この記事のポイント
 機械学習の初手にはランダムフォレストを選ぶべき。前処理がほぼ不要で過学習に強く、分類・回帰の両方に対応できる
機械学習の初手にはランダムフォレストを選ぶべき。前処理がほぼ不要で過学習に強く、分類・回帰の両方に対応できる- 決定木の本数は100〜500本の範囲で設定し、精度が安定するまで段階的に増やすのが実務的なアプローチ
- 最高精度を狙うならXGBoostやLightGBMに切り替えるべきだが、解釈性や特徴量重要度の把握にはランダムフォレストが優位
- チューニングはまずn_estimatorsとmax_featuresの2つに集中し、グリッドサーチで効率的に最適化すべき
- 医療・金融・マーケティングなど幅広い分野で実用されており、scikit-learnなら数行で実装できる導入ハードルの低さが最大の強み

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
ランダムフォレストは、複数の決定木を組み合わせることで高い予測精度と汎化性能を実現するアンサンブル学習手法です。
過学習を抑えるバギングの仕組みと、特徴量のランダム選択による多様性の確保が最大の特長で、データの前処理が少なく実務での導入が容易な点から、多くのデータサイエンティストに支持されています。
本記事では、ランダムフォレストの基本的な仕組みから、scikit-learnを用いたPythonでの実装コード、ハイパーパラメータのチューニング手法、医療・金融・マーケティングでの活用事例、Extra Treesや勾配ブースティングとの比較、導入コストの目安までを体系的に解説します。
目次
ランダムフォレストとは
機械学習アルゴリズムの中でも高い汎用性と精度を誇るランダムフォレストは、ビジネスにおける予測モデルの構築から科学研究における分析まで、幅広い分野で活用されています。複数の決定木を組み合わせることで、単一の決定木よりも高精度な予測を実現する手法です。
ランダムフォレストは、2001年にLeo Breimanが提案したアンサンブル学習手法です。決定木は理解・可視化が容易である一方、単一の決定木では過学習や推定精度の限界が課題でした。Breimanは複数の決定木を組み合わせて精度と汎化性能を高める手法としてランダムフォレスト(Random Forest)を提案し、以来20年以上にわたりディープラーニングと並ぶ主要な機械学習アルゴリズムとして使われ続けています。

ランダムフォレストの手法と位置付け
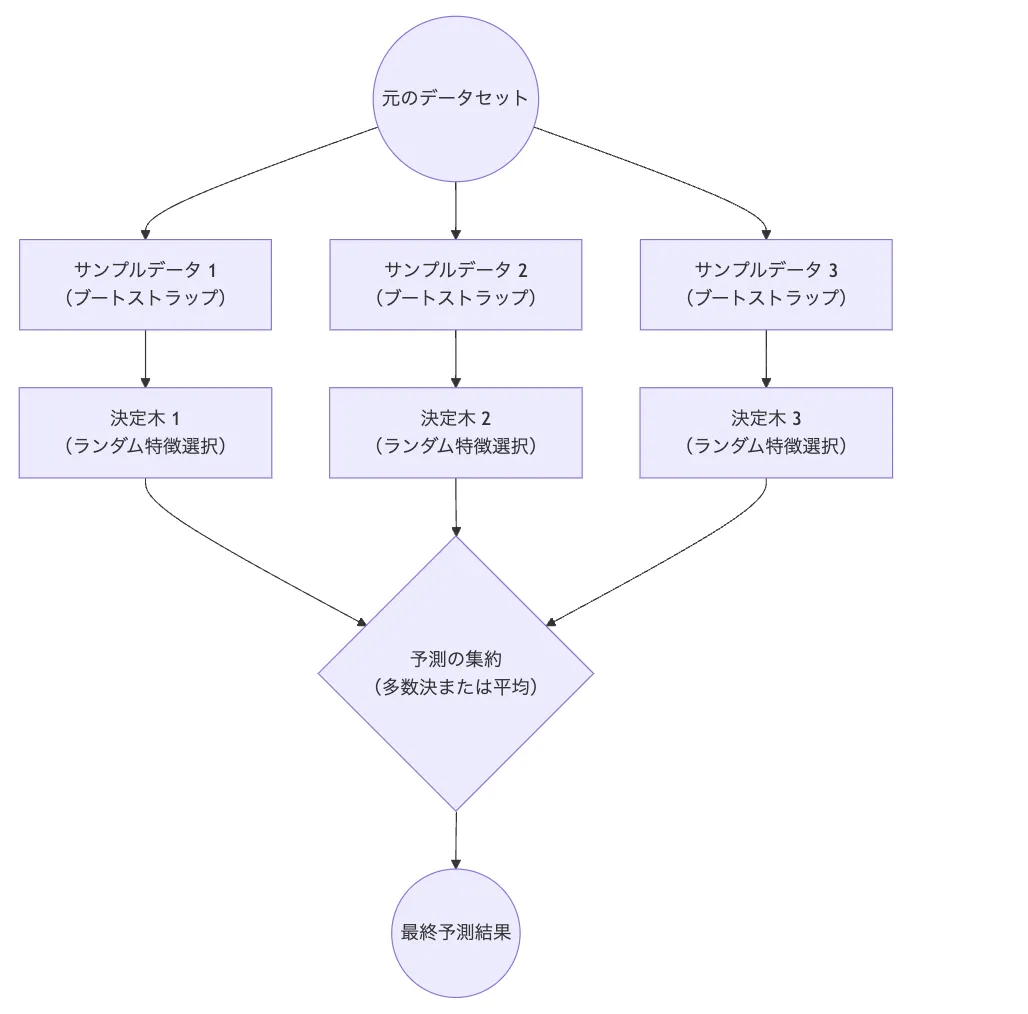
ランダムフォレストのイメージ
ランダムフォレストは、複数の決定木を組み合わせたアンサンブル学習手法のひとつです。決定木という直感的に理解しやすいアルゴリズムをベースとしながら、アンサンブル学習の力を活用することで、高い予測精度と汎用性を実現しています。
特に注目すべきは、単一の決定木が持つ過学習の傾向や、特定のデータへの過度な適合という弱点を、複数の木を組み合わせることで効果的に克服している点です。また、並列処理との相性が良く、大規模データの処理にも適しているため、ビッグデータ分析においても重要な役割を果たしています。
以下の表に、機械学習における位置づけを整理しました。
| 分類 | 特徴 | 主な用途 | 代表的な実装 |
|---|---|---|---|
| 教師あり学習 | 分類・回帰両対応 | 予測モデル構築 | scikit-learn |
| アンサンブル学習 | 複数モデルの統合 | 精度向上 | RandomForestClassifier |
| バギング手法 | ランダムサンプリング | 過学習抑制 | RandomForestRegressor |
ランダムフォレストは教師あり学習に分類され、分類問題と回帰問題の両方に対応できる汎用性の高いアルゴリズムです。
ランダムフォレストの仕組み
決定木をベースとしながら、「ランダム性」を導入することで予測精度を向上させるのがランダムフォレストの特徴です。個々の決定木の予測能力を活かしながら、集団としての安定性と精度を実現する設計となっています。
決定木とは
決定木は木の形状をしたモデルで、ノードと葉から構成されます。
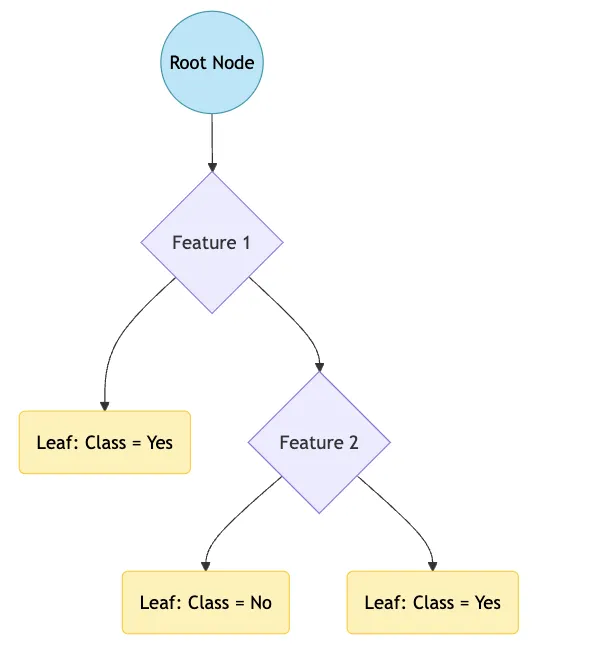
決定木イメージ
-
ノード(青色)
特徴量に基づいてデータを分割するポイントです。根ノード(最上部)から始まり、内部ノードを経て葉ノードに至ります
-
葉ノード(黄色)
最終的な予測結果を示すノードです。分類問題ではクラスラベル、回帰問題では数値を表します
アンサンブル学習とは
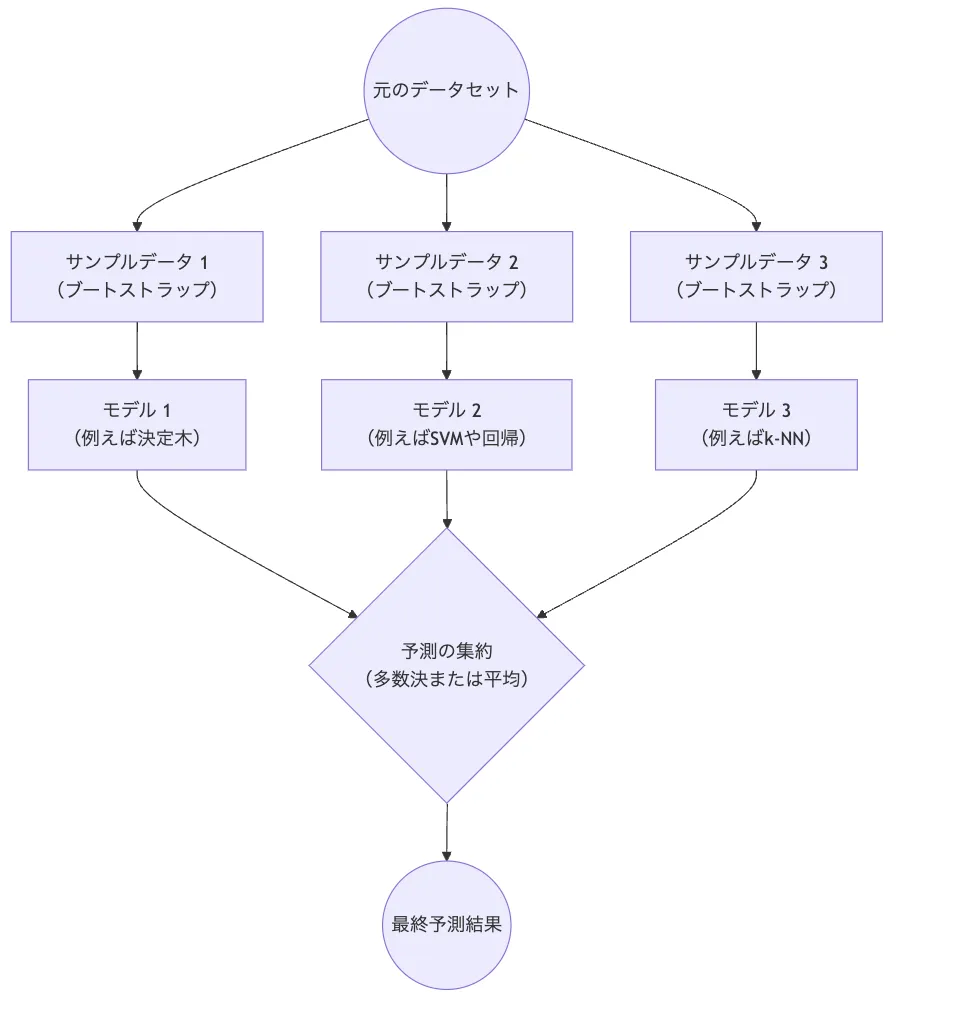
アンサンブル学習イメージ
アンサンブル学習は、複数の学習アルゴリズムやモデルを組み合わせてより高い予測精度を実現する手法です。複数の弱い学習器を組み合わせることで、全体として強い学習器を形成します。これにより個々のモデルの誤差を相殺し、精度を向上させることができます。
バギング(Bootstrap Aggregating)は、同じモデルを複数回訓練し、それらの予測を平均または多数決で集約する手法です。ランダムフォレストはこのバギングをベースに構築されています。
基本的な学習プロセスは以下の通りです。
-
データのランダム性(バギング)による多様性の確保
学習データからブートストラップサンプリングを行い、各決定木で異なるデータセットを使用します。サンプリングにより予測の分散が低減されます
-
特徴量のランダム性による過学習の抑制
分岐時に特徴量をランダムに選択することで、決定木間の相関を低減し、モデルの汎化性能を向上させます
ランダムフォレストの特徴
ランダムフォレストは、その設計思想と実装の工夫により、実務での活用において多くの利点を備えています。性能面と実務での活用しやすさの両面から特徴を整理しました。
| 分類 | 具体的な特徴 | 利点 |
|---|---|---|
| 予測精度の高さ | バギング(分散削減)、特徴量選択による過学習抑制、アンサンブル学習による安定化、外れ値に対する頑健性 | 安定した高精度な予測が可能。単一モデルよりも汎化性能が向上 |
| 汎用性 | 分類問題と回帰問題の両方に対応。大規模データや高次元データでも高い性能 | 多様な応用分野で使用可能。どのようなデータセットにも柔軟に対応 |
| 頑健性 | 外れ値やノイズに強い。欠損値があっても動作可能 | データ前処理の負担を軽減。実務データに特有の課題に対応しやすい |
| 前処理の簡便さ | データの正規化が不要。外れ値の処理が最小限。欠損値の許容 | 時間を節約でき、実務データの準備が容易 |
| チューニングの容易さ | 主なパラメータが少ない(木の本数n_estimators、特徴量数max_features)。過学習しにくい設計 | 少ない労力で最適化可能。グリッドサーチやランダムサーチで効率的に最適化できる |
| 解釈のしやすさ | 特徴量重要度の計算。部分依存プロット(PDP)で特徴量の影響を可視化。決定木構造の追跡が可能 | モデルの動作を説明しやすい。特徴量の影響を具体的に把握可能 |
性能面では、バギングやランダム特徴量選択によって過学習を抑え、安定した高精度の予測を実現します。実務面では、データの前処理がほとんど不要で、主要なパラメータが少なく、モデルの解釈性もあるため、非常に扱いやすいアルゴリズムです。
ランダムフォレストの数理的基盤
ランダムフォレストの各ステップを数式で表すと、以下のように整理できます。
| 分類 | 数式 | 特徴 |
|---|---|---|
| ブートストラップ | ( D_k \sim \text{Bootstrap Sampling from } D ) | データの多様性を確保 |
| 分割基準(Gini不純度) | ( G(t) = \sum_{k=1}^K p_k (1 - p_k) ) | 分割条件を最適化して、不純度が最小になる分割を選択 |
| ランダム特徴量選択 | ( m = \sqrt{M} ) | 過学習を防ぎ、各決定木の独立性を高める |
| アンサンブル学習 | 分類: ( \hat{y} = \text{argmax}k \sum{i=1}^T \mathbb{1}(h_i(x) = k) ) / 回帰: ( \hat{y} = \frac{1}{T} \sum_{i=1}^T h_i(x) ) | 複数モデルの結果を統合することで安定した予測を実現 |
Gini不純度が小さいほどデータの純度が高く、分類がうまくいっていることを意味します。ランダム特徴量選択では、分類問題では全特徴量の平方根、回帰問題では3分の1を選択するのが一般的です。
ランダムフォレストのアルゴリズム
ランダムフォレストのアルゴリズムは、「森」を作るように複数の決定木を組み合わせて構築されます。各決定木はそれぞれ異なるデータセットと特徴量で学習することで、多様性のある予測モデルを実現します。
決定木の構築
決定木の構築プロセスは、ランダムフォレストの性能を決定する重要な要素です。以下の表に、各フェーズの処理内容を整理しました。
| フェーズ | 処理内容 | パラメータ |
|---|---|---|
| データサンプリング | ブートストラップサンプリングによるデータ選択。元のデータセットと同じサイズのサンプルを重複を許容して抽出 | — |
| 分岐判断時 | 特徴量のランダム選択 | sqrt(n)個を選択 |
| 分割基準 | 不純度の計算 | ジニ係数/エントロピー |
| 停止条件 | 深さや不純度で判断 | max_depthなどで制御 |
各決定木はブートストラップサンプリングで異なるデータセットを使用し、分岐ごとにランダムに選ばれた特徴量の中から最適な分割を探索します。
複数の決定木の作成
個々の決定木の多様性を確保することが、ランダムフォレストの性能向上の鍵となります。
多様性は2つの仕組みで確保されています。データサンプリングの多様性では、元データの約63.2%が各決定木に選択され、残り36.8%はOOB(Out-Of-Bag)として内部的な評価に使用されます。特徴量選択の多様性では、分類問題の場合は全特徴量の平方根、回帰問題の場合は全特徴量の3分の1をランダムに選択します。
特徴量数 = floor(sqrt(全特徴量数)) # 分類の場合
特徴量数 = floor(全特徴量数 / 3) # 回帰の場合
決定木の本数は精度と計算コストのトレードオフで決定します。
| 木の数 | 効果 | 注意点 |
|---|---|---|
| 100未満 | 計算コスト低 | 精度が不安定 |
| 100〜500 | バランスが良好 | 一般的な選択 |
| 500以上 | 高精度 | 計算コスト大 |
一般的には100〜500本の範囲で設定し、精度が安定するまで段階的に増やすのが実務的なアプローチです。
予測結果の統合
複数の決定木からの予測結果を統合する方法は、タスクの種類によって異なります。
分類問題では多数決方式による決定を行い、各クラスの確率を平均して信頼度スコアを算出します。回帰問題では各決定木の予測値の平均を取り、予測値の分布から信頼区間を算出します。いずれの場合も、多数の木の予測を統合することで外れ値の影響を軽減できます。
ランダムフォレストのメリット・デメリット
機械学習アルゴリズムとしてのランダムフォレストは、優れた予測性能と実用性を備えていますが、同時にいくつかの制約も存在します。実務での活用においては、これらの特性を十分に理解したうえで適切な使用方法を選択することが重要です。
ランダムフォレストのメリット
高い予測精度
ランダムフォレストは、一般的に高い予測精度を誇ります。複数の決定木を組み合わせることで、個々の決定木の弱点を補い、全体としての精度を高めているためです。
ロジスティック回帰などの線形モデルはデータの線形な関係しか捉えることができませんが、ランダムフォレストは決定木を用いることでデータの非線形な関係も捉えられます。以下の表に、他のアルゴリズムとの比較をまとめました。
| アルゴリズム | 精度 | 計算コスト | 解釈性 |
|---|---|---|---|
| 決定木 | △ | ◎ | ◎ |
| ランダムフォレスト | ◎ | ○ | ○ |
| ロジスティック回帰 | ○ | ◎ | ◎ |
| ニューラルネットワーク | ◎ | △ | × |
ランダムフォレストは精度と解釈性のバランスが最も取れたアルゴリズムといえます。ニューラルネットワークは精度面では同等ですが、解釈性が低く計算コストも高くなります。
過学習を防ぐ効果
過学習とは、学習データに過度に適合しすぎてしまい、未知のデータに対する予測精度が低下する現象です。ランダムフォレストでは、各決定木が異なるデータと特徴量を用いて学習されるため、個々の決定木が過学習を起こしにくくなります。さらに、複数の決定木の予測結果を統合することで、過学習の影響をより軽減できます。
さまざまなデータに対応可能
ランダムフォレストは数値データだけでなく、カテゴリデータも扱うことができます。また、欠損値に対しても特別な処理を必要とせずに適用可能です。
| データ型 | 対応力 | 必要な前処理 |
|---|---|---|
| 数値データ | ◎ | スケーリング不要 |
| カテゴリデータ | ○ | エンコーディング |
| テキストデータ | ○ | ベクトル化 |
| 画像データ | △ | 特徴量抽出 |
画像データについては、CNN(畳み込みニューラルネットワーク)のほうが一般的に高い性能を発揮しますが、特徴量を手動で抽出したうえでランダムフォレストに渡すアプローチも有効です。
ランダムフォレストのデメリット
計算コストの高さ
ランダムフォレストは複数の決定木を構築するため、計算コストが高くなる傾向があります。以下の要因が計算コストに影響します。
-
データサイズ
サンプル数が多いほどブートストラップサンプリングで抽出するデータ量が増え、各木の訓練時間も長くなります。特徴量の次元数が多いデータセットでは、分岐に利用される組み合わせも膨大になるため探索時間が増加します
-
モデルパラメータ
決定木の数が多いほど予測精度は向上する可能性がありますが、計算負荷も増加します。木の深さが深いほど複雑なパターンを学習できますが、計算負荷が高くなり過学習のリスクも増します
-
リソース管理
並列処理を有効にすることで計算効率は向上しますが、メモリ消費量が増えます。大規模データを扱う場合はGPUやクラウド環境の活用も検討してください
解釈の難しさ
ランダムフォレストは複数の決定木を組み合わせるため、モデルの解釈が複雑になります。個々の決定木の構造を理解することは比較的容易ですが、全体としてのモデルの振る舞いを理解することは難しい場合があります。
-
ブラックボックス的な性質
各決定木がランダムにサンプリングされたデータや特徴量で学習されるため、全体としての振る舞いを一意に説明することが困難です。特にビジネスや医療のように予測根拠の説明が重要な場面では課題となります
-
個々の予測の判断根拠の説明困難
各木の予測結果を平均化(または多数決)するため、どの特徴量がどのように予測に影響したかを具体的に説明するのが難しくなります
-
複雑な特徴量間の相互作用
各決定木が異なるデータの部分集合で学習するため、特徴量間の相互作用が複雑になりがちです。SHAP値やLIMEといった説明性向上ツールの活用が推奨されます
データ分析チームが手作業でルールベースの予測を行い、担当者ごとに結果が変わって困っている——そんな状況であれば、ランダムフォレストの導入が有力な選択肢です。特徴量重要度によって予測の根拠も可視化できるため、属人的な判断からの脱却が可能になります。
ランダムフォレストの活用事例

ランダムフォレストは、その高い予測精度と実装の容易さから、さまざまな産業分野で実践的に活用されています。以下の表に、主要な活用分野をまとめました。
| 活用分野 | 具体的な用途 |
|---|---|
| 医療画像診断 | 病変検出、MRI画像分類 |
| 自然言語処理 | 文書分類、感情分析 |
| マーケティング | 顧客分析、離反予測 |
| 金融 | 不正検知、リスク評価 |
それぞれの分野での具体的な活用方法を見ていきます。
画像認識
医療分野からセキュリティまで、画像認識技術は現代社会のさまざまな場面で活用されています。ランダムフォレストは、ディープラーニングが普及する以前から画像認識タスクで使用されており、現在でも特定の用途では優れた選択肢です。
特に医療画像診断の領域では、X線画像やMRI画像から病変を検出する補助システムとして実装されています。医療現場では判断の根拠を示すことが重要であり、ランダムフォレストの特徴量重要度を活用することで診断の説明性を確保しています。また、製造業での品質管理においても、不良品の自動検出や製品の分類に活用され、生産性向上に貢献しています。
自然言語処理
テキストデータの爆発的な増加に伴い、自然言語処理の重要性は年々高まっています。カスタマーサポートの現場では、大量の問い合わせメールやチャットログを自動分類し、適切な部署への振り分けや優先度の判定に活用されています。ソーシャルメディアの投稿分析では、ブランドに対する感情分析やトレンドの検出にも使用されています。
特にテキストマイニングの分野では、文書分類や感情分析などの基本的なNLPタスクにおいて安定した性能を発揮します。Word2Vecなどの単語埋め込みと組み合わせることで、より深い言語理解と高精度な分析が可能になっています。
マーケティング
顧客行動の予測と理解は、現代のマーケティングにおいて極めて重要な要素です。ランダムフォレストは、豊富な顧客データを活用して精度の高い予測モデルを構築できます。
購買履歴、Webサイトでの行動データ、顧客属性情報など、複数のデータソースを組み合わせることで、離反リスクの高い顧客を早期に特定し、適切な施策を展開することが可能です。AIのビジネス活用の文脈では、レコメンデーションシステムで顧客の嗜好を学習し、パーソナライズされた商品提案を実現する用途でも活用が広がっています。
金融
金融分野では、リスク評価や不正検知など、高い精度と説明責任が求められる場面で活用されています。クレジットカードの不正利用検知では取引パターンの異常を検出し、リアルタイムでのリスク評価を可能にしています。融資審査においては、申込者の属性や過去の取引履歴からデフォルトリスクを予測し、審査の判断材料として活用されています。
金融分野での活用が進む背景には、ランダムフォレストの高い予測精度だけでなく、判断過程の説明可能性があります。金融規制上、モデルの判断基準を説明する必要がある場面で、特徴量重要度を用いて判断の妥当性を示すことができます。
リスク評価の主要領域は、信用リスク管理(返済能力評価・デフォルト予測・与信限度額の動的調整)と市場リスク分析(資産価格の変動予測・ポートフォリオのリスク評価)の2つです。いずれの領域でも、予測に影響を与えた要因を明確に示せる点が、規制当局への報告や顧客への説明において大きな利点となっています。
ランダムフォレストの実装(Python)
実務でのAI開発において、ランダムフォレストの実装にはPythonのscikit-learnライブラリが広く使用されています。scikit-learnは統一的なAPIと豊富なドキュメントを提供し、効率的なモデル開発を可能にします。
scikit-learnの基本実装
分類問題の基本的な実装方法を、ステップごとに解説します。
基本的なワークフローは、データの準備→データの分割→モデルの作成→モデルの学習→予測と評価の5ステップです。
from sklearn.datasets import load_iris # データの読み込み
from sklearn.model_selection import train_test_split # データの分割
from sklearn.ensemble import RandomForestClassifier # ランダムフォレストモデル
from sklearn.metrics import accuracy_score, classification_report # 評価用の指標
1. データの準備
data = load_iris() # Irisデータセット(例)を読み込み
X = data.data # 特徴量(花の情報)
y = data.target # ラベル(花の種類)
2. データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
3. モデルの作成と学習
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train, y_train)
4. 予測と評価
y_pred = clf.predict(X_test) # テストデータに対して予測
accuracy = accuracy_score(y_test, y_pred) # 予測精度の計算
print("Accuracy:", accuracy) # 精度の表示
print(classification_report(y_test, y_pred)) # 各クラスの詳細な評価結果
分類問題と回帰問題ではモデルのクラスが異なります。分類ではRandomForestClassifier、回帰ではRandomForestRegressorを使用します。
# 分類問題の例
clf = RandomForestClassifier(
n_estimators=100,
max_depth=None,
min_samples_split=2,
random_state=42
)
# 回帰問題の例
from sklearn.ensemble import RandomForestRegressor
reg = RandomForestRegressor(
n_estimators=100,
max_depth=None,
min_samples_split=2,
random_state=42
)
以下の表に、主要なパラメータの説明と推奨設定範囲をまとめました。
| パラメータ名 | 説明 | 推奨設定範囲 |
|---|---|---|
| n_estimators | 決定木の数。多いほど精度が向上するが、計算時間も増加する | 100〜1000 |
| max_depth | 各決定木の最大の深さ。深くするほど複雑になるが、過学習のリスクも高まる | 3〜20 |
| min_samples_split | ノードを分割する際に必要な最小サンプル数。大きな値にするとシンプルなモデルになる | 2〜20 |
| min_samples_leaf | リーフノードに必要な最小サンプル数。大きな値にすると過学習を抑えられる | 1〜10 |
| max_features | 各分割で考慮する特徴量の数。ランダム性を増やし汎化性能を向上させる | auto, sqrt, log2 |
| bootstrap | ブートストラップサンプリングの使用有無。通常はTrueに設定する | True, False |
| random_state | 再現性を保つための乱数シード | 任意の整数 |
TensorFlowやPyTorchのようなディープラーニングフレームワークと比べ、scikit-learnでのランダムフォレスト実装はコード量が少なく、パラメータも直感的です。
モデルの学習と評価
モデルの学習から評価まで、適切な評価指標の選択とクロスバリデーションによる性能評価が重要です。
分類問題の評価指標として、以下の4つが代表的です。
| 指標 | 説明 | 適用例 |
|---|---|---|
| 正解率(Accuracy) | 全体のサンプルの中で正しく分類された割合。クラスが均等でない場合は不適切な評価になることがある | 全体の正確さ確認 |
| 適合率(Precision) | 正と予測されたサンプルのうち、実際に正である割合 | スパム検出 |
| 再現率(Recall) | 実際に正であるサンプルのうち、正と予測された割合 | 疾患検出 |
| F1スコア | 適合率と再現率の調和平均 | 全体的なバランス確認 |
回帰問題では、平均二乗誤差(MSE)、平均絶対誤差(MAE)、決定係数(R²)が主に使用されます。R²が1に近いほどモデルの説明力が高いことを意味します。
ハイパーパラメータのチューニング
モデルの性能を最適化するために、以下の3つのアプローチが使われます。
- グリッドサーチ(網羅的探索)
指定したハイパーパラメータのすべての組み合わせを試行し、最も良い結果をもたらす組み合わせを見つける手法です。各組み合わせに対して交差検証を行い、モデルの性能を評価します
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# データの準備
data = load_iris()
X = data.data
y = data.target
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルのインスタンス化
model = RandomForestClassifier(random_state=42)
# ハイパーパラメータの範囲を指定
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10]
}
# グリッドサーチの設定
grid_search = GridSearchCV(
estimator=model,
param_grid=param_grid,
cv=5, # 5分割の交差検証
scoring='accuracy', # モデルの性能評価指標
n_jobs=-1 # 全てのCPUコアを使用
)
# グリッドサーチの実行
grid_search.fit(X_train, y_train)
# 最良のパラメータとスコアの表示
print("Best Parameters:", grid_search.best_params_)
print("Best Cross-validated Accuracy:", grid_search.best_score_)
- ランダムサーチ(確率的探索)
指定した範囲内からランダムにハイパーパラメータを選択し性能を評価する手法です。すべての組み合わせを試すわけではないため、計算コストが低く短時間で良好な結果を得られることがあります
from sklearn.model_selection import RandomizedSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
# データの準備
data = load_iris()
X = data.data
y = data.target
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルのインスタンス化
model = RandomForestClassifier(random_state=42)
# ハイパーパラメータの範囲を指定
param_distributions = {
'n_estimators': np.arange(100, 400, 100), # 100から300までの範囲を指定
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10]
}
# ランダムサーチの設定
random_search = RandomizedSearchCV(
estimator=model,
param_distributions=param_distributions,
n_iter=10, # 試行する組み合わせの数
cv=5, # 5分割の交差検証
scoring='accuracy', # モデルの性能評価指標
n_jobs=-1, # 全てのCPUコアを使用
random_state=42
)
# ランダムサーチの実行
random_search.fit(X_train, y_train)
# 最良のパラメータとスコアの表示
print("Best Parameters:", random_search.best_params_)
print("Best Cross-validated Accuracy:", random_search.best_score_)
- ベイズ最適化
過去の評価結果を基に次に試すべきハイパーパラメータの組み合わせを決定する手法です。少ない試行で高い性能を得られる可能性が高く、scikit-optimizeなどのライブラリで実装できます
最適化手法の選択に迷った場合は、以下の比較を参考にしてください。
| 観点 | グリッドサーチ | ランダムサーチ | ベイズ最適化 |
|---|---|---|---|
| 計算コスト | 高い(全組み合わせ) | 中程度(ランダム選択) | 低い(効率的探索) |
| パラメータ空間が狭い場合 | 最適 | 過剰 | 過剰 |
| パラメータ空間が広い場合 | 現実的でない | 有効 | 最も効率的 |
まずはscikit-learnのIrisデータセットで基本的な分類モデルを構築し、精度を確認するところから始めてみてください。コード例はそのまま実行可能で、モデルの挙動を体感できます。
モデルの保存と読み込み
scikit-learnで作成したモデルを永続化することで、再学習の手間を省きデプロイが容易になります。Pythonではjoblibライブラリが大規模データの保存に最適化されており、モデルの永続化に推奨されます。
import joblib
# モデルの保存
joblib.dump(model, 'random_forest_model.joblib')
# モデルの読み込み
loaded_model = joblib.load('random_forest_model.joblib')
運用環境では以下の点に注意が必要です。
-
バージョン互換性の確認
モデルの保存に使われたscikit-learnやPythonのバージョンと、読み込む際のバージョンが異なると互換性の問題が発生します。モデルを保存したバージョンの記録や、同じ環境でのデプロイが推奨されます
-
メモリ使用量の管理
モデルのサイズが大きくなると、読み込みや推論時にメモリを大量に消費します。必要に応じてモデルの軽量化や、メモリ消費の少ないアルゴリズムの選択を検討してください
-
推論速度の最適化
実運用では推論のスピードがシステム全体のパフォーマンスに影響します。モデルの圧縮や量子化、より高速なデータ処理ライブラリの使用を検討するとよいでしょう
-
モデルの定期的な再学習
実データが変化する可能性がある場合、一定期間ごとに再学習が必要です。再学習のスケジュールを設定し、定期的に性能評価を行うことでモデルの劣化を防ぎます

ランダムフォレストの特徴量重要度
ランダムフォレストの大きな利点のひとつは、モデルの判断に対する各特徴量の貢献度を定量的に評価できることです。特徴量重要度の分析は、モデルの解釈性を高め、ビジネス上の意思決定に役立つ洞察を提供します。
特徴量重要度の計算方法
特徴量重要度は、各特徴量がモデルの予測にどの程度影響を与えているかを数値化したものです。ランダムフォレストでは、各決定木の分岐で不純度の減少量に基づいて計算され、予測精度に寄与する度合いを評価します。
計算は3つのステップで行われます。まず、各決定木の分岐で特徴量が関与する際の不純度(ジニ不純度やエントロピー)の減少量を計算します。次に、すべての分岐点における不純度減少量を特徴量ごとに合計します。最後に、全決定木での平均を算出してモデル全体の重要度を確定します。
以下の表に、重要度を解釈する際の注意点をまとめました。
| 観点 | 説明 | 注意点 |
|---|---|---|
| 相対的な値 | 全特徴量の合計が1 | 絶対値での比較は不適切 |
| 非負値 | 0以上の値のみ | 負の影響は表現できない |
| 木の深さ依存 | 上位の分岐ほど影響大 | バイアスに注意 |
特徴量重要度はモデルの解釈に有用ですが、特徴量間の相関が高い場合は重要度が分散する傾向があります。Permutation Importance(順列重要度)を併用することで、より信頼性の高い評価が可能です。
ランダムフォレストの応用
ランダムフォレストの基本的な実装を発展させ、より高度な応用や他のアルゴリズムとの組み合わせにより、さらなる性能向上が可能です。
Extra Trees
Extra Trees(Extremely Randomized Trees)は、ランダムフォレストと似たアンサンブル学習アルゴリズムで、分岐の閾値も完全にランダムに設定する点が特徴です。ランダムフォレストでは各決定木が最適な分岐基準を探すのに対し、Extra Treesでは閾値の計算が不要なため学習時間が短縮されます。
以下の表に、ランダムフォレストとの比較をまとめました。
| 観点 | Random Forest | Extra Trees |
|---|---|---|
| 学習速度 | 標準 | より高速 |
| メモリ使用量 | 標準 | より効率的 |
| 予測精度 | 標準 | 同等/やや低下 |
| ノイズへの耐性 | 良好 | より強い |
Extra Treesは、データサイズが大きい場合やノイズの多いデータで特に有効です。特徴量の重要度分析では、ランダム性が強化されているため特徴量間の相関の影響が軽減され、より安定した結果が得られます。
from sklearn.ensemble import ExtraTreesClassifier
# Extra Treesの実装例
et_model = ExtraTreesClassifier(
n_estimators=100,
max_depth=None,
random_state=42
)
ランダムフォレストと勾配ブースティング
両手法を組み合わせることで、それぞれの長所を活かした高性能なモデルを構築できます。
ランダムフォレストは並列学習が可能で過学習しにくくパラメータ調整が容易です。一方、勾配ブースティングは誤差を修正しながら新しい木を追加していく逐次学習方式で、より高い予測精度を目指すことが可能です。
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import VotingClassifier
# アンサンブルモデルの構築
estimators = [
('rf', RandomForestClassifier()),
('gb', GradientBoostingClassifier())
]
ensemble = VotingClassifier(
estimators=estimators,
voting='soft'
)
運用時は、以下の点を考慮する必要があります。
| 項目 | 内容 | 対応策 |
|---|---|---|
| 計算コスト | 処理時間の増加 | 並列処理の活用 |
| メモリ使用量 | リソース消費の増加 | モデルの軽量化 |
| チューニング | パラメータ探索の複雑化 | 段階的な最適化 |
生成AIや強化学習が注目される現在でも、ランダムフォレストと勾配ブースティングの組み合わせは構造化データに対する予測タスクで依然として高い競争力を持っています。
ランダムフォレストの計算コストと導入のポイント
ランダムフォレストはオープンソースで無料利用可能なアルゴリズムですが、本番環境での運用には計算リソースやクラウド環境のコストが発生します。ここでは導入コストの目安を整理します。
計算リソースの目安
ランダムフォレストの計算コストは、データサイズ・木の本数・特徴量の数によって大きく変わります。
| データ規模 | 木の本数 | 学習時間の目安 | 推奨環境 |
|---|---|---|---|
| 小規模(〜10万行) | 100〜200本 | 数秒〜数分 | ローカルPC(CPU) |
| 中規模(10万〜100万行) | 200〜500本 | 数分〜数十分 | マルチコアサーバー |
| 大規模(100万行以上) | 500本以上 | 数時間以上 | クラウドMLプラットフォーム |
ディープラーニングのようにGPUが必須ではなく、CPUのマルチコア並列処理で効率的に学習できる点が、ランダムフォレストのコスト面での大きな利点です。
導入コストの目安
企業がランダムフォレストを業務に導入する場合のコスト目安を、フェーズ別に整理しました。
| フェーズ | コスト目安 | 主な内訳 |
|---|---|---|
| PoC(概念実証) | 数十万〜200万円 | データ整備、モデル構築、精度検証 |
| 部門導入 | 200万〜1,000万円 | API化、システム連携、運用体制構築 |
| 全社展開 | 1,000万円〜 | インフラ整備、モニタリング、再学習パイプライン |
ランダムフォレストはディープラーニングと比べてモデルの構築・チューニングが容易なため、PoC段階のコストを大幅に抑えられます。まずは既存のデータで小規模な検証を行い、精度と業務効果を実測したうえで段階的に拡大するアプローチが推奨されます。

ランダムフォレストの実装知識を組織のAI業務活用に活かす
ランダムフォレストの仕組みと実装方法を学んだことで、AIによるデータ分析が業務でどう役立つかの具体像が見えてきたはずです。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に進める実践ガイド(220ページ)を無料で提供しています。データ分析から業務改善への展開方法を部門別のBefore/After付きユースケースで具体化しています。
AI総合研究所が、機械学習の実装知識を組織の業務自動化に活かすための道筋を提供します。
ランダムフォレストを業務活用へ

段階的なAI導入の実践ガイド(220p)
Microsoft環境で始める段階的なAI業務自動化の実践ガイド。Copilot Chat→M365 Copilot→Copilot Studioの導入ロードマップと部門別ユースケースを収録。
まとめ
本記事では、ランダムフォレストの基本的な仕組みから、Pythonでの実装方法、ハイパーパラメータのチューニング、活用事例、応用手法、導入コストまでを体系的に解説しました。
ランダムフォレストは、バギングとランダム特徴量選択により高い予測精度と過学習抑制を両立し、データの前処理が少なく実装も容易なアルゴリズムです。医療、マーケティング、金融など多岐にわたる分野で活用されており、特徴量重要度によるモデルの解釈性も確保されています。
構造化データに対する予測タスクでは、ディープラーニングと比べて導入コストが低くチューニングも容易なため、最初に検討すべきアルゴリズムのひとつです。まずはscikit-learnのサンプルデータセットでモデルを構築し、予測精度と特徴量重要度を確認するところから始めてみてください。










