この記事のポイント
 ChatGPTのハルシネーション抑制にはRAG+ベクトルデータベースの導入が最も有効
ChatGPTのハルシネーション抑制にはRAG+ベクトルデータベースの導入が最も有効- 小規模PoCならChromaDB+OpenAI Embeddings APIで数ドル以内から始めるべき
- 既にPostgreSQLを運用中ならpgvector追加が最もスムーズな導入パス
- 本番スケールではPinecone・Qdrant・Milvusからデータ量とチーム体制で選定すべき
- エンベディングはまずtext-embedding-3-smallで検証し、精度不足時のみlargeに切り替えるのがコスト最適

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
ベクトルデータベースは、ChatGPTをはじめとする生成AIが「自社データに基づいた正確な回答」を返すために不可欠な基盤技術です。テキストや画像などのデータを数値ベクトルに変換し、意味の近さで高速に検索できる仕組みで、RAG(検索拡張生成)の中核を担っています。
本記事では、ベクトルデータベースの基本概念から、ChatGPTとの具体的な連携方法、OpenAI Vector Store・Embeddings API、主要サービス比較、活用事例、料金まで、2026年3月時点の最新情報をわかりやすく解説します。
ChatGPTの新料金プラン「ChatGPT Go」については、以下の記事をご覧ください。
ChatGPT Goとは?料金や機能、広告の仕様、Plus版との違いを解説
最新モデル「GPT-5.5」については、以下の記事をご覧ください。
GPT-5.5とは?使い方や料金、GPT-5.4との違いを解説
ベクトルデータベースとは
ベクトルデータベースは、テキスト・画像・音声などのデータを高次元の数値ベクトル(埋め込みベクトル)に変換して格納し、「意味の近さ」に基づいて高速に検索できるデータベースです。ChatGPTをはじめとする大規模言語モデル(LLM)が自社データや最新情報に基づいた回答を生成する際に、不可欠な基盤技術として利用されています。

従来のデータベースが「キーワードの一致」でデータを検索するのに対し、ベクトルデータベースは「意味の類似性」で検索します。たとえば、「犬」というキーワードで検索した場合、従来のデータベースでは「犬」という文字列を含むレコードしかヒットしません。しかしベクトルデータベースでは、「ペット」「柴犬」「動物病院」など、意味的に関連する情報も検索結果に含めることができます。

ベクトル化(エンベディング)の仕組み
ベクトルデータベースの根幹をなすのが「埋め込みベクトル化(Embedding)」という技術です。これは、テキストや画像などのデータを数百〜数千次元の数値の配列に変換する処理を指します。
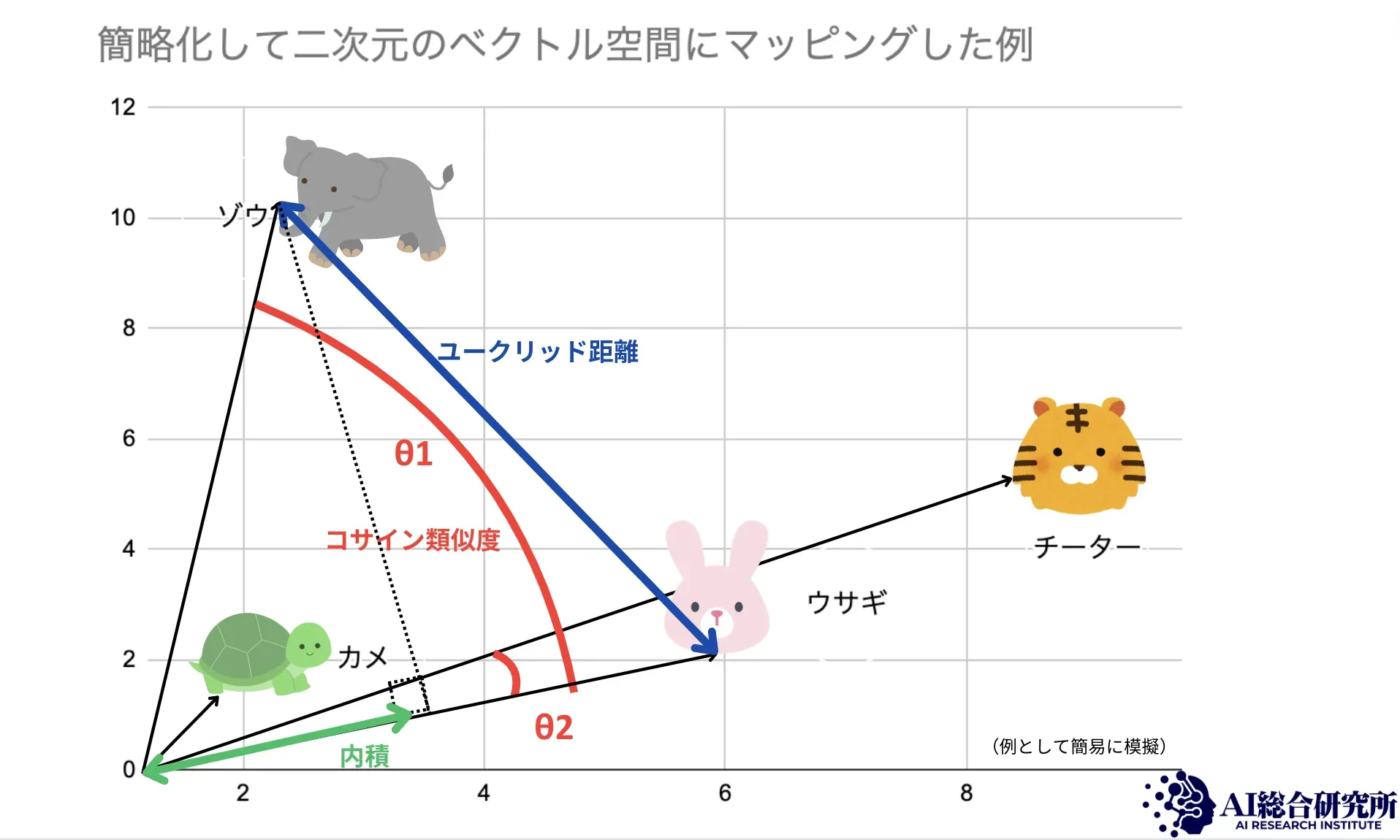
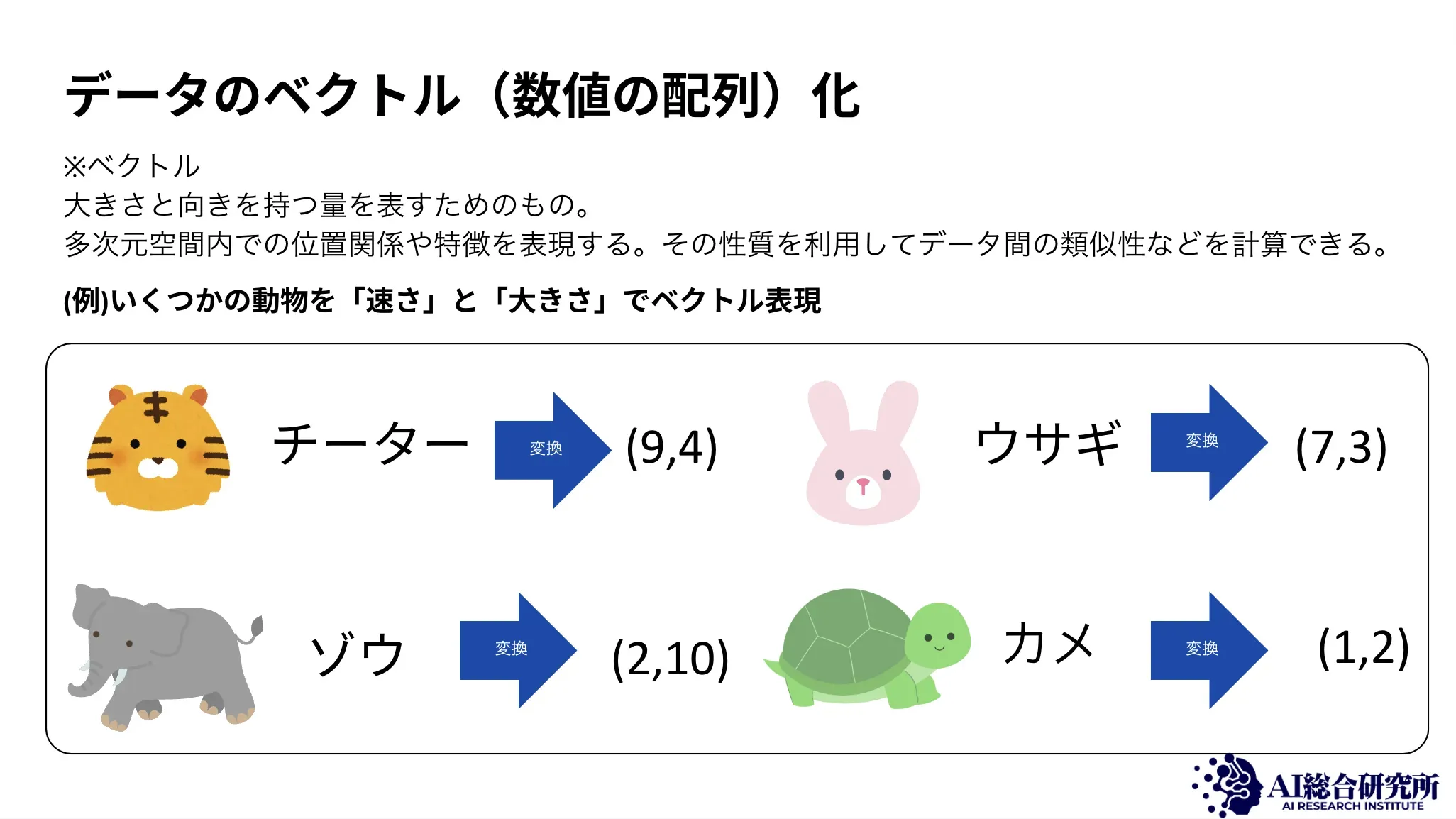
たとえば、「犬」という単語と「猫」という単語をそれぞれ数百次元のベクトルに変換すると、ベクトル空間上で近い位置に配置されます。一方、「自動車」は「犬」や「猫」から離れた位置に配置されます。この距離関係が「意味の近さ」を表しており、ベクトルデータベースはこの距離を計算することで類似データを高速に見つけ出します。
エンベディングの主な特徴を以下の表に整理しました。
| 特徴 | 内容 |
|---|---|
| 意味の保持 | 意味が近いデータはベクトル空間上で近い位置に配置される |
| 次元削減 | 元データの情報をより少ない次元に圧縮し、計算コストを削減 |
| 汎用性 | テキスト・画像・音声・コードなど多様なデータ型に対応 |
| 自動化 | 人手によるタグ付けが不要。AIモデルが自動でベクトル化 |
2026年時点では、OpenAIのtext-embedding-3-largeが3,072次元、text-embedding-3-smallが1,536次元のベクトルを生成でき、次元数を任意に指定して精度とコストのバランスを取ることも可能です。
従来のデータベースとの違い
ベクトルデータベースがなぜ注目されているのかを理解するために、従来のデータベースとの違いを以下の表で比較しました。
| 比較項目 | リレーショナルDB(SQL) | NoSQL DB | ベクトルDB |
|---|---|---|---|
| データ構造 | テーブル(行と列) | ドキュメント/キー・バリュー | 高次元ベクトル |
| 検索方式 | キーワード一致、SQL | キー検索、全文検索 | 意味的類似性(コサイン類似度等) |
| 得意なデータ | 構造化データ | 半構造化データ | 非構造化データ(テキスト・画像・音声) |
| AI連携 | 限定的 | 部分的 | RAG・セマンティック検索に最適 |
| 代表例 | MySQL、PostgreSQL | MongoDB、DynamoDB | Pinecone、Weaviate、Qdrant |
リレーショナルデータベースは顧客情報や在庫管理など、構造化されたデータの管理に優れています。NoSQLは柔軟なデータモデルで大規模データの処理に適しています。一方、ベクトルデータベースは「この文章に意味が近いデータを探す」といったセマンティック検索に特化しており、生成AIとの連携で真価を発揮します。
【関連記事】
ChatGPTの仕組みとは?全体像や図解で基礎から解説!
ChatGPTとベクトルデータベースの関係
ChatGPTの回答精度を高めるために、ベクトルデータベースは2つの重要な役割を果たしています。1つはRAG(検索拡張生成)の情報源として、もう1つはOpenAIが提供するVector Store機能としてです。
RAG(検索拡張生成)の仕組み
RAG(Retrieval Augmented Generation)は、ChatGPTのようなLLMが回答を生成する前に、外部のデータベースから関連情報を検索して参照する仕組みです。これにより、LLMの学習データに含まれていない最新情報や社内の非公開データに基づいた正確な回答が可能になります。
RAGの処理フローは以下の4ステップです。
-
Step 1 データの前処理
社内文書・FAQ・マニュアルなどのテキストデータを、エンベディングモデルでベクトルに変換し、ベクトルデータベースに格納します
-
Step 2 ユーザーの質問をベクトル化
ユーザーがChatGPTに質問すると、その質問文もベクトルに変換されます
-
Step 3 類似検索
質問ベクトルとデータベース内のベクトルの距離を計算し、意味的に最も近いドキュメントを検索します
-
Step 4 回答生成
検索で見つかった関連ドキュメントをコンテキストとしてLLMに渡し、その情報に基づいた回答を生成します
RAGの最大の利点は、ChatGPTのハルシネーション(事実と異なる回答を生成する現象)を大幅に抑制できる点です。LLMの内部知識だけに頼るのではなく、検証済みのデータソースから情報を取得するため、事実に基づいた回答が可能になります。
OpenAI Vector Store機能
OpenAIは、開発者が独自のRAGシステムを簡単に構築できるよう、Assistants API / Responses APIにVector Store機能を提供しています。
(参考)Vector Embeddings | OpenAI API
Vector Storeでは、テキストファイルをアップロードするだけで、OpenAIが自動的にテキストの分割(チャンキング)、エンベディング生成、ベクトルデータベースへの格納までを処理します。開発者は自前でベクトルデータベースを構築・運用する必要がなく、API呼び出しだけでRAGシステムを実現できます。
Vector Storeの料金は、最初の1GBが無料で、それ以降は$0.10/GB/日(処理済みデータサイズ基準、エンベディングを含む)です。小規模なプロジェクトであれば無料枠内で十分に利用できますが、大量のドキュメントを扱う場合はコストが増加するため、外部のベクトルデータベースサービスとの比較検討が必要になります。
主要ベクトルデータベースの比較(2026年版)
ベクトルデータベースの選択肢は年々増えており、2026年時点では用途・規模・予算に応じて複数のサービスから選べるようになっています。以下の表で、主要6サービスの特徴を比較しました。
| サービス | 種別 | 料金 | 主な特徴 |
|---|---|---|---|
| Pinecone | マネージドSaaS | 無料枠あり / Starter $33〜/月 | セットアップ不要、サーバーレス、エンタープライズ向け |
| Weaviate | OSS / マネージド | OSS無料 / Cloud $25〜/月 | マルチモーダル対応、GraphQL API、ハイブリッド検索 |
| Qdrant | OSS / マネージド | OSS無料 / Cloud $9〜/月 | Rust製で高速、フィルタリング性能に優れる |
| Milvus | OSS / マネージド | OSS無料 / Zilliz Cloud有料 | 大規模データ対応、GPU対応、LF AI傘下 |
| ChromaDB | OSS | 無料 | 軽量・シンプル、Python/JS SDK、プロトタイプ向き |
| pgvector | PostgreSQL拡張 | PostgreSQL本体に依存 | 既存PostgreSQL環境に追加可能、学習コスト低 |

Milvus
選択の判断基準は「目的」と「チーム体制」の2軸で考えると整理しやすくなります。すぐに始めたい場合やインフラ管理を避けたい場合はPineconeやWeaviate Cloudのようなマネージドサービスが適しています。コストを抑えつつ柔軟にカスタマイズしたい場合はMilvusやQdrantのOSS版が候補になります。既にPostgreSQLを運用している環境であれば、pgvectorを追加するのが最もスムーズです。
プロトタイプや個人開発にはChromaDBが適しており、Python数行でベクトル検索を試すことができます。本番環境でのスケーラビリティが求められる場合は、Pinecone・Milvus・Qdrantの中から要件に合ったものを選ぶのが一般的です。
【関連記事】
Azure AI Searchのベクトル検索の手順を解説!
Azure AI Search(旧Azure Cognitive Search)の機能と料金を徹底解説!
ベクトルデータベースの活用事例
ベクトルデータベースは、生成AIの普及に伴って幅広い分野で実用化が進んでいます。ここでは、代表的な活用パターンを紹介します。
セマンティック検索と社内ナレッジ管理
企業がベクトルデータベースを導入する最も一般的なユースケースが、社内ナレッジの検索精度向上です。従来のキーワード検索では、「有給休暇の申請方法」と検索しても「年次休暇の取得手続き」という文書がヒットしないことがありました。ベクトルデータベースを使えば、表現が異なっていても意味的に近い文書を検索結果に含められます。
具体的な活用パターンとして、社内FAQ・マニュアルをベクトル化してChatGPTと連携する「社内AIアシスタント」の構築が急速に広がっています。新入社員が「経費精算の方法は?」と質問すると、社内規定や申請フローの文書をベクトル検索で特定し、ChatGPTがそれらの内容をもとに自然な日本語で回答を生成するという仕組みです。
Elasticsearch(全文検索+ベクトル検索のハイブリッド検索に対応)
画像・マルチモーダル検索
ベクトルデータベースはテキストだけでなく、画像や音声のベクトル化にも対応しています。ECサイトでは、ユーザーが撮影した写真から類似商品を検索する「画像類似検索」が実用化されており、商品画像をベクトル化してデータベースに格納し、アップロードされた画像との距離を計算することで実現しています。
Faiss(Meta開発の大規模ベクトル類似検索ライブラリ)
2026年時点では、テキストと画像を同一のベクトル空間に埋め込む「マルチモーダルエンベディング」が発展しており、「赤いワンピースに合うバッグ」というテキストクエリで、対応する画像を検索するといった横断的な検索が可能になっています。画像認識や自然言語処理の進歩と相まって、マルチモーダル検索は今後さらに実用化が進む分野です。
【関連記事】
ディープラーニングとは?その仕組みや種類、機械学習との違いを解説

OpenAI Embeddings APIの活用
ベクトルデータベースを利用するには、まずデータをベクトルに変換する必要があります。OpenAIが提供するEmbeddings APIは、テキストデータのベクトル化において最も広く使われているサービスの一つです。
(参考)New embedding models and API updates | OpenAI
エンベディングモデルの選び方
OpenAIは2つのエンベディングモデルを提供しており、用途に応じて使い分けることが重要です。以下の表で、2026年3月時点のモデル仕様を比較しました。
| モデル | 次元数 | 料金(100万トークンあたり) | 特徴 |
|---|---|---|---|
| text-embedding-3-small | 1,536 | $0.02 | コスト効率が高く、大量データの処理に適する |
| text-embedding-3-large | 3,072 | $0.13 | 高精度。dimensions パラメータで次元数の削減が可能 |
text-embedding-3-smallは、ほとんどのユースケースで十分な精度を発揮しつつ、コストはtext-embedding-3-largeの約6分の1に抑えられます。まずはsmallモデルで検証を行い、精度が不足する場合にlargeモデルに切り替えるアプローチが実務的です。
text-embedding-3-largeでは、APIのdimensionsパラメータを指定することで、3,072次元のベクトルを任意の次元数(例: 256次元や1,024次元)に短縮できます。これにより、ベクトルデータベースのストレージコストと検索速度を最適化しつつ、必要な精度を確保できます。
Embeddings APIの利用にはOpenAI APIキーが必要です。Python SDKでは数行のコードでテキストをベクトルに変換でき、取得したベクトルを前述のベクトルデータベースに格納することで、RAGシステムの構築が可能になります。
【関連記事】
プロンプトエンジニアリングとは?その種類やコツを徹底解説!
ベクトルデータベースの課題と注意点
ベクトルデータベースは強力な技術ですが、導入・運用にあたっていくつかの課題を認識しておく必要があります。
-
エンベディング品質への依存
ベクトルデータベースの検索精度は、データをベクトル化する際のエンベディングモデルの品質に大きく依存します。低品質なエンベディングでは、意味的に正確な検索結果が得られません。モデルの選択とテキストの前処理(チャンキング戦略)が検索品質を左右します
-
コストとスケーラビリティのバランス
データ量が増えるとベクトルのストレージコストとインデックス再構築のコストが増大します。特にOpenAI Vector Storeは$0.10/GB/日の従量課金であるため、大量のドキュメントを扱う場合はOSSのベクトルデータベースを自社運用する方がコスト効率が良くなることがあります
-
データの鮮度管理
ベクトルデータベースに格納された情報は、元のドキュメントが更新されても自動的には反映されません。情報の鮮度を保つために、定期的なデータの再ベクトル化と更新のパイプラインを構築する必要があります
-
セキュリティとプライバシー
社内の機密情報をベクトル化して外部のクラウドサービスに格納する場合、データの暗号化、アクセス制御、コンプライアンス対応が必要です。特に個人情報を含むデータを扱う場合は、セキュリティリスクの評価を事前に行うことが重要です
社内のナレッジ検索に毎日30分以上かけているチームや、ChatGPTの回答精度に不満を感じている場合は、ベクトルデータベースによるRAGの導入が有効な解決策になり得ます。一方で、構造化されたデータ(売上データ、在庫管理など)の管理には従来のリレーショナルデータベースが依然として最適であり、ベクトルデータベースは「意味検索が必要な場面」に限定して導入するのが合理的です。
【関連記事】
ChatGPTの法人契約方法!おすすめの企業利用向けサービスの料金・セキュリティを解説

データ活用基盤の知見を組織の業務自動化に活かす

ベクトルDBの知見を業務自動化に活かす
ベクトルデータベースで「AIが自社データを活用する」基盤を理解した次のステップは、組織としてAIを業務プロセスに組み込む段階設計です。Microsoft環境での段階的なAI導入を220ページで解説したガイドです。
ベクトルデータベース・ChatGPT料金比較(2026年3月版)
ベクトルデータベースの導入を検討する際、ChatGPTのプランや関連APIのコストも含めて全体像を把握することが重要です。以下の表で、ChatGPTのサブスクリプションプランを比較しました。
| プラン | 月額料金(USD) | 主な機能 | ベクトルDB関連 |
|---|---|---|---|
| Free | 無料 | GPT-4o mini(制限付き) | APIアクセスなし |
| Go | $8 | GPT-5.2 Instant | APIアクセスなし |
| Plus | $20 | GPT-5.2/5.4フルアクセス | APIは別途課金 |
| Pro | $200 | 全モデル無制限 | APIは別途課金 |
| Team | $25〜30/ユーザー | 共有ワークスペース | APIは別途課金 |
| Enterprise | カスタム | 強化セキュリティ | カスタムRAG構築支援 |
APIを使ったRAGシステムの構築コストは、エンベディング生成(text-embedding-3-small: $0.02/100万トークン)、ベクトルデータベースのストレージ(OpenAI Vector Store: $0.10/GB/日、または外部サービス)、LLM呼び出し(GPT-5: $1.25/$10.00/100万トークン)の3要素で構成されます。
小規模な社内RAGシステム(文書1,000件程度)であれば、月額数ドル〜数十ドル程度のコストで運用できます。大規模な導入を検討する場合は、OpenAI Vector Storeの従量課金と、Pinecone・Qdrantなどの外部サービスの固定料金を比較し、データ量に応じた最適な構成を選択することが重要です。
【関連記事】
ChatGPT APIの料金ガイド 2026年3月最新版 モデル別料金一覧とコスト削減のポイント
ChatGPT料金完全ガイド!GPT-5・GPT-4o・Proプラン徹底比較
RAG基盤の構築から業務プロセスのAI自動化に進むなら
ベクトルデータベースとRAGの仕組みを理解し、「AIが自社データに基づいて回答する」基盤を構想した次のステップは、検索→回答にとどまらず業務プロセス全体をAIに委ねることです。問い合わせ対応・社内ナレッジ検索から、レポート生成・承認フローの自動化まで、RAGの先にある業務AI化が始まっています。
AI総合研究所のAI業務自動化ガイドでは、RAGの知見を起点に業務自動化へと展開するためのステップと、業務領域ごとの適用パターンを体系的にまとめています。ベクトルDBの構築計画を業務価値に結びつける参考としてご活用ください。
データ活用基盤の知見を組織の業務自動化に活かす
ベクトルDBの知見を業務自動化に活かす
ベクトルデータベースで「AIが自社データを活用する」基盤を理解した次のステップは、組織としてAIを業務プロセスに組み込む段階設計です。Microsoft環境での段階的なAI導入を220ページで解説したガイドです。
まとめ
ベクトルデータベースは、ChatGPTをはじめとする生成AIが「自社データに基づいた正確な回答」を返すために不可欠な基盤技術です。テキストや画像を高次元ベクトルに変換し、意味の近さで高速に検索するこの仕組みは、RAG(検索拡張生成)の中核として、AIの回答精度を大幅に向上させます。
2026年時点では、OpenAI Vector Storeによるフルマネージドな構築から、Pinecone・Weaviate・Qdrantなどの専用サービス、pgvectorによる既存インフラの活用まで、多様な選択肢が揃っています。企業がベクトルデータベースを活用する第一歩として、以下の3ステップを推奨します。
-
Step 1 小規模なPoCから始める
社内FAQやマニュアル10〜50件をChromaDBとOpenAI Embeddings APIでベクトル化し、ChatGPTと連携させるプロトタイプを構築します。Embeddings APIのコスト(text-embedding-3-small: $0.02/100万トークン)は非常に低いため、小規模な検証は数ドル以内で実施できます
-
Step 2 本番環境のサービス選定
PoCで効果が確認できたら、データ量・セキュリティ要件・チーム体制に基づいて本番用のベクトルデータベースを選定します。マネージドサービス(Pinecone、Weaviate Cloud)か、OSS自社運用(Milvus、Qdrant)か、既存DB拡張(pgvector)かの判断が最初のポイントです
-
Step 3 運用パイプラインの整備
データの更新・再ベクトル化の自動パイプライン、アクセス制御、コスト監視の体制を整えて本格運用に移行します










