この記事のポイント
 自社でNLPを活用するなら、まずLLM APIの導入を第一候補にすべき。形態素解析や構文解析を個別に実装する時代は終わり、GPT-5やClaude 4系が一気通貫で処理する
自社でNLPを活用するなら、まずLLM APIの導入を第一候補にすべき。形態素解析や構文解析を個別に実装する時代は終わり、GPT-5やClaude 4系が一気通貫で処理する- 日本語NLPはトークン消費が英語の4〜5倍になるため、コスト最適化にはモデル選定とプロンプト設計が不可欠
- 感情分析・FAQ対応・社内検索にはRAG+LLMの組み合わせが最も費用対効果が高く、ハルシネーション抑制にも有効
- NLP学習を始めるならspaCyとHugging Faceが最適。無料で使え、Transformerモデルの実装まで一貫して学べる
- 多言語対応やバイアスの課題を放置したままNLPを本番投入するのは避けるべき。ファインチューニングとRAGで事前に対処してから展開すべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
自然言語処理(NLP)とは、人間が日常的に使う言葉(自然言語)をコンピュータが理解・生成・分析するためのAI技術です。ChatGPTの回答生成も、Google翻訳も、音声アシスタントの音声認識も、すべてNLPの技術がベースになっています。
本記事では、NLPの定義と仕組み、形態素解析から意味解析までの処理ステップ、BERTからGPT-5・Gemini 3に至る技術進化、感情分析・機械翻訳・RAGなどの活用事例、そして多言語対応やハルシネーションなどの課題までを体系的に解説します。
NLPの全体像を把握し、自社でのAI活用の判断材料としてご活用ください。
目次
自然言語処理(NLP)とは
自然言語処理(Natural Language Processing、NLP)とは、人間が日常的に使う言葉(自然言語)をコンピュータが理解・生成・分析するためのAI技術です。
ChatGPTが質問に回答するのも、Google翻訳がテキストを別の言語に変換するのも、Siriが音声コマンドを理解するのも、すべてNLPの技術がベースになっています。
NLPは機械学習とディープラーニングを組み合わせた技術であり、テキストや音声データから意味を抽出し、人間にとって自然な形で応答を生成します。


自然言語処理の仕組み
NLPは、人間の言語を段階的に分析して意味を理解します。主な処理ステップは以下の4つです。
形態素解析(字句解析)
テキストを最小の意味単位(形態素)に分割する処理です。日本語の場合、「東京都に住んでいます」を「東京都 / に / 住ん / で / い / ます」のように分割します。英語ではスペースで区切れますが、日本語は単語の境界が明確でないため、MeCabやspaCyなどの形態素解析エンジンが使われます。
構文解析
単語間の文法的な関係(主語・述語・修飾語など)を特定する処理です。文の構造をツリー状に表現し、「誰が」「何を」「どうした」という関係を把握します。
意味解析(セマンティック分析)
単語や文が持つ意味を理解する処理です。同じ「銀行」でも「川の銀行(bank)」と「金融の銀行(bank)」では意味が異なります。文脈に応じて適切な意味を判定するのが意味解析の役割です。
文脈解析
文と文の関係性やテキスト全体の一貫性を理解する処理です。代名詞が何を指しているか(照応解析)、会話の流れから意図を推測するなど、より高度な言語理解を実現します。
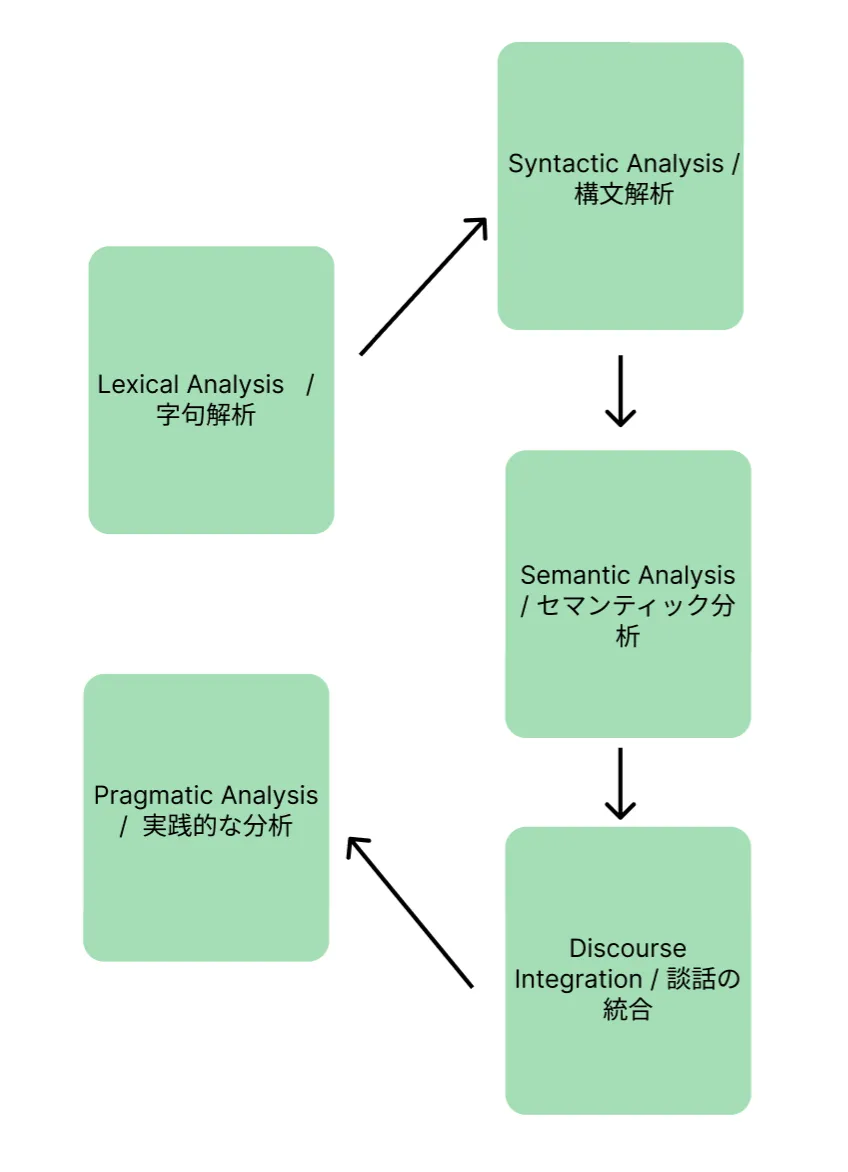
NLPプロセスの図解
2026年現在のLLMは、これら4つのステップをニューラルネットワークが内部的に処理しています。従来は各ステップを個別のモジュールで実装していましたが、Transformerアーキテクチャの登場以降はエンドツーエンド(入力から出力まで一気通貫)の処理が主流になりました。
自然言語処理の技術進化
NLPは過去数十年で劇的な進化を遂げました。特に2017年のTransformerの登場が転換点となり、LLMの時代が幕を開けました。
ルールベース時代(1960年代〜)
1966年に開発されたELIZAは、パターンマッチングによる対話を実現した最初のNLPシステムです。あらかじめ定義されたルールに基づいて応答を返す仕組みで、真の言語理解は行っていませんでしたが、AIによる対話の可能性を示した歴史的なプログラムです。
ELIZAの会話画面
統計的NLP時代(1990年代〜)
大量のテキストデータを統計的に分析し、確率モデルで言語パターンを捉える手法が主流になりました。隠れマルコフモデル(HMM)や条件付き確率場(CRF)が音声認識や品詞タグ付けで実用化されました。
Transformer・LLM時代(2017年〜)
Googleの研究チームが論文「Attention Is All You Need」で提案したTransformerアーキテクチャが、NLPの歴史を一変させました。自己注意機構により文中の長距離依存関係を効率的に捉えられるようになり、以下のモデルが次々と登場しました。
以下の表で、主要なNLPモデルの進化を整理しました。
| モデル | 開発元 | 年 | 特徴 |
|---|---|---|---|
| BERT | 2018 | 双方向の文脈理解。文分類・質問応答に強い | |
| GPT-2/3 | OpenAI | 2019/2020 | 自己回帰型のテキスト生成。Few-shot学習 |
| GPT-4 | OpenAI | 2023 | マルチモーダル対応。高度な推論能力 |
| GPT-5 / 5.2 | OpenAI | 2025/2026 | 推論能力の大幅向上。Reasoning effort制御 |
| Claude 4系 | Anthropic | 2025/2026 | 長文処理・安全性重視。100万トークン対応 |
| Gemini 3 | 2026 | マルチモーダル。Deep Research対応 |
BERTは文の理解(分類・検索)に、GPTは文の生成(対話・要約・翻訳)に特化しています。2026年現在のLLMはGPT系の自己回帰型が主流であり、理解と生成の両方を高いレベルで実現しています。

自然言語処理の活用事例
NLPはLLMの登場により、活用範囲が飛躍的に拡大しました。
感情分析
テキストに含まれる感情(肯定・否定・中立)を自動判定する技術です。SNSの投稿やカスタマーレビューから顧客の満足度をリアルタイムに把握し、マーケティング施策の改善に活用されています。
機械翻訳
Google翻訳やDeepLは、NLPの技術で一言語のテキストを別の言語に変換します。Transformerの登場以降、翻訳精度は飛躍的に向上し、ビジネス文書の翻訳でも実用的なレベルに達しています。
チャットボット・対話AI
ChatGPTに代表される対話AIは、NLPの最も身近な応用例です。カスタマーサポートの自動化、社内問い合わせ対応、教育支援など、幅広い分野で活用されています。
RAG(検索拡張生成)
RAGは、外部のドキュメントを検索してLLMに渡すことで、LLMの学習データにない最新情報や社内固有の知識に基づいた回答を生成する技術です。社内ナレッジ検索システムや法務・規制関連のQ&Aシステムで導入が進んでいます。
コード生成
GitHub CopilotやClaude Codeは、自然言語の指示からプログラミングコードを自動生成します。NLPが「人間の言語」と「プログラミング言語」の橋渡しを実現した事例です。
テキスト要約・情報抽出
大量のドキュメントから要点を抽出し、要約を生成する技術です。契約書のレビュー、ニュース記事の要約、会議議事録の自動作成などに活用されています。
自然言語処理の課題
NLPは急速に進化している一方で、いくつかの重要な課題が残っています。
ハルシネーション
LLMは事実と異なる情報を自信ありげに生成することがあります(ハルシネーション)。特に専門性の高い分野(法務・医療・金融)では、NLPの出力を人間が必ず検証するプロセスが不可欠です。RAGの導入や、出力の根拠を明示するGrounding技術で対策が進んでいます。
多言語対応
英語に比べて、日本語や韓国語などの膠着語、アラビア語やヘブライ語などの右から左に書く言語では、NLPの精度が低下する傾向があります。各言語の特性に合わせた前処理やモデルのファインチューニングが必要です。NTTのtsuzumiのように、日本語に特化した軽量LLMの開発も進んでいます。
バイアスと倫理的課題
LLMは学習データに含まれる偏見を反映した出力を生成する可能性があります。採用選考や与信審査など、人の権利に影響する判断にNLPを使う場合は、バイアスの検出とガードレールの設計が不可欠です。
計算コスト
大規模なLLMの学習と推論には膨大な計算リソースが必要です。量子化やSLM(小規模言語モデル)の活用で、コストと精度のバランスを取る取り組みが進んでいます。
NLP関連のツールと料金
NLPを実践するための主要なツールを以下の表で比較しました。
| ツール | 用途 | 料金(2026年2月時点) |
|---|---|---|
| spaCy | Pythonの産業用NLPライブラリ。形態素解析・固有表現認識 | 無料(オープンソース) |
| Hugging Face Transformers | 学習済みNLPモデルのハブ。BERT・GPT・Llama等を利用可能 | 無料(オープンソース)。Pro $9/月 |
| OpenAI API | GPT-5 miniからGPT-5.2まで。テキスト生成・分析 | GPT-5 mini: $0.25/$2.00(100万トークン) |
| Claude API | Claude Sonnet 4.6 / Opus 4.6。長文処理に強い | Sonnet 4.6: $3.00/$15.00(100万トークン) |
| MeCab | 日本語形態素解析の定番 | 無料(オープンソース) |
| Azure AI Language | 感情分析・固有表現認識・キーフレーズ抽出等のAPI | 従量課金(1,000テキストレコードあたり$1〜) |
個人の学習や研究にはspaCyとHugging Faceの組み合わせで無料で始められます。本番アプリケーションにNLPを組み込む場合は、OpenAI APIやClaude APIの利用が最も手軽です。

自然言語処理の理解を業務へのAI導入に活かす

生成AIの業務活用を体系的に学べるガイド
自然言語処理の仕組みを理解すると、チャットボットの導入、文書の自動分類、感情分析によるVOC活用など、テキストデータを扱う業務へのAI応用が具体的にイメージできます。AI総合研究所では、Microsoft環境でAI業務自動化を段階的に進める手順をまとめたガイドを無料で提供しています。
自然言語処理の理解を業務へのAI導入に活かすなら
自然言語処理の仕組みを理解すると、チャットボットによる問い合わせ対応、文書の自動分類、顧客レビューの感情分析など、テキストデータを扱う業務へのAI応用が現実的に見えてきます。形態素解析から文脈理解までの処理段階を知っておくことで、AIツールの得手不得手を的確に判断できるようになります。
AI総合研究所では、自然言語処理を含む生成AI全般を業務プロセスに導入するための手順をまとめた「AI業務自動化ガイド」を無料で提供しています。NLPの基礎を押さえた今、テキスト業務のAI化に踏み出してみてください。
自然言語処理の理解を業務へのAI導入に活かす
生成AIの業務活用を体系的に学べるガイド
自然言語処理の仕組みを理解すると、チャットボットの導入、文書の自動分類、感情分析によるVOC活用など、テキストデータを扱う業務へのAI応用が具体的にイメージできます。AI総合研究所では、Microsoft環境でAI業務自動化を段階的に進める手順をまとめたガイドを無料で提供しています。
まとめ
自然言語処理(NLP)は、人間の言語をコンピュータが理解・生成するためのAI技術であり、形態素解析から文脈解析までの段階的な処理で言語の意味を捉えます。
2026年現在、NLPの中核はTransformerアーキテクチャをベースとしたLLMであり、GPT-5、Claude 4系、Gemini 3がその代表です。チャットボット、機械翻訳、RAG、コード生成など、NLPの活用範囲はLLMの登場で飛躍的に拡大しました。
NLPを活用したい場合は、まずOpenAI APIやClaude APIで小さなプロトタイプを作り、自社の業務でどの程度の効果があるかを検証するところから始めてみてください。










