この記事のポイント
 この記事ではAIと機械学習の違いについて、特にその定義や関係性、用途に焦点を当てて説明しています。
この記事ではAIと機械学習の違いについて、特にその定義や関係性、用途に焦点を当てて説明しています。- AIとは人間の知能を模倣するコンピューターシステム全般を指すのに対し、機械学習はデータからの学習を行い予測や決定をする特定の技術を指します。
- また、教師あり学習、教師なし学習、強化学習といった、機械学習の主要なアルゴリズムについても触れられています。

Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
AIと機械学習は似ているようで異なる概念ですが、どのように違うのでしょうか。
本記事では、そんな疑問を持った方々に向けて、AIと機械学習の根本的な違いについてわかりやすく解説します。
教師あり学習、教師なし学習、強化学習など、機械学習の具体的な手法も紹介し、これらがAI技術とどのように結びついているのかを掘り下げます。
AIと機械学習の違いを理解し、それぞれの可能性を探るための一歩としてぜひ最後までお読みください。
目次
AIと機械学習の違い
AIと機械学習はしばしば混同されますが、AIと機械学習の違いは、AIが人間の知能を模倣するコンピューターシステム全般を指すのに対し、機械学習はデータから学習して予測や決定を行う特定の方法論や技術を指す点です。
AIは幅広い技術や理論を包括する概念で、機械学習が特定のタスクを知的に処理する能力を持つ手法と捉えることもできます。
以下は、AI、機械学習(マシンラーニング, ML)、深層学習(ディープラーニング)、生成AIの関係を図示しているので参考にして下さい。
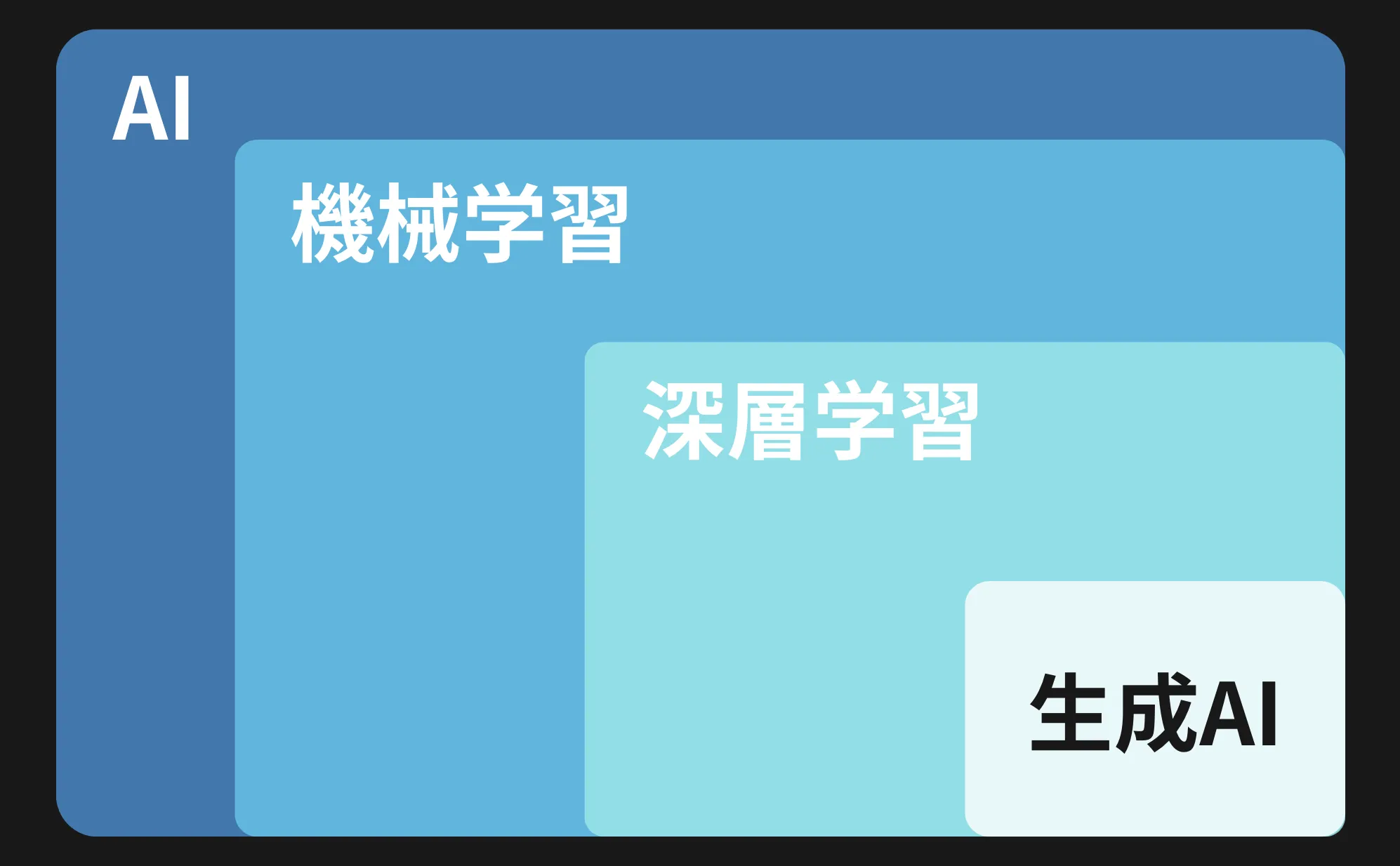
AI、機械学習、深層学習、生成AIの関係
AIとは
人工知能(Artificial Intelligence、略称AI)は、機械が人間のように学習し、理解し、行動するためのテクノロジーとプロセスを指します。
AIの目標は、知覚、推論、学習能力、自然言語処理など、人間の知的行動を模倣することです。
AIには幅広い技術が含まれています。
基本的な「ルールベースのタスク自動化システム」から、自然言語処理や画像認識などの複雑なタスクを実行する高度なアプリケーションまで、さまざまな形態があります。
一般的に、AIは指定されたタスクについて、人間と同等もしくはそれ以上のパフォーマンスを発揮することを目指しています。
【関連記事】
➡️AIとは?その定義や日常・ビジネスでの活用事例をわかりやすく解説!
機械学習とは何か?
機械学習は、アルゴリズムと統計モデルを使用して、「明示的なプログラミングなしにタスクを実行するための、パターンや推論をデータから学習する人工知能(AI)の分野」です。
機械学習のシステムは、大量のデータを分析し、そのデータ内のパターンや規則性を見つけ出し、新しいデータに遭遇したときに予測や意思決定を行うことができます。
ディープラーニングとの関係
ディープラーニングは、機械学習の一領域であり、人間の脳の神経回路網に触発されたニューラルネットワークの学習アルゴリズムが用いられます。
これらのアルゴリズムは多層的な構造を持ち、データの抽象的な特徴を抽出する能力が非常に高いことが特徴です。ディープラーニングは、画像認識や自然言語処理といった複雑なタスクでその効果を発揮しています。
機械学習とディープラーニングはしばしば同義で使われることがありますが、ディープラーニングは「機械学習の技術セット内に存在する、より特化された分野」です。
【関連記事】
➡️機械学習とディープラーニングの違いをわかりやすく解説!
機械学習の主要アルゴリズム
機械学習は多くのアルゴリズムを基礎にしており、それぞれが特定のタスクや問題に応じて設計されています。
これらのアルゴリズムは、大別すると教師あり学習、教師なし学習、強化学習にカテゴライズされることが多く、それぞれ異なるユースケースで利用されます。
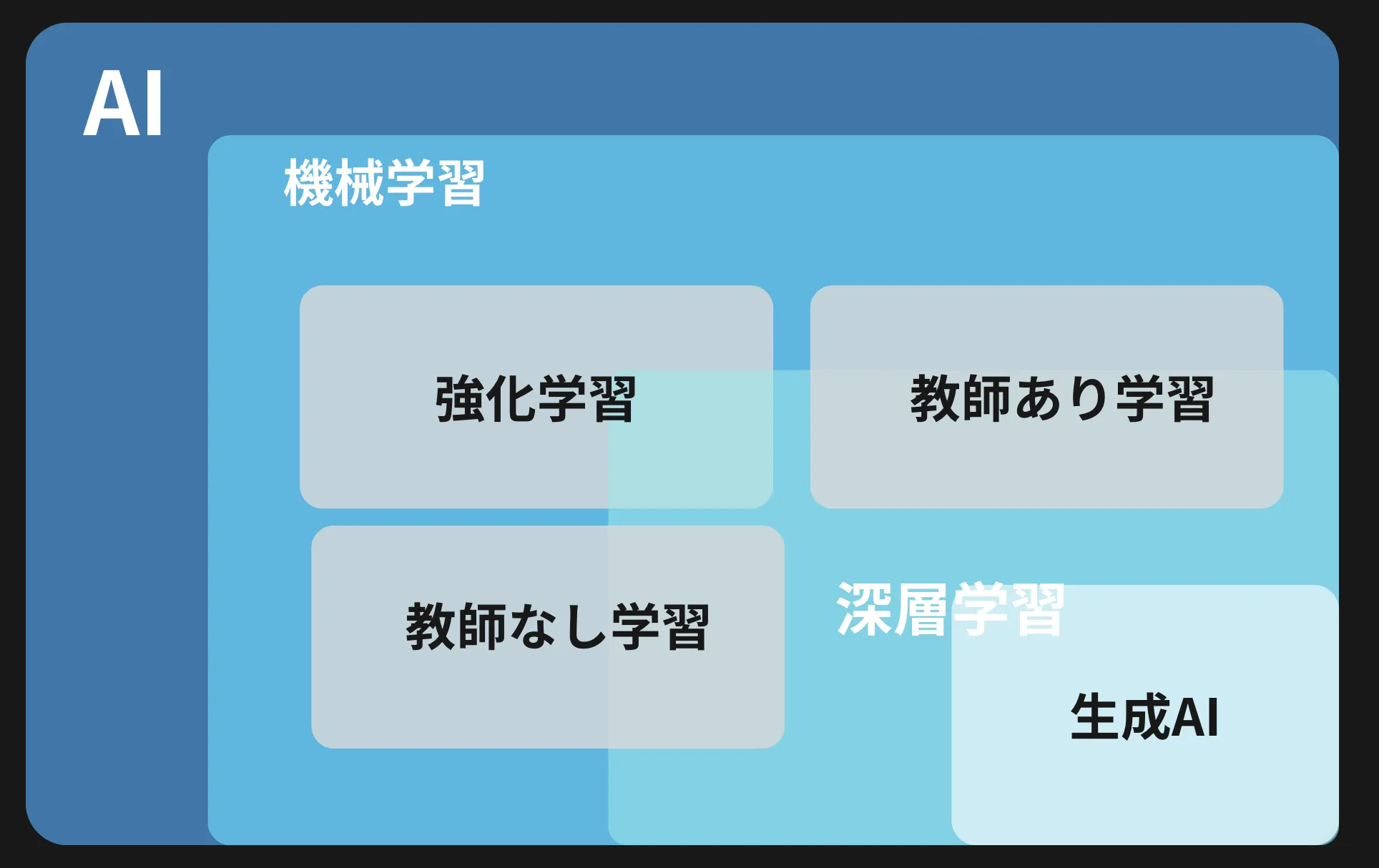
機械学習のアルゴリズム(教師あり学習、教師なし学習、強化学習)
【関連記事】
➡️機械学習の代表的な手法一覧!フローチャートを用いて選び方を解説
教師あり学習
教師あり学習は、「回帰」と「分類」が含まれます。これらのアルゴリズムにラベル付けされた訓練データを提供し、そのデータからパターンを学習して新しい未知のデータに対して予測を行います。
この分野の代表的なアルゴリズムには、「線形回帰」「ロジスティック回帰」「サポートベクターマシン(SVM)」「決定木」「ランダムフォレスト」があります。
回帰
代表的な回帰分析の手法には、線形回帰、多項式回帰、リッジ回帰、ラッソ回帰などがあり、これらは様々なデータセットにおいて、関連する変数間の関係性をモデル化するのに用いられます。
今回は教師あり学習の一例としてよく用いられる回帰モデルの一つである線形回帰分析の手法を紹介したいと思います。
線形回帰分析の例
回帰分析とは入力データから導き出された、連続的な出力値を知ることができるのが回帰分析です。
エアコンを例に考えてみましょう。部屋の温度を入力データとして用意し、出力ラベルにはエアコンの消費電力を設定してみます。
訓練データ(学習データ)の部屋の温度と消費電力の関係を学習することで、部屋の温度からその部屋のエアコンの消費電力を予測することができます。
実際に線形回帰を用いて分析を行った結果は以下の通りです。
Regression line equation: y = 3.35x + 142.26
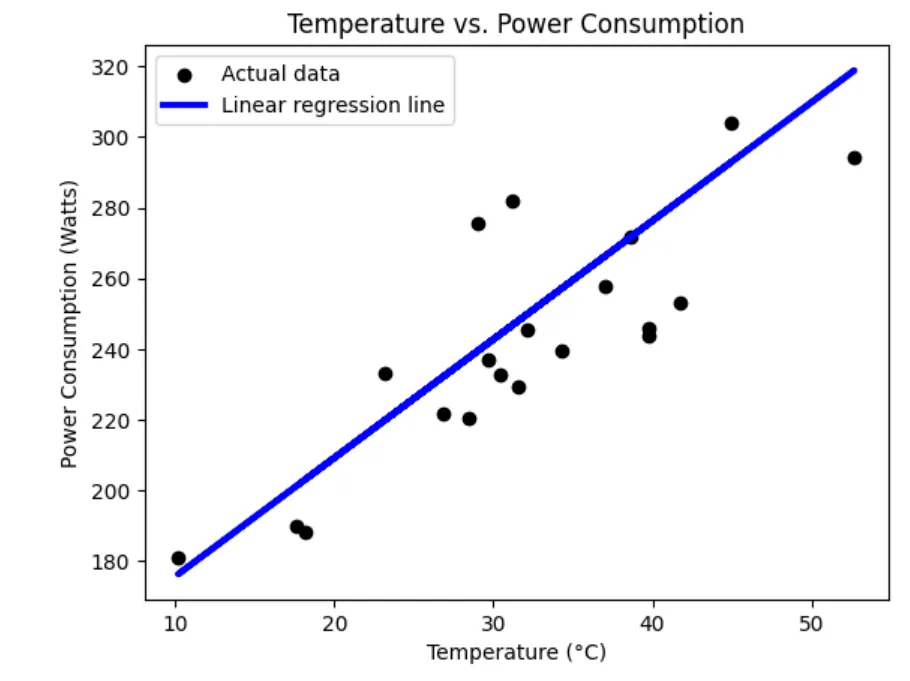
Google Colabノートブックも公開してあるので、ぜひご自身で試してみてください。
線形回帰モデル(Google Colab)
分類
分類とは、入力データを事前に設定されたカテゴリに分けるプロセスです。
メールを例に考えてみましょう。メールの内容(テキスト)が入力データであり、出力ラベルは「スパム」または「非スパム」の2つのカテゴリーです。
訓練データを学習することで、新たなメールがスパムであるかそうでないかの分類ができます。
分類の例
分類の手法としてナイーブベイズ分類器を用いたサンプルコードを準備しました。
訓練データのサンプルとして、スパムメールと非スパムメールの両方を含むメールのテキストを用意し、それらを「スパム=1」および「非スパム=0」としてラベル付けしました。
その後、データセットをトレーニングセットとテストセットに分割し、テキストデータを数値データに変換してから、ナイーブベイズ分類器で学習を行いました。
テストデータに対する予測の正確さは50%でした。
これではランダムな推測と同じ水準であり、このモデルが有効に機能しているとは言えませんので実際には、データ量、データの多様性、特徴抽出の方法を検討するなどの工夫が考えられます。
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
# サンプルデータ
emails = [#以下は自由に変更可能です(サンプルではスパムのようなメールも含んでいます)
"Congratulations! You've won a $1,000 gift card. Click here to claim now.",
"Hi friend, long time no see. Let's catch up soon!",
"Limited time offer! Get 50% off on all products. Shop now.",
"Are you available for a meeting tomorrow? Please let me know.",
"You have been selected for an exclusive reward. Claim your prize now.",
"Reminder: Your appointment is scheduled for 10 AM tomorrow.",
"This is your final notice! Account will be closed unless immediate action is taken.",
"Looking forward to our dinner next week. Let's finalize the place.",
]
# ラベル(スパム=1、非スパム=0)
labels = [1, 0, 1, 0, 1, 0, 1, 0]
# データセットをトレーニングセットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(emails, labels, test_size=0.25, random_state=42)
# テキストデータを数値データに変換
vectorizer = CountVectorizer()
X_train_counts = vectorizer.fit_transform(X_train)
X_test_counts = vectorizer.transform(X_test)
# ナイーブベイズ分類器をトレーニング
clf = MultinomialNB()
clf.fit(X_train_counts, y_train)
# テストデータで予測
y_pred = clf.predict(X_test_counts)
# 予測の正確さを評価
accuracy = accuracy_score(y_test, y_pred)
accuracy
教師なし学習
教師なし学習では、ラベル付けされていないデータセットを扱います。この手法の目的は、データ内の隠れた構造やパターンを見つけ出すことです。
教師なし学習は、データのクラスタリングや次元削減といったタスクでよく使用されます。クラスタリングは、類似した特徴を持つデータポイントをグループ化するプロセスです。
次元削減は、データセットの複雑さを減らすために、より少ない変数でデータを表現する方法です。
代表的なアルゴリズムには、k平均法、階層的クラスタリング、主成分分析(PCA)、t-SNEなどがあります。
教師なし学習の例
サンプルはKMeansクラスタリングを用いたコードです。サンプルデータは、3つのクラスタ中心を持つ300のデータポイントで構成されています。
KMeansアルゴリズムを使用してデータセットにフィットさせ、各データポイントにクラスタラベルを割り当てました。
また、クラスタの中心点も取得しています。
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# サンプルデータ生成 (クラスタ数: 3)
X, _ = make_blobs(n_samples=300, centers=3, cluster_std=0.60, random_state=0)
# KMeansクラスタリングのモデルを作成 (クラスタ数: 3)
kmeans = KMeans(n_clusters=3)
# モデルにデータをフィットさせクラスタリングを実行
kmeans.fit(X)
# 各データポイントのクラスタラベルを取得
labels = kmeans.labels_
# クラスタ中心点を取得
centroids = kmeans.cluster_centers_
labels, centroids
強化学習
強化学習は、エージェントが環境と相互作用しながら最適な行動を学習するプロセスです。
この手法では、エージェントは行動の結果として与えられる報酬を最大化するように学習します。
強化学習は、シミュレーションされた環境やゲーム、ロボティクスなど、意思決定を必要とする複雑な問題に適用されます。
代表的な強化学習のアルゴリズムには、Q学習、SARSA、ディープQネットワーク(DQN)、ポリシーグラディエント法などがあります。
これらのアルゴリズムは、エージェントが最適な方策(ポリシー)を見つけ出すのを助け、より良い選択を行うことを学びます。
強化学習の例
サンプルコードでは4x4のグリッドワールドでQ学習アルゴリズムを実装しました。この環境では、各セルが状態を表し、エージェントは上、右、下、左の4つの行動から選択できます。ゴールに到達すると報酬が与えられます。
import numpy as np
# 環境設定: 4x4グリッドワールド
grid_size = 4
n_states = grid_size ** 2 # 状態数
n_actions = 4 # 行動数: 上[0], 右[1], 下[2], 左[3]
# 報酬設定: ゴールに到達すると+1、それ以外は0
rewards = np.zeros(n_states)
rewards[n_states - 1] = 1 # ゴールの位置に報酬設定
# 行動による状態遷移確率
transition_probabilities = np.zeros((n_states, n_actions, n_states))
# グリッドワールドの状態遷移確率を設定
for state in range(n_states):
row = state // grid_size
col = state % grid_size
for action in range(n_actions):
if action == 0: # 上
next_state = state if row == 0 else state - grid_size
elif action == 1: # 右
next_state = state if col == (grid_size - 1) else state + 1
elif action == 2: # 下
next_state = state if row == (grid_size - 1) else state + grid_size
else: # 左
next_state = state if col == 0 else state - 1
transition_probabilities[state, action, next_state] = 1
# Q学習パラメータ
learning_rate = 0.1
discount_factor = 0.9
n_episodes = 1000
# Q値の初期化
Q_values = np.zeros((n_states, n_actions))
# Q学習アルゴリズム
for episode in range(n_episodes):
state = np.random.randint(0, n_states) # 初期状態
while state != n_states - 1: # ゴールに到達するまで続ける
action = np.random.choice(n_actions) # 行動選択(ランダム)
next_state = np.argmax(transition_probabilities[state, action]) # 状態遷移
reward = rewards[next_state] # 報酬の取得
# Q値の更新
Q_values[state, action] += learning_rate * (reward + discount_factor * np.max(Q_values[next_state]) - Q_values[state, action])
state = next_state # 状態更新
Q_values
AIの代表的な活用事例
AIおよび機械学習は日々急激に進化しています。ここでは人々を驚かせた事例を紹介します。
OpenAIのChatGPTの画面
生成AIの代表的なサービスである「ChatGPT」
2023年にはChatGPTが出現し、誰でも気軽にAIと対話することが可能になりました。
対話の方法も当初はチャットのみでしたが、音声、画像、動画などのマルチモーダル機能が搭載され、新たな生成物を生み出すことができるようになっています。
参考:OpenAI
【関連記事】
➡️ChatGPTとは?その機能や日本語での使い方を徹底解説!
深層強化学習を利用した「AlphaGo」
2016年、当時世界最強の囲碁棋士であったイ・セドル氏に囲碁AIである「AlphaGo」が5番勝負で4-1で勝利するという事態が起こりました。
グーグル傘下のDeepMind社によって開発された人工知能(AI)が、最強の棋士を倒したという事実に世論が驚いたのを覚えています。
もともと囲碁においてAIが人間に勝てないと言われていましたが、この事態によってAIがヒトを超える技術的特異点の到来を感じざるを得なくなりました。

まとめ
この記事では、AIと機械学習の違いについて詳しく解説しました。
AIと機械学習の分野は急速に進化しており、その技術は様々な業界に革新をもたらしています。企業は機械学習やディープラーニングを活用して、製品の品質向上、顧客体験の改善、業務プロセスの自動化などを実現し、ビジネスバリューを高めています。
技術の進化は、今後も重要なマイルストーンを迎え、アルゴリズムの正確性と効率性の向上、新たな応用分野の発見、社会的な課題の解決に貢献していくことが期待されています。
この記事を通じて、AIと機械学習の知識を深める一助となれば幸いです。










