この記事のポイント
 少量データで精度の高い推論を行いたいなら、頻度統計よりベイズ統計を第一候補にすべき
少量データで精度の高い推論を行いたいなら、頻度統計よりベイズ統計を第一候補にすべき- 2026年1月のFDAベイズ臨床試験ガイダンスにより、医療・製薬分野では事実上の標準手法になりつつある
- 実装にはPyMCが最も入門しやすく、高速処理が必要ならNumPyro(JAX)を選ぶべき
- A/Bテストの早期判定やLLMのハルシネーション検出など、2026年のAI実務で不可欠なスキルである
- 導入はパイロット(PyMCチュートリアル)→ドメイン特化PoC→本番運用の3ステップで進めるのが最短ルート

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
ベイズ統計は、事前の知識を数学的に反映しながら新しいデータで確率を更新する統計手法であり、AI・医療・金融の幅広い分野で導入が加速しています。
2026年1月にはFDAが初の包括的なベイズ臨床試験ガイダンスを発行し、製薬・医療機器分野での活用が本格化しました。さらにLLM(大規模言語モデル)の不確実性定量化やBayesian A/Bテストの普及により、データサイエンスの必須スキルとしての位置づけが強まっています。
この記事では、ベイズ統計の基本原理から2026年の最新動向、企業の活用事例、Pythonでの実装まで幅広く解説します。データに基づく意思決定の精度を高めたい方は、ぜひ本記事をお読みください。
目次
ベイズ統計とは(2026年最新ガイド)
ベイズ統計は、事前に持っている知識や信念を数学的な確率として表現し、新しいデータが得られるたびにその確率を更新していく統計手法です。たとえば「友達が遅刻しやすい」という事前知識があるとき、「今日は早く出発した」という新しい情報を加味して「遅刻する確率」を下方修正する、この直感的なプロセスを数学的に定式化したものがベイズの定理です。機械学習やディープラーニングの分野でも、モデルの不確実性を定量化する手法としてベイズ統計の重要性が高まっています。
以下の表で、ベイズ統計の基本情報を整理しました。この表を参照しながら、各要素の詳細を順に解説していきます。
| 項目 | 内容 |
|---|---|
| 正式名称 | ベイズ統計学(Bayesian Statistics) |
| 提唱者 | トーマス・ベイズ(18世紀)、ピエール=シモン・ラプラスが体系化 |
| 核心原理 | ベイズの定理に基づく事前確率から事後確率への逐次更新 |
| 対比手法 | 頻度統計学(記述統計学・推計統計学) |
| 主な応用分野 | 医療診断・臨床試験、金融リスク管理、A/Bテスト、LLM不確実性定量化 |
| 2026年の注目動向 | FDA初の包括的ベイズ臨床試験ガイダンス(2026年1月発行) |
| 代表的ツール | PyMC 5.28、Stan、NumPyro、TensorFlow Probability |
この基本情報で押さえるべきポイントは、ベイズ統計が「事前知識をデータで更新する」という一貫した原理に基づいている点です。機械学習と統計学の違いを理解するうえでも、この「確率を逐次更新する」アプローチが頻度統計との最大の差異となります。
統計学は大きく記述統計学、推計統計学、ベイズ統計学の3つに分類されます。記述統計学はデータの要約・整理を目的とし、平均・中央値・分散などの統計指標でデータの傾向を示します。推計統計学はサンプルデータから母集団の特性を推定・予測する手法で、仮説検定やp値に基づく判断を行います。
記述統計学イメージ
推計統計学イメージ
一方、ベイズ統計学は事前確率を基に新しいデータで確率を更新する方法です。一口ごとに料理の味の評価を更新していくように、データが加わるたびに推定精度が向上していく点が最大の特徴です。
ベイズ統計学イメージ
以下の表で、ベイズ統計と頻度統計の違いを比較しました。実務での使い分けを検討する際に、この対比が判断基準となります。
| 比較項目 | ベイズ統計 | 頻度統計 |
|---|---|---|
| 確率の解釈 | 主観確率(信念の度合い) | 客観確率(長期的な頻度) |
| パラメータの扱い | 確率変数として分布を推定 | 固定値として点推定 |
| 事前知識の活用 | 事前分布として明示的に組み込む | 使用しない |
| データ量の要件 | 少量データでも有効な推論が可能 | 大量データほど精度が向上 |
| 不確実性の表現 | 事後分布で直接的に表現 | 信頼区間やp値で間接的に表現 |
| 計算コスト | MCMCサンプリング等で高負荷になる場合がある | 比較的低負荷で標準的 |
この比較から分かるのは、ベイズ統計が「柔軟で現実的」、頻度統計が「シンプルで客観的」という性格を持つ点です。教師あり学習のモデル選択や教師なし学習のクラスタリングにおいても、パラメータの不確実性を事後分布で把握できるベイズ的アプローチは、意思決定の透明性を高めます。

FDA新ガイダンスとLLM時代が変えるベイズ統計の役割
2026年1月9日、FDA(米国食品医薬品局)は「Use of Bayesian Methodology in Clinical Trials of Drug and Biological Products」と題した初の包括的ドラフトガイダンスを発行しました。このガイダンスは、IND(治験薬申請)、NDA(新薬申請)、BLA(生物学的製剤承認申請)のすべての段階でベイズ手法の適用を正式に認めています。外部データの借用、小児集団への外挿、腫瘍学での用量選択、適応的試験デザインなど幅広い領域をカバーしており、Berry Consultantsはこれを「ベイズ臨床試験と規制科学における劇的な飛躍」と評価しています。コメント期限は2026年3月13日に設定されました。

同時に、大規模言語モデル(LLM)の急速な普及に伴い、ベイズ統計はAI分野でも新たな役割を担うようになっています。LLMが「自信を持って間違える」ハルシネーション問題に対し、ベイズ的な不確実性定量化(UQ)が有効な対策として注目されています。PoLAR-VBLLやBLoB(Bayesian Low-Rank Adaptation by Backpropagation)といった手法は、LoRAファインチューニング時にベイズ推論を組み込むことで、モデルの予測信頼度を定量化します。さらにUP-RLHF(Uncertainty-Penalized RLHF)は、報酬モデルの不確実性を正則化項として取り入れ、要約タスクで12%の性能向上とGPT-4による評価で56%の勝率を達成しています。
生成AIの品質保証においても、ベイズ階層モデリング(BHM)を用いたハルシネーション分析が初めて適用され、MCMCサンプリングによる信頼区間の算出が実用化されつつあります。A/Bテスト領域では、NetflixがBayesian Sequential Testingを導入してストリーミング体験の改善実験を加速させており、VWO・Optimizely・AB Tastyなどの主要プラットフォームもベイズエンジンを標準搭載しています。A/Bテストソフトウェア市場は2026年時点で約9.4億ドル規模に達し、2035年には44億ドルへの成長が予測されています。
ベイズ推論の基本と実装の実践
ベイズ統計の中核をなすのが「ベイズの定理」と呼ばれる数式です。この定理は、事前確率(Prior)が尤度(Likelihood)を受けてどのように変化するかを示す事後確率(Posterior)を求めるための方法です。尤度とは、あるモデルや仮説のもとで観測されたデータがどのくらい「もっともらしい」かを表す指標です。AIアルゴリズムの多くがこのベイズの定理を基盤として構築されています。
P(A|B)は事後確率(データBを基にしたAの確率)、P(A)は事前確率(データがないときのAの確率)、P(B|A)は尤度(Aが起こった場合にBが観測される確率)、P(B)は正規化定数(データBの確率)を表します。この定理の本質は、新しい情報が得られるたびに事前の知識と組み合わせて確率を更新し、より情報に基づいた推論を可能にする点にあります。
たとえば医療診断の場面を考えます。ある病気にかかる確率(事前確率)が1%、病気の人が検査で陽性になる確率が96%、健康な人が誤って陽性になる確率が2%とします。ベイズの定理から計算すると、検査結果が陽性だったとき実際に病気にかかっている確率は約33%となります。直感的には陽性イコール病気と思いがちですが、事前確率の低さが事後確率を大きく左右するこの事例は、ベイズ的思考の重要性を示しています。
事前確率(Prior Probability)はデータが与えられる前に持っている情報に基づく確率であり、事後確率(Posterior Probability)は観測データを基に更新された確率です。ベイズ統計では主観確率を用いるため、分析者の知識や経験が事前分布の設定に反映されます。一方、頻度統計で用いる客観確率は、同じ条件を繰り返したときの長期的な頻度に基づきます。この違いが、少量データでも有効な推論を可能にするベイズ統計の強みを生み出しています。
事前分布・事後分布の仕組みとPython実装
確率的プログラミングフレームワークの進化により、ベイズ推論の実装は大幅に容易になっています。PyMCは2026年3月時点でv5.28.2をリリースしており、Python 3.11〜3.14に対応し、JAXベースのバックエンド(NumPyro・BlackJAX)により高速なMCMCサンプリングを実現しています。Stanは2026年8月にスウェーデン・ウプサラでStanCon 2026の開催を予定しており、Fisherダイバージェンスを活用した高速適応アルゴリズムの開発が進んでいます。NumPyroはJAXベースの実装でHMC/NUTSサンプラーの100倍以上の高速化を達成し、研究コミュニティでの採用が急速に拡大しています。
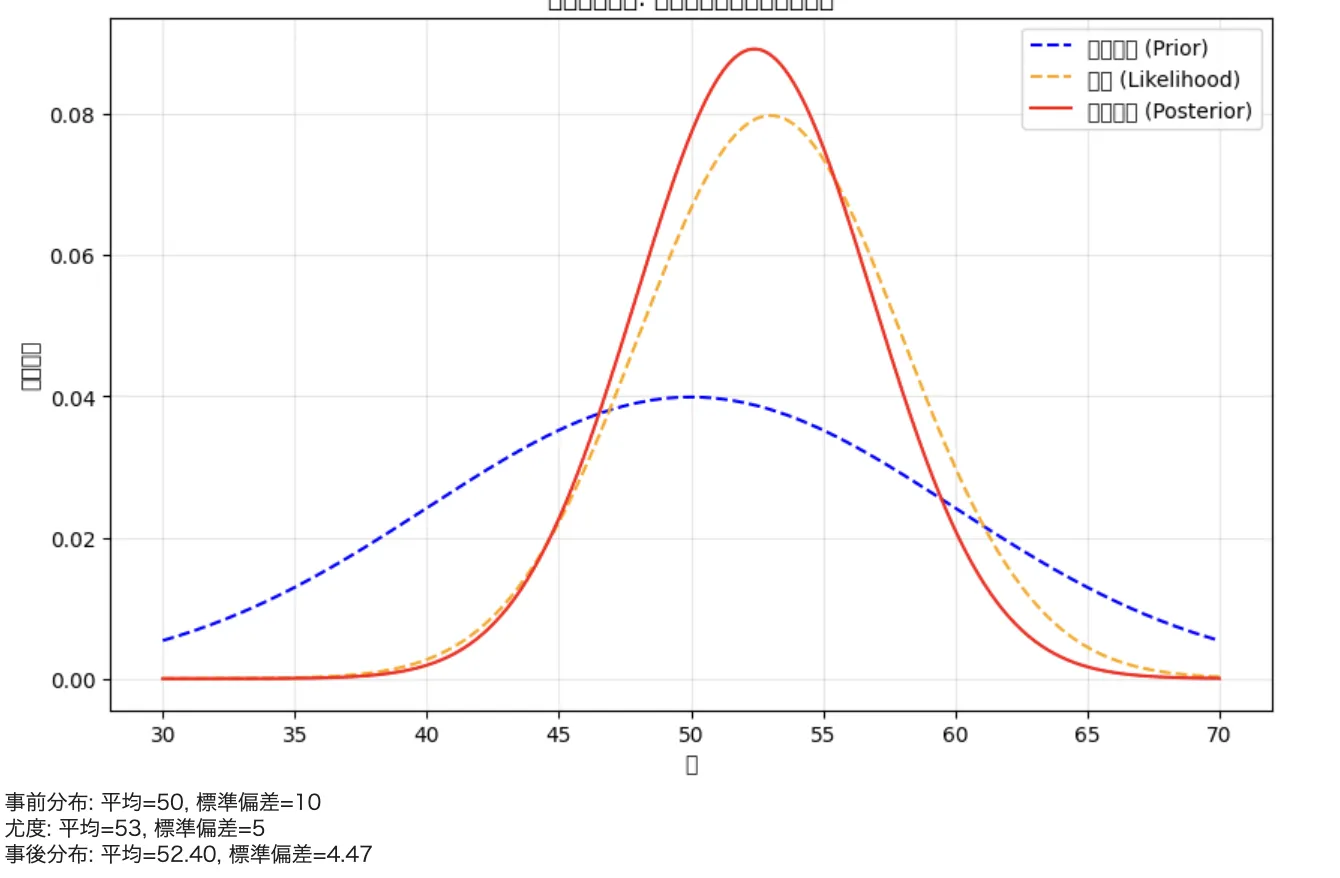
以下のPythonコード例は、事前分布と尤度から事後分布を計算し可視化する基本的な実装です。製品の寿命予測をシナリオとして、事前知識(平均50時間)と実験データ(平均53時間)をベイズ的に統合する過程を示しています。
# 必要なライブラリをインポート
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# パラメータの設定
prior_mean = 50 # 事前分布の平均
prior_std = 10 # 事前分布の標準偏差
observed_mean = 53 # 観測されたデータの平均 (尤度の平均)
observed_std = 5 # 観測誤差の標準偏差 (尤度の標準偏差)
# 事後分布の計算
posterior_mean = (prior_mean / prior_std**2 + observed_mean / observed_std**2) / (1 / prior_std**2 + 1 / observed_std**2)
posterior_std = np.sqrt(1 / (1 / prior_std**2 + 1 / observed_std**2))
# x軸の範囲
x = np.linspace(30, 70, 500)
# 確率分布
prior_dist = norm.pdf(x, loc=prior_mean, scale=prior_std)
likelihood_dist = norm.pdf(x, loc=observed_mean, scale=observed_std)
posterior_dist = norm.pdf(x, loc=posterior_mean, scale=posterior_std)
# プロット
plt.figure(figsize=(10, 6))
plt.plot(x, prior_dist, label="事前分布 (Prior)", linestyle='--', color='blue')
plt.plot(x, likelihood_dist, label="尤度 (Likelihood)", linestyle='--', color='orange')
plt.plot(x, posterior_dist, label="事後分布 (Posterior)", color='red')
plt.title("ベイズ統計学: 事前分布、尤度、事後分布")
plt.xlabel("値")
plt.ylabel("確率密度")
plt.legend()
plt.grid(alpha=0.3)
plt.show()
# 結果の出力
print(f"事前分布: 平均={prior_mean}, 標準偏差={prior_std}")
print(f"尤度: 平均={observed_mean}, 標準偏差={observed_std}")
print(f"事後分布: 平均={posterior_mean:.2f}, 標準偏差={posterior_std:.2f}")
実行結果
このコードを実行すると、事前分布(青い破線)、尤度(オレンジの破線)、事後分布(赤い実線)の3つが可視化されます。事後分布が事前分布と尤度の間に位置し、データの精度が高い(標準偏差が小さい)尤度側に引き寄せられている点が確認できます。これがベイズ統計の「既存の知識を新しい情報でアップデートするプロセス」の視覚的な表現です。回帰分析においても、事前分布を設定することでパラメータの不確実性を反映したベイズ回帰が実現できます。
評価手法と活用分野の比較
ベイズ統計は医療、金融、マーケティング、自然言語処理、生態学など多岐にわたる分野で活用されています。AIとデータサイエンスの違いを理解するうえでも、ベイズ統計がデータサイエンスの中核的な手法としてどのように位置づけられているかを把握することが重要です。
以下の表で、主要な活用分野とベイズ統計の適用方法を整理しました。各分野での具体的な成果と2026年の動向を確認できます。
| 活用分野 | 主な適用方法 | 代表的な成果 | 2026年の注目動向 |
|---|---|---|---|
| 医療・臨床試験 | 適応的試験デザイン、外部データ借用 | I-SPY 2試験で23以上の治療法を評価、4薬剤が承認取得 | FDA初のベイズガイダンス(2026年1月) |
| 金融・リスク管理 | ポートフォリオ最適化、リスクモデリング | ベイズネットワークでリスクの不確実性を定量化 | Basel III/IV AI説明可能性要件への対応 |
| A/Bテスト | Bayesian Sequential Testing | Netflixが実験速度を加速、小サンプルでも有効な判定 | 市場規模9.4億ドル(2026年)から44億ドル(2035年) |
| LLM・生成AI | 不確実性定量化、ハルシネーション検出 | UP-RLHFで要約タスク12%性能向上 | BLoB・PoLAR-VBLLによるファインチューニング統合 |
| 創薬 | 多忠実度ベイズ最適化 | AI創薬Phase I成功率80-90%(従来40-65%) | 173のAI創薬プログラムがパイプラインに |
| 生態学 | 個体数推定、絶滅リスク評価 | ムール貝3種の絶滅リスクをベイズ的に評価 | 環境変動データとの統合解析の進展 |
特に差が出るのが医療・臨床試験分野です。AI駆動の創薬プログラムでは、ベイズ的な多忠実度最適化により、Phase I臨床試験の成功率が従来の40-65%から80-90%に向上し、開発期間は10-15年から3-6年へと大幅に短縮されています。
医療・金融・A/Bテストの活用事例と成果
FDA推奨のベイズ適応的臨床試験
FDAのベイズガイダンスの実践例として最も注目されるのが、I-SPY 2プラットフォーム試験です。この試験は乳がんの術前化学療法を対象に、ベイズ適応的ランダム化デザインを採用し、23以上の実験的治療法を効率的に評価しました。ベイズ予測確率の閾値(85%)を超えた7〜9の薬剤が「卒業」し、そのうち4薬剤が最終的に販売承認を取得しています。2025〜2026年にはSMART(Sequential Multiple Assignment Randomized Trial)形式に再構成され、最大3段階の治療法を評価する設計へと進化しています。
引用元:PHARMA
生態学でのベイズ的リスク評価
アメリカの生態学者たちは、ベイズ統計を用いて淡水ムール貝3種の絶滅リスクを評価しました。都市開発や水文変動が引き起こす環境変化に基づいて事前確率を設定し、観測データで更新することで保存活動の優先順位を定量的に判定しています。このアプローチは、データが限られる絶滅危惧種の評価において、頻度統計では困難な精度の高い推論を可能にしています。

企業のBayesian A/Bテスト導入
Netflixは、Bayesian Sequential Testingを導入してストリーミング体験の改善実験を加速しています。従来の頻度主義的なA/Bテストでは固定サンプルサイズが必要でしたが、ベイズ的アプローチによりデータが蓄積される過程で早期に意思決定を行えるようになりました。GoogleやMicrosoftも多腕バンディット(ベイズ的探索・活用のバランス)を推薦システムに適用しており、CNNなどの深層学習モデルとベイズ最適化を組み合わせたハイパーパラメータチューニングも標準的な手法となっています。
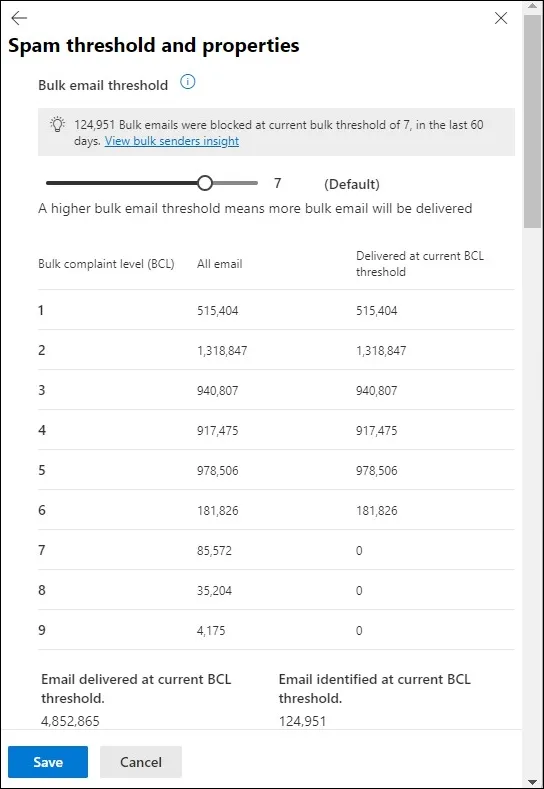
引用元:Microsoft
金融分野では、JPMorganやGoldman Sachsがベイズ的手法をバリュエーション、ヘッジ、リスク管理に活用しています。特にBasel III/IV枠組みのもとでAIモデルの説明可能性が求められるなか、ベイズネットワークによる不確実性の適切な伝播と帰属が、規制対応の重要な手段として位置づけられています。

導入時の注意点と活用ガイド
ベイズ統計の導入にあたっては、手法の特性に起因するいくつかの課題を事前に理解しておく必要があります。転移学習や機械学習の手法選択と同様に、ベイズ統計にも「向いている場面」と「注意が必要な場面」があります。
以下の表で、導入時に注意すべき主要な課題と対策を整理しました。プロジェクトの計画段階でこれらの課題を把握しておくことで、スムーズな導入が可能になります。
| 課題 | 内容 | 対策 |
|---|---|---|
| 事前分布の設定 | 適切な事前分布の選択が結果を大きく左右する。主観性の排除が困難 | 非情報的事前分布の活用、感度分析で複数の事前分布を比較検証 |
| 計算コスト | MCMCサンプリングは高次元問題で計算負荷が急増 | NumPyro(JAX)で100倍高速化、変分推論による近似、バッチ分割処理 |
| 大規模データへの適用 | 逐次更新の計算時間がデータ量に比例して増加 | 変分ベイズ推論、オンライン更新手法、ミニバッチ処理の採用 |
| 結果の解釈 | 事後分布の解釈に統計的素養が求められる | チーム内での研修実施、可視化ツールの活用、信頼区間での意思決定 |
| モデル検証 | 事後予測チェックや収束診断の省略がモデルの信頼性を損なう | R-hat統計量・トレースプロットによる収束確認、LOO-CVでモデル比較 |
実務で選ぶ際のポイントは、データ量とドメイン知識の有無です。事前知識が豊富で小〜中規模データの場合はベイズ統計が最大の威力を発揮します。一方、大規模データで事前知識の反映が不要な場合は、頻度統計的アプローチのほうが計算効率に優れます。
段階的導入ステップとよくある質問
ベイズ統計を組織に導入する際は、以下の3ステップで段階的に進めることを推奨します。
Step 1 ツール選定とパイロット(1〜2週間)
-
フレームワーク選定
PyMC・Stan・NumPyroの中から、チームのPython/R環境とユースケースに合ったものを選択する。Python環境ならPyMCが最も入門しやすく、高速処理が必要ならNumPyro(JAX)が適している
-
小規模実験
公式チュートリアル(PyMCのGetting Startedガイド)で基本的なベイズ推論を体験する。コイン投げや正規分布の推定など、直感的に結果を検証できるシンプルな問題から開始する
Step 2 ドメイン特化PoC(2〜4週間)
-
業務データへの適用
自社の実データ(A/Bテスト結果、品質検査データ、売上予測等)にベイズモデルを適用し、頻度統計との結果を比較検証する
-
事前分布の設計
ドメインエキスパートの知見を事前分布として定量化する。感度分析を実施して、事前分布の選択が結論に与える影響を確認する
Step 3 本番運用とスケールアップ(1〜2か月)
-
パイプライン構築
推論結果をダッシュボードやAPIとして提供する仕組みを構築する。MCMCの収束診断(R-hat、トレースプロット)を自動化する
-
チーム教育
事後分布の読み方、ベイズ信用区間(Credible Interval)と頻度主義信頼区間(Confidence Interval)の違い、モデル選択基準(WAIC・LOO-CV)について研修を実施する
よくある質問
Q. ベイズ統計は少ないデータでも本当に有効ですか?
事前分布がデータの不足を補完するため、少量データでも信頼性のある推論が可能です。ただし事前分布の設定が結果に大きく影響するため、感度分析による検証が不可欠です。データが増えるにつれて事前分布の影響は自然に薄れていきます。
Q. 頻度統計とベイズ統計はどちらを選ぶべきですか?
目的とデータの状況で判断します。事前知識がありデータが限られる場面(臨床試験、品質管理の初期段階)ではベイズ統計が有利です。大規模データで客観的な仮説検定が求められる場面(社会調査、品質管理の量産段階)では頻度統計が適しています。両者は排他的ではなく、同じプロジェクト内で使い分けることも一般的です。
Q. 計算コストを抑える方法はありますか?
NumPyro(JAXバックエンド)はPyTorchベースのPyroと比較してHMC/NUTSサンプラーで100倍以上の高速化を達成しています。また変分推論(Variational Inference)はMCMCの代替として大規模データにも対応でき、精度と速度のトレードオフを調整できます。BayGA(Bayesian-based Genetic Algorithm)のような新手法も2025年に提案されており、ハイパーパラメータチューニングの自動化と高速化が進んでいます。

ベイズ統計の理解からAI業務導入の設計指針を得る
ベイズ統計の原理と応用を理解することは、AIが出す予測や判断の根拠を正しく評価し、業務への適用可否を判断する力につながります。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に設計する実践ガイド(220ページ)を無料で提供しています。統計的なアプローチを活かした業務改善の設計から全社展開まで、部門別のBefore/After付きユースケースで解説しています。
AI総合研究所が、データ分析の知見を組織のAI業務設計に活かす指針を提供します。
ベイズ統計からAI導入設計へ

段階的なAI導入の実践ガイド(220p)
Microsoft環境で始める段階的なAI業務自動化の実践ガイド。Copilot Chat→M365 Copilot→Copilot Studioの導入ロードマップと部門別ユースケースを収録。
まとめ
この記事では、ベイズ統計の基本原理から2026年の最新動向、企業の活用事例、Pythonでの実装まで幅広く解説しました。
ベイズ統計が提供する3つの価値は以下のとおりです。
-
事前知識の活用による推論精度の向上
事前分布としてドメイン知識を明示的に組み込むことで、少量データでも信頼性の高い推論が可能です。FDA初の包括的ベイズ臨床試験ガイダンス(2026年1月)は、この利点を製薬・医療分野で制度的に認めた画期的な動きです
-
不確実性の定量化による透明な意思決定
事後分布を通じてパラメータの不確実性を直接表現できるため、意思決定者にとって分かりやすい確率的な判断材料を提供します。LLMのハルシネーション検出やA/Bテストの早期判定など、2026年のAI実務で不可欠な手法です
-
確率的プログラミングによる実装の容易化
PyMC 5.28、NumPyro、Stanなどのフレームワークが成熟し、数行のコードで本格的なベイズ推論を実装できる環境が整っています。JAXベースのバックエンドによりMCMCサンプリングの高速化も進んでおり、計算コストの障壁は年々低下しています
ベイズ統計は、過去の経験と新しい情報を結びつけて確率的に最適な判断を導く手法です。まずはPyMCの公式チュートリアルで小規模な推論実験を体験し、自社のデータへの適用可能性を検証することから始めてみてください。









