この記事のポイント
 Azure DatabricksはApache Spark基盤の統合データ+AI基盤、2026年はData Intelligence Platformとして再定義されている
Azure DatabricksはApache Spark基盤の統合データ+AI基盤、2026年はData Intelligence Platformとして再定義されている- 2026年10月1日にStandard tier廃止、Premiumへの自動移行でDBU単価はSKU別に変動(東部リージョン例:All-Purpose +37.5%・Jobs +100%・SQL Compute据え置き)
- Unity Catalog Mirroring GAでMicrosoft Fabric・OneLakeとゼロコピー連携、Genie for M365 CopilotがBeta提供
- 料金はDBU+Azure VM+ストレージの3層構造、Committed Use(DBCU)で最大37%割引が可能
- Sparkベース大規模ETLや独自ML運用が主軸ならDatabricks第一候補、BI・M365中心ならFabricを主にしてDatabricksをミラー元に噛ませる構成が有力

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Azure Databricksは、DatabricksのData Intelligence PlatformをMicrosoft Azureのファーストパーティサービスとして提供する、統合データ+AIプラットフォームです。
Apache Sparkによる大規模分散処理を基盤に、Delta Lakeでのレイクハウス構築、Unity Catalogによるガバナンス、Mosaic AIやGenieによるAI/BI活用までを1つのワークスペースで扱えます。
本記事では、Data Intelligence Platformとしての現代的な位置づけ、本家Databricksとの違い、主要機能、Microsoft Fabric・OneLakeとの統合、料金体系、使い方、Fabric・Synapse・Snowflakeとの使い分け、そして2026年10月のStandard tier廃止を含む導入で見落とされやすい論点までを、2026年7月時点の最新情報で体系的に解説します。
目次
Azure Databricksとは?Data Intelligence Platformとしての位置づけ
Data Intelligence Platformとしての現代的な役割
Azure Databricksと本家Databricksの違い
LakebaseとAgent Bricks——エージェント時代の追加要素
Azure DatabricksとMicrosoft Fabric・OneLakeの統合
Unity Catalog Mirroringで Fabric から Databricks データを扱う
OneLake Catalog FederationでDatabricks側からゼロコピーアクセス
Genie for M365 CopilotとExcel Add-in
Azure Databricksの使い方(Workspace作成〜Notebook実行)
Azure DatabricksとFabric・Synapse・Snowflakeの使い分け
Azure Databricks導入で見落とされやすい3つの落とし穴
Unity Catalog未整備でFabric連携が回らない
Lakebase/CustomerLakeを後付けで足す運用負債
Azure Databricksとは?Data Intelligence Platformとしての位置づけ
Azure Databricks(アジュール・データブリックス)とは、Databricks社の統合データ+AIプラットフォームを、Microsoft Azure上のファーストパーティサービスとしてOEM提供している実装形態です。
Apache Sparkによる大規模分散処理を基盤に、ノートブック開発、Delta Lakeによるデータレイクハウス構築、SQL分析、機械学習、生成AI開発までを、単一のワークスペースで扱えるように統合しています。
2026年現在、Databricksは自社の主軸コンセプトを従来の「Lakehouse Platform」からData Intelligence Platformへと進化させ、Azure Databricksもその流れをそのまま引き継いでいます。
Genie(会話型AI/BI)・Lakeflow(データエンジニアリング)・Lakebase(サーバーレスPostgres)・CustomerLake(Agentic Customer Data Platform)といった、AIエージェントを前提とする新しい構成要素が2026年前半に相次いで発表されました。
Data Intelligence Platformとしての現代的な役割
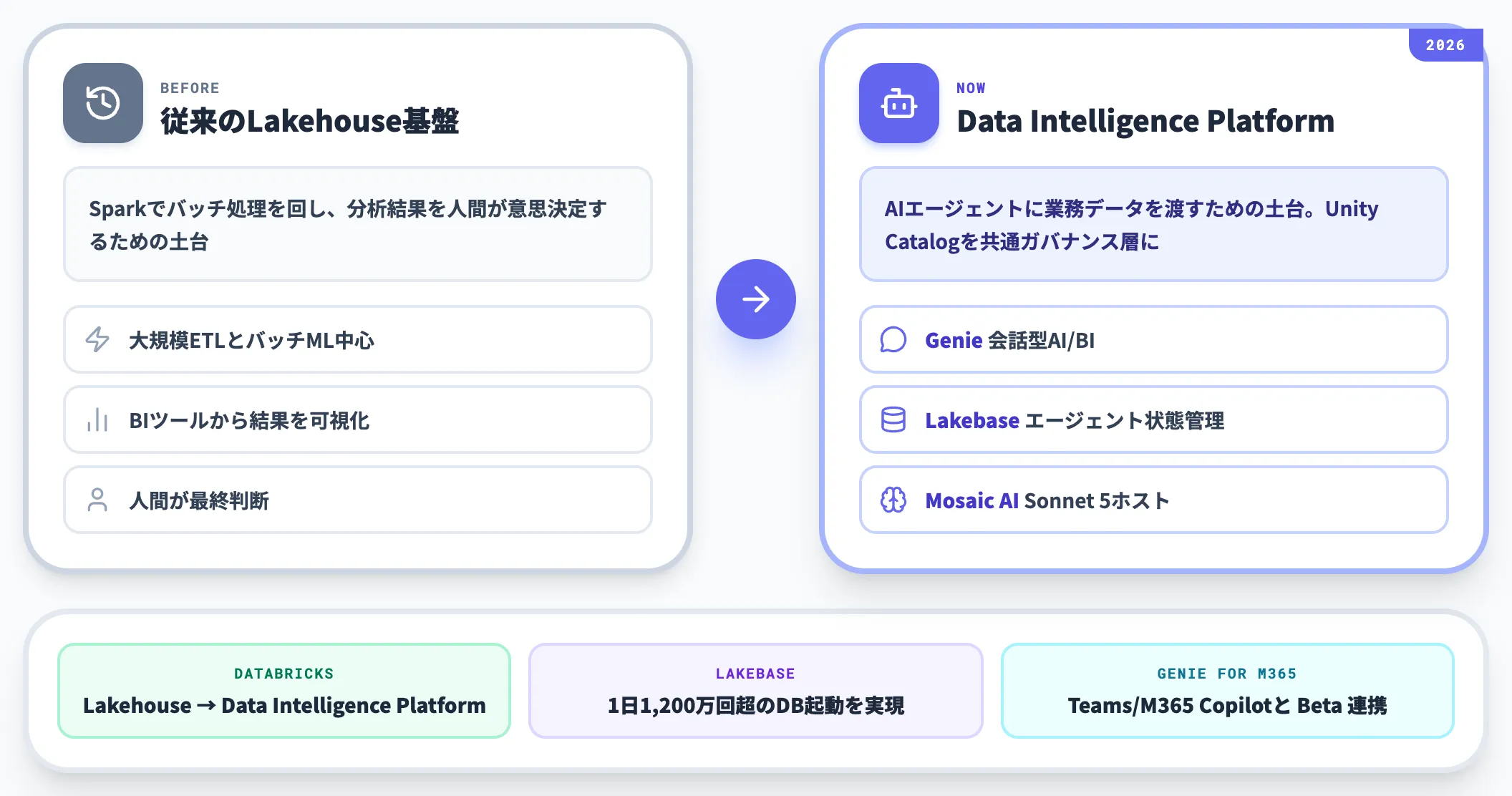
2020年代後半に入り、Azure Databricksは単なる分析基盤から「AIエージェントに業務データを渡すための土台」という性格を強めています。
Unity Catalogによる意味レイヤーと、Genie/Mosaic AI/Lakebaseといったエージェント向け機能が同じガバナンスの下に統合されているのが、この世代の特徴です。
-
Genie(AI/BI)
自然言語で社内データに問い合わせできる会話型分析。Data + AI Summit 2026で、AIコワーカー製品群「Genie One」が発表され、その一部として Genie for Microsoft Teams & M365 Copilot がBetaで提供されている(Databricks Blog)
-
Lakebase
AIエージェントの状態・メモリ・チャット履歴を保持するためのサーバーレスPostgres(Databricks Lakebase)。LTAP(Lake Transactional/Analytical Processing)アーキテクチャの基盤として2026年にGAし、1日1,200万回超のデータベース起動が公表されている(Databricks LTAPプレスリリース)
ここでのポイントは、Sparkでバッチ処理を回すだけの基盤から、AIエージェントの業務判断を支えるプラットフォームへという位置づけの転換が起きている、という点です。
Fabricとの棲み分けや、Standard tier廃止という料金上の節目も、この位置づけの変化と地続きで進んでいます。

Azure Databricksと本家Databricksの違い
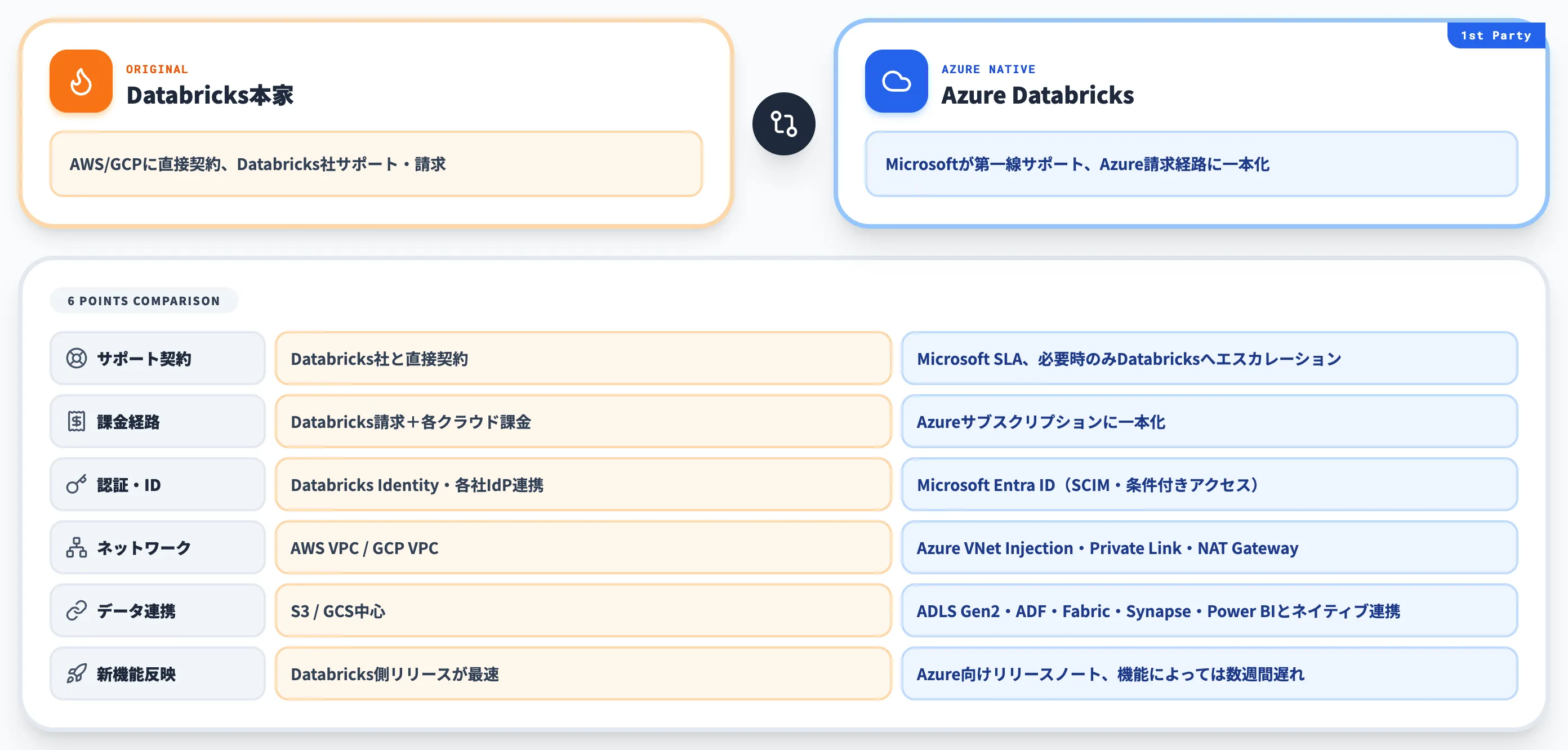
Azure Databricksは、Databricks本家の機能をほぼそのまま利用しつつ、Microsoft側のマネージドサービスとして提供される点が最大の違いです。
具体的にはMicrosoftが第一線サポートを担い、Azureサブスクリプションと請求経路を共有し、認証はMicrosoft Entra ID(旧Azure AD)で統一されます。
以下の表で、本家Databricks(AWS・GCP上で契約する形態)とAzure Databricksの主要な違いを整理しました。
| 項目 | Databricks本家 | Azure Databricks |
|---|---|---|
| サポート契約 | Databricks社と直接契約 | MicrosoftがサポートSLAを提供し、必要に応じてDatabricksへエスカレーション |
| 課金経路 | Databricks請求書+各クラウド課金 | Azureサブスクリプションに一本化(DBUとVM費用がまとめて請求) |
| 認証・ID | Databricks Identity/各社IdP連携 | Microsoft Entra ID(SCIM同期・条件付きアクセス対応) |
| ネットワーク | AWS VPC/GCP VPC | Azure VNet Injection・Private Link・NAT Gateway |
| データ連携 | S3/GCS中心 | ADLS Gen2・Azure Data Factory・Fabric・Synapse・Power BIとネイティブ連携 |
| 新機能反映 | Databricks側のリリースが最速 | Azure向けリリースノートで公開、機能によっては数週間遅れる場合あり |
Azure Databricksを選ぶ実務的な意味は、Sparkベースの分析エンジンをAzureのアイデンティティ・ネットワーク・請求・BIツールの中に閉じたまま扱える点にあります。
Azure Data FactoryからDatabricksのジョブを呼び出す、Power BIからDirect Lake経由でDeltaテーブルを直接可視化する、といった連携が最初から想定されているのも、Azureファーストパーティならではの特徴です。
Azure第一級サービスであることが実務にもたらすもの

Azureファーストパーティであることは、機能面よりも調達・運用面で効いてくる場面が多くなります。
-
Microsoft企業契約(EA/CSP)と統合されるため、稟議・調達フローが1本化できる
-
Microsoft Purviewによるカタログ・ガバナンスがDatabricksのアセットにも及ぶ
-
Azure PolicyやDefender for Cloudでコンプライアンス管理を効かせられる
-
FabricやSynapseと組み合わせる際、共通のEntra IDテナントを前提にできる
本家Databricksとの機能差自体は限定的ですが、企業のセキュリティ・調達要件を満たす目的でAzure Databricksを第一選択とする組織は多く、特に金融・製造・公共領域で顕著な傾向があります。
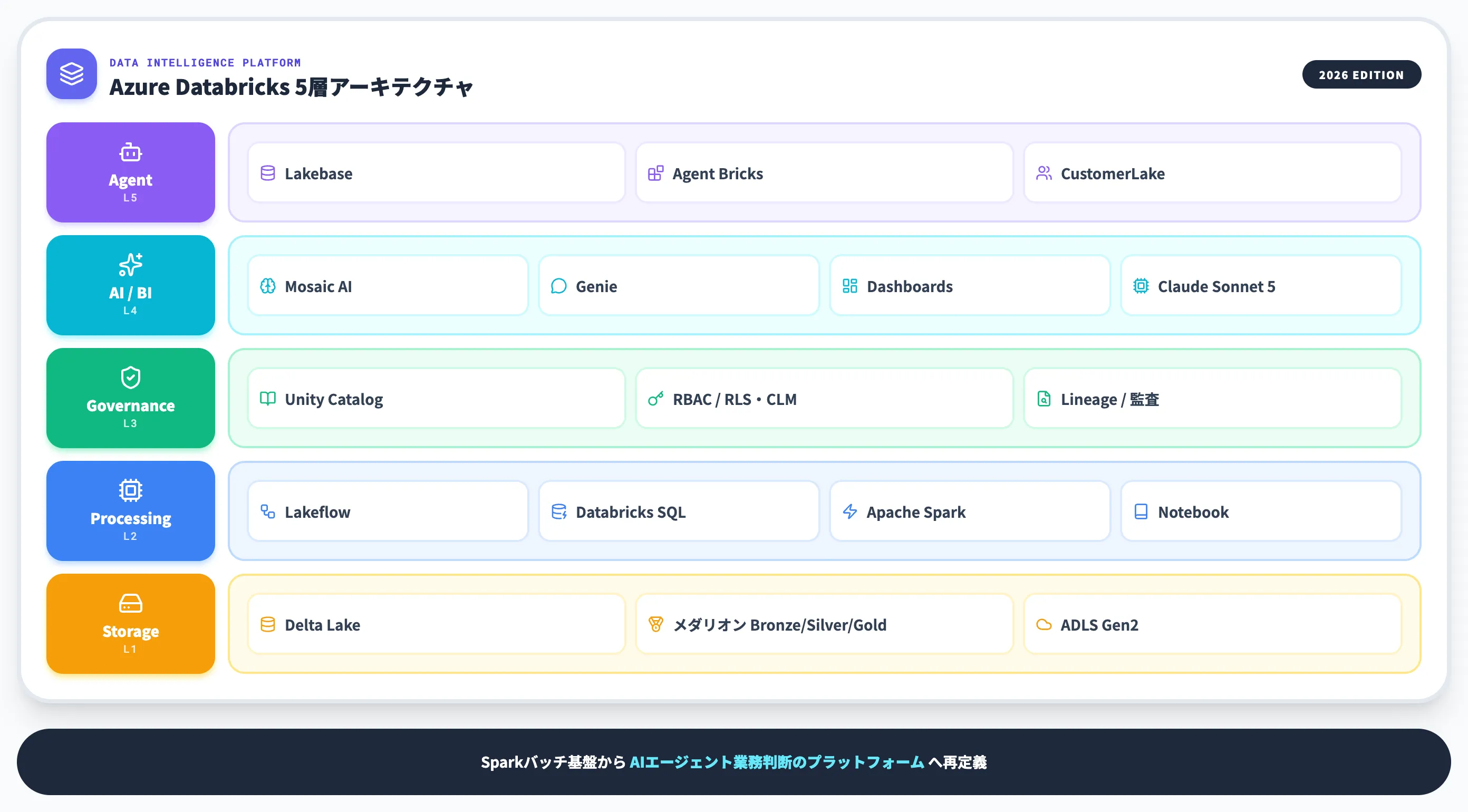
Azure Databricksの主要機能
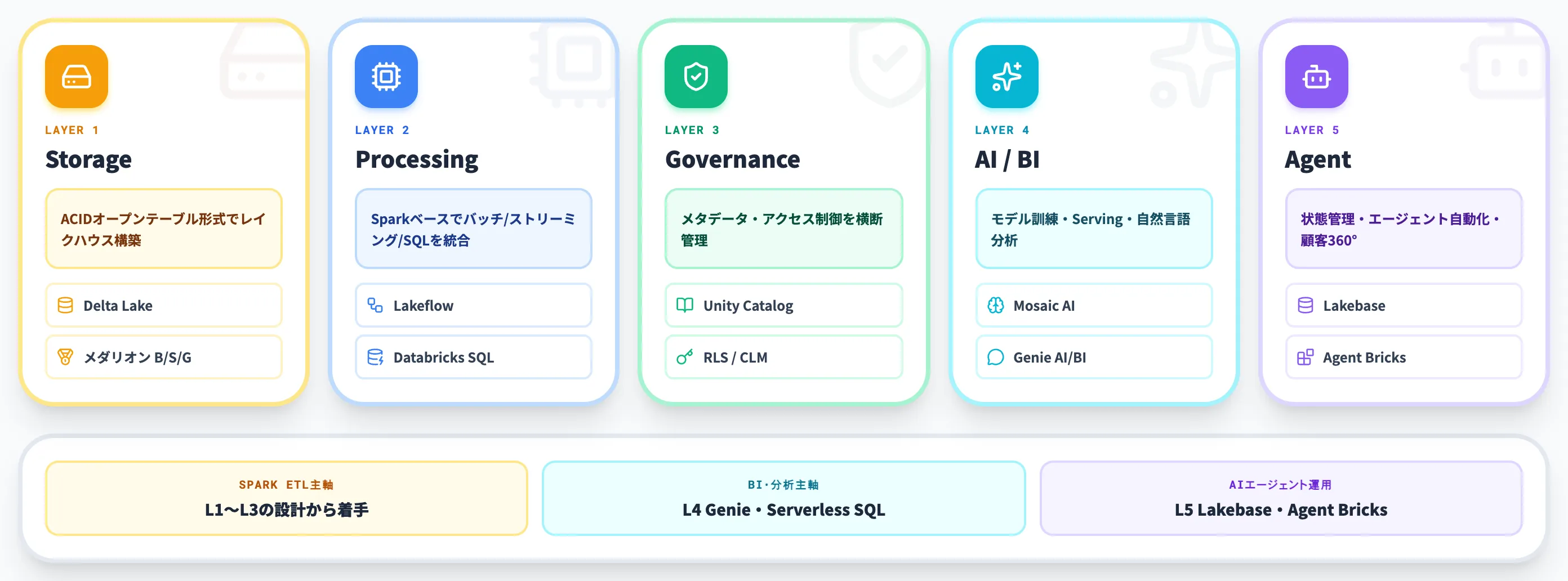
Azure DatabricksをData Intelligence Platformとして支える主要機能は、ストレージ層・処理層・ガバナンス層・AI/BI層・エージェント層の5層に整理できます。
個別機能を並べる前に、それぞれの層がどの役割を担っているかを俯瞰で押さえておくと、後段のFabric連携や料金体系の話とつながりやすくなります。
以下の表は、Azure Databricksの主要機能を層別に整理したものです。
| レイヤー | 主要機能 | 役割 |
|---|---|---|
| ストレージ | Delta Lake/メダリオンアーキテクチャ | ACID対応のオープンテーブル形式でデータレイクハウスを構築 |
| 処理 | Lakeflow(Designer/Connect/Jobs)/Databricks SQL | Sparkベースのバッチ・ストリーミング・SQL分析を統合 |
| ガバナンス | Unity Catalog | メタデータ・アクセス制御・行/列レベルセキュリティを横断管理 |
| AI/BI | Mosaic AI/Databricks AI/BI(Genie・Dashboards)/DBRX/Claude Sonnetホストモデル | モデル訓練・Serving・自然言語分析・エージェント統合 |
| エージェント | Lakebase/Agent Bricks/CustomerLake | 状態管理・エージェント自動化・顧客360°基盤 |
ここから、5層の中でも導入判断に効きやすい機能を順に掘り下げます。
Delta LakeとUnity Catalog
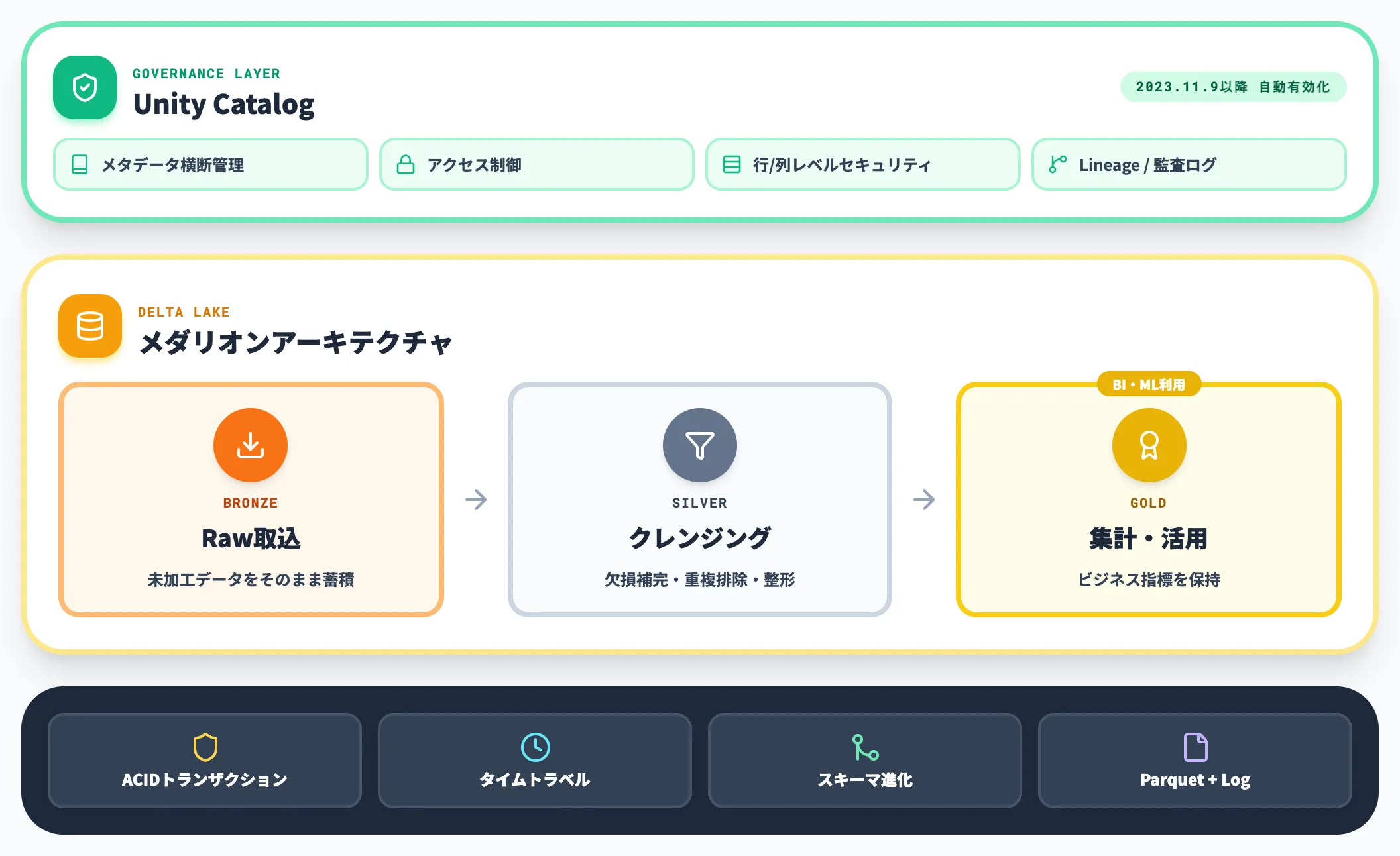
Delta Lakeは、Databricksが開発したオープンなテーブル形式で、Parquetファイルにトランザクションログを付与することでACID特性・タイムトラベル・スキーマ進化を実現します。
Azure Databricksの標準ストレージ層として位置づけられ、メダリオンアーキテクチャ(Bronze/Silver/Gold)でのレイクハウス構築が基本パターンです。
Unity Catalogは、ワークスペースをまたいだメタデータ管理・アクセス制御を提供するガバナンス層で、Azure Databricksでは2023年11月9日以降に作成されたワークスペースで自動的に有効化されます(Microsoft Learn)。
それ以前に作成された既存ワークスペースはアップグレード手順が別途必要です。
Fabric連携や後述のGenie for M365 Copilotなど、直近アップデートの大半はUnity Catalogが整備されていることを前提に設計されているため、実務上は「Unity Catalogを最初に有効化する」が導入時の必修事項になります。
Lakeflow——2026年のデータエンジニアリング主軸
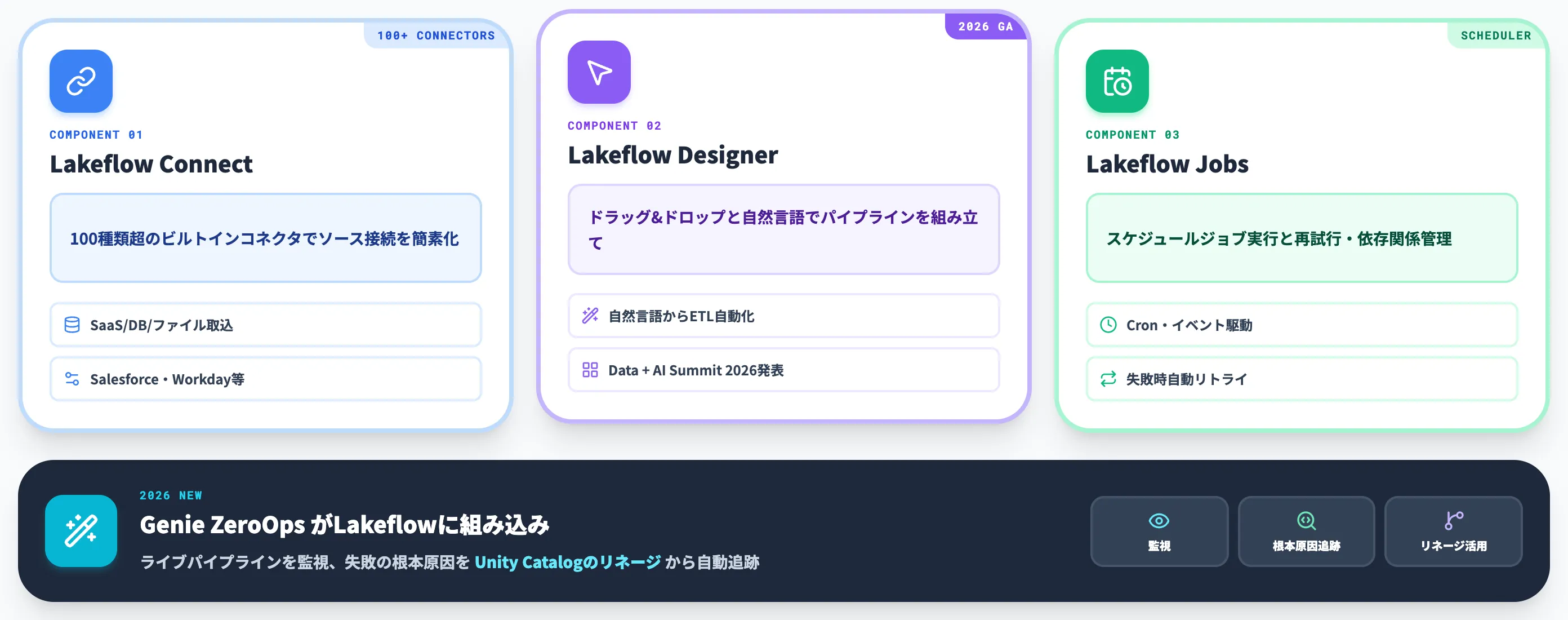
Lakeflowは、Databricksが2024年から段階的にリリースしているデータエンジニアリングの統合プロダクトで、コネクタ管理のLakeflow Connect、パイプライン構築のLakeflow Pipelines、ジョブ実行のLakeflow Jobsで構成されます。
Data + AI Summit 2026では、ドラッグ&ドロップと自然言語でパイプラインを組み立てられるLakeflow DesignerがGA、Lakeflow Connectのビルトインコネクタが100種類を超えたことが発表されました。
さらに、Genie ZeroOpsがLakeflowに組み込まれ、ライブパイプラインを監視して失敗の根本原因をUnity Catalogのリネージから追跡する自動運用も動き始めています(Databricks Blog)。
Mosaic AIとDatabricks AI/BI
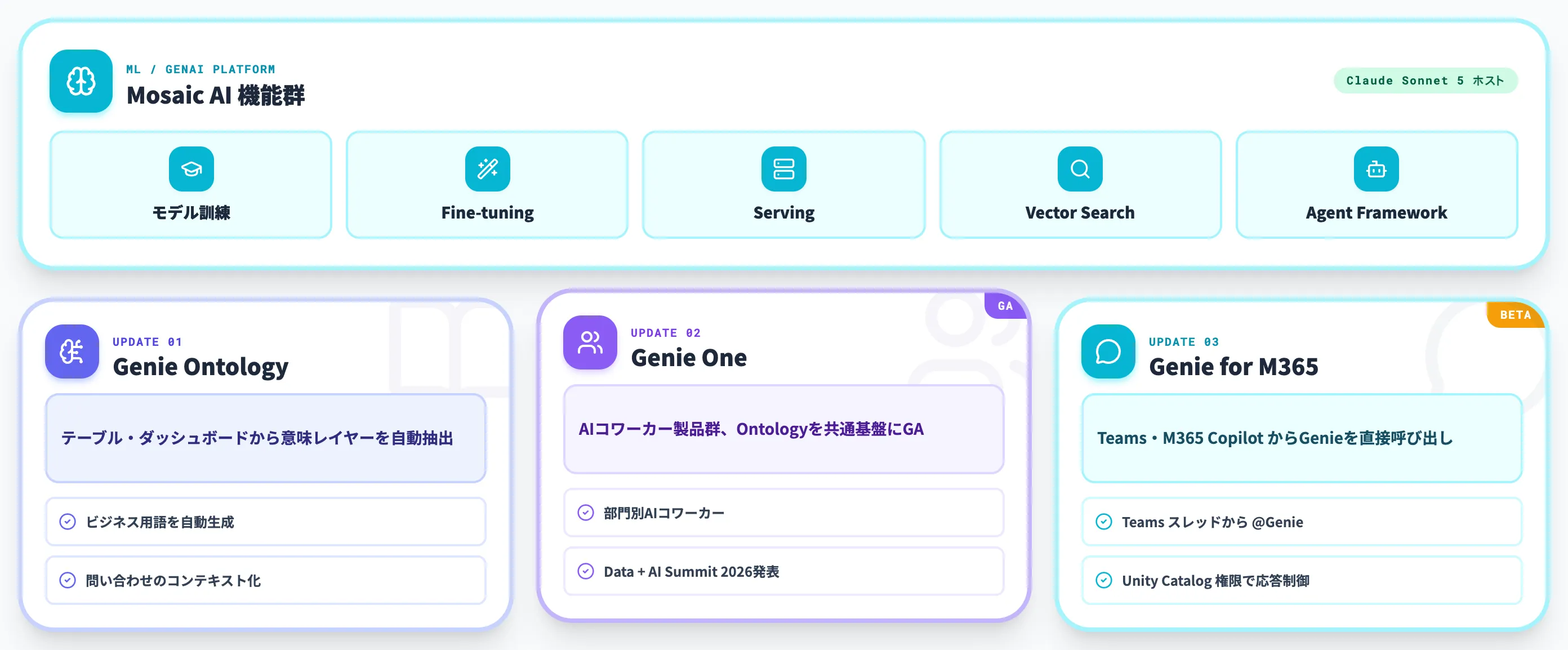
Mosaic AIは、Azure Databricks上でのモデル訓練・Fine-tuning・Serving・Vector Search・Agent Frameworkを提供する機械学習/生成AIプラットフォームです。
2026年6月にはAnthropicのClaude Sonnet 5がDatabricksホストモデルとして提供され、Azure Databricks内のUnity Catalog権限下でSonnet 5を呼び出せるようになりました。
Databricks AI/BIのGenieは、自然言語でDeltaテーブルに問い合わせてダッシュボードを組み立てる機能で、2026年の主要アップデートは以下の3つに整理できます。Genie Ontology(テーブル・ダッシュボード・パイプラインから自動抽出される意味レイヤー)と、それを基盤とするAIコワーカー製品「Genie One」がGAし、加えて Genie for Microsoft Teams & M365 Copilot 連携がBeta提供されています(Databricks Blog)。
LakebaseとAgent Bricks——エージェント時代の追加要素

Lakebaseは、Databricksのプラットフォーム上で稼働するサーバーレスPostgresで、AIエージェントの状態・メモリ・チャットセッション・設定情報を保持するトランザクショナルなバックエンドとして設計されています。
Delta/Iceberg形式で書き込みから解析までを同じストレージ層で扱う「LTAP(Lake Transactional/Analytical Processing)」の中核として、従来ETLで繋いでいた業務系DBと分析系レイクの分断を解消する構想が示されています(Databricks Lakebase)。
Agent Bricksは、Databricks上でエージェントを設計・デプロイ・監視するためのローコードなフレームワークで、Unity Catalogとの統合により権限管理と監査ログを自動的に得られます。
Azure Databricksが「AIエージェントの実行基盤」として使われる時、LakebaseとAgent BricksがGenieの受け皿として組み合わされる構成が典型的です。
Azure DatabricksとMicrosoft Fabric・OneLakeの統合
2025年から2026年にかけて最も大きく変化したのが、Azure DatabricksとMicrosoft Fabric・OneLakeの統合です。
従来はDatabricksとFabricを別々のデータ基盤として使い分けるのが一般的でしたが、Unity Catalog Mirroringが2025年7月にGAして以降、両者は「同じデータを違うUIから触る」構造へ急速に近づいています。
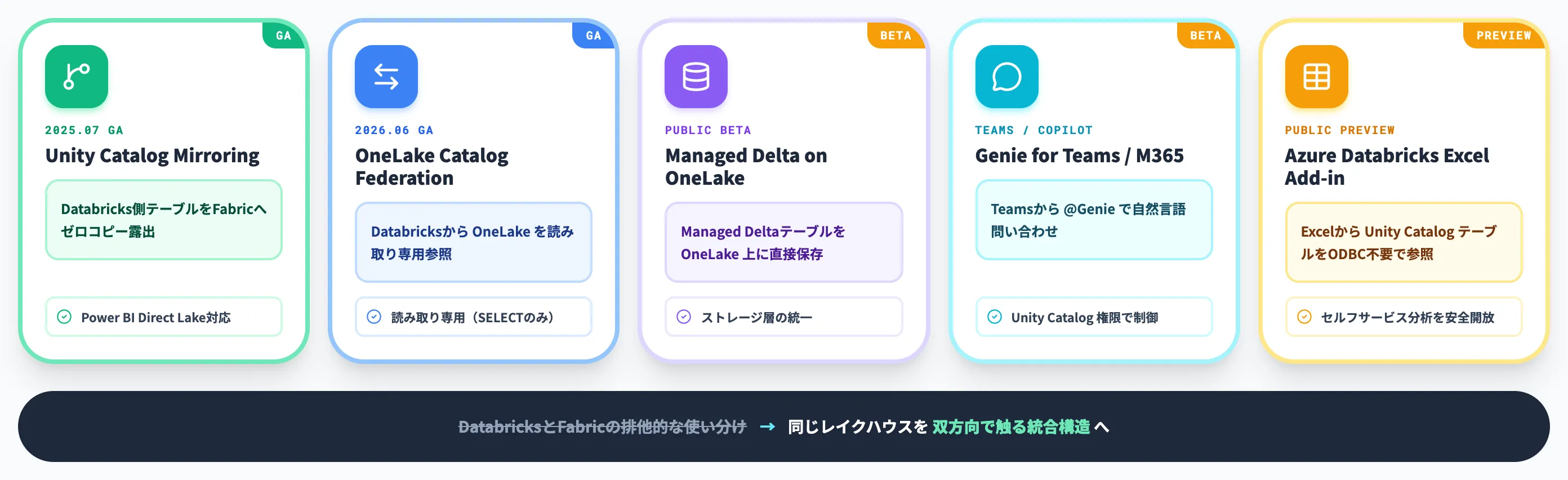
以下の表は、Azure DatabricksとFabric側の統合ポイントを2026年7月時点の提供状況別に整理したものです。
| 統合ポイント | 提供状況 | 概要 |
|---|---|---|
| Unity Catalog Mirroring | 2025年7月GA | Databricksの Unity Catalog テーブルをコピーせず Fabric に露出し、Power BI Direct Lake で分析可能 |
| OneLake Catalog Federation | 2026年6月GA(読み取り専用) | Azure Databricks から OneLake 上のデータを読み取り専用でゼロコピー参照 |
| Managed Delta on OneLake | Public Beta | Databricks の Managed Delta テーブルを OneLake 上に直接保存 |
| Genie for Microsoft Teams / M365 Copilot | Beta | Teams スレッドから Genie にメンションして自然言語でレイクハウスに問い合わせ、Unity Catalog 権限で応答制御 |
| Azure Databricks Excel Add-in | Public Preview | Excel から Unity Catalog テーブルを ODBC 設定なしで直接参照 |
この表が示すのは、DatabricksとFabricを排他的な選択肢としてではなく、同じレイクハウスを別ワークロードから触る双方向連携として設計する段階に入っている、という点です。
Unity Catalog Mirroringで Fabric から Databricks データを扱う
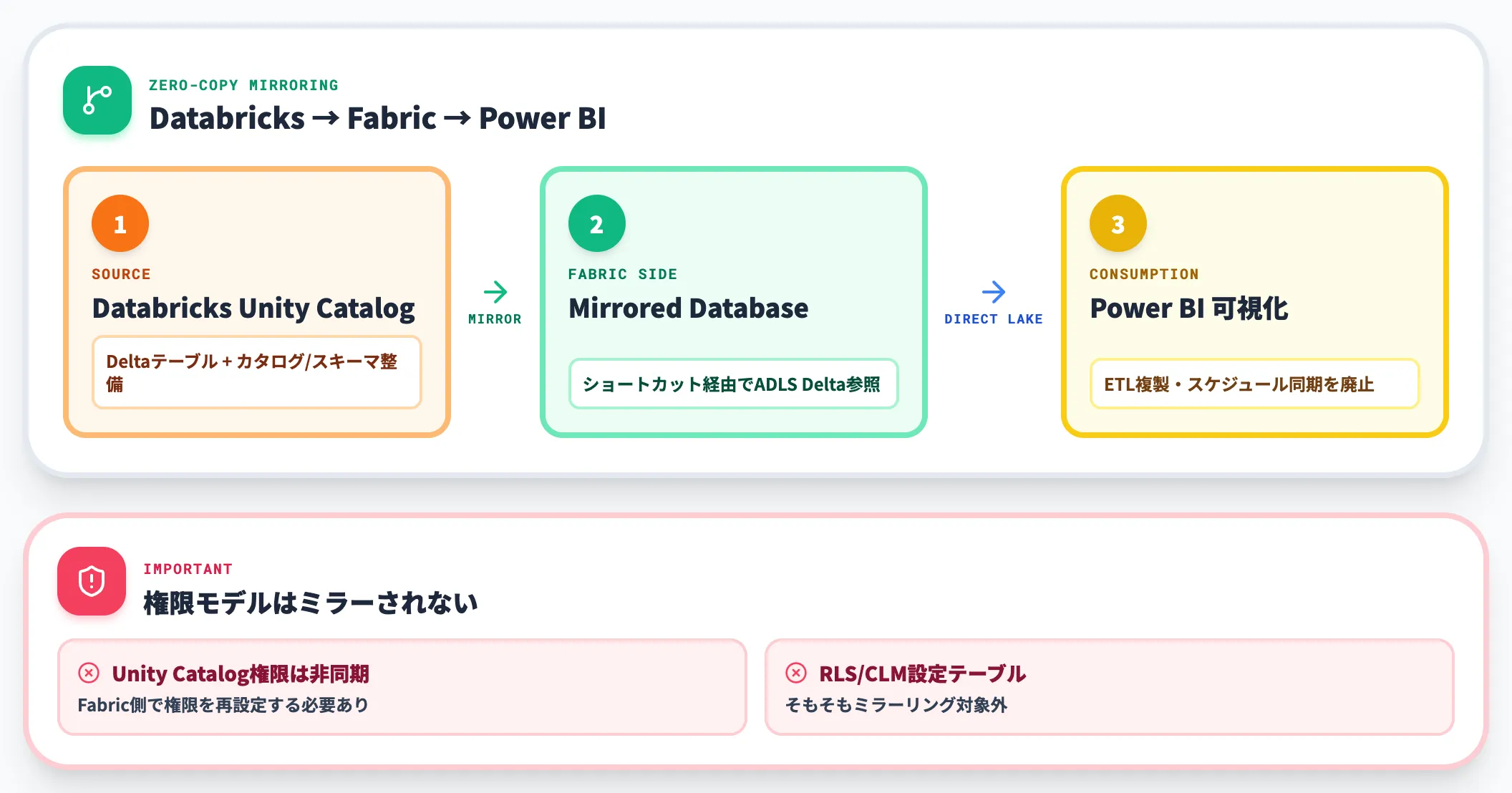
Fabric側からAzure DatabricksのUnity Catalogをミラーリングすると、Databricksのカタログ構造がFabricのMirrored Databaseとして自動同期されます。
物理的なデータコピーは発生せず、Fabric側からはショートカット経由でADLS上のDeltaテーブルに直接アクセスします。
これによってPower BIのDirect LakeモードでDatabricksテーブルを直接可視化でき、従来必要だったETL経由の複製・スケジュール同期を廃止できます。
ただし権限モデルには注意が必要です。Microsoft Learnはミラーリング時に「Unity Catalog policies and permission aren't mirrored in Fabric」と明記しており、Databricks側の権限・カタログ/スキーマ/テーブル単位のアクセス制御はFabric側にはミラーされず、Fabricの権限モデルで再設定する必要があるとされています(Microsoft Learn - Fabric mirroring security)。
加えて、Unity CatalogのRLS/CLM(行/列レベルセキュリティ)ポリシーが設定されたテーブルは、ミラーリング対象外になっている点も、機微データを扱う組織では必ず設計初期に押さえる論点です。
OneLake Catalog FederationでDatabricks側からゼロコピーアクセス
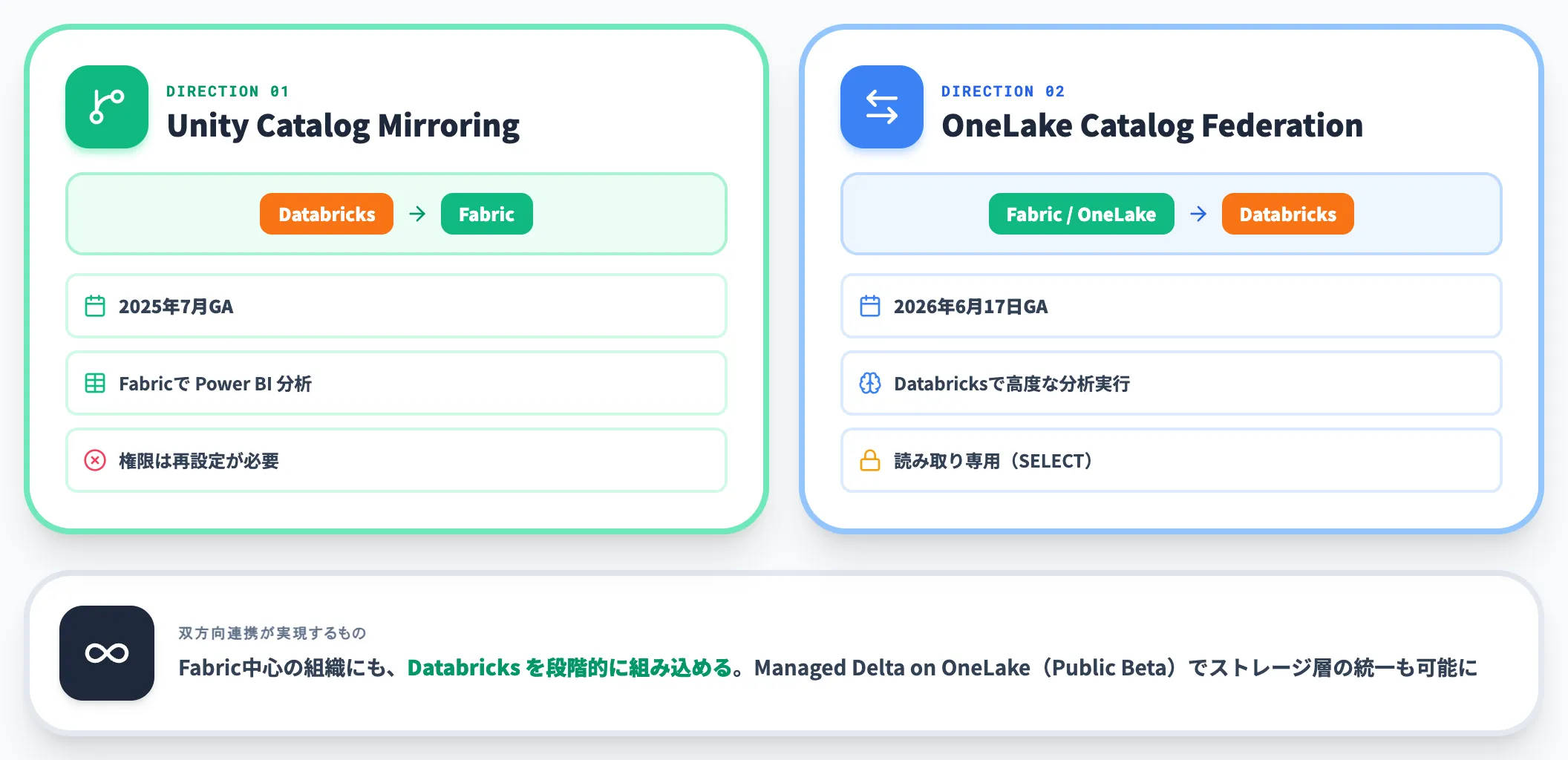
逆方向のOneLake Catalog Federationは、Azure DatabricksからOneLake上に保管されたFabricテーブル(Lakehouse・Warehouse)を、Unity Catalog経由でゼロコピー参照する機能で、2026年6月17日に一般提供(GA)となりました(Microsoft Learn)。
Fabric側で構築したSemantic Modelや、Power BIから取り込んだ業務系データを、Databricks側の高度な分析ワークロードにそのまま流し込めます。ただしアクセスは読み取り専用(SELECTクエリのみ)で、DatabricksからOneLakeへの書き込みはサポートされない点は設計時に押さえる必要があります。
さらに Managed Delta on OneLakeが Public Beta で提供され、Databricksが管理するテーブル自体を最初からOneLake上に置く選択肢も生まれました。
これは「Fabric中心の組織にDatabricksを段階的に組み込む」ときに、ストレージ層を統一しやすくする重要な布石です。
Genie for M365 CopilotとExcel Add-in

Genie for Microsoft Teams / M365 CopilotはBetaで提供中の統合機能で、Teamsのスレッドに 「@Genie」 の形で問い合わせると、Unity Catalog権限内のDatabricksテーブルを参照して自然言語で回答します。
回答内容はUnity Catalogに登録されたビジネス用語やGenie Ontology(オントロジーの自動生成レイヤー)を経由してコンテキスト化されるため、単なる検索応答ではなく業務文脈に沿った答えになります。
Microsoft IQ(Work IQ・Fabric IQ・Foundry IQ・Web IQ)の議論とも接続する重要な変化で、M365 Copilotが企業データにアクセスする経路のひとつがDatabricksになったと捉えると位置づけが分かりやすくなります。
Excel Add-inはPublic Previewで、Excelから直接Unity Catalogテーブルをクエリしピボット分析できます。個別ユーザーのODBC設定が不要になり、経理・営業部門でのセルフサービス分析を安全に開放する用途で使われ始めています。
【関連記事】
Fabric IQ オントロジーとは?仕組み・使い方・料金を解説

Azure Databricksの料金体系
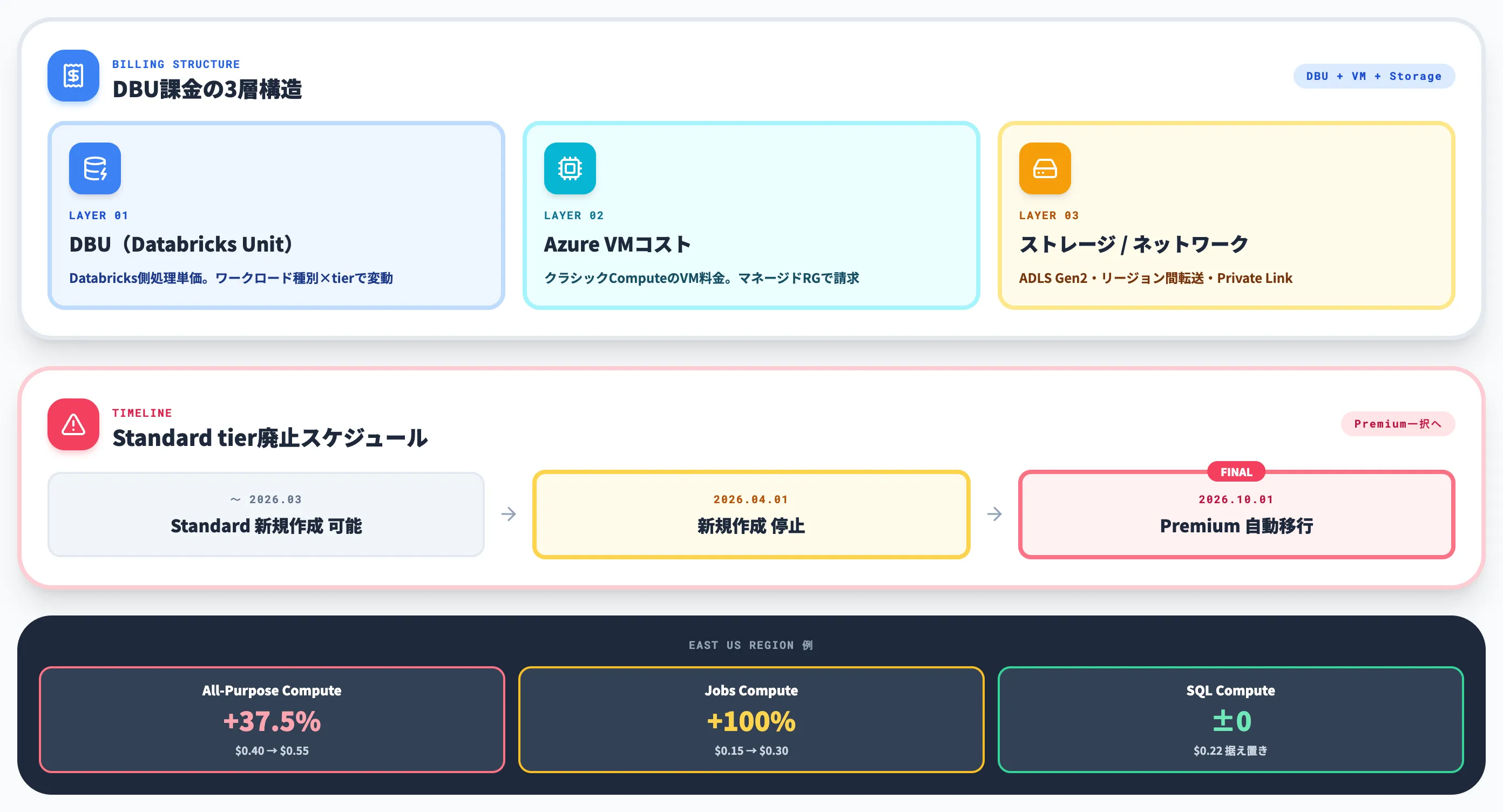
Azure Databricksの料金は、DBU(Databricks Unit)・Azure VMコスト・ストレージ/ネットワークコストの3層で決まります。
2026年前半の最大トピックは、2026年4月1日以降Standard tierの新規ワークスペース作成が停止され、2026年10月1日にStandard tierが完全廃止されて既存ワークスペースがすべてPremiumに自動アップグレードされる点です(Databricks Community)。
DBU課金の3層構造
Azure Databricksの請求書は、大きく3つのコンポーネントに分かれます。
-
DBU(Databricks Unit)
Databricks側の処理単価。ワークロード種別(All-Purpose/Jobs/SQL/Serverless)×tier(Premium)で単価が変わる
-
Azure VMコスト
クラシックコンピュートで使うVMの利用料。マネージドリソースグループでAzure側から請求される
-
ストレージ/ネットワーク
ADLS Gen2でのデータ保管、リージョン間データ転送、Private Link料金など
Serverless系のSKU(Serverless SQL Warehouse・Model Serving等)ではVM費用がDBU単価に含まれ、請求経路が1本化されます。従量課金の複雑さを減らしたいチームで採用が広がっている構成です。
SKU別の従量DBU単価の目安
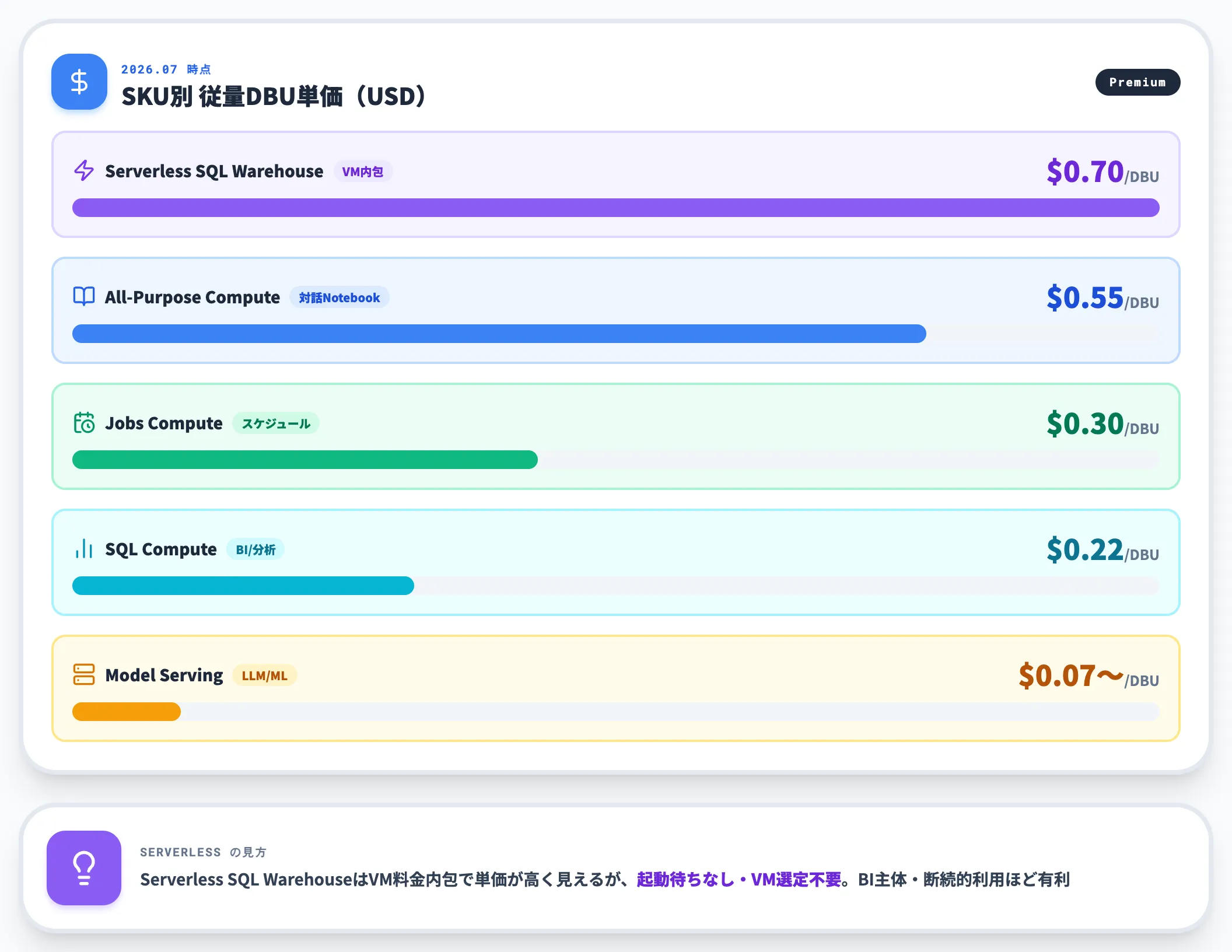
以下は、2026年7月時点で公開されている代表的なSKUのDBU単価目安です。
| SKU | 概要 | 目安DBU単価(USD) |
|---|---|---|
| All-Purpose Compute(Premium) | 対話的ノートブック実行 | $0.55/DBU |
| Jobs Compute(Premium) | スケジュールジョブ実行 | $0.30/DBU |
| SQL Compute(Premium) | Databricks SQLでのBI/分析 | $0.22/DBU |
| Serverless SQL Warehouse | サーバーレスSQL(VM料金内包) | $0.70/DBU |
| Model Serving | LLM/MLモデルサービング | $0.07/DBU〜(規模による) |
Serverless SQL WarehouseはVM料金を内包している分DBU単価が高く見えますが、クラシックコンピュートの起動待ちが不要でVM選定も不要という運用軽量化の利点があります。
BI主体・断続的利用のワークロードほどServerlessが有利になりやすいのが一般的傾向です。
2026年10月Standard tier廃止のインパクト
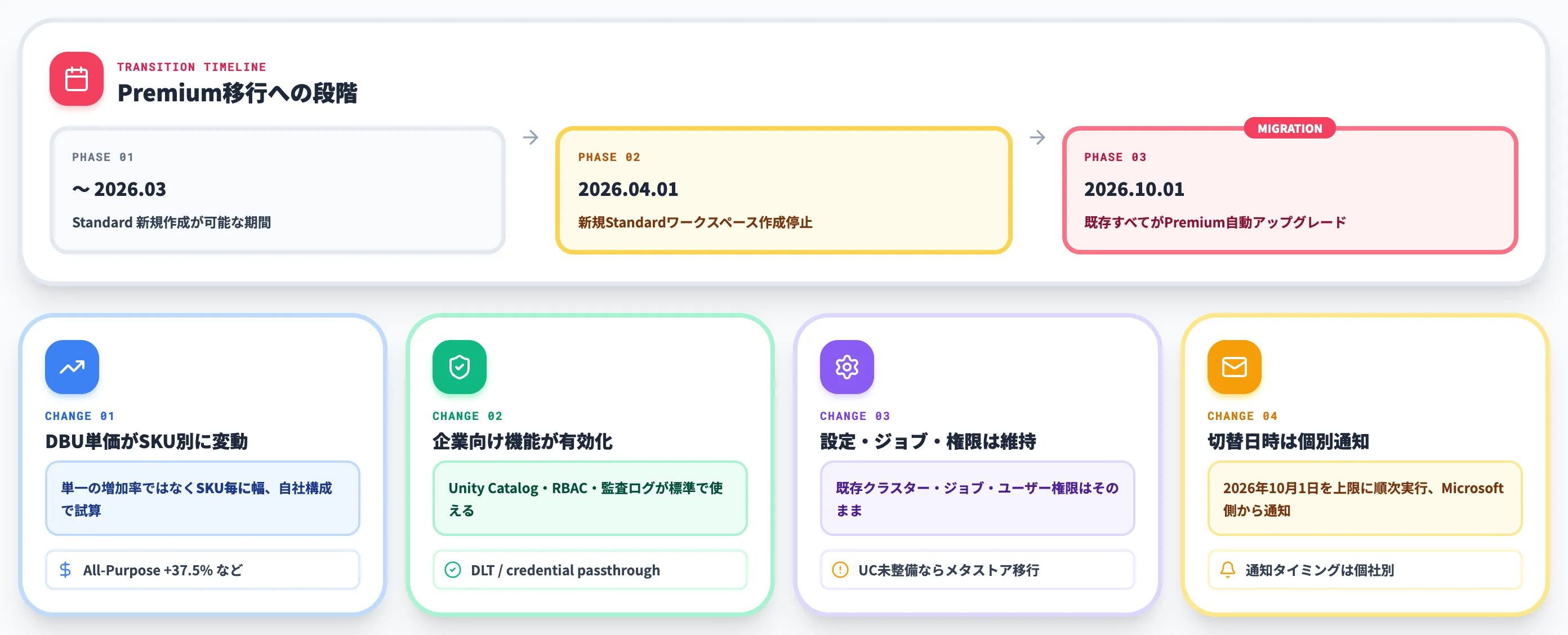
Standard tierには、Unity CatalogやRBAC(ロールベースアクセス制御)、Delta Live Tables、監査ログといった企業向け機能が含まれていませんでした。
Premiumへの自動アップグレードでは、Standard tierに残されていたワークスペースは以下の変化を受けます。
-
DBU単価がSKU別にPremium水準へ切り替わる。単一の増加率ではなくSKUで幅がある点が重要で、Azure Retail Prices APIで確認できる East USリージョン例では、All-Purpose Computeが$0.40→$0.55(+37.5%)、Jobs Computeが$0.15→$0.30(+100%)、SQL Computeは$0.22据え置き。実際の増減は自社のSKU構成・リージョン・契約で試算する
-
Unity Catalog・RBAC・監査ログ・Delta Live Tables・credential passthroughが有効化される
-
既存のクラスター設定・ジョブ・ユーザー権限はそのまま維持されるが、Unity Catalog未整備の場合はメタストア移行の実務が別途発生する
-
移行実施日は2026年10月1日を上限に順次実行、切替日時はMicrosoft側から個別に通知される
実務としては、2026年4月以降に新規Standard作成ができなくなる時点で、既に「PremiumがAzure Databricksのデフォルト形態」に切り替わっていると考えるのが妥当です。
計画的にPremiumへ移行し、Unity Catalog整備と権限設計を先に済ませておくことで、Fabric連携やGenie for M365 Copilotなどの新機能にもそのまま接続できます。
Committed Use(DBCU)による割引

Databricks Commit Units(DBCU)は1年または3年で事前購入するコミットメントで、Azure Databricks・Databricks本家共通の割引プログラムです。
コミット規模と期間に応じて、従量DBU単価と比較して最大37%程度の割引が提示されます。
年間で継続的なワークロードが確定している場合、Serverless系SKUを従量で使うより、DBCUを組み合わせてCommittedにする方が実効単価が下がります。ただしコミット未消化分は失効するため、Premium移行後の消費量見通しを1〜2四半期分は実測してから購入規模を決めるのが安全です。
Azure Databricksの使い方(Workspace作成〜Notebook実行)
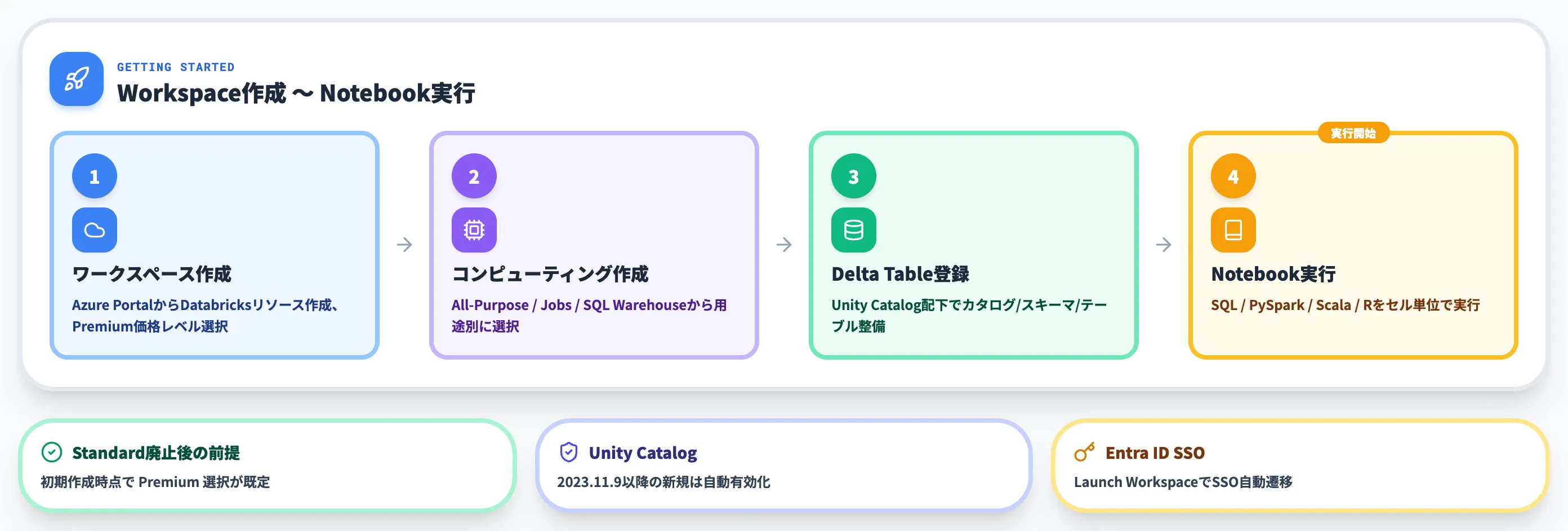
Azure Databricksを実務で使い始める場合は、Azure Portalからのワークスペース作成 → コンピューティング作成 → Delta テーブルの登録 → Notebook 実行、の順で進めるのが基本フローです。
Standard tier廃止後の2026年後半以降は、初期作成時点でPremiumが選択されることを前提に手順を進めます。
前提条件と権限
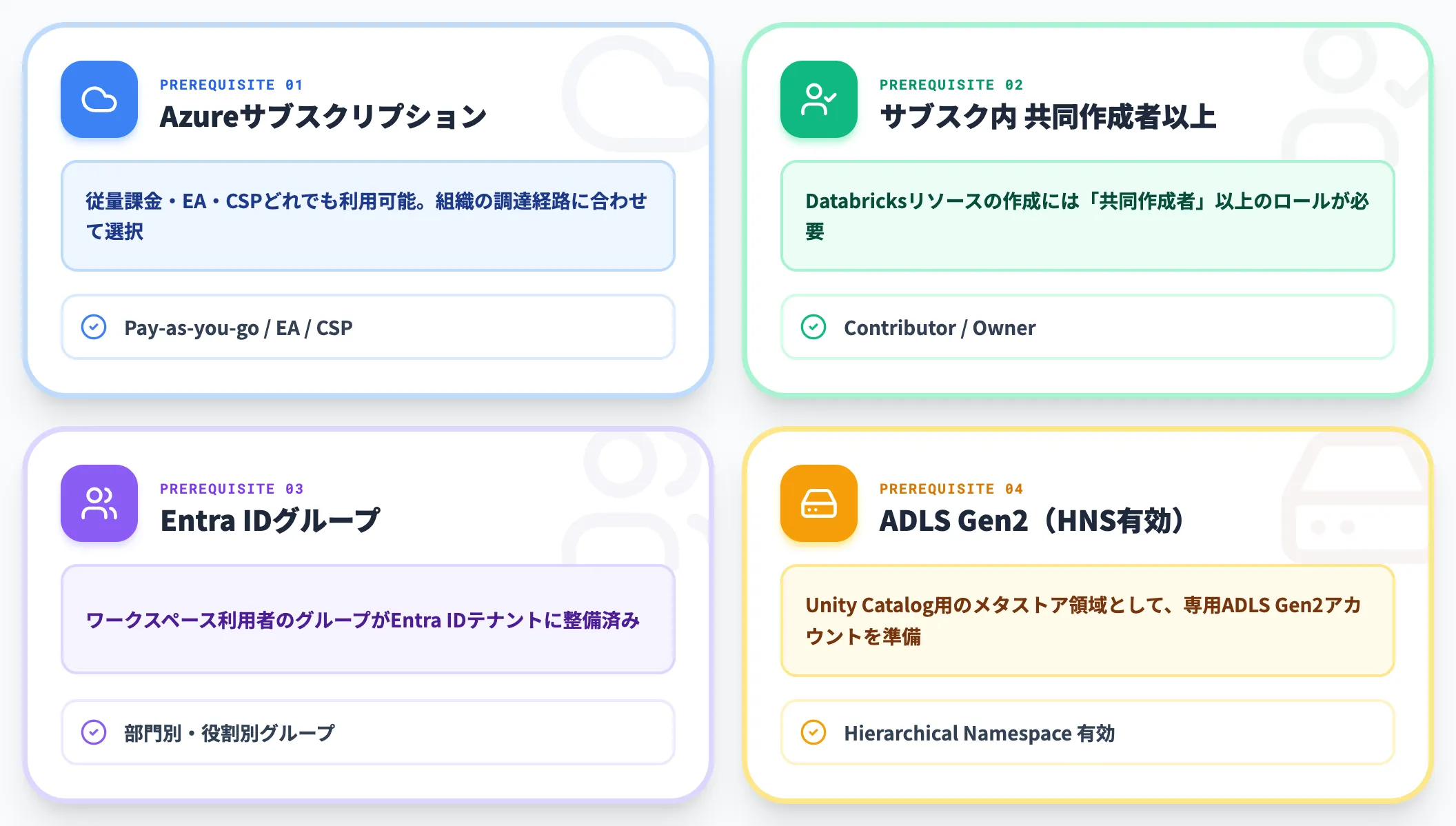
セットアップに入る前に、以下を用意しておきます。
-
Azureサブスクリプション(従量課金・EA・CSPいずれも可)
-
サブスクリプション内での「共同作成者」以上のロール
-
Microsoft Entra IDテナントで、ワークスペース利用者のグループが整備されていること
-
Unity Catalogを使うためのメタストア領域として、専用のADLS Gen2アカウント(HNS有効)
Unity Catalogは2023年11月9日以降に作成されたワークスペースでは自動的に有効化されるため、新規作成時に別途プロビジョニングは不要です。
それ以前に作成された既存ワークスペースは、Microsoft Learnのアップグレードガイドに沿ってメタストア接続と権限を手動で設定する必要があります。
ワークスペースの作成
Azure Portalの検索ボックスで「Azure Databricks」を選択し、「作成」を押します。
作成フォームで指定する主要な項目は次のとおりです。
-
リソースグループ/ワークスペース名/リージョン
既存のAzureリソースと同一リージョンに配置するのがネットワーク費用の観点で有利
-
価格レベル
現行はPremium一択(Standardは2026年4月以降新規作成不可)
-
VNet統合
既存のAzure VNetに配置する「VNet Injection」を選ぶと、社内ネットワーク・ExpressRouteとの接続が可能
作成完了後、Azure Databricks上の「Launch Workspace」ボタンを押すとMicrosoft Entra ID経由でシングルサインオンし、Databricksのポータル画面に遷移します。
コンピューティングの作成
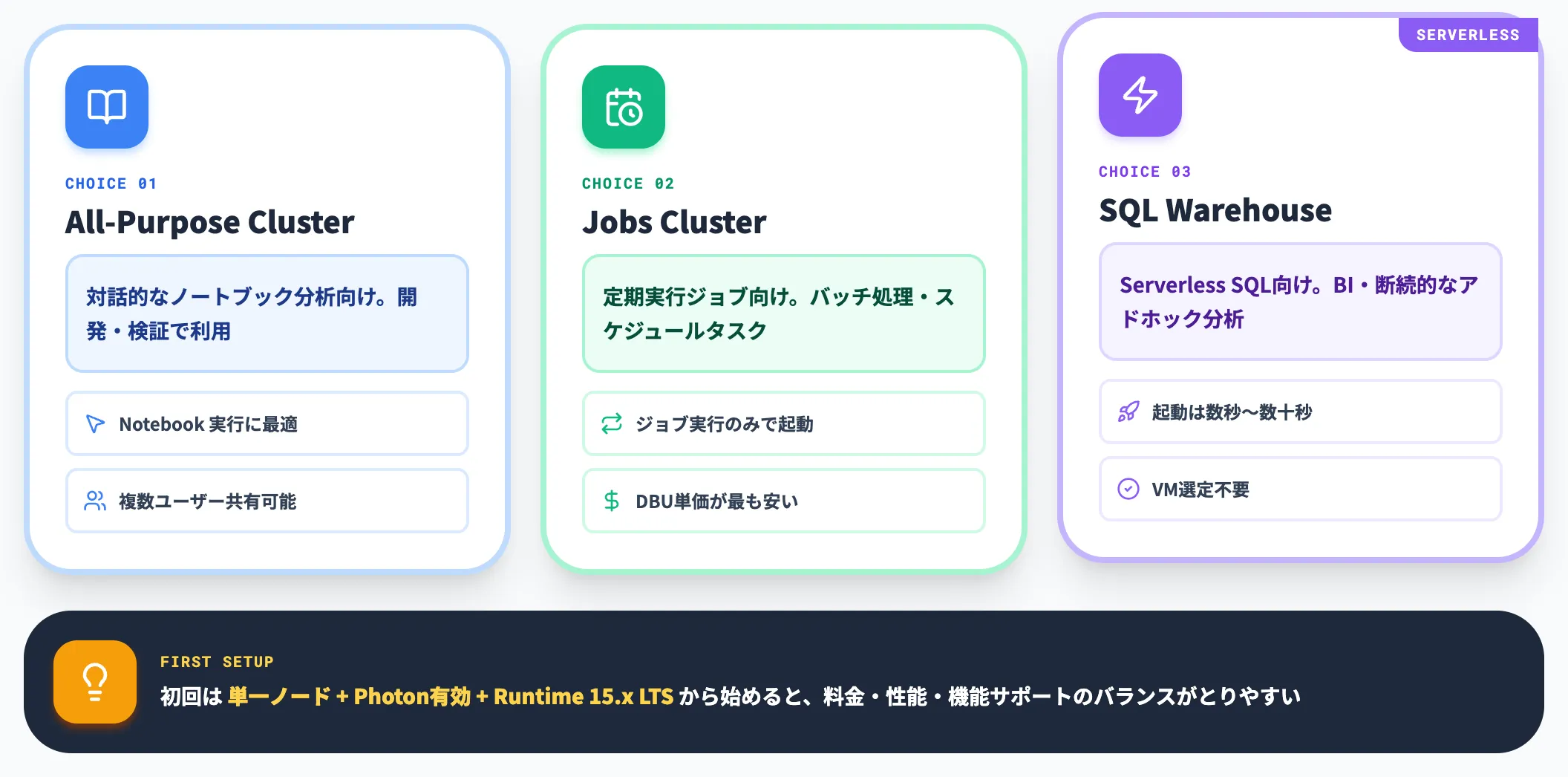
Databricksポータル左メニューの「Compute」から新規クラスターを作成します。
対話的な分析向けにはAll-Purpose Cluster、定期実行のジョブにはJobs Cluster、Serverless SQL用にはSQL Warehouseを使い分けます。
初回はテスト用に単一ノード・Photon有効・Runtime 15.x LTS程度から始めると、料金・パフォーマンス・機能サポートのバランスがとりやすい構成になります。
Serverless SQL WarehouseはVM選定が不要で、起動時間も数秒〜数十秒と短いため、BIワークロードや不定期の分析にはServerless優先が扱いやすい選択肢です。
Delta Tableの登録
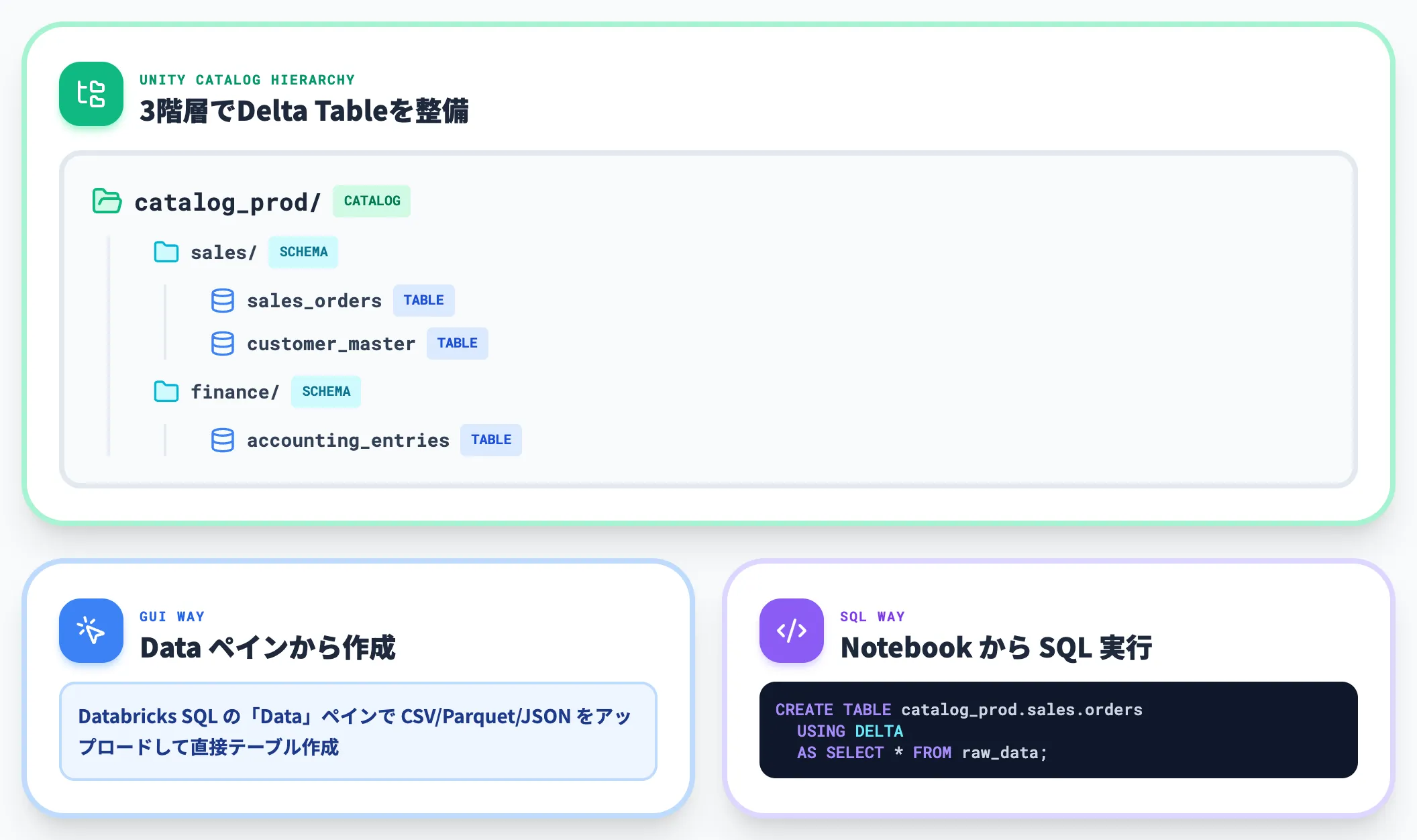
Unity Catalog配下でカタログ→スキーマ→テーブルの階層を作り、CSV/Parquet/JSONなどからDelta Tableに変換して登録します。
Databricks SQLの「Data」ペインからGUIでもテーブル作成できますし、NotebookからSpark SQLで CREATE TABLE ... USING DELTA を書いても同じ結果になります。
登録済みDelta Tableは、Unity Catalog上でカタログ/スキーマ/テーブルを整理しておくと、後段のFabric側でミラー対象を選定しやすくなり、Genie for M365 Copilotなどの入口としてもそのまま活かせます(Fabric側の権限は別途 Fabric の権限モデルで再設計します)。
NotebookでSQL / PySparkを実行
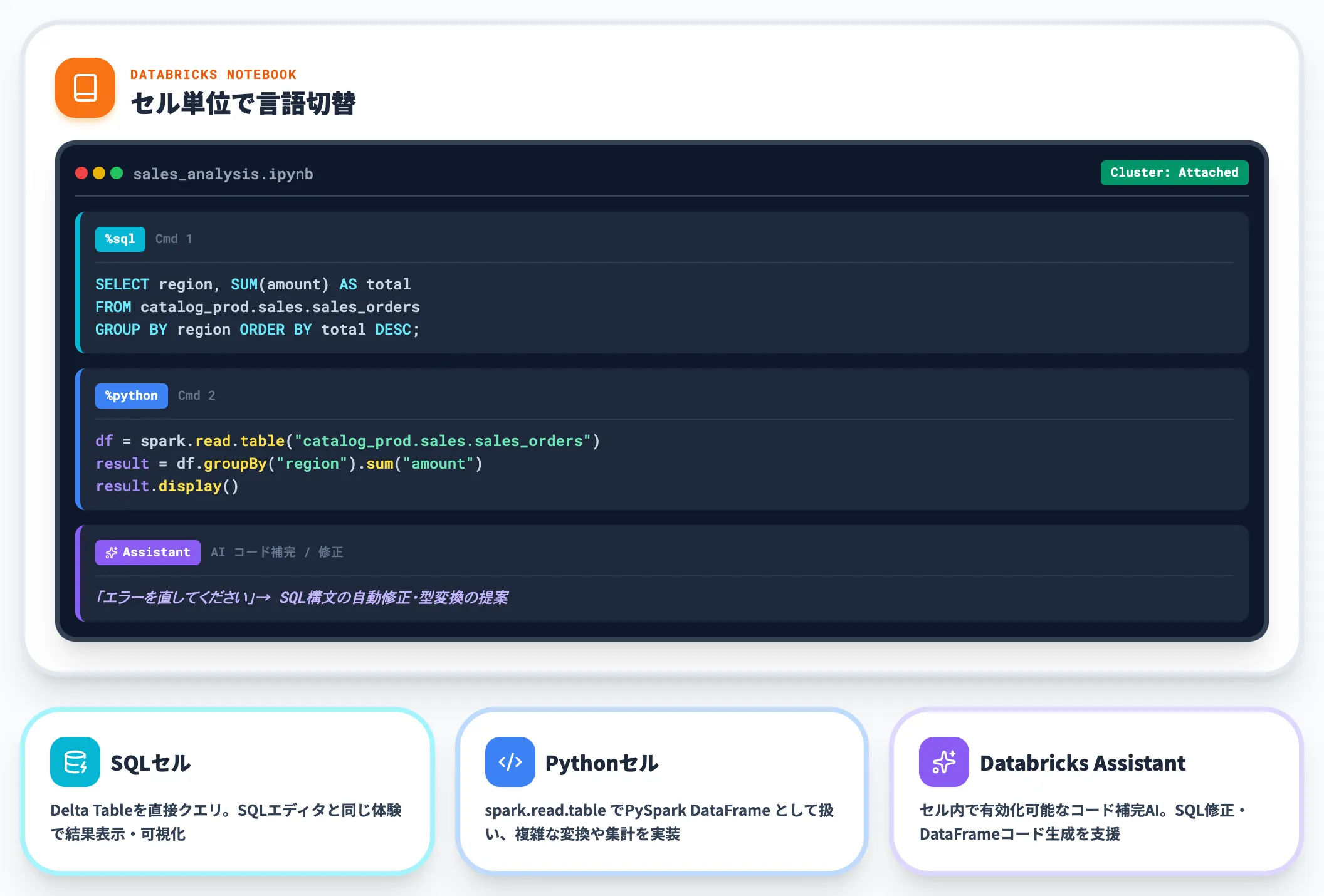
Databricks Notebookは、SQL・Python(PySpark)・Scala・Rを同一ノートブック内でセル単位に切り替えて実行できます。
-
SQLセルでDelta Tableを直接クエリし、DatabricksのSQLエディタと同じ体験で結果と可視化を得る
-
Pythonセルで
spark.read.table("catalog.schema.table")を使いPySpark DataFrameとして扱う
-
Databricks Assistant(コード補完AI)がセル内で有効化でき、SQL構文修正やDataFrameコード生成を支援する
ここまでで、Azure Databricksの「データ取り込み→登録→分析」の一巡が可能になります。
Fabric側から可視化したい場合は、この時点でUnity Catalog上のカタログ/スキーマ/テーブル構造とミラー対象を整理してから Mirrored Database の設定に進むと、Fabric側の権限再設計とミラー対象選定のトラブルが起きにくくなります。
Azure DatabricksとFabric・Synapse・Snowflakeの使い分け

Azureでデータ+AI基盤を選ぶ際、Azure Databricksと並んで検討対象になるのはMicrosoft Fabric・Azure Synapse Analytics・Snowflakeの3つです。
それぞれ得意領域が異なるため、目的と体制に応じてケース別に組み合わせを決めるのが実務的な進め方になります。
以下の表で、4プラットフォームの特徴を整理しました。
| プラットフォーム | 強み | 弱み |
|---|---|---|
| Azure Databricks | Sparkベースの大規模データエンジニアリング、Mosaic AI、Delta Lakeの成熟度 | Power BI直結の即時運用はFabricに一日の長 |
| Microsoft Fabric | OneLakeでのゼロコピー統合、Power BI・M365との近さ、Copilotの標準統合 | 大規模MLOpsや独自モデル訓練はDatabricksに寄せることが多い |
| Azure Synapse Analytics | 既存のDedicated SQL Pool資産、Data Factory統合の歴史的積み上げ | 新機能はFabricへ移り、長期的にはFabric移行の検討が推奨される |
| Snowflake | マルチクラウド運用、SQLの成熟度、Snowpark ML | Microsoft Azureとの統合深度はDatabricks/Fabricに劣る |
各プラットフォームは競合というより、企業の主軸ワークロードによって最適解が変わる補完関係にあります。
ケース別のSIer推奨

AI総研で支援先を見てきた経験からは、以下のケース分けが実務判断の起点になります。
-
Sparkベースの大規模ETL/MLパイプラインが主軸
Azure Databricksが第一候補。データエンジニア人材が確保できるならDatabricks中心で組み、Fabricは可視化窓口として最小限利用
-
Power BI・M365中心でデータエンジニア人材が薄い
Fabricを主基盤にし、ML/大規模ETLで必要な部分だけDatabricksをUnity Catalog Mirroringで噛ませる二層構成が扱いやすい
-
マルチクラウドで単一SQLエンジンを共通化したい
Snowflakeを検討軸に入れ、Azure内の連携はDatabricksよりFabric側から張るケースが多い
-
既存Synapse資産(Dedicated SQL Pool)がある
Fabricへの段階的移行を計画しつつ、当面はSynapse Dedicated Poolを維持しつつFabric側でLakehouse/Warehouseを増設する構成が一般的
AIエージェント時代のデータ基盤設計の議論と併せて考えると、「エージェントに渡す業務データはFabric中心、モデル訓練とバッチETLはDatabricks中心」という役割分担が、Microsoftエコシステム内では標準形になりつつあります。
Azure Databricks導入で見落とされやすい3つの落とし穴
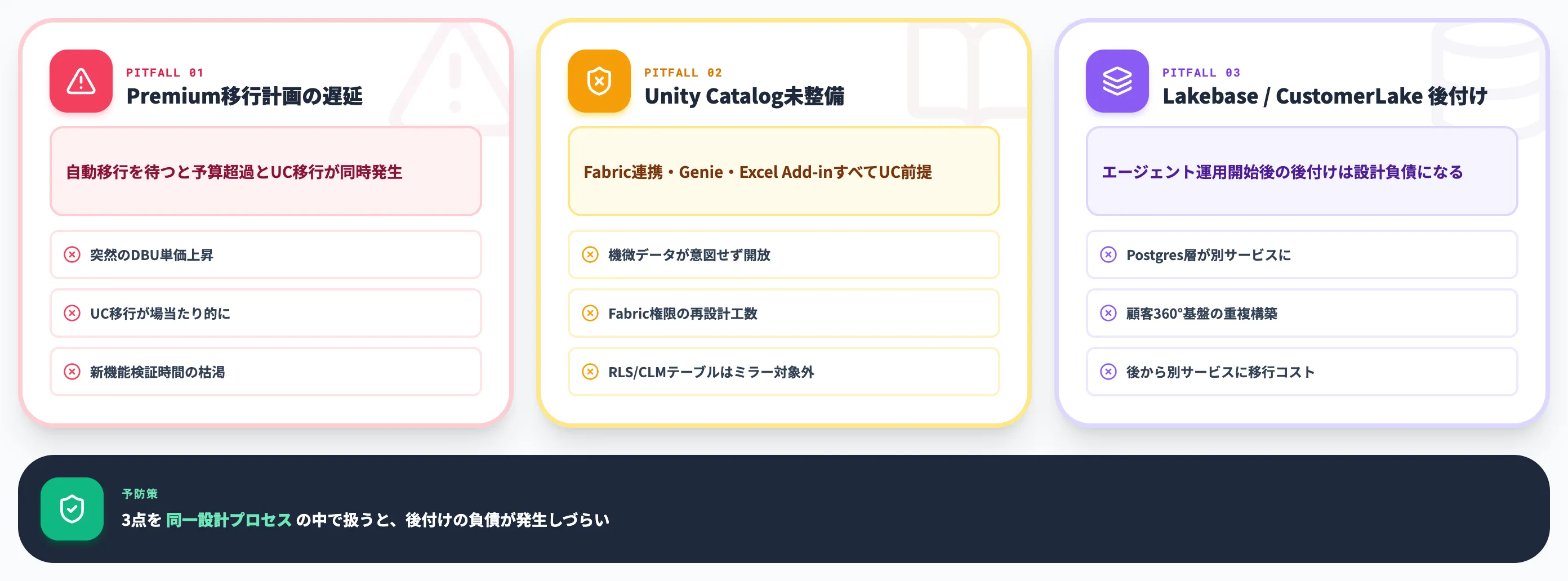
Azure Databricksの導入検討で最終決裁の前後によく詰まる論点を、3つに絞って整理します。
Standard→Premium移行計画の遅延
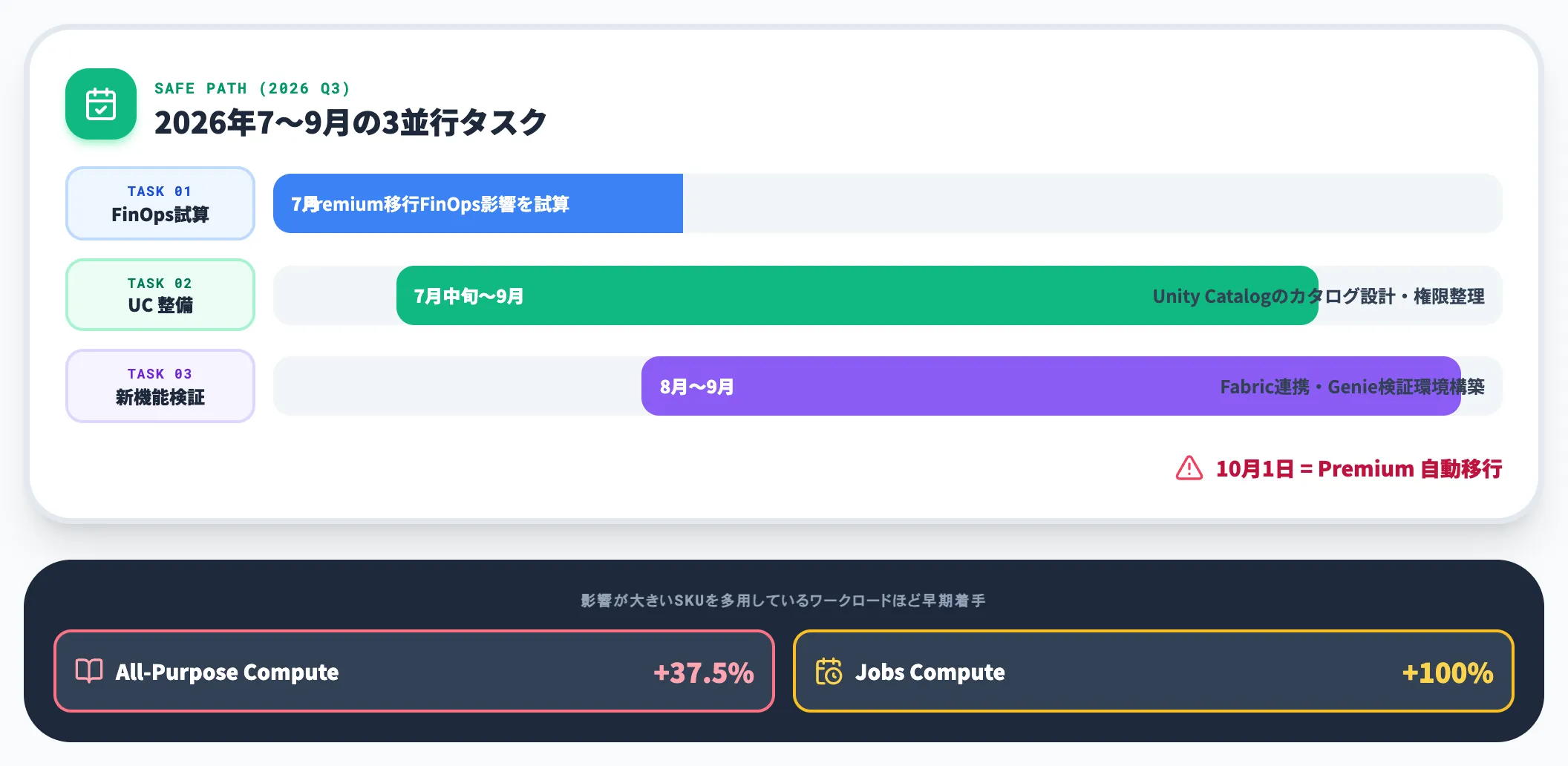
2026年10月1日のStandard tier廃止は既に決定事項で、放置していてもMicrosoft側が自動的にPremium移行を実行します。
問題は「自動移行の日を待つ」設計を選ぶと、以下の実務コストが同時期に発生する点です。
-
突然のDBU単価上昇による予算超過(East US例のAll-Purpose +37.5%・Jobs +100%を多用しているワークロードほど影響が大きい)
-
Unity Catalog移行の実装期間が確保できず、権限設計が場当たり的になる
-
Fabric連携やGenie for M365 Copilotなど、Premium前提の新機能を試す時間がなくなる
実務的には、2026年7〜9月のうちに(1)Premium移行のFinOps影響を試算、(2)Unity Catalog整備、(3)新機能の検証環境構築、を並列で走らせるのが安全な進め方です。
Unity Catalog未整備でFabric連携が回らない
Unity Catalog Mirroring・Genie for M365 Copilot・Excel Add-inなど直近アップデートの大半は、Unity Catalogが業務データ範囲で整備されていることが前提です。
また前述のとおり、Unity Catalogのアクセス権限とRLS/CLMポリシーはFabric側にミラーされず、RLS/CLMポリシーが設定されたテーブルはそもそもミラー対象外です。未整備のまま「とりあえずFabricでミラーしてみる」を進めると、機微データが意図せず開いてしまう、Fabric側で権限を再設計する工数が別途発生する、といった事故が起きやすくなります。
AI-ready dataの議論で扱われる意味レイヤー整備と同じレイヤーの話で、Fabric連携の前にUnity Catalog上のカタログ設計・グループ設計・ビジネス用語登録を先に済ませておくのが安全な順序です。
Lakebase/CustomerLakeを後付けで足す運用負債

LakebaseやCustomerLakeといったエージェント時代の追加要素は、AIエージェントの本格運用が始まった段階で「Postgres層/顧客360°基盤が別サービスにある」と気づいて後付けするケースがよくあります。
Azure DatabricksをAIエージェント基盤として本格利用する予定がある場合、初期設計時点で「エージェント状態はLakebase、顧客プロファイルはCustomerLake、モデル管理はUnity Catalog上のMosaic AI」という役割分担を決めておくと、後から別サービスに移すコストが発生しません。
Genieで問い合わせしたい業務データが増えるほど、この設計負債は大きくなります。導入初期に「AIエージェント運用を想定した最小構成」を1本描いてから、必要な機能を段階的にアクティベートする形が現実的です。

Databricksで整えた分析基盤を業務のAIエージェント運用に載せるなら
Azure DatabricksでUnity CatalogとDelta Lakeを整えた次の一歩は、そのレイクハウスを実際の業務アクション・承認フロー・監査ログまで届けることです。Teams上の業務判断、複数エージェントの協調、権限・実行ログの一元管理まで設計しないと、「分析基盤は整ったのに業務に載らない」状態に陥りやすくなります。
ここで効いてくるのが、自社Azureテナント内で動くエンタープライズAIエージェント基盤 AI Agent Hub です。Databricksのレイクハウスをデータ層、Teamsを実行層、管理ダッシュボードをガバナンス層として組み合わせ、Unity Catalog権限を活かした業務エージェント運用を1つの基盤で完結させます。
- Databricksのレイクハウスをエージェントの業務データ層として直結
Unity Catalog権限下のDeltaテーブルを、Teamsから呼び出す業務Agentがそのまま参照します。Genie for M365 Copilotが担う自然言語問い合わせと、業務実行を担うAgentが同じ権限モデルの上で動く構成です。
- Teamsから呼び出す9種の業務Agentで「読む」から「動かす」まで
経費申請Agent・請求書受領Agent・AI-OCR Agent・自動入力Agentなどを組み合わせ、Databricksが返したデータをそのまま承認フロー・基幹システム連携に落とし込みます。「分析して終わり」を構造的に防ぐ設計です。
- 管理ダッシュボードで権限・実行ログ・監査を一元化
Agent単位のアクセス権限・不変の実行ログ・セキュリティスキャンを1画面に集約。Unity Catalog整備と地続きのガバナンス層として、Standard→Premium移行後の権限設計をそのまま業務Agent運用に活かせます。
AI総合研究所の専任チームが、Microsoft MVP・Solution Partner認定の実績をもとに、Databricks・Fabricと組み合わせたAgent基盤の設計から運用まで伴走支援します。AI Agent Hubのサービスページで、Databricksのデータを業務に載せるためのAgent基盤の全体像をご確認ください。
Databricksを業務のAIエージェント運用へ

Teamsから業務実行・管理までを一体運用
Azure Databricksで整備したUnity Catalog配下のレイクハウスを、Teams実行基盤・9種の業務Agent・管理ダッシュボードと接続し、業務アクション・承認・監査までを自社Azureテナント内で運用できるエンタープライズAIエージェント基盤です。
Azure Databricksに関するまとめ
本記事では、Azure DatabricksをData Intelligence Platform時代の観点から整理してきました。要点を再掲します。
-
Azure DatabricksはDatabricks本家をAzureにファーストパーティ提供する形態で、Entra ID・Azure課金・Fabric統合が本家との主要な違い
-
Delta Lake/Unity Catalog/Lakeflow/Mosaic AI/Genie/Lakebase/Agent Bricksが2026年時点の主要機能
-
Fabric・OneLakeとの統合は、Unity Catalog Mirroring GA・OneLake Federation・Genie for M365 Copilotで急速に深化中
-
料金はDBU+VM+ストレージの3層構造、Serverless SKUはVM込みで単価が高く見えるが運用軽量化の利点あり
-
2026年10月1日のStandard tier廃止で自動的にPremiumへ移行、DBU単価はSKU別に変動(East US例:All-Purpose +37.5%/Jobs +100%/SQL Compute据え置き)
-
Sparkベース大規模ETLやMosaic AIが主軸ならDatabricks第一候補、Power BI・M365中心ならFabric主軸+Databricksミラーの二層構成が有力
-
導入で詰まりやすいのはStandard→Premium移行計画の遅延、Unity Catalog未整備、Lakebase/CustomerLake後付け負債の3点
Azure Databricksは単なるSparkの実行基盤ではなく、Unity Catalogで統制されたAIエージェント時代のデータハブとして再定義されつつあります。Fabricとの棲み分けとStandard廃止対応を同じスケジュールで進めれば、2026年後半以降のAI基盤を大きく前進させられます。










