この記事のポイント
 この記事はHugging Faceの新しい音声認識と話者識別技術について詳しく解説しています。
この記事はHugging Faceの新しい音声認識と話者識別技術について詳しく解説しています。- 自動音声認識(ASR)と話者識別の統合により、会話内容の高速かつ効率的なテキスト化が可能になっています。
- カスタマイズ可能な推論エンドポイントを用意しており、ユーザーは自身のニーズに合わせた設定ができます。
- Pythonコードを用いた具体的なセットアップ手順を示しており、実践的な理解の助けとなります。

監修者プロフィール
坂本 将磨
Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
自動音声認識(ASR)技術と話者識別の統合は、音声データの解析をますます進化させています。
ASRと異なる話者を特定する技術が統合されたことで、複雑な音声データも効果的に処理できるようになりました。WhisperモデルとPyannoteモデルの組み合わせにより、会議の記録やニュース放送など、誰がいつ何を話したかを自動で把握できます。
また、高速な推論を実現する「推測的デコード」を取り入れ、カスタム可能な推論エンドポイントも用意されており、ユーザーのニーズに応じた設定が可能です。
Hugging Faceがこれまで以上に革新的な音声認識ソリューションを提供する様子を、ぜひご覧ください。

Hugging FaceでASRと話者識別を統合する最新機能
Hugging Faceは、「自動音声認識(ASR)」と「話者識別技術」を統合した新しい機能を発表しました。
音声データからテキストへの変換を行うASRと、音声内の異なる話者を識別する機能が一つになったことで、より複雑な音声データの解析が可能になります。
この統合には、WhisperモデルとPyannoteという2つのモデルが活用されています。Whisperモデルは音声からテキストへ変換するためのもので、Pyannoteは話者の識別に特化したモデルです。
これらの技術を組み合わせることで、たとえば会議の記録やニュース放送の文字起こしといった場面で、誰がどのタイミングで何を言ったのかを自動で把握することができるようになります。
この機能は、初期予測には小型のモデルを使用し、その後に大型のモデルで検証を行う「推測的デコード」という手法を導入しており、推論速度の向上が期待されます。
カスタマイズ可能な推論エンドポイント
この新しいシステムは、モジュール式で設計されており、ASR、話者識別、推測的デコードといった各機能を組み合わせて利用することができます。
ユーザーは自身のニーズに合わせて、特定のモデル設定と環境変数を使用してシステムをカスタマイズし、デプロイすることが可能です。
また、アシスタントモデルを使用することで推測的デコードを実施し、話者分離用の話者識別モデルを含めることもできます。
ただし、パフォーマンスは使用条件によって変動する可能性があり、アシスト処理によってはオーディオファイルの処理時間が長くなることがあるとのことです。
ユーザーは推論パラメーターとしてタスクタイプ、バッチサイズ、話者数などを制御でき、Pythonコードを使用したセットアッププロセスも提供されています。
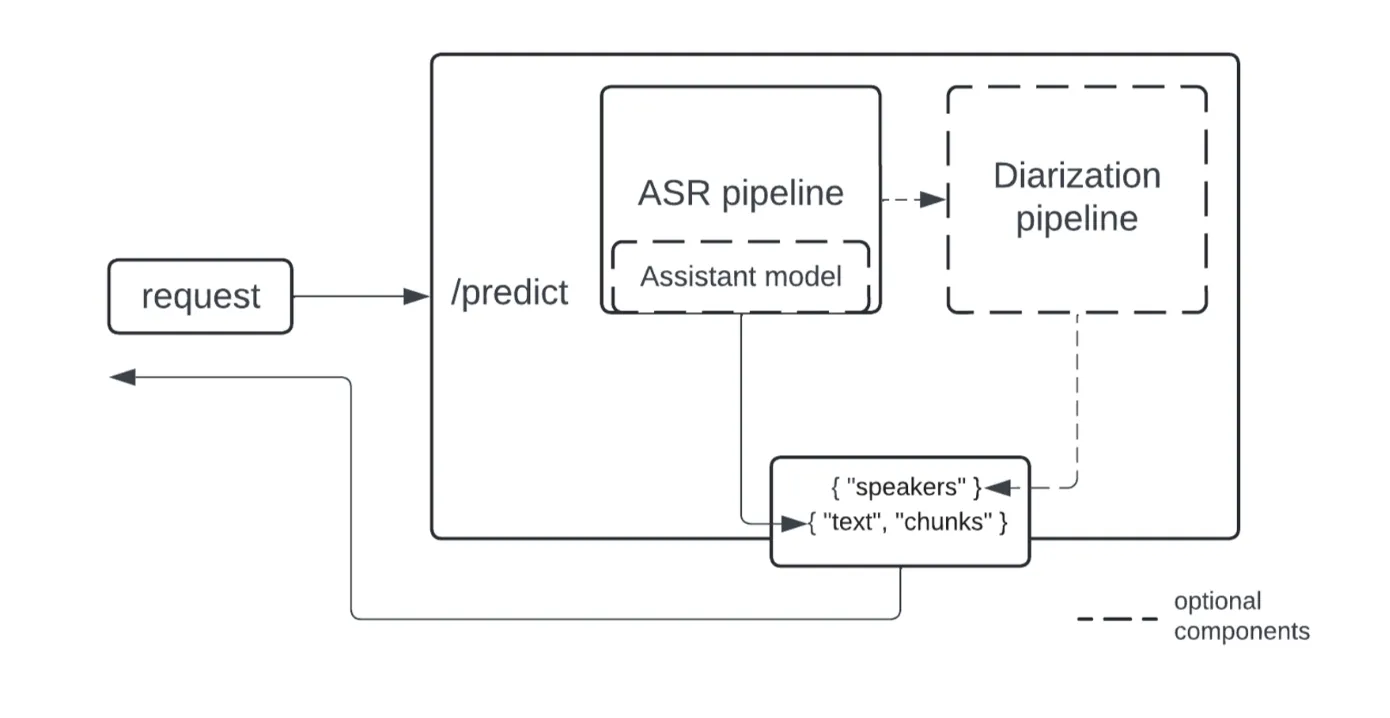
モジュール図
Pythonコード例と関連リソースの紹介
この記事では、Pythonコードを使用したセットアッププロセスが例として示されており、技術に詳しくない人でも理解しやすい内容となっています。
音声データを入力とし、ASRと話者識別を行うまでの手順が詳しく書かれており、実際に自分で試してみることができるようになっています。
さらに、記事内ではSanchit Gandhiによる「推測的デコード」に関する記事が参照され、Whisperモデルの推論速度を2倍に向上させるという主張がなされていることも言及されています。
これにより、ユーザーは自分のプロジェクトに適した情報をさらに探求することができます。関連リソースへのリンクも提供されており、興味を持った読者がさらに深く技術について学ぶことが可能です。
出典:Hugging Face