この記事のポイント
 コスト重視のキーバリュー検索ワークロードにはTable Storageを選ぶべき。100 GBでも月額約$4.50で運用できる
コスト重視のキーバリュー検索ワークロードにはTable Storageを選ぶべき。100 GBでも月額約$4.50で運用できる- GPv1ストレージアカウントは2026年10月に自動移行されるため、事前にGPv2へアップグレードしてトランザクションコストを検証すべき
- PartitionKey/RowKey以外での検索が頻発するならCosmos DB for Tableへの移行を検討すべき。接続文字列の変更だけで移行可能
- 共有キー認証からEntra IDトークンベース認証に早期移行すべき。2025年8月のGA対応でRBACが正式サポートされている
- PartitionKey設計がパフォーマンスの最大要因。デバイスIDや日付でパーティションを適切に分散させるべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Azure Table Storageは、スキーマレスなNoSQLデータストアとして大量のキーバリューデータを低コストで管理できるサービスです。
2026年にはGPv1ストレージアカウントの廃止やEntra ID認証のGA対応など重要な変更が進んでおり、既存環境の見直しが求められています。
本記事では、基本仕様からデータ構造・CRUD操作、Cosmos DB for Tableとの比較、セキュリティ・冗長性、料金体系までを体系的に解説します。
Azureの概要はこちら
目次
Azure Table Storageとは(2026年最新ガイド)
Azure Table Storageのデータ構造とCRUD操作
Azure Table StorageとCosmos DB for Tableの比較
Azure Table Storageとは(2026年最新ガイド)
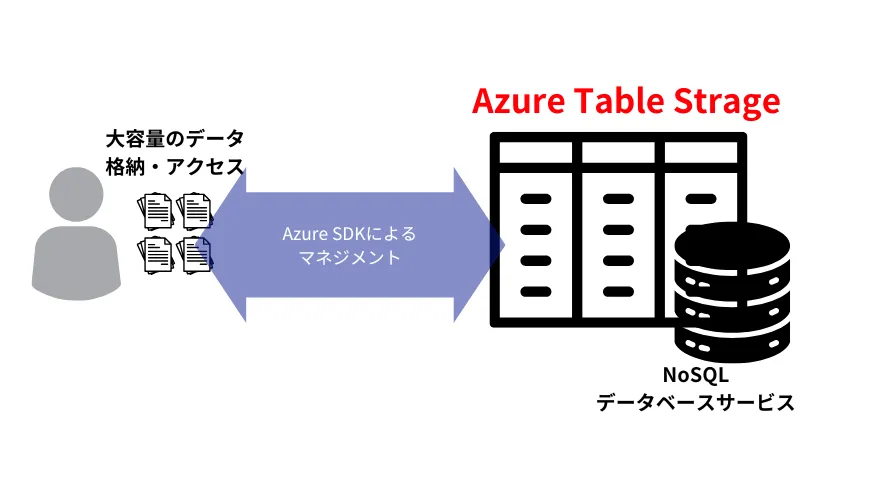
AzureTableStrageイメージ図
Azure Table Storageは、Microsoft Azure Storageプラットフォームの一部として提供されるNoSQLキーバリューデータストアです。リレーショナルデータベースのように固定のスキーマ(テーブル構造のルール)を必要とせず、エンティティごとに異なるプロパティを持たせられるスキーマレス設計が特徴です。IoTセンサーデータ、ユーザープロファイル、セッション情報など、構造が一定でない大量データを低コストかつ高速に格納・取得する用途に適しています。
以下のテーブルで、Azure Table Storageの基本仕様を整理しました。
| 項目 | 内容 |
|---|---|
| サービス分類 | Azure Storage内のNoSQLキーバリューストア |
| 最大テーブルサイズ | 500 TiB |
| 最大エンティティサイズ | 1 MiB(252ユーザー定義プロパティ + 3システムプロパティ) |
| キー構成 | PartitionKey(最大1,024文字)+ RowKey(最大1,024文字) |
| スループット上限 | アカウントあたり最大20,000 TPS(1 KiBエンティティ) |
| パーティションスループット | パーティションあたり最大2,000エンティティ/秒 |
| SDK対応言語 | Python / .NET / Java / JavaScript / Go / C++ |
| SLA | 99.99%(RA-GRS/RA-GZRS読み取り: 99.99%) |
この仕様から分かるのは、Table Storageが「大量の小さなエンティティを高速に読み書きする」ワークロードに最適化されている点です。500 TiBまでのテーブルサイズとアカウントあたり20,000 TPSの処理能力により、数億件規模のデータを単一テーブルで管理でき、パーティション設計を適切に行えば一貫した低レイテンシでアクセスできます。
2026年において、Table Storageに関して押さえるべき重要な変更が2つあります。まず、GPv1(汎用v1)ストレージアカウントの廃止です。2026年3月3日から新規GPv1アカウントの作成がブロックされ、2026年10月13日には既存GPv1アカウントがGPv2へ自動移行されます。GPv2ではBlobティアリング、ライフサイクル管理、ZRS/GZRS冗長性オプションなどの機能が追加される一方、読み取り・書き込み・一覧操作の料金体系が変わるため、トランザクション量の多い環境ではコストが増加する可能性があります。次に、2025年8月にEntra ID認証とRBACがTable Storage補足API(GetTableACL / SetTableACL)でGA(一般提供)となり、共有キー認証からの移行が推奨されています。
GPv1アカウントでTable Storageを運用している場合、2026年10月の自動移行前に自らGPv2へアップグレードし、トランザクションコストへの影響を検証しておくことが重要です。アップグレードは不可逆(GPv1に戻せない)のため、事前にバッチ操作の統合やアクセスパターンの最適化を検討してください。

Azure Table Storageのデータ構造とCRUD操作
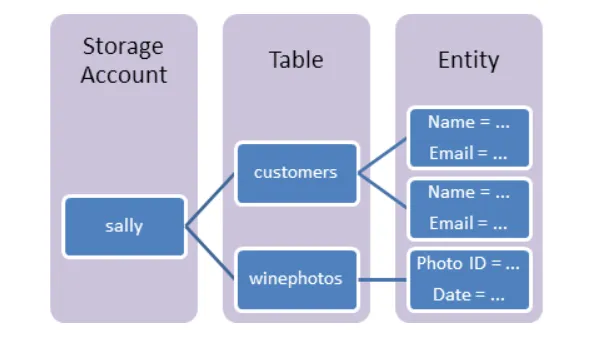
データ構造イメージ
Azure Table Storageのデータは「エンティティ」という単位で管理されます。各エンティティはPartitionKeyとRowKeyの2つのキーで一意に識別され、最大252個のユーザー定義プロパティ(文字列・数値・日時・バイナリなど)を持つことができます。通常のリレーショナルデータベースではスキーマ(列の定義)を事前に決める必要がありますが、Table Storageはスキーマレスのため、同一テーブル内でエンティティごとに異なるプロパティを持たせることが可能です。
以下のテーブルで、データ構造の主要概念を整理しました。
| 概念 | 説明 | 制約・上限 |
|---|---|---|
| エンティティ | データの最小単位(RDBの「行」に相当) | 最大1 MiB / プロパティ最大255個 |
| PartitionKey | データのグループ化キー(同一パーティション内で高速アクセス) | 最大1,024文字 |
| RowKey | パーティション内の一意識別キー | 最大1,024文字 |
| プロパティ | エンティティ内の各データフィールド | 型: String / Int32 / Int64 / Double / Boolean / DateTime / Binary / GUID |
| エンティティグループトランザクション | 同一パーティション内の一括処理 | 最大100エンティティ / ペイロード4 MiB以内 |
PartitionKeyの設計はTable Storageのパフォーマンスを左右する最も重要な要素です。同じPartitionKeyを持つエンティティは同一パーティションに格納され、パーティション単位で最大2,000エンティティ/秒のスループットが確保されます。逆に、すべてのエンティティに同じPartitionKeyを設定するとホットパーティション(アクセス集中)が発生し、スロットリングの原因になります。アクセスパターンに応じて、地域コード・デバイスID・日付範囲などで適切に分散させることが推奨されます。
データ操作には3つの基本手法があります。CRUD操作(Create / Read / Update / Delete)は個別エンティティに対する基本操作で、Azure PortalのストレージブラウザまたはSDK経由で実行できます。バッチ操作は同一パーティション内の複数CRUD操作を1回のHTTPリクエストにまとめる機能で、ネットワークラウンドトリップを削減し処理効率を向上させます。エンティティグループトランザクションは、同一パーティション内の最大100エンティティに対する操作をアトミック(全成功または全失敗)に処理し、データの整合性を保証します。
クエリパフォーマンスの最適化では、PartitionKeyとRowKeyの両方を指定するポイントクエリが最も高速です。PartitionKeyのみの指定ではパーティションスキャン、キー指定なしではフルテーブルスキャンとなり、データ量に比例して処理時間が増加します。ODataフィルター($filter)を活用することでプロパティ条件による絞り込みが可能ですが、PartitionKey/RowKey以外のプロパティにはインデックスが作成されないため、フィルタ条件が複雑になるほどパフォーマンスは低下します。大量データに対する複雑なクエリが頻繁に必要な場合は、後述するCosmos DB for Tableへの移行を検討する価値があります。
Azure Table Storageの作成手順と初期設定
Azure Table Storageを利用するには、まずAzure Portalでストレージアカウントを作成します。
作成手順Azureポータル画面
ポータルにサインインしたら「リソースの作成」からストレージアカウントを検索し、作成画面に進みます。
ストレージアカウント選択画面
「基本」タブでサブスクリプション・リソースグループ・アカウント名・リージョン・パフォーマンス(Standard推奨)・冗長性を設定します。2026年3月以降はGPv2のみ作成可能のため、アカウントの種類は自動的にStorageV2(汎用v2)が選択されます。
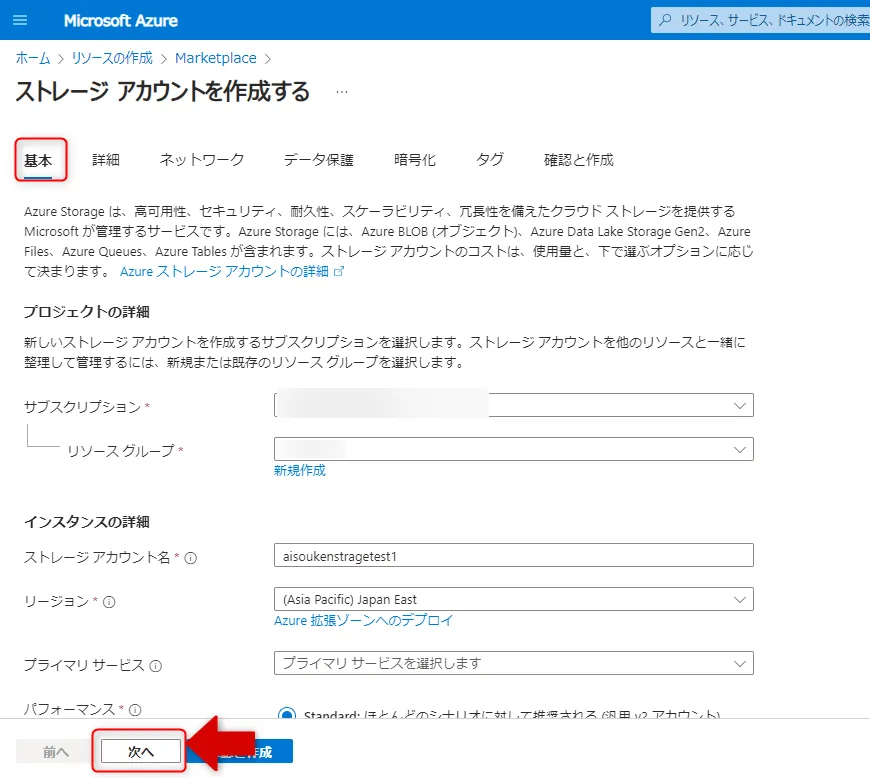
基本タブ画面
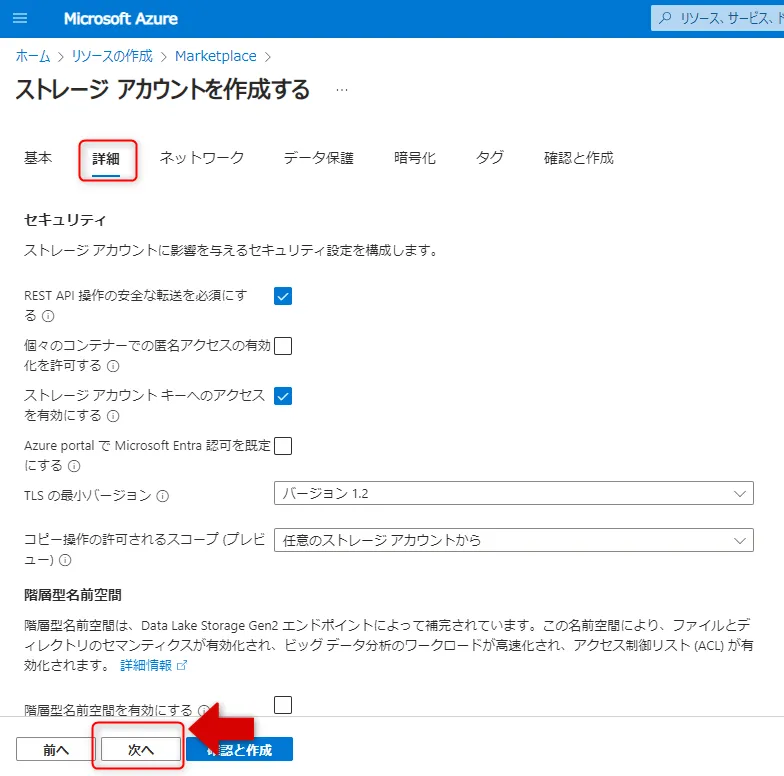
詳細タブ画面
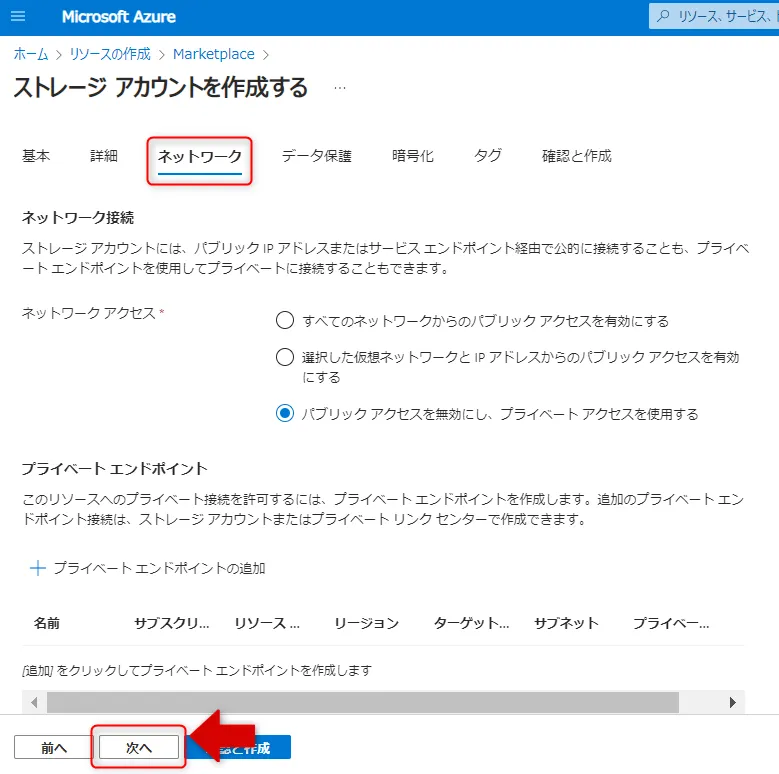
ネットワークタブ画面
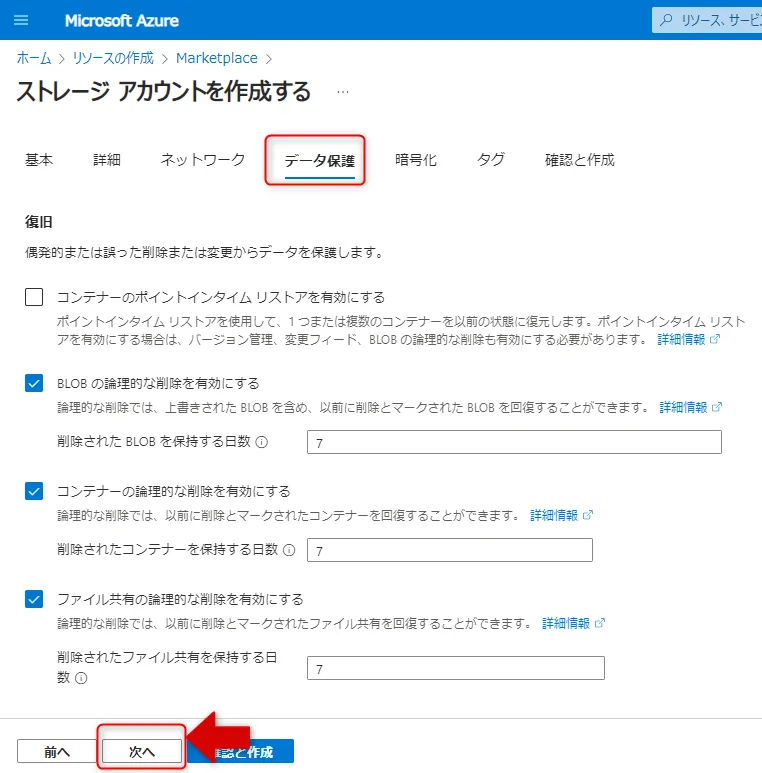
データ保護タブ画面
暗号化タブ画面
各タブで詳細・ネットワーク・データ保護・暗号化の設定を確認し、「確認と作成」で設定内容を検証してからデプロイを実行します。
確認と作成画面
デプロイ完了画面
デプロイ完了後、作成したストレージアカウントの左メニューから「データストレージ」→「テーブル」を選択し、テーブルを追加します。
テーブル追加画面
テーブル作成後はStorage Explorerやストレージブラウザからエンティティを追加できます。「エンティティの追加」ボタンをクリックし、PartitionKey・RowKeyと必要なプロパティを入力して「挿入」を実行します。
エンティティの追加ボタン
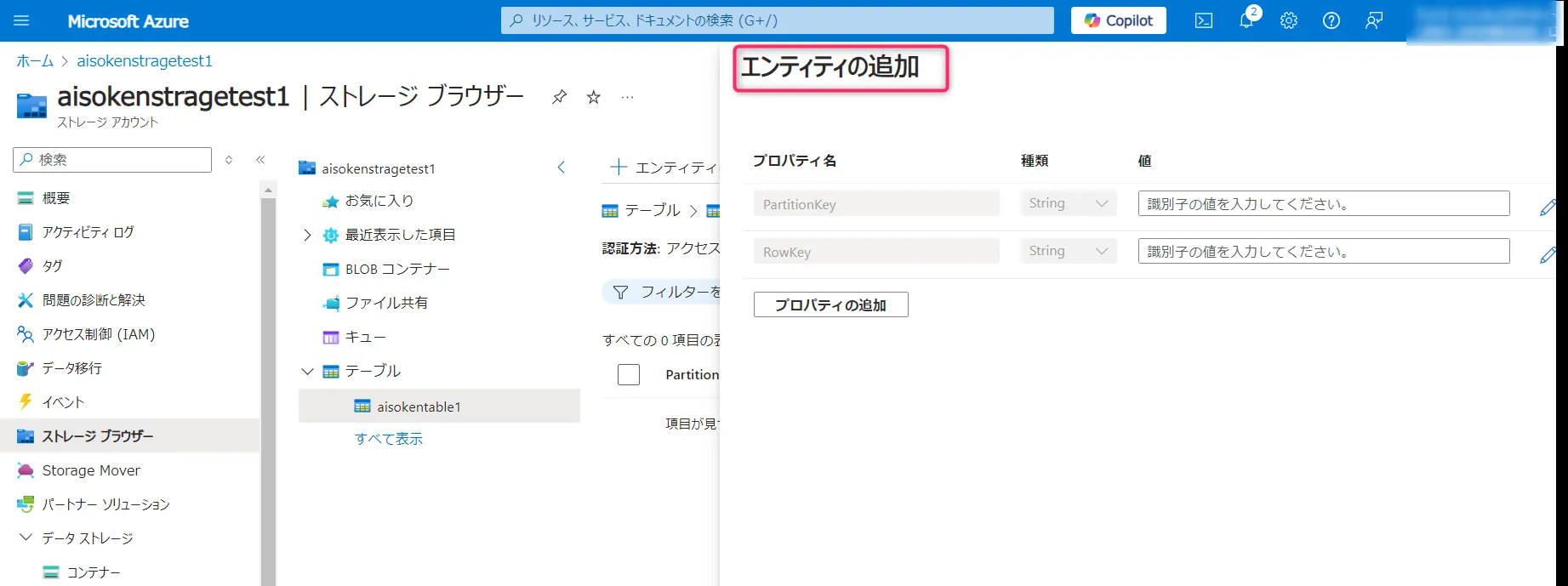
エンティティの追加画面
プログラムからの操作にはazure-data-tables SDKを使用します。2026年3月時点の最新安定版はPython 12.7.0 / .NET 12.11.0で、Microsoft Entra IDによるトークンベース認証にも対応しています。Python 3.9以上が必要な点に注意してください。
Azure Table StorageとCosmos DB for Tableの比較
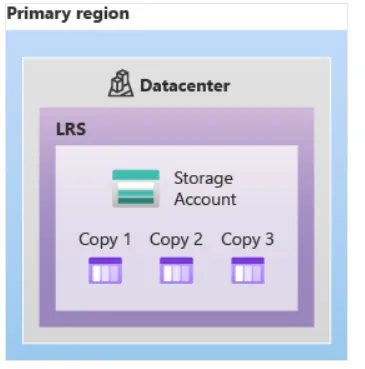
LRSイメージ
Azure Table Storageを検討する際に必ず比較対象となるのが、Azure Cosmos DB for Tableです。Cosmos DB for Tableは、Table Storageと同じSDK(azure-data-tables)で操作でき、接続文字列の変更だけで移行が可能です。ただし、機能・性能・料金体系に大きな違いがあるため、ワークロードに応じた選定が重要です。
以下のテーブルで、両サービスの主要な違いを比較しました。
| 比較項目 | Azure Table Storage | Cosmos DB for Table |
|---|---|---|
| レイテンシ | 高速だが上限保証なし | 読み取り10ms未満 / 書き込み15ms未満(99パーセンタイル) |
| スループット上限 | テーブルあたり20,000 TPS | テーブルあたり1,000万TPS以上(プロビジョニングモード) |
| グローバル配信 | 単一リージョン + 1セカンダリ(読み取り専用) | 1〜30以上のリージョンでターンキー配信 |
| インデックス | PartitionKey + RowKeyのみ | 全プロパティに自動インデックス |
| 整合性レベル | Strong(プライマリ)/ Eventual(セカンダリ) | 5段階(Strong / Bounded Staleness / Session / Consistent Prefix / Eventual) |
| 最大エンティティサイズ | 1 MiB | 2 MiB |
| SLA(可用性) | 99.99% | 単一リージョン99.99% / マルチリージョン読み取り99.999% |
| 課金モデル | ストレージ容量 + トランザクション件数 | RU/s(プロビジョニング)またはRU消費量(サーバーレス) |
選定の判断基準は明確です。単純なキーバリュー検索が中心でコスト重視の場合はTable Storageが適しています。一方、PartitionKey/RowKey以外のプロパティでの検索が頻繁に発生する場合、グローバル配信が必要な場合、またはレイテンシのSLA保証が必要な場合はCosmos DB for Tableが適しています。Microsoftは新規プロジェクトについてはCosmos DB for Tableを推奨していますが、Table Storage自体の廃止予定はなく、コスト効率を重視するシンプルなワークロードでは引き続き有力な選択肢です。
セキュリティ面では、Azure Table Storageは保存データと転送データの両方を自動的に暗号化します。保存データにはStorage Service Encryption(SSE)が適用され、AES-256ビットで暗号化されます。暗号化キーはMicrosoft管理キー(既定)、カスタマーマネージドキー(Azure Key Vaultで管理)、カスタマー提供キーの3つから選択できます。転送データはSSL/TLSプロトコルで保護されます。
アクセス制御では、RBAC(ロールベースのアクセス制御)によりStorage Table Data Contributor(読み書き削除)とStorage Table Data Reader(読み取り専用)の組み込みロールが利用でき、Entra IDトークンベース認証が推奨されています。一時的なアクセスにはSAS(共有アクセス署名)トークンを使用し、操作権限・有効期限・IPアドレス制限を細かく設定できます。2025年8月のGA対応により、OAuth認証の未承認リクエストに対するエラーコードが404から403(Forbidden)に変更されている点に注意が必要です。
冗長性オプションとリージョン選定
Azure Table Storageでは、データの耐障害性を確保するために6つの冗長性オプションが用意されています。以下のテーブルで各オプションの特性とコストを比較しました。
| 冗長プラン | 複製先 | 耐障害性 | コスト | 推奨場面 |
|---|---|---|---|---|
| LRS | 同一データセンター内3重 | データセンター内障害 | 最安 | 開発・テスト環境、再構築可能なデータ |
| ZRS | 同一リージョン内3ゾーン | ゾーン障害 | やや高 | 高可用性が必要な本番環境 |
| GRS | プライマリLRS + セカンダリリージョンLRS | リージョン全体障害 | 高 | リージョン間DRが必要な場合 |
| RA-GRS | GRS + セカンダリ読み取り可 | リージョン全体障害 + 読み取り継続 | 高 | 災害時にも読み取りを継続したい場合 |
| GZRS | プライマリZRS + セカンダリリージョンLRS | ゾーン障害 + リージョン障害 | より高 | 最高レベルの冗長性 |
| RA-GZRS | GZRS + セカンダリ読み取り可 | ゾーン + リージョン障害 + 読み取り継続 | 最高 | ミッションクリティカルなワークロード |
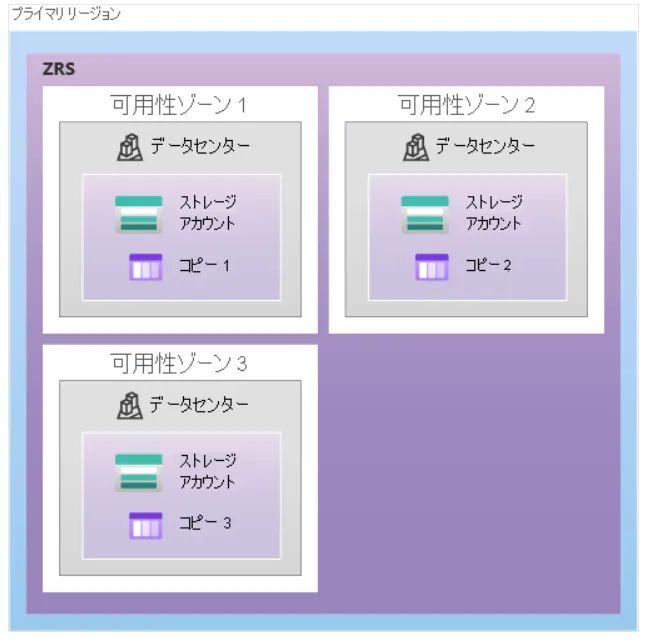
ZRSイメージ
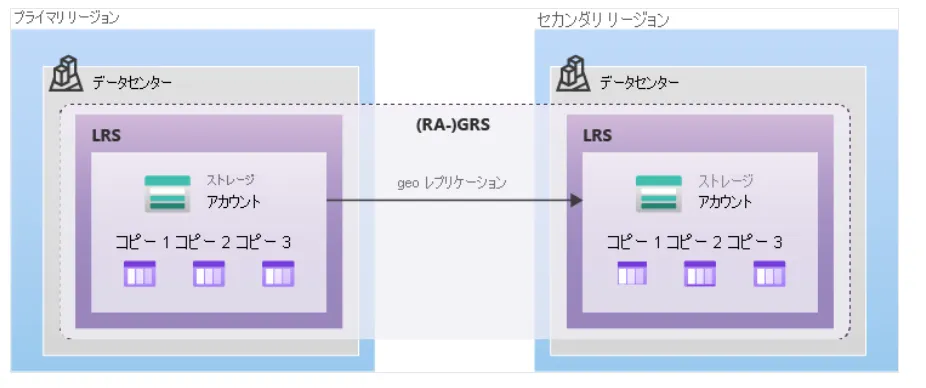
GRSイメージ
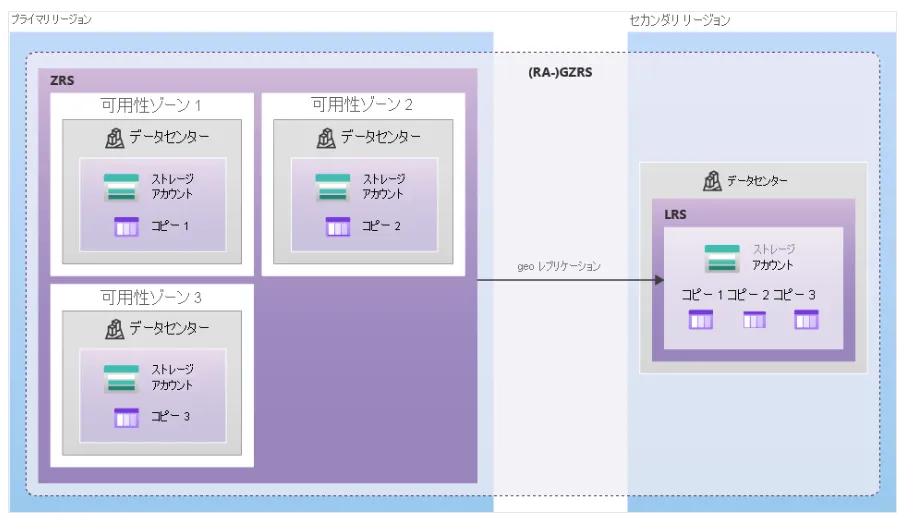
GZRSイメージ
リージョン選定では、データ転送レイテンシの低減(ユーザーに近いリージョンを選択)、コンプライアンス要件(データ所在地の法的制約)、冗長プランの対応状況(一部リージョンではZRS/GZRSが未対応)の3点を考慮します。日本国内のワークロードでは、Japan East(東日本)をプライマリリージョンとするのが一般的です。Azure Blob Storageなどの他ストレージサービスと組み合わせる場合も、同一リージョンに配置することでリージョン間データ転送料金を回避できます。

Azure Table Storageの料金体系とコスト最適化
Azure Table Storageの料金は、データ保存量とトランザクション件数の2要素で構成されています。以下のテーブルで、2026年3月時点のJapan Eastリージョン料金を整理しました(参考: Azure Tables Storage 料金)。
| 料金要素 | LRS | ZRS | GRS | RA-GRS |
|---|---|---|---|---|
| データ保存(GB/月) | 約$0.045 | 約$0.056 | 約$0.09 | 約$0.10 |
| 書き込み(1万件あたり) | 約$0.0036 | 約$0.0045 | 約$0.0072 | 約$0.0072 |
| 読み取り(1万件あたり) | 約$0.0036 | 約$0.0045 | 約$0.0036 | 約$0.0036 |
Table Storageの料金メリットが最も大きいのは「データ量が多く、トランザクション頻度が低い」ワークロードです。たとえば100 GBのデータをLRSで保存した場合、月額のストレージコストは約$4.50(約675円)です。これにCosmos DB for Tableのプロビジョニングモード(400 RU/s最小構成)の月額約$23.36と比較すると、5分の1以下のコストで運用できます。
コスト最適化のポイントは3つあります。まず、GPv2移行後はトランザクション料金の変動に注意が必要です。大量の小さなトランザクションを発行している場合は、バッチ操作(同一パーティション内の最大100エンティティ)に統合することでトランザクション件数を削減できます。次に、冗長プランの選定ではLRSが最安ですが、本番環境ではZRS以上を推奨します。最後に、Azure Monitorでトランザクションメトリクスを監視し、不要なフルテーブルスキャンやリスト操作がないか定期的に確認することが重要です。
ユースケースと導入効果
Azure Table Storageは、スキーマレスかつ低コストという特性を活かして多様な場面で活用されています。以下のテーブルで代表的なユースケースと効果を整理しました。
| ユースケース | 活用データ | Table Storageのメリット |
|---|---|---|
| IoTセンサーデータ蓄積 | 温度・湿度・振動等のテレメトリデータ | 数十億件の時系列データを低コストで蓄積、デバイスIDをPartitionKeyに設定し高速取得 |
| Webアプリケーションのセッション管理 | ユーザーセッション・ショッピングカート | TTL不要データを低コストで一時保存、トラフィック急増時も自動スケール |
| ユーザープロファイル・設定 | アカウント情報・個人設定・デバイス情報 | スキーマレスで項目の追加が容易、ユーザーIDをRowKeyに設定し高速ルックアップ |
| ログ・監査データの長期保存 | アプリケーションログ・アクセスログ | 日付をPartitionKeyに設定し時系列アクセス最適化、Data Factory連携で分析基盤に転送 |
IoTセンサーデータの管理では、デバイスIDをPartitionKeyに、タイムスタンプをRowKeyに設定するパターンが一般的です。この設計により、特定デバイスの特定期間のデータをポイントクエリまたは範囲クエリで高速に取得でき、数十億件のデータでも一貫したパフォーマンスを維持できます。蓄積データはPower BIと連携してトレンド分析や予知保全に活用されており、機器のダウンタイムを15%削減した事例も報告されています。
Webアプリケーションのセッション管理では、ユーザーIDをPartitionKeyに設定し、セッションデータを低コストで一時保存します。セッション終了後のデータ削除も1トランザクションで完了するため、eコマースサイトのキャンペーン期間中のトラフィック急増にも柔軟に対応できます。Azure Functionsと組み合わせることで、セッションの有効期限管理やクリーンアップ処理を自動化するサーバーレスアーキテクチャも構築可能です。

テーブルストレージの知見をAI業務自動化にも活かすなら
Table Storageで構築したキーバリューデータ基盤は、AIエージェントが設定情報・メタデータ・ログを参照する際のバックエンドとして活用できます。データストア設計の知見をAI自動化にも展開するなら、まずは全体像を把握しておくことをお勧めします。
テーブルストレージからAI業務自動化へ

Microsoft環境でのAI活用を徹底解説
Table Storageで構築したキーバリューデータ基盤は、AIエージェントが設定情報やメタデータを参照する際のバックエンドになります。本ガイドでは、Microsoft環境でのAI業務自動化の段階設計を解説しています。
まとめ
本記事では、Azure Table Storageの基本仕様からデータ構造・CRUD操作、Cosmos DB for Tableとの比較、セキュリティ・冗長性オプション、料金体系とユースケースまでを解説しました。
Azure Table Storageを導入・最適化するには、以下のステップで段階的に進めることを推奨します。まず、GPv1ストレージアカウントを利用中の場合は2026年10月の自動移行前にGPv2へアップグレードし、トランザクションコストへの影響を検証してください。次に、Entra ID認証への移行を進め、共有キー認証からトークンベース認証に切り替えることでセキュリティを強化します。PartitionKey/RowKey以外のプロパティでの検索が頻繁に発生し始めた場合や、グローバル配信・レイテンシSLA保証が必要になった場合は、接続文字列の変更だけで移行できるCosmos DB for Tableへのステップアップを検討してください。










