この記事のポイント
 GPT-4.1はOpenAIが提供する3種類の最新APIモデル群。高性能かつ低コストを実現。
GPT-4.1はOpenAIが提供する3種類の最新APIモデル群。高性能かつ低コストを実現。- 従来より大幅に向上したコーディング能力と指示追従性。複雑なタスクでも高精度に対応。
- 最大100万トークンの長文処理能力。長大な文書からの情報抽出も高い精度で実現。
- 法務、財務分析、コードレビューなど実ビジネスでの活用事例と効果を多数確認。
- 低価格化とキャッシュ割引75%など効率的な料金体系。コスト効率の高いAI開発が可能に。

Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
OpenAIが発表した最新APIモデルファミリーは、私たちの日常生活や業務に大きな変化をもたらそうとしています。もはや単なる技術的な進歩にとどまらず、GPT-4.1は私たちの生活を根本から変える存在として、その重要性が広く認識されるようになりました。
しかし、「GPT-4.1とは具体的に何を指すのか?」「私たちの業務にどのように役立つのか?」と疑問に思う方も多いのではないでしょうか。
本記事では、GPT-4.1ファミリーの基本概念から、実際の応用例、そして性能や価格に至るまで、幅広く解説していきます。OpenAIの最新モデルが私たちの業務や開発に与える影響を理解するために、ぜひ最後までお読みください。
GPT-4.1とは? OpenAIの最新APIモデルファミリー【チャットGPTモデル】
OpenAIは、APIを通じて利用可能な新しいGPTモデルファミリーとしてGPT-4.1、GPT-4.1 mini、そして同社初のナノモデルとなるGPT-4.1 nanoを発表しました。
これらのモデルは、従来の主力モデルであるGPT-4oおよびGPT-4o miniと比較して、特にコーディング能力と指示追従性において大幅な性能向上を遂げています。
また、最大100万トークンという広大なコンテキストウィンドウをサポートし、長文に対する読解力も向上しています。知識カットオフは2024年6月に更新されました。
GPT-4.5 Previewの廃止
今回発表されたGPT-4.1ファミリーは、APIを通じてのみ提供されます。ChatGPTにおいては、GPT-4.1の改善点の多くが最新版のGPT-4oに段階的に組み込まれており、今後も反映される予定です。
GPT-4.1がGPT-4.5 Previewと同等以上の性能を低コスト・低レイテンシで提供できるため、GPT-4.5 Previewは2025年7月14日をもってAPIでの提供を終了します。(開発者には3ヶ月の移行期間が設けられます。)
GPT-4.5から得られた知見や、評価された創造性、文章品質、ユーモア、ニュアンスなどは将来のAPIモデルに引き継がれる予定です。
また、GPT-4.1のAPIはすでに以下のサービスでも利用可能です。
API発行の方法は以下の記事をご確認ください。
【関連記事】
ChatGPT API(OpenAI API)とは?使い方や料金体系、活用事例を解説!

利用可能のアナウンス 参考:Microsoft
Azure AI Foudryでの利用方法
AzureAI Foundryでのモデル選択画面
Azureにアクセスしてモデルカタログを開くと、GPT-4.1が選択できます。
【関連記事】
Azure OpenAI Serviceとは?その機能や料金、活用方法を解説
GitHub Copilotでの利用方法
GitHub Copilotでの4.1活用
vscodeかいずれかのIDEを立ち上げるもしくは、GitHub CopilotのWebアプリを開くと、GPT-4.1が利用可能になります。
モデル選択のドロップダウンメニューから「GPT-4.1」を選択することで、GPT-4.1が利用できます。
【関連記事】
Github Copilotとは?使い方や料金、VScodeへの導入方法を解説
GPT-4.1ファミリーの位置付け
GPT-4.1ファミリーは、知能(Intelligence: Multilingual MMLUで測定)と応答速度(Latency)のバランスにおいて、それぞれ特徴的なポジショニングを示しています。
GPT-4.1 nanoは最も高速、GPT-4.1は最も高性能、GPT-4.1 miniはその中間に位置します。
%E3%81%A8%E3%83%AC%E3%82%A4%E3%83%86%E3%83%B3%E3%82%B7%E3%81%AE%E9%96%A2%E4%BF%82.webp)
GPT-4.1ファミリーの知能(Multilingual MMLU)とレイテンシの関係 (出典: OpenAI)
GPT-4.1
ファミリーのフラッグシップモデルです。業界標準の測定基準において、特にコーディング、指示追従性、長文読解で優れた性能を発揮します。
GPT-4.1 mini
小型モデルの性能を大きく飛躍させたモデルです。GPT-4oに匹敵または凌駕する知能評価を持ちながら、レイテンシをほぼ半減させ、コストを83%削減しています。
GPT-4.1 nano
OpenAI史上最速かつ最も安価なモデルです。100万トークンのコンテキストウィンドウを持ち、MMLUやGPQAなどのベンチマークでGPT-4o miniをも上回るスコアを記録しています。
分類や自動補完など、低レイテンシが重要なタスクに最適です。
GPT-4.1ファミリーのパフォーマンス
GPT-4.1ファミリーは、様々なベンチマークにおいてGPT-4oを上回る性能を示しており、特にコーディング、指示追従性、長文コンテキスト処理、画像理解において顕著な改善 が見られます。
コーディング性能の大幅向上
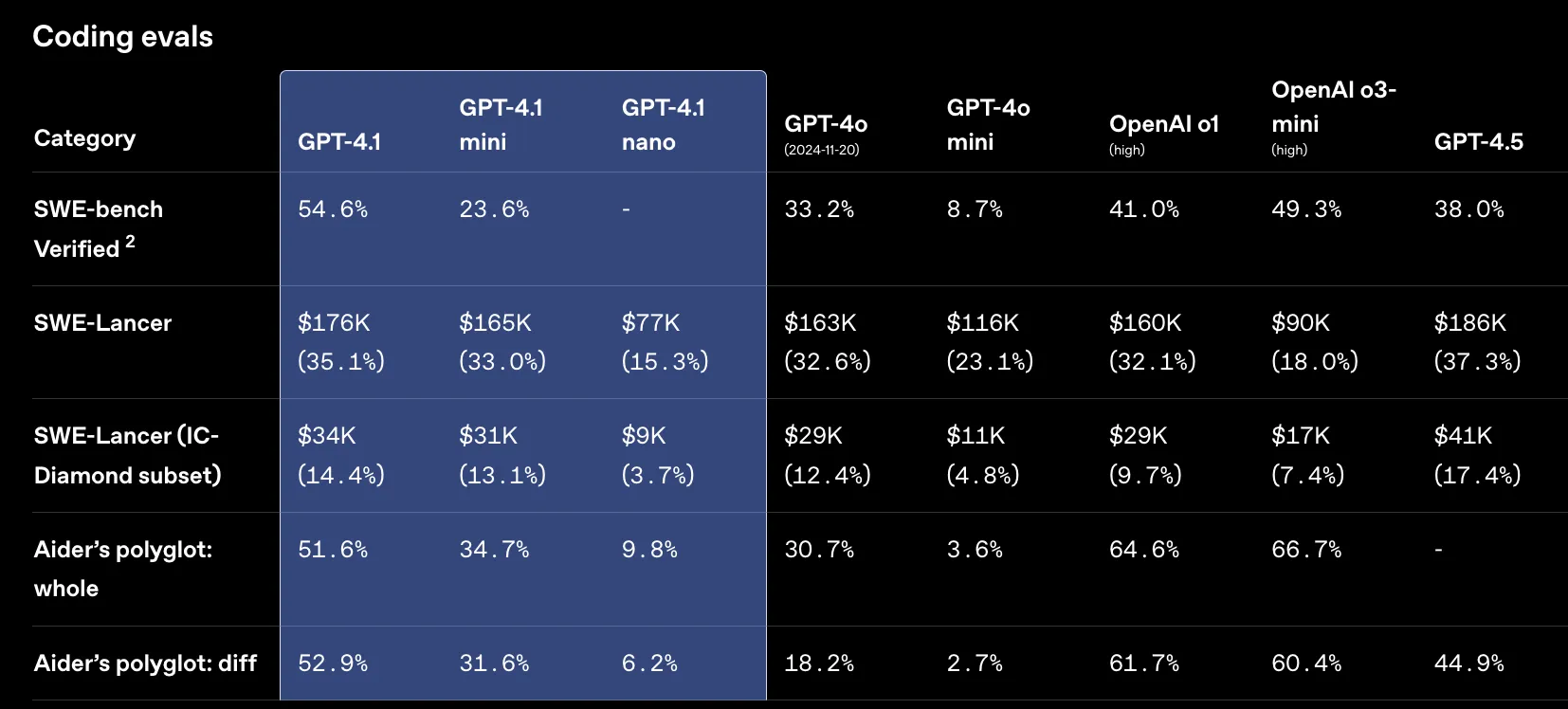
GPT-4.1はコーディングタスクでGPT-4oを大幅に上回ります。
特に、実世界のソフトウェアエンジニアリング能力を測るSWE-bench Verifiedでは、GPT-4.1が54.6%のタスク完了率を達成し、GPT-4o (33.2%)から21.4%の大幅な向上を見せています。
コーディング性能のベンチマーク
また、多言語コーディングと差分形式での変更生成能力を測るAider's polyglot diff benchmarkでは、diff形式で 52.9% を達成し、GPT-4o (18.2%) の2倍以上となりました。
フロントエンドコーディング能力も向上し、不要な編集も減少しています。
指示追従性の向上
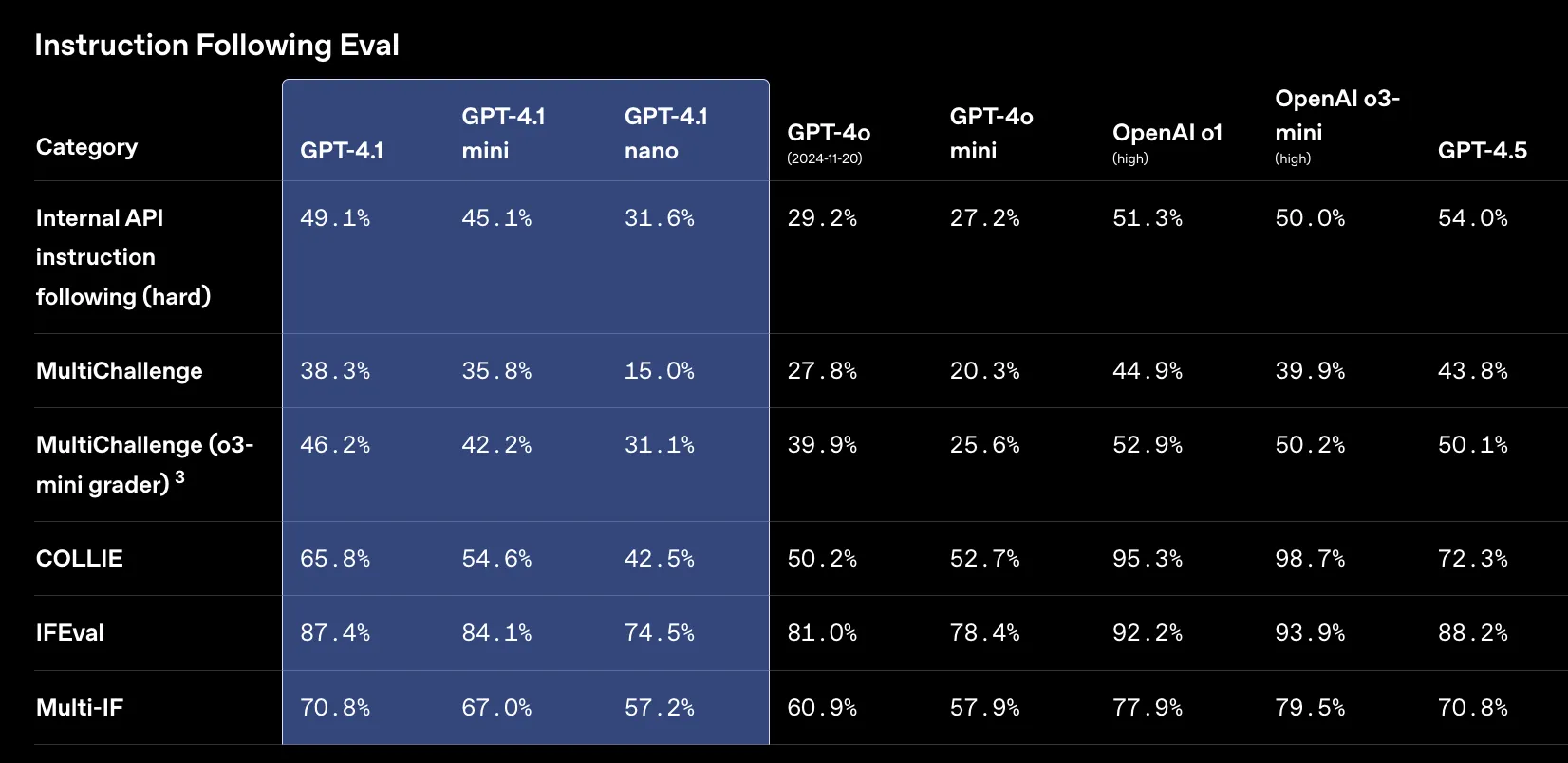
GPT-4.1は複雑な指示に対する追従性が向上しました。
以下の表の通り、OpenAI内部評価 (Hard subset)では、GPT-4.1は49.1%の精度を達成し、GPT-4o (29.2%) から大幅に改善。
複数ターン対話能力を測るMultiChallengeや、具体的な指示への準拠度を測るIFEvalといった公開ベンチマークでもGPT-4oを上回っています。
指示追従性のベンチマーク
長文コンテキスト処理能力の進化 (最大100万トークン)
GPT-4.1ファミリーの全モデルは、GPT-4oの128,000トークンから大幅に増加した最大100万トークンのコンテキストを処理可能です。
Needle in a Haystack
長大なテキストの中に隠された特定の情報(Needle)を見つけ出す能力を評価します。
GPT-4.1、mini、nanoはいずれも100万トークンのコンテキスト長全体にわたって、Needleの位置に関わらず一貫して正確に情報を抽出できました。
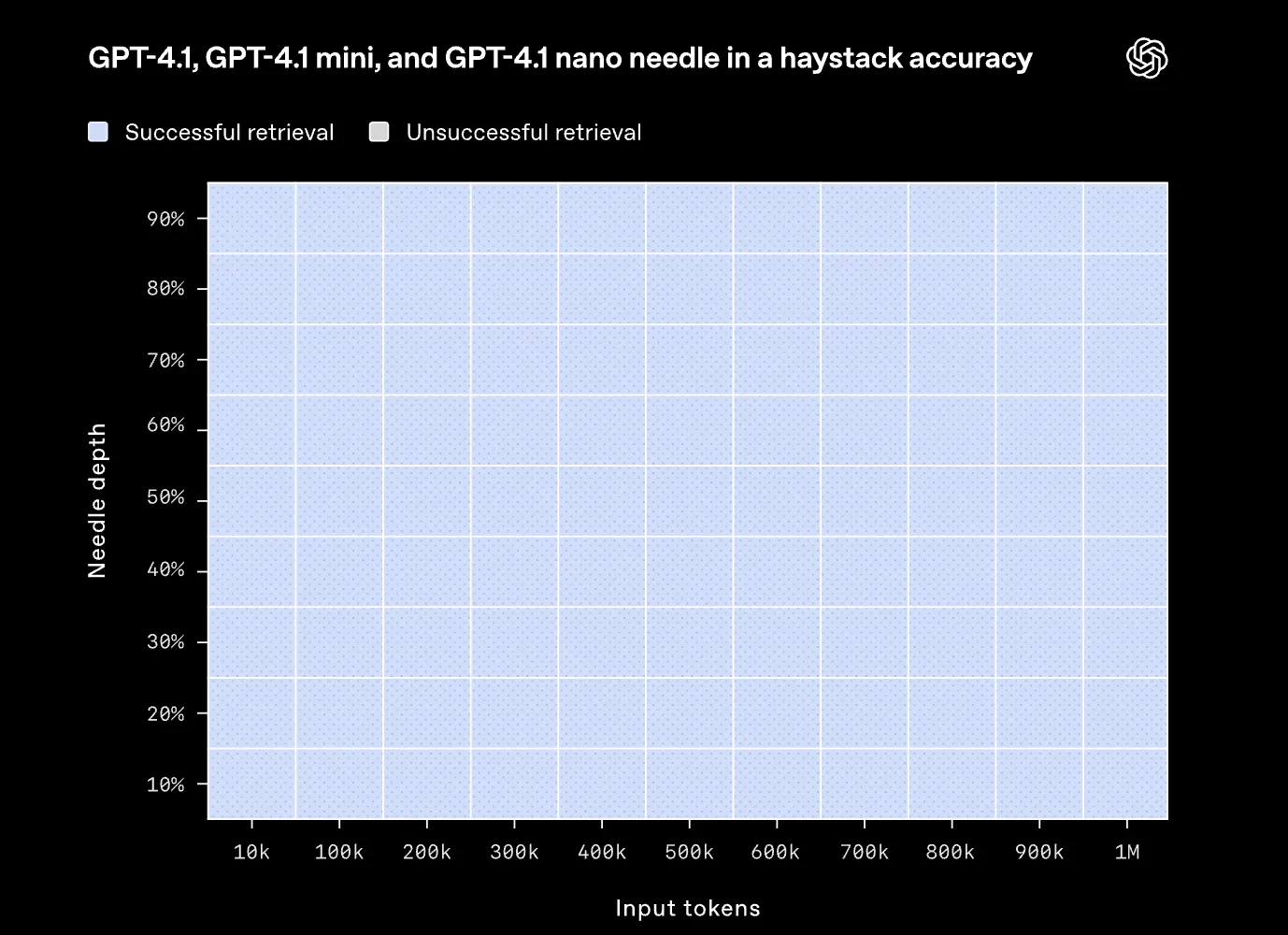
Needle in a Haystackテスト結果 (出典: OpenAI)
OpenAI-MRCR (Multi-Round Coreference):
コンテキスト内に隠された複数の類似した情報(Needle)を区別し、特定の一つを正確に取得する能力をテストする新しい評価セットです(データセットはこちら)。
GPT-4.1はGPT-4oを上回り、100万トークンまで高い性能を維持します。
以下のグラフは2つのNeedleを用いた場合の結果です。
%20%E3%82%B0%E3%83%A9%E3%83%95.webp)
OpenAI-MRCR (2 needle) 精度比較 (出典: OpenAI)
GPT-4.1(青線)は、比較対象のモデル(GPT-4o:緑、GPT-4.1 mini:オレンジ等)よりも一貫して高い精度を示しています。
特に、入力トークン数が増加しても精度の低下が比較的緩やかであり、128kトークン付近で57%程度、1Mトークン(1024k)でも46%程度の精度を維持しており、長文コンテキストにおける情報検索・識別能力の高さがうかがえます。
Graphwalks:
複数箇所にわたる論理的な繋がり(マルチホップ推論)を評価するデータセットです(データセットはこちら)。
BFSタスク(<128k)で、GPT-4.1は 61.7% の精度を達成し、GPT-4o (41.7%) を大きく上回りました。
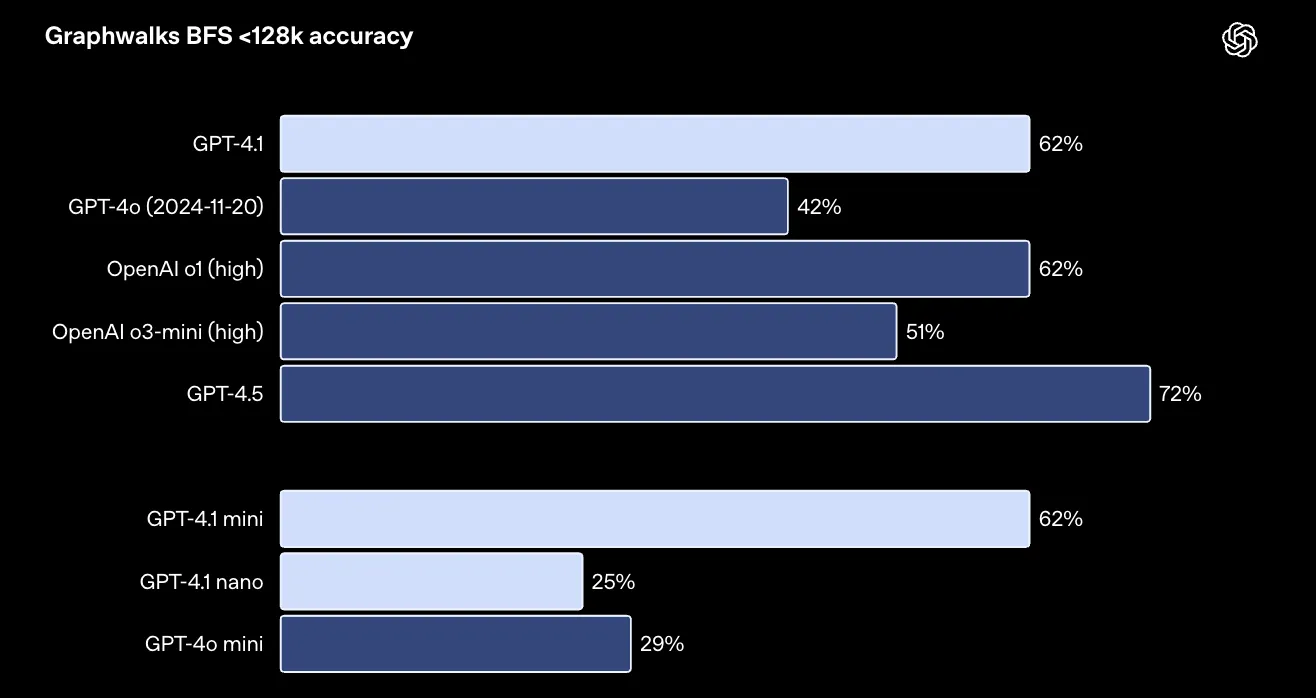
Graphwalksのベンチマーク結果
Vision (画像理解) 能力
静止画像の理解能力も強化されています。
MMMU(大学レベルのマルチモーダルタスク)、MathVista(視覚的な数学問題)、CharXiv-R(科学論文のグラフに関する推論)などのベンチマークで高い性能を示しており、特にGPT-4.1 miniはしばしばGPT-4oを上回ります。
%20%E8%83%BD%E5%8A%9B%E3%81%AE%E3%83%99%E3%83%B3%E3%83%81%E3%83%9E%E3%83%BC%E3%82%AF.webp)
Vision (画像理解) 能力のベンチマーク
長文コンテキスト処理能力は、長いビデオの処理 のようなマルチモーダルなユースケースにおいても重要です。
Video-MME (long w/o subs)ベンチマークでは、モデルは字幕なしの30~60分の長尺動画に基づいて多肢選択式の質問に答えます。
このテストにおいて、GPT-4.1は72.0% というスコアを達成し、GPT-4oの65.3%から大幅に向上させ、この分野で最先端のパフォーマンスを確立しました。

ビデオ理解のスコア比較
エージェント開発への活用
GPT-4.1の指示追従性の向上と長文読解能力は、ユーザーに代わってタスクを自律的に達成するAIエージェント(自律型AIシステム) の開発において、その能力を大幅に向上させます。
特に、OpenAIが提供する新しいResponses APIと組み合わせることで、開発者はより強力で信頼性の高いエージェントを効率的に構築できるようになります。
GPT-4.1とResponses APIによる高度なエージェント開発
GPT-4.1の高い指示追従性と長文処理能力は、Responses APIの機能と相乗効果を生み出します。
- 複雑なタスクの実行:
複数のステップやツール連携が必要なタスク(例: Webで情報を検索し、その結果をファイルにまとめ、特定の形式で出力する)を、より少ないコード量と高い信頼性で実現できます。
- インタラクティブな応答:
モデルが思考プロセス(Chain of Thought)やツール使用の途中結果をストリーミングで返し、ユーザーが必要に応じて介入したり確認したりするような、よりインタラクティブなエージェントの構築が容易になります。
- 信頼性の向上:
GPT-4.1が指示やコンテキストをより正確に把握し、Responses APIが状態管理とツール連携を担うことで、エージェント全体の動作安定性と信頼性が向上します。
これにより、以下のような高度なタスクを、より少ない開発者の手間(手動での調整やオーケストレーション)で実現できる可能性が広がります。
- 実世界のソフトウェアエンジニアリング: コードリポジトリの探索、Issueに基づくコード修正、テスト実行などを自動化。
- 大規模文書からのインサイト抽出: 複数の長文ドキュメントを横断的に読み解き、複雑な質問に回答したり、要約を作成したりする。
- 顧客リクエスト解決: 過去の対話履歴や製品マニュアル(ファイル検索)、最新のFAQ情報(Web検索)などを参照しながら、より自律的に顧客の問題を解決する。
GPT-4.1とResponses APIは、AIエージェント開発のハードルを下げ、より実用的でインテリジェントなアプリケーションの実現を加速させる重要な要素となるでしょう。
GPT-4.1ファミリーの料金
推論システムの効率改善により、GPT-4.1シリーズはより低価格で提供されます。
| モデル | 入力 (1Mトークンあたり) | キャッシュ入力 (1Mトークンあたり) | 出力 (1Mトークンあたり) | ブレンド価格* (1Mトークンあたり) |
|---|---|---|---|---|
| gpt-4.1 | $2.00 | $0.50 | $8.00 | $1.84 |
| gpt-4.1-mini | $0.40 | $0.10 | $1.60 | $0.42 |
| gpt-4.1-nano | $0.10 | $0.025 | $0.40 | $0.12 |
*ブレンド価格は、一般的な入力/出力比率とキャッシュヒット率に基づいた参考値です。
コスト効率のポイント:
- 低価格化: GPT-4.1は中央値クエリでGPT-4oより26%安価。GPT-4.1 nanoは最安価モデル。
- キャッシュ割引向上: 同じコンテキストを繰り返し渡す場合の**プロンプトキャッシュ割引が75%**に (従来50%)。
- 長文追加料金なし: 最大100万トークン利用に追加料金なし。
- Batch API割引: Batch API 利用でさらに50%割引。
GPT-4.1ファミリーの使い方
GPT-4.1、GPT-4.1 mini、GPT-4.1 nanoは現在、すべての開発者がAPI経由で利用可能です。
1. API利用
OpenAI APIを通じてアプリケーションに組み込めます。
- モデルID: 「gpt-4.1」, 「gpt-4.1-mini」,「gpt-4.1-nano」
2. Playground
Playground でコードを書かずに試用できます。モデルセレクターから選択してください。
現実世界での活用事例
GPT-4.1の性能向上は、ベンチマークスコアだけでなく、アルファテスターによる実際のアプリケーション利用を通じても確認されています。以下にいくつかの事例を紹介します。
コーディング分野
まずは開発分野での活用事例です。
Windsurf
成果:
内部コーディングベンチマークでGPT-4o比60%高いスコアを記録。これはコード変更が初回レビューで承認される頻度と強く相関。
具体的な改善点:
ユーザーからは、ツールの呼び出し効率が30%向上し、不要な編集の繰り返しや非効率なコード読み取りが約50%減少したとの声が上がっています。
これにより、エンジニアリングチームのイテレーションが加速し、ワークフローがよりスムーズになりました。
Qodo
成果:
GitHubプルリクエストからのコードレビュー生成テスト(200件の実例)において、GPT-4.1が55%のケースでより良い提案を実施。
具体的な改善点:
特に、提案すべきでない場合を見極める**「精度」と、必要に応じて徹底的な分析を行う「網羅性」の両面で優れており、かつ真に重要な問題に焦点を当て続ける**点が評価されました。
指示追従分野
指示に対しての追従性が向上したことは、特に複雑なタスクや長文コンテキストを扱う分野での活用が期待されます。
Blue J:
成果:
最も困難な実世界の税務シナリオに関する内部ベンチマークで、GPT-4o比53%高い精度を達成。
具体的な改善点:
この精度の飛躍的向上は、GPT-4.1の複雑な規制に対する理解力と、長文コンテキストにわたる微妙な指示への追従能力の向上を示しています。
ユーザーにとっては、より速く信頼性の高い税務調査が可能になり、高付加価値なアドバイザリー業務により多くの時間を割けるようになります。
Hex:
成果:
最も難しいSQL評価セットにおいて、GPT-4o比でほぼ2倍の性能改善。
具体的な改善点:
大規模で曖昧なデータベーススキーマから正しいテーブルを選択する信頼性が大幅に向上しました。これは、プロンプト調整だけでは改善が難しい上流の判断であり、SQL全体の精度に直結します。
結果として、手動でのデバッグ作業が測定可能なレベルで削減され、本番レベルのワークフローへの移行が加速しました。
長文コンテキスト分野
長い入出力に耐える事例としては、以下のようなものがあります。
Thomson Reuters
成果:
法律専門家向けAIアシスタントCoCounselを用いた複数文書レビューの内部ベンチマークで、GPT-4o比17%の精度向上。
具体的な改善点:
複数の長文法的文書を扱う複雑なワークフローにおいて、ソース間の文脈を維持する能力や、矛盾する条項・補足情報といった文書間の微妙な関係性を正確に特定する能力の信頼性が特に高いと評価されました。
これは法的分析と意思決定に不可欠な能力です。
Carlyle
成果:
複数の長文文書(PDF、Excel等)から詳細な財務データを抽出するタスクにおいて、データ密度の高い大規模文書からの情報検索で50%優れたパフォーマンスを発揮。
具体的な改善点:
他のモデルでは課題となっていたNeedle-in-a-Haystack検索、Lost-in-the-middleエラー(長文の中間部分の情報を見失う問題)、文書間のマルチホップ推論といった主要な制限を克服した最初のモデルであると評価されました。
まとめ
OpenAIの最新APIモデルファミリー、GPT-4.1、GPT-4.1 mini、GPT-4.1 nanoは、コーディング、指示追従性、長文コンテキスト処理 (最大1Mトークン)、Vision能力において大幅な進化を遂げました。
これにより、開発者はより高性能でコスト効率の高いAIシステムや、これまで以上に信頼性の高いエージェントアプリケーションを構築できます。ソフトウェア開発、大規模データ分析、顧客対応など、幅広い分野での活用が期待されます。










