この記事のポイント
 画像分類の入門にはCNNが最適で、TensorFlow+Kerasなら数十行のコードで基本構造を実装可能
画像分類の入門にはCNNが最適で、TensorFlow+Kerasなら数十行のコードで基本構造を実装可能- 畳み込み層→プーリング層→全結合層の3層構造で画像の特徴を階層的に抽出する、画像認識の基盤技術
- Google・Tesla・Bosch・AWS・Philipsなど6社の事例が示す、自動運転から医療診断まで幅広い産業での実用化
- 2026年はVision Transformerとのハイブリッドが主流化し、物体検出ならYOLO26、画像分類ならConvNeXt V2が有力選択肢
- データ不足には転移学習、計算コストには量子化、ブラックボックス性にはGrad-CAMによる可視化が実務上の対策手段

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
「画像分類や物体検出を実装したいが、CNNの仕組みがよくわからない」——CNN(畳み込みニューラルネットワーク)は画像認識の基盤技術で、自動運転から品質検査まで幅広い分野で使われています。
2026年時点ではVision Transformer(ViT)との統合やYOLO26の登場など、CNNを取り巻く技術動向も大きく変化しています。
本記事では、CNNの基本原理からTensorFlowによる実装コード、Google・Tesla・Boschなど企業6社の活用事例、最新モデルの動向までを解説します。
目次
CNNとは
CNN(畳み込みニューラルネットワーク)は、画像を見て「何が写っているか」を判断できるAIの仕組みです。例えば、写真を見て「これは猫だ」「これは車だ」と識別してくれます。
身近なたとえで言えば、目のいい友達が写真を見て「耳があって、しっぽがあるね。これは猫だ」と説明してくれるイメージです。CNNはこのように画像の情報を部分ごとに分析し、人間のように「何が写っているか」を理解する仕組みです。
2012年のImageNetコンペティションでAlexNetが従来手法を大幅に上回る精度を達成して以降、CNNは画像認識の標準的なアーキテクチャとして定着しました。2026年現在でもVision Transformer(ViT)とのハイブリッドモデルが研究の主流になるなど、CNNの設計思想は依然として画像処理の基盤を支えています。

ニューラルネットワークとの違い
ニューラルネットワークと聞くと、漠然と「AIの基本的な仕組み」とイメージする方も多いでしょう。しかし、CNN(畳み込みニューラルネットワーク)は、一般的なニューラルネットワークと少し違った特性を持っています。その違いを知ることで、なぜCNNが画像認識に特化しているのかを理解できるようになります。
ニューラルネットワークとは
普通のニューラルネットワークは、すべての情報をひとまとめにして考える仕組みです。例えば画像を扱う場合、写真のピクセルを1列に並べて計算するため、「どこに耳があるか」「目がどこにあるか」などの位置関係は考慮しません。
一方でCNNは、画像を理解するのに特化したニューラルネットワークです。
ニューラルネットワークとの違い
- ニューラルネットワーク
全体をひとまとめにして考えるため、計算負荷が大きく、画像の構造(位置関係)を無視してしまいます。数字やテキストの処理に向いており、株価予測や文章分類などに使われます。時系列データにはRNN(再帰型ニューラルネットワーク)が適しています。
- CNN
画像の特徴を効率よく見つける仕組みを持ち、画像や空間の情報を上手に活用できます。猫と犬の識別や自動運転の物体検出など、画像・映像を扱う場面に強みがあります。
AIなどと比較すると以下のように示すことができます。
ニューラルネットワークの一般的な仕組みと比較することで、CNNがどのように特別なのか、その特性がクリアになりました。これを踏まえ、さらに深くCNNの魅力を掘り下げてみましょう。
画像認識における役割
画像認識におけるCNNの役割は、写真や画像を見て「何が写っているのか」を判断するAIの仕組みです。
画像を理解する3ステップ
CNNは画像を「部分ごとに特徴を見つけて、全体を判断する」役割を果たします。以下の3つのステップで動作します。
-
特徴を見つける(どんな模様があるか探す)
まず、画像を小さなエリアに分けて、「線」「丸い形」「角」などの特徴を探します。例えば、猫の耳の三角形や犬の目の丸い形を見つけるイメージです。
-
特徴を組み合わせる(全体像をつかむ)
見つけた小さな特徴を組み合わせて、「この形は猫の顔っぽい」「これは車のボディだな」と判断します。
-
最終的な答えを出す
「これは猫」「これは車」と分類結果を出力します。
CNNの力は、画像認識の精度を飛躍的に高め、人間の視覚を補完する新たな道を切り開いています。この技術が日常生活でどのように活かされているのか、さらに探ってみましょう。
CNNの構造
CNNは複数の層が重なり合って構成される深層学習モデルです。主に畳み込み層、プーリング層、全結合層から成り、それぞれが異なる役割を持っています。
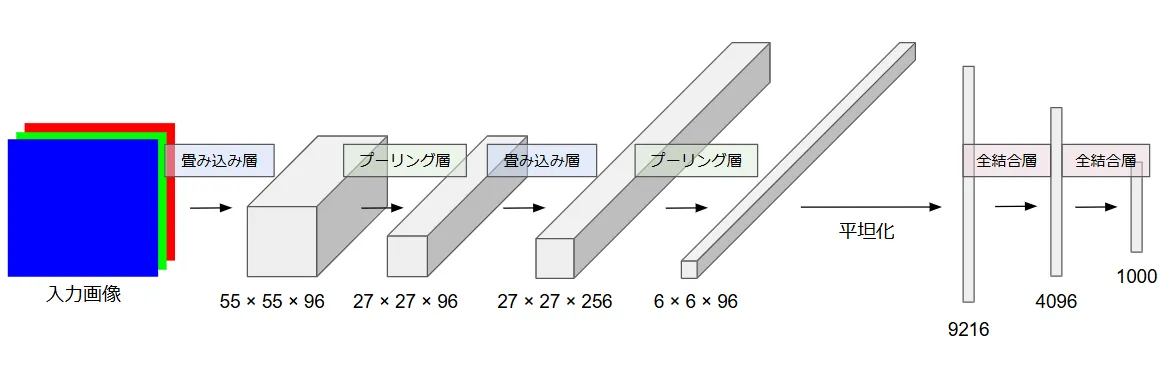
畳み込み層(Convolutional Layer)
畳み込み層は、CNNの中で画像やデータから特徴を抽出する役割を担っています。具体的には、画像を小さな「フィルタ(カーネル)」を使ってスキャンし、特徴を見つけます。
| 要素 | 説明 |
|---|---|
| 役割 | 画像から特徴を抽出 |
| 処理内容 | フィルタによる畳み込み演算 |
| パラメータ | ・フィルタサイズ ・ストライド ・パディング |
| 出力 | 特徴マップ |
フィルタとは、小さなマトリックス(例えば3x3や5x5のサイズ)のことです。画像全体をスライドしながらこのフィルタを適用し、特定の特徴(エッジや模様など)を見つけるように学習されます。畳み込み演算では、フィルタを画像にスライドさせてピクセルの値とフィルタの値を掛け合わせ、その合計を求めます。この演算を画像全体に適用することで、新しい特徴マップ(Feature Map)が生成されます。
例えば、画像に「直線」や「円」がある場合、畳み込み層はそれを検出します。最初は簡単な特徴(線やエッジ)を抽出し、次の層でそれらを組み合わせてより複雑な特徴(顔の輪郭や物体の形)を認識していきます。
畳み込み層は、画像から重要な特徴を抜き出す土台です。この層があるおかげで、CNNは複雑なパターンを認識できるのです。
プーリング層(Pooling Layer)
プーリング層は、画像のサイズを縮小して計算を効率化するとともに、重要な特徴を保持するために使われます。プーリングは、畳み込み層で抽出した特徴を圧縮して、データの次元(サイズ)を削減します。
| 処理タイプ | 特徴 |
|---|---|
| Max Pooling | 領域内の最大値を選択 |
| Average Pooling | 領域内の平均値を計算 |
| Global Pooling | 特徴マップ全体を集約 |
最も一般的なMax Poolingでは、画像を小さな領域(例えば2x2)に分けて、その領域内の最大値を取ります。これにより、重要な情報を残しつつデータを圧縮できます。Average Poolingは領域内の平均値を取る方式で、Max Poolingよりも情報が滑らかに保たれます。
画像が「猫の顔」の特徴を持っているとき、Max Poolingは猫の顔の特徴を保持しつつ背景の細かい部分を無視します。次の層で計算する際にデータ量が削減されるため、処理速度の向上につながります。
例えば以下は範囲内の合計を集約するプーリングとなっており、緑の領域内の合計値/2の値が右に記載されていますね。
このような操作をプーリングといいます。
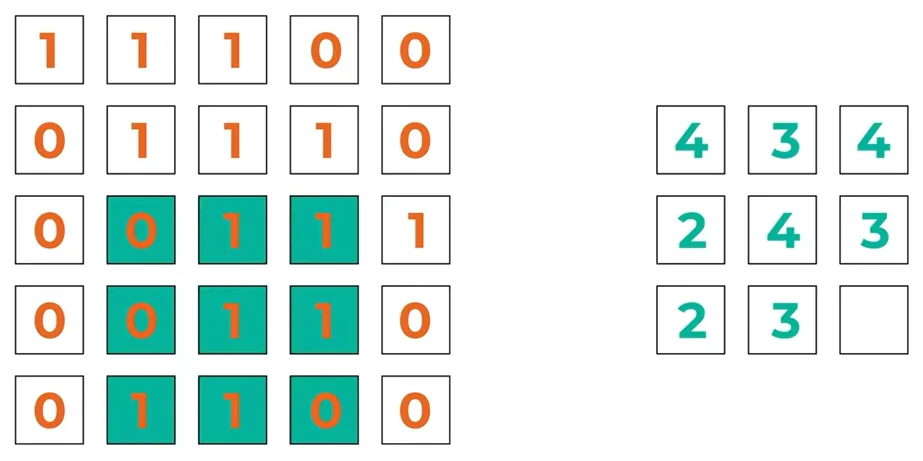
引用元:Packt Youtube
プーリング層のおかげで、CNNは無駄を省きつつ重要な情報を保持できます。この効率性が、モデルの実用性を大きく高めているのです。
全結合層(Fully Connected Layer)
全結合層は、画像の特徴を最終的な結果に変換する役割を持っています。畳み込み層やプーリング層で抽出された特徴を使って、「これは猫だ」「これは犬だ」といった最終的な判断を下す層です。
処理の流れ
- 特徴を一つのベクトルに変換
畳み込み層とプーリング層で得られた特徴を平らに(1次元のベクトル)し、全結合層に入力します。この層がすべての特徴を結びつけて、最終的な判断を行います。
- ニューロン間の接続
全結合層では、すべてのニューロン(ユニット)が次の層のすべてのニューロンと接続されています。入力された特徴がすべてのニューロンに伝達され、それぞれのニューロンが重要度を学習します。
最後の層では、「これは猫」「これは犬」というクラス分類を行います。例えば、最初に「猫の耳」や「犬の鼻」といった特徴を抽出し、最後にそれらを組み合わせて「この画像は猫だ」と決定します。
全結合層は、CNNの最終的なアウトプットを形作る重要な部分です。この層のおかげで、モデルは「この画像は何か」という答えを出せるのです。
CNNの学習
学習データ
CNNが学習するためには「データ」が必要不可欠です。このデータが、モデルに知識を与え、成長させる原動力となります。質の高いデータが用意されていれば、モデルのパフォーマンスも飛躍的に向上します。
- 訓練データ(Training Data) モデルの学習に使用されるデータ。
- 検証データ(Validation Data) モデルのハイパーパラメータ調整や過学習の検出に使用されるデータ。
- テストデータ(Test Data) 最終的なモデルの評価に使用されるデータ。
それぞれの役割を具体例で整理すると、訓練データは「芝生の上で遊ぶ犬」「ソファの上で寝ている猫」のようにモデルが特徴を学ぶための画像です。検証データは「別の角度から撮影された犬」「木の下で撮られた猫」のように、モデルの調整時に使用されます。テストデータは「プールサイドで遊ぶ犬」「冬の背景で撮影された猫」のように、完全に新しいデータでモデルの最終的な性能を評価するために使います。
活性化関数
活性化関数は、CNNの中で「ニューロン」を活性化させるスイッチのようなものです。このスイッチが、モデルに複雑なパターンを学習する力を与えています。主な活性化関数は以下の通りです。
| 活性化関数 | 数式 | 特徴 |
|---|---|---|
| シグモイド関数 | $ \sigma(x) = \frac{1}{1 + e^{-x}} $ | 出力値が0から1の範囲。勾配消失問題を起こしやすい。 |
| ハイパボリックタンジェント | $ \tanh(x) = \frac{\exp(x) - \exp(-x)}{\exp(x) + \exp(-x)} $ | 出力値が-1から1の範囲。シグモイドより中心が0に近い。 |
| ReLU | $ \text{ReLU}(x) = \max(0, x) $ | 負の入力を0、正の入力をそのまま出力。計算が高速で、勾配消失を軽減。ただし、死んだニューロン問題が発生する可能性がある。 |
それぞれの活用例として、シグモイド関数は猫と犬の画像分類で犬である確率
損失関数
損失関数は、モデルが間違った場合に「どれだけ間違えたか」を教えてくれる指標です。いわば、モデルに対する教師のような存在で、「ここが間違いだよ」とフィードバックを与えます。
| 損失関数 | 数式 | 適用例 |
|---|---|---|
| 平均二乗誤差 (MSE) | $ MSE = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2 $ | 回帰問題でよく使用される。 |
| クロスエントロピー誤差 | $ CE = -\sum y \log(\hat{y}) $ | 分類問題で広く使用される。 |
平均二乗誤差はeコマースでの商品需要予測のような回帰問題に適しており、クロスエントロピー誤差は画像認識や顔認証のような分類問題で広く使われています。CNNの画像分類タスクでは、クロスエントロピー誤差が標準的な選択です。
最適化アルゴリズム
最適化アルゴリズムは、モデルが効率よく学習するための道具箱のようなものです。損失を減らすために重みやバイアスを調整し、モデルをより良い状態へ導きます。代表的なアルゴリズムは以下の通りです。
| アルゴリズム | 特徴 |
|---|---|
| 確率的勾配降下法 (SGD) | シンプルで計算効率が良いが、局所最適解に陥る可能性がある。 |
| Adam | SGDを改良し、学習率の調整を自動化。高速かつ安定した収束を実現。 |
過学習
過学習とは、モデルが訓練データにこだわりすぎて、まるで「教科書を暗記しているだけ」の状態になることです。この状態では、未知のデータに対してうまく対応できなくなります。過学習を防ぐための手法として以下が挙げられます。
- ドロップアウト
学習時にランダムに一部のニューロンを無効化し、モデルの汎化性能を向上させます。
- 正則化
損失関数にペナルティ項を追加し、モデルの複雑さを抑制します。L1正則化は重みの絶対値の和をペナルティとし、L2正則化は重みの二乗和をペナルティとします。
これらの要素を適切に組み合わせることで、CNNの学習が効果的に行われます。ディープラーニング全般に共通する概念ですが、CNNでは特に画像データの特性に合わせたパラメータ調整が重要になります。
CNNの実装
ここではTensorFlowを使って、実際にCNNモデルを構築・学習する手順を紹介します。PyTorchでも同様の実装が可能ですが、本記事ではTensorFlowのFunctional APIを使用します。手書き数字データセット(MNIST)を使い、畳み込み層・プーリング層・全結合層の動作を確認します。
模擬コード
以下のコードは、TensorFlowのFunctional APIでCNNモデルを定義し、MNISTデータセットで学習した後、各畳み込み層の特徴マップを可視化するものです。
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.keras import layers, models, Model
# 1. MNISTデータセットのロードと前処理
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
# データの前処理(画像を28x28x1にリシェイプし、正規化)
train_images = train_images.reshape((train_images.shape[0], 28, 28, 1)).astype('float32') / 255
test_images = test_images.reshape((test_images.shape[0], 28, 28, 1)).astype('float32') / 255
# 2. CNNモデルの定義(Functional APIを使用)
input_img = layers.Input(shape=(28, 28, 1))
# 畳み込み層1
x = layers.Conv2D(8, (3, 3), activation='relu', name='conv1')(input_img)
x = layers.MaxPooling2D((2, 2), name='pool1')(x)
# 畳み込み層2
x = layers.Conv2D(16, (3, 3), activation='relu', name='conv2')(x)
x = layers.MaxPooling2D((2, 2), name='pool2')(x)
# 畳み込み層3
x = layers.Conv2D(32, (3, 3), activation='relu', name='conv3')(x)
# 平坦化と全結合層
x = layers.Flatten(name='flatten')(x)
x = layers.Dense(64, activation='relu', name='dense1')(x)
output = layers.Dense(10, activation='softmax', name='output')(x)
# モデルの作成
model = Model(inputs=input_img, outputs=output)
# モデルのコンパイル
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# モデルの訓練(1エポック)
history = model.fit(train_images, train_labels, epochs=1, batch_size=64, validation_split=0.1)
# モデルの概要を表示
model.summary()
# 3. 中間層の出力を取得するためのモデルの定義
# 特徴マップを取得したい層をリストに追加
layer_names = ['conv1', 'conv2', 'conv3']
layer_outputs = [model.get_layer(name).output for name in layer_names]
# 中間層の出力を取得するモデル
activation_model = Model(inputs=model.input, outputs=layer_outputs)
# 4. 特徴マップを取得するために予測を実行
# 例として最初のテスト画像を使用
img = test_images[0].reshape(1, 28, 28, 1)
activations = activation_model.predict(img)
# 5. 特徴マップの可視化
for layer_name, layer_activation in zip(layer_names, activations):
num_filters = layer_activation.shape[-1]
size = layer_activation.shape[1]
# フィルタ数を表示する数に制限
num_display = min(8, num_filters)
# プロットの設定
fig, axes = plt.subplots(2, 4, figsize=(12, 6))
fig.suptitle(f'Feature maps from layer: {layer_name}', fontsize=16)
for i in range(num_display):
row = i // 4
col = i % 4
ax = axes[row, col]
ax.imshow(layer_activation[0, :, :, i], cmap='viridis')
ax.axis('off')
ax.set_title(f'Filter {i+1}')
# 残りのサブプロットを削除
for i in range(num_display, 8):
fig.delaxes(axes.flatten()[i])
plt.tight_layout()
plt.subplots_adjust(top=0.88) # タイトルの位置調整
plt.show()
# 画像として保存(オプション)
fig.savefig(f'feature_maps_{layer_name}.png')
実行結果
実行するとCNNの過程が明らかですね!

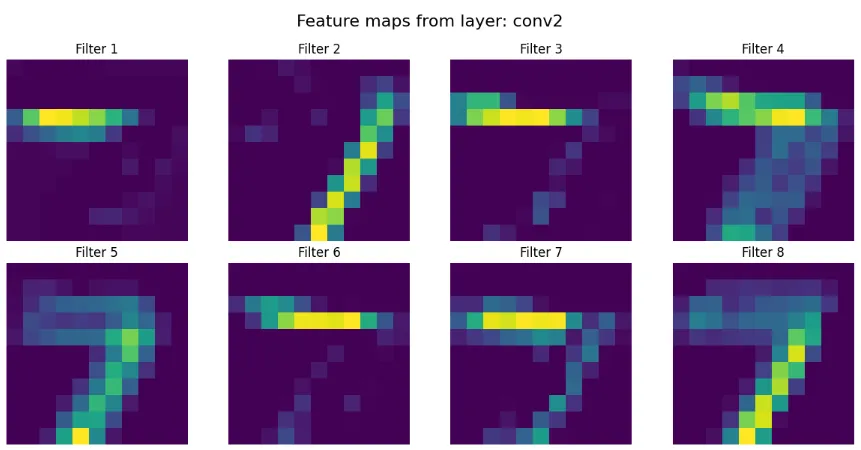

実行過程の画像
conv1→conv2→conv3と層が深くなるにつれて、抽出される特徴がエッジのような単純なパターンから、より複雑な形状パターンへと変化していくことが確認できます。この階層的な特徴抽出がCNNの強みです。

CNNの活用例
ディープラーニングの中でもCNNは特に画像処理分野で幅広く活用されています。産業から研究まで、さまざまな分野で実用化が進んでいます。
画像認識
「この画像には何が写っているのか?」そんな問いに答えるのが画像認識技術の役割です。そして、その中核を担っているのがCNNです。
| 適用分野 | 具体例 | 特徴 |
|---|---|---|
| SNS | 顔認識タグ付け | ・リアルタイム処理 ・高精度な認識 |
| セキュリティ | 監視カメラ解析 | ・24時間監視 ・異常検知 |
| コンテンツ管理 | 画像分類 | ・自動タグ付け ・検索効率化 |
Googleの例

引用元:TensorFlow
Googleは、画像認識や物体検出に深層学習(CNNを含む)技術を活用しています。特にGoogle Photosの自動タグ付けや検索機能では、CNNが使われています。Googleのディープラーニングライブラリ「TensorFlow」は、CNNを効率的に実装できるプラットフォームとして広く使用されています。

引用元:TensorFlow core
物体検出
自動運転や監視システムでの活用例:
- 歩行者の検出
- 車両の認識
- 障害物の検知
Teslaの例
Teslaの自動運転技術(Autopilot/FSD)では、CNNを用いた画像処理が中核を担っています。カメラ映像から歩行者や他の車両、標識などをリアルタイムで認識する物体検出にCNNが使われています。
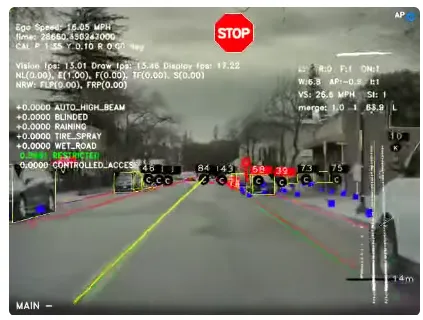
引用元:Tesla
画像分類
産業での実用例:
- 製品の品質管理
- 不良品の自動検出
- 商品の自動仕分け
Boschの例
Boschは、製造ラインでの品質管理にAIと画像認識技術を活用しており、不良品を自動で検出するシステムを提供しています。CNNを使用して部品の形状や表面の欠陥をリアルタイムでチェックしています。

引用元:Bosch
セグメンテーション
医療分野での活用:
- 臓器の領域分割
- 病変部の特定
- 手術支援システム
Microsoftの例
Microsoftは、CNNを活用して衛星画像や航空写真から地物(建物、道路、河川など)をセグメント化する技術を提供しています。この技術は、農業や都市計画、災害対応などの分野で活用されています。Microsoft AzureのAIツールは、セグメンテーション技術を使って地理情報の解析を効率化しています。
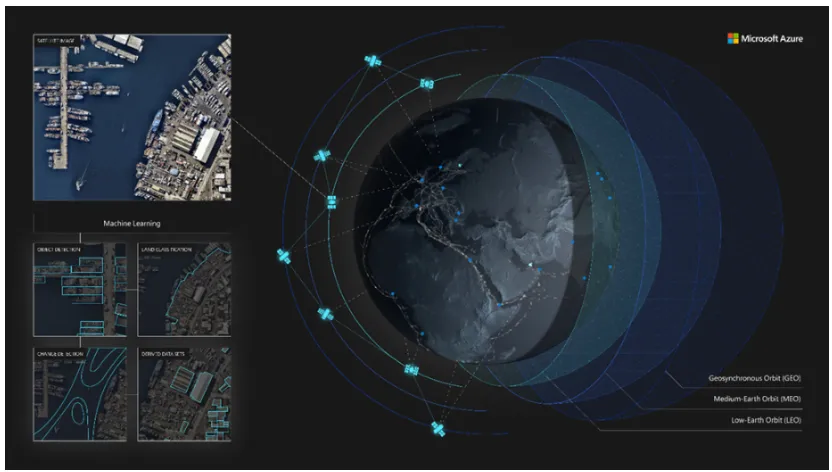
引用元:Microsoft
顔認識
| 用途 | 具体例 |
|---|---|
| 認証 | ・スマートフォンのロック解除 ・入退室管理 |
| マーケティング | ・顧客分析 ・行動追跡 |
| エンターテイメント | ・フィルター効果 ・アバター生成 |
Amazon Web Servicesの例
AWS Rekognitionは、CNNを使用した顔認識技術を提供するクラウドサービスで、顔の検出や分析、顔同士の一致の確認を行います。企業はこのサービスを活用して、監視カメラ映像から顔を認識したり、ユーザーの顔情報をもとにパーソナライズされたサービスを提供したりしています。

引用元:AWS
医療画像診断
| 診断分野 | 応用例 |
|---|---|
| X線検査 | 骨折検出、肺炎診断 |
| MRI | 腫瘍検出、脳疾患診断 |
| 内視鏡 | 病変部位の特定 |
Philips Healthcareの例
Philips Healthcareは、CNNを利用した医療画像診断ソリューションを提供しています。CTスキャン、MRI、X線画像における病変検出や診断支援を行っており、がんや脳卒中などの早期発見をサポートしています。医師の診断精度を向上させるツールとして、医療現場で導入が進んでいます。
引用元:Philips
CNNの発展と未来
CNNは1990年代から現在に至るまで、急速な進化を遂げています。技術の発展と共に、より高度な画像認識や新たな応用分野が開拓され続けています。
最新モデル
CNNの進化はとどまるところを知りません。ResNetやEfficientNetなど、これまで登場してきたモデルはそれぞれ独自の特長を持ち、さまざまな課題を解決してきました。2026年時点では、精度を高めつつ計算コストを抑えるモデルや、Vision Transformer(ViT)の設計思想を取り入れたハイブリッドモデルが主流になっています。
以下の表で、代表的なCNNモデルの特性を整理しました。
| モデル | 開発元 | 主な特徴 | 用途 |
|---|---|---|---|
| EfficientNet | スケーリング手法で高精度・低計算コスト | モバイル・エッジデバイス | |
| ResNet | Microsoft Research | 残差接続で100層超の深層学習が安定 | 大規模データセットの分類 |
| ConvNeXt V2 | Meta AI | Transformer設計をCNNに導入、ImageNet top-1精度88.9% | 汎用画像認識 |
| YOLO26 | Ultralytics(2026年1月) | NMSフリー、5タスク対応、エッジ最適化 | リアルタイム物体検出 |
EfficientNet
EfficientNetは、Googleが開発したCNNモデルで、最適化されたアーキテクチャとスケーリング手法(入力画像サイズ・ネットワークの深さ・幅・解像度の調整)を組み合わせて、効率的に高精度を達成します。計算資源を抑えながら高精度な結果を出せるため、モバイルデバイスなどリソースが限られた環境で注目されています。公式リポジトリはEfficientNet(GitHub)で公開されています。
ResNet(Residual Networks)
ResNetは、非常に深いニューラルネットワークでも学習が安定するように設計されたCNNアーキテクチャです。残差接続(Residual connections)を使用することで、深いネットワークでも勾配消失問題を回避し、より高精度な学習が可能になります。100層以上のモデルでも安定して学習でき、大規模データセットで優れたパフォーマンスを発揮します。公式リポジトリはResNet(GitHub)で公開されています。
ConvNeXt V2
ConvNeXt V2は、Meta AIが開発したCNNモデルで、Transformerの設計思想をCNNアーキテクチャに取り入れています。Masked Autoencoder(MAE)との共同設計により、ImageNet top-1精度88.9%を達成しました。Vision Transformerが注目される中でも、純粋なCNNアーキテクチャが依然として高い性能を出せることを示したモデルです。
YOLO26
YOLOは、物体検出において高速かつ高精度なモデルとして広く知られています。2026年1月にリリースされたYOLO26は、従来のNMS(Non-Maximum Suppression)を不要にしたエンドツーエンド検出を実現し、物体検出・セグメンテーション・姿勢推定・回転物体検出・分類の5タスクに対応しています。エッジデバイスへの最適化も強化されており、自動運転や監視システムでのリアルタイム処理に適しています。
今後の展望
技術の進化に伴い、CNNにも新しい可能性が広がっています。計算効率の向上や軽量化に加え、Vision Transformerとのハイブリッド活用が進むことで、これまで以上に実世界での応用が期待されています。
Vision Transformerとの融合
2020年以降、Vision Transformer(ViT)が画像認識分野で台頭していますが、CNNが完全に置き換えられたわけではありません。2026年現在はCoAtNetやConvNeXt V2のように、CNNの局所特徴抽出とTransformerの大域的注意機構を組み合わせたハイブリッドモデルが研究の主流です。小規模データセットやエッジ環境ではCNNの方が有利なケースも多く、用途に応じた使い分けが求められています。
エッジデバイスでの展開
エッジAI市場は2025年に約2,490億ドル規模に達し、2033年には約1兆1,870億ドル(CAGR 21.7%)まで拡大すると予測されています。CNNの量子化(4-8倍の圧縮)により、GPUだけでなくNPUやスマートフォンのチップでもリアルタイム推論が可能になっており、製造ラインの異常検知や医療機器での即時診断など、クラウドに依存しない処理が現実のものとなっています。
ハードウェアの進化
半導体技術の微細化と専用アクセラレータの普及により、CNNの処理速度は大幅に向上しています。NVIDIAのTensorRTなどの推論最適化ツールを使えば、学習済みモデルを数倍高速に実行でき、より複雑なモデルのリアルタイム処理が可能です。
次世代デバイス技術
スピントロニクスや量子デバイスなど、次世代のデバイス技術が開発中です。これらが実用化されることで、CNNの性能や応用範囲が飛躍的に拡大する可能性があります。これらの進展により、CNNがさらに多くの分野で活用され、産業や生活に大きな影響を与えることが期待されています。

AI技術の理解を組織の業務設計に落とし込むなら
CNNの仕組みや活用事例を理解した方は、AIが「何をどこまでできるか」を技術的に判断できる立場にいます。この知見は、画像認識に限らず、組織全体の業務プロセスにAIをどう組み込むかの設計にも直結します。技術の理解があるからこそ、「AIに任せる業務」と「人が判断すべき業務」の線引きを正しく設計できます。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に進めるための実践ガイド(220ページ)を無料で提供しています。Copilot Chatでの個人業務効率化からCopilot Studio、Microsoft Foundryへとスケールする導入設計を、経費精算・申請承認・人事・情シスなど部門別のBefore/After・KPI付きで解説しています。AIの性能より業務設計と運用設計が成否を分けるという視点は、CNN実装で培った「データと精度の関係」を理解している方にこそ響く内容です。
AI総合研究所の専任チームが、AI技術への理解を組織全体の業務導入計画に接続するところまで支援します。まずはガイドで段階設計の進め方をご確認ください。
AI技術理解の次は組織での実装設計へ

技術知識を業務プロセス改善に活かす
CNNの仕組みを理解したなら、次は組織としてAIをどう業務に実装するかの設計が重要です。Microsoft環境での段階的なAI導入を220ページの実践ガイドで解説しています。
CNNの注意点と限界
CNNは画像認識分野で高い性能を発揮しますが、万能ではありません。導入や活用にあたって理解しておくべき注意点を整理します。
以下の表で、CNNの主な限界とその対策を整理しました。
| 課題 | 内容 | 対策 |
|---|---|---|
| 大規模データの必要性 | 高精度なモデルには数万~数十万枚の学習画像が必要 | データ拡張(Data Augmentation)、転移学習の活用 |
| 計算コスト | 学習・推論ともにGPU/TPUなど専用ハードウェアが必要 | モデル軽量化(量子化・蒸留)、エッジ向け最適化 |
| 解釈性の低さ | 判断根拠がブラックボックスになりやすい | Grad-CAMなどの可視化技術、XAI(説明可能AI)の導入 |
| 位置不変性の限界 | 回転・スケール変化に対する頑健性が不十分な場合がある | データ拡張で多様な変換パターンを学習に含める |
大規模データと計算リソース
CNNが高い精度を出すためには、質の高い大量の学習データが不可欠です。医療画像のようにアノテーションコストが高い分野では、データ収集自体がボトルネックになります。また、学習には高性能なGPUが必要で、数日から数週間かかるケースも珍しくありません。転移学習を活用すれば、少ないデータでも事前学習済みモデルの知識を再利用できるため、コストと時間を大幅に削減できます。
Vision Transformerとの使い分け
2026年現在、画像認識分野ではVision Transformer(ViT)が注目を集めていますが、すべてのケースでCNNより優れているわけではありません。大規模データセットではViTが高い性能を示す一方、小規模データセットやエッジデバイスではCNNの方が学習効率と推論速度の面で有利です。目的やリソースに応じて、CNN単体・ViT単体・ハイブリッドモデルを使い分けることが実務上の最適解です。
判断根拠の説明性
CNNは「なぜその判断をしたのか」を人間が理解しにくいという課題があります。特に医療診断や自動運転のような安全性が求められる分野では、判断根拠の説明性が重要です。Grad-CAMなどの可視化手法を使えば、モデルが画像のどの部分に注目して判断したかを確認できます。また、GAN(敵対的生成ネットワーク)で生成された画像への耐性も考慮が必要です。導入時には、精度だけでなく説明可能性の確保も計画に含めることが重要です。
まとめ
畳み込みニューラルネットワーク(CNN)は、画像や映像の中から意味を見つけ出す技術です。一般的なニューラルネットワークと異なり、画像の形や模様、色の違いを読み取り、それをもとに判断を下せる仕組みを持っています。
CNNの進化は、医療・自動運転・製造業など幅広い産業で実用化が進んでおり、2026年時点ではConvNeXt V2やYOLO26のような最新モデル、Vision Transformerとのハイブリッド活用、エッジデバイスへの展開が新たな潮流になっています。
CNNを活用する第一歩として、次の3つのステップが有効です。
- 本記事のTensorFlow実装コードで基本的な動作を体験する
- 自社の課題に近い活用事例を参考に、適用可能性を検討する
- 転移学習やモデル軽量化など、リソースに合った導入方法を選定する










