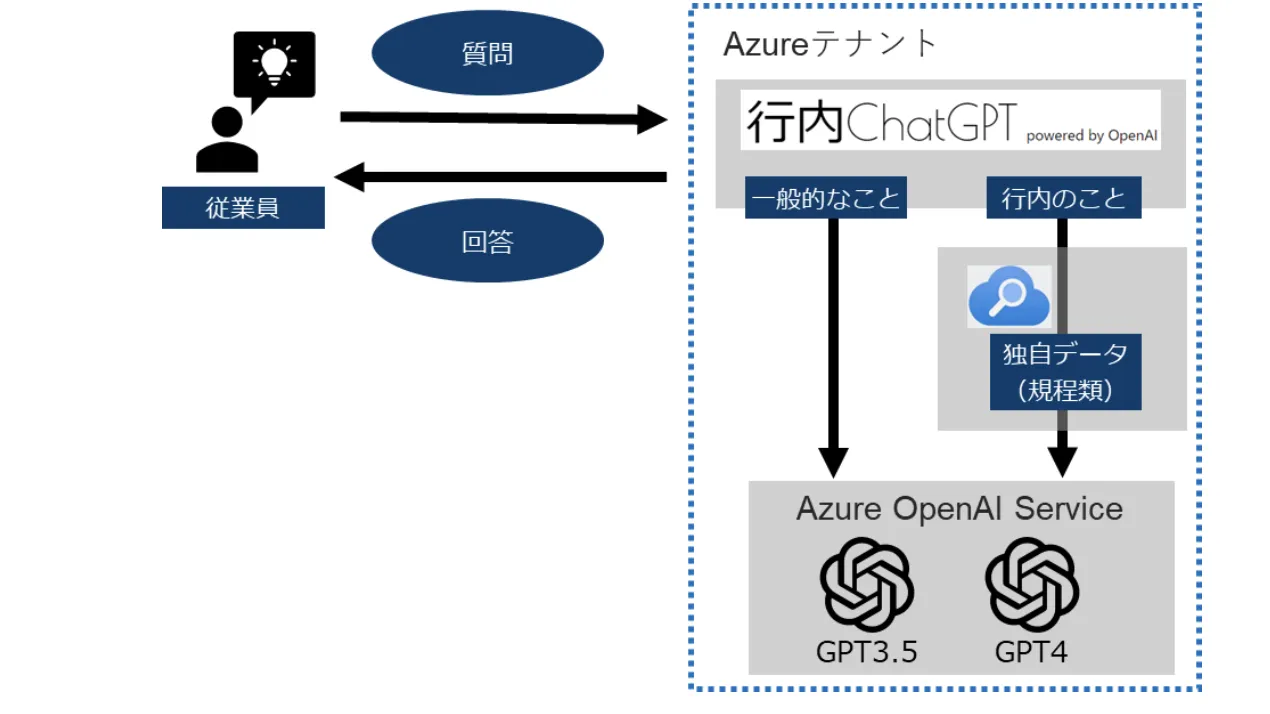
この記事のポイント
 この記事は、画像とテキストを理解できるAIツールであるVision Language Models(VLM)について解説しています。
この記事は、画像とテキストを理解できるAIツールであるVision Language Models(VLM)について解説しています。- VLMは多言語やチャット機能を含むバリエーション豊富なモデルを持ち、画像とテキストの組み合わせによる作業が得意です。
- ユーザーはVision ArenaやOpen VLM Leaderboardといったベンチマークツールを活用してVLMの性能評価ができます。
- VLMは画像エンコーダ、プロジェクタ、テキストデコーダーなどから構成され、事前学習を必要としない場合もあります。
- 具体的なモデルの使用方法とファインチューニングの手順について、詳細にわたって説明がされています。

監修者プロフィール
坂本 将磨
Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
画像とテキスト両方を理解し、これらを組み合わせた知識を活用できるVision Language Models(VLM)について、その仕組みや活用方法、さらに評価のためのベンチマークツール等についてわかりやすく解説していきます。
VLMは多様な機能を持ち、チャット機能含む複数言語をサポートするものもあります。また、多岐にわたるサイズのVLMの性能を比較するための有効なツールについても紹介し、具体的な使用例やファインチューニングの方法までを幅広くカバーします。
この記事を通じて、Vision Language Modelsの可能性と、それを最大限に引き出すための知識とツールを身につける手助けになることでしょう。

VLMの活用と評価方法紹介
Vision Language Models(VLM)は、画像とテキストを組み合わせてテキストを生成するAIツールです。画像キャプションの作成や、視覚的な質問に答えるといったことが得意です。
VLMは英語で提供されており、Hugging Face Hubにホストされています。サイズや機能が様々で、追加言語やチャット機能をサポートするモデルもあります。
これらのモデルの性能を比較・評価するために、Vision ArenaやOpen VLM Leaderboardなどのベンチマークツールがあります。
また、VLMEvalKitやLMMS-Evalといったツールを使って、MMEやMMBenchなどのタスクでモデルを試すことができます。
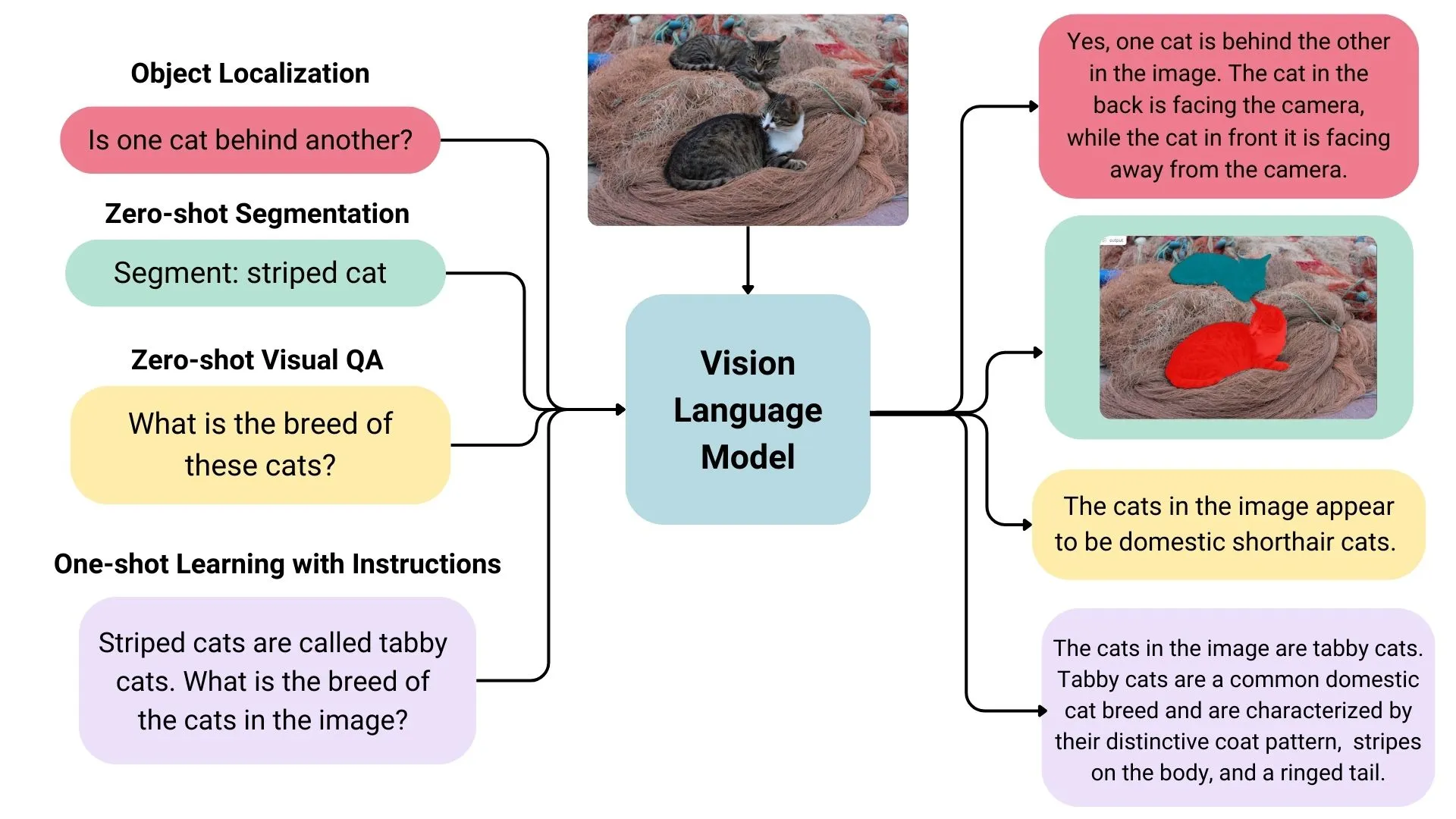
VLMの構造と事前学習
VLMは通常、画像エンコーダ、プロジェクタ、テキストデコーダーを含んでいます。これらは異なる事前学習戦略やコンポーネントを持っており、事前学習が必ずしも必要ではありません。
モデルはtransformersやSFTTrainerなどのツールを使って、特定のタスクに合わせてファインチューニングされることがあります。つまり、VLMは特定のニーズに応じてカスタマイズ可能で、柔軟に対応できるのです。
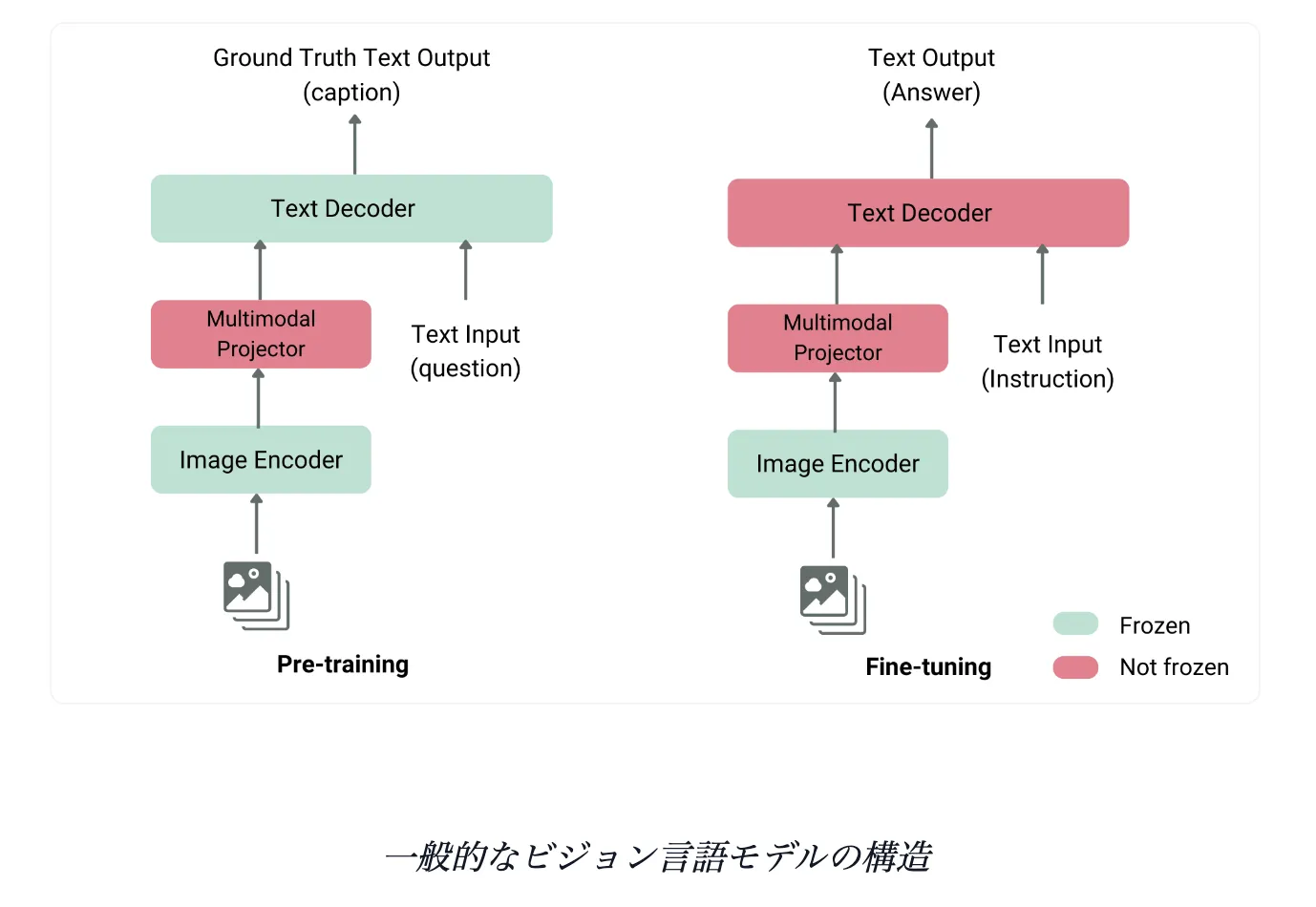
一般的なVLMの仕組み
VLMの具体的な使用方法とファインチューニング
記事ではLlavaNextのようなモデルを使って、VLMをどのようにtransformersで使用するのかを、モデルの初期化から処理、応答の生成までの流れに沿って説明されています。
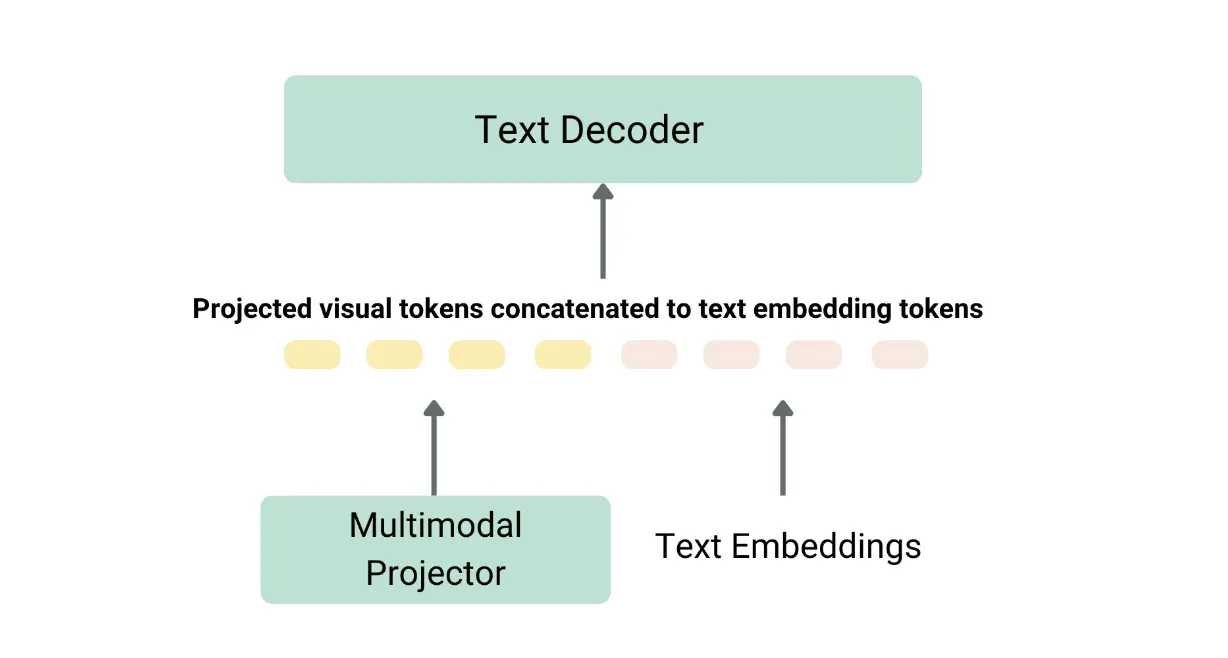
VLMにおけるTransformerの活用
また、lava-instructデータセットを使ってLlava 1.5をファインチューニングする例も紹介されており、TRLのSFTTrainerを使用したVLMのファインチューニングのプロセスがカバーされています。
Hugging Face Hubへのモデルのトレーニングとアップロード、テキストと画像のペアを処理するカスタムデータコレクタの使い方についても触れられています。