この記事のポイント
 大規模モデルの知識を小型モデルへ
大規模モデルの知識を小型モデルへ- 推論の高速化・軽量化が可能
- 蒸留損失で確率分布を学習
- エッジデバイスでのAI活用に貢献
- モデルのコモディティ化を促進

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
近年、AIの性能向上は目覚ましいですが、その裏でモデルは巨大化し、計算コストや消費電力の増大が課題となっています。
ハイスペックな計算資源を持たない環境では、最新AIモデルの恩恵を受けることが難しい…そんな悩みを解決するのが「知識蒸留」です。
本記事では、この「知識蒸留」について、基礎から応用までをわかりやすく解説します。
知識蒸留の仕組み、具体的な実装方法、メリットとデメリット、そして今後の可能性までを、幅広く網羅的に説明します。
目次
AIの蒸留(知識蒸留)とは?
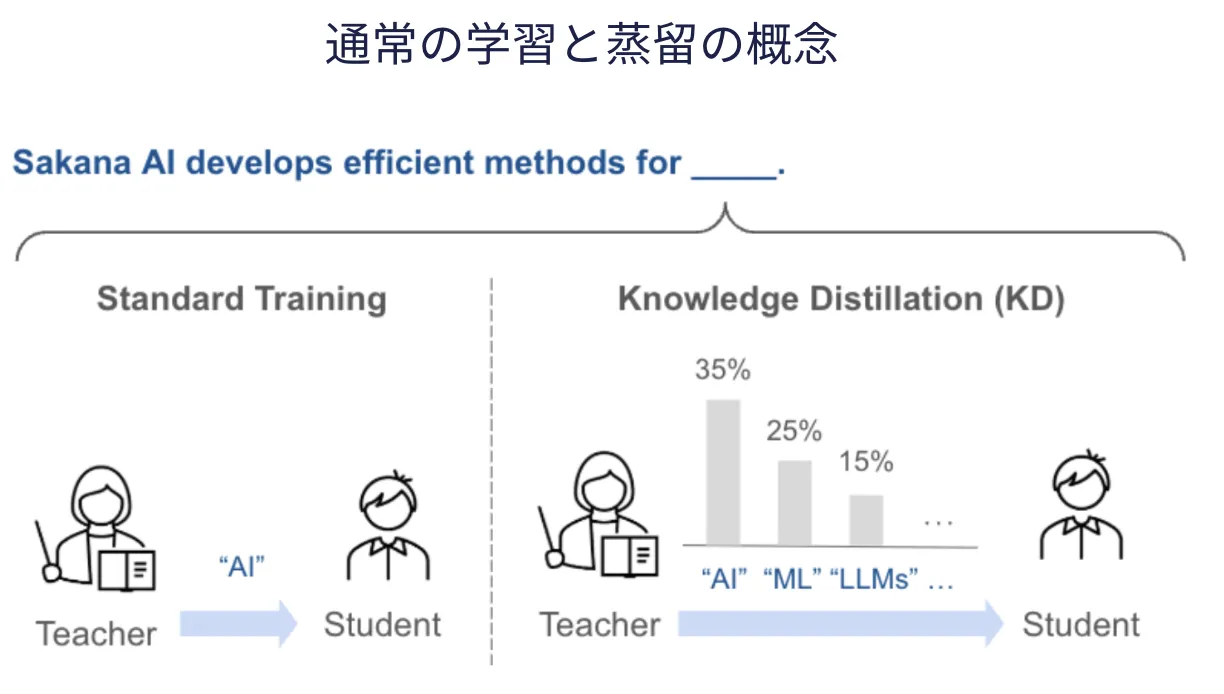
知識蒸留[引用:SakanaAI]](https://sakana.ai/taid-jp/)
知識蒸留とは、大きくて高性能なモデル(一般に「教師モデル」や「Teacher Model」と呼ぶ)が持っている知識を、より小さく軽量なモデル(「生徒モデル」または「Student Model」)へ移し替える技術のことです。
ディープラーニングの分野では、パラメータ数が多いモデルほど高精度な推論ができる一方で、サイズや推論速度の問題から、実際の利用には不便が伴うことがあります。
知識蒸留を用いると、巨大なモデルが到達した「知識」を、小さなモデルに効率良く学習させることが可能になり、推論の高速化やリソース削減を実現しやすくなります。
知識蒸留が注目される背景
- 大規模モデルの増加
画像認識や自然言語処理などのタスクで、モデルのパラメータ数は年々増加しています。GPUやクラウド環境が普及しつつあるとはいえ、学習・推論にかかるコストは決して無視できません。
- エッジデバイスでの推論ニーズ
モバイル端末やIoT機器の上でリアルタイム推論を行うためには、モデルの軽量化・高速化が必須となります。
ネットワーク遅延やバッテリー消費量、メモリ容量を考慮すると、大規模モデルをそのまま動かすのは難しい場合が多くあります。
- 軽量化手法の多様化
モデルの軽量化手法としては、パラメータの剪定(Pruning)や量子化(Quantization)なども知られています。
しかし知識蒸留では、教師モデルから得られる「出力分布の情報」も利用できるため、精度を極力落とさずに小型化しやすいという利点があり、注目度が高まっています。

知識蒸留の手法と仕組み
知識蒸留においては、一般的に以下の手順を踏みます。
-
教師モデル(Teacher)
大きくて高精度なネットワーク。あらかじめ学習済みで、推論性能が優れていることが前提です。
-
生徒モデル(Student)
教師モデルよりもパラメータ数を抑えた小さなネットワーク。最終的にこのモデルがデバイス上で動作することを想定します。
蒸留損失(Distillation Loss)
知識蒸留のカギとなるのが、教師モデルの出力する「ソフトラベル(Soft Label)」を利用することです。
従来の学習では、正解ラベルが one-hot(1つのクラスのみが1で、他は0)になっていることが多いですが、教師モデルのロジット(未正規化の出力)をソフトマックス関数でならして得られる「確率分布」は、クラス間の微妙な確信度の違いを含んでいます。
- 温度パラメータ(Temperature)
ソフトマックスの鋭さを調整するために導入されるパラメータです。
高い温度を設定すると出力確率の分布がよりなめらかになるため、生徒モデルが教師モデルから得られる「クラス間の相対的な関係性」を学習しやすくなります。
一般的には、生徒モデルの学習時に「蒸留損失(Distillation Loss)」と呼ばれる以下のような式を用います。
[
\mathcal{L} = \alpha \cdot \text{CrossEntropy}(p_{student}^\tau, p_{teacher}^\tau) + (1 - \alpha) \cdot \text{CrossEntropy}(p_{student}, y_{true})
]
ここで、
- ( p_{teacher}^\tau ) は教師モデルのソフトマックス出力(温度 (\tau) を適用)
- ( p_{student}^\tau ) は生徒モデルのソフトマックス出力(温度 (\tau) を適用)
- ( y_{true} ) は正解ラベル(one-hot など)
- (\alpha) はハイパーパラメータ(ソフトラベル損失と通常の損失のバランスを決める)
蒸留の実装例
では実際の実装方法をご紹介します。
PyTorchを用いた簡単な例
import torch
import torch.nn.functional as F
def compute_knowledge_distillation_loss(student_logits, teacher_logits, y_true, T=2.0, alpha=0.5):
"""
知識蒸留の損失を計算する関数。
Parameters:
student_logits (Tensor): 生徒モデルのロジット(未正規化の出力)
teacher_logits (Tensor): 教師モデルのロジット(未正規化の出力)
y_true (Tensor): 正解ラベル(クラスのインデックス)
T (float): 温度パラメータ(高いほどソフトな分布になる)
alpha (float): 蒸留損失とハードラベル損失のバランスを決める係数
Returns:
float: 最終的な損失値
"""
# 1. ソフトマックス出力(温度T適用)
p_student = F.log_softmax(student_logits / T, dim=1)
p_teacher = F.softmax(teacher_logits / T, dim=1)
# 2. 蒸留損失(KLダイバージェンスを利用)
distill_loss = F.kl_div(p_student, p_teacher, reduction='batchmean') * (T * T)
# 3. ハードラベル損失(クロスエントロピー)
hard_loss = F.cross_entropy(student_logits, y_true)
# 4. 最終的な損失を計算
total_loss = alpha * distill_loss + (1 - alpha) * hard_loss
# 5. デバッグ用の出力
print("\n=== 知識蒸留の損失計算 ===")
print(f"教師モデルの出力 (logits):\n{teacher_logits}")
print(f"生徒モデルの出力 (logits):\n{student_logits}")
print(f"教師モデルの確率分布 (Softmax):\n{p_teacher}")
print(f"生徒モデルの確率分布 (Log Softmax):\n{p_student}")
print(f"蒸留損失 (Distillation Loss): {distill_loss.item():.4f}")
print(f"ハードラベル損失 (Cross Entropy Loss): {hard_loss.item():.4f}")
print(f"最終的な損失 (Total Loss): {total_loss.item():.4f}")
return total_loss
# サンプルデータを用意(クラス数3、バッチサイズ2のミニバッチ)
torch.manual_seed(42) # 乱数シードを固定
student_logits = torch.randn(2, 3) # 生徒モデルの出力
teacher_logits = torch.randn(2, 3) # 教師モデルの出力
y_true = torch.tensor([0, 2]) # 正解ラベル(クラスインデックス)
# 損失の計算
loss = compute_knowledge_distillation_loss(student_logits, teacher_logits, y_true, T=2.0, alpha=0.5)
出力結果
=== 知識蒸留の損失計算 ===
教師モデルの出力 (logits):
tensor([[ 2.2082, -0.6380, 0.4617],
[ 0.2674, 0.5349, 0.8094]])
生徒モデルの出力 (logits):
tensor([[ 0.3367, 0.1288, 0.2345],
[ 0.2303, -1.1229, -0.1863]])
教師モデルの確率分布 (Softmax):
tensor([[0.6029, 0.1453, 0.2518],
[0.2895, 0.3309, 0.3796]])
生徒モデルの確率分布 (Log Softmax):
tensor([[-1.0478, -1.1518, -1.0989],
[-0.8417, -1.5183, -1.0500]])
蒸留損失 (Distillation Loss): 0.3908
ハードラベル損失 (Cross Entropy Loss): 1.0333
最終的な損失 (Total Loss): 0.7120
上記は蒸留損失を計算する関数の一例です。実際には教師モデルと生徒モデルを定義し、教師モデルの出力であるteacher_logits、生徒モデルの出力であるstudent_logitsを使って損失を計算し、生徒モデルを学習します。
Hugging Face などでの事例
自然言語処理の分野では、Hugging Faceが提供しているDistilBERTというモデルが代表例です。

元のBERTモデルよりも約40%小さく、推論速度も高速でありながら、性能の低下を最小限に抑えています。公式のライブラリでは、追加のコードや知識なしに簡単に蒸留済みモデルを利用できます。
またDeepSeekでの活用が注目されたり、Sakana AIでの活用も報告されています。
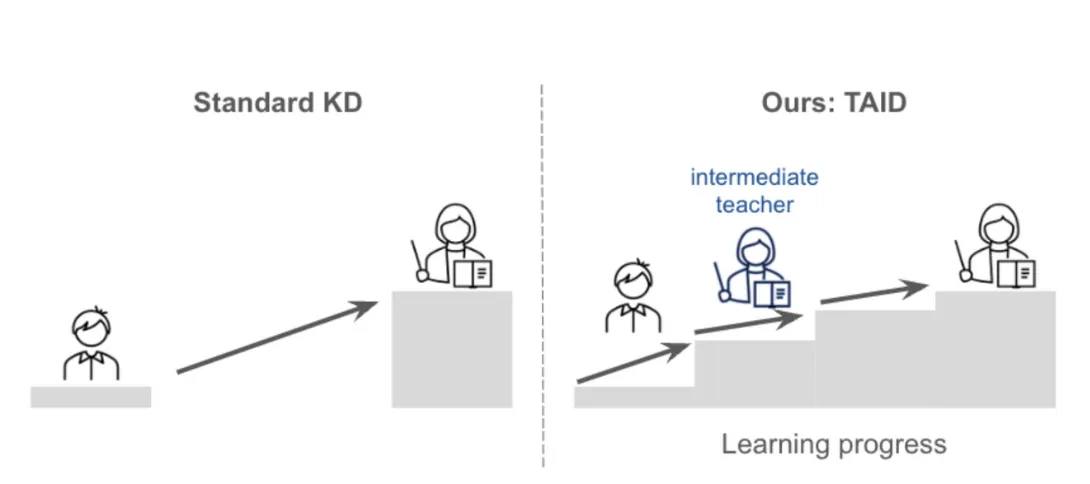
通常の蒸留とSakanaAIの蒸留引用:https://sakana.ai/taid-jp/
SakanaAIは2025年、1月30日に知識蒸留手法「TAID (Temporally Adaptive Interpolated Distillation)」を報告しました。
従来であれば、教師モデルと性能差が大きい場合、同等の性能を得ることは難しいことがありましたが中間のintermediate teacherを置くことでその精度を高める手法を提案しています。

考慮すべき課題・限界
知識蒸留は完璧なものではなくいくつかの課題や限界もあります。
-
教師モデルの作成コスト
大規模な教師モデルを用意するためには、多大な計算資源とデータが必要です。蒸留の恩恵を受けるためには、まず大きなモデルのトレーニングが前提となります。
-
データの必要量
生徒モデルを蒸留する際には、教師モデルと同じか、ある程度同質のデータを用意する必要があります。データが不足している場合、蒸留の効果が十分に発揮されないことがあります。
-
性能劣化のリスク
生徒モデルの容量には限界があるため、教師モデルとまったく同等の性能を得ることは難しい場合があります。しかし、適切なハイパーパラメータを見つけるなど工夫によって、多くのケースで実用的な性能を確保できます。
-
ライセンスや知的財産の問題
教師モデルが商用の学習データや独自のライセンス下にある場合、そのモデルを蒸留する行為自体に法的な制限がかかる可能性があります。利用前にライセンス条件などを確認することが重要です。
まとめ
本記事では、知識蒸留(Knowledge Distillation) の基本概念、メリット、実装方法について解説しました。巨大なAIモデルが持つ豊富な知識を、より小型で高速なモデルへと移植する技術は、推論コストの削減やメモリ制約の厳しい環境での活用において、大きなアドバンテージとなります。
このような技術の進化により、AIモデルのコモディティ化(一般化・標準化)が急速に進んでいます。特に、MoE(Mixture of Experts)やGRPO(Guided Reward Policy Optimization) といった手法の活用によって、モデルの軽量化・効率化が進み、高性能なAIが低コストで利用できる時代が到来しつつあります。
この流れの中で、AIの競争領域はモデルの差別化からアプリケーションレイヤーへと移行していくことも予想されています。
企業がAIを活用する際には、単なるモデルの性能比較ではなく、実運用におけるコスト、応用範囲、統合のしやすさを考慮する必要があります。今後のAI市場では、「どのモデルを使うか」ではなく、「どのように使うか」 が、成功の鍵となるでしょう。
AI総合研究所は企業のAI活用をサポートしています。お気軽にご相談ください。






