この記事のポイント
 ChatGPT-4oの画像生成は、DALL·Eベースの画像生成が統合され、画像の編集も可能に
ChatGPT-4oの画像生成は、DALL·Eベースの画像生成が統合され、画像の編集も可能に- 無料プランと有料プランでは使える回数や機能に差がある
- 画像生成のコツは「構造化されたプロンプト」と「段階的な修正」
- ジブリ風イラストやアニメ調など、幅広いデザインに対応
- 広告画像、資料作成、SNS投稿など、ビジネス利用にも最適

Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
2025年に入り、ChatGPT 4oはついに“画像も描ける”ようになりました。
では、今までの画像生成と何が違うのでしょうか?最新のGPT-4oでは、テキストを入力するだけで高品質な画像を自動生成。手軽なのに驚くほどクオリティが高く、ビジネスやクリエイティブの現場でも活用が始まっています。
本記事では、ChatGPT 4oの画像生成機能について、使い方・プロンプト例・制限事項・活用シーン・他AIとの違いまで、実例を交えてわかりやすく解説します。これからAIで画像をつくる人の必読ガイドです。
AI総合研究所では企業のAI導入をサポートしています。お気軽にご相談ください。
目次
ChatGPT 4o(GPT-4o)の画像生成とは?【2025年最新アップデート対応】
ChatGPT 画像生成のプロンプト例と作成のコツ【完全保存版】
ChatGPTの画像生成は商用利用できる?【制限と注意点まとめ】
ChatGPT 4oの画像生成の活用事例【業務・SNS・プレゼンに】
ChatGPT 4o(GPT-4o)の画像生成とは?【2025年最新アップデート対応】

GPT-4oで生成した画像
2025年3月、OpenAIは最新の基盤モデル「GPT-4o(オムニ)」に画像生成機能を統合し、ChatGPT上で誰でも画像を生成できるようになりました。
従来のChatGPTでは、DALL·E 3をバックエンドとして使用しながらも、画像生成はやや“別機能”として扱われており、操作も限定的でした。
今回のアップデートでは、ユーザーがテキストを入力すれば、ChatGPTがその文脈を理解し、自然な流れで画像を生成・提案することが可能 になりました。
また、これまで画像の修正はできず“一発勝負”でしたが、GPT-4oでは対話を通じて「もう少し明るく」「背景を変えて」などの指示を出しながら、段階的に画像を編集できるように なっています。
この魅力的になった画像生成について詳しくみていきましょう!
ChatGPTの料金や4oモデルの使い方などは以下の記事をご参照ください。
ChatGPT-4o(GPT-4o)とは?使い方や料金、GPT-4との違いを解説! | AI総合研究所
ChatGPT-4o(GPT-4o)の使い方や料金体系、画像生成機能について解説。GPT-4oを無料で使う方法や切り替え手順、アプリ版の使い方などをわかりやすく紹介します。
https://www.ai-souken.com/article/summary-of-chatgpt-updates

ChatGPT-4oの画像生成機能の使い方
ここからは実際の使い方をご紹介します。
ChatGPT 4oの画像生成機能は、特別な設定やツールを使わず、ChatGPTの画面上だけで簡単に使えます。
ステップ①:ChatGPT(GPT-4o)にアクセス
まずは、ChatGPT公式サイトにアクセスし、
無料プランでも順次提供が進んでいますが、画像生成機能はPlusユーザー(月額20ドル)以上で安定して使える状態です。
ステップ②:テキストで画像をリクエスト
GPT-4oが選択されていることを確認します。
チャットに自然な文章で画像の要望を書くだけでOKです。

モデルの選択と画像生成
例
- 「桜の木の下でお花見している猫のイラストを描いてください」
- 「4oの画像生成のご紹介」という画像を生成して等
入力が完了すると、ChatGPTが画像を生成し、チャット画面にプレビューを表示してくれます。だいたい1-5分ほどかかります。
ステップ③:マルチターンで画像を調整
生成された画像に対して、「もう少し明るくして」「背景を夜に変えて」「人物の服を青に変えて」などと伝えることで、AIが画像を再生成しながら微調整してくれます。これは従来のAI画像ツールにはなかった大きな進化ポイントです。

右上にある選択ボタン

修正部分を実際に選択した画像
ChatGPT 画像生成のプロンプト例と作成のコツ【完全保存版】
ChatGPT 4oの画像生成では、プロンプト(指示文)の内容が画像のクオリティに直結します。とはいえ難しいルールはありません。
このセクションでは、効果的なプロンプトの書き方と実用的な例を紹介します。
1. 構造を意識して書く 「画像を生成して」と含める
「誰が」「どこで」「何をしている」を意識すると、イメージが正確に伝わります。
例:
「赤いマフラーを巻いた柴犬が、雪が降る公園でジャンプしている画像を生成して」
2. スタイルや雰囲気も指定する
「イラスト風」「リアル調」「油絵」「図解っぽく」など、アートスタイルや用途を明確にすると出力が安定します。
例:
「フラットデザイン風のビジネス会議シーン(資料に使いたい)」
3. ネガティブ指示も使える
「〜は含めないで」「背景はシンプルに」など、避けたい要素を明確にすることで意図しない画像生成を防げます。
例:
「女性のイラスト、背景は白。文字や看板などの文字情報は含めない」
4.画像で指示もできる

参考画像を提示
上記の画像のように参考画像を入れることで
その画像をもとに生成を行ってくれます。言葉で伝えづらい時に重宝するでしょう。
5.得意不得意があることを知る
GPT-4oの画像生成は以前よりバイアスが少なくなっていますが以前として人種・性別・肌の色など得意な生成物には偏りがあります。
| 分類 | 現状の傾向 | 残る課題・制限 |
|---|---|---|
| 性別 | DALL·E 3より女性の登場が増えた | それでも男性が多く登場する傾向が残っている(特に「医者」など職業系) |
| 人種 | 白人以外の人種も描かれるようになった | 白人の登場が依然として多めで、特定の人種は頻度が少ない(例:東南アジア人など) |
| 肌の色 | 明るい肌色に偏らず、中間・暗いトーンも表現される | それでも 「非常に暗い肌」の出現は少なく、完全な均等ではない |
| プロンプト未指定時の振る舞い | 属性未指定でも、比較的多様な出力が得られる | 明確な属性を指定しないと「よくあるパターン」に寄りやすい傾向が残る |
| 歴史的な文脈 | 歴史的・文化的に正確な描写ができる精度が向上 | プロンプトが曖昧だと、リアルとは異なる表現が出る場合がある |
| カスタマイズ性 | ユーザーが属性を指定することである程度調整可能 | 初期設定では偏りが出やすく、ユーザーが意識的に制御する必要がある |
より詳細が知りたい場合は公式のシステムカードをご参照ください。
1回で完成しなくてOK!
ChatGPT 4oの強みは会話しながら画像をブラッシュアップできること。最初はざっくり指示して、あとから「もう少し明るく」「帽子を追加して」といった修正を繰り返すことで、理想の画像に近づけられます。ぜひ試してみてください。
ChatGPT4oの画像生成機能の料金
このように魅力的な画像生成ですが、ChatGPTのどのプランで利用できるのでしょうか。
ChatGPTのプランは以下の通りです。
| プラン名 | 月額料金 | 画像生成 | 利用制限・補足 |
|---|---|---|---|
| 無料プラン | 無料 | ⚠️ 近々、利用可能になる(順次提供中) | GPT-4oモデル利用可。画像生成は人気により遅延中(一部ユーザーから順次利用可能に) |
| Plusプラン | $20 / 月(約3,000円) | ✅ 利用可能 | GPT-4o完全対応。画像生成は使用量制限あり(詳細非公開) |
| Teamプラン | $25 / ユーザー / 月(年契約) | ✅ 利用可能 | コラボ向け。画像生成は使用制限あり、チーム共有が可能 |
| Enterpriseプラン | 要問い合わせ | ✅ 利用可能 | 大規模向けプラン。SLA・高度な管理機能・画像生成含むすべての機能が利用可能 |
- 無料ユーザーもGPT-4oモデル+画像生成機能にアクセスできるようになりますが、2025年3月時点では「順次展開中」であり、すぐには使えない可能性があります。
- Plusプラン以上では、安定して画像生成機能が利用可能ですが、1日の回数制限などは明示されていません(OpenAIのリソース状況により動的に変動する仕様)。
- APIも数週間以内に公開予定。
- 商用利用は基本的に可能ですが、生成画像の内容が利用規約に違反していないかは要確認です。
※最新情報は公式ページをご確認ください。
ChatGPTの画像生成は商用利用できる?【制限と注意点まとめ】
画像生成AIをビジネスやコンテンツ制作に活用する際に気になるのが、「商用利用できるのか?」「著作権はどうなっているのか?」といった点です。
ここでは、ChatGPT 4oの画像生成に関する利用制限や注意点をまとめました。
商用利用は基本的に可能(ただし条件あり)
OpenAIの利用規約によると、ChatGPTで生成したコンテンツ(画像含む)は、商用利用が可能です。
つまり、Webサイト、広告、SNS投稿、プレゼン資料、印刷物などに活用することができます。
ただし以下の条件に注意が必要です:
- 不正利用・誤情報・名誉毀損などは禁止
- 著作権や商標権を侵害しない内容であること
- ポリシー違反となるスタイル模倣はNG
禁止されている画像生成の例
OpenAIは、以下のような画像の生成を禁止または制限しています:
- 著名人・実在人物に酷似した画像の生成
- ジブリ風・ディズニー風など特定のスタイルを模倣するプロンプト
- 暴力・ヘイト・差別的表現を含む画像
- 選挙・政治的な偽情報に関わる画像
これらに違反すると、アカウント停止や生成制限がかかることがありますので注意しましょう。
ChatGPT 4oの画像生成の活用事例【業務・SNS・プレゼンに】
では色々なアイデアで実際に生成していきましょう!
入力したプロンプトの下に、生成された画像を掲載します。
マーケティング資料・広告画像の作成
プロンプト
「爽やかな青春を思い出すような飲み物のSNS広告画像を作って」

マーケティング用に生成した画像
部分的な変更
プロンプト
「その画像を男性のアニメ画像にして」

男性画像への変換
同じ男性で教師にして
この男性のまま「研修教材用の同じイラストの教師の画像を複数画像生成して」

研修教材の生成画像
このように文字が切れることもあります。
生成画像を研修教材やEラーニングに活用 など
プロンプト
「研修教材用の同じイラストの教師の画像を複数画像生成して」

研修教材用の同じイラストの教師の画像
4コマ漫画
プロンプト
「4コマ漫画を生成して、戦いの話が良いな」

4コマ漫画
画像のgif化
プロンプト
「その画像をgif化して」
そうするとgifの動く画像が生成されます。

gifダウンロード画面
完全に実験的にやってみたけど、PDFの画像からグラフ作れてgifでビジュアル化まで出来た!
— あやみ|マーケティング (@ayami_marketing) May 23, 2024
GPT-4oのポテンシャルはもっと全然、引き出せるはず… pic.twitter.com/wb2GpJXkRe
活用方法は無限にありそうですね!
ChatGPT 画像生成とDiffusionモデルの違い【技術解説付き】
まず、ChatGPTの画像生成は従来と何が変化したのでしょうか?
2025年、画像生成AIは単なるテキスト→画像変換を超え、「Any-to-Any」マルチモーダル時代へ突入しています。

GPT-4oの画像生成が高性能な理由(技術的ポイント)
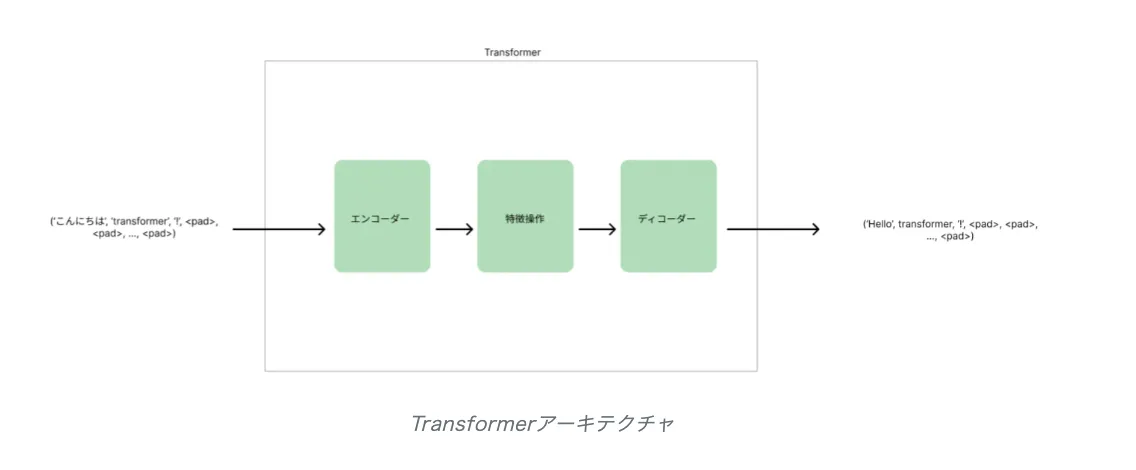
トランスフォーマーアーキテクチャ
GPT-4oが画像生成で非常に特徴的であったポイントは以下の通りです。
-
Transformerベースで完結した画像生成
GPT-4oでは、プロンプトから出力される画像もモデルが“意味的に理解して生成” しています。従来の画像生成ツールとは異なり、会話の文脈・話題を反映した画像が出力されるのが特徴です。トランスフォーマーについてよく知りたい方はこちらをご参照ください。 -
マルチターン画像生成(チャット中の逐次修正)
Stable DiffusionやMidjourneyでは「1プロンプト=1出力」が基本でしたが、GPT-4oはチャット形式で「背景を青に」「もう少し可愛く」など、自然言語によるインクリメンタル修正が可能です。 -
音声や画像との文脈共有
今後、画像や音声を入力に含めた上で新たな画像生成が可能に(画像+指示→別の画像など)になっています。Any-to-Anyワークフローという新たな形で活用が可能です。
Any-to-Anyとは何か?
Any-to-Anyのイメージ画像参考:arxiv
「Any-to-Any」とは、以下のような任意の入力・出力モダリティ間の変換ができるAIのことを指します。
- テキスト → 画像(生成)
- 画像 → テキスト(説明、OCR)
- 音声 → テキスト(Whisper)
- テキスト → 音声(TTS)
- 画像 → 音声、音声 → 画像(将来的応用)
これに対応しているのが、GPT-4oとGemini 2.0です。Stable Diffusionは画像生成に特化したSingle-to-Single構造(Text-to-Image) であり、モダリティの柔軟性では一歩遅れています。
各モデルのアーキテクチャとマルチモーダル性能比較
他のモデルとの違いは以下の通りです。
| 比較項目 | GPT-4o | Stable Diffusion | Google Gemini 2.0 |
|---|---|---|---|
| モデルタイプ | Transformer + マルチモーダル統合 | Diffusion(拡散モデル) | Mixture-of-Experts型 マルチモーダル |
| 入力対応 | テキスト・画像・音声 | テキスト | テキスト・画像・音声・動画 |
| 出力対応 | テキスト・画像・音声 | 画像のみ | テキスト中心(画像生成は限定的) |
| 対話インターフェース | 強力(Chatベース) | なし | Bard UI or API |
| リアルタイム性 | 高い(マルチターン対応) | 低め(1画像に数秒) | 高速(特に音声・動画処理) |
| 編集性(画像) | 会話で即時修正可 | 一部(img2img等) | 編集は限定的・開発中 |
| モダリティ統合性 | 非常に高い(Any-to-Any対応) | 低い(単一方向) | 高い(Any-to-Any対応) |
まとめ
ChatGPT 4oの画像生成機能について、使い方やプロンプトのコツ、商用利用の注意点、他モデルとの技術的違いまで紹介してきました。
特に「会話しながら画像を作れる」という新しい体験は、従来の画像生成AIとは一線を画します。
Gemini 2.0との比較からもわかる通り、GPT-4oはAny-to-Any時代の中核的存在です。
用途次第で業務にも創作にも活かせる、今もっとも実用的な画像生成AIのひとつと言えるでしょう。
AI総合研究所では、企業のAI導入を支援しています。研修や伴走支援もサポートしていますのでお気軽にご相談ください。






