この記事のポイント
 高品質な画像生成を目指すなら、GANよりもDiffusionモデルが安定性・多様性の両面で第一候補
高品質な画像生成を目指すなら、GANよりもDiffusionモデルが安定性・多様性の両面で第一候補- 条件付き生成(テキスト→画像)にはStable Diffusion系が最適で、企業のクリエイティブ業務効率化に直結する
- スコアベースモデルと拡散確率モデルは用途で使い分けるべきで、生成品質重視なら後者を選ぶのが有効
- 画像編集・修復・動画生成への応用を見据えるなら、UNet構造の理解とファインチューニング技術を押さえておくべき
- 初期導入はHugging Face Diffusersライブラリから始め、段階的にカスタムモデルへ移行するのが実務的なアプローチ

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
画像生成AIの最前線で注目される「Diffusionモデル」は、どのようなデータからもノイズを徐々に取り除いて特定の画像を生成する技術です。この記事では、その仕組みや種類、応用例までを分かりやすく解説していきます。専門用語を避けた平易な言葉で、Diffusionモデルがどのようにして美しい画像を作り出すのかを語ります。さらに、スコアベースモデルや拡散確率モデルなどの種類についても触れ、Diffusionモデルの持つ多様な可能性について考察します。技術の詳細部分ではマルコフ連鎖や確率論などの基礎知識から、UNetの構造に至るまでを易しく解説。また、実際に簡単な実装例を交えつつ、画像編集・修復や動画生成への応用例も紹介していきます。最先端のAI技術に興味がある方や、自社システムにDiffusionモデルを取り入れたい企業にとって、一読の価値のある内容となっております。
Diffusionモデルとは
拡散モデルは、「ノイズから元の画像を作り出す」AIの仕組みです。
たとえば、白い砂嵐のようなぐちゃぐちゃなノイズから、美しい絵や写真を作り出すことができます。
画像生成AIで使われる最新技術のひとつで、画像生成AIの基盤「白紙から絵や写真を生み出す」のが得意です。

Diffusionモデルの仕組み
拡散モデルは、「ノイズを追加する過程(順拡散)」と「ノイズを取り除く過程(逆拡散)」を通じて、データを生成しています!ではそれぞれどんな工程なのかみていきましょう!
順拡散過程
元のデータ(画像など)に少しずつノイズを加えていき、最終的に完全なノイズにするプロセスです。モデルの学習時に行われます。

ノイズを付加するコードはこちら
import cv2
import numpy as np
import matplotlib.pyplot as plt
# Google Colabに画像をアップロード
uploaded = files.upload()
# アップロードした画像の名前を指定(image.png)
img = cv2.imread('image.png') # 画像名を 'image.png' に合わせて変更
# 画像が正しく読み込めているか確認
if img is None:
print("画像が読み込めませんでした。ファイルパスを確認してください。")
else:
# 画像をRGBに変換(OpenCVはBGRで読み込むため)
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# ガウスノイズを生成する関数(強いノイズを加える)
def add_gaussian_noise(image, mean=0, var=50000): # varを大きくしてノイズを強くする
row, col, ch = image.shape
sigma = var**0.5
gauss = np.random.normal(mean, sigma, (row, col, ch))
noisy = np.clip(image + gauss, 0, 255) # ノイズを加えた後、範囲を[0, 255]に制限
return noisy.astype(np.uint8)
# 強いガウスノイズを加える
noisy_img = add_gaussian_noise(img_rgb)
# 元の画像とノイズを加えた画像を表示
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.title("Original Image")
plt.imshow(img_rgb)
plt.axis('off')
plt.subplot(1, 2, 2)
plt.title("Stronger Noisy Image")
plt.imshow(noisy_img)
plt.axis('off')
plt.show()
数式で表現
x_t t \beta_t t N
逆拡散過程
完全なノイズ状態から始めて、少しずつノイズを取り除きながら元のデータ(または新しいデータ)を復元するプロセスです。データ生成時に行われます。

数式で表現
\mu_\theta(x_t,t) \sum_\theta
Diffusionモデルの種類と特徴
各種Diffusionモデルには、それぞれ異なる特徴と利点があります:
スコアベースモデル
- 特徴:データの「スコア関数」(データがどれだけノイズっぽいかを表す指標)を学習するモデルです。
- 仕組み:データ空間内で、ノイズの勾配(変化の方向)を予測します。これにより、ノイズを除去して元のデータを復元します。
- 強み:高品質な画像を生成できる点で注目されています。
拡散確率モデル
- 特徴:順拡散(ノイズを加える)と逆拡散(ノイズを取り除く)を確率モデルで設計し、データを生成します。
- 仕組み:ノイズを少しずつ加えたり減らしたりする過程を学習し、確率的に元のデータを復元します。
- 強み:学習が安定しやすく、生成プロセスが明確に数式化されています。
条件付き拡散モデル
- 特徴:指定された条件(テキストやラベルなど)に基づいて、特定のデータを生成します。
- 仕組み:通常の拡散モデルに条件(たとえば「犬の画像を作りたい」など)を追加して、目的に沿った生成を行います。
- 強み:プロンプトに応じた画像生成が可能な点で、画像生成AI(Stable DiffusionやDALL-E)に広く使われています。
技術的な詳細
数学的な背景
マルコフ連鎖と変分推論を理論的基盤としています。順拡散過程では、各ステップでのノイズ追加を確率的な遷移として扱い、逆拡散過程では、この確率分布を学習することで画像を生成します。
確率分布
確率論とは?
- 確率論は、「物事がどのくらいの可能性で起こるか」を考える数学の分野です。
- 画像データも確率論で扱えます。例えば、「この画像のピクセルは明るい可能性が高い」「この部分は暗い可能性が高い」という具合に、ピクセル値がどのように分布しているかを確率として記述します。
基本的は以下のような「正規分布(ガウス分布)」で表されます。
\mu \sigma
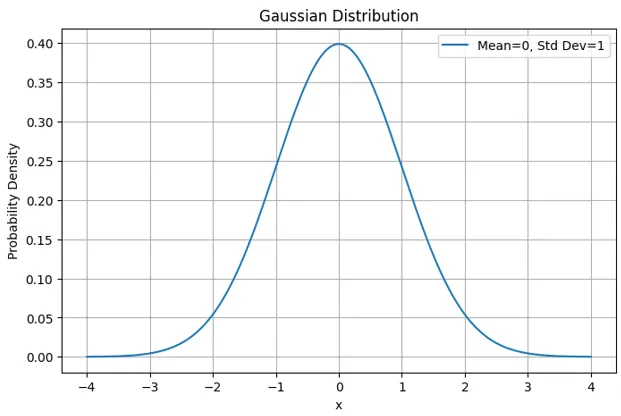
マルコフ連鎖
マルコフ連鎖とは?
- マルコフ連鎖は、「未来の状態は、今の状態だけに依存する」というルールを持った仕組みです。
- 過去の状態は関係なく、現在の情報だけを使って次のステップに進むため、計算が効率的です。
数式で現在の状況を
過去の状態(
UNetアーキテクチャ
UNetは、画像処理のタスク(例えば医療画像のセグメンテーション)で生まれたアーキテクチャですが、Diffusionモデルにおいては、画像生成やノイズ除去の主要な構成要素として利用されています。以下で、その構造と役割をわかりやすく説明します。
UNetの基本概念
UNetは以下の2つの主要部分から構成されます。
- エンコーダ(Encoder):入力画像から特徴を抽出する部分。
- デコーダ(Decoder):抽出した特徴を元に画像を再構築する部分。
UNetの構造図解
以下にUNetの構造を図解で説明します。
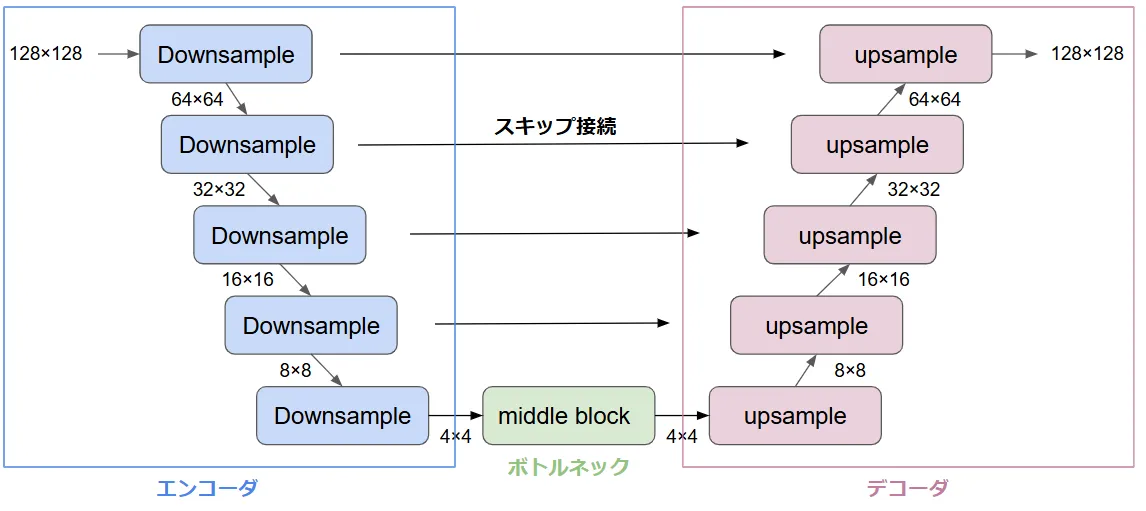
- 入力:ノイズが付加された画像(例:順拡散プロセスの一部)。
- エンコーダ:ノイズの特徴を抽出。
- ボトルネック:現在のノイズレベル(時間情報
t - デコーダ:抽出した特徴を元に、ノイズを除去した画像を復元。
- 出力:ノイズを減らした新しい画像。
学習プロセス
以下の手順で学習を行います:
- 訓練データから画像を取得
- 複数のノイズレベルを設定
- 各ノイズレベルでのノイズ予測を学習
- 損失関数を最小化して精度を向上
他のモデルとの比較
Diffusionモデルは、AIを使って画像やデータを生成する技術の一つで、他の生成モデルと比べて以下のような特徴があります。
VAE(変分オートエンコーダー)と比べて
Diffusionモデルは、よりリアルで高品質な画像を生成できます
VAEは速いですが、生成物がややぼんやりしていることがあります。一方で、Diffusionモデルは手間をかけて段階的に画像を仕上げるため、くっきりとしたリアルな結果が得られます。
GAN(生成的敵対ネットワーク)と比べて
Diffusionモデルは、学習が安定しており、モード崩壊(多様性が失われる問題)が起きにくいです。
GANは高品質な画像を生成できる一方、特定のパターンばかりを学習してしまい、他のパターンを見落とすことがあります。Diffusionモデルはこの問題を回避でき、多様性に富んだ結果を生み出します。
フローベースモデルと比べて
Diffusionモデルは、計算効率が良く、生成する画像の質が高いです。
フローベースモデルは正確な数式で処理を行うため、計算量が増えがちですが、Diffusionモデルはそのプロセスを簡略化しながらも高品質を維持しています。

実際に実装してみよう!
実装手順
今回は模擬コードを実装してみます。
以下がDiffusionモデル模擬コードです。
画像の準備
Google Colabでコードを実行すると画像をアップロードするプロンプトが表示されます。
今回は任意の猫の画像を選択してアップロードします。

画像処理
画像はグレースケールに変換され、サイズは64x64にリサイズされます。
正規化でピクセル値を [0, 1] の範囲に調整します・
ノイズ除去
ノイズを付加し、段階的に元画像に近づけるように処理します。
alpha の値を調整して、緩やかなノイズ除去を実現します。
最終画像の微調整
再構成後に、元画像との平均を取ることでノイズをさらに除去します。
実装コード
実際の実装コードは以下となります!
# ライブラリのインポート
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from google.colab import files
# 犬の画像をアップロード
uploaded = files.upload() # ファイル選択ダイアログが表示されます
# 画像を読み込み、グレースケールに変換
for file_name in uploaded.keys():
original_image = Image.open(file_name).convert("L") # グレースケール
original_image = original_image.resize((64, 64)) # サイズを統一
original_image = np.array(original_image) / 255.0 # 値を0~1に正規化
# ディフュージョンモデルの設定
timesteps = 100 # 時間ステップ数
noise_scale = 0.5 # ノイズのスケール
# ノイズを追加
noisy_image = original_image + noise_scale * np.random.randn(*original_image.shape)
noisy_image = np.clip(noisy_image, 0, 1) # 値を0~1にクリップ
# ディフュージョンプロセス
images = [noisy_image]
for t in range(1, timesteps + 1):
alpha = np.exp(-t / (timesteps / 8)) # 緩やかなノイズ削減
denoised_image = alpha * images[-1] + (1 - alpha) * original_image
denoised_image = np.clip(denoised_image, 0, 1)
images.append(denoised_image)
# 再構成画像の微調整
final_image = (images[-1] + original_image) / 2 # 最後に元画像との平均を取る
# 初期画像、ノイズ画像、最終再構成画像の表示
plt.figure(figsize=(18, 6))
# 元画像
plt.subplot(1, 3, 1)
plt.title("Original Image")
plt.imshow(original_image, cmap="gray")
plt.axis("off")
# ノイズ付加画像
plt.subplot(1, 3, 2)
plt.title("Noisy Image")
plt.imshow(images[0], cmap="gray")
plt.axis("off")
# 再構成された画像
plt.subplot(1, 3, 3)
plt.title("Reconstructed Image")
plt.imshow(final_image, cmap="gray")
plt.axis("off")
plt.show()
実装結果
実行すると以下のような結果が出てきます。

Diffusionモデルの基本概念である「順拡散過程」と「逆拡散過程」が現れているのがわかりますね。
Diffusionモデルの活用事例
画像生成AI
Diffusionモデルの応用事例
Diffusionモデルは、特に画像生成において強力なツールとして広く使われています。代表的な応用事例として、Stable Diffusion、Imagen、そしてMidjourneyがあります。それぞれの特徴を以下に比較し、説明します。
Stable Diffusion

引用元:Stable Diffusion
オープンソースでカスタマイズ性が高く、効率的な画像生成が可能です。自由に使用でき、クリエイターやデザイナーに適しています。
【関連記事】
Stable Diffusionの詳細はこちらで解説しています。
Imagen

引用元:Imagen
高精度でリアルな画像生成を得意としており、商業用の高品質な画像制作に向いています
【関連記事】
Imagenの解説はこちらをご参照ください。
Midjourney

引用元:Midjourney
アートスタイルに特化しており、ビジュアルに魅力的な画像を生成します。特にアートやゲームデザインなどで活用されています。
【関連記事】
Midjourneyはこちらからご参照ください。
詳細な比較
| 特徴 | Stable Diffusion | Imagen | Midjourney |
|---|---|---|---|
| 開発元 | Stability AI | Google Research | Midjourney Inc. |
| 画像生成品質 | 高品質だがややアート的 | 極めて高品質でリアル | アート的で創造的な画像 |
| 特徴的な利点 | オープンソース、軽量で効率的 | 高精度な生成、細かい制御可能 | 直感的なインターフェース、アート的 |
| 利用事例 | アート、デザイン、広告 | 商業用画像生成、コンテンツ制作 | アート、ファッション、ゲーム |
| アクセシビリティ | オープンソースで自由にカスタマイズ | クローズド、Google製品向け | Discordベースで簡単に利用 |
| カスタマイズ性 | 高い(ユーザーが独自にカスタマイズ可能) | わずかに低い(Googleのフレームワークに依存) | 高い(コミュニティでシェア可能) |
画像編集・修復
Diffusionモデルは、以下のような画像編集や修復のタスクに広く応用されています。それぞれの具体的なサイトやツールとともに、どのように使われているかを説明します。
画像の拡大(スーパーレゾリューション)
Diffusionモデルは、低解像度の画像を高解像度に変換するための超解像技術に利用されています。これにより、画像の詳細を補完して鮮明にすることが可能です。
例
Topaz Labsの「Gigapixel AI」は、AI技術を用いて画像の拡大を行い、ディテールを再構成します。これにより、低解像度の画像を鮮明にし、特に印刷用途やディスプレイでの拡大時に高品質な結果を得られます。
![]()
引用元:GigapixelAI
ノイズ除去(デノイジング)
Diffusionモデルは、画像から不要なノイズを除去するために使われることが多いです。この技術は、画像を徐々にきれいにする「デノイジング」タスクに特化しています。
例
**DeepAI**の「Image Denoising」ツールは、Diffusionモデルを用いて画像内のノイズを効果的に取り除きます。このツールは、写真やスキャン画像など、あらゆるノイズを除去する際に役立ちます。
引用元:DeepAI
欠損部分の補完(インペインティング)
画像の欠損部分を補完するタスク(インペインティング)にもDiffusionモデルが使用されます。これにより、欠けている部分を周囲の内容に合わせて自動的に埋めることができます。
例
**RunwayML**の「Inpainting」ツールは、Diffusionモデルを使って、画像内の欠けた部分を補完します。例えば、人が多くいる画像の人を消して、欠けた部分に自然に画像を完成させることができます。
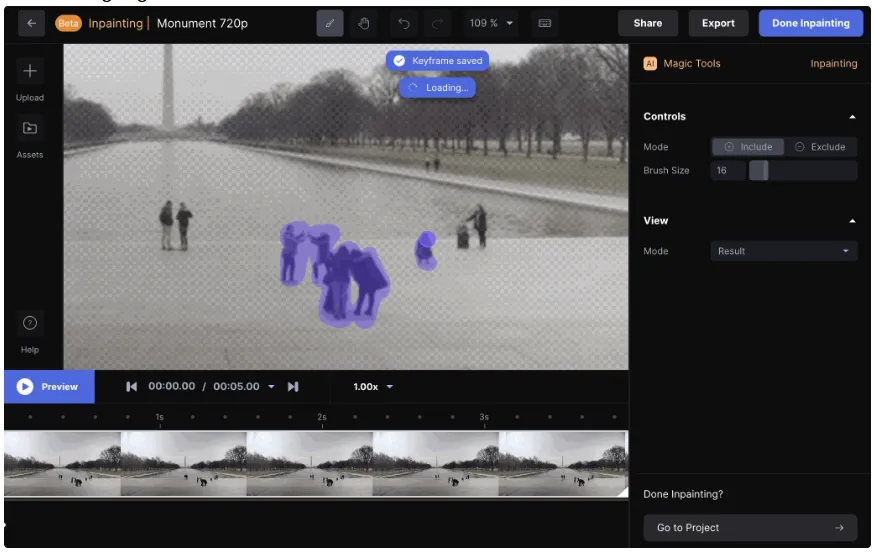
引用元:Runway
https://www.ai-souken.com/article/what-is-runway-gen3
スタイル変換
Diffusionモデルは、ある画像のスタイルを別の画像に転送するスタイル変換にも利用されます。これにより、画像の内容はそのままで、アート風のスタイルに変換することができます。
例
Prisma などのツールは、ユーザーがアップロードした画像にアートスタイルを適用するために、Diffusionモデルを用いたスタイル変換技術を利用しています。これにより、ユーザーは写真を有名な絵画スタイルに変換できます。
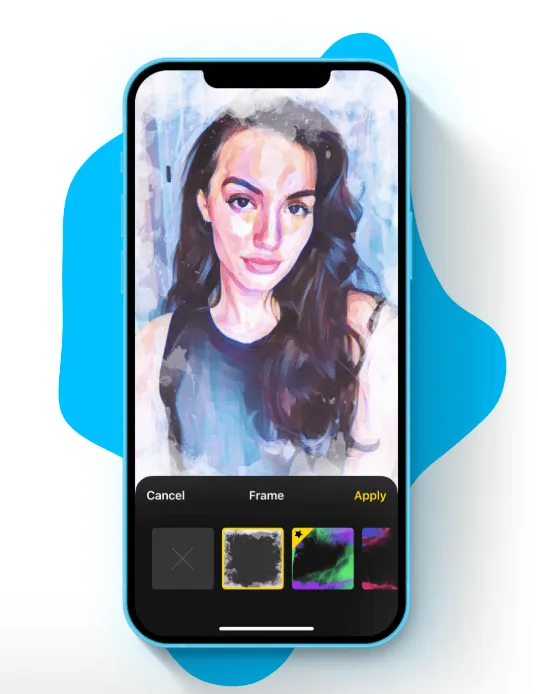
引用元:PrismaLabs
動画・3D生成
Diffusionモデルは、画像生成に加えて、動画生成や3D形状の生成、さらにはテキストから3Dモデルを生成するなど、非常に多様な応用が進んでいます。以下では、具体的な事例を挙げて、それぞれの技術の利用方法を説明します。
フレーム間の補間による動画生成
Diffusionモデルは、動画生成においてフレーム間補間技術を使い、滑らかなアニメーションを作り出すために使用されています。フレーム間に存在しない過渡的な動きを予測し、補完することで、動画がスムーズに見えるようにします。
例
D-ID の「Creative Reality Studio」や **RunwayML**の「Frame Interpolation」機能では、動画のフレーム間に必要な画像を生成するためにDiffusionモデルを使用しています。これにより、低フレームレートの動画が滑らかで高品質なものに変換されます。
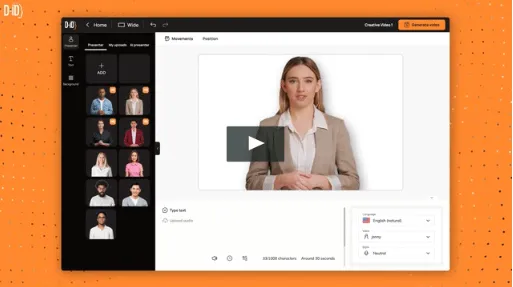
引用元:D-iD
3D形状の生成と編集
Diffusionモデルは、2Dの画像から3D形状を生成したり、既存の3Dモデルを編集するためにも使われます。この技術は、特にデジタルアートやゲームデザイン、映画のCG制作などで活用されています。
例
KAEDIM は、テキストや簡単なスケッチから3Dモデルを生成するプラットフォームで、Diffusion技術を利用しています。この技術を使うことで、ユーザーは短時間で3Dデザインを生成・編集でき、クリエイティブなプロセスを加速できます
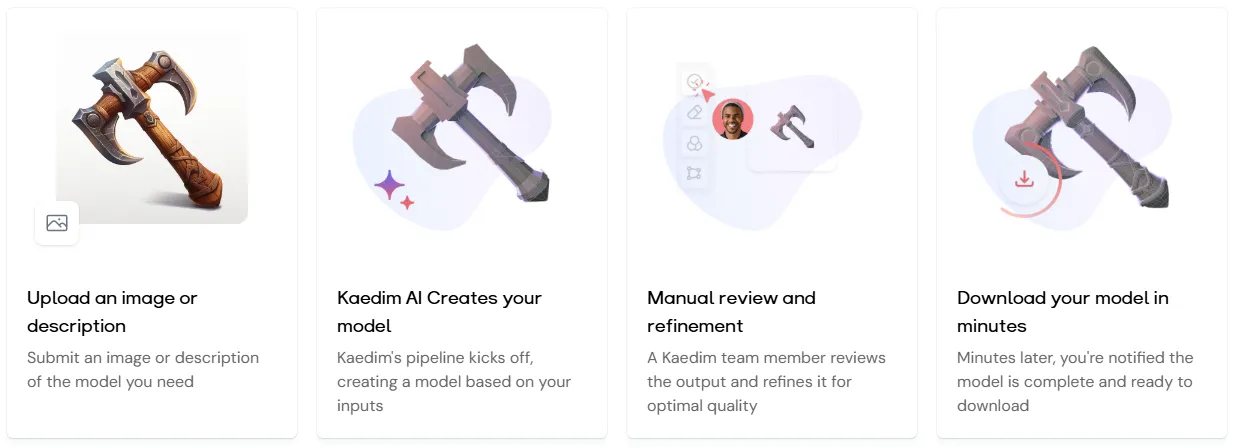
引用元:KAEDIM
テキストから3Dモデルの生成
最近、テキストから直接3Dモデルを生成する技術が進化しており、Diffusionモデルはその一環として利用されています。ユーザーが入力したテキストに基づいて、3Dオブジェクトが自動的に生成される技術です。
例
OpenAIの「DALL·E 3」やGoogle DeepMindが開発した「DreamFusion」は、テキストから3Dオブジェクトを生成するツールで、Diffusionモデルを用いています。これにより、ユーザーは詳細な指示を与えるだけで、リアルな3D形状を瞬時に作成できます。

引用元:OpenAI
https://www.ai-souken.com/article/exploring-dall-e-3

Diffusionモデルの理解からAI業務活用の全体像を描く
Diffusionモデルの仕組みを理解したことで、AIがデータを処理して価値を生み出す基本原理が見えてきたはずです。こうした技術への理解は、画像生成に限らず、組織がAIを業務に取り入れる際の重要な判断材料になります。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に進める実践ガイド(220ページ)を無料提供しています。経費精算や申請承認といった部門別ユースケースを、Before/After付きで具体的に解説しています。
AI総合研究所が、AI技術への理解を実際の業務改善に結びつけるプロセスを支援します。
拡散モデルの知識を組織AI活用に広げる

段階的なAI導入の実践ガイド(220p)
Diffusionモデルの仕組みと応用を理解した次は、AIを実際の業務プロセスに組み込む段階設計です。Copilot Chatから本格的な業務自動化基盤まで、段階的に設計する220ページの実践ガイドで導入ロードマップをご確認ください。
まとめ
Diffusionモデルは、ノイズから情報を取り戻し、美しい画像を再構築するというユニークなアプローチを持つ技術です。その背後には数学的な巧妙さと、機械が「混沌の中から秩序を見出す」という哲学的な美しさが潜んでいます。
私たちの生活でも、日々の喧騒の中から意味や価値を見出す瞬間があるように、このモデルもまた、無作為なノイズの中から元の姿を復元します。技術としての力強さだけでなく、私たちに「創造のプロセス」を改めて考えさせてくれる示唆に富んだ技術ではないでしょうか。
今後、Diffusionモデルは画像生成だけに留まらず、さまざまな分野で応用が広がる可能性を秘めています。その可能性を探る旅は、まさに私たち人類の創造力そのものを試す挑戦と言えるでしょう。
AI総合研究所は企業のAI導入をサポートしています。導入の構想段階から、AI開発はもちろんのことdiffusionモデルなどのシステム開発まで一気通貫で支援いたします。興味がある方はお気軽に弊社にご相談ください。
この記事を読んで、Diffusionモデルの奥深さに少しでも興味を持っていただけたなら幸いです。未来のイノベーションの中で、この技術がどのような役割を果たしていくのか、ぜひ皆さんも注目してみてください。










