この記事のポイント
 2026年のディープラーニングではTransformerが圧倒的主流。テキスト・画像・マルチモーダルの大半はTransformerベースを選ぶべき
2026年のディープラーニングではTransformerが圧倒的主流。テキスト・画像・マルチモーダルの大半はTransformerベースを選ぶべき- リアルタイム物体検出や医療画像ならCNNが依然として第一選択。エッジデバイスの時系列処理にはRNN/LSTMが最適
- 学習フレームワークはPyTorch 2.xを選ぶべき。学術論文の80%以上がPyTorchを使用しており、Hugging Faceとの連携も緊密
- 表形式データ(売上予測・顧客分類)にはXGBoost等の勾配ブースティングが有利。ディープラーニングは画像・テキスト・音声など非構造化データで真価を発揮する
- 学習開始はCourseraかFast.aiの基礎理論から着手すべき。GPUはGoogle Colab無料枠で十分で、初期段階では理論理解を優先する

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
ディープラーニングは、画像認識・自然言語処理・音声認識から創薬・自動運転まで、現代のAI技術の中核を担う技術です。2026年現在、Transformerベースの基盤モデルやState Space Model(Mamba)の登場、Mixture of Experts(MoE)アーキテクチャの普及により、ディープラーニングの技術地図は大きく変化しています。
本記事では、機械学習の一分野であるディープラーニングについて、ニューラルネットワークの基本原理から主要モデル(CNN・RNN・Transformer)の比較、2026年の応用事例、学習リソースまで包括的に解説します。
AI技術の基礎を体系的に理解し、ビジネスや研究に活用したい方に向けた実践ガイドです。
ディープラーニングとは(2026最新ガイド)
ディープラーニング(深層学習)は、機械学習の一分野であり、多層のニューラルネットワークを用いてデータから複雑なパターンを自動的に学習する技術です。脳内のニューロンが情報を処理する仕組みに着想を得ており、入力層・中間層(隠れ層)・出力層から構成されるネットワークが、大量のデータから特徴を抽出してパターンを識別します。従来の機械学習では人手で設計する必要があった特徴量の抽出を自動化できることが、ディープラーニングの最大の強みです。
2026年現在、ディープラーニングは生成AIの基盤技術として不可欠な存在です。ChatGPTを支えるTransformerアーキテクチャ、DALL-Eや拡散モデルによる画像生成、GANによるスタイル変換など、現代のAIサービスの大半がディープラーニングの上に構築されています。ディープラーニング市場はIMARC Groupの調査によれば$309億(2024年)から$4,234億(2033年)への成長が予測されており、CAGR約30%という急速な拡大が見込まれています。
以下の表で、ディープラーニングの基本情報を整理しました。
| 項目 | 内容 |
|---|---|
| 正式名称 | ディープラーニング(Deep Learning / 深層学習) |
| 分類 | 機械学習の一分野(教師あり・教師なし・強化学習すべてに対応) |
| 核心原理 | 多層ニューラルネットワークによる自動特徴抽出 |
| 主要アーキテクチャ | CNN・RNN/LSTM・Transformer・State Space Model |
| 代表的フレームワーク | PyTorch 2.x・TensorFlow 2.x・JAX |
| 2026年注目動向 | 基盤モデル・MoE・State Space Model・エッジAI推論 |
| 市場規模 | $309億(2024年)→ $4,234億(2033年)CAGR約30% |
ディープラーニングと従来の機械学習の最大の違いは、特徴量設計の自動化です。従来の機械学習手法では、画像認識であればエッジ検出フィルタやHOG特徴量など、タスクごとに専門家が手動で特徴量を設計する必要がありました。ディープラーニングでは、生データを入力するだけでネットワークが自動的に最適な特徴表現を学習するため、より高い精度と汎用性を実現しています。両者の違いをより詳しく知りたい方は機械学習とディープラーニングの違いの記事も参考にしてください。
 機械学習とディープラーニングの違い
機械学習とディープラーニングの違い

基盤モデルとState Space Modelが変えるディープラーニングの2026年動向
2026年のディープラーニングにおける最も注目すべき進化は、基盤モデル(Foundation Model)のスケーリングとアーキテクチャの多様化です。GPT-5.x系列やGemini 3、Claude 4.x系列など、数兆パラメータ規模のモデルが実用化されており、1つのモデルで対話・画像理解・コード生成・推論を統合的に処理するマルチモーダルAIが主流となっています。
Transformer以外のアーキテクチャとして注目を集めているのがState Space Model(SSM)です。MambaやJambaに代表されるSSMベースモデルは、Transformerの自己注意機構(Self-Attention)が持つ入力長の二乗に比例する計算コスト問題を解消し、線形の計算量で長いシーケンスを処理できます。100万トークン以上のコンテキストウィンドウを効率的に扱えるため、長文ドキュメントの要約やゲノム解析など、従来のTransformerでは困難だったタスクへの適用が進んでいます。
Mixture of Experts(MoE)アーキテクチャも普及が加速しています。全パラメータのうち一部のエキスパートのみを活性化させることで、推論時の計算コストを抑えながらモデル全体の知識量を拡大する設計で、Mixtral、DeepSeek-V3、GPT-5.xなどがこの手法を採用しています。ハードウェア面ではNVIDIA B200 GPU(Blackwellアーキテクチャ)が2025年に出荷開始され、前世代H100比で推論性能が最大30倍向上しています(実環境では8〜15倍程度)。GPUの進化と分散学習技術の成熟により、大規模モデルの学習コストは着実に低下しており、企業のAI導入障壁は低くなっています。
ディープラーニングの仕組みとネットワークモデルの実践
ディープラーニングの仕組みは、ニューラルネットワークにおける入力の伝播、重みの学習、出力の生成という3つのプロセスで構成されています。以下の表で、主要なネットワークアーキテクチャの概要と活用場面を整理しました。
| アーキテクチャ | カテゴリ | 概要 |
|---|---|---|
| CNN(畳み込みニューラルネットワーク) | 空間認識 | 畳み込み演算で局所的な特徴を抽出。画像認識・物体検出・医療画像解析に活用 |
| RNN(再帰型ニューラルネットワーク) | 時系列処理 | 過去の入力情報を保持し時系列データを処理。音声認識・センサーデータ分析に活用 |
| LSTM(長期短期記憶) | 時系列処理 | RNNの勾配消失問題を解決するゲート機構を追加。長期依存関係の学習に対応 |
| Transformer | 注意機構 | 自己注意機構(Self-Attention)で入力全体の関係性を並列処理。自然言語処理・画像生成の主流 |
| State Space Model | 線形時系列 | 線形の計算量で長いシーケンスを処理。100万+トークンの長文処理に最適 |
| GAN(敵対的生成ネットワーク) | 生成モデル | 生成器と識別器の対抗学習で高品質データを生成。スタイル変換・データ拡張に活用 |
ニューラルネットワークの基本動作は、入力データに重み(Weight)を掛けて足し合わせる線形結合と、非線形性を加える活性化関数の2つの処理の繰り返しです。
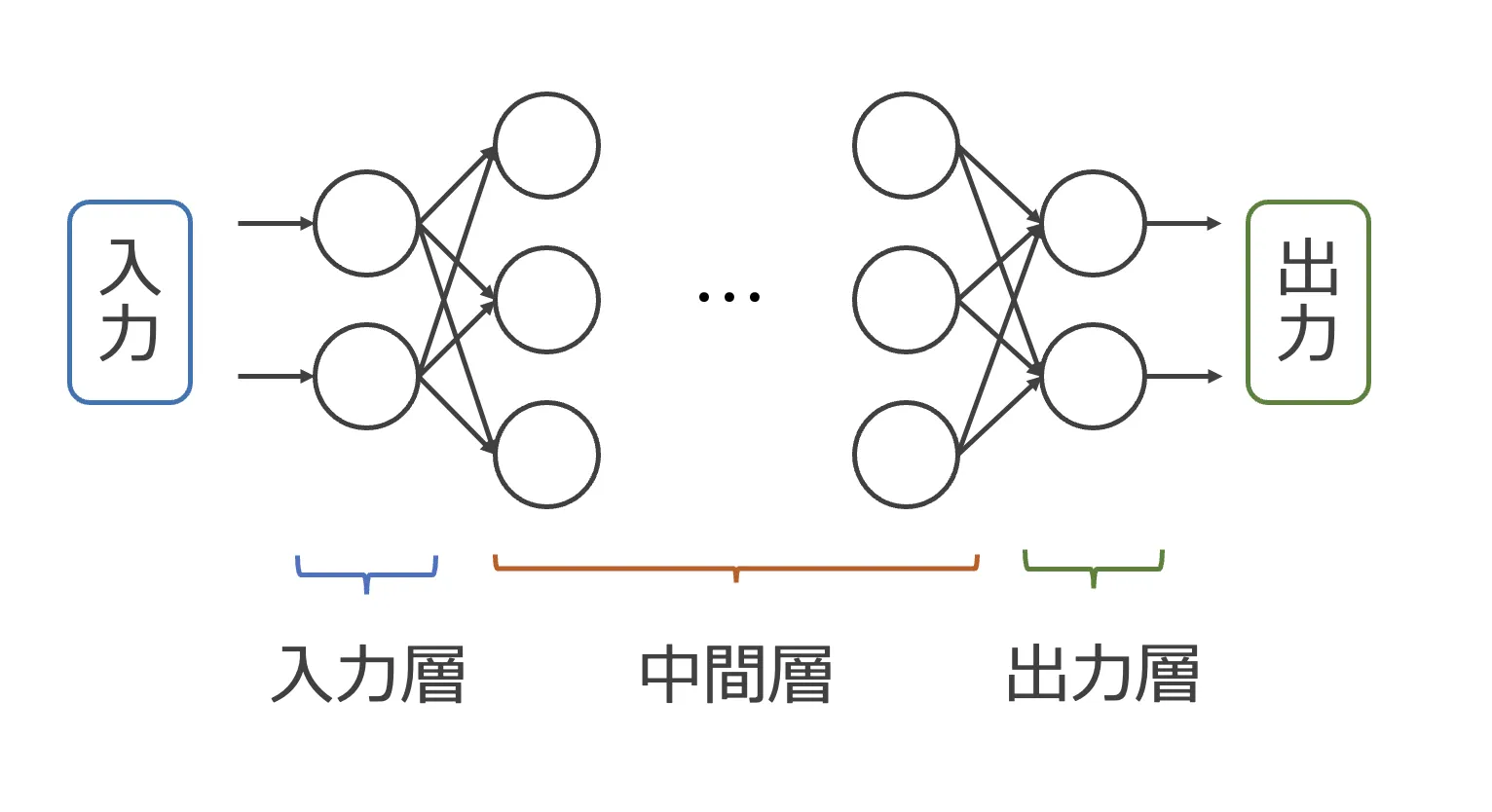 ニューラルネットワークの概要図
ニューラルネットワークの概要図
線形結合の例として、入力値「2」に重み「3」と「5」をそれぞれ掛けた出力「6」と「10」を、さらに重み「2」と「4」で結合すると「6x2 + 10x4 = 52」となります。この演算を多層に積み重ねることで、ネットワークは複雑なパターンを表現できるようになります。
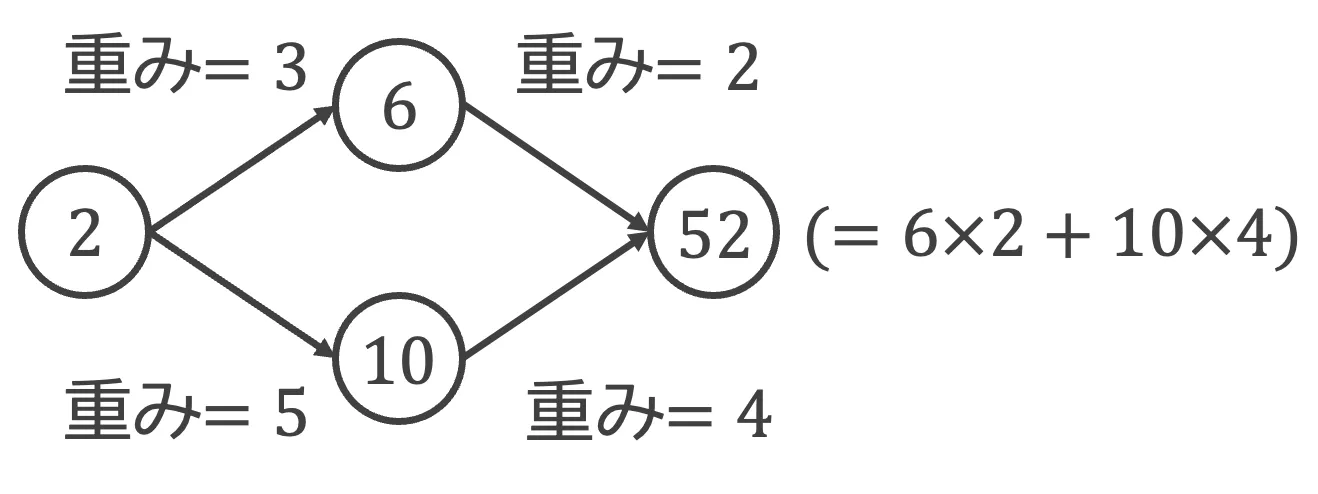 簡単なニューラルネットワークの例
簡単なニューラルネットワークの例
活性化関数は、線形結合の結果に非線形変換を適用する関数で、ReLU(Rectified Linear Unit)、シグモイド関数、ハイパボリックタンジェントなどが代表的です。2026年の実務ではReLUとその派生(GELU、SwiGLU)が主流で、特にTransformerモデルではSwiGLU活性化関数が標準的に使用されています。
CNNは畳み込み演算により画像の局所的な特徴(エッジ、テクスチャ、パターン)を階層的に抽出する仕組みで、小さなフィルタ(カーネル)を画像上でスライドさせながら特徴マップを生成します。
 畳み込みの計算方法
畳み込みの計算方法
RNNは時系列データを先頭から順に処理し、各時刻の入力と過去の隠れ状態を合成することで文脈を保持しますが、長い入力では勾配消失問題が発生します。この問題を解決したのがLSTMで、セルゲート・入力ゲート・出力ゲート・忘却ゲートの4つのゲート機構とメモリセルにより、長期的な依存関係を効果的に学習します。
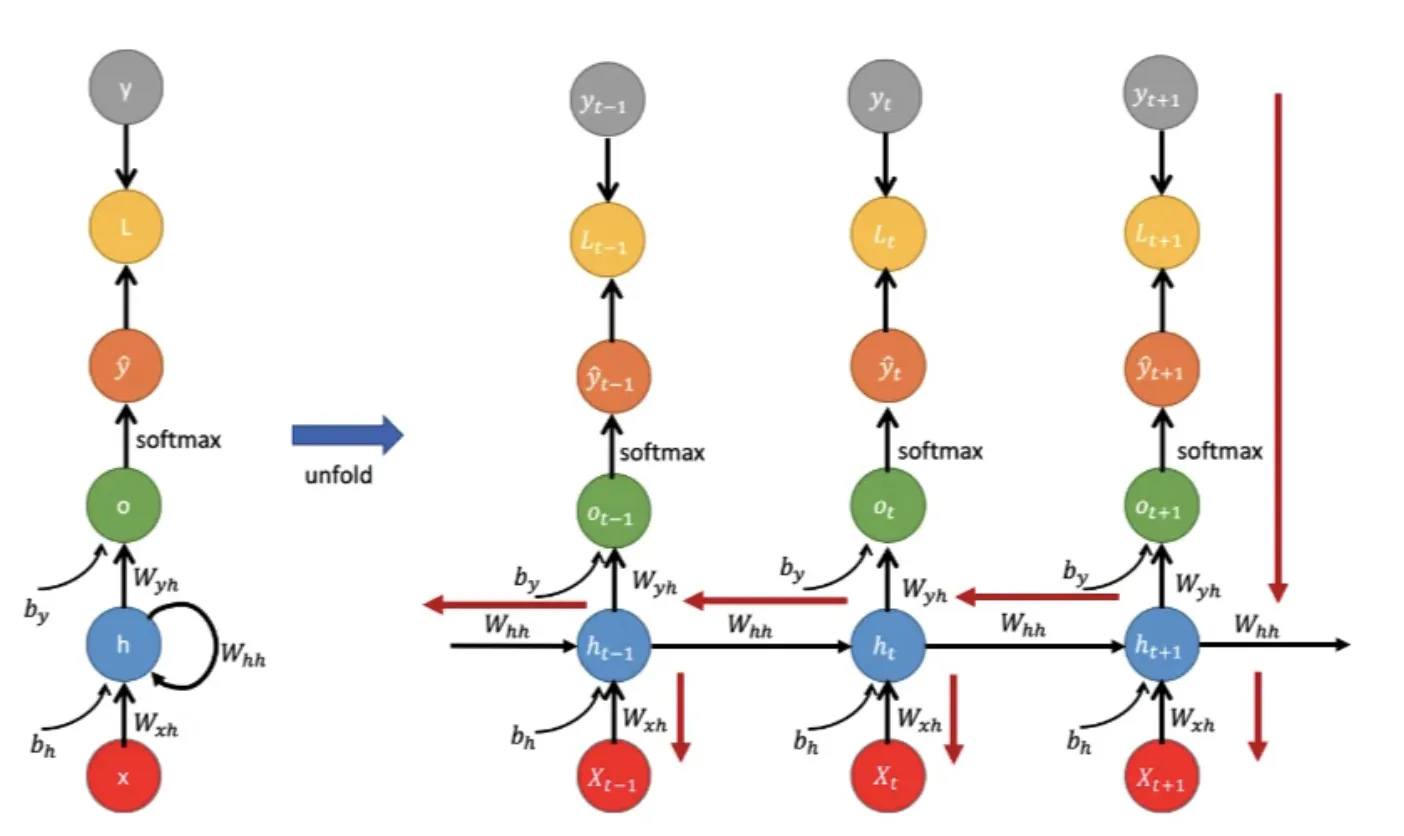 RNNの仕組み
RNNの仕組み
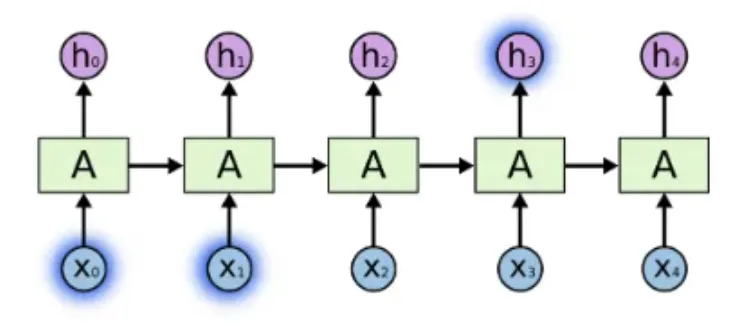 RNNは短い文章だと有効
RNNは短い文章だと有効
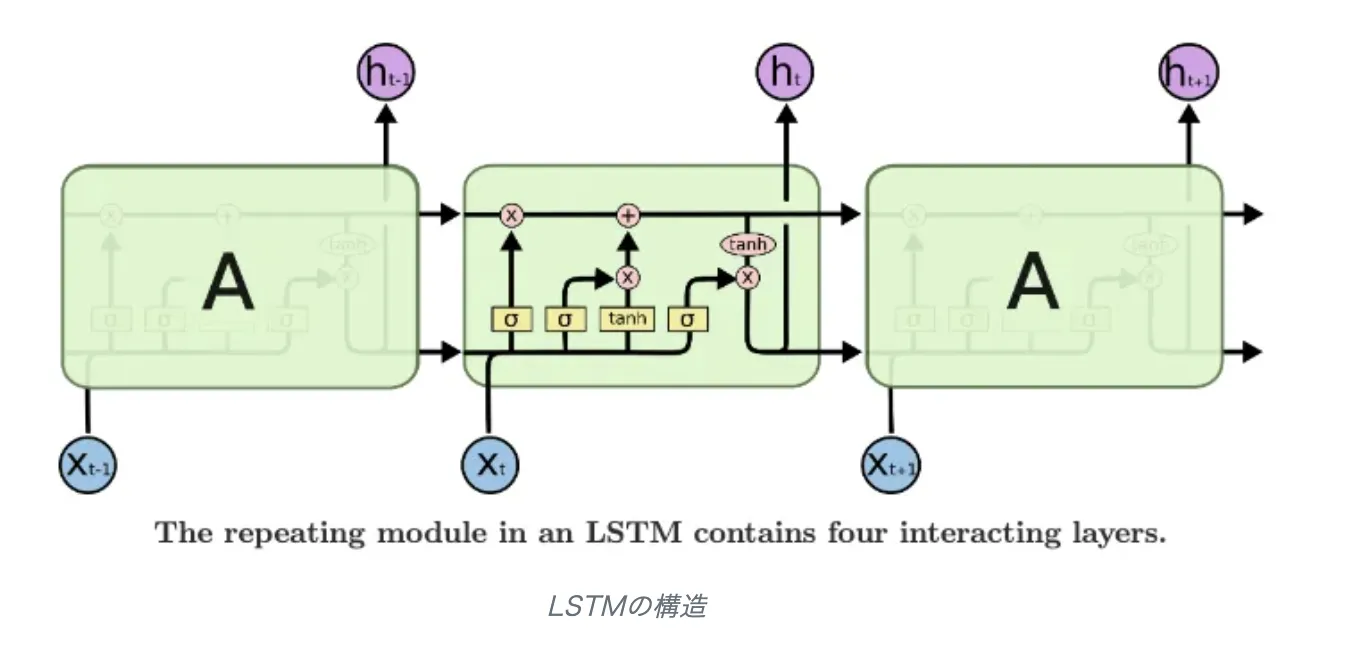 LSTMの構造
LSTMの構造
畳み込み・再帰・注意機構の3大アーキテクチャ比較と選定基準
ディープラーニングモデルの選定では、入力データの種類、シーケンス長、計算リソース、精度要件を総合的に評価する必要があります。以下の表で、主要3アーキテクチャの特性を比較しました。
| 項目 | CNN | RNN/LSTM | Transformer |
|---|---|---|---|
| 得意な入力 | 画像・動画・空間データ | 時系列・音声・センサーデータ | テキスト・画像・マルチモーダル |
| 計算量 | O(k x n)(カーネルサイズ x 入力長) | O(n)(入力長に線形) | O(n^2)(入力長の二乗) |
| 並列処理 | 高い(畳み込みは並列可) | 低い(逐次処理が必要) | 高い(注意機構は完全並列) |
| 長期依存関係 | 局所的(受容野に制限) | LSTM/GRUで改善も限界あり | 優れている(全入力を直接参照) |
| 2026年の主流用途 | 物体検出・医療画像・自動運転 | エッジAI・組み込みセンサー | LLM・画像生成・マルチモーダルAI |
| 代表的モデル | ResNet・EfficientNet・YOLO v10 | LSTM・GRU・Bi-LSTM | GPT-5.x・Claude 4.x・Gemini 3 |
この比較から分かるのは、2026年のディープラーニングにおいてTransformerが圧倒的な主流であるという現実です。ただし、CNNはリアルタイム物体検出(YOLO v10)や医療画像解析では依然として第一選択であり、RNN/LSTMは計算リソースが限られるエッジデバイスやIoTセンサーの時系列処理で活用されています。実務での選択基準は、まずタスクの種類(画像/テキスト/時系列)で大分類し、次に計算リソースとレイテンシ要件で最終決定するのが一般的です。
応用事例と市場規模の比較
ディープラーニングは、2026年現在、ほぼすべての産業分野で実用化が進んでいます。以下の表で、主要な応用分野と代表的な成果を整理しました。
| 分野 | 応用例 | 2026年の代表的成果 |
|---|---|---|
| 画像認識 | 顔認証・自動運転・品質検査 | Tesla FSD v13(市街地完全自律走行)、YOLO v10リアルタイム検出 |
| 自然言語処理 | 対話AI・翻訳・要約 | GPT-5.x・Claude 4.x・Gemini 3による高精度推論と100万+トークン処理 |
| 創薬 | 分子設計・標的探索・臨床試験最適化 | AlphaFold 3による分子間相互作用予測、AI設計薬のPhase I成功率81%(従来52%) |
| 音声認識 | 文字起こし・音声合成・翻訳 | Whisper v4による50+言語リアルタイム認識、Personal Voiceによる合成 |
| 生成AI | テキスト・画像・動画生成 | Sora 2動画生成、Midjourney V7高品質画像、音楽生成Suno v4 |
| ロボティクス | 自律移動・マニピュレーション | Figure 02・Tesla Optimus二足歩行ロボット、Boston Dynamics Atlas |
この応用事例の中で特に実務的インパクトが大きいのは、創薬と生成AIの2分野です。AlphaFold 3は2024年の発表以来、タンパク質だけでなくDNA、RNA、低分子化合物との相互作用予測を可能にし、従来3〜5年かかっていた標的探索フェーズを数週間に短縮しています。2026年1月時点でAI創薬プログラムは200件以上が臨床段階に進んでおり、AI設計薬のPhase I成功率は81%と従来の52%を大幅に上回っています。
生成AI分野では、ディープラーニングの各アーキテクチャが融合したマルチモーダルAIが主流となり、テキスト・画像・音声・動画を統合的に処理するモデルが実用化されています。アノテーションにかかるコストも合成データ生成の進展により削減が進んでおり、高品質な学習データの調達コストが低下しています。
画像認識・自然言語処理・創薬の活用事例と導入成果
画像認識分野では、製造業の品質検査が最も成熟した適用領域です。トヨタの品質検査システムは見逃し率ゼロを達成し、日本精工の外観検査は99.9%の精度で不良品を自動検出しています。自動運転分野ではTesla FSD(Full Self-Driving)がVersion 13で市街地での完全自律走行に対応し、WaymoはSan Franciscoを含む20都市以上で自律運転タクシーサービスを展開しています。
自然言語処理では、GPT-5.xやClaude 4.x、Gemini 3などの基盤モデルが100万トークン以上のコンテキストウィンドウを持ち、書籍全体の要約や大規模コードベースの理解が1回の推論で処理可能になっています。企業導入の観点では、パナソニック コネクトが全社12,400名にAIアシスタントを展開し、年間44.8万時間の業務時間削減を達成した事例が代表的です。
創薬では、Insilico MedicineがAIで設計した特発性肺線維症治療薬INS018_055がPhase IIa試験で安全性の主要エンドポイントを達成し、Phase IIbへの移行を計画しています。標的探索から臨床試験候補の特定までを18か月で完了した点が注目されています。Recursion Pharmaceuticalsは独自のOS-2プラットフォームで23のプログラムを同時並行で進め、従来比で開発コストを40-60%削減しています。

課題と学習ガイド
ディープラーニングの実用化と学習に際しては、技術的・社会的な課題を把握しておく必要があります。以下の表で主要な検討項目を整理しました。
| 課題 | 詳細 |
|---|---|
| 計算コストとエネルギー消費 | 大規模モデルの学習には数千GPU・数百万ドルのコストと莫大な電力を要する。GPT-4の学習には推定$100M以上、CO2排出量は自動車の生涯排出量の5倍以上 |
| データ品質とアノテーションコスト | モデル精度は学習データの品質に依存する。RLHFの人手アノテーションコストは600件で$60,000に達し、2023→2024でラベリングコストは88倍増 |
| ブラックボックス性と説明可能性 | ディープラーニングモデルの判断プロセスは人間にとって不透明。医療・金融・法律分野ではXAI(説明可能なAI)技術の導入が規制要件となりつつある |
| 規制とガバナンス | EU AI Act(2026年8月2日完全施行)、日本AI推進法(2025年9月施行)により、高リスクAIシステムへの透明性要件や影響評価が義務化 |
| セキュリティリスク | 敵対的攻撃(Adversarial Attack)によるモデルの誤判定、学習データからの個人情報抽出(メンバーシップ推論攻撃)、データポイズニングのリスク |
特に注意が必要なのは、計算コストとエネルギー消費の問題です。Epoch AIの調査によれば、AI学習に使用される計算量は3.4か月ごとに倍増しており、IEAは2026年のデータセンター電力消費が全世界の電力需要の4%以上に達すると予測しています。MoEアーキテクチャやモデル蒸留、量子化(INT4/INT8)などの効率化技術が進んでいますが、スケーリング則に基づく大規模化の圧力は継続しています。
ディープラーニングの技術的課題と対策
社会的課題に加えて、ディープラーニングのモデル学習自体にも固有の技術的課題が存在します。実装や運用で直面しやすい代表的な3つの問題を把握しておくことが重要です。
-
勾配消失問題
ネットワークの層が深くなると、誤差逆伝播(Backpropagation)の過程で勾配が極端に小さくなり、入力に近い層の重みがほとんど更新されなくなる現象です。RNNで特に顕著であり、LSTMのゲート機構やResNetのスキップ接続、Batch Normalizationなどの手法で緩和されています。
-
過学習(Overfitting)
学習データに対して高い精度を示すものの、未知のデータに対する汎化性能が低下する状態です。データ拡張(Data Augmentation)、ドロップアウト(Dropout)、正則化(L1/L2正則化)、早期停止(Early Stopping)が代表的な対策で、事前学習済みモデルの転移学習も少量データでの過学習防止に効果的です。
-
局所最適解
損失関数の最適化において、大域的な最適解ではなく局所的な最適解に収束してしまう問題です。学習率スケジューリング(Cosine Annealing、Warm-up)や確率的勾配降下法(SGD)のモメンタム、Adam/AdamWオプティマイザの使用、バッチサイズの調整で回避を試みます。実務上は、適切なハイパーパラメータ探索(Optuna等のAutoML手法)を組み合わせることが一般的です。
これらの技術的課題は、フレームワーク側のサポートが進んだ2026年現在でも完全には解消されていません。特に新規モデルの構築やファインチューニングの際には、学習曲線やバリデーション精度の推移を注視し、適切な対策を組み合わせる必要があります。
学習ロードマップとFAQ
ディープラーニングの学習は、以下の3ステップで段階的に進めることを推奨します。
-
ステップ1 基礎理論とPythonプログラミング(1〜2か月)
線形代数・微積分・確率統計の基礎を確認し、PythonとNumPyの基本操作を習得します。CourseraのAndrew Ng「Deep Learning Specialization」やFast.aiの「Practical Deep Learning for Coders」は2026年も最も推奨される入門コースです。日本語の学習リソースとしては、Preferred Networksの「ディープラーニング入門:Chainerチュートリアル」が数学的基礎からの学習に適しています。
-
ステップ2 フレームワーク実践とモデル構築(2〜3か月)
PyTorch 2.x(2026年のデファクトスタンダード)でCNN・RNN・Transformerの基本実装を経験します。PyTorch公式チュートリアルとHugging Face Transformersライブラリのチュートリアルを組み合わせ、画像分類・テキスト分類・ファインチューニングの実践プロジェクトを完了します。
-
ステップ3 専門分野への応用と実務プロジェクト(3〜6か月)
Kaggleコンペティションへの参加やHugging Faceへのモデル公開を通じて実践力を磨きます。専門分野(自然言語処理、コンピュータビジョン、音声処理など)の最新論文を追い、ファインチューニングやRAG(Retrieval-Augmented Generation)の実装まで到達することを目標とします。
以下は、ディープラーニングの学習を始める際によくある質問とその回答です。
-
ディープラーニングの学習にGPUは必須か
基礎的な学習であればGoogle Colabの無料GPU(T4)で十分です。本格的なモデル学習にはNVIDIA RTX 4070以上(VRAM 12GB+)が推奨されますが、クラウドGPU(AWS、Azure、Lambda Cloud)を時間課金で利用する選択肢もあります。学習の初期段階ではGPUよりも理論の理解とコードの書き方に集中すべきです。
-
PyTorchとTensorFlowのどちらを学ぶべきか
2026年現在、研究・産業の両方でPyTorchが主流です。学術論文の80%以上がPyTorchを使用しており、Hugging Face、Meta AI、OpenAIのライブラリもPyTorchベースです。TensorFlowはモバイル・組み込み展開(TensorFlow Lite)に強みがありますが、最初に学ぶフレームワークとしてはPyTorchを推奨します。
-
機械学習とディープラーニングはどう使い分けるべきか
表形式データ(売上予測・顧客分類など)にはXGBoostやLightGBMなどの勾配ブースティング手法が依然として第一選択です。画像・テキスト・音声などの非構造化データにはディープラーニングが適しています。データ量が少ない場合(数百件以下)は機械学習手法のほうが安定した結果を得られます。
-
数学がわからなくてもディープラーニングは学べるか
フレームワークが計算を抽象化しているため、実装レベルでは高度な数学知識なしでも始められます。ただし、モデルの挙動を理解しデバッグするためには、行列演算、偏微分(勾配降下法の理解)、確率分布の基礎知識が不可欠です。Andrew Ngのコースは数学的前提を最小限に抑えつつ直感的な理解を重視しており、数学に自信のない方にも適しています。
-
ディープラーニングエンジニアの年収はどの程度か
日本国内のディープラーニングエンジニアの年収は600万〜1,200万円(経験3年以上)、LLM・基盤モデルの専門性がある場合は1,000万〜2,000万円です。米国ではML Engineerの中央値が$180,000、基盤モデル関連のポジションでは$250,000〜$400,000に達しています。

ディープラーニングの技術知識を組織のAI業務活用に結びつける
ディープラーニングの原理と応用事例を理解した今、次のステップは自社の業務課題にこの技術をどう適用するかを設計することです。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に設計する実践ガイド(220ページ)を無料で提供しています。AI技術の業務適用を部門別のBefore/After付きユースケースで具体化し、PoC→段階展開の実践的なロードマップを提示しています。
AI総合研究所が、ディープラーニングの技術的理解を組織の業務改善に直結させるガイドをお届けします。
ディープラーニングを業務活用に繋げる

段階的なAI導入の実践ガイド(220p)
ディープラーニングの仕組みを理解した次は、AI技術を組織の業務プロセスへどう組み込むかの段階設計です。部門別のBefore/Afterと導入ロードマップを220ページの実践ガイドにまとめました。
まとめ
本記事では、ディープラーニングの基本原理、主要アーキテクチャ(CNN・RNN・Transformer)の比較、2026年の応用事例、課題、学習ロードマップについて解説しました。
ディープラーニングは、自動特徴抽出による高精度なパターン認識を核に、画像認識・自然言語処理・創薬・自動運転・生成AIなど広範な分野で革新を生んでいる技術です。2026年にはTransformerベースの基盤モデルとState Space Model、MoEアーキテクチャの3つが技術の中心であり、市場規模は$309億(2024年)から年率約30%で成長しています。
まずはステップ1のCourseraまたはFast.aiでの基礎理論学習から着手し、PyTorch 2.xでの実装経験を積みながら、専門分野のプロジェクトに取り組むことで実践力を構築することを推奨します。










