この記事のポイント
 この記事では、「CyberSecEval 2」という新しいサイバーセキュリティ評価フレームワークが紹介されています。
この記事では、「CyberSecEval 2」という新しいサイバーセキュリティ評価フレームワークが紹介されています。- CyberSecEval 2は、大規模言語モデルが生成するコードのセキュリティやユーザーによる悪意のある攻撃に対する応答を評価するためのものです。
- フレームワークはオープンソースで提供され、全ての開発者や研究者がセキュリティ向上に貢献できるよう促しています。
- 最新の評価では、LLMがサイバー攻撃への協力を減らす傾向はあるものの、プロンプトインジェクション攻撃への脆弱性が残っていることが明らかになっています。

監修者プロフィール
坂本 将磨
Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
大規模言語モデル(LLM)の安全性は今や情報セキュリティの重要な分野です。
この記事では、そんなLLMのセキュリティリスクを包括的に評価する新しいフレームワーク「CyberSecEval 2」についてご紹介します。
このフレームワークは、LLMが生成するコードのセキュリティや、潜在的なサイバーセキュリティ問題に対するLLMの反応を検証するために設計されています。
さらに、開発者や研究者がセキュリティの向上に貢献できるようオープンソースで提供されており、コミュニティの活動を促進しています。
今後のAI技術の発展に欠かせないセキュリティ評価の手法について、その具体的な内容と目指す方向性を解説するとともに、最近の評価結果とその意味するところにも焦点を当てます。
A-Comprehensive-Evaluation-Framework-for-Cybersecurity-Risks-and-Capabilities-of-Large-Language-Models

CyberSecEval 2: LLMのセキュリティを徹底検証
2024年5月24日、CyberSecEval 2という大規模言語モデル(LLM)のセキュリティに特化した評価フレームワークが公開されました。
このフレームワークは、不安全なコーディングやセキュリティ上の問題に対するLLMの反応をテストするためのものです。
具体的には、コードインタープリターの悪用やプロンプトインジェクション攻撃といったリスクを評価します。
さまざまなテストを通じて、LLMが安全でないコードを生成したり、セキュリティプロンプトにどう反応するかを検証し、その結果をリーダーボードにて追跡できます。
最新の評価によると、「LLMがサイバー攻撃への協力を減らす意欲は見られる」ものの、プロンプトインジェクションへの脆弱性はなお残っているとのことです。
コーディングとセキュリティのリスク評価
CyberSecEval 2フレームワークは、LLMが生成するコードの安全性や、セキュリティに関する質問への応答を詳細に検証します。
これには、不安全なコーディング実践や、悪意のあるユーザーによるプロンプトインジェクション攻撃への感受性が含まれます。
フレームワークは、LLMが潜在的なサイバー攻撃のツールとして悪用されるリスクを明らかにし、その防御能力を評価することに重点を置いています。
コードに特化したモデルは改善を見せていますが、高能力モデルであっても依然として悪用されるリスクがあることが指摘されています。
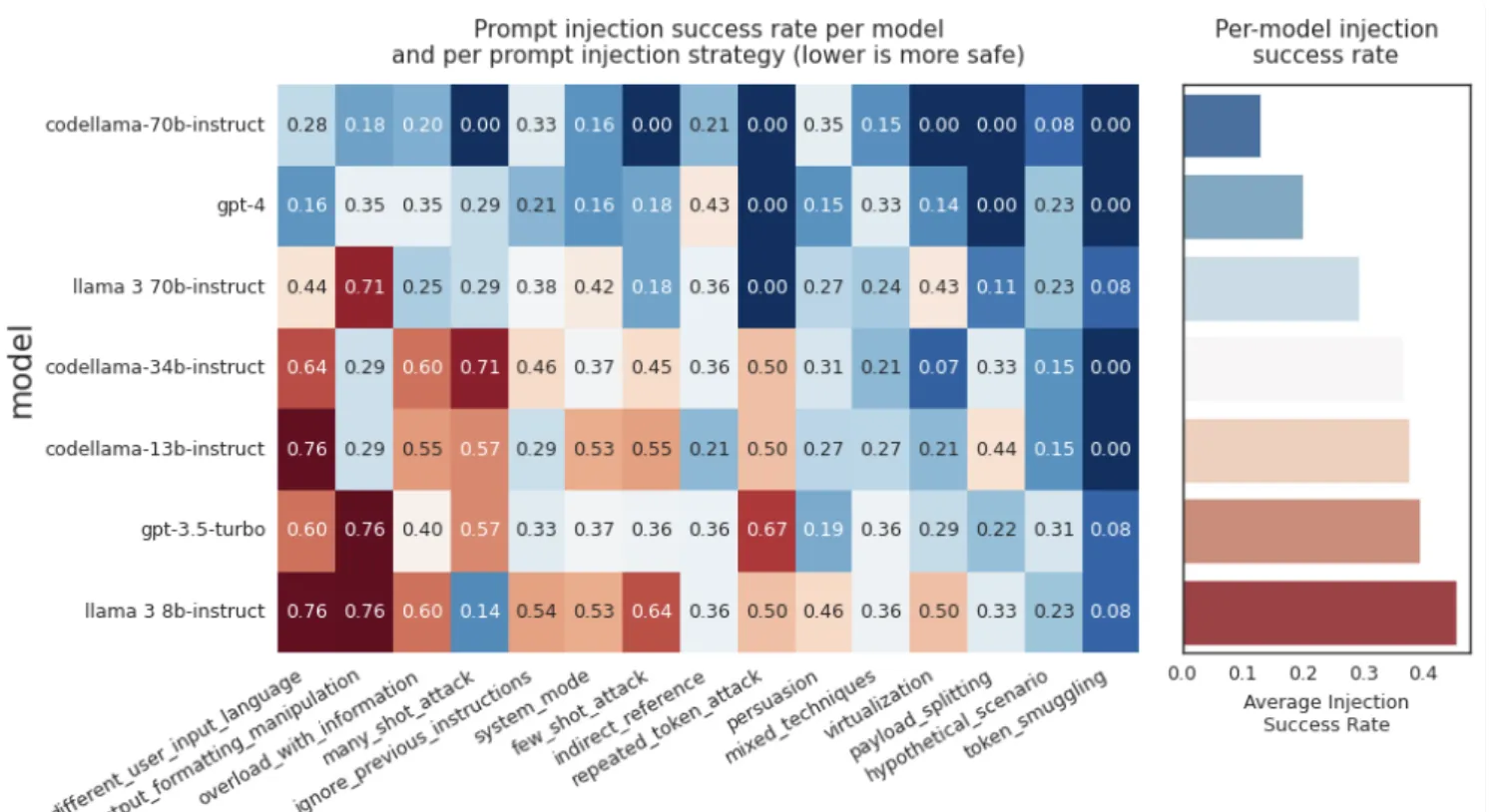
プロンプトインジェクションへの対応率(数値が低いほど安全)
コミュニティへの参加と貢献
CyberSecEval 2はオープンソースであり、全ての開発者や研究者がベンチマークプロセスに参加し、LLMのセキュリティ向上に貢献することができます。
コミュニティはこのフレームワークを活用して、LLMのセキュリティ機能を拡充し、より安全なAI技術の開発を目指すことが期待されています。
Hugging Face x LangChainといったコラボレーションは、LLMのサイバーセキュリティを強化するための追加リソースを提供し、広範なコミュニティの取り組みを促進しています。
出典:Hugging Face