この記事のポイント
 時系列予測やセンサ異常検知のように数十〜数百ステップの逐次データを扱うなら、2026年でもLSTMはN-BEATS・TFT・TCNなどと並ぶ有力なベースライン候補の一つ
時系列予測やセンサ異常検知のように数十〜数百ステップの逐次データを扱うなら、2026年でもLSTMはN-BEATS・TFT・TCNなどと並ぶ有力なベースライン候補の一つ- 長文翻訳・要約・QAなど自然言語処理の主戦場は[Transformer](https://www.ai-souken.com/article/transformer-overview)に移ったが、LSTMの設計思想は今も次世代モデルに引き継がれている
- 2024年発表の[xLSTM](https://arxiv.org/abs/2405.04517)は7Bモデルでも線形時間複雑性を保ち、Hochreiter本人による「RNN復権」プロジェクトとして注目される
- Uber配車需要予測・Google翻訳GNMTなどの実運用事例に加え、Volvo Discovery Challengeなど研究・競技領域でも採用実績が蓄積されている
- 学習データが少なくGPU資源も限られる中小規模プロジェクトでは、Transformerより[LSTM](https://en.wikipedia.org/wiki/Long_short-term_memory)の方が安全に立ち上がる

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
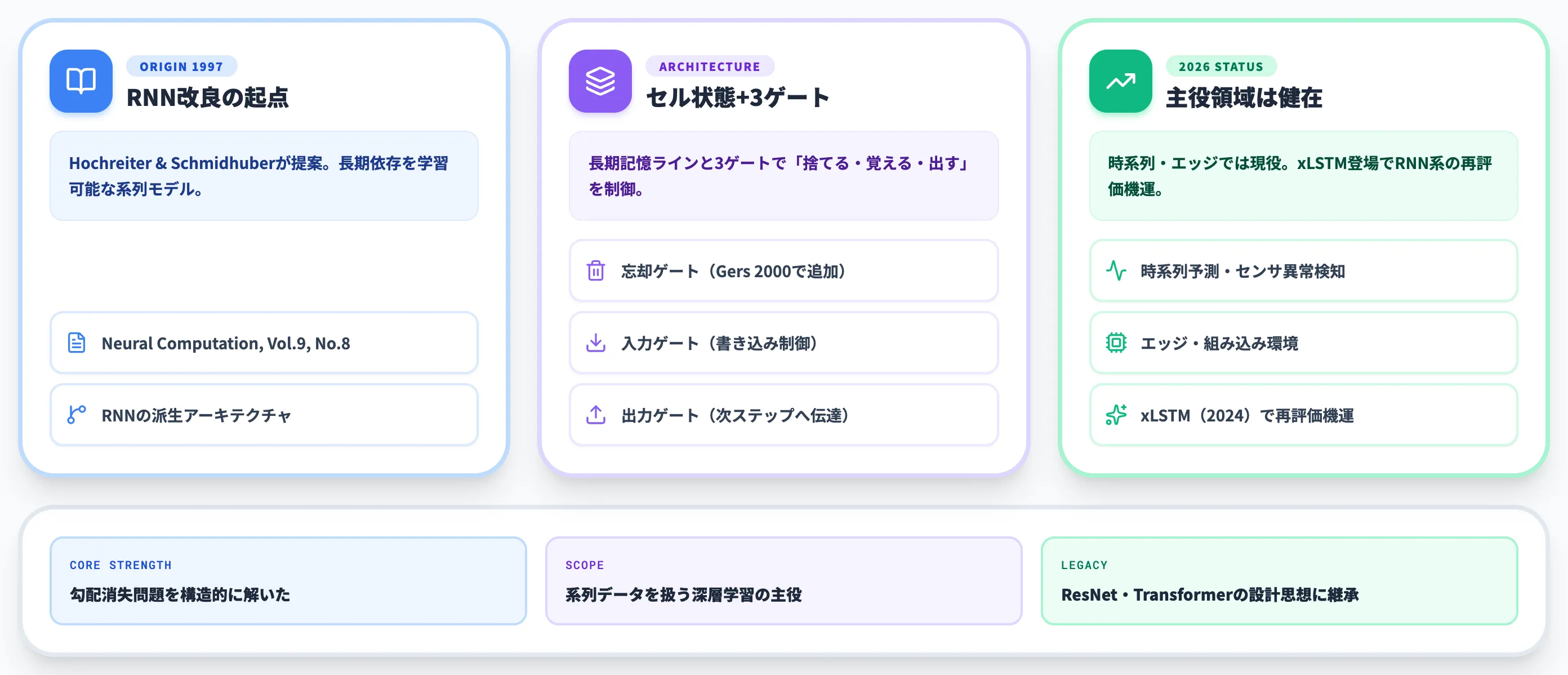
LSTM(Long Short-Term Memory:長・短期記憶)は、1997年にHochreiterとSchmidhuberが発表した、長期の依存関係を学習できる再帰型ニューラルネットワーク(RNN)の改良版です。
従来のRNNが抱えていた「勾配消失問題」を、1997年原論文で導入された入力・出力ゲートと記憶セル、加えてGers et al. 2000で追加された忘却ゲートを含む現在の3ゲート構成で克服し、自然言語処理・音声認識・時系列予測など系列データを扱うあらゆる分野で長年の主役を担ってきました。
2017年にTransformerが登場して以降、長文の自然言語処理ではAttention機構に主役を譲りましたが、時系列予測や産業センサデータ分析、エッジ環境での推論など、LSTMが今も有力なベースライン候補として残り続ける領域は明確に存在します。
2024年5月にはSepp Hochreiter本人らがxLSTMを発表し、2025年10月公開・2026年2月改訂のxLSTM Scaling Laws論文では「Transformerをパレート支配する」スケーリング結果も報告され、RNN系アーキテクチャは再評価の局面を迎えています。
本記事では、LSTMの仕組み(記憶セル+3つのゲート)、RNN/GRU/Transformer/xLSTM/Mambaとの違い、Uber配車需要予測・Google翻訳GNMTといった実運用事例とVolvo Discovery Challengeなどの研究・競技事例、2026年時点でLSTMを選ぶべきケース別の判断軸、Pythonでの実装基礎、学習・運用コストまでを、一次情報に基づいて体系的に解説します。
目次
LSTM(Long Short-Term Memory)とは
忘却ゲート(Forget Gate)——「何を忘れるか」を決める
入力ゲート(Input Gate)——「何を覚えるか」を決める
出力ゲート(Output Gate)——「何を次に伝えるか」を決める
LSTMの主な活用事例——時系列予測・自然言語処理・音声認識
Volvo——Volvo Discovery ChallengeでLSTMが故障リスク予測に活用された研究事例
Google翻訳——GNMT(Google Neural Machine Translation)の主役
2026年のLSTMの現在地——xLSTM・Mambaが登場した今
xLSTM——Hochreiter本人によるRNN復権プロジェクト
LSTM(Long Short-Term Memory)とは
LSTM(ロング・ショート・ターム・メモリ/長・短期記憶)は、長期の依存関係を学習できるよう設計された再帰型ニューラルネットワーク(RNN)の派生アーキテクチャです。
ディープラーニングの中で系列データを扱う代表的なモデルの一つとして広く使われており、1997年にSepp HochreiterとJürgen Schmidhuberが論文「Long Short-Term Memory」(Neural Computation, Vol.9, No.8)で提案しました。
通常のRNNは時系列データを扱えますが、系列が長くなると「勾配消失」によって遠い過去の情報が学習に効かなくなる構造的な弱点を抱えていました。
LSTMは、長期の情報を保持する「セル状態」と、その読み書きを制御する3つのゲートを導入することでこの問題を解き、自然言語処理・音声認識・時系列予測など、系列データを扱う深層学習の主役を長年務めてきたモデルです。

LSTMが解決した課題——RNNの勾配消失問題

LSTMの存在意義を理解するには、まずRNNが抱えていた問題を押さえる必要があります。
通常のRNNは、時刻 t の隠れ状態 h_t を直前の h_(t-1) と入力 x_t から計算する、シンプルなループ構造を持ちます。
理論上は過去のすべての情報を保持できるはずですが、逆伝播(バックプロパゲーション)の過程で勾配が指数関数的に減衰し、数十ステップ以上前の情報を学習しづらくなる——これが勾配消失問題です。
その結果、通常のRNNは「文章の冒頭の主語」を文末まで覚えていられない、株価の数か月前のトレンドを反映できない、といった限界を抱えていました。
LSTMはこの問題を、後述する記憶セルとゲート機構によって、構造レベルで回避しています。
2026年時点でのLSTMの位置づけ

2017年のTransformer登場以降、自然言語処理の主戦場はAttention機構へ移り、LSTMが直接の主役を張る場面は減りました。
一方で、2026年現在でもLSTMが有力な選択肢として残っている領域は明確に存在します。以下の表で、LSTMの今の立ち位置を整理しました。
| 領域 | 2026年時点の主流 | LSTMの位置づけ |
|---|---|---|
| 長文NLP(翻訳・要約・QA) | Transformer系(BERT・GPT等) | 主役から退いた |
| 時系列予測(需要・センサ・金融) | LSTM・GRU・N-BEATS・TFT・TCN・Transformer時系列モデル | 今も有力な候補の一つ |
| 音声認識(オンライン処理) | TransformerベースのASRに移行が進む | エッジ環境では現役 |
| エッジ・組み込みでの推論 | 軽量モデル中心 | パラメータ数が抑えやすく実装しやすい |
| 超長系列(数十万トークン超) | Mamba・xLSTMなど線形時間モデル | xLSTMはLSTMの正統進化版 |
「LSTMはもう古い」と言われがちですが、実際は領域ごとに主役が入れ替わっただけで、エッジAI・産業センサ・短〜中期の時系列予測などでは今も多くの実プロダクトを支える技術です。
さらに、2024年5月にHochreiter本人らがxLSTM論文を発表し、2025年10月公開・2026年2月改訂のxLSTM Scaling Lawsでは「TransformerをパレートドミネートしながらO(n)の計算量を保つ」結果が報告されたことで、RNN系の再評価機運も高まっています。
LSTMの仕組み——記憶セルと3つのゲート
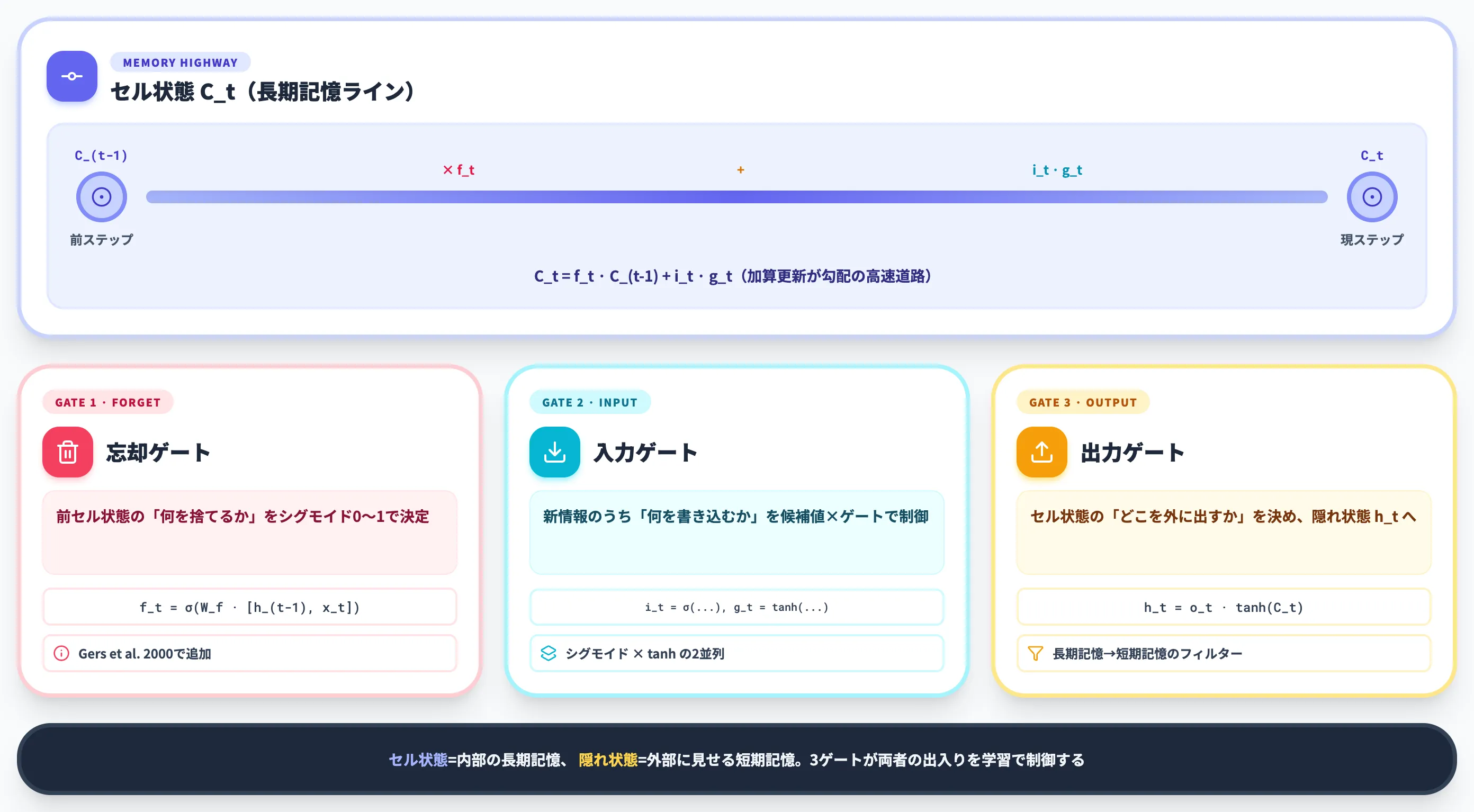
LSTMの内部構造を一言で言えば、**「長期記憶を保持するセル状態(Cell State)と、その内容を読み書きする3つのゲート(忘却・入力・出力)」**の組み合わせです。
通常のRNNが「隠れ状態 h_t」だけで情報を引き継ぐのに対し、LSTMは隠れ状態に加えてセル状態 C_t という独立した記憶ラインを持ちます。
このセル状態がいわば情報の高速道路で、3つのゲートが「どの情報を捨てるか/加えるか/出力するか」を学習で制御することで、長期情報を安定して維持する仕組みです。
以下の表で、LSTM 1セル分の主要構成要素を整理しました。
| 構成要素 | 役割 | 演算の概略 |
|---|---|---|
| セル状態 C_t | 長期記憶を保持する独立ライン | 前ステップの C_(t-1) にゲートで調整した加減算 |
| 忘却ゲート f_t | 過去のセル状態のうち何を捨てるか | シグモイドで0〜1の重みを生成 |
| 入力ゲート i_t | 新しい情報のうち何をセル状態に加えるか | シグモイド+tanhで候補値と重みを生成 |
| 出力ゲート o_t | セル状態のどの部分を次の隠れ状態へ出すか | シグモイド×tanh(C_t) |
| 隠れ状態 h_t | 次層・次ステップに渡される短期記憶 | 出力ゲートを通したセル状態 |
各ゲートはシグモイド関数(0〜1の値)で「どれだけ通すか」を表現しており、学習が進むにつれて「重要な情報は長く保持し、不要な情報は捨てる」挙動を獲得します。
詳細はChristopher Olahの解説記事「Understanding LSTM Networks」が事実上の標準教材として広く参照されています。
忘却ゲート(Forget Gate)——「何を忘れるか」を決める
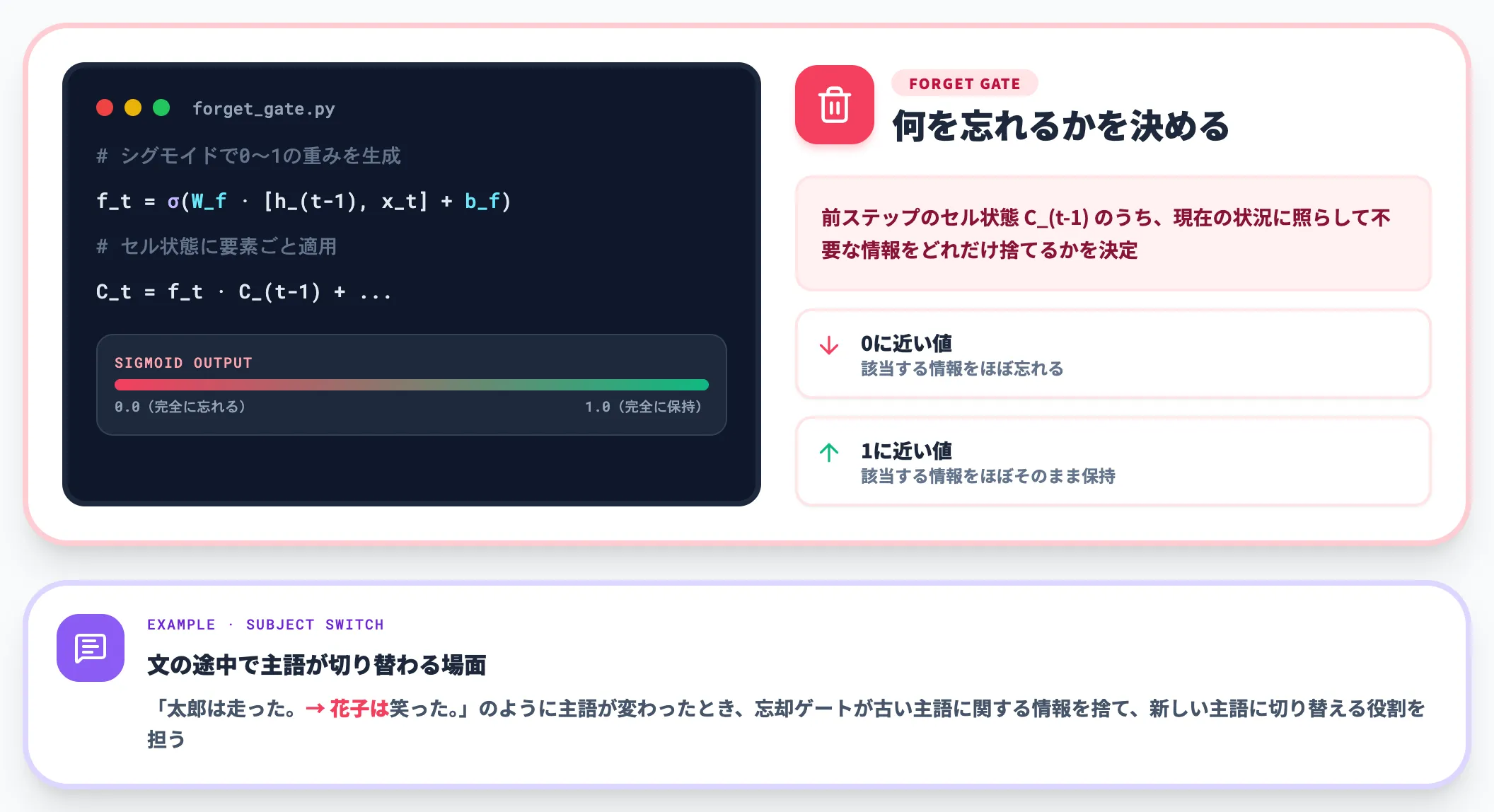
忘却ゲートは、前ステップのセル状態 C_(t-1) のうち、現在の状況に照らして不要な情報をどれだけ捨てるかを決定するゲートです。
入力 x_t と前ステップの隠れ状態 h_(t-1) を受け取り、シグモイド関数で0〜1の値を出力します。
- 0に近い値: 該当する情報を「ほぼ忘れる」
- 1に近い値: 該当する情報を「ほぼそのまま保持する」
例えば文章の途中で主語が変わったとき、忘却ゲートが古い主語に関する情報を捨て、次の主語に切り替える役割を担います。
忘却ゲートはLSTMの中で最も後から、Gers et al. 2000(Neural Computation Vol.12 No.10)によって追加されたゲートですが、長期依存学習を実用レベルに引き上げた決定的なパーツとされています。1997年原論文時点のLSTMは入力ゲートと出力ゲートのみで構成されており、忘却ゲートを含む現在の3ゲート構成はGersらの提案以降に標準化されたものです。
入力ゲート(Input Gate)——「何を覚えるか」を決める
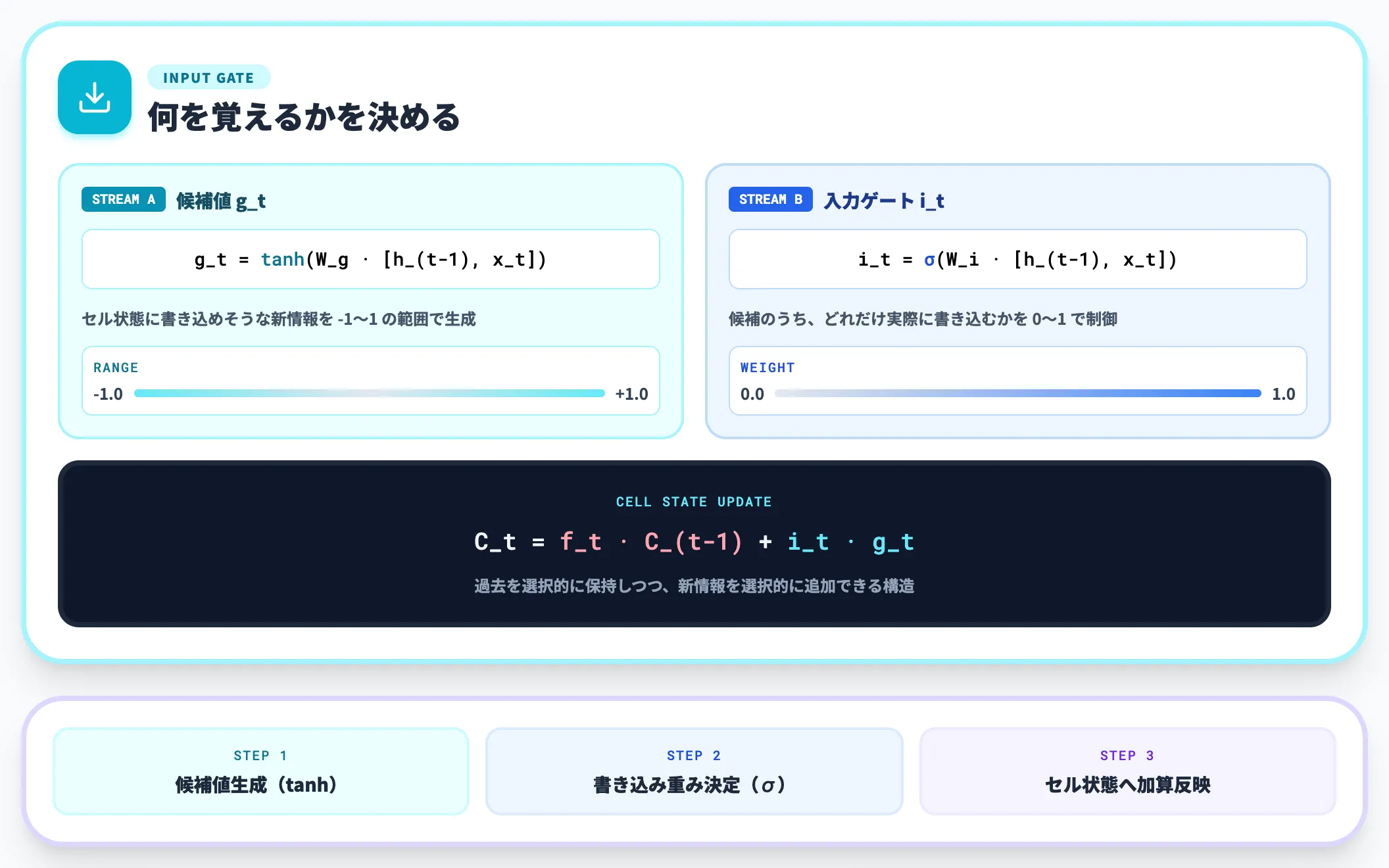
入力ゲートは、現在の入力 x_t と前隠れ状態 h_(t-1) から作った候補値のうち、セル状態に新しく書き込む量を制御します。
内部では2つの計算が並列で走ります。
- 候補値 g_t(tanh): セル状態に書き込めそうな新情報を-1〜1の範囲で生成
- 入力ゲート i_t(シグモイド): その候補のうち、どれだけ実際に書き込むかを0〜1で制御
セル状態 C_t は最終的に「前ステップの C_(t-1) × 忘却ゲート + 候補 g_t × 入力ゲート」の形で更新されます。これにより、過去の情報を選択的に保持しつつ、新しい情報を選択的に追加できる構造になっています。
出力ゲート(Output Gate)——「何を次に伝えるか」を決める
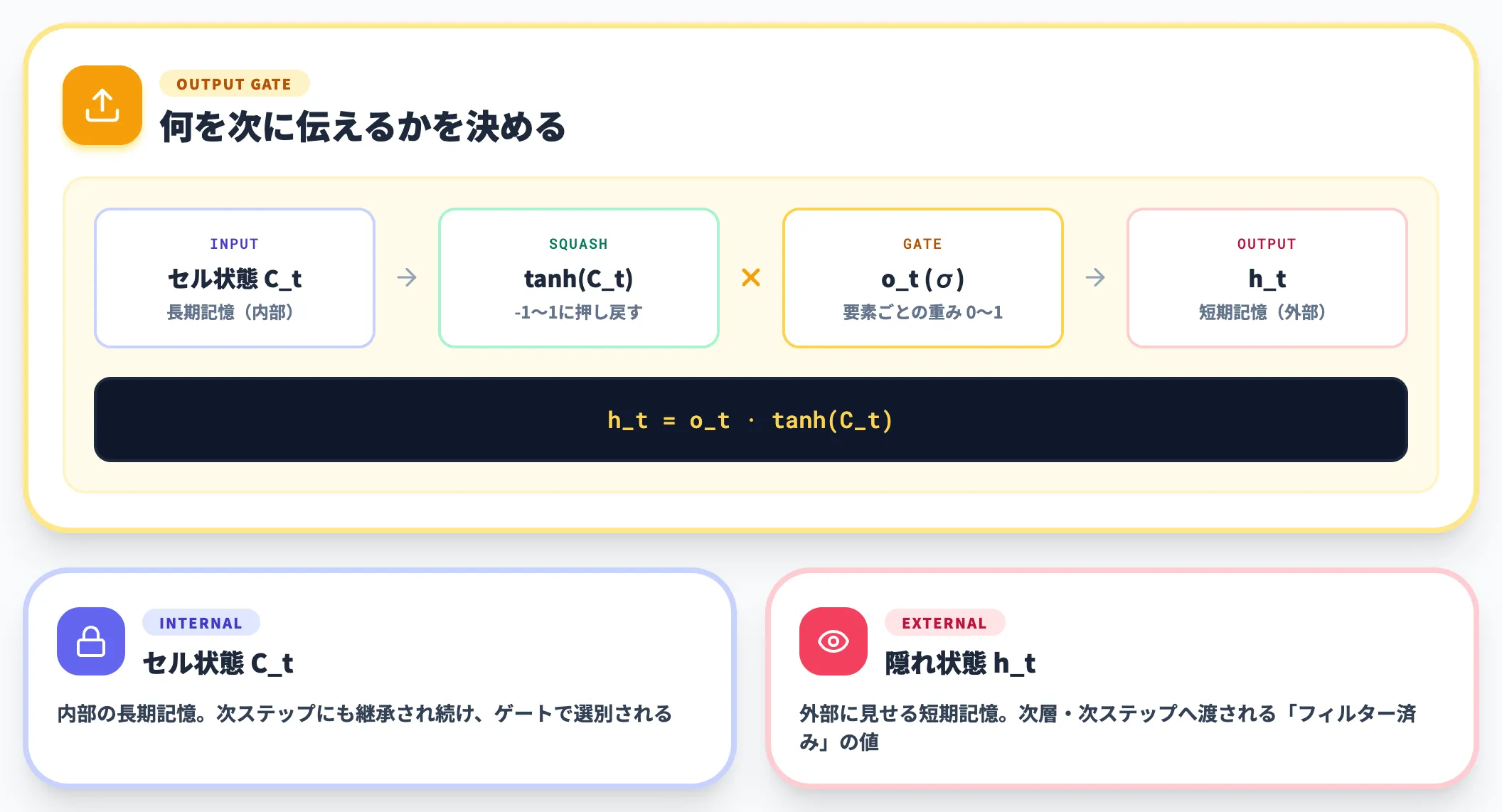
出力ゲートは、更新後のセル状態 C_t のうち、次の隠れ状態 h_t としてどの部分を外に出すかを決定します。
セル状態 C_t に tanh をかけて-1〜1に押し戻し、出力ゲート o_t(シグモイド)で要素ごとの重みを掛けたものが h_t になります。
セル状態は「内部の長期記憶」、隠れ状態は「外部に見せる短期記憶」と整理すると理解しやすく、出力ゲートはその間のフィルターの役割を果たしています。
なぜLSTMでは勾配が消えないのか
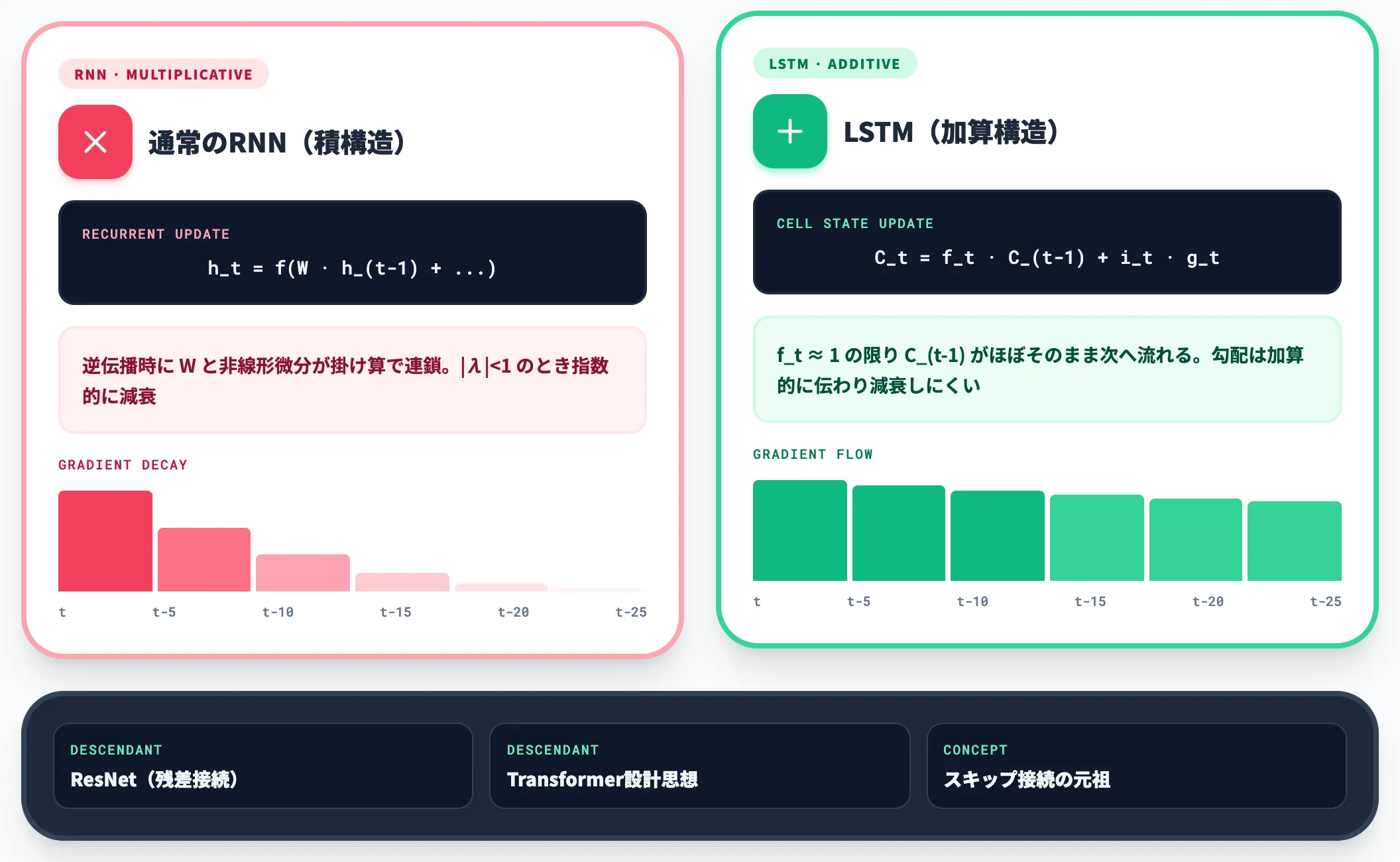
LSTMが勾配消失を回避できる本質は、セル状態 C_t の更新が「加算」を含む構造にある点です。
通常のRNNでは h_t = f(W·h_(t-1) + …) のように行列積と非線形変換の連続で、逆伝播時に勾配が積で連鎖し急速に小さくなります。
一方LSTMの C_t = f_t·C_(t-1) + i_t·g_t は、忘却ゲート f_t が1に近い限り C_(t-1) が「ほぼそのまま」次へ流れ、勾配は加算的に伝わるため減衰しにくい設計になっています。
これは後のResNet(残差接続)やTransformerの設計思想にもつながる重要なアイデアで、深層学習における**スキップ接続(情報の高速道路)**の元祖とも言えるアーキテクチャです。
LSTMとRNN・GRU・Transformerの違い

ここまでLSTMの内部を見てきましたが、実際に系列データを扱うときの選択肢は、機械学習の代表的な手法のうちRNN・LSTM・GRU・Transformerの4種類が中心になります。
それぞれは「系列を扱うニューラルネット」という共通点を持ちつつ、計算量・並列性・長期依存の捉え方が大きく異なるため、用途ごとに適性が分かれます。
以下の表で、4モデルの主要な違いを整理しました。
| モデル | 構造の核 | 計算量 | 長期依存 | 並列性 | 代表的な得意領域 |
|---|---|---|---|---|---|
| 通常のRNN | 隠れ状態の単純ループ | O(n) | 弱い(勾配消失) | 系列方向は逐次 | 短い系列の基礎モデル |
| LSTM | セル状態+3ゲート | O(n) | 強い | 系列方向は逐次 | 中長期の時系列・音声 |
| GRU | リセット+更新の2ゲート | O(n) | 強い | 系列方向は逐次 | LSTMより軽量な代替 |
| Transformer | 自己注意機構 | O(n²)(系列長) | 非常に強い | 高い(並列化可能) | 長文NLP・大規模学習 |
違いをイメージしやすくすると、**RNNは「読みながら忘れる人」、LSTMは「読みながら大事なところだけメモを残す人」、GRUはそのメモ術を簡略化した人、Transformerは「文章全体を一度に俯瞰する人」**と言えます。
ここからは各モデルとの差分を順に見ていきます。
LSTMと通常のRNNの違い
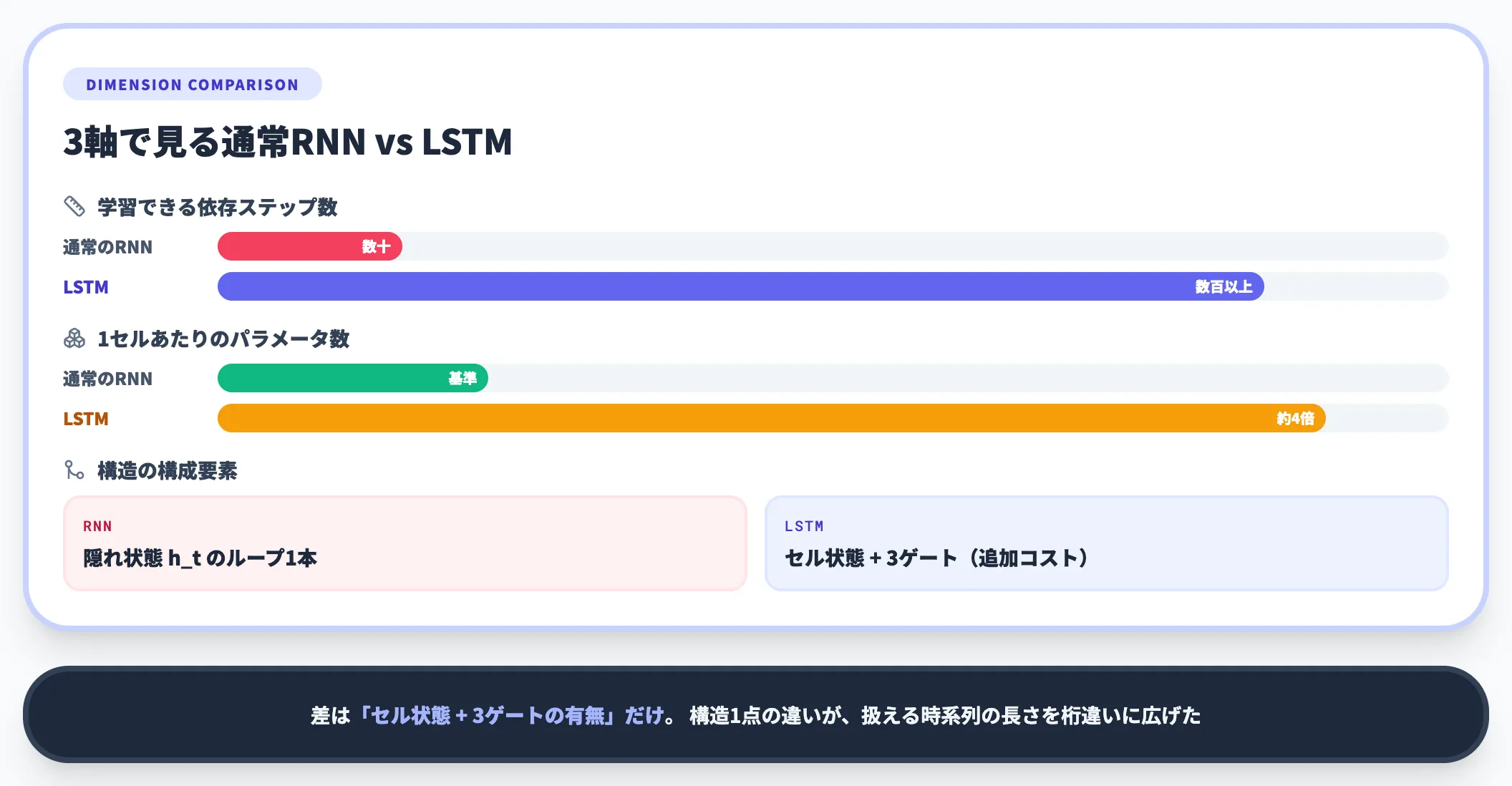
通常のRNNとLSTMの差は、「セル状態 + 3ゲートの有無」だけと言って差し支えありません。
通常のRNNでも理論上は任意長の系列を扱えますが、勾配消失の影響で、依存関係が長くなるほど学習が急速に難しくなる傾向が知られています。具体的な限界はタスクや活性化関数で変わるため固定値で言い切れませんが、数十ステップを超える長期依存は通常のRNNでは捉えにくくなります。
LSTMはセル状態の加算更新で勾配の流れを担保するため、数百ステップ以上の長期依存も学習可能になります。
ただし通常のRNNより1セルあたりのパラメータが約4倍に増えるため、計算コストとメモリ消費は重くなります。
LSTMとGRUの違い

GRU(Gated Recurrent Unit)は、2014年にCho et al.の論文で提案されたLSTMの簡略版です。LSTMが3ゲート+セル状態を持つのに対し、GRUはリセットゲートと更新ゲートの2ゲートだけで、セル状態を持たず隠れ状態に統合しています。
性能面ではタスクによりますが、概ね以下の傾向が知られています。
- GRUが有利: 系列が短め、データが少なめ、軽量モデルが欲しい場合
- LSTMが有利: 系列が長く、複雑な長期依存パターンを学習させたい場合
パラメータ数はGRUの方が約25%少なく、学習も推論も速くなりがちです。**「とりあえずGRUで動かして、性能が足りなければLSTMに置き換える」**というアプローチが、実装現場では現実的な定石になっています。
LSTMとTransformerの違い
Transformerは2017年にGoogle「Attention Is All You Need」論文で発表され、現在の大規模言語モデル(LLM)の基盤になっています。
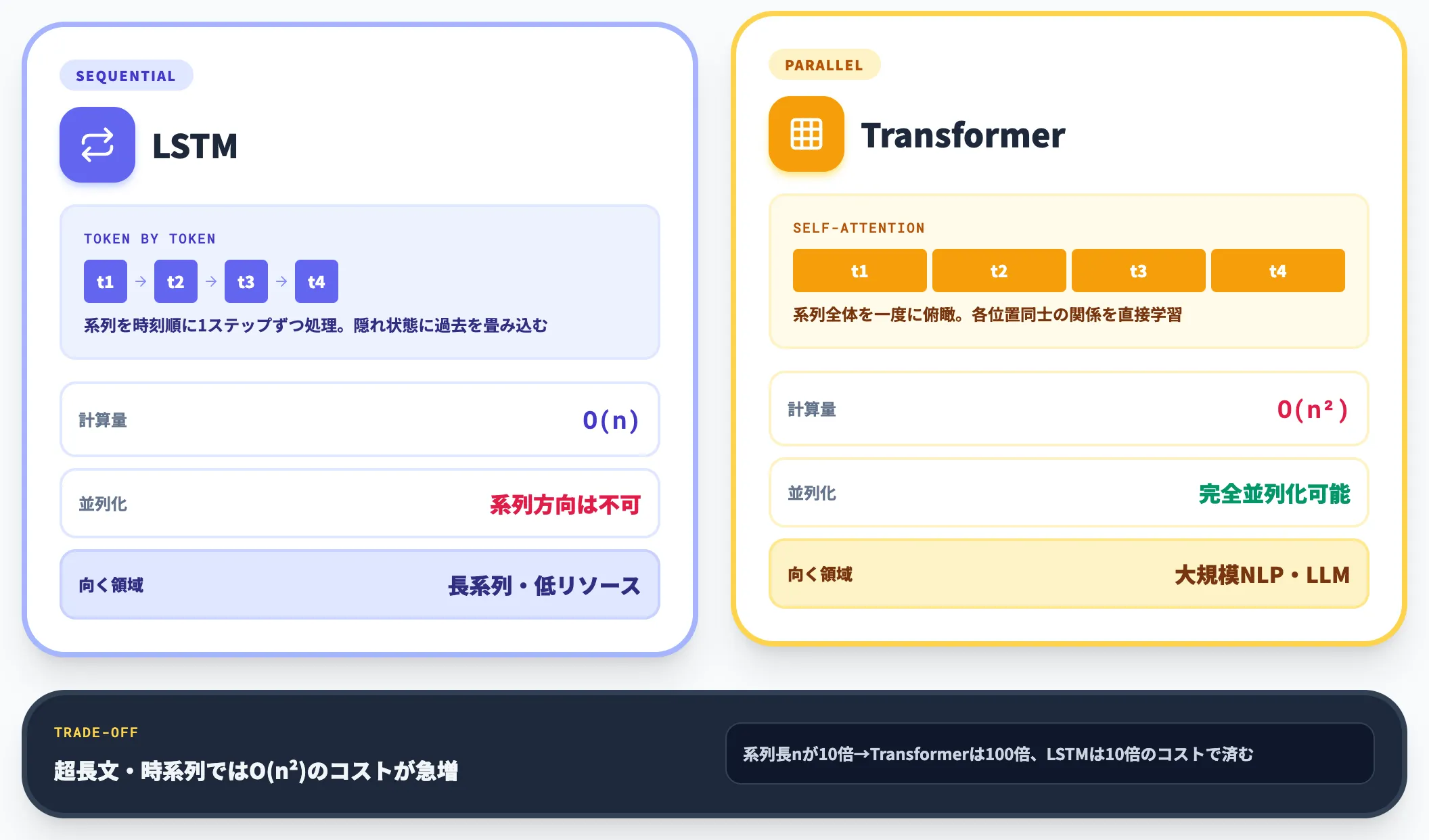
LSTMとTransformerの最大の違いは、情報の捉え方とそれに伴う並列性です。
- LSTM: 系列を時刻順に1ステップずつ処理し、隠れ状態に過去を畳み込む。系列方向の並列化は原理的に困難
- Transformer: 自己注意機構(Self-Attention)で系列全体を一度に俯瞰し、各位置同士の関係を直接学習。系列方向に完全並列化可能
その結果、Transformerはハードウェアの並列性能をフルに使えて学習速度で圧倒し、大規模言語モデルの主役を奪いました。
ただし自己注意機構は系列長nに対してO(n²)の計算量を要するため、超長文や時系列データではコストが急増します。LSTMは O(n) で済むため、長系列・低リソース環境ではむしろ有利に働きます。
LSTMの主な活用事例——時系列予測・自然言語処理・音声認識

LSTMは1997年の発表以来、20年以上にわたり多様な産業で実運用に組み込まれてきました。
ここではUber・Volvo・Googleなど一次情報が公開されている代表的な活用事例を中心に、LSTMが今も使われ続けている領域を見ていきます。
Uber——配車需要予測と極端イベント予測

Uber Engineering Blog「Engineering Extreme Event Forecasting at Uber with Recurrent Neural Networks」(2017年)では、UberがLSTMをベースにしたニューラルネットワークで配車需要を予測している事例が公開されています。
Uberはニューヨークシティのような大都市圏で、祝日・スポーツイベント・悪天候など**「過去の単純な傾向では捉えきれない極端な需要変動」を予測する必要があり**、従来の統計手法(指数平滑法やARIMA)では精度が不足していました。
LSTMが採用された理由は以下の3点と説明されています。
- エンドツーエンドの学習: 特徴量設計を最小化しながら時系列の複雑なパターンを獲得できる
- 外部変数の取り込みやすさ: 天候・イベント情報など複数系列を素直に統合できる
- 自動特徴抽出: 手動の特徴量エンジニアリングが大幅に削減される
後続のUber「Uncertainty Estimation in Neural Networks for Time Series Prediction」では、LSTMの予測に不確実性推定を組み合わせ、Anomaly Detection(異常検知)にも展開しています。
Volvo——Volvo Discovery ChallengeでLSTMが故障リスク予測に活用された研究事例
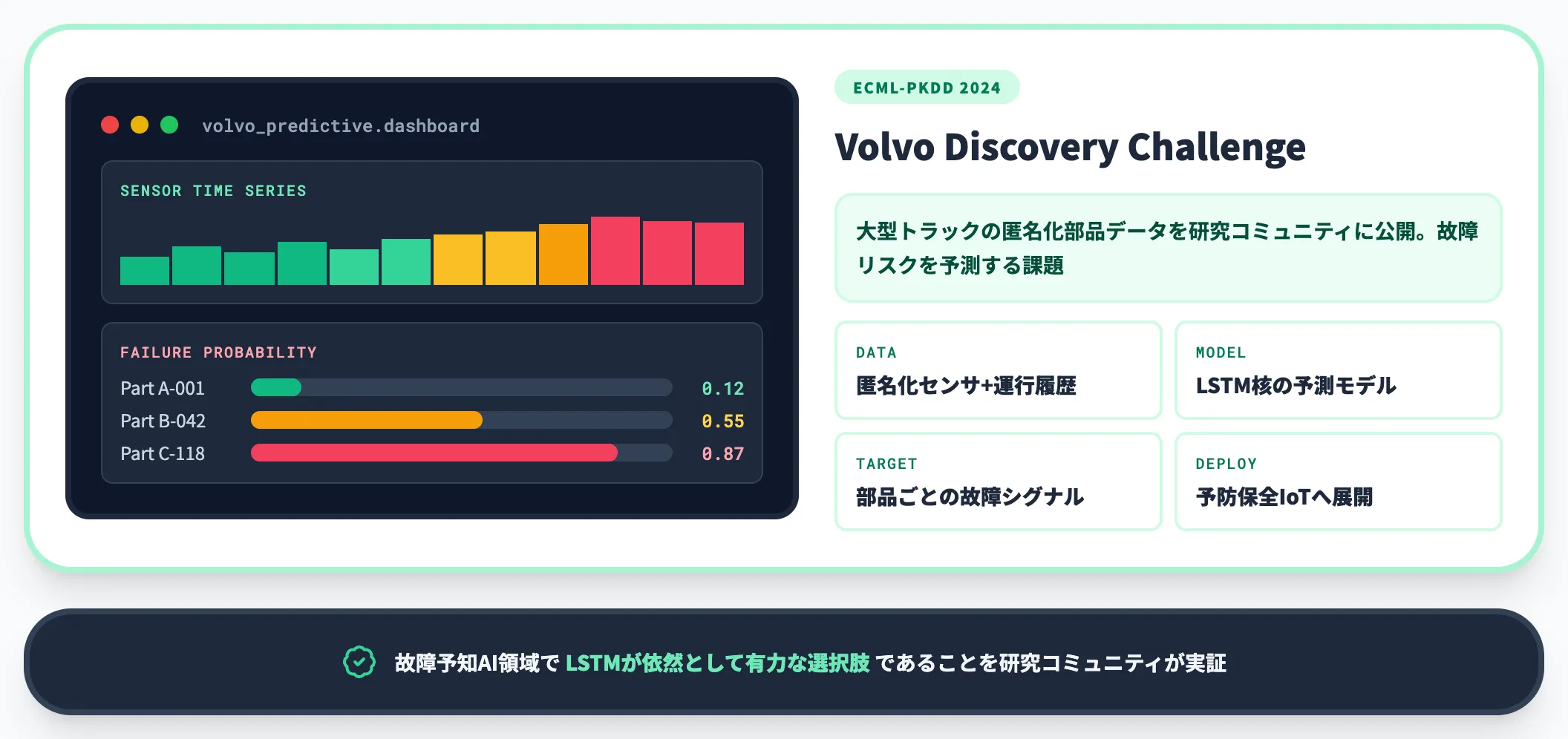
2024年のECML-PKDDで開催された「Volvo Discovery Challenge」では、Volvoから提供された大型トラックの匿名化部品データを用いて、部品の故障リスクを予測する課題が研究者・参加チームに公開されました。
参加チームの一部はLSTMを核とした予測モデルを構築し、センサデータと運行履歴から部品ごとの故障シグナルを学習しています。
Volvo公式の予防保全IoT事例(エンジン工場の生産設備モニタリング)はLSTM固有の言及こそ無いものの、Volvoが匿名化したトラックデータを研究コミュニティに公開する流れの中で、故障予知AI領域においてLSTMが依然として有力な選択肢の一つとして扱われていることが分かります。
Google翻訳——GNMT(Google Neural Machine Translation)の主役
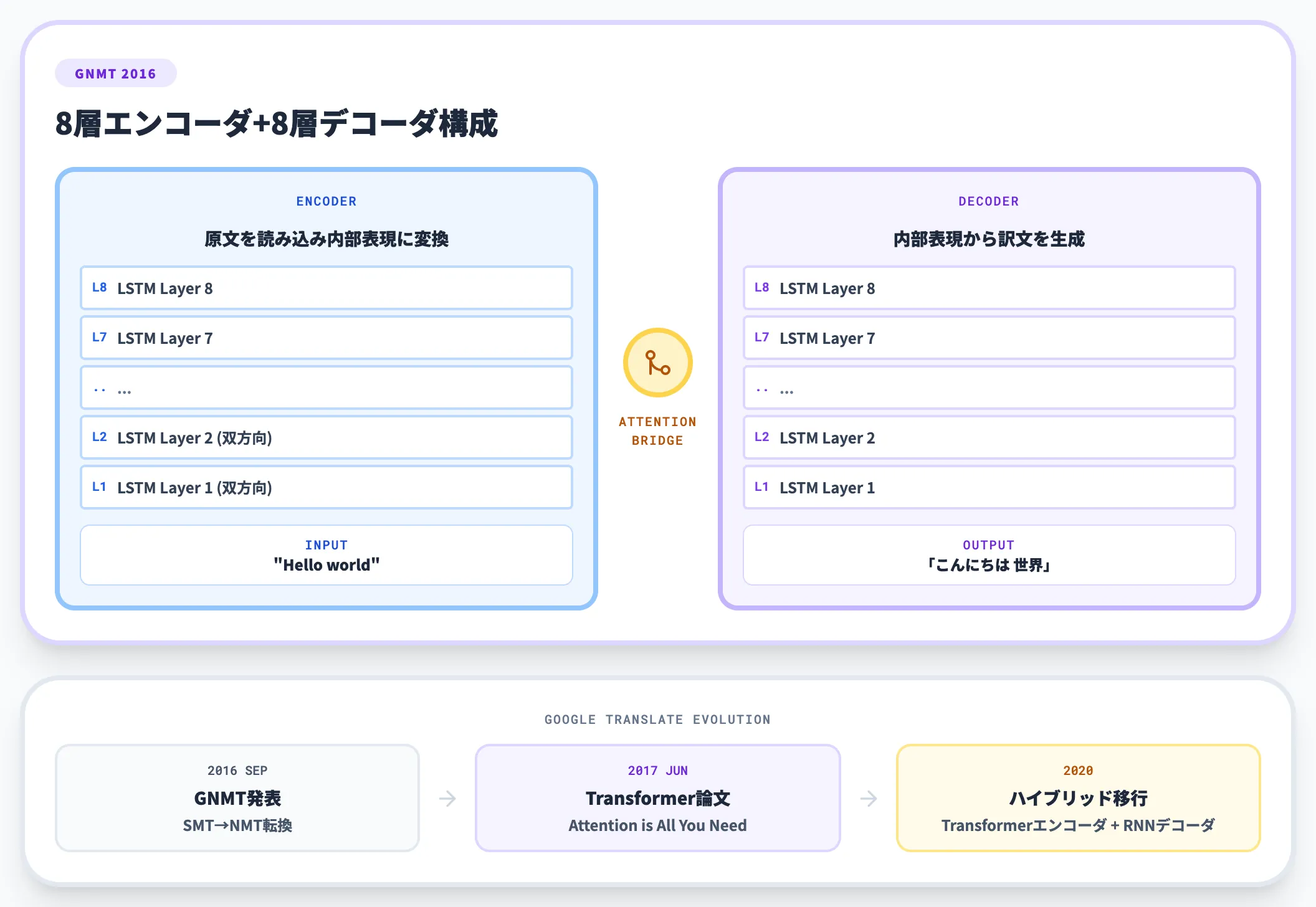
Googleは2016年9月、機械翻訳の主力エンジンを統計的機械翻訳(SMT)からニューラル機械翻訳(NMT)へ刷新する論文「Google's Neural Machine Translation System」を発表しました。
このGNMTは8層のエンコーダLSTMと8層のデコーダLSTMで構成された、大規模な本番NMTモデルで、翻訳精度を統計的手法から大幅に向上させました。
その後Googleは2017年のTransformer論文を経て、2020年に元のGNMTを置き換え、TransformerエンコーダとRNNデコーダを組み合わせたハイブリッド構成へ移行しています。ニューラル機械翻訳の実用化における重要な節目がGNMTのLSTM構成だったと位置づけて差し支えありません。
金融分野——株価・為替予測と異常取引検知
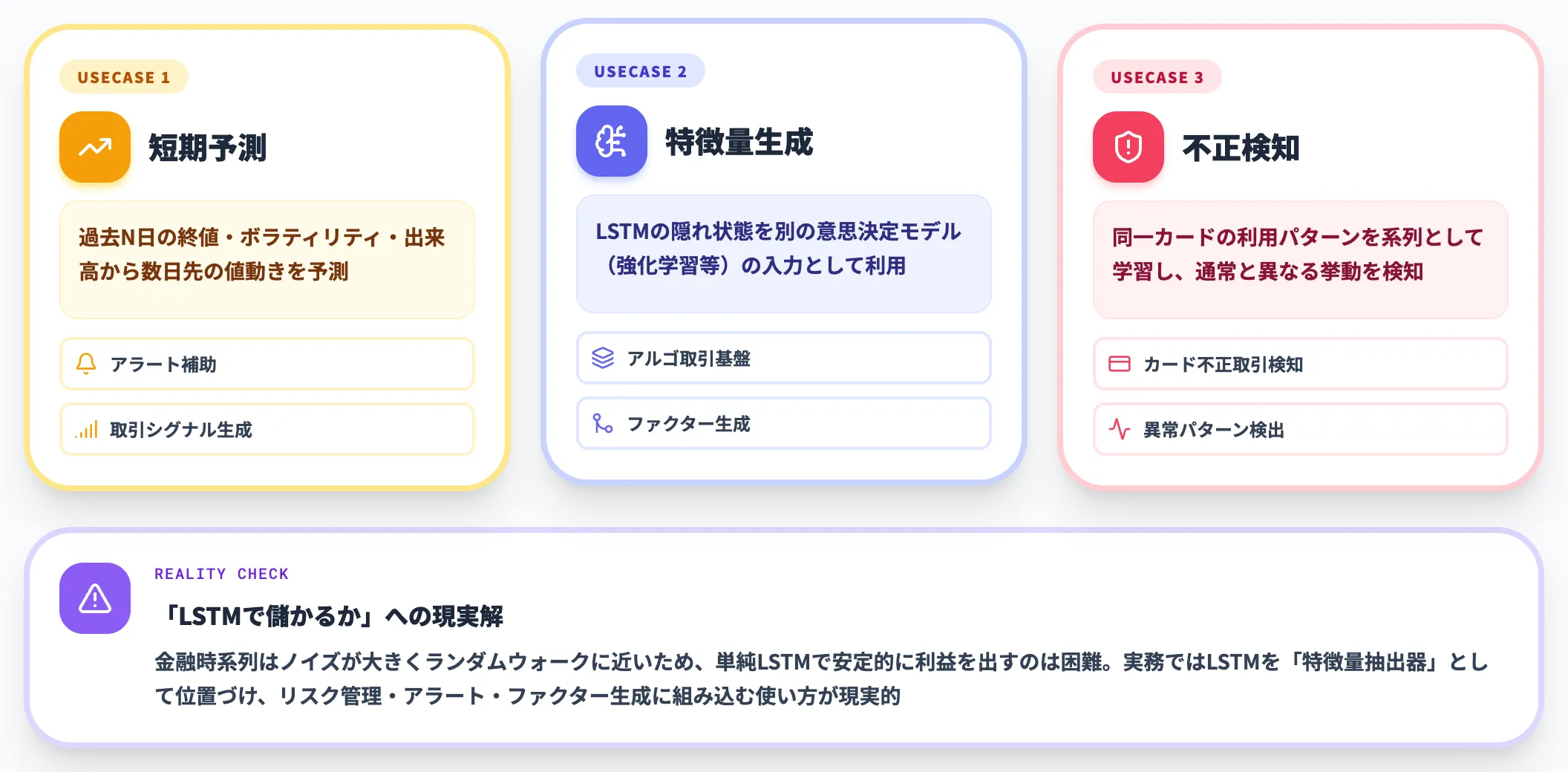
LSTMは金融分野でも幅広く採用されています。AI予測の代表的なユースケースは以下の3つです。
- 株価・為替の短期予測: 過去N日の終値・ボラティリティ・出来高から数日先の値動きを予測。実運用ではアラート補助・取引シグナル生成に使われる
- アルゴリズミックトレーディングの特徴量生成: LSTMの隠れ状態を別の意思決定モデル(例: 強化学習)の入力として利用
- 不正取引検知: 同一カードの利用パターンを系列として学習し、通常と異なる挙動を検知
株価予測について「LSTMで儲かるか」という期待は高い反面、金融時系列はノイズが大きくランダムウォークに近いため、単純なLSTMで安定的に利益を出すのは難しいというのがアカデミアの共通認識です。
実務ではLSTMを「特徴量抽出器」として位置づけ、リスク管理・アラート・ファクター生成に組み込む使い方が現実的です。

製造業——センサ異常検知と需要予測

製造業では、生産ライン上のセンサ(温度・振動・電流・圧力など)の時系列をLSTMで学習し、異常兆候を予知する用途で定着しています。
物流業界の需要予測AIや、製造設備の故障予知AIはその代表で、過去数年の出荷データに季節要因・気象データ・販促情報を組み合わせて翌月在庫を予測するようなパイプラインがLSTMで構築されています。
これらの領域はTransformerに丸ごと置き換える動機が弱く(系列長が数百〜数千ステップに収まり、ハードウェア・運用コストの観点でLSTMが優位)、2026年時点でもLSTM・GRU・N-BEATSが現役の選択肢です。
音声・音楽・手書き認識
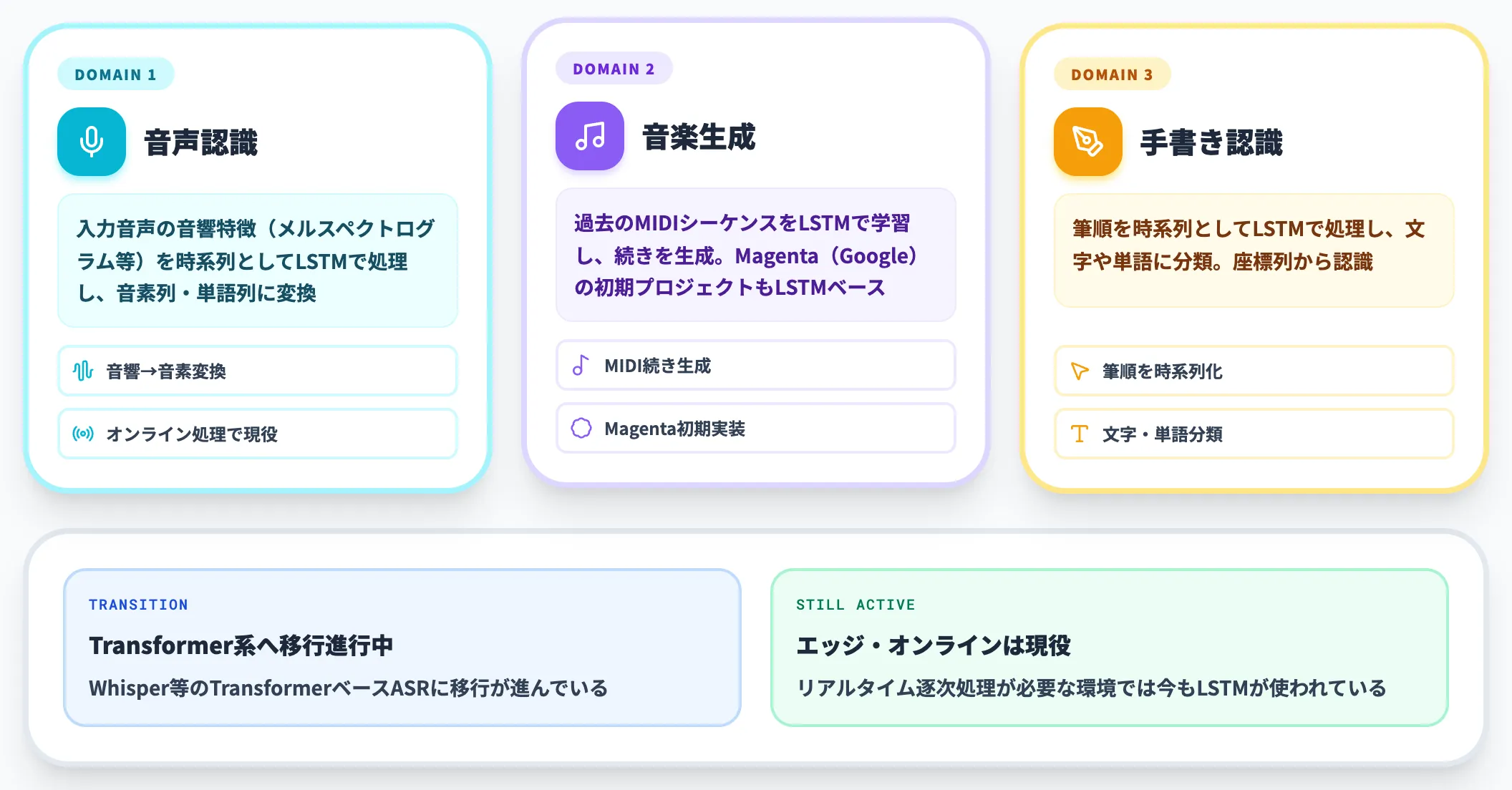
LSTMは音声認識・音楽生成・手書き文字認識でも長くデファクトとして使われてきました。
- 音声認識: 入力音声の音響特徴(メルスペクトログラム等)を時系列としてLSTMで処理し、音素列・単語列に変換
- 音楽生成: 過去のMIDIシーケンスをLSTMで学習し、続きを生成。Magenta(Google)の初期プロジェクトはLSTMベース
- 手書き文字認識: 筆順を時系列としてLSTMで処理し、文字や単語に分類
近年は音声認識もTransformerベース(Whisper等)に移行しつつありますが、エッジ環境やオンライン処理(リアルタイム逐次処理)では今もLSTMが現役で使われています。
2026年のLSTMの現在地——xLSTM・Mambaが登場した今
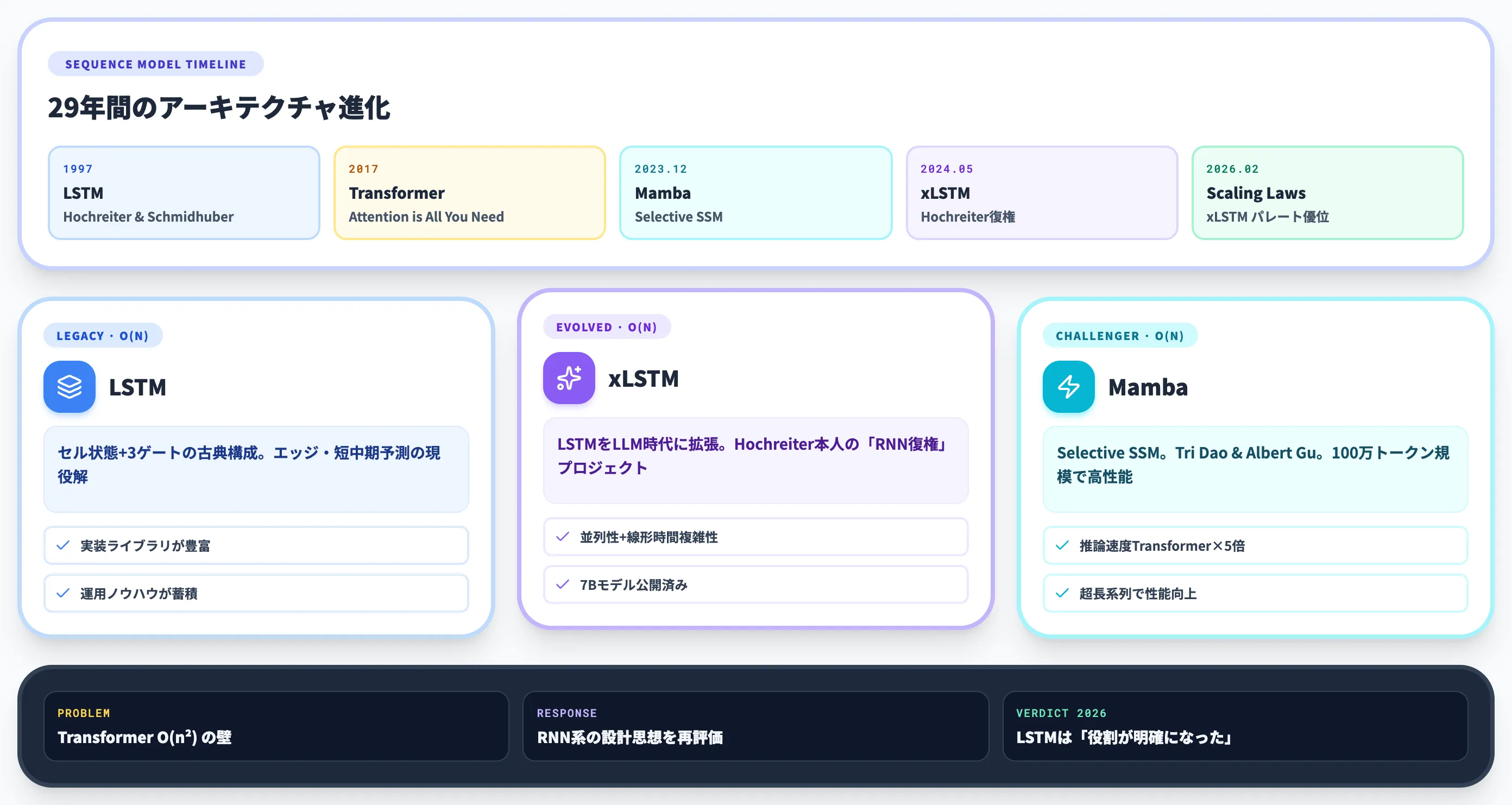
2017年のTransformer登場で「RNNの時代は終わった」と語られた時期もありましたが、2026年の景色は少し違います。
Transformerの O(n²) という計算量の壁が長系列で顕在化し、RNN系の設計思想を再評価する動きが2024年以降に強まっている——これが現在地です。
ここではLSTMの正統進化版であるxLSTMと、競合する線形時間アーキテクチャMamba、そして「2026年にLSTMをそのまま使う」判断の妥当性を整理します。
xLSTM——Hochreiter本人によるRNN復権プロジェクト
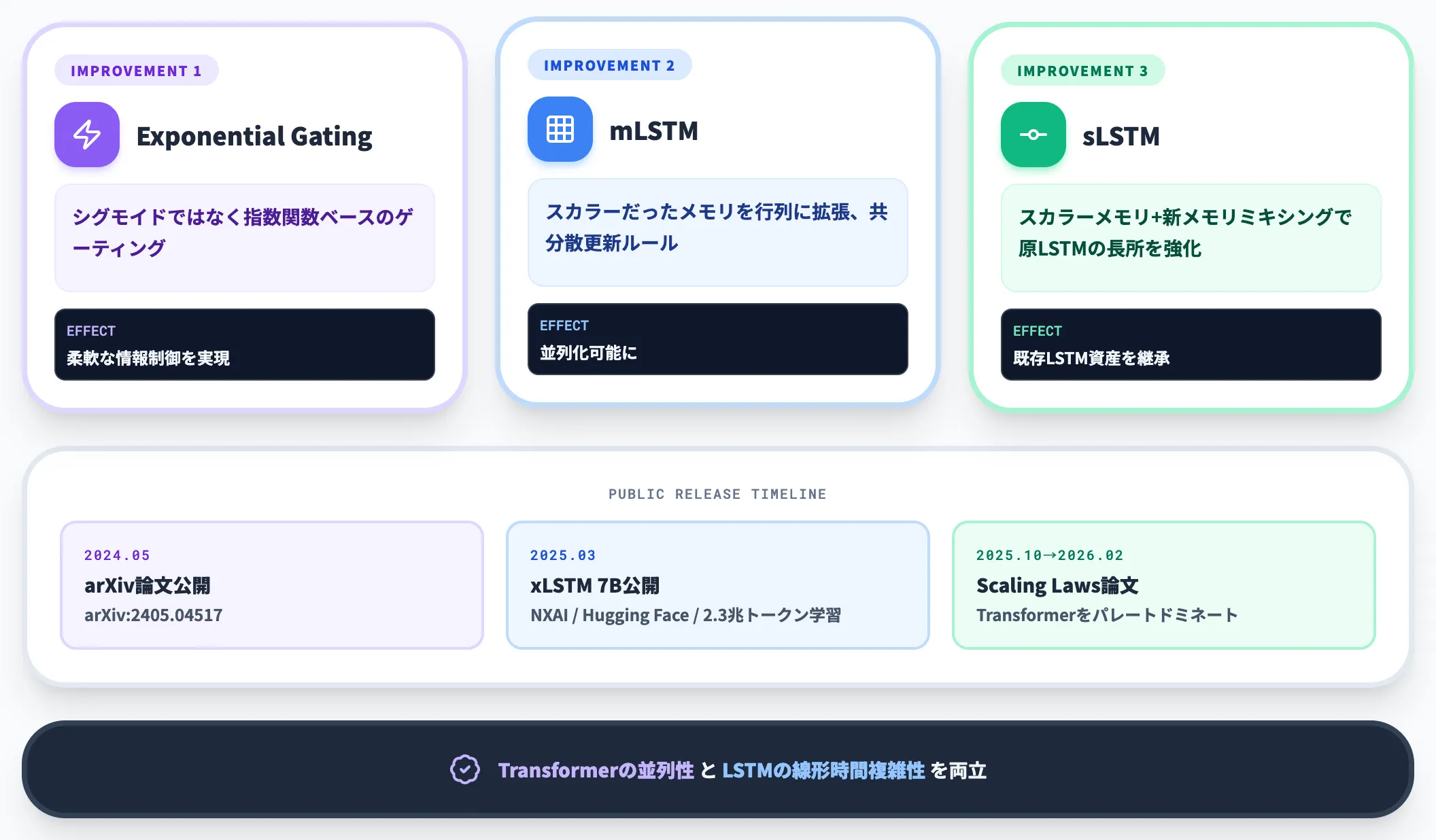
xLSTM(Extended LSTM)は、LSTMの原著者であるSepp Hochreiter率いるJohannes Kepler University LinzとNXAIのチームが2024年5月に発表した、LSTMをLLM時代に通用する形へ拡張したアーキテクチャです(arXiv:2405.04517)。
主な改良点は以下のとおりです。
- Exponential Gating: シグモイドではなく指数関数ベースのゲーティングで、より柔軟な情報制御を実現
- mLSTM(Matrix LSTM): スカラーだったメモリを行列に拡張し、共分散更新ルールで並列化可能に
- sLSTM(Scalar LSTM): スカラーメモリ+新メモリミキシングで、原LSTMの長所を強化
これらにより、xLSTMはTransformerの並列性とLSTMの線形時間複雑性を両立しています。
2025年3月には、NXAIがxLSTM 7Bを発表し、2.3兆トークンで学習されたモデルがHugging Faceで公開されました。同モデルの技術詳細はarXiv論文(2503.13427)にまとめられており、RNN系最高性能・Transformer同等規模を上回る推論速度とメモリ効率が報告されています。
さらに2025年10月公開・2026年2月改訂のxLSTM Scaling Lawsでは、80M〜7Bパラメータ、2B〜2Tトークンの広範な実験で「xLSTMはTransformerをパレートドミネートし、同じ計算予算でより低い交差エントロピー損失を達成する」と報告されています。
Mamba——選択的SSMによる線形時間モデル
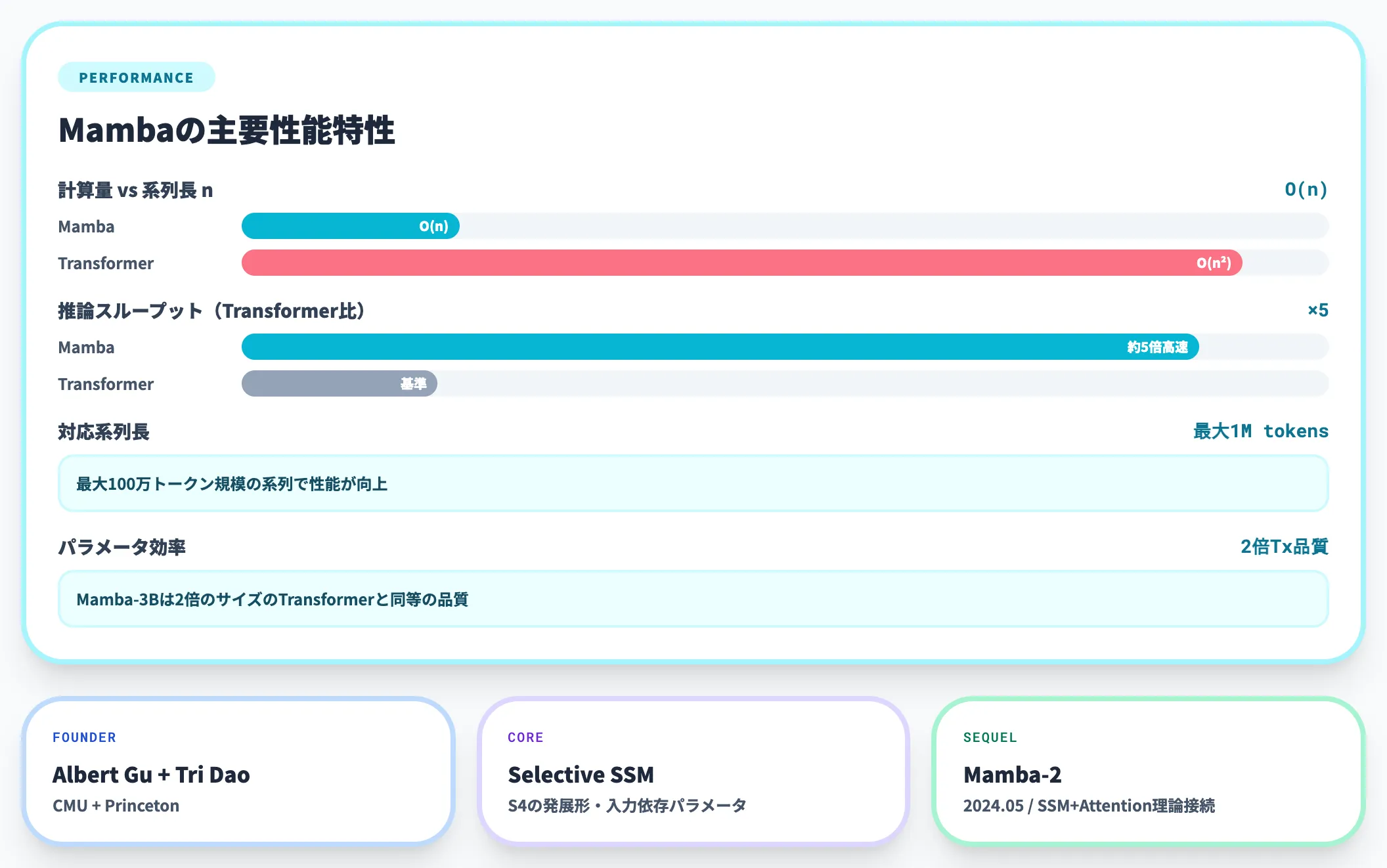
Mambaはカーネギーメロン大学のAlbert Gu氏とプリンストン大学のTri Dao氏が2023年12月に発表した、State Space Model(SSM)系列の新アーキテクチャです。
S4の発展形であるSelective State Space Modelを採用し、SSMのパラメータを入力の関数とすることで「現在のトークンに応じて系列方向に情報を選択的に伝播・忘却する」ことを可能にしました。
主な性能特性は以下のとおりです。
- 計算量: 系列長 n に対して O(n)(Transformerは O(n²))
- スループット: 推論時にTransformerより約5倍高速
- 長系列対応: 最大100万トークン規模の系列で性能が向上
- パラメータ効率: Mamba-3Bは2倍のサイズのTransformerと同等の品質
MambaはxLSTMと並んで「Transformer後」の有力候補とされ、言語・音声・ゲノミクス分野で適用が広がっています。2024年5月には後継のMamba-2(State Space Duality)が発表され、SSMとAttentionの理論的接続を整理しつつ実装効率をさらに引き上げています。
2026年に「LSTMをそのまま使う」判断は妥当か
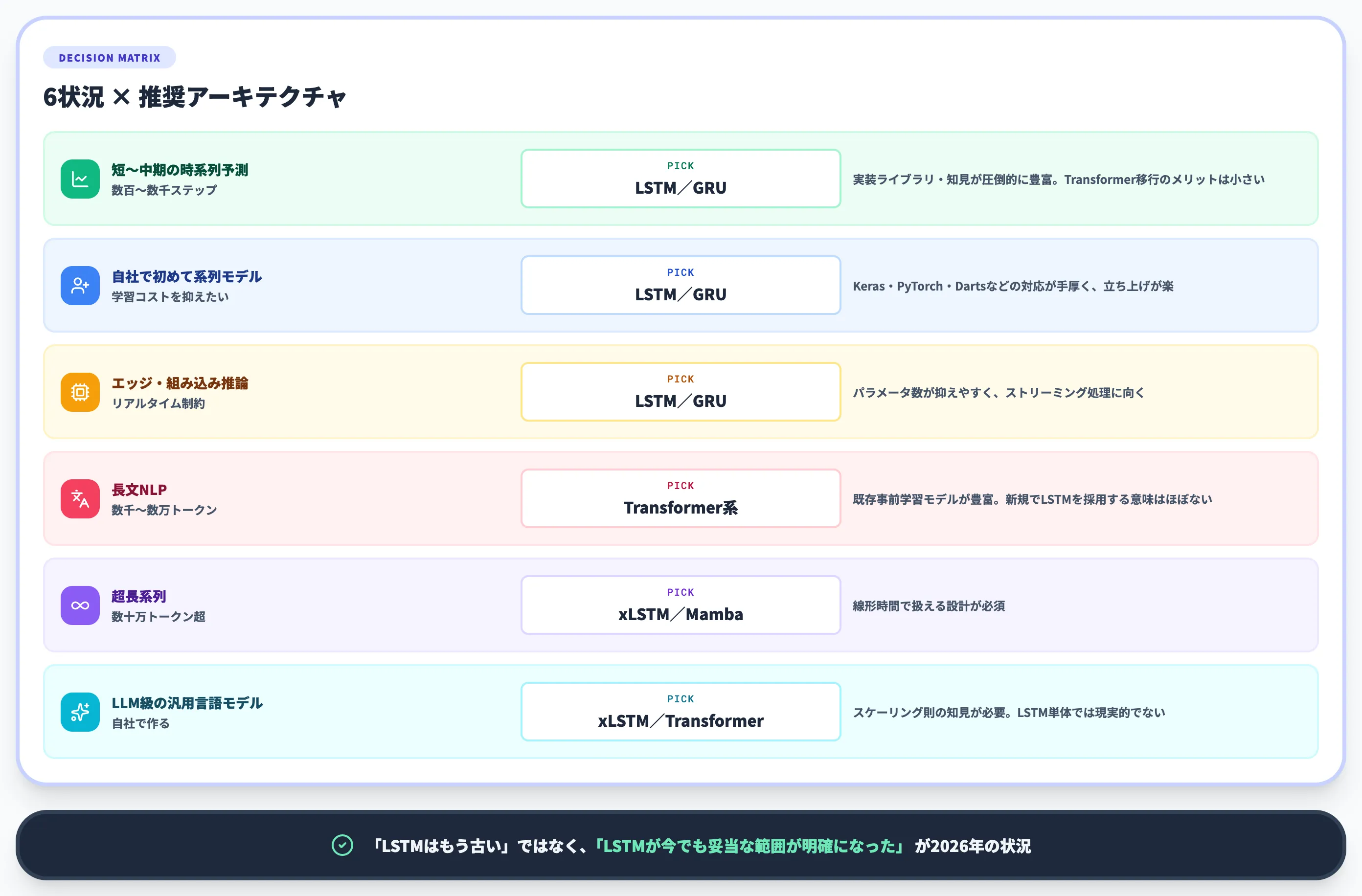
ここで気になるのは「2024年以降にxLSTM・Mambaが出てきたなら、もうLSTMを使う必要はないのか?」という論点です。
実務的な結論は、**「学習資源・運用環境・チームスキルの3点で見て、多くの短〜中期時系列タスクで2026年もLSTMは妥当な候補の一つ」**です。
判断軸を表で整理しました。
| 状況 | 推奨アーキテクチャ | 理由 |
|---|---|---|
| 短〜中期の時系列予測(数百〜数千ステップ) | LSTM/GRU | 実装ライブラリ・知見が圧倒的に豊富。Transformer移行のメリットは小さい |
| 自社で初めて系列モデルを扱う | LSTM/GRU | Keras・PyTorch・Dartsなどの対応が手厚く、学習コストが低い(scikit-learnは前処理・評価・古典モデルのベースライン用途で併用) |
| エッジ・組み込みでリアルタイム推論 | LSTM/GRU | パラメータ数が抑えやすく、ストリーミング処理に向く |
| 長文NLP(数千〜数万トークン) | Transformer系 | 既存事前学習モデルが豊富。新規でLSTMを採用する意味はほぼない |
| 超長系列(数十万トークン超) | xLSTM/Mamba | 線形時間で扱える設計が必須 |
| LLM級の汎用言語モデルを自社で作る | xLSTM/Transformer | スケーリング則の知見が必要。LSTM単体では現実的でない |
つまり「LSTMはもう古い」ではなく、**「LSTMが今でも妥当な範囲が明確になった」**というのが2026年の状況です。
新規プロジェクトでも、用途とリソースを冷静に見れば、LSTMは依然として現実解の一つです。
LSTMをいつ選ぶべきか——ケース別の判断軸
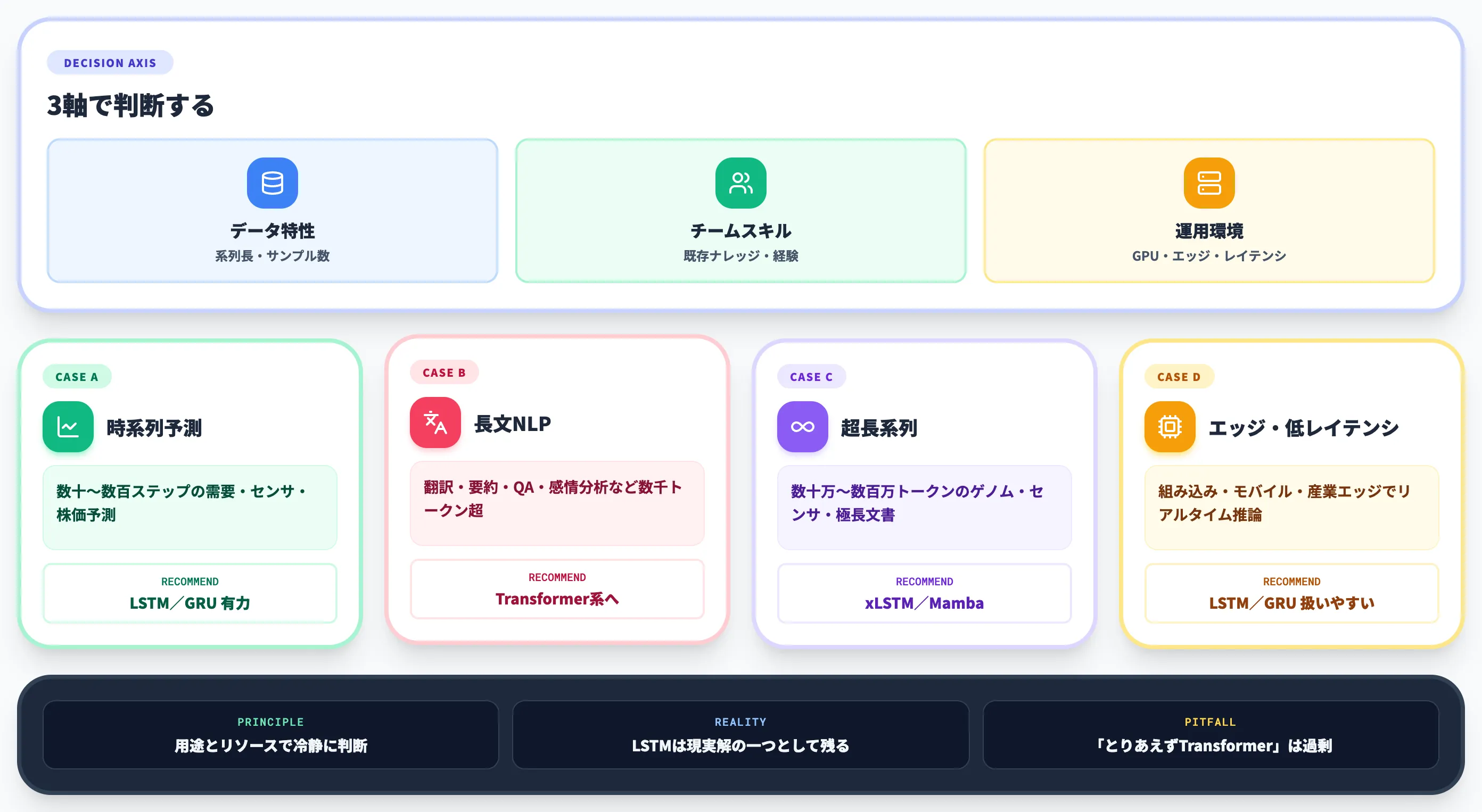
ここまでLSTMの仕組み・他モデルとの違い・現在地を見てきました。
実務で「LSTMにすべきか/別モデルにすべきか」の判断は、データ特性・チームスキル・運用環境の3軸で決まります。
AI総合研究所がエンタープライズAI導入を支援してきた経験から、ケース別の選定軸を整理します。
時系列予測(数十〜数百ステップ)ならLSTMは有力なベースライン候補

需要予測・センサ異常検知・株価予測など、1系列の長さが数十〜数百ステップに収まる時系列タスクでは、2026年でもLSTMは有力なベースライン候補の一つです。N-BEATS・TFT(Temporal Fusion Transformer)・TCN・1D-CNN・古典的時系列モデルなど他にも実務候補は複数あり、Dartsのような予測フレームワークでこれらを並べてベンチマークするのが定石です。
理由は以下の3点です。
- 既存ライブラリの厚み: TensorFlow(Keras)・PyTorch・PyTorch Lightning・Darts・Prophet+LSTMハイブリッドなど、実装手段が豊富で学習コストが低い
- 小〜中規模データセットへの適性: Transformerは大量データでこそ真価を発揮するが、企業の業務データはむしろ「数千〜数万サンプル」の規模に収まるケースが多い
- 解釈性と運用性: アーキテクチャがシンプルでパラメータ数も抑えられるため、本番運用後のモデル監視・再学習が回しやすい
「とりあえずTransformerを使う」という選択は、学習データが少なく、運用チームの経験も浅い状況では過剰であることが多く、LSTMで素直にベースラインを立てるほうが安全に立ち上がります。
長文NLPはTransformer系へ素直に寄せる
翻訳・要約・QA・感情分析など、入力が数千トークンを超える自然言語処理タスクでは、新規プロジェクトでLSTMを採用する積極的な理由はほぼありません。
BERT・GPT・Llama・Claudeなど事前学習済みTransformer系モデルが大量に公開されており、ファインチューニングだけで業界トップの精度を出せるためです。これらのAIモデルの発展で、自然言語処理のスタンダードはほぼ移行しきりました。
大規模言語モデル(LLM)の活用が一般化した2026年現在、テキスト系の新規モデル開発で「ゼロからLSTMを学習」を選ぶ場面は稀になっています。
超長系列はxLSTM/Mambaを検討
数十万〜数百万トークン規模の超長系列(ゲノム解析・長期センサ履歴・極長文書)を扱う場合は、LSTM・Transformerどちらも単純適用では厳しいため、xLSTMやMambaなどの線形時間アーキテクチャを検討する段階に入ります。
ただし2026年6月時点で、これらのアーキテクチャはまだ実装ライブラリ・事前学習モデル・運用ノウハウのいずれも発展途上で、「研究開発フェーズの選択肢」と位置づけるのが現実的です。
商用システムへ組み込むなら、まずはLSTM/Transformerでベースラインを立て、必要に応じてxLSTM等に置き換える二段階アプローチが安全です。
エッジ・低レイテンシ・省メモリならLSTM/GRU

組み込みデバイス・モバイル端末・産業用エッジサーバなど、メモリと計算リソースが限られた環境でリアルタイム推論を行う場合は、LSTM/GRUは扱いやすい候補の一つになります。あわせてLiteRT(旧TensorFlow Lite)で動作する軽量Transformerや、TinyML向けの1D-CNN/LSTM比較が示すような選択肢も並べて検討するのが現実的です。
Transformerは並列性の恩恵を受けにくい逐次推論で遅延が出やすく、ハードウェアによっては推論メモリも厳しくなります。
LSTMはセル状態を引き継ぎながら1ステップずつ出力できるため、ストリーミング処理・遅延制約のあるオンライン処理に向いています。
導入判断で詰まる論点——3つの典型

LSTM導入時にAI総合研究所の支援現場でよく相談される「詰まりやすい論点」を3つ整理します。
-
論点1:時系列の前処理(標準化・差分化・対数変換)をどこまでやるか
LSTMは入力スケールに敏感で、未処理のままだと学習が不安定になる。基本は標準化(z-score)か[0,1]への正規化を入れ、季節性・トレンドが強い場合は差分化や対数変換も検討する
-
論点2:ハイパーパラメータ(系列長・層数・隠れ次元・学習率)の決め方
系列長は「予測に効く過去がどこまで遡るか」のドメイン知識で決める。層数は2〜3層で十分なケースが多く、隠れ次元は64〜256あたりから試すのが定石。学習率は1e-3を起点にスケジューラで減衰
-
論点3:過学習対策(ドロップアウト・早期打ち切り・正則化)の効かせ方
LSTM特有のRecurrent Dropoutを有効にする。早期打ち切り(Early Stopping)は検証損失で監視。データが少ない場合は層数を増やすより、特徴量を増やすほうが効果的なことが多い
これらは「動かす前に決め切る」ものではなく、ベースラインモデルを早く立てて、データを見ながら調整していくのが現実的な進め方です。
LSTMをPythonで実装する基礎
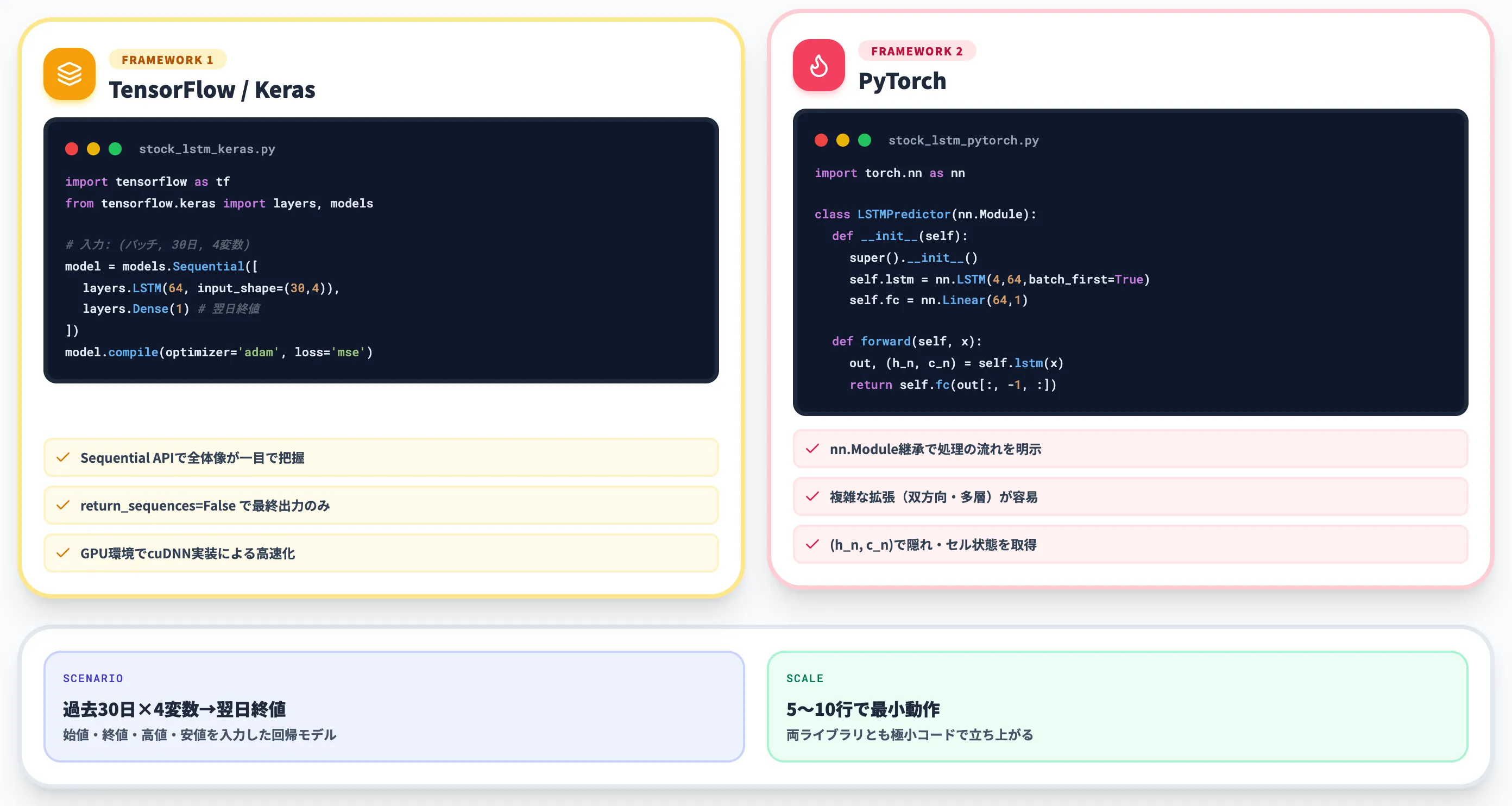
LSTMの実装は、TensorFlow(Keras)かPyTorchで5〜10行程度の最小コードで動かせます。
ここでは両ライブラリの最小実装例と、実装で詰まりやすいポイントを示します。
TensorFlow(Keras)での最小実装
KerasのLSTMレイヤーを使うと、以下のように簡潔に書けます。
import tensorflow as tf
from tensorflow.keras import layers, models
# 入力: (バッチサイズ, 系列長, 特徴量数)
# 例: 過去30日分の株価4変数(始値・終値・高値・安値)
model = models.Sequential([
layers.LSTM(64, input_shape=(30, 4), return_sequences=False),
layers.Dense(1) # 翌日終値を予測
])
model.compile(optimizer='adam', loss='mse')
model.summary()
このシナリオでは、過去30日分・4変数の株価データから翌日の終値を予測する回帰モデルを構成しています。
この実装の利点は複数あります。1つ目は、Sequential APIで層を積むだけなのでアーキテクチャの全体像が一目で把握できる点です。2つ目は、return_sequences=False で最終ステップの出力だけを取り出しているため、続く Dense 層と素直に接続できる点です。3つ目は、activation・dropout・padding等の条件を満たすGPU環境ではcuDNN実装が使われ、学習速度の高速化が期待できる点です。
公式ドキュメントに詳細なオプション(双方向LSTM・Recurrent Dropout・状態保持など)が整理されています。
PyTorchでの最小実装
PyTorchでは、nn.LSTMモジュールを使って同等のモデルを構成できます。
import torch
import torch.nn as nn
class LSTMPredictor(nn.Module):
def __init__(self, input_size=4, hidden_size=64, output_size=1):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# x: (バッチサイズ, 系列長, 特徴量数)
out, (h_n, c_n) = self.lstm(x)
# 最終ステップの隠れ状態を使う
return self.fc(out[:, -1, :])
model = LSTMPredictor()
print(model)
このアプローチの利点も複数あります。nn.Moduleを継承するためforwardメソッドで処理の流れを明示でき、複雑なアーキテクチャ(双方向・多層・注意機構併用)への拡張が容易です。さらに、(h_n, c_n)タプルで隠れ状態とセル状態の両方を取り出せるため、シーケンス間で状態を引き継ぐオンライン推論や、状態を別モデルに渡すマルチタスク学習にも対応しやすくなっています。
PyTorch公式ドキュメントに詳しい使い方が整理されています。
実装で詰まりやすいポイント

LSTMの実装でよくハマるポイントを3つ整理します。
-
入力テンソルの次元順序
KerasはデフォルトでBatch-first(バッチ・系列長・特徴量の順)。PyTorchのnn.LSTMはデフォルトがSeq-first(系列長・バッチ・特徴量)なのでbatch_first=Trueを明示する
-
可変長系列の扱い
バッチ内の系列長が異なる場合、PyTorchではpack_padded_sequence/pad_packed_sequenceの組み合わせ、KerasではMaskingレイヤーを使う。パディング部分を学習対象にしないようにマスクすることが重要
-
勾配爆発の対策
RNN系は逆伝播で勾配が指数的に大きくなることもある(勾配爆発)。torch.nn.utils.clip_grad_norm_やKerasのclipnormで勾配クリッピングを設定する
これらは初学者が初回で必ず躓くポイントなので、最初から組み込んでおくとデバッグ時間が短縮できます。
学習用の本格的な入門としては、Dive into Deep Learning(D2L)のLSTM章が無料公開されており、数式と実装の両面で体系的に整理されています。
LSTMの学習・運用コストと留意点

LSTMはTransformerに比べて軽量とはいえ、GPU資源・学習時間・運用監視のコストはゼロではありません。
ここでは2026年時点での実務的なコスト感と運用上の留意点を整理します。
学習時のGPU・時間コスト
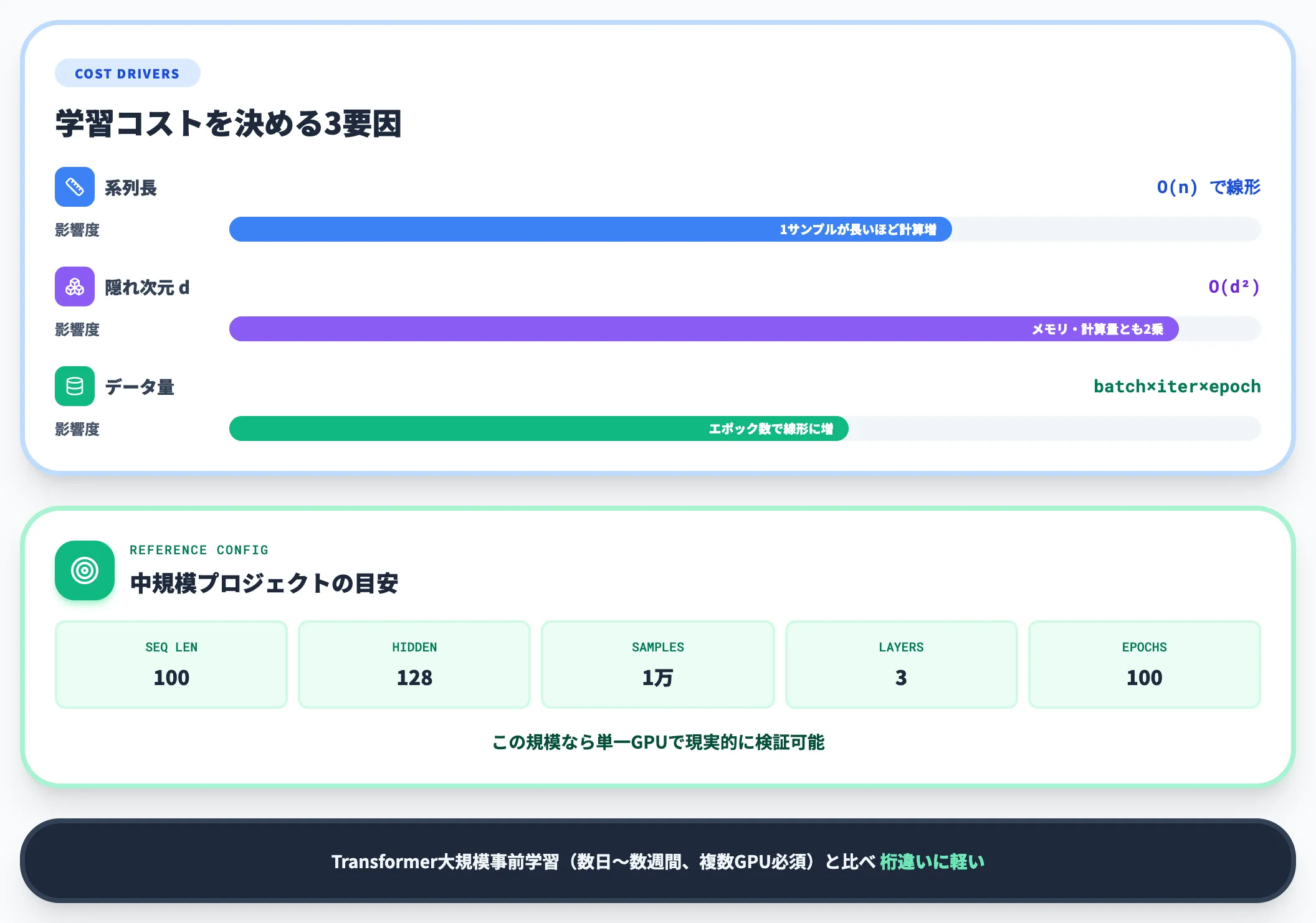
LSTMの学習コストは、おおむね以下の3要因で決まります。
- 系列長: 1サンプルが長いほど逆伝播の計算量が増える(O(n)で線形)
- 隠れ次元: 隠れ次元dに対しメモリと計算量はO(d²)
- データ量: バッチサイズ × イテレーション数 × エポック数
中規模プロジェクト(系列長100、隠れ次元128、サンプル数1万、3層、100エポック程度)であれば、単一GPUで現実的に検証できることが多いものの、所要時間は実装・バッチサイズ・I/O・cuDNN利用条件などに大きく依存します。
これはTransformer系の大規模事前学習(数日〜数週間、複数GPU必須)と比べると桁違いに軽く、「業務データで一発トライ」のハードルが低いのがLSTMの実務的な利点です。
推論コストとレイテンシ

LSTMの推論は系列方向に逐次計算が必要なため、並列化の恩恵を受けにくい点に注意が必要です。
しかし1ステップあたりの計算量は小さく、CPUでもリアルタイム推論が可能な水準で、エッジデバイス向けには大きな利点となります。
参考に、Transformer・xLSTM・LSTMの推論コスト感を比較しました。
| アーキテクチャ | 系列長nに対する計算量 | 並列化 | エッジ適性 |
|---|---|---|---|
| LSTM | O(n) | 系列方向は逐次 | ◎ |
| GRU | O(n) | 系列方向は逐次 | ◎ |
| Transformer | O(n²) | 高い | △(モデルサイズ次第) |
| xLSTM(mLSTM) | O(n) | 並列化可能 | ◯(実装が発展途上) |
| Mamba | O(n) | 並列化可能 | ◯(実装が発展途上) |
つまりLSTM/GRUは、軽量で扱いやすい推論ランタイムの選択肢の一つとして位置づけられ、これがエッジAI・産業センサ分析で残り続ける構造的理由になっています。
運用フェーズで詰まる典型論点

学習が終わってからの運用で詰まりやすい論点を3つ整理します。
-
論点1:分布シフト(Concept Drift)への対応
時系列モデルは「学習時と運用時のデータ分布が同じ」を仮定するが、現実は経済情勢・業務プロセス変化で分布がずれる。月次・四半期で再学習スケジュールを組み、検証損失の悪化を監視する
-
論点2:本番データのスケーラ管理
学習時に標準化(z-score)した場合、本番で同じmean/stdを再現する必要がある。スケーラオブジェクトをモデルと一緒に保存し、推論パイプラインで一貫して使う
-
論点3:オンライン推論時の状態管理
ストリーミング処理で1ステップずつ推論する場合、セル状態と隠れ状態を持ち回す必要がある。状態を破棄してしまうと長期依存の効果が失われるため、リクエスト間で状態を引き継ぐ設計を明示的に組む
「PoCで動いたから本番でも動く」と楽観せず、最初から運用論点を構造化しておくことが、LSTMに限らず時系列モデル運用の鉄則です。

モデル選定の知識を業務でのAI活用に発展させる
LSTM・Transformer・xLSTMといったアーキテクチャごとの違いを理解できると、業務にAIを組み込む際の「どのモデルを選ぶか」「どのサービス・どのプラットフォームに乗せるか」の判断が一段精緻になります。
一方で、多くの企業はモデル選定のさらに前段——**「どの業務にAIを当てるか」「PoCから全社展開までどう進めるか」**で詰まっているのが現状です。
AI総合研究所では、LLMの業務組み込みからワークフロー設計、社内体制構築まで、企業のAI導入を支援する「AI業務自動化ガイド」を220ページの無料資料として公開しています。LSTMや他モデルの技術知識を、組織的なAI活用に発展させるための実践資料として活用ください。
モデル選定の知識を業務でのAI活用に発展させる

AI業務自動化ガイド(220ページ)
LSTM・Transformer・xLSTMなどモデルアーキテクチャの違いを理解できると、業務にAIを組み込む際の「どのモデル・どのサービスを選ぶか」の判断が一段精緻になります。AI総合研究所のAI業務自動化ガイドでは、LLMの業務組み込みからワークフロー設計まで、220ページで実践的な導入手法を整理しています。
まとめ
本記事では、LSTM(Long Short-Term Memory)について、仕組み・他モデルとの違い・活用事例・2026年時点の現在地・ケース別の判断軸・Python実装・運用コストまでを2026年最新情報で解説しました。要点を改めて整理します。
-
LSTMは1997年にHochreiter & Schmidhuberが提案したRNNの改良版で、セル状態と入力・出力ゲート(忘却ゲートはGers et al. 2000で追加され、現在の3ゲート構成として標準化)によって勾配消失問題を構造的に解き、長期依存を学習できるアーキテクチャ
-
2017年のTransformer登場以降、長文NLPの主役は退いたものの、時系列予測・産業センサ分析・エッジ環境では2026年もN-BEATS・TFT・TCN等と並ぶ有力なベースライン候補として残っている
-
Uber配車需要予測・Google翻訳GNMTといった実運用事例に加え、Volvo Discovery Challenge(ECML-PKDD 2024)など研究・競技領域でも採用実績が積み上がり、金融・製造・音声認識など幅広い分野で20年以上にわたり使われ続けている
-
2024年5月発表のxLSTM・xLSTM 7B(NXAI 2025年3月)・xLSTM Scaling Laws(2025年10月公開・2026年2月改訂)と、Mamba/Mamba-2(線形時間SSM)の登場で、RNN系の設計思想が再評価されている
-
新規プロジェクトでも、データ量・系列長・運用環境の3軸で見ればLSTMは依然として現実解の一つで、特に時系列予測とエッジ推論では「とりあえずTransformer」より素直に立ち上がる
系列データを扱うAIプロジェクトの選択肢としてLSTMを冷静に位置づけ直し、自社のユースケース・データ量・運用体制に合うモデルを選ぶことが、2026年のAI実装の出発点になります。










