 正規化済みベクトルでパフォーマンスを優先する場合 |
| euclidean | 2つのベクトル間のユークリッド距離(L2ノルム)を測定 | 空間的な距離が重要な場合 |
Azure OpenAIの埋め込みモデルを使用している場合はcosineを選択してください。距離メトリクスは埋め込みモデルの特性に合わせて選ぶことが重要です。
ハイブリッド検索
ハイブリッド検索は、ベクトル検索とキーワード検索を同一リクエスト内で並列実行し、結果を統合する手法です。Azure AI Searchはベクトルフィールドとテキストフィールドの両方を含むインデックスに対して、両方のクエリを同時に実行できます。
結果の統合には**Reciprocal Rank Fusion(RRF)**が使用されます。RRFは各検索手法のランキングを組み合わせて最終的なスコアを算出するため、単一の検索手法よりも安定した精度を実現します。
さらに、ハイブリッド検索にセマンティックランカーを組み合わせることで精度がさらに向上します。Microsoft社のベンチマークテストでは、ハイブリッド検索+セマンティックランキングの組み合わせが最も関連性の高い結果を一貫して返すことが確認されています。
セマンティック検索
セマンティック検索は、AIベースの機能を利用してテキストの意味論的な理解に基づく検索結果を提供する技術です。キーワードの一致だけでなく、ワードの意味や文脈を分析し、より関連性の高い結果を返します。
Azure AI Searchのセマンティックランカーは、検索結果に対してL2リランキングを実施し、意味的な関連性に基づいて順位を再調整します。この機能はBasic以上のすべてのティアで利用可能で、毎月1,000クエリまで無料で使用できます。
フィルター付きベクトル検索
フィルター付きベクトル検索では、ベクトルクエリとフィルター式を組み合わせて実行できます。フィルターはテキストフィールドや数値フィールドに適用され、メタデータに基づいて検索結果を絞り込みます。
たとえば、「カテゴリが技術文書のドキュメントのみを対象にベクトル検索を実行する」といった使い方が可能です。ベクトルフィールド自体はフィルタリングの対象にはなりませんが、別途設定したフィルタリング可能なフィールドと組み合わせることで柔軟な検索を実現します。
マルチモーダル検索と多言語検索
Azure AI Searchは、テキスト以外のデータ形式にもベクトル検索を拡張できます。
- マルチモーダル検索
テキストと画像をマルチモーダル埋め込み(OpenAI CLIPやGPT-4 Turbo with Visionなど)でエンコードし、異なるコンテンツタイプをまたいだ検索を実現します。テキストクエリで関連する画像を検索する、画像クエリで類似ドキュメントを検索するといったシナリオに対応します。
- 多言語検索
複数言語で訓練された埋め込みモデルを使用することで、言語をまたいだ検索が可能です。統合ベクトル化のパイプラインでカスタムスキルやビルトインスキルを通じて多言語の埋め込みモデルを呼び出せます。ハイブリッド検索シナリオでは、Azure AI Searchの多言語機能をテキスト検索側でも活用できます。
Azure AI Searchのベクトル検索の使い方
Azure AI Searchでベクトル検索を実装するには、手動でベクトルを生成して投入する方法と、統合ベクトル化(Integrated Vectorization)でパイプラインを自動化する方法の2つがあります。ここでは統合ベクトル化の概要と、Azure Portalを使った実装手順を解説します。
統合ベクトル化(Integrated Vectorization)
統合ベクトル化は、Azure AI Searchのインデクサーパイプラインに組み込まれた機能で、データのチャンク分割とベクトル生成を自動化します。2026年3月時点ですべてのリージョンとティアで利用可能です。
統合ベクトル化は以下の2つのフェーズで動作します。
- インデックス作成時
インデクサーがデータソースからドキュメントを取得し、スキルセットのText Splitスキルでチャンクに分割した後、Azure OpenAI Embeddingスキルなどの埋め込みスキルでベクトルを自動生成します。
- クエリ実行時
テキストクエリをベクトルに変換するベクトライザーをインデックスに設定しておくことで、ユーザーがテキストで検索するだけで自動的にベクトルクエリに変換されます。
統合ベクトル化を使えば、個別にチャンク分割やベクトル生成のパイプラインを構築する必要がなくなります。データソースの変更もインデクサーが自動検知して処理するため、運用負荷を大幅に軽減できます。
対応する埋め込みスキルとベクトライザーの組み合わせは以下の通りです。
| 埋め込みスキル | ベクトライザー |
|---|---|
| Azure OpenAI Embedding | Azure OpenAI vectorizer |
| カスタムスキル(Web API) | Custom Web API vectorizer |
| Azure Vision マルチモーダル(プレビュー) | Azure Vision vectorizer |
| AML スキル(Microsoft Foundryモデルカタログ) | Microsoft Foundry model catalog vectorizer |
Azure OpenAIの埋め込みモデルを使用する場合は、Azure OpenAI Embeddingスキルとベクトライザーの組み合わせが最もシンプルです。ポータルの「データのインポートとベクター化」ウィザードを使えば、コードを書かずに統合ベクトル化を試すこともできます。
ポータルでのベクトル検索の手順
Azure AI Searchを使って実際にベクトル検索を構築する手順を、ポータルの操作に沿って解説します。
データの準備
まずAzure Portalにログインし、検索対象のデータを準備します。

Azure ポータルにログイン画面
Azure Storage Accountを作成し、コンテナーを設定します。
Azure Storage Account の作成
テキストデータや画像など、ベクトル検索したいデータをAzure Storageにアップロードします。
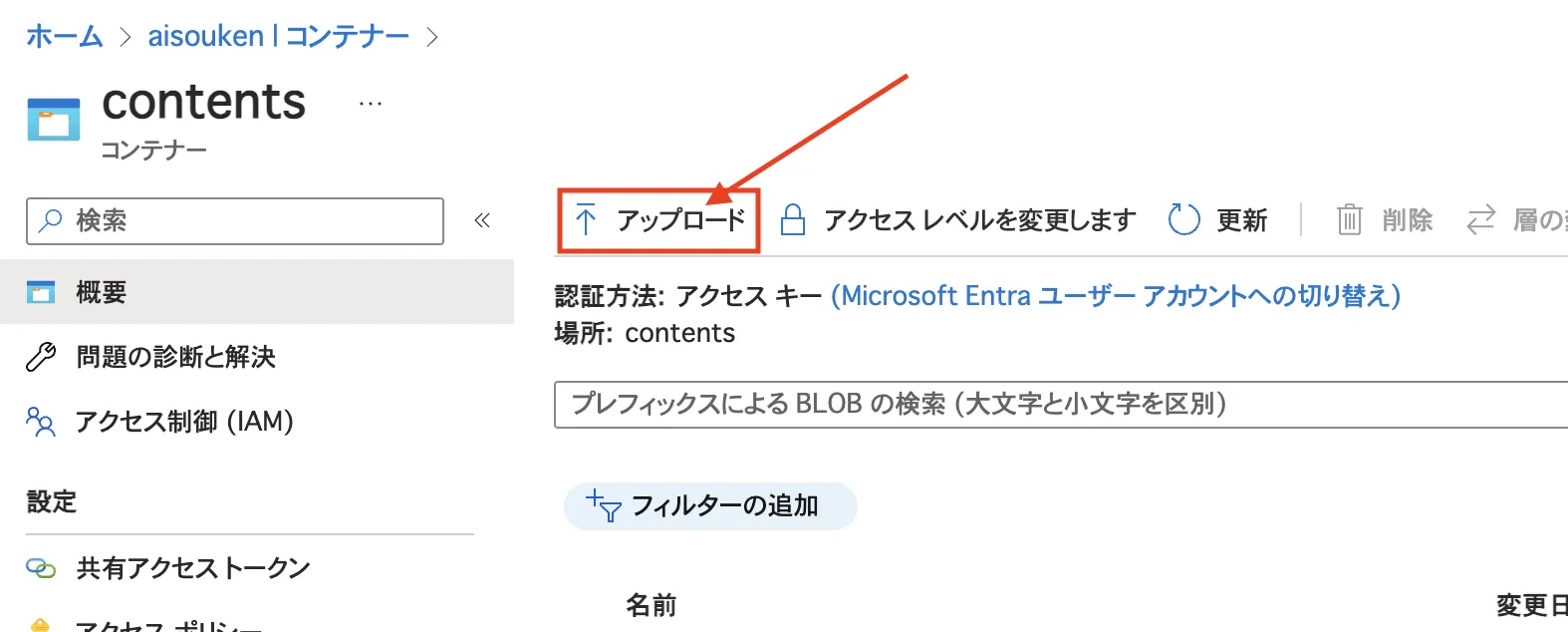
Azure Storageにアップロード画像
AI Searchのセットアップ
AIサービスをメニューから検索し、AI Searchサービスを作成します。
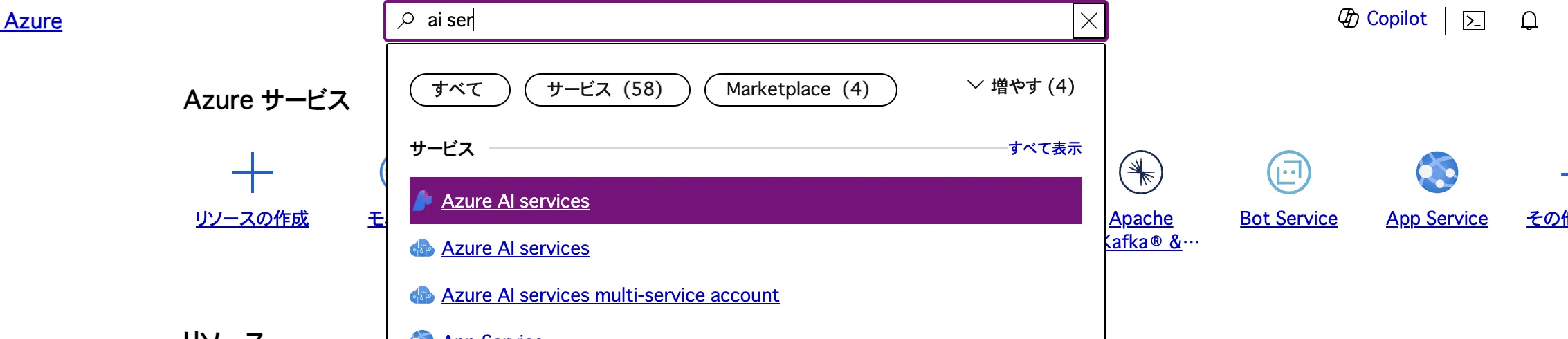
AI Search サービスを検索画面
メニューバーからAI検索を探して選択します。
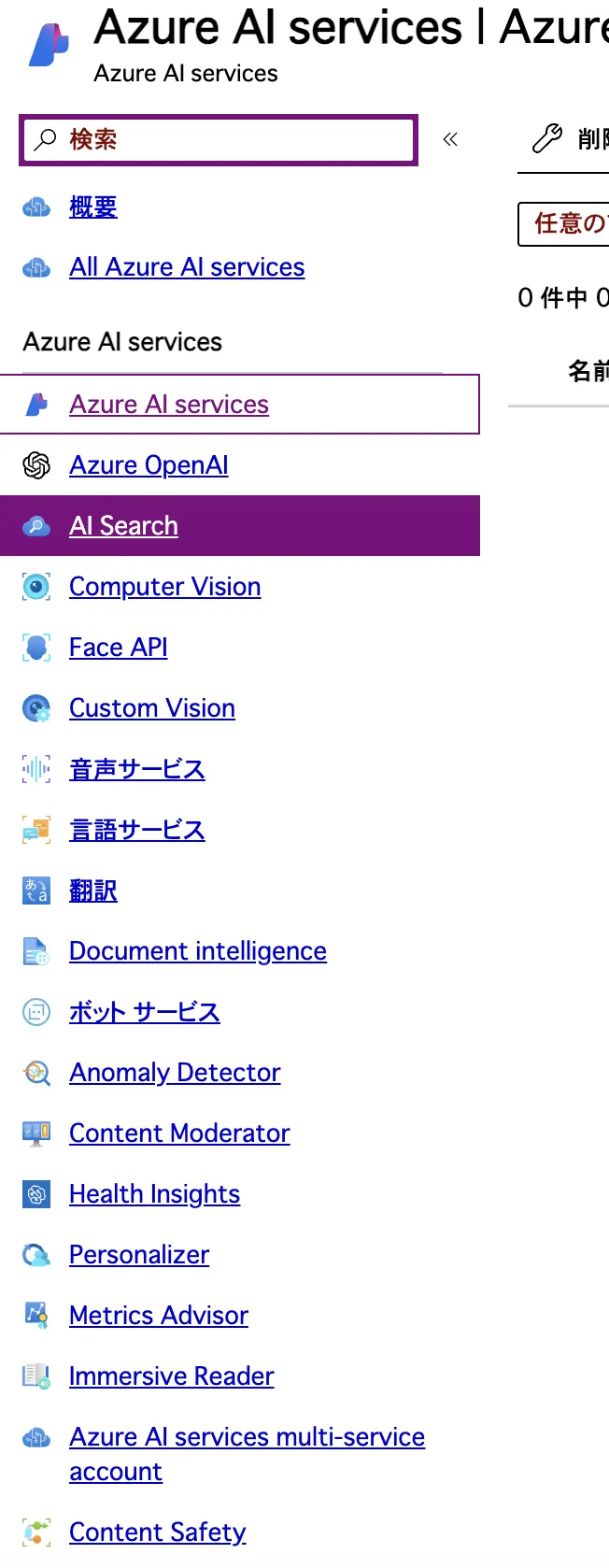
AI Searchのメニュー画面
サービスが未作成の場合は新規作成してください。作成時の料金プランについてはこの記事の料金セクションで詳しく解説しています。
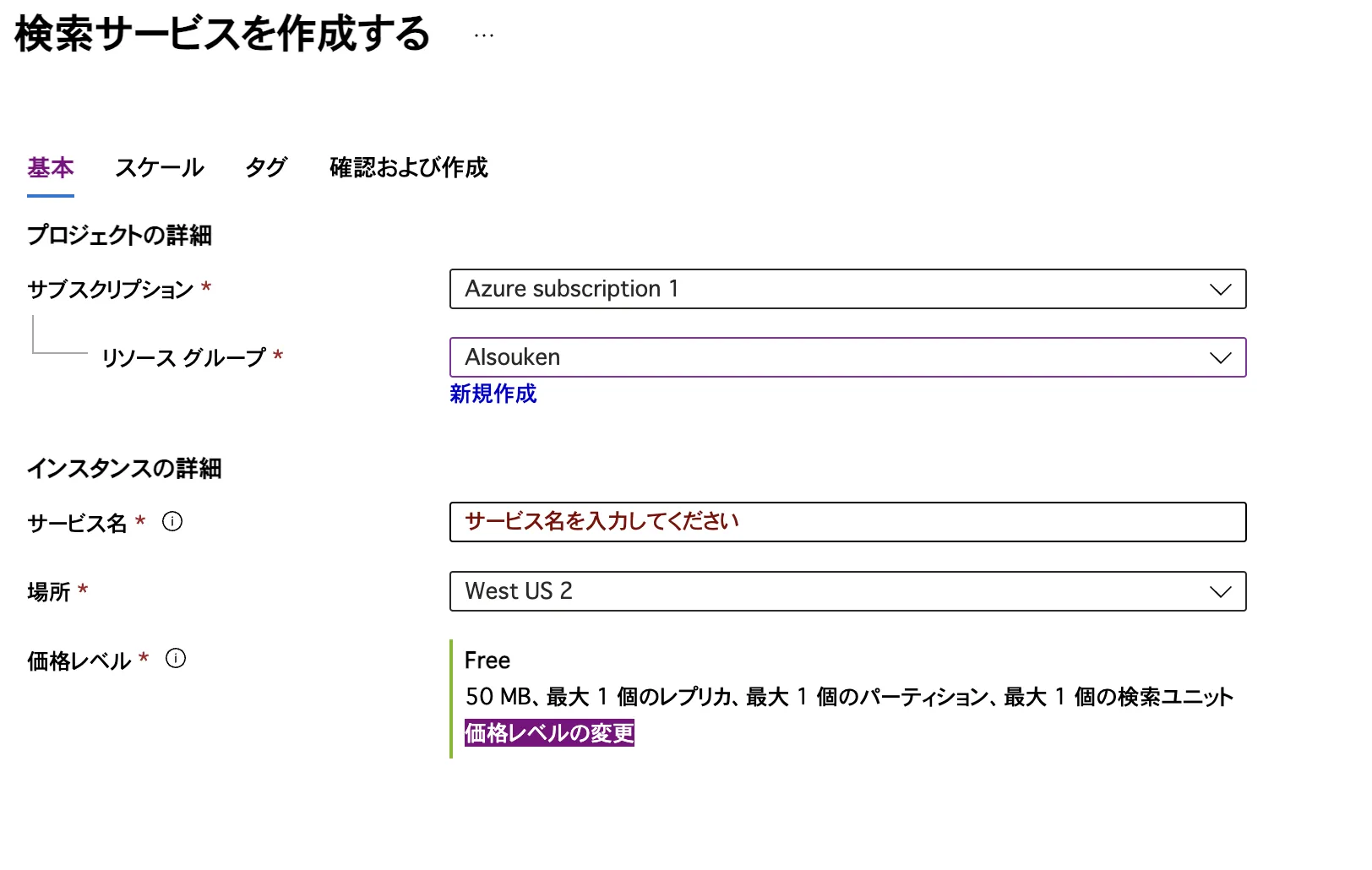
AI Search サービス作成画面
データのインポートとベクター化
AI Searchサービスの「データのインポートとベクター化」を選択します。この機能が統合ベクトル化のウィザードに該当します。
データのインポートとベクター化選択画面
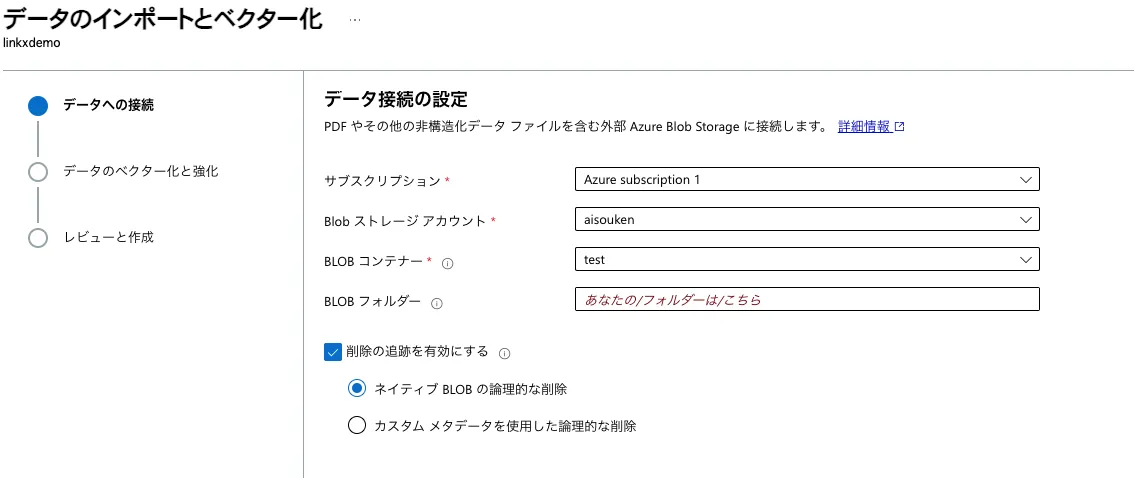
格納したデータがあるストレージアカウントのコンテナーを指定します。
データのインポートとベクター化入力画面
Azure OpenAIの設定を行い、必要に応じてセマンティックランカーも有効にします。セマンティックランカーを有効にすると、ハイブリッド検索の精度が向上します。
インデックス名となるオブジェクトのプレフィックスを設定します。
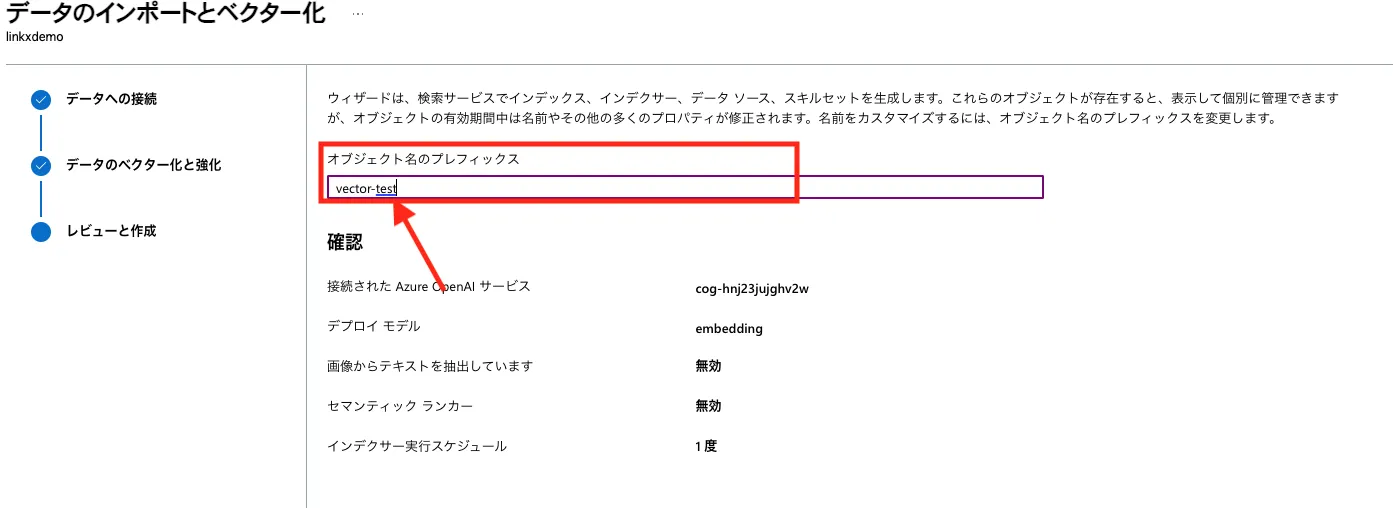
オブジェクトのプレフィックスを設定
検索結果の確認
作成ボタンをクリックし、インデクサーがデータの取り込みを完了するまで待ちます。完了画面が表示されたら検索の開始をクリックします。
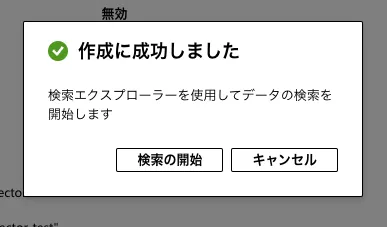
作成完了画面
インデックスを確認し、ベクトルフィールドが正しく作成されていることを確認します。

インデックスの確認画面
実際に検索を行い、ベクトル表現が加わった結果を確認します。
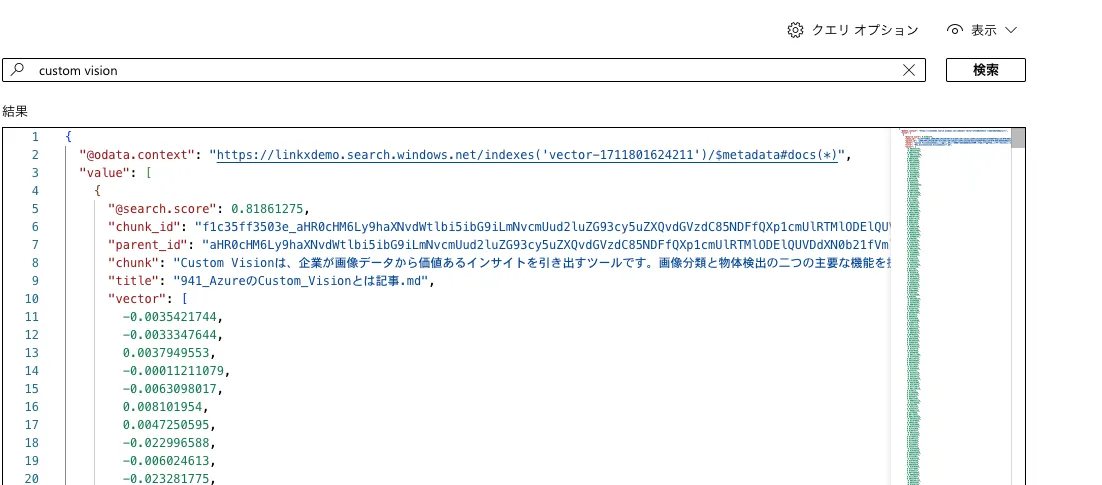
検索テスト
ここまでの手順で、Azure AI Searchを使ったベクトル検索の一連の構築が完了します。
補足情報
ベクトル検索の構築にあたって、いくつかの補足事項があります。
- データの適切な準備とインデクサー設定が検索精度に大きく影響します。特にチャンクサイズとオーバーラップの設定は、埋め込みモデルの入力トークン制限と検索精度のバランスを考慮して決定してください。
- セマンティック検索の有効化やAzure OpenAIの埋め込みモデルの利用により、テキストデータを含む様々なファイルタイプから高精度な検索結果を得られます。
- スキルセットやアナライザの設定によって検索の振る舞いや結果が変わるため、目的に応じた調整が必要です。
- 検索精度に満足できない場合は、チャンクサイズの拡大、HNSWのefConstructionパラメータの調整、ハイブリッド検索+セマンティックランキングの組み合わせを試してみてください。
Azure AI Searchのエージェント検索(Agentic Retrieval)
Azure AI Searchには、2025年にパブリックプレビューとして追加された**エージェント検索(Agentic Retrieval)**があります。これは、LLM(大規模言語モデル)を活用して複雑なクエリを分解・並列実行するマルチクエリパイプラインで、RAGアプリケーションやエージェント間ワークフローに最適化されています。
エージェント検索の仕組み
エージェント検索は、以下の流れで動作します。
- クエリ分解
LLM(gpt-4o、gpt-4.1、gpt-5シリーズに対応)が、ユーザーの質問とチャット履歴を分析し、複雑な質問を焦点を絞ったサブクエリに分解します。
- 並列実行
分解されたサブクエリがすべて同時に実行されます。各サブクエリはキーワード検索・ベクトル検索・ハイブリッド検索に対応し、セマンティックランカーで結果がリランキングされます。
- 結果統合
すべてのサブクエリの結果を統合し、グラウンディングデータ・ソース参照・実行計画の3パートからなるレスポンスを返します。
たとえば「ビーチ近くのホテルで空港送迎があり、ベジタリアンレストランまで徒歩圏内の場所を探して」という複合的な質問でも、エージェント検索はこれを複数のサブクエリに分解し、それぞれの条件に合致する結果を統合して返すことができます。
Knowledge BaseとFoundry Agent Service
エージェント検索の中核となるのが**Knowledge Base(ナレッジベース)とKnowledge Source(ナレッジソース)**の概念です。
Knowledge Sourceは検索インデックスやBlob Storage、SharePointなどのデータソースをラップするオブジェクトで、Knowledge Baseに紐付けることでエージェント検索のパイプラインに組み込まれます。
Knowledge BaseはFoundry Agent Serviceと連携でき、AIエージェントにベクトル検索の結果をナレッジとして提供します。Foundry IQ(パブリックプレビュー)を使えば、RAGワークフローを動的な推論プロセスとして一元化し、応答品質を向上させることも可能です。
MCP(Model Context Protocol)対応
エージェント検索のKnowledge Baseは、MCP(Model Context Protocol)サーバーとしても機能します。MCPはAIアプリケーションが外部データソースやツールに接続するためのオープンプロトコルで、Foundry Agent ServiceのほかGitHub CopilotやClaudeなどのMCP対応クライアントから呼び出せます。
Knowledge Baseがknowledge_base_retrieveツールを公開し、MCP互換クライアントがこのツールを呼び出すことで、エージェントアーキテクチャにAzure AI Searchの検索機能をシームレスに統合できます。

Azure AI Searchのベクトル検索の活用事例
利用場面
ベクトル検索は、データの意味的な類似性に基づく検索能力により幅広いシナリオで活用されています。ここでは代表的な活用事例を紹介します。
RAGアプリケーションの構築
ベクトル検索の最も代表的な活用先が、RAG(Retrieval-Augmented Generation、検索拡張生成)パターンです。社内ドキュメントやナレッジベースをベクトルインデックスに格納し、ユーザーの質問に対して関連するチャンクを検索し、LLMに渡して回答を生成するアーキテクチャです。
Azure AI Searchのベクトル検索をRAGに使う場合、Azure OpenAI ServiceのOn Your Data機能と組み合わせることで、独自データに基づくチャットアプリケーションを構築できます。ハイブリッド検索+セマンティックランキングを組み合わせると、回答の精度がさらに向上します。
社内ナレッジ検索の高度化
企業内のドキュメント管理システムやFAQデータベースにベクトル検索を導入することで、従業員が必要な情報に素早くアクセスできるようになります。プロジェクト報告書、マニュアル、社内ポリシーなどを意味的に検索できるため、キーワードの選び方に依存しない効率的な情報検索を実現します。
Azure AI SearchのインデクサーはAzure Blob StorageやAzure Cosmos DB、OneLakeなど複数のデータソースに対応しており、既存のデータ基盤と統合しやすいのも利点です。
eコマースとコンテンツ管理
eコマースサイトでは、顧客の検索クエリや過去の購買履歴に基づいて類似商品を推薦するシナリオでベクトル検索が有効です。「赤いワンピース」で検索して色味やスタイルが近い商品を提示するといった、従来のカテゴリ検索では実現しにくいマッチングが可能になります。
メディア企業では、画像やビデオのアーカイブに対してマルチモーダル検索を適用し、テキストクエリから関連するビジュアルコンテンツを発見するといった活用もされています。
社内のナレッジ検索に毎日30分以上かけているなら、それはベクトル検索とRAGで解決できる状態です。とりわけドキュメントが数千件を超える組織では、キーワード検索だけでは必要な情報にたどり着けないケースが増えてきます。ベクトル検索の導入を検討するタイミングかもしれません。
Azure AI Searchのベクトル検索の注意点
ベクトル検索を導入する際には、ティア別の制限事項やコスト面の考慮が必要です。ここでは実装前に把握しておくべきポイントを解説します。
ティア別のベクトルインデックス制限
Azure AI Searchでは、ベクトルフィールドのインデックス作成時に内部的なベクトルインデックスが構築されます。このベクトルインデックスのサイズは、サービスのティアと作成日によって制限されています。
以下の表は、公式のサービス制限ページに基づくパーティションあたりのベクトルインデックスサイズの上限です(2024年5月17日以降に作成されたサービスの場合)。
| ティア | ベクトルインデックスサイズ(パーティションあたり) | ストレージ(パーティションあたり) | 最大インデックス数 |
|---|---|---|---|
| Free | 該当なし | 50 MB | 3 |
| Basic | 5 GB | 15 GB | 15 |
| Standard S1 | 35 GB | 160 GB | 50 |
| Standard S2 | 150 GB | 512 GB | 200 |
| Standard S3 | 300 GB | 1 TB | 200 |
| Storage Optimized L1 | 150 GB | 2 TB | 10 |
| Storage Optimized L2 | 300 GB | 4 TB | 10 |
ベクトルインデックスのクォータはパーティションごとに適用されるため、パーティションを追加することでベクトル容量を拡張できます。たとえばS1を6パーティションで構成した場合、ベクトルインデックスの合計容量は35GB×6=210GBとなります。
2024年4月以降のサービスの高容量化
2024年4月3日以降に作成されたAzure AI Searchサービスでは、パーティションサイズとベクトルクォータが大幅に拡張されています。それ以前に作成されたサービスでは、たとえばBasicのベクトルインデックスは1GBに制限されていました。
古いサービスを使用している場合は、サービスのアップグレードで高容量化できる可能性があります。アップグレードの可否はリージョンによって異なるため、事前にポータルで確認してください。
埋め込みモデルのコスト管理
ベクトル検索自体に追加料金はかかりませんが、ベクトルの生成に使用する埋め込みモデルのAPIコールにはモデルプロバイダーのトークン課金が発生します。
コストを抑えるための方法として以下があります。
- 統合ベクトル化ではインデクサーのスケジュール実行(たとえば5分おき)を設定し、Azure OpenAIのトークン上限によるスロットリングを回避する
- インデックス作成用とクエリ用で埋め込みモデルのデプロイを分け、異なるサブスクリプションに配置することでトークン上限の競合を避ける
- ベクトルの圧縮(スカラー量子化やバイナリ量子化)を活用してインデックスサイズを削減し、パーティションコストを抑える
Azure AI Searchのベクトル検索の料金
ベクトル検索はすべてのリージョンとすべてのティアで追加料金なしで利用できます。料金はサービスのティアに応じた検索ユニット(SU)単位の固定時間課金です。
利用料金の見積もりにはAzureの料金計算ツールの利用をおすすめします。
ティア別の基本料金
以下の表は、2024年4月以降に作成されたサービスのティア別スペックと料金体系をまとめたものです。
| ティア | ストレージ/パーティション | 最大パーティション | 最大レプリカ | 最大SU | 特徴 |
|---|---|---|---|---|---|
| Free | 50 MB | なし | なし | なし | 評価・検証用。SLAなし |
| Basic | 15 GB | 3 | 3 | 9 | 小規模ワークロード向け |
| Standard S1 | 160 GB | 12 | 12 | 36 | 汎用。スケーラブル |
| Standard S2 | 512 GB | 12 | 12 | 36 | 中〜大規模ワークロード |
| Standard S3 | 1 TB | 12 | 12 | 36 | 大規模。高密度モードあり |
| Storage Optimized L1 | 2 TB | 12 | 12 | 36 | 大容量ストレージ。変更頻度の低いインデックス向け |
| Storage Optimized L2 | 4 TB | 12 | 12 | 36 | 最大容量。変更頻度の低いインデックス向け |
各ティアの具体的な時間単価はリージョンや通貨によって異なります。Azure AI Searchの公式料金ページから最新の価格を確認してください。
料金は1つのレプリカと1つのパーティションの初期構成に対する固定費用として発生し、レプリカやパーティションを追加するごとにSU単位で増加します。たとえば2レプリカ×1パーティション=2 SUの構成では、時間単価の2倍が課金されます。
セマンティックランカーとエージェント検索の追加料金
基本のティア料金に加えて、以下のプレミアム機能には追加料金が設定されています。
| 機能 | 無料枠 | 超過分 |
|---|---|---|
| セマンティックランカー | 毎月1,000クエリまで無料 | 追加1,000クエリごとに課金 |
| エージェント検索(Agentic Retrieval) | 毎月5,000万トークンまで無料 | 追加100万トークンごとに課金 |
エージェント検索ではさらに、クエリプランニングに使用するLLM(Azure OpenAI)のトークン料金が別途発生します。gpt-4o-miniのような軽量モデルを使用することで、クエリプランニングのコストを抑えることが可能です。
また、Azureの無料アカウントを利用すれば、Freeティアのサービスを1つ作成してベクトル検索を無料で試すことができます。Freeティアはストレージが50 MBに制限されていますが、機能検証やチュートリアルの実行には十分です。
Azure製品全般の料金体系についてはAzureの料金体系を解説!サービスごとの料金例や確認方法も紹介もあわせてご覧ください。

AI検索技術をAIエージェントの業務自動化に統合するなら
Azure AI Searchのベクトル検索やRAG基盤を構築しているなら、次のステップはAIエージェントによる検索結果の活用と業務自動化です。AI Agent Hubなら、検索AI技術をエージェントベースの業務自動化に統合できます。
- ベクトル検索・RAG基盤をエージェントベースの業務自動化に統合 AI Searchの検索精度を、AIエージェントが判断・処理まで担う業務自動化に活かせます
- Teams上で完結するため、既存のMicrosoft環境にそのまま導入可能
- 自社テナント内で完結するセキュリティで、安心して業務データを扱える
AI検索技術をAIエージェントの業務自動化に統合

ベクトル検索の知見をエージェント基盤に拡張
Azure AI Searchのベクトル検索を活用しているなら、次はAIエージェントによるRAG基盤の業務自動化です。AI Agent Hubで、検索AI技術をエージェントベースの業務自動化に拡張できます。
まとめ
本記事では、Azure AI Searchのベクトル検索について、基本概念からアルゴリズム、統合ベクトル化、エージェント検索、活用事例、注意点、料金体系までを解説しました。
ポイントを3つにまとめます。
- ベクトル検索はすべてのティアで追加料金なし
HNSWアルゴリズムによる高速な近似検索と、ハイブリッド検索+セマンティックランキングの組み合わせで、キーワード検索だけでは実現できない意味的な情報検索を提供します。
- 統合ベクトル化でパイプラインを自動化
データのチャンク分割からベクトル生成、クエリ時のベクトル変換まで、Azure AI Searchのインデクサーパイプラインで一元管理できます。個別のベクトル化パイプラインを構築・運用する手間が不要になります。
- エージェント検索で次世代のRAGを実現
LLMによるクエリ分解・並列実行・結果統合のパイプラインで、複雑な質問にも高精度な回答を返せるようになります。Foundry Agent ServiceやMCP対応クライアントとの連携も可能です。
まずはFreeティアのサービスを作成し、ポータルの「データのインポートとベクター化」ウィザードで小規模なデータセットを使ったベクトル検索を試してみてください。基本的な動作を確認したら、ハイブリッド検索やセマンティックランキングを追加して精度を検証し、本番環境ではティアのスケーリングとインデクサーのスケジュール実行で運用を安定させるのが推奨される導入ステップです。










