この記事のポイント
 リアルタイムのログ・時系列分析基盤にはAzure Data Explorerが第一候補。ストリーミング取り込みから可視化まで一気通貫で回せる
リアルタイムのログ・時系列分析基盤にはAzure Data Explorerが第一候補。ストリーミング取り込みから可視化まで一気通貫で回せる- 分析クエリはKQLで統一すべき。Azure Monitorでも共通言語として使えるため、ログ分析スキルの投資対効果が高い
- Event Hubs・IoT Hub経由の取り込みとPower BIでの可視化を組み合わせることで、監視・異常検知の即応体制を構築できる
- RDB的なトランザクション処理や少量データの用途には向かないため、用途を見極めてから導入すべき
- 料金はクラスター規模で大きく変動するため、ピーク流量とデータ保持期間を先に固めてから見積もりに着手するのが鉄則

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
システム運用のログ、IoTデバイスのテレメトリ、アプリのイベントなど、企業が扱うデータは「大量・高速・時系列」になりがちです。こうしたデータは、保存して終わりではなく、異常検知や原因調査のために、素早く探索できる状態が求められます。
本記事では、リアルタイム分析に強いフルマネージド分析基盤であるAzure Data Explorerについて、特徴、使い方、活用シーン、料金の考え方までを一通り整理します。
Azure Data Explorerは、ストリーミング取り込みからクエリ実行、可視化までを一気通貫で扱える点が強みです。独自のクエリ言語であるKusto Query Language KQLを使い、ログや時系列データを探索的に分析できます。
「どのデータを、どれくらいの頻度で、どんな意思決定につなげたいか」を起点に、導入・見積もりを進めるための判断材料として活用してください。
Azure Data Explorerとは
Azure Data Explorerは、Microsoft Azureが提供するフルマネージドの分析サービスです。大量のログやテレメトリのような時系列データを、取り込みから分析まで低遅延で回しやすく、運用監視や障害調査のような用途で採用されます。
Azure Data Explorerイメージ
分析にはKusto Query Language KQLを使います。KQLはAzure Data Explorerだけでなく、ログ分析の文脈ではAzure Monitorでも登場するため、ログ分析の基礎として押さえておくと応用が効きます。
Azure Data Explorerの公式概要は、Microsoft Learnもあわせて確認しておくと安心です。
【参考】Azure Data Explorer の概要

Azure Data Explorerの特徴
この章では、Azure Data Explorerが「ログや時系列データの分析」に向いている理由を、機能面と運用面から整理します。
高速な取り込みと低遅延の探索的分析
Azure Data Explorerは、ストリーミング取り込みとインタラクティブなクエリ実行を想定して設計されています。検索や集計の遅延を抑えやすく、監視や障害対応のような場面で、原因候補の切り分けを素早く回せる点が強みです。
また、列指向のデータ配置やキャッシュなどの仕組みにより、集計やフィルタを多用するクエリでも応答性を保ちやすいとされています。深い性能チューニングは後回しにしつつ、まずは分析ループを回せるところから始めやすいのが現場では助かるポイントです。
多様な取り込み元とスキーマ設計の柔軟性
実運用では「データの形が揃っていない」「ログ形式が途中で変わる」といった問題が起きがちです。Azure Data Explorerは、こうした現場データを段階的に整備しながら分析する用途にも向きます。
取り込み経路としては、ストリーミング基盤との連携もよく使われます。たとえば、イベントの受け口としてAzure Event Hubs、IoTデバイスのテレメトリ基盤としてAzure IoT Hubを組み合わせる設計が代表例です。
Kusto Query Language KQLでのクエリ作成
KQLは、ログや時系列データの分析で使いやすいように設計されたクエリ言語です。フィルタ、集計、時系列の整形などを段階的につなげて書けるため、試行錯誤しながら分析を進めやすいのが特徴です。
KQLの公式リファレンスは、Microsoft Learnにまとまっています。
【参考】KQL クエリ言語
Azureサービスや可視化ツールと連携しやすい
Azure Data Explorerは、取り込み元や可視化先を広げやすい点も魅力です。たとえば、ダッシュボードでの可視化、BIツールでのレポート化、監視ツールでのグラフ化など、用途に応じて出口を選べます。
可視化やレポートの文脈では、Power BIとの連携が検討候補になります。公式の連携まとめは、Microsoft Learnのガイドも参照してください。
【参考】Azure Data Explorer の統合と視覚化
使い始める前に知っておきたい注意点
Azure Data Explorerは強力な一方、導入前に押さえておきたい注意点もあります。
- クラスター設計がコストと性能に直結する
小さく始められる反面、データ保持期間やクエリ頻度が増えると、必要なクラスター規模も変わります。後述の料金セクションで、見積もりの進め方を整理します。
- KQLの学習コストが発生する
SQL経験者でも、関数や書き方の癖に慣れる必要があります。まずは頻出パターンをチームで共有し、クエリのテンプレート化から始めると進めやすいです。
- 運用設計はゼロではない
フルマネージドでも、アクセス制御、データ保持方針、取り込み失敗時の扱いなどは設計が必要です。既存の監視基盤やログ収集の流れと一緒に検討してください。
Azure Data Explorerの使い方
ここからは、Azure Data Explorerを使い始めるまでの基本手順を、代表的な流れに沿って紹介します。画面構成は更新されることがあるため、実際のUIと差分がある場合はMicrosoft Learnの最新手順も確認してください。
クラスターとデータベースの作成
最初に、分析基盤となるクラスターと、データを格納するデータベースを作成します。
ステップ1:クラスターの作成
-
Azureポータルにアクセスし、検索欄で「Azure Data Explorer」を検索します。
Azureポータル画面Azureポータルの基本操作が不安な場合は、先にこちらを確認しておくと迷いにくくなります。
【関連記事】
Azure Portalとは?操作方法やメリットをわかりやすく解説! -
「リソースの作成」を選択します。
リソースの作成ボタン -
検索画面で「Azure Data Explorer」と入力し、Azure Data Explorerを選択して「作成」をクリックします。
検索画面 -
クラスター名、リージョン、スケーリングのオプションなどを設定し、「確認と作成」をクリックします。
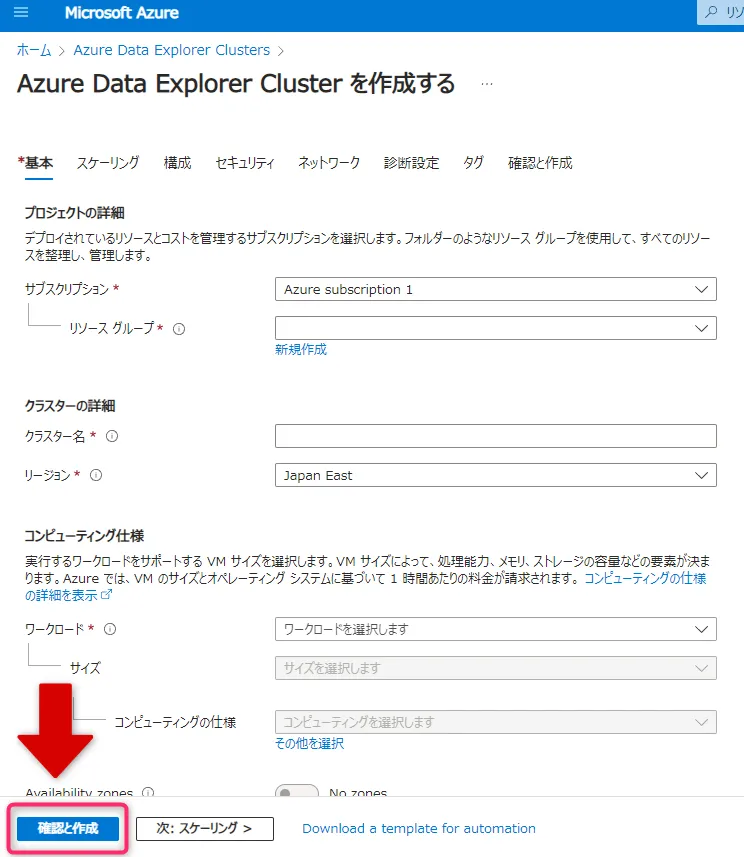
クラスター設定画面 -
内容を確認して「作成」をクリックします。

作成ボタン
ステップ2:データベースの作成
クラスターが作成できたら、データベースを追加します。
-
クラスターの概要タブで「データベースの追加」を選択します。
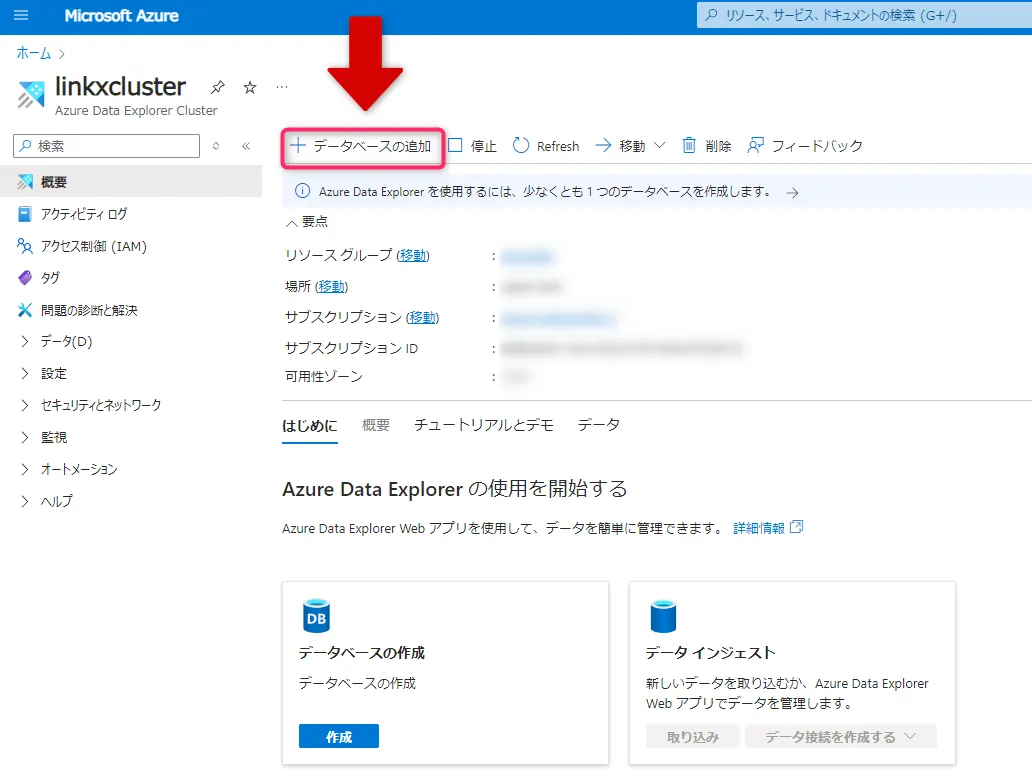
データベースの追加ボタン -
新しいデータベースの作成画面に必要事項を入力し、「作成」をクリックします。
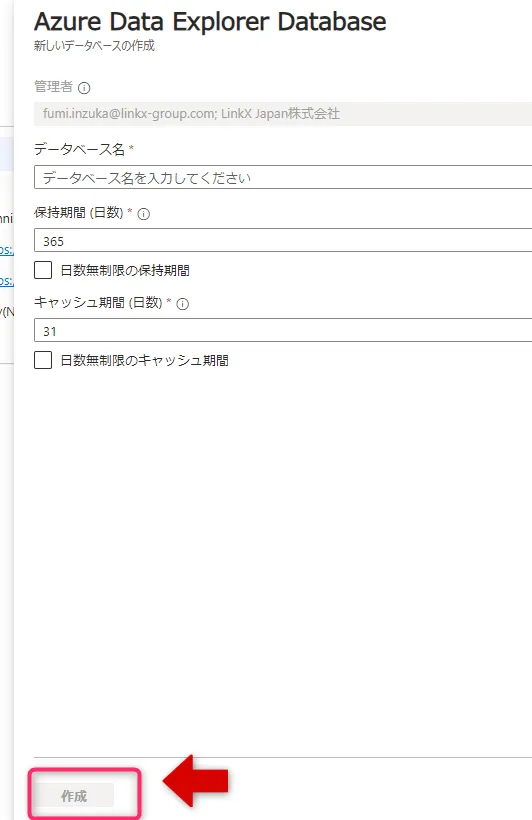
データベースの作成画面
データの取り込み
次に、分析対象のデータを取り込みます。Azure Data Explorerは多様なデータソースに対応しますが、ここでは操作をイメージしやすいように、ローカルファイルを新しいテーブルに取り込む手順を紹介します。
ストリーミングデータを扱う場合は、Event HubsやIoT Hub側のデータ流量とスキーマを整理しておくと、取り込み設計がスムーズです。
-
クラスターのページ左側メニューから「クエリ」を選択し、取り込み先のデータベースを選んでから、Web UIで開きます。
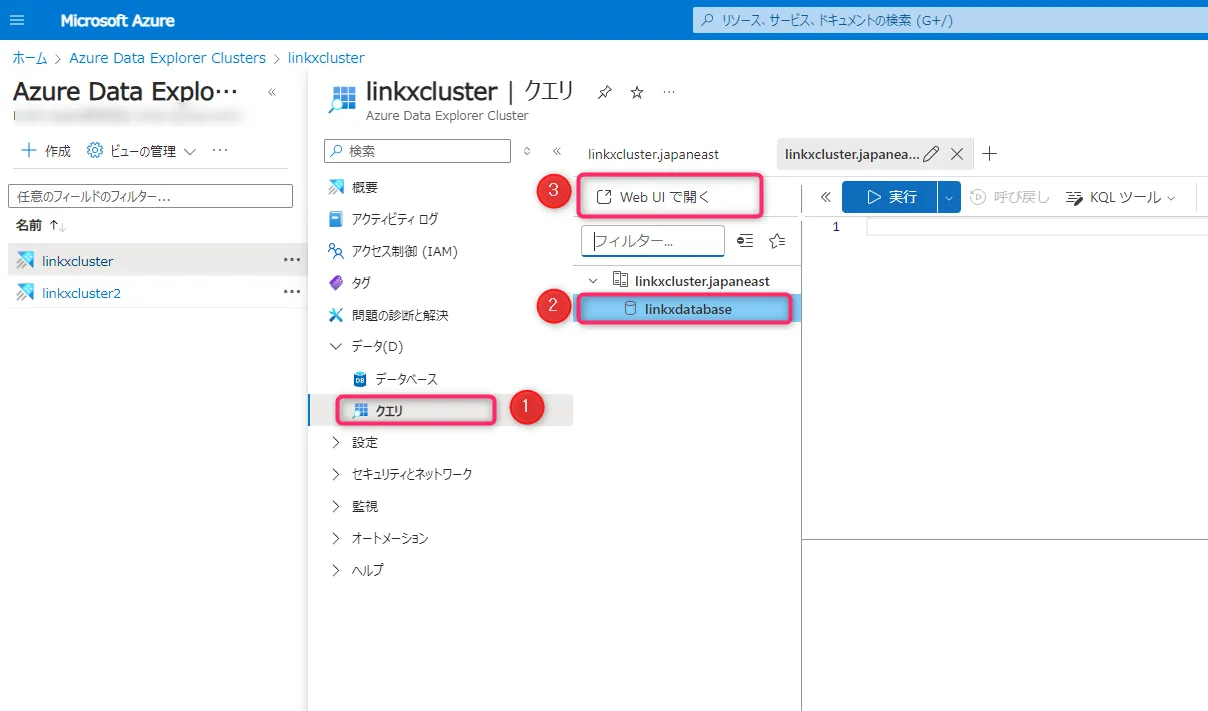
クラスターページ -
Azure Data Explorer Web UIが開きます。ここはクエリと分析に特化したUIで、素早く検証したいときに便利です。
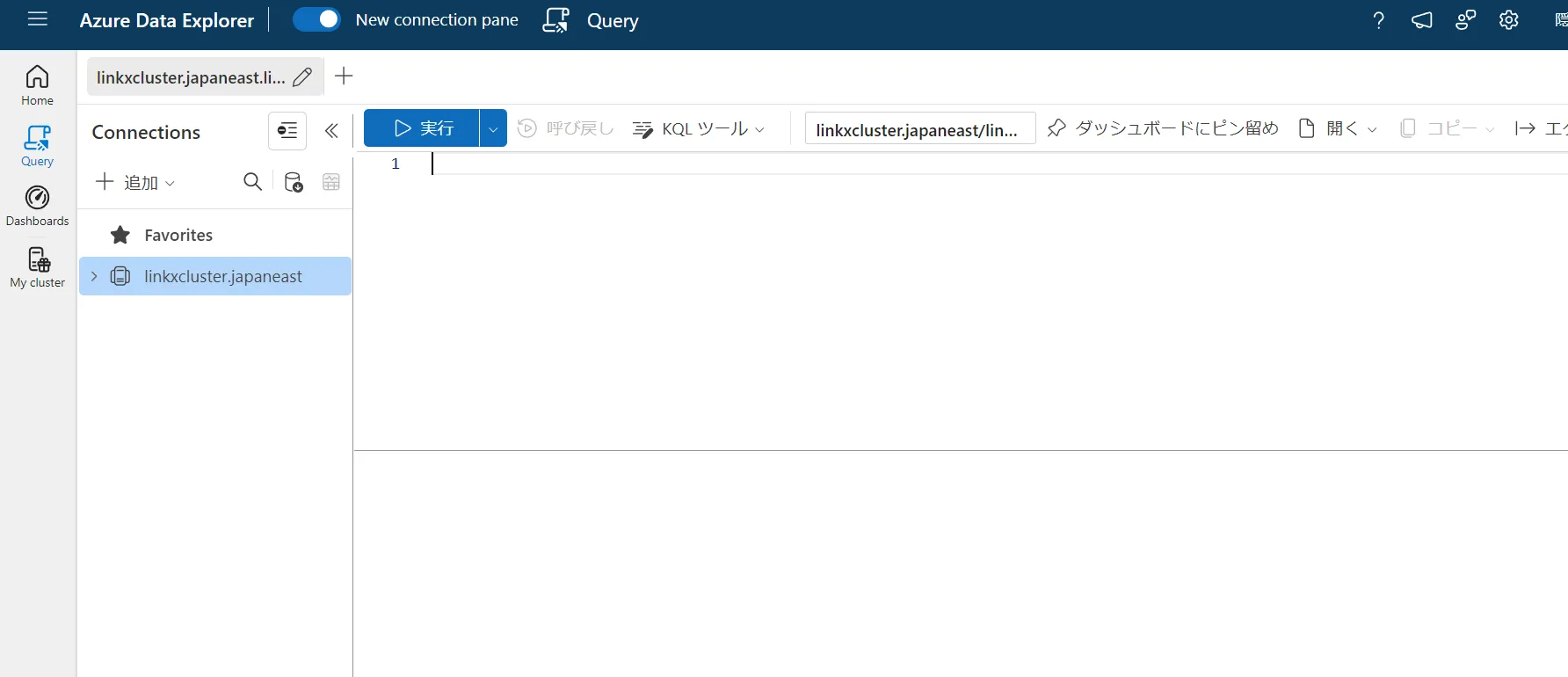
Azure Data Explorer Web UI -
取り込み先のデータベースを右クリックし、「Get Data」を選択します。
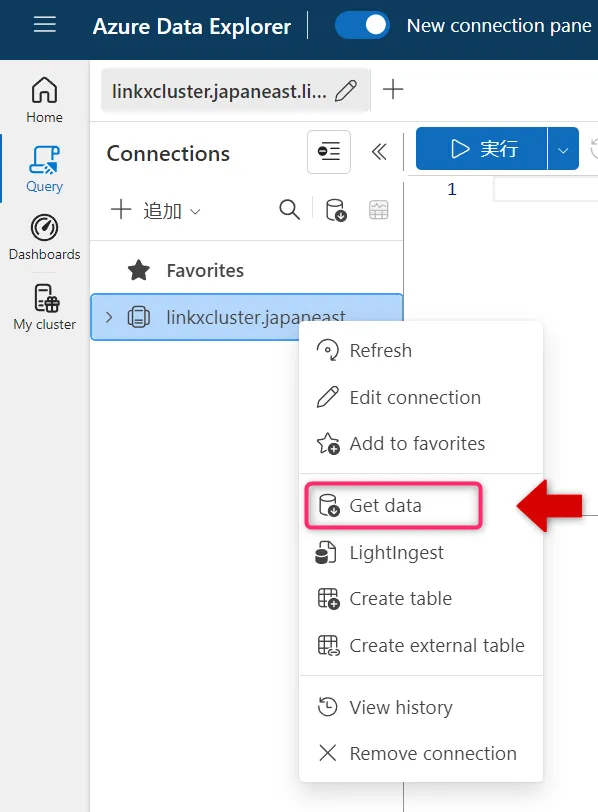
Get Dataボタン -
データソースの一覧から「ローカルファイル」を選択します。
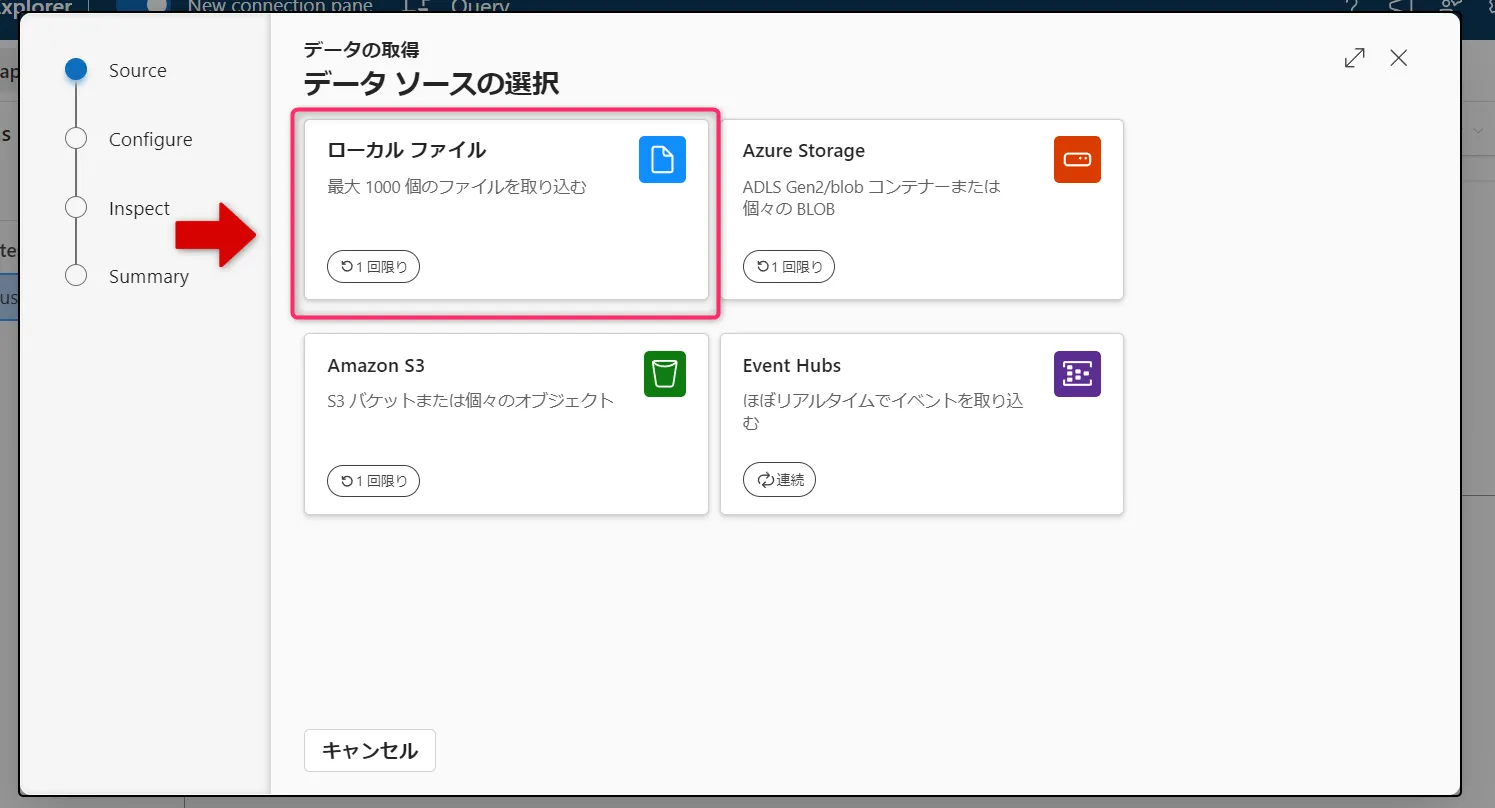
ソースタブ -
取り込み先のテーブルを指定します。新しいテーブルに取り込む場合は「新しいテーブル」を選び、テーブル名を入力します。
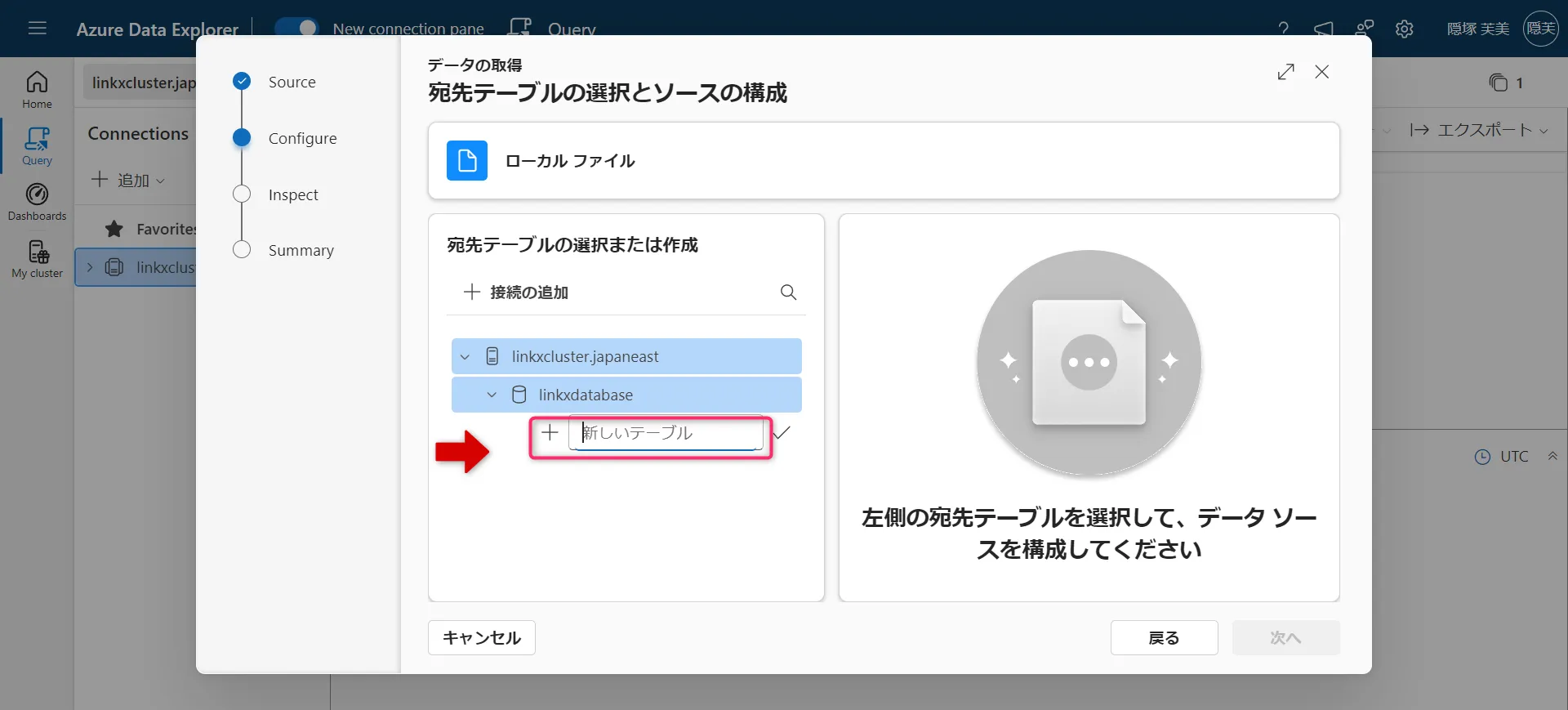
新しいテーブル入力画面 -
ファイルをウィンドウにドラッグするか、「ファイルの参照」を選択してアップロードします。
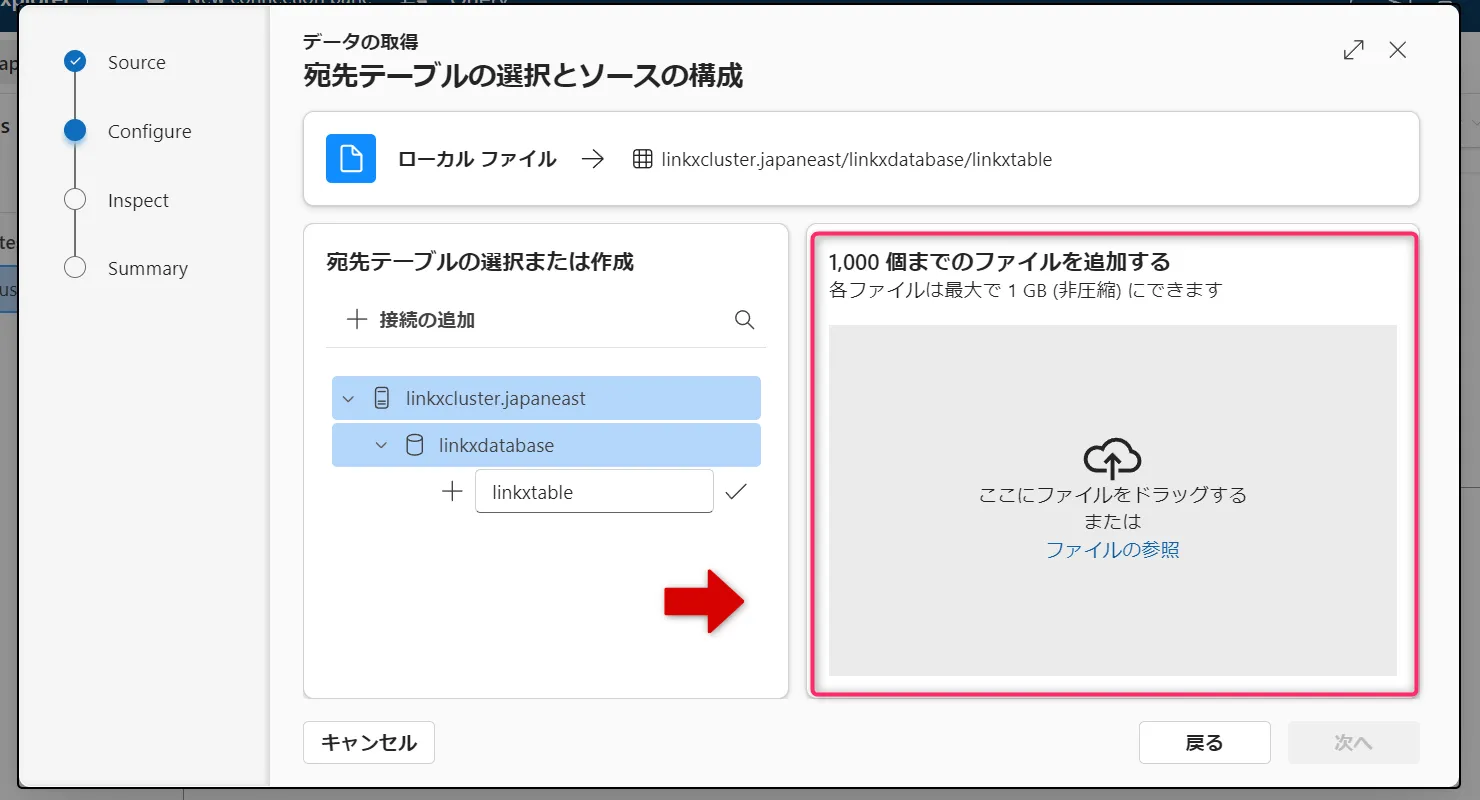
ドラッグ画面 -
ファイルを追加したら「次へ」をクリックします。
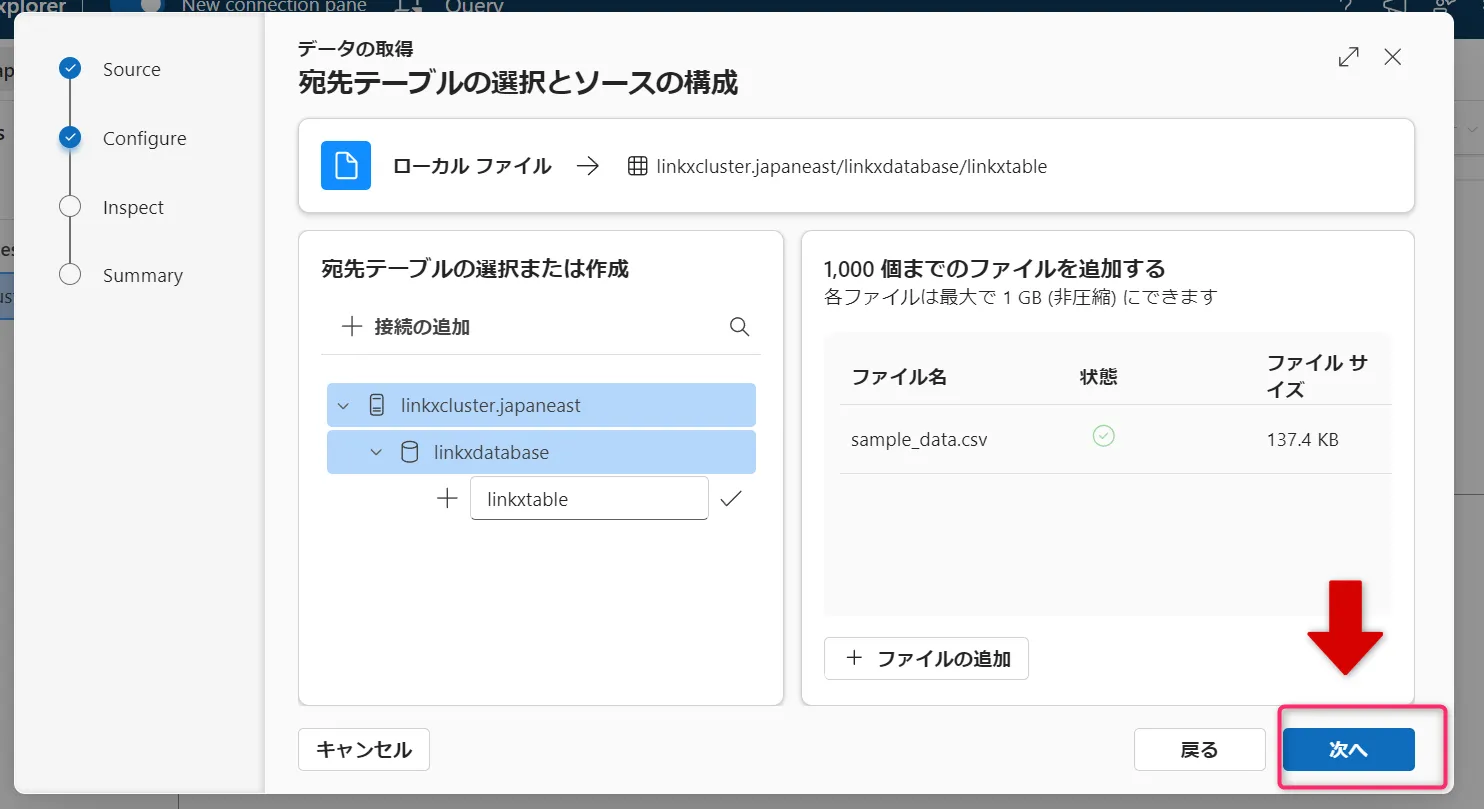
次へボタン -
取り込み前のプレビューを確認し、「終了」を選択して取り込みを完了します。
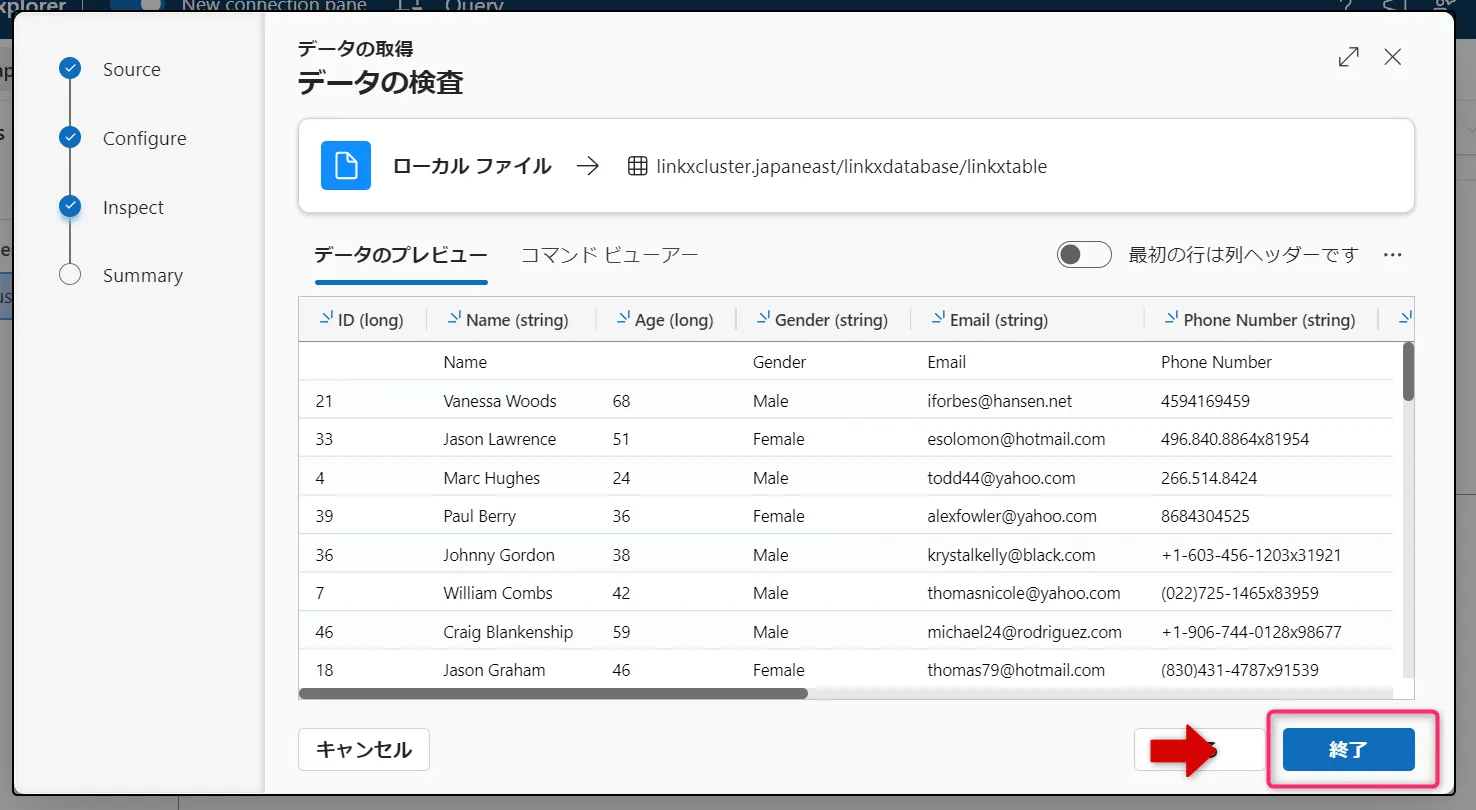
検査画面
KQLでクエリを実行する
取り込みができたら、KQLでクエリを実行します。最初は「テーブルを絞る」「並べ替える」「件数を制限する」あたりから始めると、UI操作の流れを掴みやすいです。
-
左側のメニューで「クエリ」を選択し、データベースを選びます。
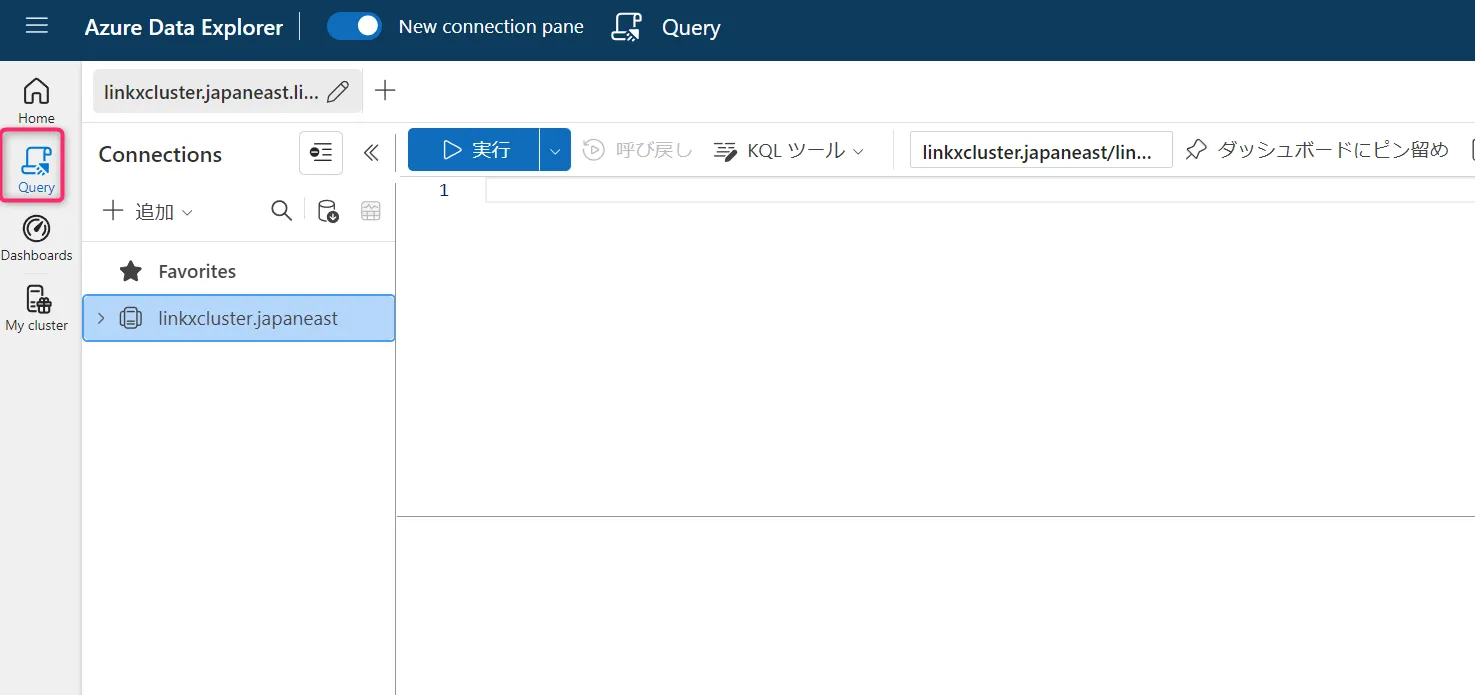
クエリ選択 -
例として、次のクエリをクエリウィンドウに貼り付けて実行します。
Linkxtable | sort by Name desc | take 10テーブル名と列名は、取り込んだデータに合わせて置き換えてください。
-
実行結果が表示されます。
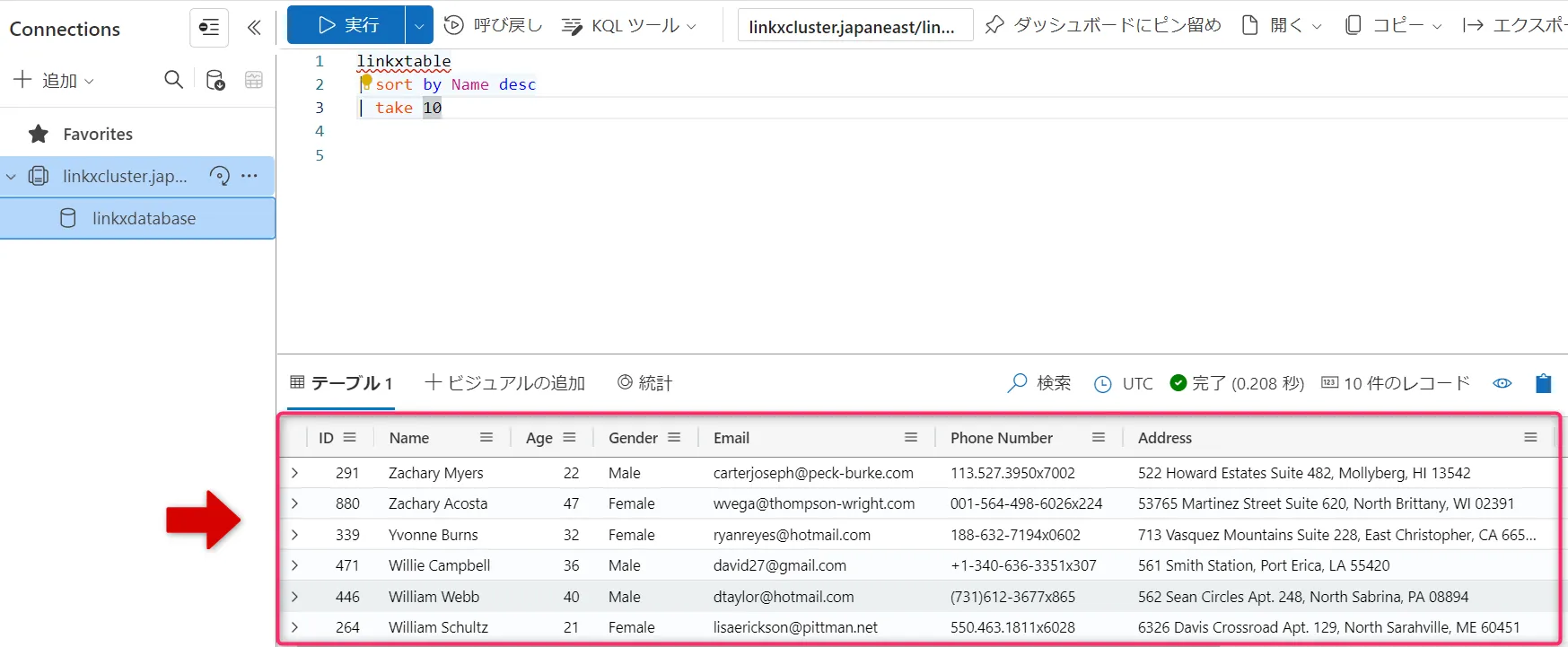
結果画面
可視化ツールと連携する
Azure Data Explorerでは、クエリ結果を可視化して意思決定につなげるために、複数のツールを使い分けられます。
-
Azure Data Explorer Dashboards
Azure Data Explorerに組み込まれているダッシュボード機能です。KQLで作ったクエリをベースに、インタラクティブなグラフやチャートを作成できます。 -
Power BI
BIツールでレポートを作る用途に向きます。 -
Grafana
監視のダッシュボードとして採用されやすい可視化ツールです。 -
Excel
Excelから接続して分析し、ピボットテーブルなどを作成できます。 -
Jupyter Notebooks
PythonやRなどでクエリと分析を進めたい場合に便利です。
公式の連携ガイドは、Microsoft Learnも参照してください。
【参考】Azure Data Explorer の統合と視覚化
Azure Data Explorer ダッシュボードの例(参考:Microsoft)
Azure Data Explorerの活用シーン
ここからは、Azure Data Explorerが効果を発揮する具体的な活用シーンをご紹介します。
ログデータ分析
Azure Data Explorerは、大規模なログデータの分析に適しています。たとえば、次のような場面で効果的です。
- アプリケーションログ
エラーやパフォーマンスの問題を迅速に特定するために利用されます。
- セキュリティログ
不正アクセスや異常なアクティビティを、リアルタイムに近い粒度で検出しやすくなります。
- インフラストラクチャログ
サーバー、ネットワーク機器、ストレージなど、システム全体の健全性をモニタリングします。
IoTテレメトリデータ分析
Azure Data Explorerは、IoTデバイスから生成される大量のテレメトリデータを、リアルタイムに近い形で分析したい場合に向きます。たとえば次のような用途です。
- センサーデータのリアルタイム処理
温度、湿度、圧力などのデータを継続的に取り込み、傾向や異常を追跡します。
- デバイスのパフォーマンス監視
デバイスごとの稼働状況を監視し、異常な動作やパフォーマンス低下を早期に発見します。
- 予測メンテナンスのためのパターン分析
過去データから異常パターンを見つけ、故障兆候の検知に役立てます。
異常検知や予測モデルの作成
Azure Data Explorerは、分析の下準備として、特徴量の集計や時系列の整形といった処理にも使えます。たとえば、次のような用途で価値が出ます。
- 時系列データの異常検知に向けた前処理
特徴量の集計や欠損値処理を行い、異常検知の精度を上げるためのデータ整備に使います。
- トレンド予測や需要予測のための集計
時系列の集約や粒度の統一など、予測の前工程を効率化します。
- クラスタリングやセグメンテーションのための特徴量作成
行動ログやイベントデータを、分析・モデルに使える形へ整形します。

Azure Data Explorerの料金
Azure Data Explorerは、クラスターを起点に利用するサービスです。料金は「どれくらいのデータを、どれくらいの期間保持し、どれくらいの頻度でクエリするか」で大きく変わるため、最初に前提を決めてから見積もるのがポイントです。
料金体系の主な構成要素
料金は主に次の要素で決まります。
- クラスターのコンピュート
インスタンスタイプやノード数、稼働時間が効きます。クエリの同時実行数が増えるほど、必要な余力も大きくなりやすいです。
- ストレージとデータ保持
保持期間が長いほどストレージ費用が増えます。ログは保持要件が監査やセキュリティ要件と結びつくため、要件確認が重要です。
- 取り込み経路とデータ量
Event Hubsなどを経由する場合、取り込み側サービスの料金も含めて設計する必要があります。
- ネットワーク
クラスターの外にデータを出す通信や、リージョンを跨ぐ構成では、ネットワーク費用が影響する場合があります。
- 予約などの割引要素
長期利用が見込める場合は、予約により割引されることがあります。割引の条件はSKUやリージョンで変わるため、料金ページで最新条件を確認してください。
価格例の捉え方
開発・検証用途で試すなら、開発者向けクラスターを起点にすると、手元のデータで操作感を確認しやすいです。提供条件や制約は変わり得るため、利用前に公式料金ページで確認してください。
【参考】Azure Data Explorer の価格
価格注記
料金やSLAは構成や選択肢によって変わります。特に次の点は事前に確認しておくと、見積もりのブレが減ります。
- リージョン
同じ構成でもリージョンで単価が変わることがあります。
- オートスケールの方針
平常時とピーク時で必要な規模が違う場合、スケーリング方針がコストに直結します。
- 開発者向けクラスターの制約
本番用途の要件を満たすとは限りません。SLAも含め、用途に応じて適切なプランを選びます。
見積もりの作り方
見積もりは、料金表の数字を見る前に「前提条件」を固めるのが近道です。たとえば次の順で整理すると進めやすくなります。
- 取り込みデータの種類、1日あたりのデータ量、保持期間を決める
- 想定ユーザー数と、クエリの頻度やピークを整理する
- 取り込み経路を決める。Event HubsやIoT Hubを使うなら、その料金もあわせて見る
- Azureの料金計算ツールで概算を作り、最小構成で検証して調整する
Azureの料金計算ツールの使い方は、こちらも参考にしてください。
【関連記事】
Azureの料金計算ツールの利用方法!基本機能や円表示の手順を解説
Azure Data Explorerのメリット
Azure Data Explorerは、分析スピードと運用負担の両面でメリットがあります。
分析の試行錯誤を回しやすい
探索的に分析を進めたい場面では、次の点が効いてきます。
- 低遅延でクエリを回しやすい
原因調査や仮説検証で、クエリを小さく回して確度を上げていく流れに向きます。
- KQLで段階的に組み立てやすい
フィルタ、集計、整形などをパイプ記号でつないで書けるため、処理の流れを読みやすく保ちやすいです。
- 可視化に接続しやすい
ダッシュボードやBIツールにつなげ、チームで同じ指標を見ながら改善を回せます。
フルマネージドで運用負担を抑えやすい
フルマネージドとして提供されるため、運用面では次のようなメリットがあります。
- 基盤運用を任せやすい
パッチ適用や基本的なメンテナンスの負担を減らしやすくなります。
- 可用性の前提を置きやすい
SLAはプランや構成により変わるため、要件に合わせて公式情報を確認しながら設計します。
- アクセス制御を統合しやすい
Microsoft Entra IDと連携してアクセス制御を設計できます。
Microsoft Entra IDについてはこちらの記事もご覧ください。
【関連記事】
Microsoft Entra IDとは?その機能や料金体系をわかりやすく解説!

データ分析基盤の知見をAI業務自動化にも活かすなら
Azure Data Explorerでログ分析や時系列データの処理を行ってきた経験は、AI業務自動化の分析基盤設計にも直結します。AI業務自動化ガイドでは、データ分析の知見を活かしたAI導入の進め方を220ページにわたって解説しています。
データ分析基盤からAI業務自動化へ

Data Explorerの分析力をAI活用に展開
Azure Data Explorerでログ分析や時系列データ処理を行ってきた経験は、AI業務自動化の分析基盤設計にも活きます。220ページの実践ガイドで、Microsoft環境でのAI導入を計画してみませんか。
Azure Data Explorerのまとめ
Azure Data Explorerは、ログや時系列データのような「大量・高速・継続的に増えるデータ」を、取り込みから分析、可視化まで低遅延で回しやすいフルマネージド分析基盤です。Kusto Query Language KQLにより探索的な分析を進めやすく、運用監視や障害調査、IoTテレメトリの分析などで価値を出しやすくなります。
一方で、性能とコストはクラスター構成や保持期間、クエリ頻度に強く依存します。まずは検証で操作感をつかみつつ、前提条件を整理して概算を作り、必要に応じて段階的に拡張していく進め方が現実的です。










