この記事のポイント
 テーブルデータの分類・回帰にはXGBoostかLightGBMを第一候補にすべき。2026年現在もディープラーニングを上回る精度報告が多い
テーブルデータの分類・回帰にはXGBoostかLightGBMを第一候補にすべき。2026年現在もディープラーニングを上回る精度報告が多い- 画像・音声・テキストの非構造化データにはディープラーニング一択。CNNかTransformerをタスクに応じて選ぶ
- 初めての機械学習プロジェクトはランダムフォレストから始めるべき。前処理が少なく過学習に強いため失敗リスクが低い
- ラベル付きデータが十分なら教師あり学習、不足しているならAutoMLか半教師あり学習で補完するのが実務の定石
- scikit-learnのフローチャートに沿って「データ量→タスク種別→線形性」の3ステップで手法を絞り込むのが最短ルート

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
機械学習の手法は数多く存在しますが、特定の課題に最適な手法を選ぶことがプロジェクト成功の鍵です。
教師あり学習、教師なし学習、強化学習、ディープラーニングの4つの学習パラダイムを理解し、データの性質と目的に応じた手法を選択することで、精度とコストのバランスを最適化できます。
本記事では、線形回帰からニューラルネットワークまで11の代表的な手法を図解付きで紹介し、2026年に注目されるXGBoost・LightGBM・AutoMLの最新動向もあわせて解説します。
目次
機械学習の手法とは(2026年最新)
機械学習とは、データからパターンや規則性を学習し、その学習結果をもとに予測や判断を行う技術です。データの質と量がモデルの性能に直接的な影響を与えるため、目的に合った手法とデータの組み合わせが成功の鍵となります。
犬ロボが壁のボタンを押せるように進化しています。立ち上がる、ボタンを押す、などの動作をそれぞれ機械学習でシュミレートした後、実機で順番にタスクを実行することで実現しています。その内、同時に複数タスクを機械学習できる手法も考案されそうです。既にあるのかな。。 pic.twitter.com/pZrjMq69Dd
— ナムチャン 南原 徹也/Nambara Tetsuya @甲子化学工業/KOUSHI HOTAMET (@namchan_koushi) March 29, 2023
2026年現在、機械学習の手法は大きく4つの学習パラダイムに分類されます。以下の表で、各パラダイムの特徴と代表的な用途を整理しました。
| 学習パラダイム | 入力データ | 目的 | 代表的な用途 |
|---|---|---|---|
| 教師あり学習 | ラベル付きデータ | 入力→出力のマッピング学習 | 画像認識、スパム検出、価格予測 |
| 教師なし学習 | ラベルなしデータ | データの構造・パターン発見 | 顧客セグメンテーション、次元削減 |
| 半教師あり学習 | 少量のラベル付き+大量のラベルなし | ラベル不足の補完 | テキスト分類、バイオインフォマティクス |
| 強化学習 | 環境からの報酬信号 | 報酬を最大化する戦略の学習 | ゲームAI、自動運転、ロボット制御 |
この4つに加えて、ディープラーニング(深層学習)はいずれのパラダイムにも横断的に適用可能な手法群として位置づけられます。手法の選択を誤ると、精度の低いモデルに開発コストを費やし続けることになりかねません。特に初めて機械学習プロジェクトに取り組む場合は、手法の特徴を正しく理解した上で選定することが重要です。

機械学習の4つの学習パラダイム
各学習パラダイムは、データの性質と解きたい問題の種類によって使い分けます。ここでは、教師あり学習、教師なし学習、半教師あり学習、強化学習の4つについて、それぞれの仕組みと代表的な応用例を解説します。
教師あり学習は、入力データとそれに対応する正解ラベルの両方を使ってモデルを訓練する手法です。画像認識、スパム検出、金融詐欺検出など、正解が明確に定義できるタスクに適しています。十分な量のラベル付きデータが確保できる場合に最も効果を発揮します。
教師なし学習は、ラベルのないデータから内在する構造やパターンを発見する手法です。顧客の購買データから類似グループを自動的に分類するクラスタリングや、高次元データを可視化可能な低次元に圧縮する次元削減が代表的な応用です。正解ラベルが存在しない、または作成コストが高いデータに対して有効です。
半教師あり学習は、少量のラベル付きデータと大量のラベルなしデータを組み合わせて学習する手法です。ラベル付けのコストが高い医療画像分析やバイオインフォマティクスの分野で活用されています。教師あり学習と同等以上の性能を、より少ないラベル付きデータで達成できる場合があります。
強化学習は、エージェントが環境と相互作用しながら、試行錯誤を通じて報酬を最大化する戦略を学習する手法です。生成AIの分野では、ChatGPTやClaudeのRLHF(人間のフィードバックからの強化学習)がこの手法を応用しています。自動運転やゲームAIなど、連続的な意思決定が必要なタスクに適しています。
ディープラーニングの位置づけ
ディープラーニングは、多層のニューラルネットワークを用いた学習手法の総称であり、教師あり学習、教師なし学習、半教師あり学習、強化学習のいずれにも適用可能です。畳み込みニューラルネットワーク(CNN)は画像認識に、LSTMなどのリカレントニューラルネットワーク(RNN)は時系列データに、Transformerは自然言語処理に特に優れた性能を発揮します。Transformerから派生したBERTは文章分類や質問応答に、GPT-4やGPT-5などの大規模言語モデルはテキスト生成に革新をもたらしました。
2026年現在、大規模言語モデル(LLM)の基盤となるTransformerアーキテクチャが最も注目されていますが、テーブルデータ(表形式データ)の分類・回帰タスクでは、依然として勾配ブースティング(XGBoost、LightGBM)がディープラーニングを上回る性能を示すケースが多く報告されています。タスクの性質を見極めて、ディープラーニングと従来手法を使い分けることが実務では重要です。
代表的な機械学習手法11選
機械学習には多数のアルゴリズムが存在しますが、ここでは実務で頻繁に使われる11の手法を図解付きで紹介します。以下の表で、各手法のカテゴリ、用途、強み、注意点を一覧で比較しました。
| 手法 | カテゴリ | 主な用途 | 強み | 注意点 |
|---|---|---|---|---|
| 線形回帰 | 教師あり(回帰) | 売上予測、価格予測 | 解釈が容易 | 非線形データに弱い |
| ロジスティック回帰 | 教師あり(分類) | スパム検出、信用判定 | 確率を直接出力 | 非線形境界に限界 |
| 決定木 | 教師あり(分類/回帰) | 顧客分類、診断支援 | 視覚的に理解しやすい | 過学習しやすい |
| ランダムフォレスト | アンサンブル | 特徴量重要度の評価 | 高精度、過学習に強い | 計算コストが高い |
| SVM | 教師あり(分類) | テキスト分類、画像認識 | 高次元データに強い | 大規模データに不向き |
| k-NN | 教師あり(分類/回帰) | レコメンド、異常検知 | 実装が容易 | 次元の呪いに弱い |
| ナイーブベイズ | 教師あり(分類) | テキスト分類、感情分析 | 高速、少量データでも有効 | 特徴間独立性の仮定 |
| k-平均法 | 教師なし(クラスタリング) | 顧客セグメンテーション | 直感的かつ高速 | クラスタ数の事前指定が必要 |
| PCA | 教師なし(次元削減) | データ可視化、前処理 | ノイズ除去に有効 | 非線形構造を捉えにくい |
| 勾配ブースティング | アンサンブル | Kaggleコンペ、CTR予測 | テーブルデータで最高水準の精度 | ハイパーパラメータが多い |
| ニューラルネットワーク | ディープラーニング | 画像認識、音声認識、NLP | 複雑なパターンを学習可能 | 大量データと計算資源が必要 |
実務で選ぶ際のポイントは、データの量と種類に応じた使い分けです。テーブルデータで数千〜数万行の規模であればランダムフォレストや勾配ブースティング、画像・音声・テキストなどの非構造化データであればディープラーニングが第一候補となります。以下で各手法の仕組みを図解とともに解説します。
線形回帰
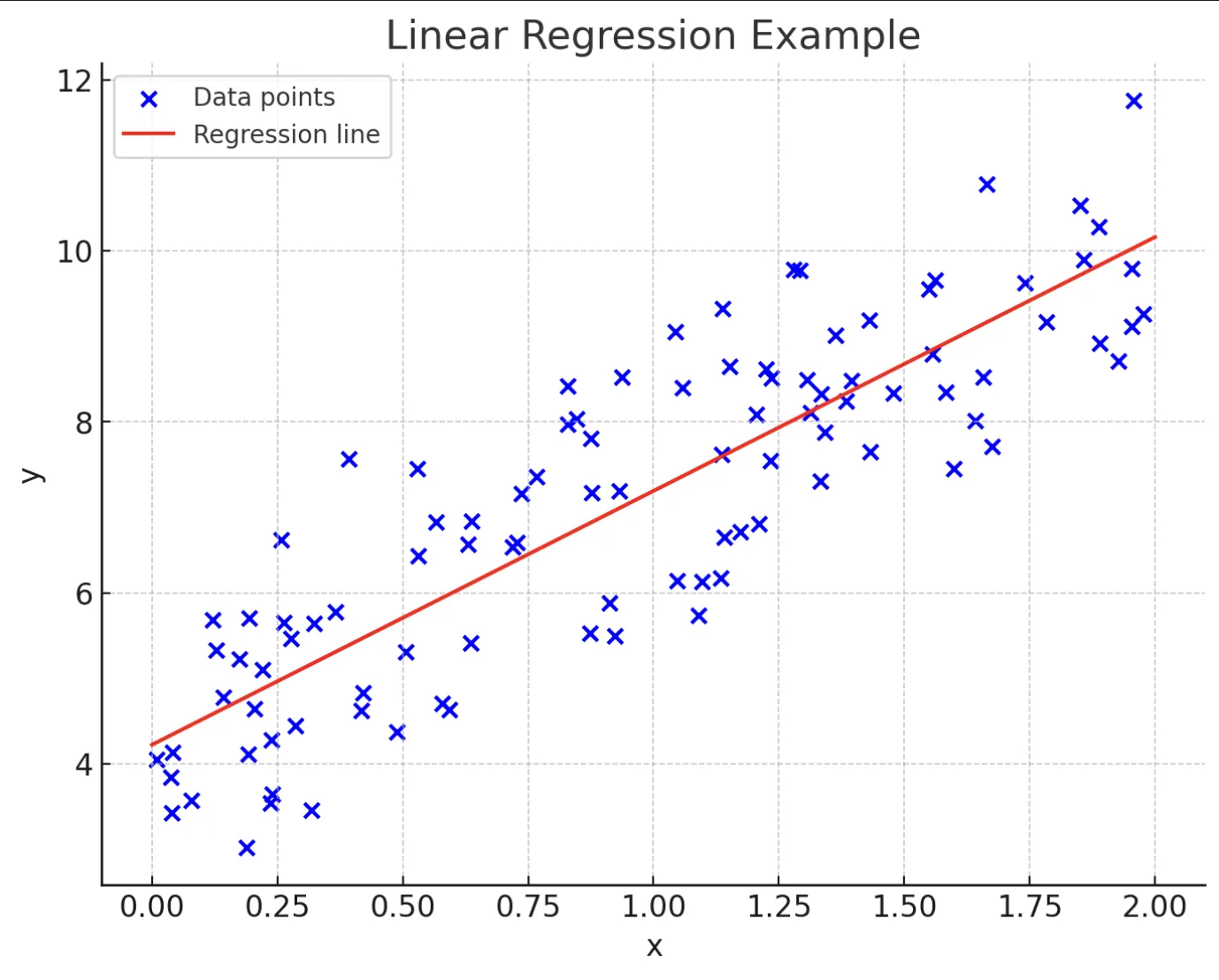
連続値の予測に使用される最も基本的な手法です。データの関係を直線で近似するため、解釈のしやすさが最大の強みですが、外れ値の影響を受けやすい点に注意が必要です。販売予測や不動産価格の推定に広く応用されています。
ロジスティック回帰

2クラスの分類問題に用いられる手法で、各データが正クラスに属する確率を直接出力します。図の緑の線は決定境界と呼ばれ、クラスが切り替わる確率が0.5の位置を示しています。スパム検出や信用スコアリングで広く使われています。
決定木
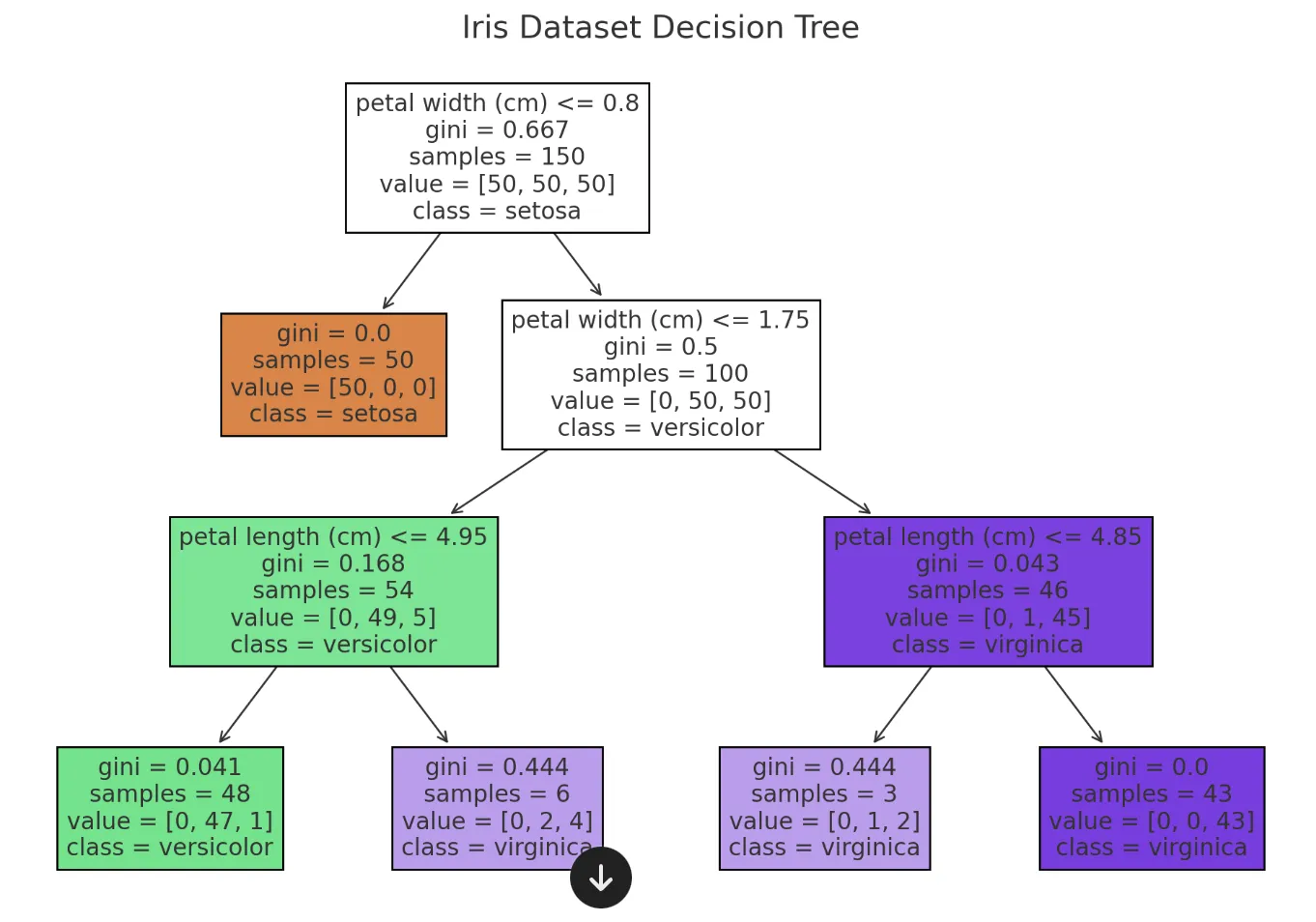
判断基準を階層的な木構造で表現し、データを分類・回帰する手法です。図はIrisデータセットを用いた花の種類の分類例です。人間が理解しやすい反面、深い木は過学習に陥りやすいため、枝刈り(pruning)が重要です。
ランダムフォレスト

複数の決定木を組み合わせるアンサンブル手法です。各決定木はデータと特徴量のランダムなサブセットで学習するため、単一の決定木よりも過学習に強く高精度な予測を実現します。特徴量の重要度を算出できる点も実務で重宝されます。
サポートベクターマシン(SVM)
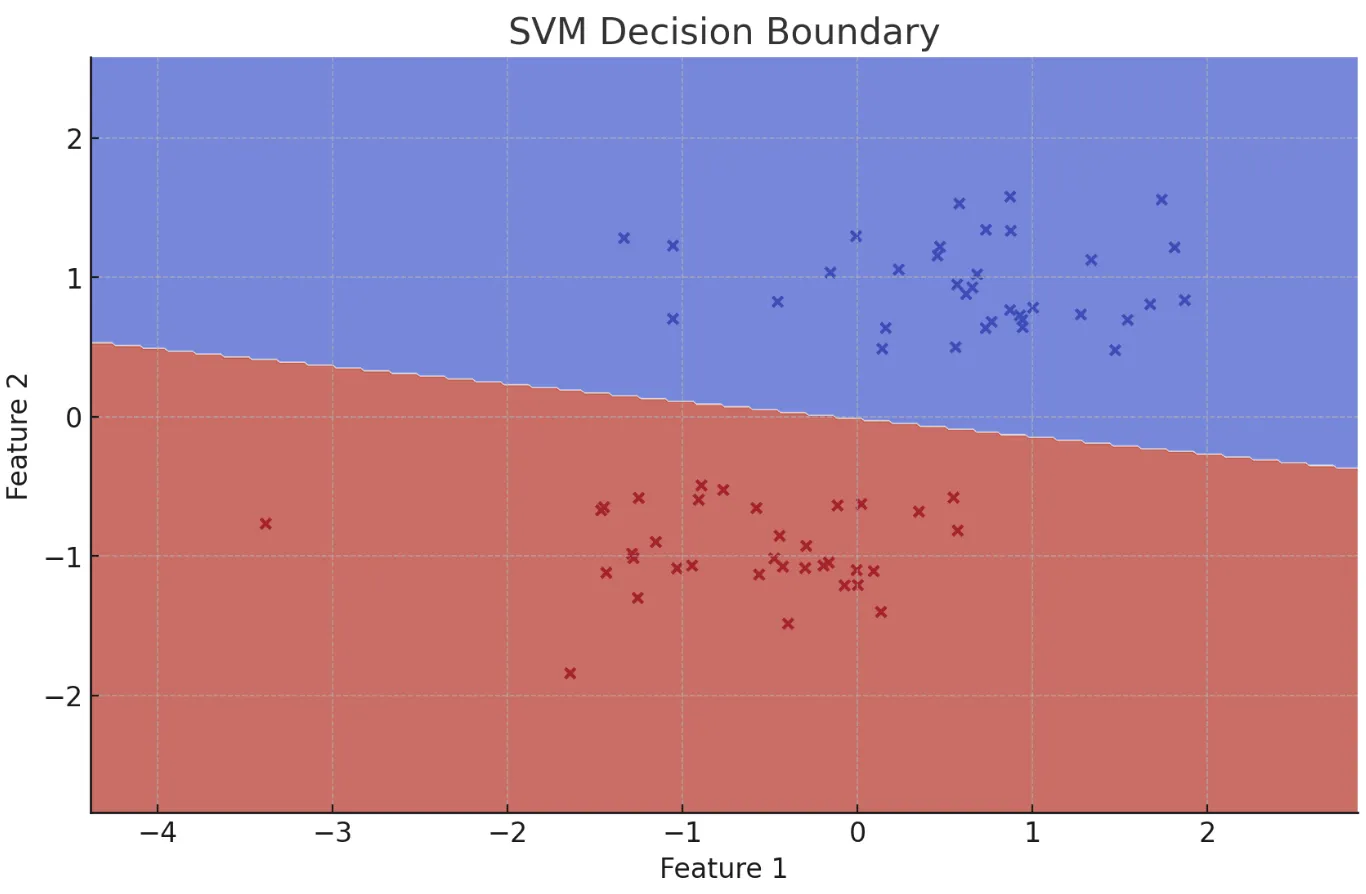
2クラスを最も広いマージンで分離する境界線(超平面)を求める手法です。カーネル関数を用いることで非線形な境界も学習でき、高次元データに強い特性があります。テキスト分類や画像認識で高い性能を示しますが、大規模データでは学習時間が長くなります。
k-最近傍法(k-NN)
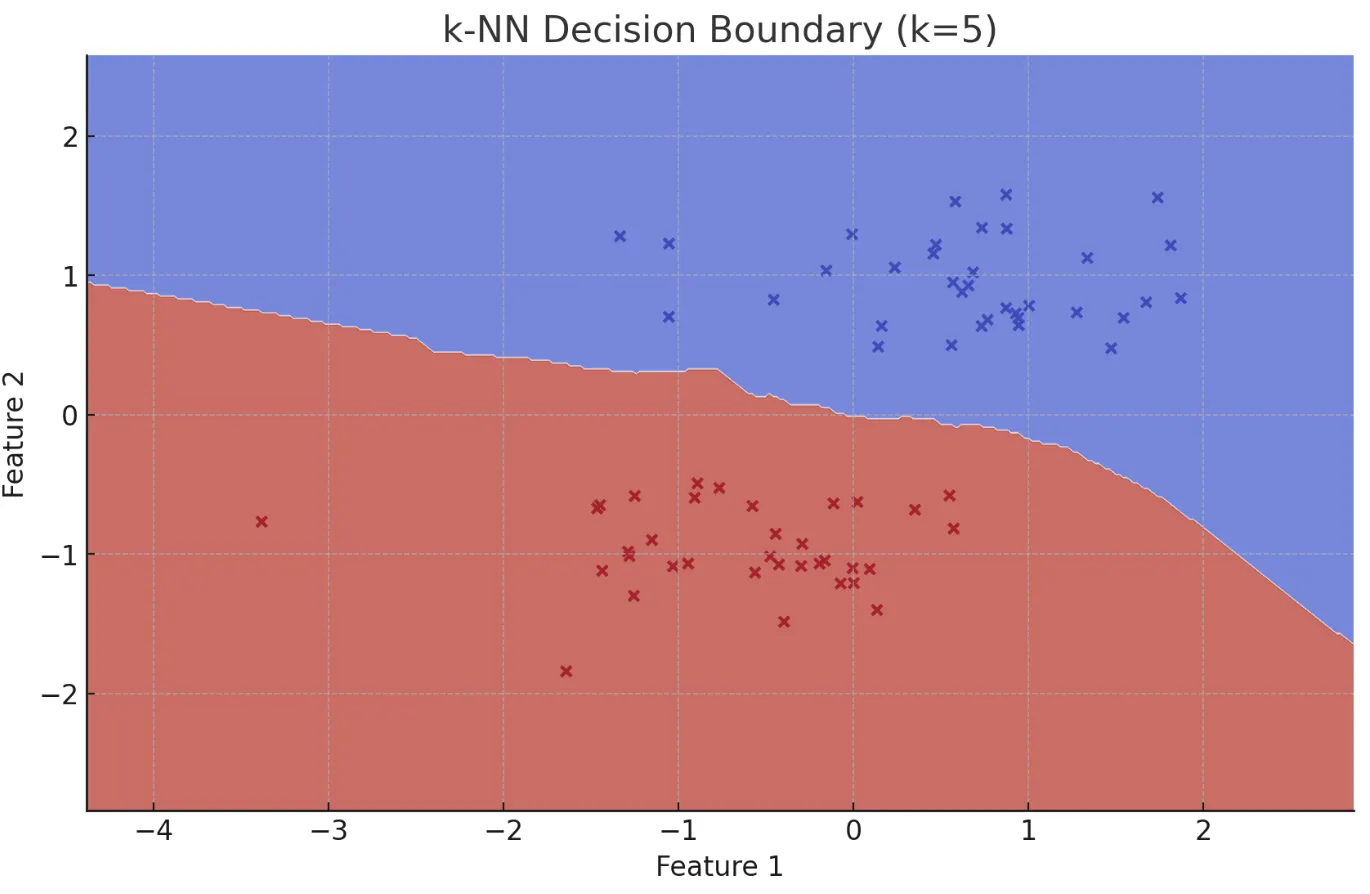
新しいデータに最も近いk個の学習データの多数決でクラスを決定する手法です。モデルの学習が不要で実装が簡単な反面、データ数が増えると予測時の計算コストが増大します。レコメンドエンジンや異常検知に活用されています。
ナイーブベイズ

ベイズの定理を用いて各クラスの確率を計算する手法で、特徴間の独立性を仮定することで高速な計算を実現します。学習データが少なくても比較的高い精度を出せるため、テキスト分類や感情分析で特に有効です。
k-平均法(k-means)
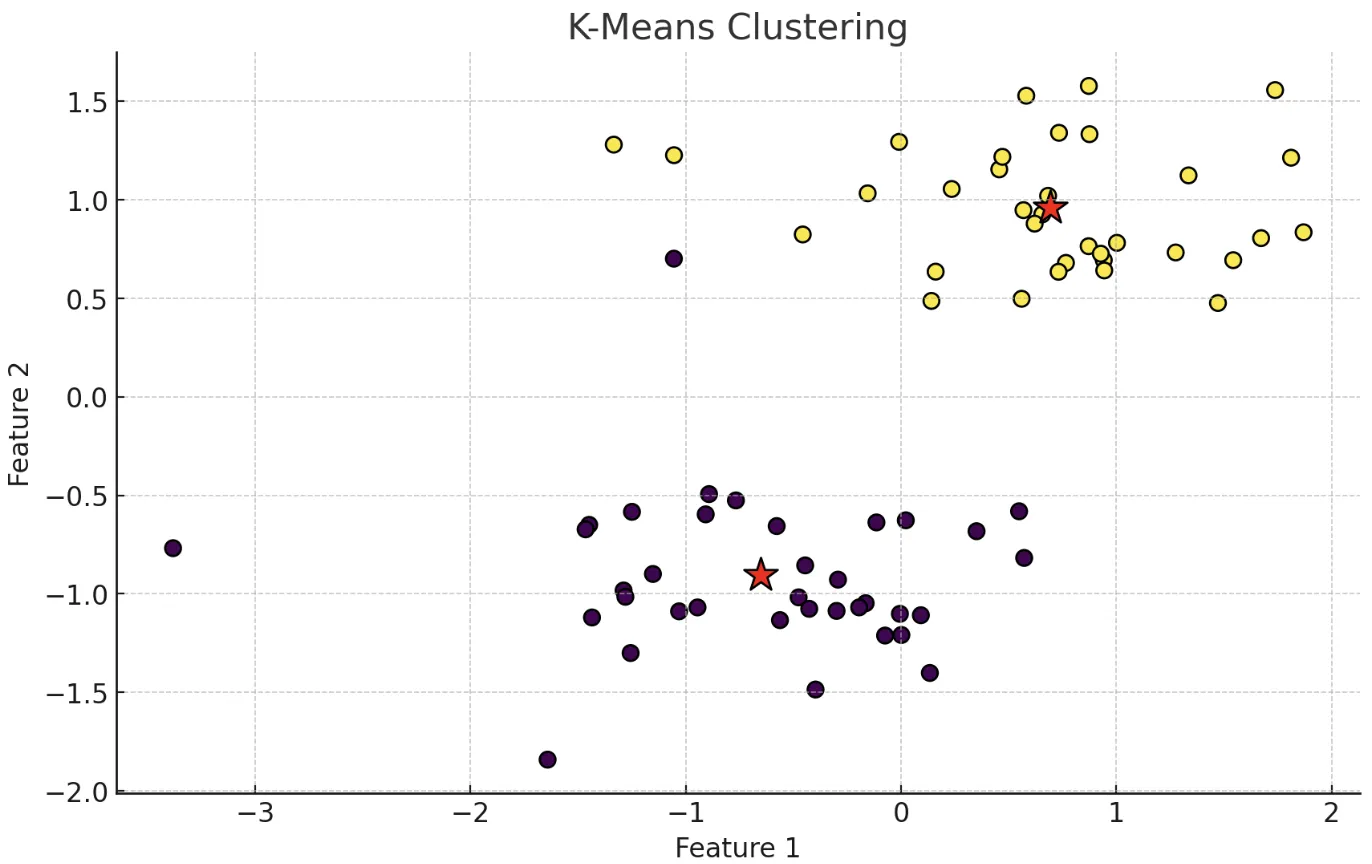
教師なし学習の代表的なクラスタリング手法です。データをk個のグループに分類し、各グループの中心(セントロイド)との距離を最小化するようにデータを割り当てます。顧客セグメンテーションやマーケティング分析で広く使われますが、クラスタ数kを事前に指定する必要があります。
主成分分析(PCA)
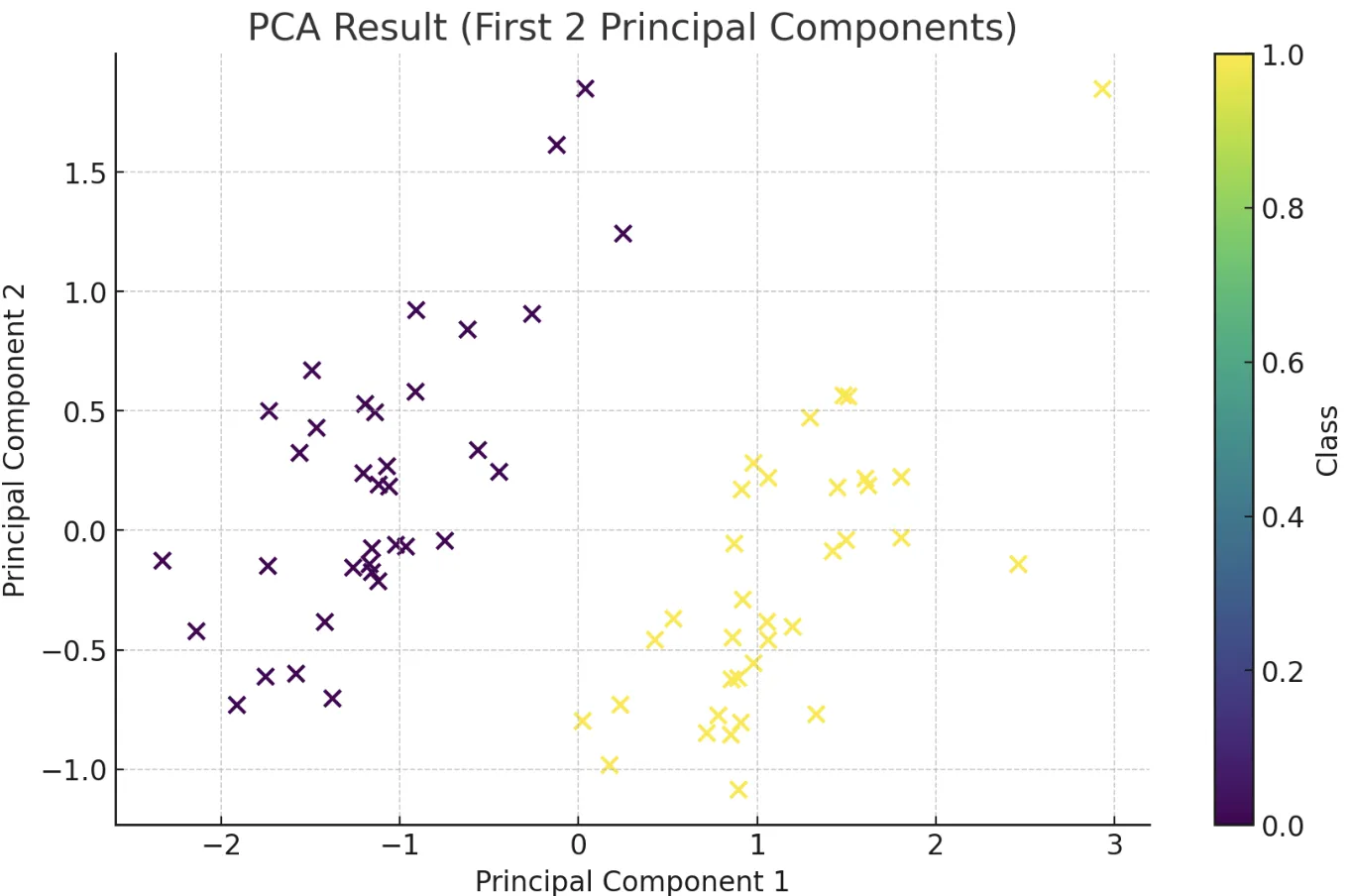
高次元データの分散が最大となる方向を見つけ、より少ない次元で表現する次元削減手法です。データの可視化や、他の機械学習アルゴリズムへの前処理としてノイズ除去に役立ちます。ただし、非線形な構造を持つデータには効果が限定的です。
勾配ブースティング

弱い学習器(通常は浅い決定木)を逐次的に訓練し、前のステップの残差(誤差)を重点的に学習するアンサンブル手法です。2026年現在、テーブルデータの分類・回帰タスクで最も高い精度を達成する手法として、XGBoost、LightGBM、CatBoostの3つの実装が広く使われています。
ニューラルネットワーク
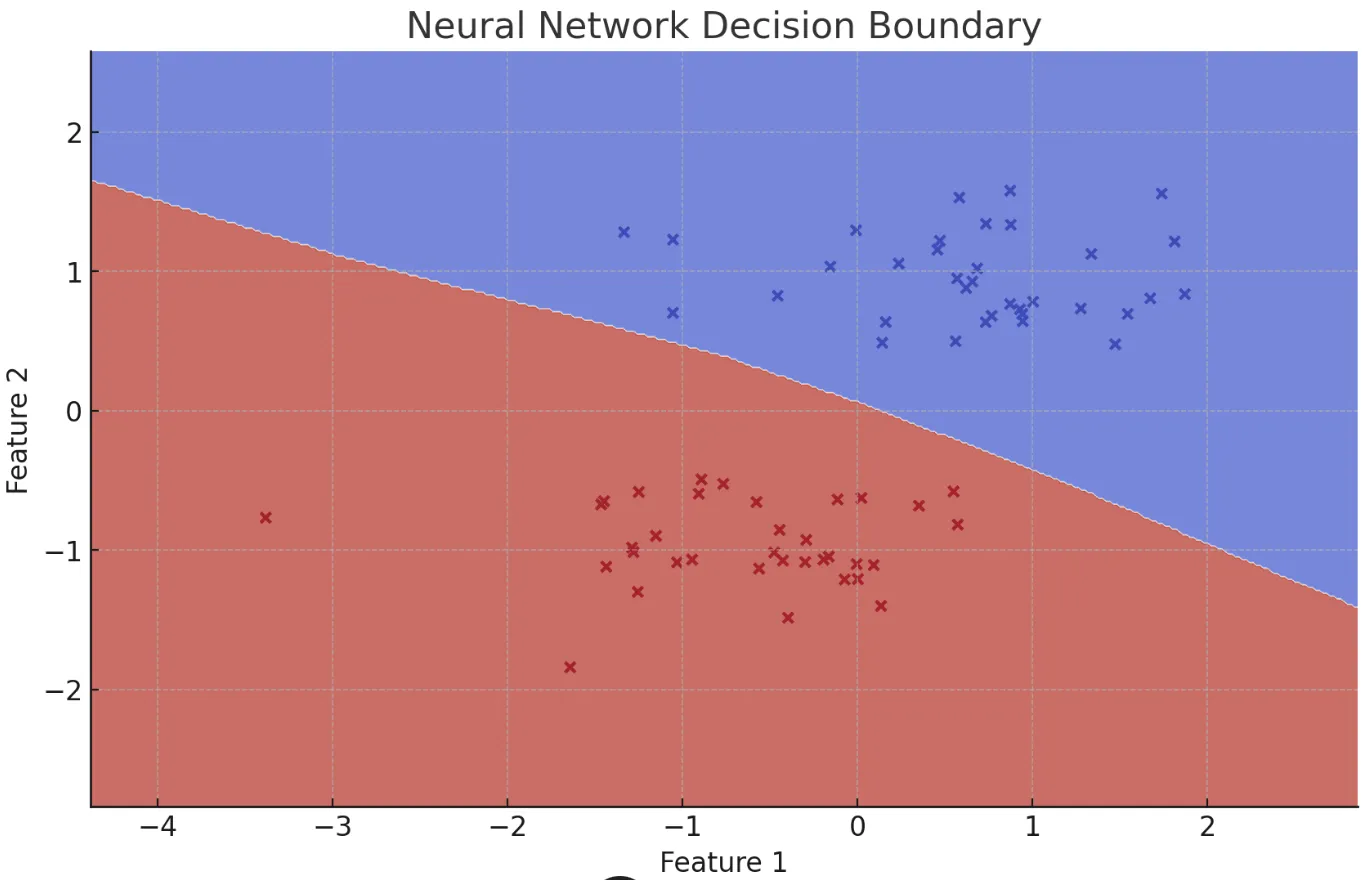
脳のニューロンの動作を模倣した計算モデルで、入力層、隠れ層、出力層から構成されます。学習過程ではデータからパターンを学び取るためにネットワーク内の重みが調整されます。画像認識、音声認識、自然言語処理など、大量のデータが利用可能な場面で特に高い精度を達成します。

特にランダムフォレストと勾配ブースティングは、Kaggleなどのデータサイエンスコンペティションで頻繁に上位を占める手法です。一方、ニューラルネットワークは画像・音声・テキストなどの非構造化データで強みを発揮し、近年のディープラーニングの進展により最も注目を集めています。
アンサンブル学習とXGBoost・LightGBM
アンサンブル学習は、複数の弱い学習器を組み合わせて強い予測モデルを構築する手法の総称です。ランダムフォレスト(バギング)と勾配ブースティング(ブースティング)が2つの代表的なアプローチであり、特に勾配ブースティングの実装であるXGBoost、LightGBM、CatBoostは2026年現在もテーブルデータの分類・回帰タスクで最高水準の精度を達成しています。
XGBoostは、正則化による過学習抑制と並列計算による高速化を特徴とする勾配ブースティングの実装です。LightGBMはMicrosoftが開発した実装で、リーフワイズ(葉優先)の木成長戦略を採用しているため、XGBoostのレベルワイズ(段階的)成長と比較してより高速に学習が完了し、特に大規模データセットで有利です。CatBoostはYandexが開発した実装で、カテゴリカル変数(性別、都道府県などの質的変数)を前処理なしで直接扱える点が特長です。
実務では、まずLightGBMで素早くベースラインを構築し、次にXGBoostやCatBoostと比較して最も精度の高いモデルを選択するアプローチが一般的です。3つのモデルのアンサンブル(スタッキング)により、単一モデルを超える精度を達成できる場合もあります。

機械学習手法の選び方
機械学習の手法選択は、プロジェクトの成否を左右する重要なステップです。scikit-learnの公式フローチャートは、データの特性と目的に基づいて最適な手法を絞り込むための実用的なガイドとして広く活用されています。以下の表で、手法選択の主要な判断基準を整理しました。
| 判断基準 | 確認内容 | 推奨手法 |
|---|---|---|
| データの種類 | テーブルデータか非構造化データか | テーブル→勾配ブースティング、画像/音声/テキスト→ディープラーニング |
| ラベルの有無 | 正解ラベルがあるか | あり→教師あり学習、なし→クラスタリング/次元削減 |
| データ量 | 数百件か数万件以上か | 少量→ナイーブベイズ/ロジスティック回帰、大量→ランダムフォレスト/勾配ブースティング |
| 解釈性の要求 | モデルの判断根拠を説明する必要があるか | 必要→決定木/線形回帰/ロジスティック回帰 |
| 計算資源 | GPUや大量メモリが利用可能か | 制限あり→ナイーブベイズ/k-NN、潤沢→ニューラルネットワーク |
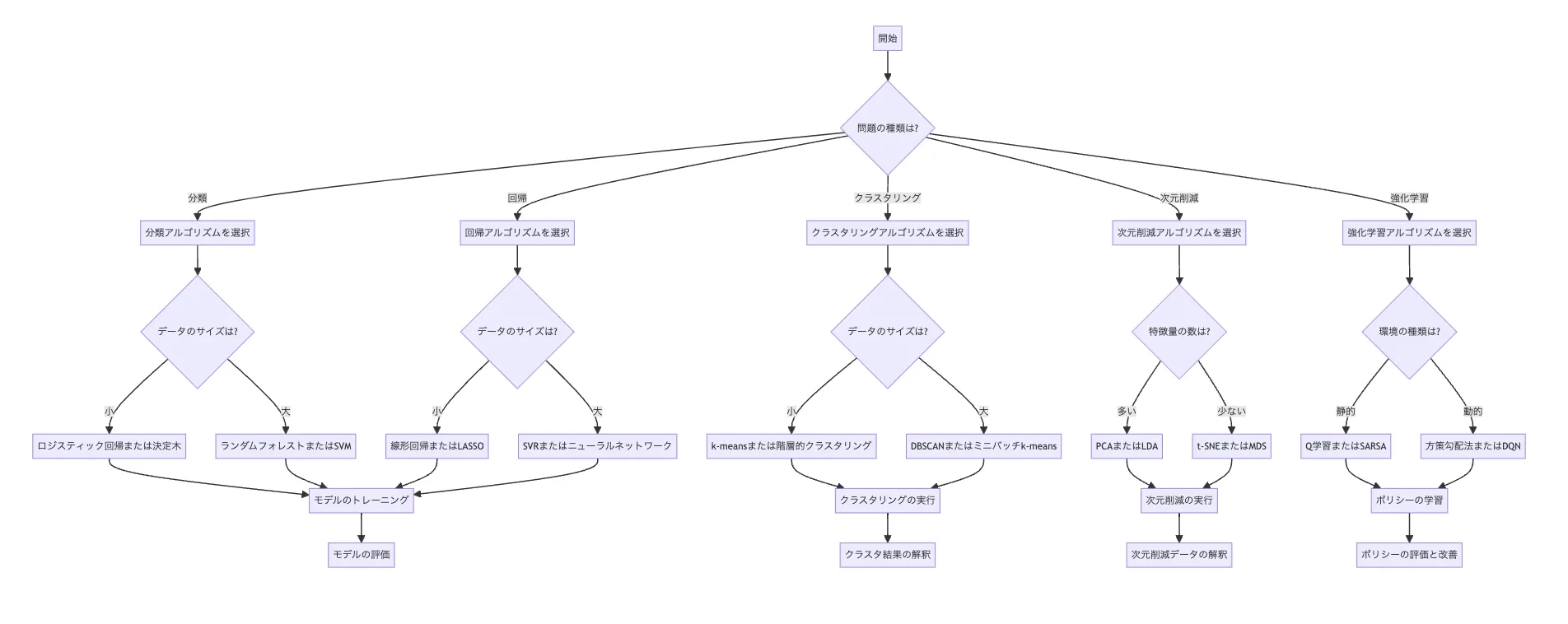
上記はAI総研編集部が作成した機械学習手法の選択フローチャートです。データの量、ラベルの有無、タスクの種類(分類/回帰/クラスタリング)を順に確認することで、候補となる手法を効率的に絞り込めます。
2026年のAutoMLとモデル選定の自動化
2026年現在、手法選定のプロセスそのものを自動化するAutoML(Automated Machine Learning)が実務で広く活用されています。AutoMLは、データの前処理、特徴量エンジニアリング、モデル選択、ハイパーパラメータチューニングを自動的に実行し、最適なモデルを提案します。
代表的なAutoMLツールとして、AWSが開発するAutoGluonがテーブルデータの自動モデル選定で高い評価を得ています。AutoGluonは、XGBoost、LightGBM、CatBoostに加えて最新のディープラーニングモデルも候補に含めた上で、最適なモデルとそのアンサンブルを自動的に構築します。最小限のコードで複数モデルを同時に評価できるため、機械学習の初学者でも高精度なモデルを構築できるようになっています。
ただし、AutoMLは万能ではありません。ドメイン知識に基づく特徴量設計や、ビジネス要件に合わせた評価指標の選択は、依然として人間のエンジニアが判断する必要があります。AutoMLは手法選定の効率化ツールとして活用し、最終的なモデルの検証と運用設計は人間が行うことが推奨されます。AIプロジェクトの成功には、ツールの活用と人間の判断の適切なバランスが不可欠です。

機械学習の手法理解を組織のAI導入設計として形にする
機械学習の主要手法と選定基準を理解した今、次のステップはこの知識を自社の業務課題に当てはめることです。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に設計する実践ガイド(220ページ)を無料で提供しています。AI技術の業務適用に必要なPoC→パイロット→全社展開のプロセスを、部門別のBefore/After付きで解説しています。
AI総合研究所が、機械学習の知識を組織の業務改善計画として形にするガイドをお届けします。
【無料DL】AI業務自動化ガイド(220P)

Microsoft環境でのAI活用を徹底解説
Microsoft環境でのAI業務自動化・AIエージェント活用の完全ガイドです。Microsoft環境でのAI業務自動化の段階設計を詳しく解説します。
まとめ
本記事では、機械学習の4つの学習パラダイムと代表的な11の手法を図解付きで解説し、フローチャートを用いた手法選定のガイドラインを紹介しました。
テーブルデータの分類・回帰タスクでは勾配ブースティング(XGBoost、LightGBM、CatBoost)が最高水準の精度を達成し、画像・音声・テキストなどの非構造化データではディープラーニングが最適です。AutoMLの活用により、手法選定とハイパーパラメータチューニングの効率化も進んでいます。
機械学習プロジェクトを始める方は、以下の手順で取り組むことをおすすめします。
- scikit-learnのフローチャートでデータとタスクに合った手法の候補を絞り込む
- ランダムフォレストまたはLightGBMでベースラインモデルを構築し、精度の目安を把握する
- AutoGluon等のAutoMLツールで複数モデルを自動評価し、最適なモデルを選定する










