この記事のポイント
 GAN(敵対的生成ネットワーク)は生成モデルの革新技術で、高品質なデータ生成を実現
GAN(敵対的生成ネットワーク)は生成モデルの革新技術で、高品質なデータ生成を実現- 医療画像診断から創薬まで、幅広い産業分野での実用化が進展
- PyTorchやTensorFlowによる実装方法と学習のポイントを解説
- 技術的課題と倫理的問題、対策について詳しく説明
- 自動運転や創薬など、今後期待される革新的な応用分野を紹介

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AI技術の中でも特に注目されている「敵対的生成ネットワーク(GAN)」は、リアルなデータを生成する能力を持ち、多様な分野で革新的な応用が進んでいます。
本記事では、GANの基本的な概要、それがどのように機能するのか、また、訓練の過程で直面する課題について詳しく解説していきます。
さらに、ファッション、医療、エンターテインメントといった業界での実際の活用事例をご紹介し、将来の技術展望についても触れていきます。
医療画像の高精度化からデジタルアートの創出、さらにはセキュリティ向上に至るまで、GANがこれからのテクノロジー革新をどうリードしていくのか、その可能性を探ります。
GAN(敵対的生成ネットワーク)とは
「GANって何?」と思う方もいるかもしれません。GAN(敵対的生成ネットワーク)は、一見複雑そうですが、その仕組みを知ると「AIがこんな風に学ぶのか!」と驚きと共に理解が深まります。
この技術は、生成ネットワークと識別ネットワークがまるでゲームをするように競い合いながら学習する、画期的な仕組みを持っています。
GAN(敵対的生成ネットワーク)の定義と仕組み
**敵対的生成ネットワーク(GAN: Generative Adversarial Network)**は、2つのコンピュータープログラム(生成する役目と判別する役目)が競い合うことで、新しいデータを作る仕組みです。
生成するプログラム(生成ネットワーク)は、データを作ります。一方、判別するプログラム(識別ネットワーク)は、そのデータが本物か偽物かを見分けることを目的としています。
この2つが競争を繰り返すことで、生成するプログラムはより本物に近いデータを作れるようになり、偽物を作る技術がどんどん向上していくのです。
GANの仕組みを理解することで、「AIがどうやってリアルな画像や音声を作るのか?」という疑問が解消されます。
次は、GANが他の機械学習とどう違うのか、そしてその独自性についてさらに掘り下げていきましょう。
GAN(敵対的生成ネットワーク)の特徴と従来の機械学習との違い
これまでの機械学習は、主に分類や予測に特化してきましたが、GANはまったく違う視点からアプローチします。「新しいデータを生み出す」という革新的な特性が、GANを特別な存在にしています。
この違いを詳しく見ていきましょう。
GANは、教師なし学習に分類される技術です。これにより、学習データにラベル(正解)を付ける必要がなく、データそのものの特徴を直接学習することができます。
この点で、GANはラベル付きデータを使って正解を予測する教師あり学習を利用する従来の識別モデルとは大きく異なります。
さらに、GANは識別モデルのように「何かを判別する」ことを目的とするのではなく、データを新たに生成することに特化しています。
この生成能力によって、画像、音声、テキストなど多岐にわたる種類のデータを作り出すことが可能です。
特に、GANは高解像度の画像生成や、現実世界のデータに近い合成データの作成で大きな成果を上げています。
このように、GANは教師なし学習の一種でありながら、従来の手法では難しかったリアルなデータ生成を実現する技術として注目されています。
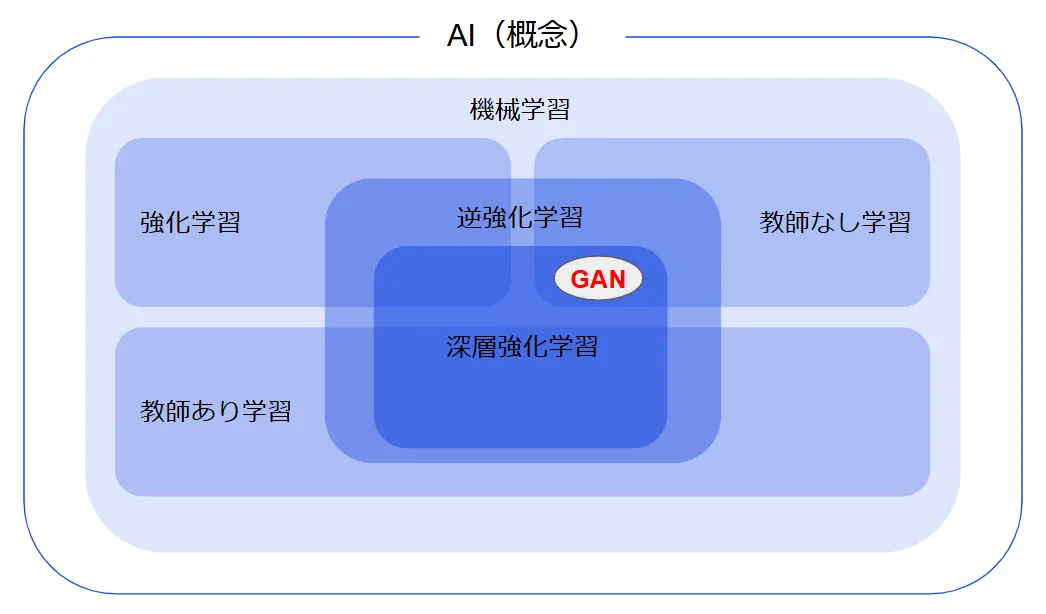
GANの立ち位置
従来の機械学習とは異なるGANの特性が、AIの新たな可能性を広げていることが分かりますね。では、このGANを支える重要な要素について、次の章で詳しく説明していきます。
GAN(敵対的生成ネットワーク)の構成要素と動作原理
生成ネットワークは、GANの「クリエイティブ担当」といえる存在です。本物そっくりのデータを作ることがその使命で、試行錯誤を繰り返しながら徐々に精度を高めていきます。
この仕組みを知ると、AIが創造する力を持っていることに驚かされるはずです。
生成ネットワーク(Generator)の役割
生成ネットワークは、簡単に言えば「アイデアを形にするアーティスト」です。最初は何の形もないランダムなノイズを受け取りますが、それを少しずつ加工して、誰もが「本物っぽい」と思うようなデータを作り出します。
例えば、画像生成のケースでは、ぼんやりとしたノイズの集合が、徐々にリアルな写真のように見えるデータへと進化していくプロセスを担っています。
このネットワークの「ミッション」は、識別ネットワーク(後述)に「これは本物だ!」と思わせるようなリアルなデータを作ること。このいたちごっこを繰り返しながら、生成ネットワークはどんどん巧妙な生成能力を身につけていきます。
生成ネットワークが頑張って「本物らしいデータ」を生み出す背後には、もう一つの重要なプレイヤーである「識別ネットワーク」の存在があります。
次はその役割について見ていきましょう。
識別ネットワーク(Discriminator)の役割
一方で、識別ネットワークは「批評家」のような存在です。「これは本物だ」「いや、偽物だ」と生成ネットワークのデータをチェックし、厳しいフィードバックを返します。
これによって、生成ネットワークが成長するのです。
識別ネットワークは、「目利きの審査員」です。生成ネットワークが作り出したデータが「本物なのか偽物なのか」を見極める役割を果たします。
画像生成を例にとると、識別ネットワークは色合いや質感、形状といった特徴を細かくチェックしながら、本物らしさを評価します。
そして、「本物っぽい」データには高得点を、「偽物っぽい」データには低得点を与えます。この評価は、識別ネットワーク自身の精度を高めるだけでなく、生成ネットワークにフィードバックとして送り返されます。
こうして、生成ネットワークと識別ネットワークが競い合いながら進化するのが、GAN(生成的敵対ネットワーク)の仕組みなのです。
識別ネットワークがいるからこそ、生成ネットワークは進化を続けられます。この絶妙な関係性が、GANの強みを引き出しています。では、両者がどのように連携して学習するのかを見ていきましょう。
GAN(敵対的生成ネットワーク)の学習プロセス
GANの学習は、生成ネットワークと識別ネットワークが「競争しながら協力する」プロセスです。
最初はぎこちないやりとりですが、次第にお互いが成長し、驚くほどリアルなデータが生み出されるようになります。
GANの学習は、**生成ネットワーク(Generator)と識別ネットワーク(Discriminator)**が競い合う仕組みで進行します。
このプロセスを具体例で説明します。
-
生成ネットワークがデータを作成
最初に、生成ネットワークはランダムなノイズから偽のデータを生成します。例えば、猫の画像を生成したい場合、生成ネットワークは最初は意味不明な模様や形の画像を作ります。
-
識別ネットワークが真偽を判別
次に、識別ネットワークが生成された偽物のデータと本物の猫の画像を比較し、「どちらが本物か」を判定します。このとき、識別ネットワークはデータの特徴(形、色、質感など)を分析して、本物か偽物かのスコアを出します。
-
フィードバックによる調整
- 偽物と判断された場合:
生成ネットワークは「どうすればより本物に近い猫の画像を作れるか」を学び、次の生成で改善するようパラメータを調整します。例えば、「耳の形が不自然だ」と判定されたら、次は耳を本物らしく描くように修正します。 - 本物と誤認された場合:
識別ネットワークは「なぜ騙されたのか」を分析し、次回は同じミスをしないように特徴を捉える力を強化します。
- 偽物と判断された場合:
-
競争が繰り返される
生成ネットワークは、識別ネットワークを欺くことを目指してどんどん精巧なデータを作り出し、識別ネットワークはその偽物を見破るために精度を高めます。この競争を何度も繰り返すことで、最終的に生成ネットワークは非常にリアルなデータを生成できるようになり、識別ネットワークもより鋭くデータの真偽を判別できるようになります。
このように、2つのネットワークが「競争と成長」を続ける仕組みがGANの学習の本質です。

GAN生成プロセス
このプロセスを通じて、GANは驚異的な生成能力を獲得します。この仕組みを応用することで、さまざまな種類のGANモデルが開発されてきました。次の章では、そんな代表的なモデルと応用例を詳しく見ていきましょう。
GAN(敵対的生成ネットワーク)の種類と応用例
最新のGANモデルとその具体的な活用事例を紹介します。
DCGANやStyleGANなどの代表的なモデルから、画像生成、音声合成、医療分野での応用まで、GANの多様な可能性について解説します。
代表的なGANモデル(DCGAN、CycleGAN、StyleGANなど)
GANにも「進化の歴史」があります。その中で登場したさまざまなモデルが、それぞれの得意分野で活躍しています。DCGAN、CycleGAN、StyleGANなど、聞いたことがあるかもしれませんね。
ここでは、それらの特徴を紹介します。
-
DCGAN (Deep Convolutional GAN)
画像生成に特化したGANモデル。畳み込みニューラルネットワークを用いることで、高品質な画像を生成することができる。
-
CycleGAN
画像のスタイル変換を行うGANモデル。例えば、馬の画像をシマウマの画像に変換することができる。
-
StyleGAN
高解像度で写実的な画像を生成することができるGANモデル。顔画像生成などでよく用いられる。
| モデル名 | 特徴 | 用途 |
|---|---|---|
| DCGAN | 畳み込みニューラルネットワークを用いた画像生成 | 画像生成 |
| CycleGAN | 画像のスタイル変換 | 画像変換 |
| StyleGAN | 高解像度で写実的な画像生成 | 顔画像生成など |
これらのモデルは、GANの可能性を広げる重要なステップでした。では、具体的にどのような場面で活用されているのか、次のセクションで詳しく見ていきましょう。
画像生成
画像生成は、GANの最も得意とする分野の一つです。風景やポートレートを描き出したり、古い写真を復元したりと、幅広い用途で活躍しています。ここでは、実際の応用例をいくつかご紹介します。
1.顔画像生成
GANを使用すると、実在しない人物の顔をリアルに生成することができます。
例えば、広告や映画で試用される架空のキャラクターの顔を作成したり、AIによる創作アートに活用されています。
以下の人物の画像はGANを用いたサイト「Generated Photos」が生成した存在しない人物の顔写真です。
もはや、現実と虚構の境目境界を見分けられないレベルに到達していることがわかります。顔画像の人物は性別や年齢、人種だけではなく、目の色、髪の長さや色など、多様な要素で構成されます。

引用元:Generated Photos
2.画像の高解像度化(Super-resolution)
低解像度の画像を高解像度に変換する技術です。例えば、ぼやけた猫の画像を鮮明に復元することで、印刷やデジタル表示での品質を向上させることができます。
「PULSE」はピクセルが見えてしまうほど低解像度の写真を、本物の人間のように見える写真に変換したものです。

引用元:PULSE
3.画像の修復(Restoration)
傷ついたり劣化した写真を修復する用途です。例えば、古い家族写真の色褪せや破損部分を修復し、元の状態に近づけることが可能です。
GFPGANは入力された顔画像から事前情報を作成し、作成した事前情報を人の顔画像で学習済みのStyleGAN2という高画質に特化した生成モデルで使用することで、高画質な顔画像の復元を実現することができます。

引用元:Towards Real-World Blind Face Restoration with Generative Facial Prior
画像生成分野での成功は、GANの可能性を示す一例にすぎません。
次に、画像以外の分野でどのように応用されているのかも見ていきましょう。
音声合成
GAN(敵対的生成ネットワーク)は、音声合成の分野でも革新的な進展をもたらしています。音声合成とは、テキストデータを元に人工的に音声を生成する技術ですが、従来の音声合成技術では、合成音声が機械的で不自然に聞こえることがありました。
GANを活用することで、より自然で人間らしい音声を作り出すことが可能になりつつあります。
1.音声の自然さの向上
GANは生成ネットワークと識別ネットワークの競争によって、より滑らかで自然な音声を生み出すことができます。
識別ネットワークは本物の音声と生成音声を区別し、その結果、生成ネットワークは人間の声に非常に近い音声を生成することを学びます。
2.音声の表現力の向上
GANを用いることで、感情やイントネーション、アクセントを反映した音声の合成が可能になり、より感情豊かな音声合成が実現しています。
例えば、テキストに込められた感情や状況に応じて、音声が自動的に変化することができます。
3.リアルタイム音声合成
GANは、高速な音声生成が可能であり、リアルタイムでの音声合成にも利用されています。
これにより、音声アシスタントや音声翻訳などの技術で、よりインタラクティブで自然な会話が可能になります。
【音声合成の例】
以下の動画の3:30~、実際にAIレセプションが客対応しています。まるで人間化のように自然な会話ができているのがここからわかります。言われなければAIとはわからないですよね?
音声合成におけるGANの活用は、音声の自然さ、表現力、リアルタイム処理など、さまざまな面での進化を促進しています。
今後、さらに多くの分野で人間に近い、感情やニュアンスを反映した音声生成が実現することが期待されています。
その他の応用分野(医療、アート、セキュリティなど)
医療画像の改善からアートの創作、さらにはセキュリティ対策まで、GANの応用範囲は非常に広がっています。
その中でも特に注目される分野について、ここでは詳しく説明します。
1.医療
医療画像の生成
GANは、CTスキャンやMRIなどの医療画像を生成するために活用されています。例えば、少ないデータしかない病院で、GANを使って高品質な医療画像を生成し、診断精度を向上させることができます。
また、GANを用いることで、異常のない健康な臓器の画像を生成し、医師が病気の早期発見に役立てることができます。
病気の診断支援
GANを利用したシステムは、医師が診断を行う際の支援ツールとしても利用されています。例えば、GANを使って病気の兆候を捉えやすい画像やパターンを生成し、早期診断のために活用されることがあります。
乳がんや肺がんの早期検出において、従来の画像診断よりも高精度な診断を支援します。
-
例
元画像特徴を維持したまま、目的とする特徴を付加するようAIを訓練することで、元の広角眼底画像の視神経乳頭や血管などの特徴を維持したまま、高い表現力を持つ擬似的な網膜剥離症例画像を生成しました。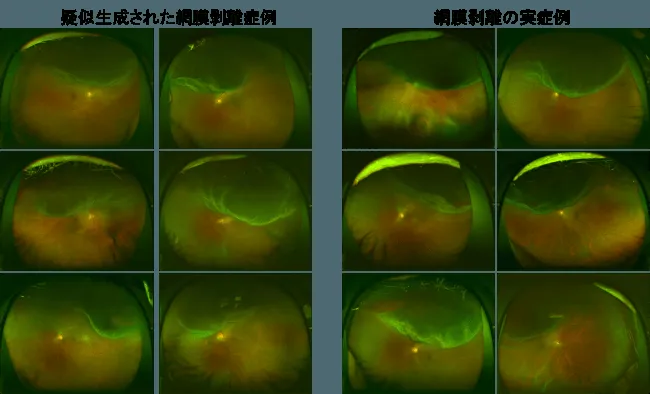
引用元:プレスリリース
2.アート
新しい芸術作品の創造
GANは、アーティストやデザイナーにとって新しい作品を生み出すための強力なツールです。
例えば、「Artbreeder」などのプラットフォームでは、GANを使用して様々なスタイルや要素を組み合わせ、ユニークなアート作品を生成することができます。
これにより、アーティストは自分のアイデアを拡張し、創造的なインスピレーションを得ることができます。
スタイル変換
GANは、画像や絵画のスタイルを変換するためにも利用されています。たとえば、写真を特定の画家のスタイル(例えばピカソ風やゴッホ風)に変換する技術は、GANを用いて実現されています。
この技術により、写真やデジタルアートがまるで歴史的な芸術作品のように見えるように変化します。
- 例
Artbreederで生成した画像

引用元:公式HP
3.セキュリティ
偽造防止
GANは、セキュリティ分野でも重要な役割を果たします。特に、偽造防止技術としての利用が進んでいます。
例えば、偽造されたIDカードや通貨を検出するために、GANを利用して本物のデザインを学習し、偽造されたアイテムが持つ微妙な違いを識別することができます。
このような技術は、犯罪防止や安全なオンライン取引に活用されています。
異常検知
GANは、異常検知にも応用されています。例えば、企業のネットワークやオンラインシステムにおける不正アクセスや異常な行動を検出するために、通常のネットワークトラフィックやパターンを学習し、そのパターンに基づいて異常をリアルタイムで検知することができます。
これにより、早期にサイバー攻撃を発見し、対策を講じることが可能になります。
医療画像の改善からアートの創作、さらにはセキュリティ対策まで、GANの応用範囲は非常に広がっています。その中でも特に注目される分野について、ここでは詳しく説明します。
GANの実装方法
GANを実際に使ってみたい!そう思ったとき、最初のステップがネットワークの構築です。生成ネットワークと識別ネットワークの2つを設計し、それぞれがどのように機能するかを考えるところから始まります。
ここでは、基本的な構築の流れを見ていきましょう。
GANのネットワーク構築
GANを実装するには、PyTorchやTensorFlowといった深層学習フレームワークを使用します。これらのフレームワークを用いることで、生成ネットワーク(Generator)と識別ネットワーク(Discriminator)の構造を簡単に定義し、それぞれのパラメータを学習させることができます。
ここでは、PyTorchとTensorFlowを使用したGANの基本的な実装方法を簡単に説明します。
-
PyTorchを用いたGANの実装
- ライブラリのインポート
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader- 生成ネットワークの定義(Generator)
Generatorはランダムなノイズを入力として受け取り、それを画像に変換するネットワークです。ここでは、全結合層を使って簡単なGeneratorを定義します。
class Generator(nn.Module): def __init__(self): super(Generator, self).__init__() self.fc = nn.Sequential( nn.Linear(100, 256), # 入力ノイズの次元(100) nn.ReLU(), nn.Linear(256, 512), nn.ReLU(), nn.Linear(512, 1024), nn.ReLU(), nn.Linear(1024, 28*28), # 生成される画像のサイズ (28x28) nn.Tanh() # 出力を-1から1に正規化 ) def forward(self, z): return self.fc(z).view(-1, 1, 28, 28) # 画像の形にリシェイプ- 識別ネットワークの定義 (Discriminator)
Discriminatorは、生成された画像が本物か偽物かを判別するネットワークです。
class Discriminator(nn.Module): def __init__(self): super(Discriminator, self).__init__() self.fc = nn.Sequential( nn.Linear(28*28, 1024), nn.LeakyReLU(0.2), nn.Linear(1024, 512), nn.LeakyReLU(0.2), nn.Linear(512, 256), nn.LeakyReLU(0.2), nn.Linear(256, 1), nn.Sigmoid() # 出力は0か1で偽物か本物かを判定 ) def forward(self, x): return self.fc(x.view(-1, 28*28))- 損失関数と最適化手法
criterion = nn.BCELoss() # バイナリクロスエントロピー損失 optimizer_G = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999)) optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))- 学習の実行
for epoch in range(num_epochs): for i, (real_images, _) in enumerate(data_loader): # 本物のラベルは1、偽物のラベルは0 real_labels = torch.ones(batch_size, 1) fake_labels = torch.zeros(batch_size, 1) # Discriminatorの更新 optimizer_D.zero_grad() outputs = discriminator(real_images) d_loss_real = criterion(outputs, real_labels) d_loss_real.backward() noise = torch.randn(batch_size, 100) fake_images = generator(noise) outputs = discriminator(fake_images.detach()) d_loss_fake = criterion(outputs, fake_labels) d_loss_fake.backward() optimizer_D.step() # Generatorの更新 optimizer_G.zero_grad() outputs = discriminator(fake_images) g_loss = criterion(outputs, real_labels) g_loss.backward() optimizer_G.step() print(f'Epoch [{epoch}/{num_epochs}], D Loss: {d_loss_real.item()+d_loss_fake.item()}, G Loss: {g_loss.item()}') -
TensorFlowを用いたGANの実装
- ライブラリのインポート
import tensorflow as tf from tensorflow.keras import layers, models- 生成ネットワークの定義
def build_generator(): model = models.Sequential() model.add(layers.Dense(256, input_dim=100)) model.add(layers.LeakyReLU(0.2)) model.add(layers.Dense(512)) model.add(layers.LeakyReLU(0.2)) model.add(layers.Dense(1024)) model.add(layers.LeakyReLU(0.2)) model.add(layers.Dense(28*28, activation='tanh')) # 出力を-1から1に正規化 model.add(layers.Reshape((28, 28, 1))) # 画像サイズにリシェイプ return model- 識別ネットワークの定義 (Discriminator)
def build_discriminator(): model = models.Sequential() model.add(layers.Flatten(input_shape=(28, 28, 1))) model.add(layers.Dense(1024)) model.add(layers.LeakyReLU(0.2)) model.add(layers.Dense(512)) model.add(layers.LeakyReLU(0.2)) model.add(layers.Dense(256)) model.add(layers.LeakyReLU(0.2)) model.add(layers.Dense(1, activation='sigmoid')) # 出力は0か1 return model- 損失関数と最適化手法
cross_entropy = tf.keras.losses.BinaryCrossentropy() def discriminator_loss(real_output, fake_output): real_loss = cross_entropy(tf.ones_like(real_output), real_output) fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output) return real_loss + fake_loss def generator_loss(fake_output): return cross_entropy(tf.ones_like(fake_output), fake_output)- 学習の実行
generator = build_generator() discriminator = build_discriminator() generator_optimizer = tf.keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5) discriminator_optimizer = tf.keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5) @tf.function def train_step(real_images): noise = tf.random.normal([batch_size, 100]) with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape: fake_images = generator(noise, training=True) real_output = discriminator(real_images, training=True) fake_output = discriminator(fake_images, training=True) gen_loss = generator_loss(fake_output) disc_loss = discriminator_loss(real_output, fake_output) gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables) gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables) generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables)) discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables)) for epoch in range(num_epochs): for real_images in dataset: train_step(real_images)
PyTorchとTensorFlowの両方で、GANの実装は非常に似ていますが、フレームワークの構造やAPIに違いがあります。
どちらのフレームワークも、生成ネットワークと識別ネットワークの構造を定義し、最適化アルゴリズムや損失関数を設定することで、効率的にGANの学習ができます。
GANを実際に使ってみたい!そう思ったとき、最初のステップがネットワークの構築です。生成ネットワークと識別ネットワークの2つを設計し、それぞれがどのように機能するかを考えるところから始まります。ここでは、基本的な構築の流れを見ていきましょう。
GANの学習における注意点
GAN(生成的敵対的ネットワーク)を学習させるときには、いくつかの落とし穴があります。その中でも代表的なものが、**勾配消失(vanishing gradients)と勾配爆発(exploding gradients)**です。
この問題が起きると、ネットワークの学習が進まなかったり、不安定になったりしてしまいます。
なぜこうなるの?
- 初期化が原因
ネットワークの重みが適切に設定されていないと、学習初期に勾配がほとんど流れなかったり、逆に極端な値を取って学習が破綻することがあります。 - 活性化関数の選択
よく使われるReLUなどの関数は、深い層のネットワークで勾配がゼロに近づきやすく、学習を妨げることがあります。
どう対処するの?
- 初期化を工夫する
重みの初期化を工夫するだけで劇的に改善することがあります。例えば、Xavier初期化やHe初期化は安定した学習のための定番手法です。 - 活性化関数を見直す
勾配消失を緩和するために、LeakyReLUやELUなどの活性化関数が効果的です。これらは勾配がゼロになりにくいため、学習をスムーズに進められます。
勾配の問題だけでなく、GANにはモード崩壊(mode collapse)や学習の不安定性といった独特の困難もつきものです。生成されるデータが多様性を欠いたり、訓練が全く進まなくなるケースもあります。
どう乗り越える?
-
WGAN(Wasserstein GAN)
勾配消失を防ぐために、損失関数の設計を工夫したWGANは、GAN学習の不安定性を軽減する強力な手法です。 -
勾配ペナルティ(Gradient Penalty)
勾配が極端な値を取らないよう制御することで、安定性を高めます。 -
条件付きGAN(Conditional GAN)
ラベル情報を活用することで、生成物の制御性や多様性を向上できます。
GANの学習は一筋縄ではいかないことも多いですが、こうした工夫を重ねていくことで、より安定して質の高いモデルを構築できます。
問題に直面しても、「なぜうまくいかないのか」を探ることが、次のブレークスルーにつながります!
GANの評価指標
GANの評価指標は、生成されたデータの品質を定量的に測定するための重要なツールですが、完全に標準化された指標はまだ確立されていません。
GANによる生成結果は、主観的な判断が多く絡むため、評価方法も多様です。
ここでは、代表的な評価指標をいくつか紹介し、それぞれの特性について解説します。
1.フリーダイバージェンス(Fréchet Inception Distance: FID)
FIDは、生成された画像の品質を評価するための指標で、画像の特徴量の分布を基に計算されます。
具体的には、生成画像と本物の画像をInceptionネットワークで特徴量ベクトルに変換し、その特徴量の分布の差異(平均と共分散の差)をフリーダイバージェンスとして測定します。
2.識別精度(Discriminator Accuracy)
GANにおける識別ネットワーク(Discriminator)が、生成データと本物データをどれだけ正確に区別できるかを評価する指標です。
識別精度が高いと、生成されたデータは本物のデータと大きく異なっていると判断されます。
3.経済的損失(Inception Score: IS)
Inception Scoreは、生成画像がいかに多様で意味のある内容を持っているかを測るための指標です。
生成した画像をInceptionネットワークに通し、クラス分類の結果がどれほど確信的であるかを基にスコアを計算します。
生成画像が1つのクラスに対して非常に確信的で、かつ多様なクラスにまたがっている場合、ISスコアは高くなります。
4.多様性指標(Diversity Metrics)
生成されたデータの多様性を評価するための指標で、生成画像の間にどれだけの変動があるかを測ります。
たとえば、生成された画像の類似度を計算することで、どれだけ多様な画像が生成されたかを測定します。
それぞれの評価指標の長所と短所をまとめると以下のようになります。
| 評価指標 | 長所 | 短所 |
|---|---|---|
| フリーダイバージェンス(FID) | - 画像の品質を高精度に測定できる - 生成画像と本物の画像の統計的違いを反映 |
- 計算にInceptionネットワークを使用するため、ネットワークの性能に依存 - ネットワークの精度が低いと評価も低くなる可能性 |
| 識別精度(Discriminator Accuracy) | - シンプルで直感的な指標 - 学習が進むと、生成画像が本物に近づいていることを示唆 |
- 識別精度が高い場合でも、生成画像が必ずしも高品質とは限らない - 識別器の過学習の可能性 |
| 経済的損失(Inception Score: IS) | - 生成された画像の多様性と意味を測れる - 計算が速くシンプル |
- クラス分類に基づいており、視覚的な多様性や質を完全に反映しきれない - ネットワークの性能に依存 |
| 多様性指標(Diversity Metrics) | - モード崩壊を評価できる - 生成モデルが異なるデータを生成できるかを評価できる |
- 視覚的な品質を評価するのは難しい - 多様性の測定のみで、質の高い画像の評価が困難 |
GANの評価には様々な指標があり、それぞれが異なる側面から生成結果の品質を評価します。
FIDやISなどの定量的な指標は一般的に使用されますが、最終的には複数の評価指標を組み合わせることで、より正確で信頼性の高い評価を行うことが重要です。
また、技術的な改善や新しい評価基準が進む中で、今後さらに有効な指標が開発されることが期待されています。
GANの課題と今後の展望
GANは便利な技術である一方で、悪用されるリスクも抱えています。
ここでは倫理的課題と、それに対する対策について考えていきます。
GANの倫理的問題と対策
GAN技術はその革新性と可能性の一方で、悪用のリスクも抱えています。特にディープフェイク(Deepfake)は、その代表的な懸念材料です。
ディープフェイクとは、GANを用いて作成された偽の画像や動画で、特に有名人や一般人の顔をリアルに再現し、誤った情報や偽のコンテンツを広めることができます。
この技術を悪用することで、社会的混乱やプライバシーの侵害が引き起こされる可能性があります。
ディープフェイクの悪用を防ぐためには、技術的な対策と社会的な対応が重要です。技術的には、ディープフェイクを自動的に検出するアルゴリズムや、偽情報を発信した際にその正当性を保証するブロックチェーン技術の導入が研究されています。
さらに、生成されたコンテンツに対して元の出所を明確にするためのタグ付けや、透明性を高める技術の開発も進められています。
一方で、法的・倫理的な対応も不可欠です。多くの国で、ディープフェイクによる名誉毀損や詐欺、脅迫などの犯罪行為に対する法規制が進んでおり、これにより悪用を未然に防ぐための法的枠組みが整いつつあります。また、技術開発者や企業が倫理的に責任を持つよう、AI技術の利用に関する倫理的ガイドラインの整備が求められています。
このように、GANの悪用を防ぐためには技術的なイノベーションとともに、法的および倫理的な枠組みをしっかりと構築することが不可欠です。
AI規制法については、こちらの記事をご覧ください。
AI規制法とは?日本・海外の事例を踏まえ、その内容と影響を徹底解説
GANの将来性と期待される発展
GANがもたらす未来は、まだまだ広がっています。AIアートや映画制作、自動運転のシミュレーション、さらには医療分野での活用など、無限の可能性を秘めています。この章では、GANの将来性を具体的に描いていきます。
自動運転
自動運転車の開発においても、GANは重要な役割を果たしています。特に、仮想環境でのシミュレーションによるデータ生成や、障害物や交通標識の画像生成などに利用されています。Waymo(Googleの自動運転車開発部門)などの企業は、GANを利用して自動運転車のシミュレーションに必要な大量のデータを生成し、テストと学習の効率化を図っています。

引用元:Waymo
創薬
創薬分野では、GANを用いて新しい薬の候補分子を生成する研究が進んでいます。従来の方法では膨大な時間とコストがかかるところ、GANを使えば新しい分子を効率的に生成でき、創薬のスピードが加速します。
企業例としては、Insilico Medicineがあり、同社はGANを利用した創薬プラットフォームを開発し、特定の病気に効果的な分子の候補を生成しています。こ
れにより、従来の手法よりも迅速に新薬を発見できる可能性があります。

GANは課題を乗り越えながらも、私たちの未来を豊かにする力を持っています。最後に、これまでの内容を振り返り、GANという技術の魅力を改めて確認していきましょう。

まとめ
GAN(生成敵対的ネットワーク)は、今後の技術革新を大きく牽引する可能性を持っています。基本的には、生成ネットワークと識別ネットワークが互いに競い合いながら学習する仕組みで、これによってリアルなデータが次々に生成されます。特に画像や音声生成の分野ではすごい進化を遂げていて、ディープフェイク技術のように、リアルすぎる偽データも簡単に作れるようになっています。
ただし、GANには学習の不安定性や生成物の多様性が足りないといった課題もあります。さらに、ディープフェイクなどの悪用のリスクもあるため、技術的な対策や法的な規制が急務です。
それでも、AIアートや自動運転、医療診断、創薬といった分野では、GANがすでに実用化されており、これからもっと広がることが期待されています。例えば、Waymoの自動運転技術や、NVIDIAの医療用画像解析など、GANを活用した新しい技術が現実のものとなっています。
今後のGANには、まだ課題が残っているものの、可能性は無限大!
これからも進化し続け、さまざまな分野で活躍していくことが楽しみです。







