この記事のポイント
 Hugging FaceはFSDPとDeepSpeedを統合し、AIモデルトレーニングのGPU利用とメモリ節約を効果的に実現しました。
Hugging FaceはFSDPとDeepSpeedを統合し、AIモデルトレーニングのGPU利用とメモリ節約を効果的に実現しました。- 新たな低精度モードの導入により、大規模モデルトレーニング時のメモリ消費を抑制しつつ性能を維持できるようになりました。

監修者プロフィール
坂本 将磨
Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
AIモデルのトレーニング効率を向上させるための革新的な取り組みにおいて、Hugging Faceが新たなマイルストーンを達成しました。
この記事でご紹介するのは、Fully Sharded Data Parallel(FSDP)とDeepSpeedの統合に成功し、AIモデルのトレーニング過程でGPU利用の最適化とメモリ節約の両立を実現したHugging Faceの最新動向です。
この技術統合により、大規模なAIモデルも効率的にトレーニング可能になり、さらに低精度モードの導入でメモリ消費を抑制しつつも性能を維持するという成果が得られています。
また、半精度形式でのMistral-7Bモデルの性能向上も報告されており、今後のAI研究と開発における新たな可能性が開かれています。
研究者や開発者に向けた実用ガイドも提供されており、広くAIコミュニティの発展に寄与することが期待されます。
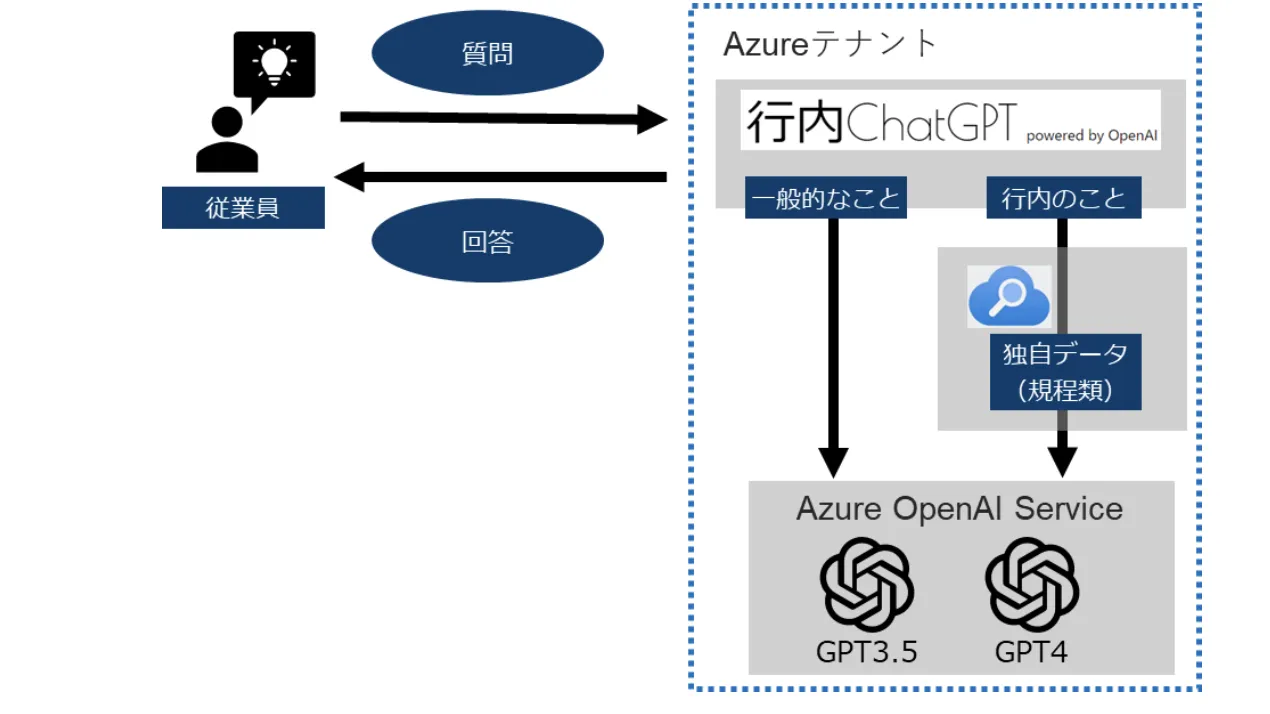
Hugging Faceが推進するAIトレーニングの最適化:FSDPとDeepSpeedの統合
2024年6月13日、Hugging FaceはAccelerateフレームワークにおいて、Fully Sharded Data Parallel(FSDP)とDeepSpeedを統合したと発表しました。これにより、人工知能(AI)モデルのトレーニング過程で、GPUの効率的な使用とメモリ節約を実現したことが明らかにされました。
FSDPは、GPUのメモリに収まらない大きなモデルも効率的にトレーニングすることができ、GPUの数に応じて学習率を調整することで、DeepSpeedと同程度の損失収束を達成しています。
また、新たな低精度モードを導入し、メモリ使用量を削減しながらも性能を維持することができるようになりました。
この統合は、より大きなモデルのトレーニングを可能にし、将来的にはGPUの利用効率をさらに高め、モデルの品質を向上させることを目指しています。
AIのトレーニングプロセスを最適化し、より多くの研究者や開発者が利用できるようにする取り組みであり、IBMリサーチなど他の団体との協力によって進められています。
Mistral-7Bモデルの性能向上:FSDPとDeepSpeedの統合の影響
Hugging Faceの記事は、半精度形式(FP16)でのMistral-7BモデルのトレーニングにおけるFSDPとDeepSpeed統合の効果を詳しく説明しています。
統合によって、FSDPはDeepSpeedと同様の混合精度トレーニングをサポートし、新しい低精度モードが追加されました。
これにより、大規模なAIモデルでもメモリ使用量を抑えつつ、高い精度を維持することが可能になります。
FSDPとDeepSpeedの違いには、どのように精度を扱い、メモリ使用と最適化に影響を与えるかという点があります。
これらの違いを理解し、適切に統合することで、AIモデルのトレーニングプロセスが効率化され、より高品質なモデル開発に貢献しています。
記事には、この統合による利点だけでなく、具体的な使用方法についてのガイドも提供されており、開発者が容易にこれらの技術を適用できるようになっています。
統合技術の利用ガイドと将来的な展望
Hugging Faceの取り組みは、IBMリサーチをはじめとする他の組織との協力により進められており、共同での研究成果を通じてAIコミュニティ全体の進歩に貢献しています。
今後も、GPUを効率的に利用し、より高品質なAIモデルを開発するための技術革新が期待されています。
また、公開されている実験結果とコードを通じて、誰でもこの技術の再現性を確認し、学習や研究に活用することが可能です。
出典:Hugging Face