この記事のポイント
 DeepSeekのAPIは入力$0.14/100万トークンと業界最安水準のため、コスト最優先のバッチ処理や大量推論用途には有力な選択肢
DeepSeekのAPIは入力$0.14/100万トークンと業界最安水準のため、コスト最優先のバッチ処理や大量推論用途には有力な選択肢- MoE+MLA+GRPOの技術スタックは「限られたGPUで高性能を出す」設計思想であり、自社でローカル推論環境を構築する際の参考アーキテクチャとして最適
- ただし中国企業である以上、機密データの処理にDeepSeek APIを直接利用するのは避けるべき。オンプレミスでのOSSモデル運用か、Azure経由での利用が安全策
- MITライセンスのオープンソースモデルとして公開されているため、自社環境へのデプロイやファインチューニングが自由に行える点は大きな優位性
- AI開発コストの常識を覆した事例として、自社AI戦略の予算策定時には「DeepSeek型の効率開発」も選択肢に含めるべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
近年、AI開発競争が激化する中で、「高性能なAIには、巨額の資金と最先端の設備が不可欠」という常識を覆す企業が現れました。
それが、中国発のAIスタートアップ「DeepSeek(ディープシーク)」です。
DeepSeekは、限られたリソースでOpenAIに匹敵するAIモデルを開発し、世界に衝撃を与えました。本記事では、このDeepSeekについて、その正体と革新的な技術、そしてAI市場への影響までを徹底解説します。
DeepSeekの登場により、AI開発の新たな潮流が生まれる可能性があります。
AI総合研究所ではディープシークについて野村証券様のセミナーで解説しました。
最新モデル「DeepSeek V3.2」については、こちらの記事で詳しく解説しています。 ▶︎DeepSeek-V3.2とは?使い方や料金、ベンチマーク性能を徹底解説!
目次
② GRPO(Guided Reward Policy Optimization)
③ 知識蒸留(Knowledge Distillation)
Microsoft Azure AI Foundryでの活用とその意味
DeepSeek(ディープシーク)とは?
DeepSeek(ディープシーク)とは、限られたリソースで世界トップレベルのAIを生み出した、中国・杭州発の革新的スタートアップです。
DeepSeekは、中国・杭州を拠点とするAIスタートアップで、2023年に連続起業家の梁文峰(Liang Wenfeng)氏によって設立されました。
同氏はこれまでに複数のAI関連ビジネスを立ち上げており、技術と投資の両面に通じた実績を持っています。
中国杭州: Google Mapより
DeepSeekは、資金調達に依存せず、自社主導でAIモデルの研究開発を進めている点が特徴です。商業化よりも技術革新を重視するアプローチにより、限られたリソースでありながら、競合大手に匹敵する性能を持つ高性能なオープンソースAIモデルを次々に発表しています。

DeepSeek(ディープシーク)が注目された理由
DeepSeekが世界的に注目を集めたきっかけは、OpenAIやAnthropicといった米国のAI企業に匹敵する性能を、圧倒的な低コストで実現した点にあります。
その象徴ともいえるのが、2024年から2025年にかけて発表されたDeepSeek-R1やそのベースモデルDeepSeek-V3-0324です。
これらのモデルは、一般的に高性能AIの開発に必須とされるNVIDIA H100のような高額GPUに依存せず、限られた計算資源と人員で驚異的な性能を実現しました。
主な注目ポイント
✅ Multi-Head Latent Attention(MLA)アーキテクチャの採用
→ 従来のMHA(Multi-Head Attention)よりもメモリ効率が高く、最大13%のメモリ削減を実現。
✅ MoE(Mixture-of-Experts)構造の一部、「DeepSeekMoESparse」技術を搭載
→ モデル内部の一部の専門家ネットワークだけを動かすことで、必要最小限の計算で推論を実行。
✅ 開発費 約1,000万ドル以下・従業員200人規模
→ これまで「数千億円規模の資金が必要」とされていた高性能AI開発に新たな常識を打ち立てた。
✅ 破格のAPI価格(MITライセンス)
→ 入力100万トークンあたり $0.14、出力100万トークンあたり $0.28 という、業界でも屈指の低価格で提供。
DeepSeekの取り組みは、「資金力よりもアーキテクチャの工夫と効率性が重要である」というメッセージを世界に発信しました。
この姿勢は、AI開発の民主化を象徴するものとして、グローバルな注目を集め続けています。
ディープシークショック:AI業界および株式市場への影響
DeepSeekの登場は、AI業界におけるハードウェア依存の概念を変える可能性を投げかけました。
特に、NvidiaのH100やH200、B200のような高性能GPUが必須であるという従来の認識に新たな視点をもたらし、発表直後にNvidiaの株価が約17%(90兆円規模)下落し世界を驚かせました。
一方、Nvidiaのジェンスン・ファンCEOは、CES 2025で「事前学習・強化学習・推論の3つのスケーリング則がAIの進化を支えており、今後も大規模な計算リソースが必要である」と強調しました。
これにより、AI開発におけるハードウェアの重要性は依然として高いことが示唆されています。
さらに、AnthropicのダリオCEOは、「ほぼすべての点でほぼすべての人間よりも賢いAIを作るには、数百万個のチップと数百億ドルが必要であり、2026〜2027年の実現が最も高い」と述べており、DeepSeekのリリースによっても、この基本的な状況が大きく変わることはないとしています。
DeepSeekが活用する主要技術
DeepSeekが開発するAIモデルの効率性の高さは、以下の3つの主要技術によって支えられています。
① MoE(Mixture of Experts)
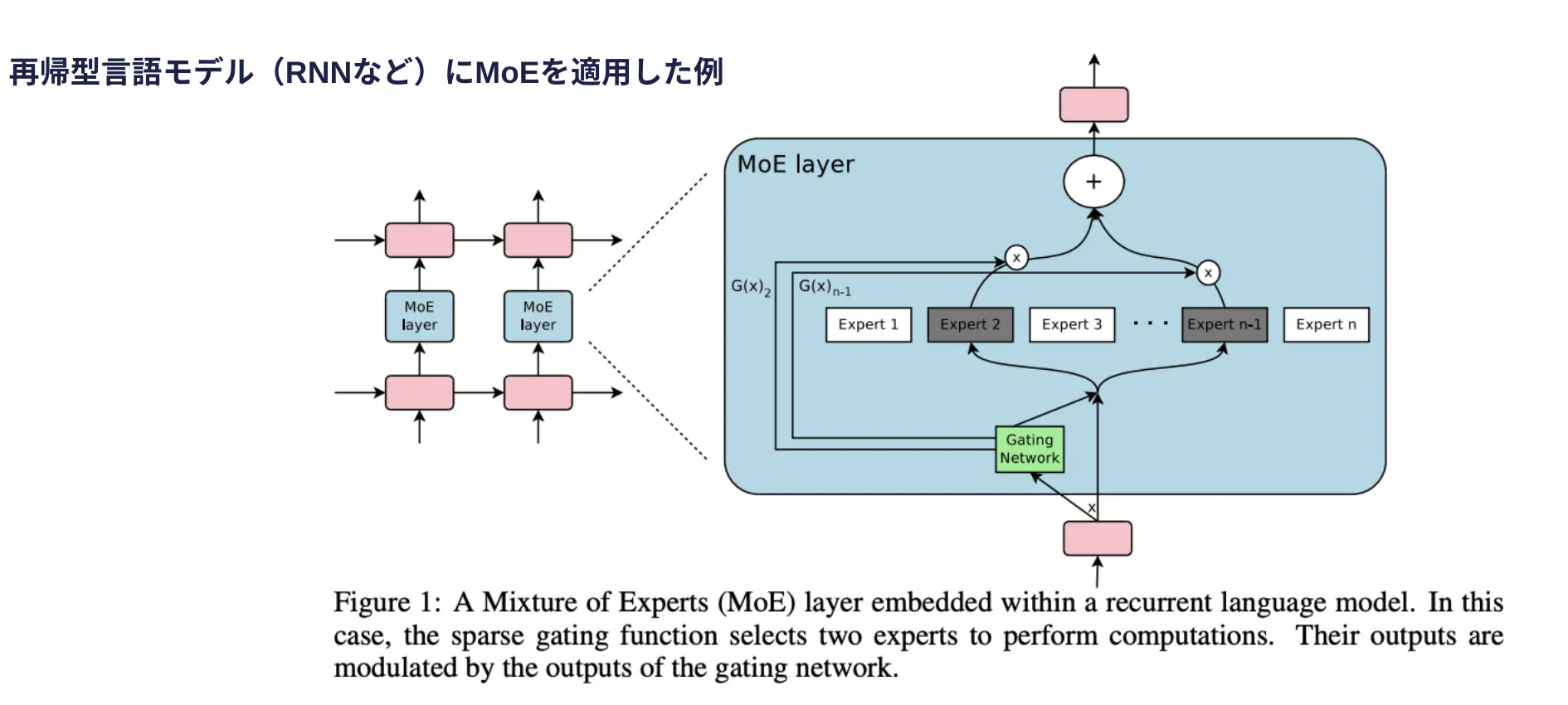
MoEは、専門家モデル(Experts)を選択的に活性化することで、計算コストを抑えながら高精度な推論を可能にする技術です。通常のニューラルネットワークとは異なり、入力ごとに異なる専門家モデルが選択されるため、計算負荷を削減しながら高い性能を維持できます。
この技術を活用することで、DeepSeekはメモリ使用量を削減しつつ、効率的な学習と推論を実現しています。
② GRPO(Guided Reward Policy Optimization)
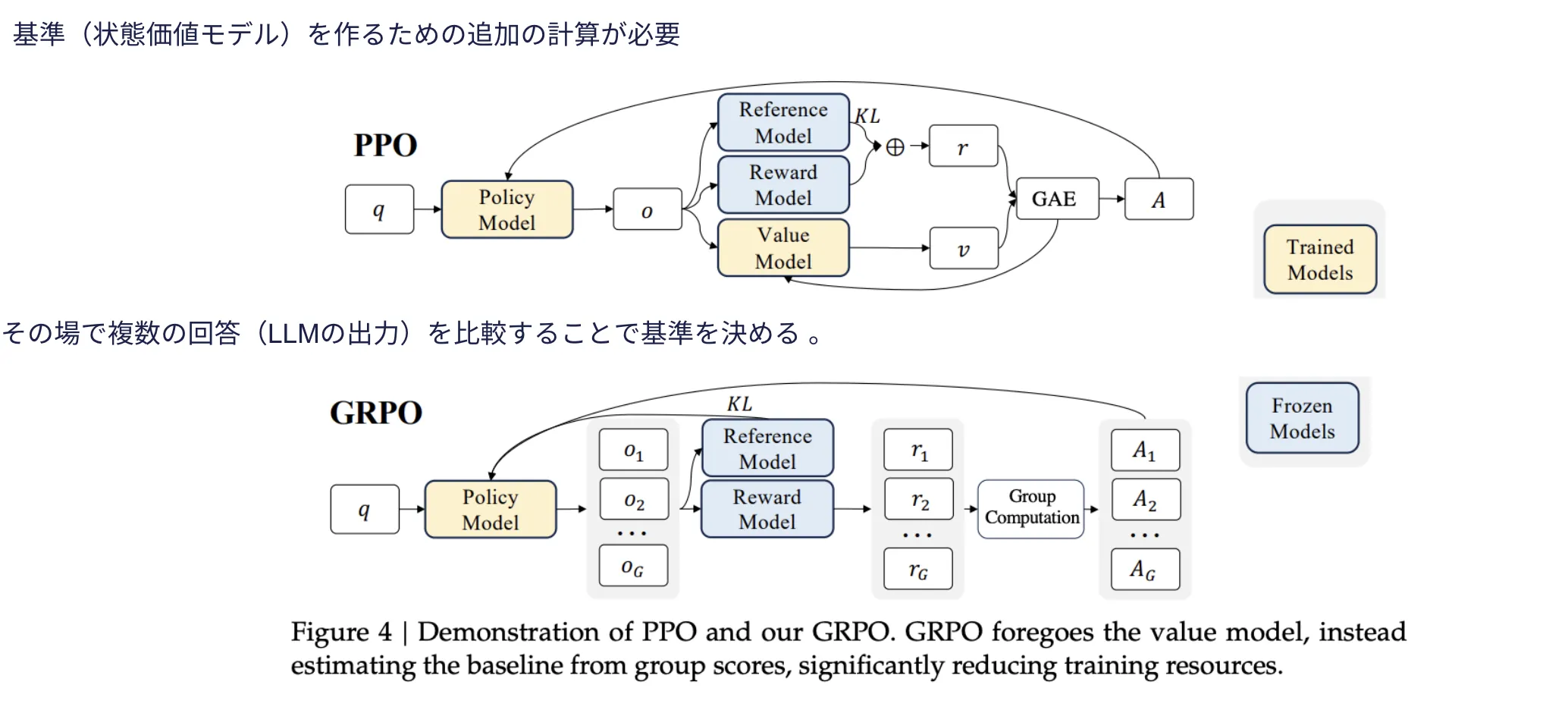
GRPO引用:DeepSeekMath
GRPOは、従来のPPO(Proximal Policy Optimization)を改良した手法で、計算リソースの削減を実現します。PPOでは、AIが報酬を最大化するための方策(Policy)を学習する際に「状態価値モデル」を利用しますが、GRPOでは事前の状態価値モデルを不要にし、その場で比較することで基準を決定します。
このアプローチにより、DeepSeekは従来のPPOよりもメモリ使用量を削減しながら、高い性能を維持できるようになっています。
③ 知識蒸留(Knowledge Distillation)

知識蒸留引用:sakana.ai
知識蒸留は、高性能なLLM(教師モデル)が自身の知識を小型のSLM(生徒モデル)へ転移させる技術であり、ゼロから新たなモデルを学習するよりも効率的にAIを訓練できます。
DeepSeekでは、既存の大規模モデル(DeepSeek-R1)からQwen2.5やLlama3といったオープンソースモデルに知識を転移し、微調整を加えることで、より効率的なAIモデルを構築しています。
【関連記事】
➡️知識蒸留とは?その手法を詳しく解説!
他の企業はDeepSeekを真似できるのか?
DeepSeekが活用するMoE、GRPO、知識蒸留などの技術は、基本的には公開されているため、他の企業も理論的には模倣可能です。
しかし、DeepSeekが短期間で高性能なAIモデルを開発できた背景には、単にこれらの技術を組み合わせるだけでなく、独自の工夫やノウハウが影響しています。
また、DeepSeekが公開しているtechnical reportには、モデル構造や学習の詳細は含まれておらず、MITライセンスのもとで一部の情報は開示されていますが、完全な再現は困難です。さらに、他の米中企業も同様のモデルを開発し、それ以上の性能を実現する可能性が示唆されており、今後の競争が激化することは間違いありません。

DeepSeekの安全性について
DeepSeekは、その画期的な性能によりAI業界で大きな注目を集めていますが、同時に、その安全性や情報漏洩リスクに対する懸念も急速に高まっています。
特に、中国企業であるという背景から、収集されたデータが中国政府に渡る可能性を危惧する声が強く、各国・地域の政府機関や主要企業が、職員や関係者による利用を制限する動きが相次いでいます。
懸念される主なリスク
DeepSeekに関して、国際社会で特に問題視されているのは、以下のリスクです。
-
中国政府への情報漏洩
DeepSeekが収集したデータが、中国の法律や政府の要請に基づき、当局に提供される可能性が最も大きな懸念材料となっています。
-
個人情報保護
DeepSeekのプライバシーポリシーには、ユーザーから広範な個人情報を収集し、中国国内のサーバーに保存すると記載されています。
収集対象には、アカウント作成時の情報(メールアドレス、電話番号、生年月日など)、ユーザーが入力したテキストや音声、チャット履歴、さらにはデバイス情報(機種、OS、IPアドレス、キー入力パターンなど)が含まれます。
これらの情報は、サービスの改善や提供、広告パートナーやグループ企業との共有など、多岐にわたる目的で利用され、「必要な限り」保管されるとされています。
-
安全保障
政府機関や重要インフラ企業などがDeepSeekを利用した場合、機密情報や国家の安全に関わる情報が漏洩するリスクが指摘され、各国が警戒を強める要因となっています。
各国・地域における具体的な対応
-
米国
宇宙航空局(NASA)や海軍といった主要機関が、職員や軍関係者に対し、DeepSeekの利用を控えるよう内部的に指示を出しています。
これは、個人情報の保護に関する懸念と、国家安全保障上のリスクを考慮した措置とされています。
-
イタリア
イタリア政府は、国内におけるDeepSeekのアプリの利用を制限する公式な決定を下しました。
当局は、DeepSeek社に対し、利用者に関する個人情報の収集目的や、その法的根拠などについて詳細な説明を求めていましたが、同社の回答は「不十分」であると判断しました。
-
台湾
台湾は、公的機関の職員に対し、DeepSeekの使用を禁止する措置を講じることを発表しました。
当局は、中国側への情報漏洩の可能性を強く懸念しており、DeepSeekの利用が「安全保障上の重大なリスク」につながりかねないと警告しています。
-
その他の国々
韓国、アイルランド、フランス、オーストラリアなど、多くの国々がDeepSeek社に対し、個人情報の取り扱いに関する詳細な情報を開示するよう求めるなど、警戒態勢を強めています。
AI利用におけるセキュリティ問題については、DeepSeekに限らず、一般的にAIモデルへの入力情報(指示や質問)は、サービス提供者側で利用可能な状態になるため、機密性の高い情報を扱う際には、常に注意が必要です。
日本のDeepSeek活用への対応は?
DeepSeekの急速な普及を受け、日本国内でもその安全性や情報管理体制に対する懸念が高まっており、政府機関や企業が相次いで対応を強化しています。
政府機関での対応
2025年2月、デジタル庁および内閣サイバーセキュリティセンター(NISC)は、各省庁に対してDeepSeekを含む生成AIの利用に関する注意喚起を発出しました。通知では以下の点が強調されています。
- DeepSeekが取得する情報が中国国内のサーバーに保存され、中国の法律が適用されること
- 機密情報の入力は避けるべきであること
- 利用には目的の明確化と、内部承認プロセスの設定が必要であること
また、個人情報保護委員会は、DeepSeekのプライバシーポリシーが中国語や英語のみで提供されていることに言及し、日本の利用者がその内容を十分に理解できない可能性を指摘しています。
地方自治体・企業の動き
一部の地方自治体では、すでに利用制限が始まっています。例えば鳥取県庁は、県庁内の端末からDeepSeekへのアクセスを禁止する措置を導入しました(参考:NHK)。
民間でも同様の対応が進んでおり、トヨタ自動車、三菱重工業、ソフトバンクなどの大手企業は、社内でのDeepSeekの使用を明確に禁止しています。これらの企業は、情報漏洩やセキュリティ上のリスクを考慮し、安全性を最優先に判断したと見られています。
ディープシークの企業活用、ローカル環境・クラウドの選択
DeepSeekを企業で活用する際には、ローカル環境での運用が有効な選択肢のひとつです。社内のGPUサーバー上で、Ollamaなどのツールを使ってモデルを直接実行することで、外部との通信を遮断し、データ送信リスクを最小限に抑えることができます。
アクセス制御や監査ログを併用すれば、セキュリティ統制や不正利用対策にも対応できます。ただし、モデル自体がジェイルブレイクに対して脆弱とされる点には留意が必要で、ローカルであっても入力制御や利用ポリシーの整備が求められます。業務の性質に応じて、他のLLMと使い分ける判断も視野に入れるとよいでしょう。
では、クラウド利用はどうでしょうか。
Microsoft Azure AI Foundryでの活用とその意味
各国で規制が進む一方で、Microsoftは、Azure AI FoundryのモデルカタログにDeepSeek R1を追加し、サーバーレスエンドポイントとして利用可能にしました。
Microsoftは、「DeepSeek R1が厳格なレッドチーミングと安全性評価を受けており、Azure AI Content Safetyによるコンテンツフィルタリングがデフォルトで利用可能である」 と説明しています。
この動きは、DeepSeekの技術力が高く評価されていることを示す一方で、安全性に関する懸念が完全に払拭されたわけではないことを示唆しています。
Azure上での利用は、Microsoftのセキュリティ基準と監視下で行われるため、一定の安全性は確保されると考えられますが、利用者自身もリスクを認識し、慎重に利用する必要があります。
低コストAIモデルの可能性を自社業務のAI化に結びつけるなら
DeepSeekが証明した低コスト・高性能AIの実現は、企業にとってAI導入のハードルが大きく下がったことを意味します。モデルのコスト構造を理解した上で、自社のどの業務プロセスからAI化を始めるかを具体的に検討するタイミングです。
AI総合研究所では、コスト効率を考慮した業務プロセスへのAI導入を段階的に進めるための実践ガイドを無料で提供しています。モデル選定とコスト設計を並行して進める具体的な方法を確認してみてください。
低コストAIモデルの可能性を自社の業務AI化に活かす

AI業務自動化ガイド
DeepSeekが示した低コスト・高性能AIの可能性は、企業のAI導入コスト障壁を下げています。コスト効率を意識しながら業務プロセスにAIを段階的に導入するための実践ステップをガイドにまとめました。
まとめ
DeepSeekは、中国発のAIスタートアップとして、高性能なAIを低コストで開発し、従来のAI開発の常識を覆しました。その成功は、MoE、GRPO、知識蒸留といった技術の活用によるものですが、単なる技術の模倣だけでは同等の性能を達成するのは難しいとされています。
今後、DeepSeekの技術がAIエージェントやフィジカルAIにどのように応用されるのか、また、他の企業がどのように対抗するのかが注目されています。
AI総合研究所は企業のAI活用をサポートしています。お気軽にご相談ください。











