この記事のポイント
 GPT-4Vは提供終了済み。マルチモーダル機能を使うならGPT-5またはGPT-4oへの移行が必須
GPT-4Vは提供終了済み。マルチモーダル機能を使うならGPT-5またはGPT-4oへの移行が必須- 画像認識・分析用途にはGPT-5のビジョン機能が第一候補。GPT-4V比で精度・速度ともに大幅に向上している
- 無料版でもマルチモーダル機能は利用可能だが、業務利用なら制限の少ないPlus以上のプランにすべき
- GPT-4V時代のAPI連携コードはGPT-5対応への書き換えが必要。放置すると動作停止リスクがある

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
GPT-4V(GPT-4 Vision)は、2025年8月のGPT-5発表により、最新モデルGPT-5に統合されました。現在は独立したモデルとしては提供されていません。
「GPT-4Vってまだ使えるの?」「画像認識機能はどうなったの?」そんな疑問をお持ちではないでしょうか。
2023年9月に発表されたGPT-4Vは、テキスト、画像、音声を統合的に処理できるマルチモーダルAIとして革新的でしたが、その機能は現在、より高度なGPT-5や後継モデルに引き継がれています。
本記事では、GPT-4Vの歴史的な役割と特徴、そして現在利用可能な後継モデル(GPT-5、GPT-4o)の使い方について詳しく解説します。マルチモーダルAIの進化を理解することで、最新のChatGPT機能を最大限に活用できるようになります。
ChatGPTの新料金プラン「ChatGPT Go」については、以下の記事をご覧ください。
ChatGPT Goとは?料金や機能、広告の仕様、Plus版との違いを解説
✅最新モデル「GPT-5.5」については、以下の記事をご覧ください。
GPT-5.5とは?使い方や料金、GPT-5.4との違いを解説
GPT-4Vの現状:GPT-5への統合

GPT-4Vとは(歴史的背景)

GPT-4Vのイメージ
2023年9月にOpenAIは新機能GPT-4V(GPT-4 Vision)を発表しました。
これは従来のGPT-4の機能に加え、画像解析機能と音声出力機能を統合したマルチモーダルAIです。
GPT-4Vは、テキストだけでなく画像や音声も理解し処理できる、マルチモーダルAIの先駆けとなりました。
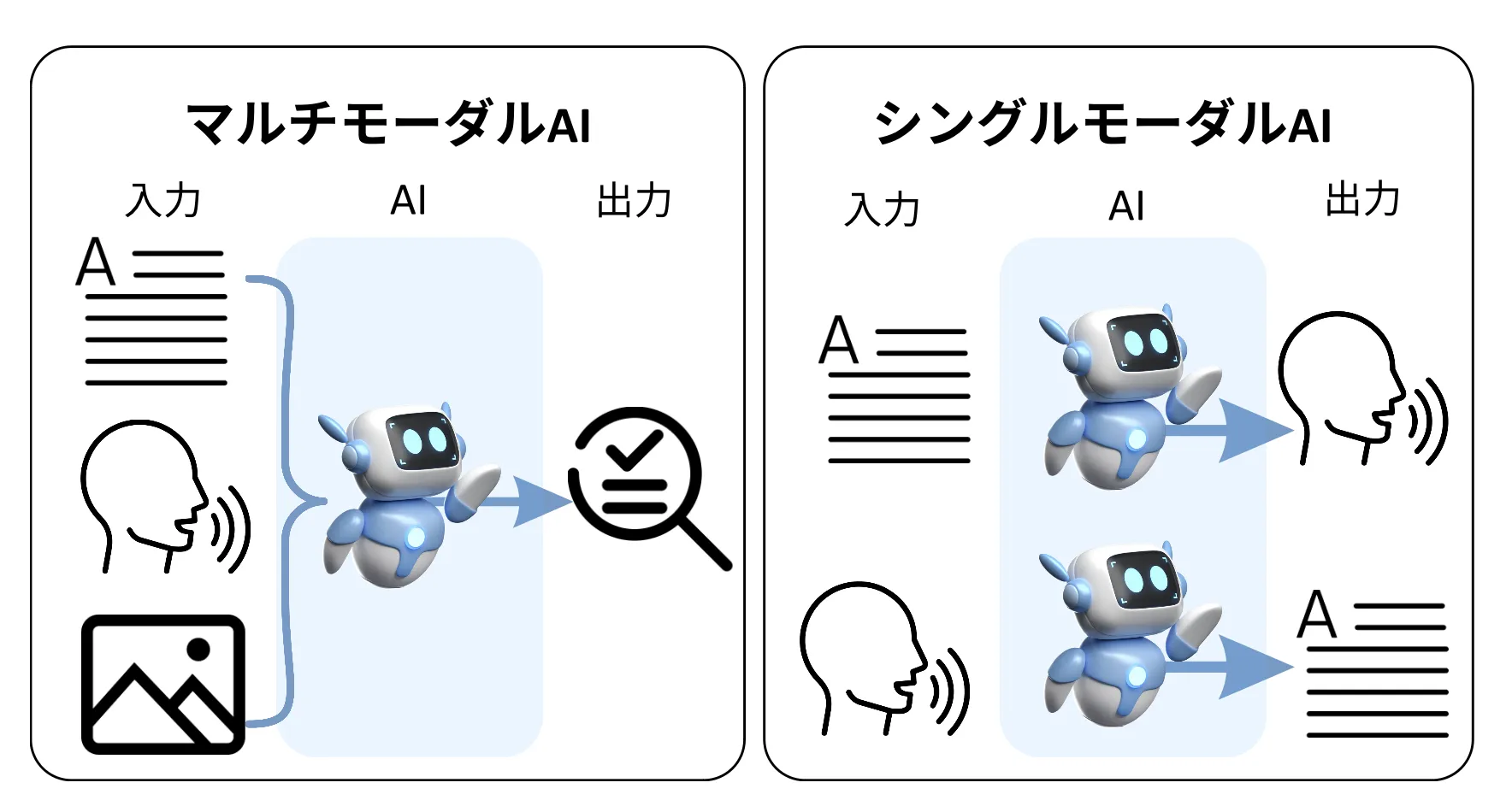
マルチモーダルの解説画像
GPT-4Vの歴史的意義:
- テキストのみだったGPT-4に、画像理解機能を追加した最初のモデル
- 音声入出力機能も統合し、真のマルチモーダルAIを実現
- その技術基盤が、現在のGPT-5やGPT-4oに引き継がれている
GPT-4Vでできたこと(現在はGPT-5/GPT-4oで利用可能)
GPT-4Vが先駆けとなった以下の機能は、現在GPT-5やGPT-4oで利用できます。
- 1.ChatGPTで画像入力ができる
- 2.ChatGPTで似ている画像の生成を行う
- 3.ChatGPTで音声入力ができる

マルチモーダル機能(現在はGPT-5/GPT-4oで提供)
1.ChatGPTで画像入力ができる

ChatGPTで画像入力ができる
画像入力機能を使うことで、アップロードした画像に関する質問をすることができます。例えば、画像内の物体を識別するよう依頼したり、画像のシーンを説明してもらったりすることが可能です。その画像を解析し、それに関連するテキスト情報を提供します。
例えば画像を入力してみます。

GPT画像説明
すると画像に写っている風景や状況を読み取り、それについて解説してくれます。
以下は、Xに投稿された活用事例です。
画像からソフトウェアを作成する
From now on I’m now going to be using AI to build software by simply drawing it. pic.twitter.com/qKovq5CJBA
— Mckay Wrigley (@mckaywrigley) September 27, 2023
画像から実際のコードを書く
ChatGPT、クラス図からクラス書いてくれる。
— きしだൠ(K1S) (@kis) September 27, 2023
ニャー、ワンワンまで書いてくれるのヤバすぎだろー pic.twitter.com/8YbObkQduG
複雑な政府資料を説明する
GPT-4V vs. 霞が関 pic.twitter.com/6im95nLZET
— めんだこ (@horromary) September 28, 2023
2.ChatGPTで似ている画像の生成を行う
類似画像の生成機能によって、様々なアイデア案を検討することや、画像の高画質化が可能になりました。
例えば、写真のイラスト化や類似画像の生成を頼むことが可能です。

類似画像生成例
以下では実際の活用例を紹介します。
ラフ画をロゴにする
The combination of Bing Chat vision with DALL•E 3 is amazing.
— Alvaro Cintas (@dr_cintas) October 2, 2023
Bing not only understood my image but also brought my logo sketch to life using DALL•E 3.
Here is how you can do it too in a couple of minutes: pic.twitter.com/tby9IcqEd8
デザインカンプの案を出す
DALL-E 3 can design website mockups in seconds.
— Matt Shumer (@mattshumer_) October 4, 2023
This will change everything for designers — infinite ideas and inspiration. pic.twitter.com/wDb2wuMCk4
【関連記事】
➡️【画像生成AI】DALL-E3とは?その魅力や使い方を徹底解説
3.ChatGPTで音声入力ができる
GPT-4Vの音声入力機能を使用する際のメリットは、手を使わずに操作ができる点、テキスト入力が苦手な人でも簡単に利用できる点です。
ChatGPTの音声入力機能
以下で実際の活用例を見ていきましょう。
英会話の先生として振る舞う
えぐい!
— チキン(小橋川 遥)@マーケター (@HeroofChickens) September 27, 2023
えぐい、えぐい!
ハンズフリーでChatGPTと会話できる
どうなってんだこれ、本当に今日まで生きてきた世界か?
未来に来たのか? pic.twitter.com/vulhoylWIy
キャラクターと会話する
https://x.com/hirochuu8/status/1735886647475204588?s=20
ハンズフリーでChatGPTと音声会話する
ついにやっちまった。
— 平岡 | 罰ゲーム化する管理職を変える生成AI活用術 (@hiraoka_dx) February 25, 2023
ChatGPTと音声で直接喋れる様になった。
これで、皿洗い中でもChatGPTに相談できる。。
勿論、誰でもできるように、一行もコード書かずに、全部無料でやる方法を模索しました。需要あれば後日解説出します。
以降、面倒な電話はこいつに対応してもらうか。。笑 pic.twitter.com/N5mG87bQFB
GPT-4Vが苦手なこと
一般的に画像内の情報が非常に混み入っていたり難解な場合、GPT-4Vで推論することは難しくなります。
以下で事例を紹介します。
クロスワードを解く

クロスワード/gpt4V
2つの画像を比較するタスク(間違い探し)はある程度可能ですが、完璧な精度ではないようです。
専門知識が必要なタスク
この実験ではGPT-4Vの識別能力を測るために専門家の放射線科医として、この画像の放射線診断レポートの生成タスクを課しました。
診断結果として肺結節のおよそ正しい見解を示している一方、位置やサイズについてはハルシネーションを起こしています。
Here, the model correctly identified a suspicious pulmonary nodule but incorrectly described its location and explicitly hallucinated its size. Additionally, it inferred a lack of pathologically enlarged lymph nodes, which is impossible to determine from just one slice. pic.twitter.com/avQCbTmLVS
— Christian Bluethgen (@cxbln) October 4, 2023
参考:The Dawn of LMMs: Preliminary Explorations with GPT-4V(vision)
その他OpenAIによる制限
OpenAIにより、下記のような質問には応答しないよう設定されています。
- 個人情報の特定(例:ユーザーが人物の画像をアップロードしてその人物が誰かを尋ねる場合、または一対の画像をアップロードして同じ人物かどうかを尋ねる場合)
- デリケートな話題(例:年齢、人種)
- 根拠のない結論を招きかねないもの

GPT-4Vの後継モデル料金体系
GPT-4Vの画像読み込みや音声入力・会話機能は、現在以下のプランで利用できます:
| プラン | 月額料金 | 利用可能モデル | 特徴 |
|---|---|---|---|
| 無料版 | $0 | GPT-4o(制限あり) | 基本的な画像・音声機能を利用可能 |
| Plusプラン | $20 | GPT-5、GPT-4o、o3など | 80メッセージ/3時間、高度な画像・動画生成機能 |
| Proプラン | $200 | 全モデル無制限 | 無制限のGPT-5 Thinking、128Kコンテキスト |
| Businessプラン | $25-30/ユーザー | GPT-5、GPT-5 Pro、o3など | チーム利用、高度なセキュリティ |
| Enterpriseプラン | 要問い合わせ | 全モデル無制限 | 大企業向け、最高レベルのセキュリティ |
API料金
GPT-5およびGPT-4oのAPIでも画像入力機能を利用できます。料金は以下の通りです:
- GPT-5 API:入力1Mトークンあたり5.00ドル、出力1Mトークンあたり15.00ドル
- GPT-4o API:入力1Mトークンあたり2.50ドル、出力1Mトークンあたり10.00ドル
トークンの計算方法やChatGPT APIの使い方について詳しく知りたい方は、以下の記事をご覧ください。
ChatGPT API(OpenAI API)とは?使い方や料金、活用事例を徹底解説 | AI総合研究所
2025年最新版!ChatGPT API(OpenAI API)の使い方を徹底解説。Responses API、GPT-5、画像・ファイル解析、Web検索、エージェント構築など最新機能と料金体系、活用事例を紹介。
https://www.ai-souken.com/article/how-to-get-chatgpt-api-key

GPT-4V機能の使い方(GPT-5/GPT-4oで利用)
GPT-4Vの機能を使うには、まずChatGPTにログインし、モデルのバージョン「GPT-5」もしくは「GPT-4o」を選択してください。
画像入力機能の使い方
1.画像をアップロードするボタン(📎マーク)をクリックし、画像を選択します。
2.画像を添付後、通常のChatGPTの使い方同様、画像に関する質問やタスクを入力します。
3.GPT-5/GPT-4oが画像を解析し、適切な回答を生成します。
GPT-5では、GPT-4Vと比較してより高度な視覚理解が可能になりました:
- 画像の内容を詳細に説明させる(改善された精度)
- 画像から位置情報を特定する
- 画像内のアイテムの用途を説明させる
- 手書きの文字や図を読み取らせる(改善された認識精度)
- チャートや図表を分析させる(複雑な図表にも対応)
- 複数画像の比較分析(GPT-5で強化)
音声機能の使い方
GPT-5/GPT-4oの音声入力・音声会話機能は、無料版・有料版のいずれでも利用可能ですが、ブラウザ版(PC版)とスマホアプリ版で利用方法が異なります。
スマホ版ではアプリ内のマイクボタンを押すことで簡単に使えますが、ブラウザ版ではデフォルトで搭載されていません。
そのため、ブラウザ版で音声会話機能を利用したい場合は、Google Chromeの拡張機能をインストールする必要があります。
詳しい使い方については、以下の記事をご覧ください。
ChatGPTの音声入力・音声会話機能とは?設定方法や使い方を解説 | AI総合研究所
ChatGPTの音声入力機能と設定方法を丁寧に解説。PC・スマホそれぞれでの使い方や、ビジネスや英会話練習など多様なシーンでの活用をご紹介します。
https://www.ai-souken.com/article/voice-input-in-chatgpt

GPT-4Vの機能を引き継いだGPT-5/GPT-4oは、画像と音声の入力に対応し、より高度な視覚理解と推論能力を持っています。ぜひ実際に試して、その進化した性能を体感してみてください。

GPT-4Vの画像理解能力から組織のAI活用の可能性を見出す
GPT-4Vのマルチモーダル機能を理解した今、次は視覚AIを含めたAI技術を組織の業務にどう取り入れるかを検討する段階です。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に進める実践ガイド(220ページ)を無料で提供しています。最新のAI技術を業務に適用する際のPoC→全社展開のプロセスと、部門別のBefore/After付きユースケースを収録しています。
AI総合研究所が、最新AIモデルの理解を組織の業務改善の可能性として見出すきっかけを提供します。
マルチモーダルAIの進化を業務に活かす

Microsoft環境でのAI業務自動化ガイド
GPT-5のビジョン機能で画像・テキスト統合が進んだ今、組織としてAIをどう業務に組み込むかの設計が重要です。段階的な導入プロセスを220ページで解説します。
まとめ
GPT-4Vは、ChatGPTをテキストのみの対話ツールから、視覚と聴覚を持つマルチモーダルAIへと進化させた画期的なモデルでした。
現在、GPT-4Vの機能は以下のモデルに引き継がれています:
- GPT-5(gpt-5-main):GPT-4Vの後継モデルとして、より高度な視覚理解と推論能力を提供
- GPT-4o:引き続き利用可能で、無料ユーザーでも画像・音声機能を利用可能
これらのモデルでは、GPT-4Vの以下の機能がさらに進化しています:
- 画像理解:より高精度な画像認識と詳細な説明生成
- 音声入出力:自然な音声会話とリアルタイム応答
- マルチモーダル統合:テキスト、画像、音声を統合した高度な推論
ChatGPT Plus(月額20ドル)やProプラン(月額200ドル)への加入により、これらの最新機能を最大限に活用することができます。教育・研究・データ分析・エンジニアリングなど、多岐にわたる分野での応用がさらに拡大しています。
GPT-4Vから始まったマルチモーダルAIの革新は、GPT-5とGPT-4oによって新たな段階へと進化し続けています。










