この記事のポイント
 この記事は「RHLF(Reinforcement Learning from Human Feedback)」について、その定義、特徴、対話型AIへの応用例などを解説している内容です。
この記事は「RHLF(Reinforcement Learning from Human Feedback)」について、その定義、特徴、対話型AIへの応用例などを解説している内容です。- RHLFは、人間の判断を取り入れながらAIモデルを学習させる手法で、曖昧な基準や主観的なタスクに対応可能です。

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AIの進化を支える手法のひとつである「RHLF」とは何か、その魅力について徹底解説します。 人間のフィードバックを利用して学習する強化学習手法であり、AIによりユーザーフレンドリーな出力を重視したものが求められる現代において、RHLFはますます重要性を増しています。
本記事では、RHLFの基本概念から特徴、メリット・デメリット、そして具体的な適用事例まで、幅広く紐解いていきます。
AIにとっての望ましい振る舞いを定義する上で中心となるRHLFの概念を理解し、その応用可能性と今後の展開についても一緒に学んでいきましょう。
RHLF(Reinforcement Learning from Human Feedback)とは
RHLFは、AIモデルが人間のフィードバックを活用して、望ましい振る舞いや出力を学習する手法 です。
通常、AIは大量のデータや既存のルールに基づいて学習しますが、それだけでは「人間にとって望ましい」動作をするとは限りません。
RHLFでは、人間が好ましい回答や避けるべき回答など、人間の意見やフィードバックを使って、AIが「何が良い結果か」を理解し、調整することを目的としています。
具体的には、以下の図のように環境から得る定量的報酬に加え、人間のフィードバックを取り入れることで、モデルは実社会で求められる柔軟な応答品質を理解し、回答が行えるようになるのです。
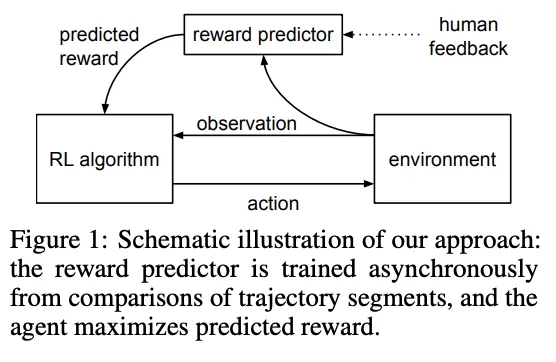
RHLFの構成図参照:Deep Reinforcement Learning
from Human Preferences
RHLFの特徴
RHLFは、強化学習の一部ですが従来との違いは以下の通りです。
| 観点 | 従来の強化学習 | RHLF |
|---|---|---|
| 報酬源 | 環境報酬のみ | 人間評価を統合 |
| 応用範囲 | タスク特化型が多い | LLM、対話AI、要約など幅広い |
| 改善ポイント | 定量的評価に集中 | 倫理性やユーザー志向性も重視 |
RHLFとファインチューニングの違い
RHLF(Reinforcement Learning from Human Feedback)とファインチューニングは、どちらもAIモデルの性能を向上させるための手法ですが、アプローチが異なります。
| 項目 | RHLF | ファインチューニング |
|---|---|---|
| 目的 | 人間のフィードバックを活用し、モデルの出力を人間の価値観や好みに合わせる | 特定のタスクやデータセットに特化して、モデルの性能を向上させる |
| 学習データ | 人間による評価データ(例:出力のペアワイズ比較、良し悪しのラベル付け) | タスク固有のラベル付きデータセット |
| 学習方法 | 強化学習(報酬モデルを介して、人間のフィードバックを報酬としてポリシーを最適化) | 教師あり学習(ラベル付きデータを用いて、モデルのパラメータを微調整) |
| 適用例 | 対話型AI、コンテンツ生成、ユーザーの好みに合わせた応答の生成 | テキスト分類、固有表現抽出、機械翻訳など、特定のタスクの精度向上 |
| メリット | 曖昧なタスクや主観的な問題に対応可能、人間の倫理観を反映できる | 比較的少ないデータで高い性能を発揮しやすい、既存モデルの転用が可能 |
| デメリット | 人間による評価コストが高い、評価基準が曖昧になりやすい | 過学習のリスクあり、大量のラベル付きデータが必要となる場合がある |
| 補足 | 主観的、倫理的な出力が求められる場合に有用 | タスクが明確で、正解データがある場合に有用 |
簡単にまとめると
- RHLF: 人間のフィードバックを使って、「人間にとって望ましい出力」 を学習させる。(例:より自然な会話、倫理的な配慮)
- ファインチューニング: 特定のタスクのラベル付きデータを使って、「タスクの精度」 を向上させる。(例:文章分類の精度向上、機械翻訳の精度向上)
使い分けのポイント:
- 出力の良し悪しが主観的で、人間の価値観を反映させたい場合はRHLFが適しています。
- 出力の良し悪しが客観的に定義でき、特定のタスクでの精度向上が目的の場合はファインチューニングが適しています。
RHLFと従来手法の違い
ここでは、RHLFがなぜ既存の強化学習や教師あり学習、ルールベース手法と異なり、特有の強みを発揮できるのかをご紹介します。
RHLFは、定量的な報酬だけでは表せない「人間的な基準」を取り込み、モデルの応答をより私たち人間が求める回答に近づけるアプローチです。
強化学習(Reinforcement Learning:RL)との違い
従来の強化学習は環境から得られる報酬に基づいて方策を更新するのが基本です。
AIエージェントが環境内で行動を試し、環境から「報酬」を受け取ることを通じて、AIはどの行動をとれば最大の報酬が得られるかを学びます。
| 項目 | 従来の強化学習(RL) | RHLF(人間のフィードバックを使った強化学習) |
|---|---|---|
| 報酬の起源 | 環境が自動的に与える数値的な報酬 | 人間が直接与えるフィードバック |
| 適用範囲 | 数値化されたゴールが明確なタスク | 曖昧な基準や主観的なタスク |
| 報酬設計の手間 | 高い(適切な報酬設計が必要) | 少ない(人間が直接評価するため報酬設計が不要) |
| 柔軟性 | 固定的なルールに適応 | 人間の意図や好みに柔軟に対応 |
| コスト | 設定後は自律的に学習 | 人間による継続的なフィードバックが必要 |
| 学習効率 | 高い(大量の試行で効率的に報酬を学習) | 低い(フィードバックが少量で学習が遅くなる場合あり) |
| 例 | ゲームAI、ロボット制御 | 会話AI、文章生成、画像の品質評価 |
従来のRLは数値化可能な目標に強く、RHLFは曖昧な価値観や人間の好みに対応できる点が特徴的だとわかります。
そのため、RHLFは、国際的・文化的な違いや微細な嗜好に合わせたモデル調整が可能となり、多様なユーザーベースに対応できる点で大きな強みを発揮するでしょう。
RHLF導入のメリット・デメリット
ここまではRHLFがどんなものなのか、その概要について解説してきました。
現状のモデルに対して、RHLFを活用することで、モデル品質向上が期待できる一方で、人間評価コストや評価基準設定の難しさも発生します。
具体的には、以下の表のようなメリット、デメリットが考えられます。
| 観点 | メリット | デメリット |
|---|---|---|
| 品質 | 人間基準反映で出力向上 | 基準不統一の懸念 |
| コスト | 有用性強化による価値増加 | 人的評価コスト増 |
| 信頼性 | 倫理性・安全性向上 | 明確な評価基準策定困難 |
RHLFのメリット3点
- ユーザー嗜好反映:より人間的で満足度の高い出力が可能になります。
- 倫理面の調整:不適切応答や偏った見方による出力を調整することができます。
- オープンエンドな改善:継続的な学習を行うことで、連続的な品質向上が期待できます。
RHLFのデメリット・課題3点
- 評価コスト:人間アノテーション作業が増加し、負担が大きくなります。
- 主観的要素:評価者間で基準がばらつく可能性があり、
- 大規模運用課題:規模が大きくなればなるほど、評価作業のスケールが難しいです。
これらの活用し、改善していくために、評価ルールの標準化や、一部自動評価システム導入などで、時間とコストを削減しつつRHLFの恩恵を最大化する取り組みが進んでいます。
RHLFの適用領域と実用例
ここでは、これまで概説したRHLFの特徴や従来手法との比較を踏まえ、RHLFが実際の現場でどのように活用され、どんな効果が期待できるかについて具体例を交えながら紹介します。
RHLFはその特性を活かし、対話型AIや大規模言語モデル、さらにはカスタマーサポートやドキュメント要約といった多岐にわたる領域で活躍しています。
対話型AI(ChatGPTなど)への応用
RHLFを使うと、従来の手法に比べ、対話AIはユーザーの意図や好み、文化的背景に合った自然な応答を返しやすくなります。
誤情報や不適切表現を減らしつつ、よりスムーズなコミュニケーションが可能になるのです。
例えば、以下のようなツールでの活用が考えられます。
- カスタマーサポートチャットボットの精度向上
- メール返信提案ツールの品質改善
- 教育・学習支援への適用でより分かりやすい解説提供
以下は、Metaによって発表された、RHLFを活用して新たな可能性を示唆するポストです。
これまでの手法とは異なり、人間の思想回路を再現することで、より高度なコミュニケーションが可能になるかもしれません。
New research from Meta FAIR: Large Concept Models (LCM) is a fundamentally different paradigm for language modeling that decouples reasoning from language representation, inspired by how humans can plan high-level thoughts to communicate. pic.twitter.com/yY8QZXrTts
— AI at Meta (@AIatMeta) December 23, 2024
将来は、個人特化型AIアシスタントや業界特化モデルへの展開も想定され、ユーザーエクスペリエンスがさらに進化していくことが期待されています。
RLHFの実装プロセスと具体的手法
RLHF(Reinforcement Learning from Human Feedback)は、人間のフィードバックを活用してAIモデルを調整・最適化する手法です。以下では、報酬モデルの構築方法や学習プロセスを具体的に説明します。
報酬モデルの構築
報酬モデルは、AIの出力がどれだけ「望ましい」かを評価する役割を担います。人間のフィードバック(例:ペアワイズ比較)を基に学習し、AIが人間の価値観を理解する基盤を作ります。
数式で表す報酬モデルの学習
人間によるペアワイズ比較を用いて、以下の損失関数を最小化することで報酬モデルを学習します:
[
L(\phi) = - \log \sigma(R_\phi(y_1) - R_\phi(y_2))
]
- (\sigma(x)):シグモイド関数
- (R_\phi(y)):出力 (y) に割り当てられるスコア
- (\phi):報酬モデルのパラメータ
このプロセスにより、モデルは「望ましい出力」をスコアリングする能力を獲得します。
報酬モデル構築の流れ
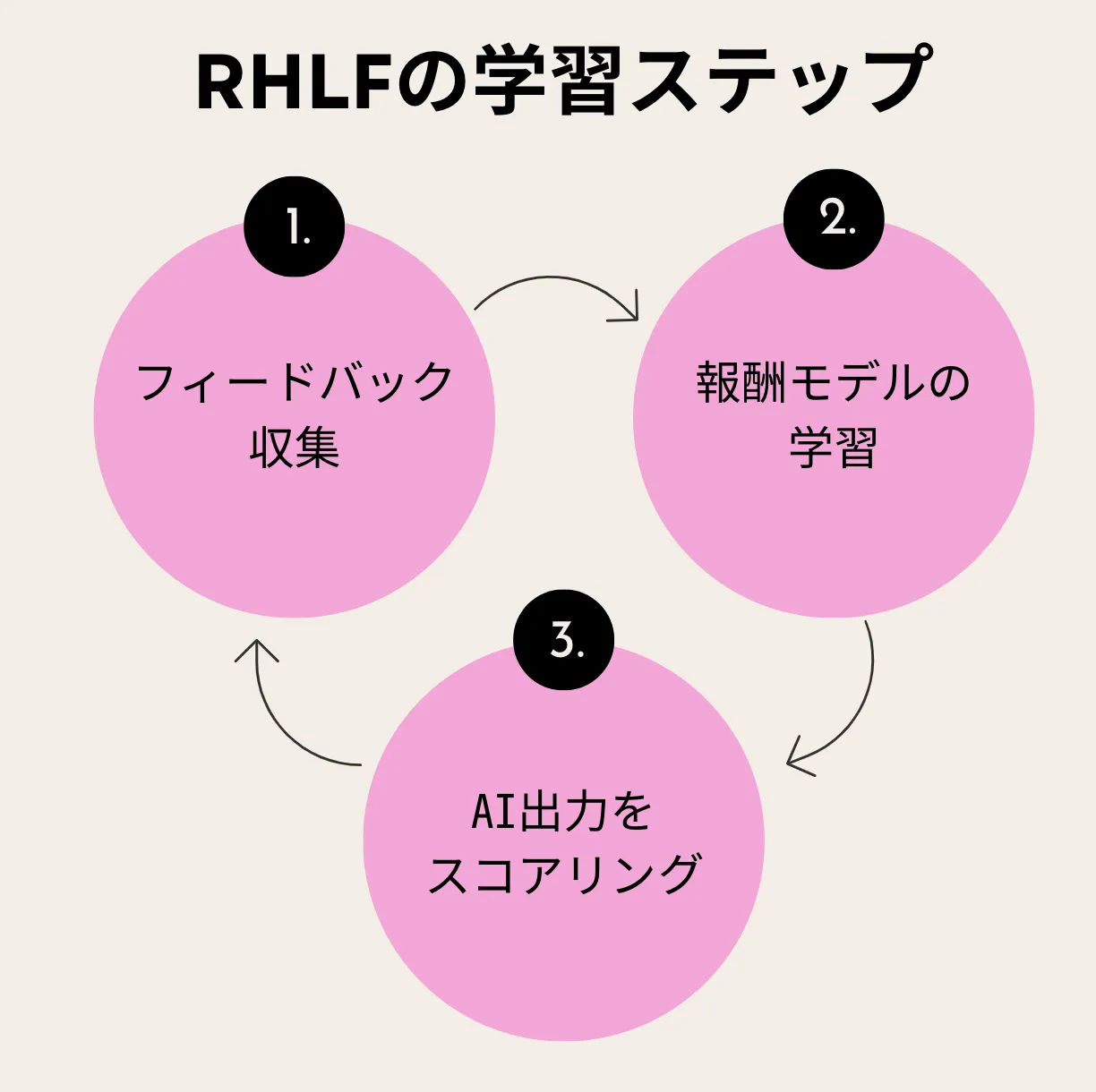
報酬モデル構築の流れ
- フィードバック収集: 人間が出力の良し悪しを評価。
- 報酬モデルを学習: 評価データを基にモデルを訓練。
- AI出力をスコアリング: モデル出力を評価し、改善に利用。
学習プロセスの流れ
RLHFは「初期モデルの出力生成 → 人間の評価 → 報酬モデルの更新 → ポリシーの最適化」のサイクルで進行します。この反復により、モデルの品質が段階的に向上します。
学習プロセスの5ステップ
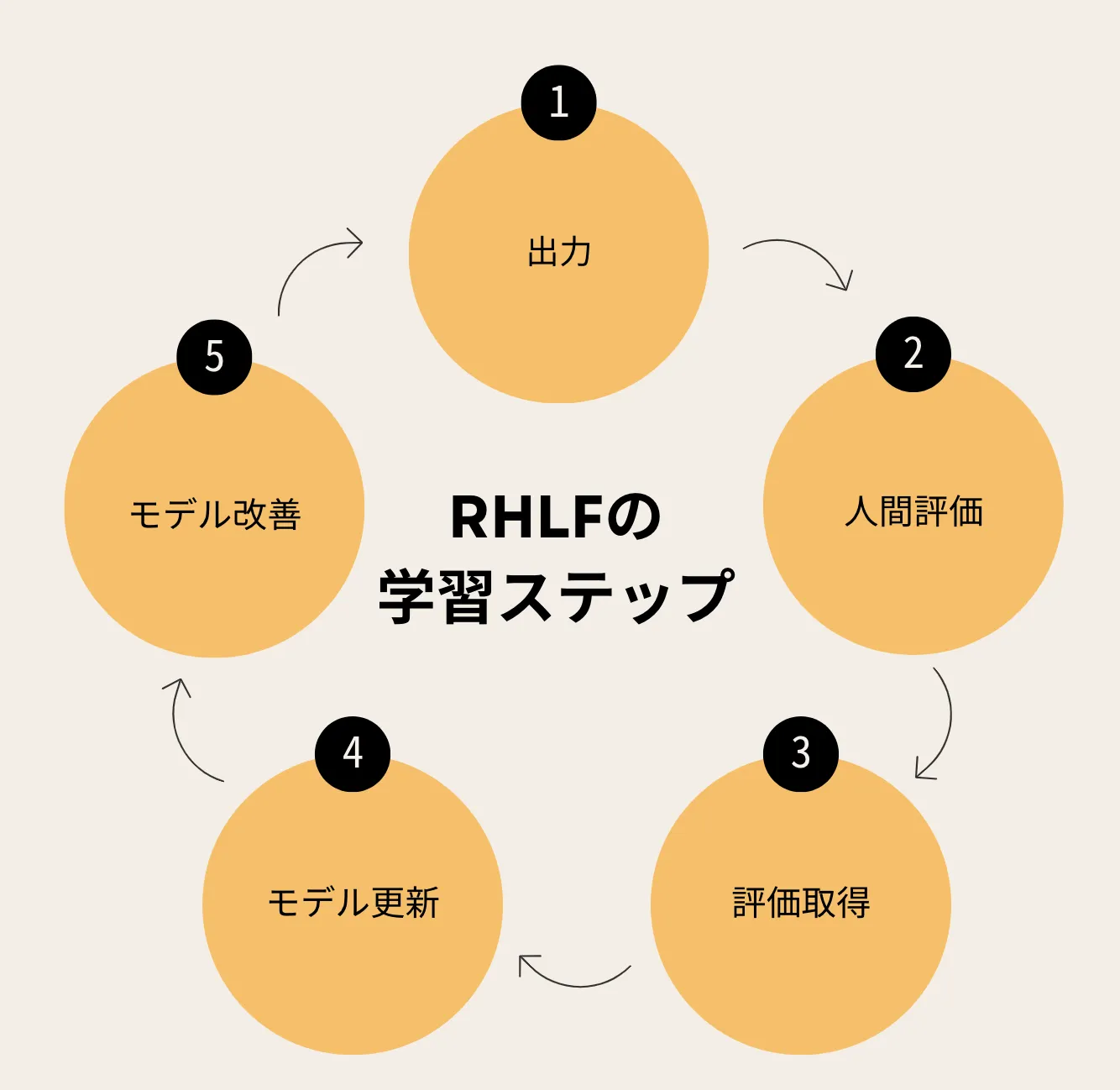
学習の流れ
- 初期モデルの出力生成: モデルが回答を生成。
- 人間による評価: アノテータが出力を評価。
- 報酬モデルを更新: 評価データを基に報酬モデルを改良。
- ポリシーの最適化: 報酬モデルを使い、以下の式でポリシーを改善:
[
\nabla_\theta J(\theta) = \mathbb{E}{a \sim \pi\theta} \left[ \nabla_\theta \log \pi_\theta(a | s) \cdot r(s, a) \right]
]
- KL制約の適用: プリトレーニング済みモデルと乖離しすぎないよう調整:
[
L(\theta) = - \mathbb{E}{a \sim \pi\theta} [ R_\phi(y) ] + \beta \cdot \text{KL}(\pi_\theta || \pi_0)
]
RLHFは、人間のフィードバックを活用してモデルを改善する強力な手法です。報酬モデルを構築し、反復的にポリシーを最適化することで、AIモデルはより人間の価値観に沿った出力を生成できるようになります。このプロセスを通じて、安全性と信頼性の高いAIシステムが構築されます。
RHLFが優秀なのはなぜ?
RHLF(Reinforcement Learning from Human Feedback)が優秀である理由は、既存手法の限界を克服し、人間にとって 「本当に役立つAI」 を作るための重要な特性を備えているからです。
簡単にまとめると、RHLFは特に「人間と協働するAI」や「ユーザーに寄り添うAI」を目指す分野で、非常に優秀な手法といえます。
RHLFが優秀である理由のまとめ
RHLFは、以下の特性を持つため、他の手法よりも現実世界の課題に適しています:
- 曖昧で主観的な問題にも対応可能:数値化できない基準でも学習できる。
- 人間らしい価値観を反映:倫理的で望ましい結果を学ぶ。
- 継続的な改善:使うほど賢くなるAIを実現。
- 柔軟性と適応性:ルールや固定されたデータに縛られない。
- 報酬設計が不要:人間のフィードバックが報酬の代わりになる。→図に起こす
1. 曖昧なタスクや主観的な問題に対応できる
従来の手法(教師あり学習や従来の強化学習)は、数値化されたゴールや明確なラベルが必要ですが、現実世界の多くのタスクは「曖昧」で「主観的」です。
たとえば、「自然な会話をする」「美しいデザインを生成する」などのタスクは、数値化やラベル付けが難しいです。
RHLFは人間のフィードバックを直接取り入れることで、こうした曖昧な目標にも柔軟に対応できます。
2. 人間の価値観や倫理観を反映できる
従来の手法は、「環境のルール」や「事前に定めたラベル」に従って学習しますが、それが人間の倫理や価値観と一致するとは限りません。
RHLFでは、人間がフィードバックを通じてAIをガイドするため、人間にとって望ましい結果や倫理的な判断を学ばせることが可能です。
例:
- ユーザーに対して失礼のない応答を学ぶ。
- 誤情報を広めない回答を優先させる。
3. フィードバックを活用した継続的な改善が可能
従来の手法では、一度モデルを学習させるとそれ以上の改善が難しい場合があります。
一方でRHLFは、フィードバックを増やし続けることで、継続的にモデルの品質を向上させることができ、時間とともに「使うほど賢くなるAI」を実現できます。
4. 柔軟で動的な学習プロセス
ルールベースや教師あり学習のように「事前に固定されたルール」や「ラベル」に頼らず、動的に調整可能です。ユーザーの好みやニーズが変化した場合にも、柔軟に対応できます。
例:
- ユーザーごとに異なる好みに合わせた会話スタイルを学ぶ。
- 特定の状況に応じて応答のトーンを変える。
5. 報酬設計の手間を省ける
従来の強化学習では、報酬関数の設計が成功の鍵ですが、これが非常に難しいタスクです。報酬関数が間違っていると、AIは期待しない行動を学んでしまいます。RHLFは人間のフィードバックをそのまま報酬として活用するため、複雑な報酬設計が不要で、設計の手間やリスクを減らすことができます。
6. 現実世界の課題解決に適している
RHLFは、実際のユーザーや人間のフィードバックを通じて学習するため、現実世界の課題解決に直結します。これにより、より実用的で信頼できるAIを構築できます。
例:
- カスタマーサポートで顧客満足度を最大化する回答を学ぶ。
- 生成した画像や文章が「使いやすい」「好ましい」とされる基準を学ぶ。
実際にRHLFをやってみましょう
RLHF(Reinforcement Learning from Human Feedback)は、人間のフィードバックを活用してAIモデルを強化学習で改善する手法です。以下に、その実装プロセスをGoogle Colabを使って簡易的に再現する方法を示します。
実際に使ってみることで理解を深めてみてください!
必要なライブラリのインストール
Google Colabで以下を実行してください。
!pip install transformers torch numpy datasets
ステップ1: 初期モデルの出力生成
事前学習済みモデル(GPT-2)を使用して出力を生成します。
GPT-2モデルを使い、「フランスの首都はどこか?」という質問に対する回答を生成しました。
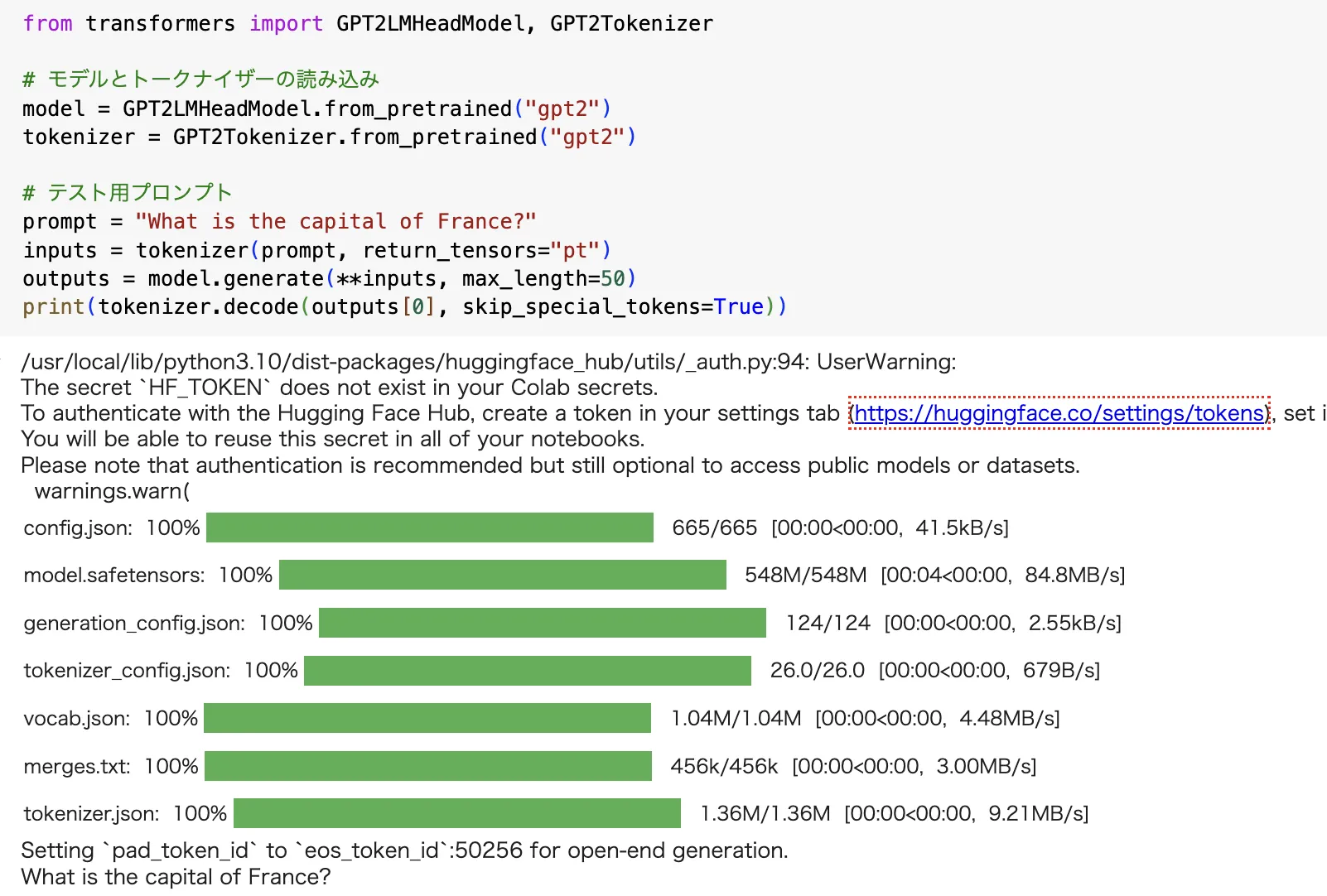
初期モデルの出力生成
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# モデルとトークナイザーの読み込み
model = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# テスト用プロンプト
prompt = "What is the capital of France?"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
実行結果例:
"The capital of France is Paris, which is located in the northern part of the country..."
ステップ2: 人間のフィードバック収集
出力を比較し、優れた方にスコアを付けます。以下は簡単な例です。
2つの異なる回答(例:パリ vs リヨン)を比較し、どちらが望ましいかを人間のフィードバックとして記録しました。
# 出力例
output_1 = "The capital of France is Paris."
output_2 = "France's capital is Lyon."
# ペアワイズ比較データ
feedback = {"output_1": 1, "output_2": 0} # output_1が優れていると評価
ステップ3: 報酬モデルの学習
報酬モデルを構築し、ペアワイズ比較データを基に学習します。
import torch
import torch.nn as nn
import torch.optim as optim
# 報酬モデル
class RewardModel(nn.Module):
def __init__(self):
super(RewardModel, self).__init__()
self.fc = nn.Linear(768, 1) # GPT-2の隠れ層サイズに合わせる
def forward(self, x):
return self.fc(x)
reward_model = RewardModel()
optimizer = optim.Adam(reward_model.parameters(), lr=1e-4)
# 損失関数の計算と学習
def train_reward_model(output_1, output_2, feedback):
reward_1 = reward_model(torch.randn(1, 768)) # ダミー入力
reward_2 = reward_model(torch.randn(1, 768))
loss = -torch.log(torch.sigmoid(reward_1 - reward_2) * feedback["output_1"]
+ torch.sigmoid(reward_2 - reward_1) * feedback["output_2"])
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss.item()
# 学習の実行
for epoch in range(10):
loss = train_reward_model(output_1, output_2, feedback)
print(f"Epoch {epoch}, Loss: {loss}")
ステップ4: ポリシーの最適化
報酬モデルを基にポリシーを更新します。
報酬モデルを利用して、モデルが「パリ」という正解に近い出力を生成しやすいようにポリシーを最適化しました。
def update_policy():
reward = reward_model(torch.randn(1, 768)) # ダミー報酬
loss = -reward.mean() # 報酬を最大化
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss.item()
# ポリシーの更新
for step in range(10):
policy_loss = update_policy()
print(f"Step {step}, Policy Loss: {policy_loss}")
このプロセスを繰り返すことで、モデルは段階的に改善され、人間の意図を反映した出力を生成できるようになります。
ChatGPTの進化を支えたRHLF
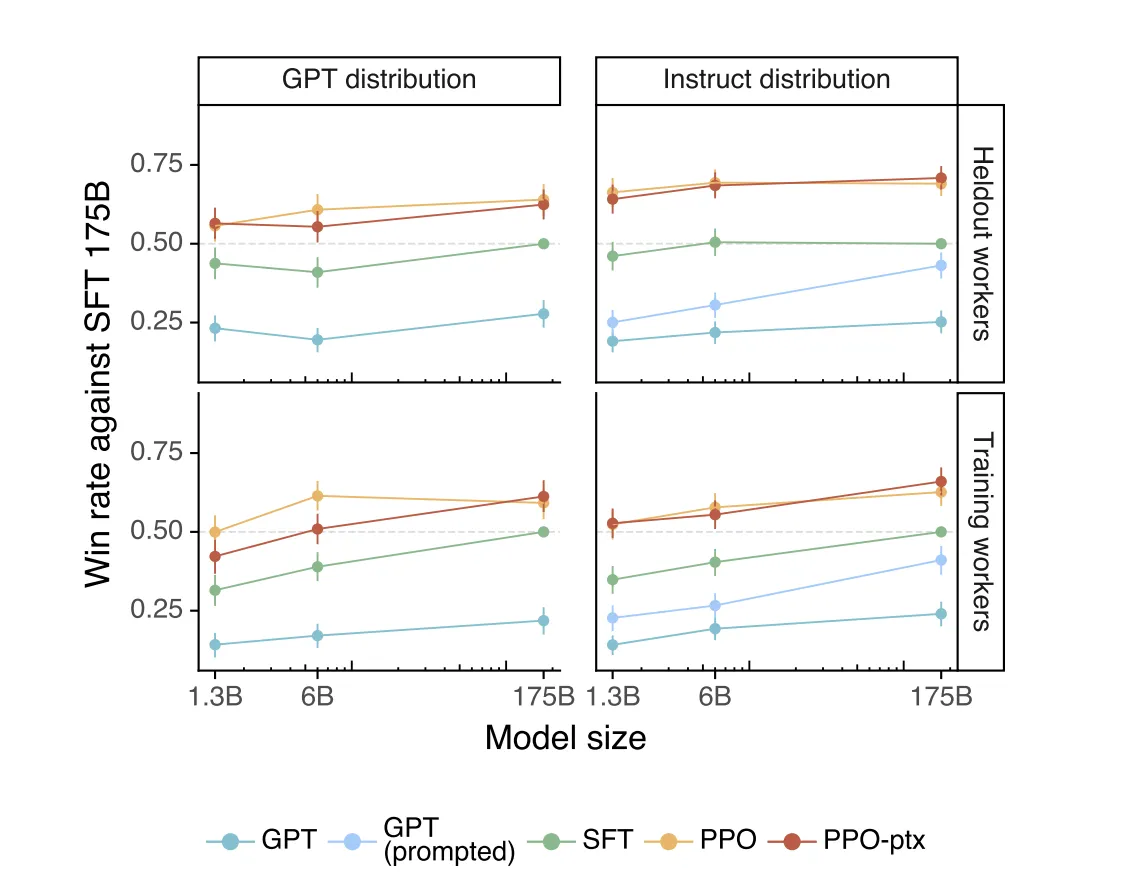
RHLFの効果を示した論文参考:Training language models to follow instructions
with human feedback
近年、ChatGPTシリーズが大きく進化を遂げた背景にも、RHLFの導入が大きく寄与しています。
RHLFを活用することで、回答の質が飛躍的にし、ChatGPT-1からChatGPT-3に至る進化の鍵となりました。
この図は、InstructGPTが人間のフィードバックを活用して他のモデルよりも優れた性能を発揮することを視覚的に示しています。また、PPO-ptxのような高度な学習手法が勝率を大幅に向上させることを証明しており、提案手法の有効性を強調しています。
o1でのRHLFの導入
OpenAI o1は、大規模な強化学習(RLHF)を利用して、チェーン・オブ・ソート(CoT)を用いた推論を可能にする訓練が行われました。
ここでは、人間のフィードバックを活用してモデルの学習を進める仕組みが基盤を作ったといえます。
-
初期段階の特徴:
o1では、基本的なペアワイズ比較が主に活用されました。
モデルは単純な回答精度だけでなく、「人間がどのような回答を望むか」という観点で調整されるようになりました。
その結果、これまで再現できなかった、文字情報から人間の意思を推測する行為が可能になったのです。 -
成果:
o1では、人間らしい応答や直感的なインタラクションが可能になり、従来のモデルよりも対話の自然さが向上しました。
o3での進化:RHLFの高度化
OpenAI o3では、RHLFの手法がさらに進化しました。o1で得られた基礎をもとに、新しい工夫が施されているともいわれています。
o1からo3への変化
-
回答の自然さと精度
o1では「自然で直感的な回答」が実現しましたが、o3ではさらに精度と深みのある回答が可能になり、複雑な質問にも適切に対応できるようになりました。 -
文脈理解の向上
o3では、前後の文脈を理解して回答を調整する能力が強化され、長い会話や複雑な文脈の中でも一貫性を保つことが可能になりました。 -
ユーザー満足度の飛躍的向上
OpenAIの調査によると、o3ではユーザーの満足度が大幅に向上しました。これは、RHLFを通じてモデルがユーザーの期待により正確に応えるようになったためです。
RHLFの今後の展望
最後に、RHLFが今後どのような進化を遂げ、新たな可能性を切り開くかを展望します。持続可能な評価体制づくりや多文化対応、さらなる効率化など、研究・実装両面での発展が期待されます。
持続可能なフィードバック収集体制
RHLFの成功には、長期的かつ効率的な人間フィードバック収集が不可欠です。ユーザー行動ログの活用や自動化ツールの導入で、評価負荷低減や改善サイクルの持続化が実現されるでしょう。
- ユーザー操作ログから自然な評価取得
- 半自動評価ツールで人的コスト軽減
- 改善サイクルを回し続けることで品質向上
RHLFと新たなモデル評価基準
RHLFは、状況変化やユーザーニーズ変化に柔軟に対応する新たなモデル評価基準づくりを促します。倫理性や文化的多様性にも配慮したモデルが世界中で活用可能となり、グローバルな満足度向上が望まれます。

まとめ
RHLF(Reinforcement Learning from Human Feedback)は、強化学習の枠組みに人間評価を取り入れることで、モデルをよりユーザー志向かつ価値観に適合した形へ導く手法です。
本記事では、RHLFの定義や既存手法との違い、適用事例、実装、を踏まえ、RHLFの強みについて概説しました。
RHLFにより、モデルは単なる「正解」以上の質を追求し、ユーザーや社会的文脈に沿った応答が可能となります。
しかし、人間評価コストや基準設定の難しさといった課題もあるため、運用設計や評価戦略が欠かせません。
今後は、評価プロセス効率化や多言語対応、倫理基準の確立など多面的な改善が進み、RHLFはより洗練された形でAI活用を後押しすることが必要になってきます。
ユーザー満足度や信頼性向上を目指す上で、RHLFは有力なアプローチとして成長し続けるでしょう。
これからのRHLFの活用、また、テクノロジー全般の動きも要チェックです!
参考文献
-
Christiano, P. F., et al. (2017): Deep reinforcement learning from human preferences
arXiv:1706.03741- 人間のフィードバックを利用した強化学習が、従来の教師あり学習を凌駕する性能を示す実験結果。
-
Ouyang, L., et al. (2022): Training language models to follow instructions with human feedback
arXiv:2203.02155- ChatGPTシリーズにおけるRHLFの具体的な適用例とその成果。





