この記事のポイント
 この記事では、大規模言語モデル(LLM)の基礎から活用例、課題、今後の展望について詳しく解説しています。
この記事では、大規模言語モデル(LLM)の基礎から活用例、課題、今後の展望について詳しく解説しています。- コンテンツ生成やチャットボット等、幅広いシーンで利用されるLLMですが、データの偏りや鮮度など、さまざまな課題を抱えていることが説明されています。
- LLMの基盤となる技術的仕組みについて深く掘り下げ、トランスフォーマーアーキテクチャや事前学習といった概念を分かりやすく解説しています。
- AIのブラックボックス化による不透明性やアルゴリズムバイアスなど、LLMがはらむ倫理的・社会的課題にも触れ、技術の健全な発展に向けた示唆を与えています。
- LLMの将来的な可能性として、自然言語処理の高度化やマルチモーダル学習への応用など、技術革新の方向性を展望しています。

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
「ChatGPT」というワードは今を生きる私達なら一度は耳にしたことがあるのではないでしょうか。 観光・語学・プログラミングなどジャンルを問わずありとあらゆる疑問の解決に役立つChatGPTですが、その基盤となるのは大規模言語モデル(LLM)と呼ばれる技術でです。
この記事では、大規模言語モデル(LLM)の基盤となる仕組みやその活用例、課題や将来の展望について詳しく解説します。さらには、AIのブラックボックス化などによる不透明性やデータの偏り、そして技術的課題にも触れ、LLMを正しく理解し使いこなすための知識を提供します。
これらの洞察は、技術の進展を追いかけ、その可能性を最大限に引き出したいと考える皆様にとって価値あるものになるはずです。ぜひ最後までお読みいただき、LLMに関する包括的な理解を深めてください。
大規模言語モデル(LLM)とは?
大規模言語モデル(Large Language Model: LLM)は、巨大なデータセットを用いてトレーニングされたAIモデルであり、人間のように自然言語を理解し生成する能力を持ちます。
これらのモデルは莫大な量のテキストデータを処理し、文章の要約、翻訳、質問応答、生成など、人間の言語に関連する幅広いタスクを実行することができます。
LLMの目的は、自然言語の複雑さと多様性を捉え、人間の書き手や対話者としての役割を模倣することです。
この技術を活用することで、ユーザーエクスペリエンスを向上させる対話システムや、人間の助けとなるビジネス自動化ツールなど、様々なアプリケーションでの使用が考えられます。
【関連記事】
➡️自然言語処理とは?AIが人間の言語を理解する仕組みをわかりやすく解説
大規模言語モデル(LLM)と生成AIの違い
LLMは言語の理解と生成に焦点を当てており、多様なテキストベースのタスクをこなすことができます。つまり、ある文脈における単語や文章を予測し、適切な応答を生成する能力を持っています。
一方で、生成AIは画像、音楽、動画など、より広範なコンテンツを生成するために設計されています。生成AIには、LLMの文脈理解の機能に加えて、画像合成、音声合成などの能力が含まれることがあります。
これらのモデルは、特定の入力に基づいて新しいコンテンツを「生成すること」に特化しており、ただテキストに答えるのではなく独自のコンテンツを作り出します。
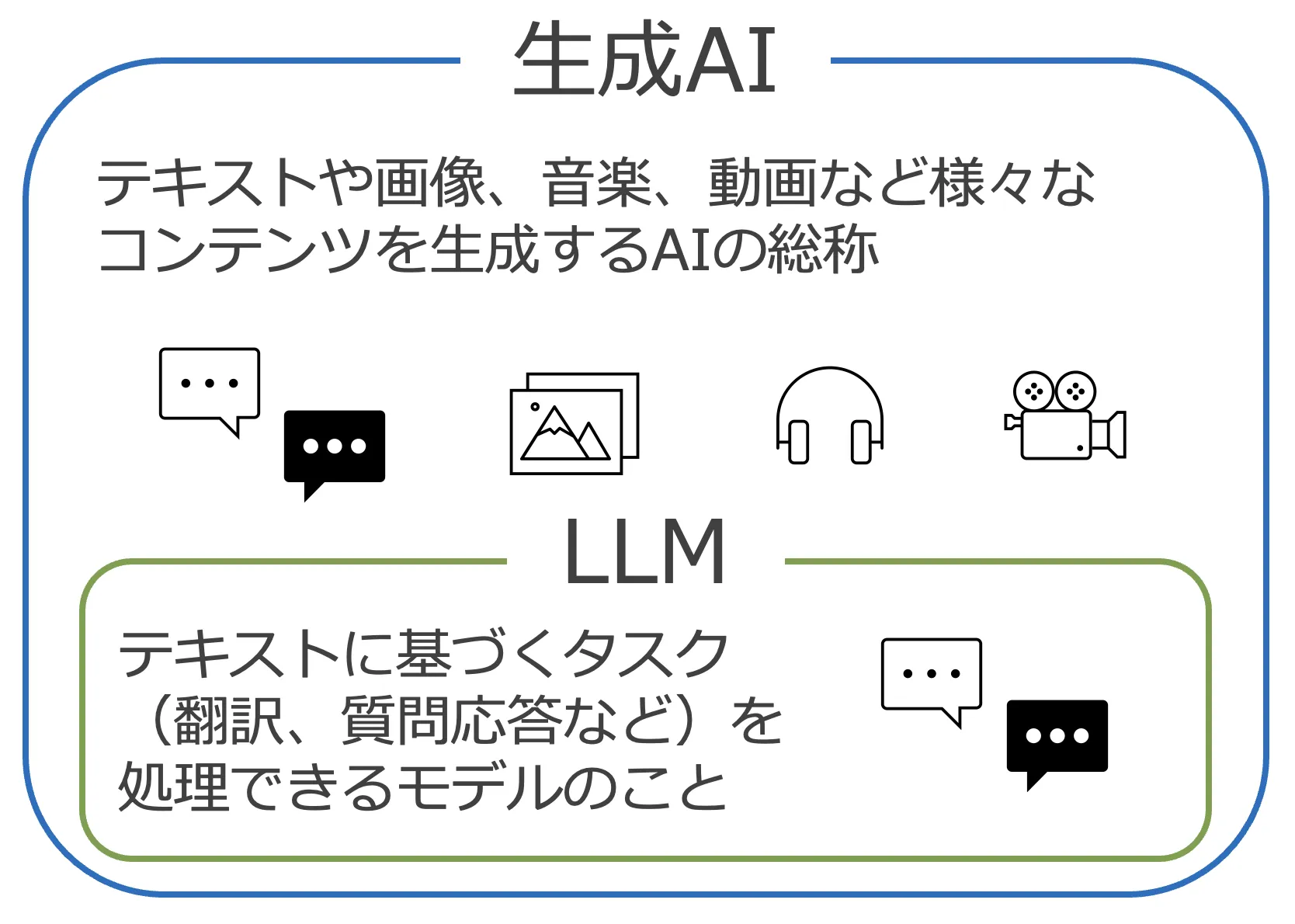
生成AIとLLMの関係
大規模言語モデル(LLM)とChatGPTの違い
LLMとChatGPTは、時に同じものとして言及されがちですが、根本的な違いが存在します。
LLMは、言語処理に特化し、非常に大規模なデータセットを使用して訓練されたAIモデルの総称です。
これに対し、ChatGPTは、特に対話形式のタスクに特化しており、OpenAIによって開発されたGPT(Generative Pre-trained Transformer)モデルの一つです。
【関連記事】
➡️生成AIと対話型AIの違いは?それぞれの特徴やメリットの観点から解説!
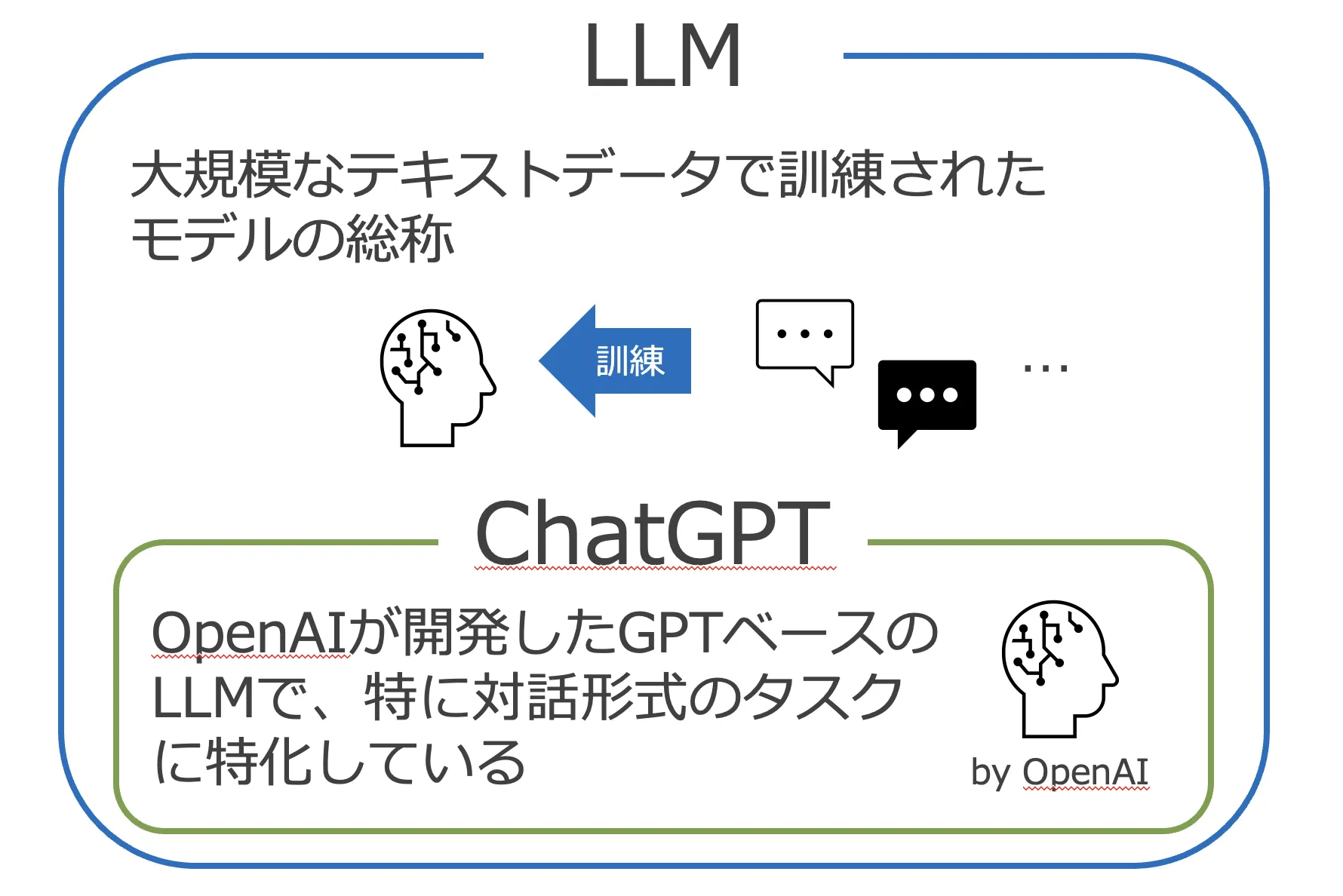
LLMとChatGPTの関係
大規模言語モデル(LLM)の仕組み
大規模言語モデル(LLM)の主な仕組みは、機械学習とディープラーニング、特にTransformerというアーキテクチャに基づいています。
Transformer
Transformerは、エンコーダーとデコーダーから成るニューラルネットワークアーキテクチャです。エンコーダーは入力を内部表現に変換し、デコーダーはその内部表現を使って出力を生成します。
主な要素は先ほど述べた自己注意機構で、各単語が他の単語とどれほど関連しているかを計算します。
これにより、長距離の文脈の依存関係を捉えることが可能になります。また、位置エンコーディングを使って単語の位置情報をモデルに組み込みます。Transformerは並列処理がしやすく、長いシーケンスにも適しています。
【関連記事】
→Transformerとは?モデルの概要やBERTとの違いをわかりやすく解説
LLMの学習方法
大規模言語モデル(LLM)の学習は、大量のテキストデータから言語パターンやルールを学ぶ処理です。例えば文章が与えられたときに、次の単語や文章を予測する能力を身につけます。
学習が進むにつれて、モデルはより複雑な言語パターンを捉え、さまざまな文脈で適切な予測ができるようになります。これにより、自然な文章を生成したり、翻訳したり、質問に回答したりするなど、さまざまな言語タスクを処理することができるようになります。
大規模言語モデル(LLM)の種類
大規模言語モデル(LLM)には様々な種類が存在し、それぞれ特定の機能に特化した設計がされています。
以下はLLMの代表的な種類です。
GPT
OpenAIによって開発されたGPT(Generative Pre-trained Transformer)はTransformerのデコーダーをベースにしたモデルです。それゆえに文章生成タスクを得意としています。
事前学習には大規模なテキストデータを用いて。ある文章に続く単語を予測することで言語生成能力を獲得しています。また、GPTはファインチューニングをすることでタスクの学習をしますが、GPT-2やGPT-3になると数例与える(Few-shot学習)だけでタスクを理解できるようになります。もちろんChatGPTもFew-Shot学習でタスクを理解し、応答を生成できます。
【関連記事】
→ChatGPTの仕組みは?図解を用いてわかりやすく解説!
BERT
BERT(Bidirectional Encoder Representations from Transformers)は、Googleが開発した自然言語処理のためのモデルです。
BERTは双方向のTransformerエンコーダーを使用し、大規模なテキストコーパスで事前訓練されます。
この事前訓練ではランダムにマスクされた単語を予測するタスク(穴埋めタスクのようなもの)と、2つの文のペアが連続しているかどうかを判定するタスクを通して知識を獲得します。
その後、事前訓練されたBERTモデルは、特定のNLPタスクにファインチューニングされます。これにより、BERTは幅広い言語表現を獲得し、文脈に応じた意味の理解や柔軟な言語処理が可能になります。
【関連記事】
➡️自然言語処理におけるBERTとは?その全貌をわかりやすく解説!
BART
BART(Bidirectionaland Auto-Regressive Transformers)は、Facebookが開発した系列変換モデルです。BARTは、エンコーダーデコーダーアーキテクチャを採用し、BERTと同様にTransformerをベースにしています。BARTは、入力文をエンコードし、それを再度デコードして元の文に戻すことで、文章の再構成や翻訳などのタスクに適しています。事前学習ではBERTと同様の単語のマスキングをはじめとし、単語の削除やシャッフルなどで破損させた文から元の文を復元することで知識を獲得します。BARTは、文章の生成、要約、質問応答などのタスクに適用され、幅広い生成タスクに役立ちます。
T5
T5(Text-to-Text Transfer Transformer)は、Googleによって開発された系列変換モデルです。T5は、あらゆる自然言語処理タスクをテキスト変換問題として統一的に捉えます。具体的には、入力文を与えられた形式に変換する問題とすることで、さまざまなNLPタスクを解決します。
T5は、Transformerアーキテクチャを採用し、大規模なデータセットでマスク部分を予測する事前訓練が行われます。事前訓練後、ファインチューニングを行うことで、特定のNLPタスクに適用されます。T5の特徴は、その統一的なアーキテクチャと柔軟性にあります。これにより、さまざまなタスクに対応することができ、事前学習されたモデルの再利用性が高まります。T5は、文章生成、翻訳、要約、質問応答などの様々なNLPタスクで広く使用されています。
関連論文
「Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer」
XLNet
XLNetは、Googleが開発したBERTとGPTという2つの主要な自然言語処理モデルに基づいて開発されました。XLNetは、BERTの双方向性とGPTの自己回帰性を組み合わせたモデルです。具体的には、XLNetはBERTと同様に双方向性の言語表現を学習しますが、GPTと同様に自己回帰的な予測タスクを使用します。また、XLNetでは文中の単語の順序をランダムに入れ替えることで、モデルが文脈の関係をより深く理解することを目指します。この組み合わせにより、XLNetは文脈を捉えつつも双方向性の利点を享受し、さまざまな自然言語処理タスクにおいて優れた性能を発揮します。
関連論文
「XLNet: Generalized Autoregressive Pretraining for Language Understanding」
tsuzumi
tsuzumiはNTTが開発した日本語に強い軽量の大規模言語モデルで、2024年3月から商用サービスが開始されます。最も大きな特徴はモデルが軽量であること(ChatGPTに用いられているGPT-3が1,750億パラメータであるのに対し、tsuzumiは6~70億パラメータ)で、これにより計算コスト(GPUなどの資源や電力など)を大幅に削減することができます。近年のLLMはパラメータのサイズを爆発的に増やすことで性能の向上が図られてきました。しかし、それには計算リソースの増加とエネルギー消費量増加という課題があります。そこでNTTは、パラメータを増加させるのではなく、日本語学習データの質と量を向上させるアプローチにより非常に軽量なモデルで高い日本語処理能力を実現しました。
主要な大規模言語モデル(LLM)サービス
ここでは、Web上で使える主要なLLMサービスを5つ紹介します。
ChatGPT
ChatGPTは、OpenAIが開発したLLMです。ChatGPTは自然言語やプログラムのコードを理解して生成し、流暢に応答することが可能です。
ChatGPTに使用されているモデルのうち、GPT-3.5は現在無料で使用することができます。
有料版であるChatGPT Plusでは、高性能かつ画像や音声などでも会話が可能なGPT-4を使用することが可能です。
参考文献:OpenAI Platform
【関連記事】
➡️ChatGPTとは?その機能・使い方を徹底解説!活用例も紹介
Gemini
Geminiは、Googleが開発したLLMです。Googleの中で最も高性能なLLMで、テキスト、画像、音声、動画、コードなど幅広いモダリティ全体でシームレスな推論をすることができます。
Geminiには3種類のモデルが展開されており、最も高性能かつ最大規模のGemini Ultra、幅広いタスクに最適なGemini Pro、オンデバイスタスク向けの最も効率的なGemini Nanoがあります。
Gemini Proモデルは無料で使用することができますが、月額2,900円でGemini Advancedにアップグレードすれば、Gemini Ultraを使用可能になるとともに、GmailやDocsなどでもGeminiを使用することができます(2024年3月8日時点)。
【関連記事】
➡️Geminiとは?その概要や日本語での使い方、料金体系を徹底解説
Copilot
Copilotは、Microsoftが開発したLLMベースのAIです。
テキスト、音声、画像を使用したチャットや、Windows, Edge, Bingなどへのアクセス、Webページの要約や画像生成などが可能です。
また、月額3,200円でCopilot Proにアップグレードでき、GPT-4およびGPT-4 Turboへの優先アクセスや、無料版に比べてより高速かつ多くの画像を生成することができます(2024年3月8日時点)。
さらに、Microsoftが提供する特定のサブスクリプションに加入することで、CopilotをMicrosoft 365アプリの中で使用することが可能となり、Word文書の代筆や、PowerPointでプレゼンテーションの作成などを行うことができます。
【関連記事】
➡️GPT-4搭載!Microsoft Copilotとは?できることや料金をわかりやすく解説
Azure OpenAI Service
Azure OpenAI ServiceもMicrosoftが提供しているAPIサービスで、GPT-4やGPT-3.5, DALL-EなどのOpenAIのモデルに対してAPIでのアクセスを提供しています。
Azure OpenAIでは、OpenAIモデルを利用できると同時に、プライベートネットワークやコンテンツフィルタリングなど、Azureが提供する堅牢なセキュリティ対策を組み合わせることが可能です。
さらに、Azure OpenAI Studioを活用することで、文の長さ、単語の繰り返しに対するペナルティ設定、モデルのファインチューニングなどを通じて、モデルを独自のニーズに合わせてカスタマイズすることができます。
料金は従量課金制で、使用したモデルとトークン数に応じて料金が加算されます。
【関連記事】
➡️Azure OpenAI Serviceとは?その機能や料金、活用方法を解説
Hugging Face Transformers
Hugging Face Transformersは、Hugging Faceという機械学習のためのモデルやデータセットなどを提供しているプラットフォームのうちの1つです。中でもTransformersでは最先端の学習済みモデルを手軽にダウンロードし、学習に活用できるAPIとツールを提供しています。
また、TransformersではBERTやBARTをはじめとした様々なモデルを使用することができ、rinnaやmetaのLlama2といった大規模言語モデルも使用可能です。
こちらは先ほど紹介した4つのサービスとは異なり、Web上でそのまま使用するわけではなく、手元にモデルをダウンロードして使用します。Hugging Face Transformersは自然言語処理の研究でもよく使用されています。
大規模言語モデル(LLM)の活用例とそのメリット
大規模言語モデル(LLM)はその先進性と汎用性のおかげで、様々な産業とビジネスプロセスに革命的な影響をもたらしています。以下ではLLMの活用例と主なメリットについて述べています。
-
コンテンツ生成
コンテンツ生成は、人工知能(AI)や大規模言語モデル(LLM)を活用して、記事、レポート、広告コピー、ソーシャルメディアの投稿など、さまざまな形式のコンテンツを自動的に生成するプロセスです。
これにより、マーケティングや報道などの分野で、大量のコンテンツを迅速かつ効率的に作成することが可能になります。LLMは自然言語処理の技術を駆使し、人間による手作業よりも迅速にコンテンツを生成します。
-
カスタマーサポート
カスタマーサポートは、顧客が商品やサービスに関する疑問や問題を解決するための支援を提供するプロセスです。ここで、LLMはチャットボットや自動応答システム**として活用されます。
顧客からの問い合わせに対して、事前に訓練されたモデルが適切な回答や解決策を提供し、24時間365日対応することが可能です。これにより、顧客満足度を向上させるとともに、企業の効率性を高めることができます。
-
翻訳
翻訳は、一つの言語から別の言語へのテキストの変換プロセスです。LLMを用いた翻訳では、高度な自然言語処理技術が利用されます。LLMは大規模な言語データセットを学習し、文脈を理解して適切な翻訳を生成します。
これにより、異なる言語間のコミュニケーションを円滑にし、国際的なビジネスや文化交流を促進します。
-
個人化されたレコメンデーション
個人化されたレコメンデーションは、ユーザーの個々の好みや興味に基づいて、製品やサービスを推奨するプロセスです。LLMはユーザーの過去の行動や嗜好を分析し、その情報に基づいた最適なレコメンデーションを提供します。これにより購買率や顧客満足度が向上します。
【関連記事】➡️レコメンドAIとは?その仕組みや種類、活用例を紹介!
-
データ分析
データ分析では、LLMは膨大なデータセットを解析し、重要な情報やトレンドを抽出します。LLMは自然言語処理技術を用いて、テキストデータや意見のマイニング、テキスト分類、要約などのタスクに活用されます。これにより、意思決定の支援や、問題の解決などに役立ちます。
-
検索エンジンやチャットボット
LLM(Large Language Model)は特に、検索エンジンやチャットボットなどの対話型アプリケーションでの利用において目覚ましい効果を発揮しています。検索エンジンでの利用では、ユーザーの自然言語のクエリ(調べる時に検索エンジンに入力する検索キーワードのこと)を解析し、より関連性の高い結果を迅速に提供するためにLLMが活用されます。これにより、ユーザーのニーズに即した情報を得やすくなります。
一方、チャットボットにおいては、LLMは顧客からの問い合わせに対してリアルタイムかつ自然で人間らしい対話を行うことが可能です。これによりカスタマーサポートなどで時間とコストの節約につなげることができます。また、人間のオペレーターに任せるべき複雑な問題を識別する能力も、チャットボットの機能として重要となります。
-
フリーマーケットサービスでの活用事例
ここで、身近で具体的に活用されている事例としてメルカリを見てみましょう。メルカリでは、2023年10月17日に生成AI・大規模言語モデル(LLM)を活用した、顧客一人ひとりのためのAIアシスタント機能「メルカリAIアシスト」の提供を開始しました。
メルカリAIアシストが持つ機能の第一弾として出品商品の改善提案機能が実装されています。これによって出品者は商品をより売れやすくなるような提案を受けることが出来ます。
メルカリAIアシスト
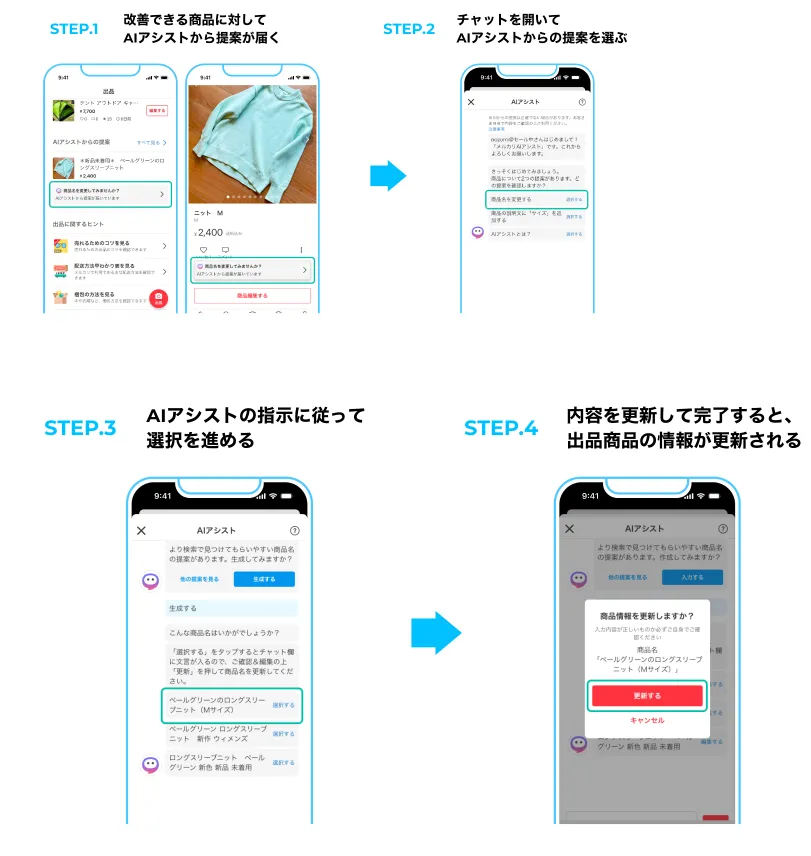
出品商品の改善提案機能
出典:メルカリ、生成AI・LLMを活用してお客さまの最適な行動を促す「メルカリAIアシスト」の提供を開始
LLMの課題
大規模言語モデル(LLM)には多くの有能な特徴がある一方で、現実的な課題も存在します。LLMは膨大な量のデータを処理し学習するため、データの品質や、偏りのない多様性が求められます。
また、訓練に必要な計算資源は高コストで、環境への影響も無視できません。
以下では、これらをはじめとするLLMの課題について詳しく紹介します。
生成コンテンツの不透明性
LLMが生成するコンテンツはどのような過程を踏んで応答が得られたのかがわからず、その不透明性が課題となっています。LLMの内部構造は複雑なニューラルネットワークで構成され、膨大な量のパラメータを持っています。
この内部構造は一般的にブラックボックスとして扱われ、特定の入力に対して得られる出力の過程を完全に理解することが困難です。
さらに、LLMは大量のデータを学習し、訓練データのバイアスやエラーが生成されるコンテンツに影響を与える可能性があります。以上のことからLLMによるコンテンツの生成過程は不透明となります。
これらの不透明性は、LLMが生成するコンテンツの品質や信頼性を保証することを困難にします。生成されたコンテンツが適切であるかどうかを判断するためには、人間の判断や追加の検証が必要になる場合があります。
そのため、LLMを使用する際には、その不透明性を認識し、慎重な判断が必要です。
また、そのような生成AIに関する判断力や知識、活用スキルを身につけるために、一般社団法人生成AI活用普及協会により**生成AIパスポート試験**が実施されています。
ハルシネーションやプロンプトインジェクションなどの技術的問題点
ハルシネーションとは、「モデルが事実に基づかない情報、簡潔に言うと嘘を生成してしまう問題」です。LLMは莫大な量のデータセットにより訓練されますが、それでも得られなかった未知の知識については、なんの根拠もなくそれらしい応答を生成してしまうことがあります。
このような問題は、誤った情報を提供することで人間の意思決定や行動に影響を与えることになり、特に正確な情報や専門知識が求められる場面において重大な被害を引き起こす可能性があります。
プロンプトインジェクションは、ユーザーが特定の入力をすることで、言語モデルが開発者の意図しない回答を生成する攻撃手法です。ユーザーが特定のプロンプトを与えることで、モデルが秘密情報を漏洩させたり、予期しない行動を取る可能性があります。
これらの課題は、学習データの質の向上や量の増加などにより対策をすることは可能ですが、完璧に対応するのは非常に困難です。そのため、現在盛んにこれらの課題に対する技術が調査・研究されています。
【関連記事】
➡️ハルシネーションとは?その原因やリスク、対策方法を解説
学習データの偏りや言語精度の問題
LLMの性能においては、モデルの訓練に使用されるデータの品質も重要な要素となります。データセットに偏りがある場合、LLMはバイアスを持った情報を学習し、偏りを反映した出力を生成してしまう可能性があります。
これは、社会性や文化的側面において問題を引き起こすだけでなく、モデルの汎用性にも影響を与えます。
また、言語の細かなニュアンスや意味の理解、特に異なる言語や方言、専門用語を含むテキストの処理においても、精度の向上が求められています。
文脈に応じた適切な表現を生成するためにはまだ多くの改善が必要で、これが実現されればより自然で汎用性のある対話が可能になると期待されます。
情報の鮮度
LLMは膨大なデータセットで事前に訓練されるため、訓練時から時間が経過するとモデルの言語表現や知識が古くなり、出力の品質が低下する可能性があります。最新の情報やトレンドが反映できないため、最新の文脈やニーズに対応できず、信頼性が損なわれる恐れがあります。
そのため、定期的なデータの更新やファインチューニングが重要となります。
このようなLLMが最新情報を扱えないという問題を解決するために、**RAGアーキテクチャ**というものが利用されています。RAGは、取得した情報をLLMに与えることで、クエリに対してより適切な応答を生成する技術となっています。
これにより、莫大なパラメータを持つLLMをわざわざ訓練し直したりファインチューニングしたりせずに最新情報を反映させた応答を生成することが可能になります。
LLMの今後の展望
LLMは強力な性能を発揮しており、実社会でも様々な場面で役立っていますが、一方でLLMを使用するにあたっての注意点や課題なども多く存在します。ここでは、そんなLLMについての今後の展望と付き合い方について焦点を当てて紹介します。
-
性能の向上と応用の拡大
LLMの性能は着実に向上し続けており、LLMの性能調査や、その性能を活かして使いこなすための研究も盛んに行われています。将来的には、より高度なタスクや領域においても、より精度の高い予測や生成が可能になると期待されています。
-
倫理と透明性の向上
LLMが生成するコンテンツに対する倫理的な問題や透明性の欠如に対処するための取り組みが進んでいます。これには、バイアスの除去や誤った情報の検出、生成されたコンテンツの説明可能性の向上などが含まれます。
-
LLMを活用した創作活動
LLMを活用した創作活動では、魅力的なキャラクターやストーリーの創作、作詞などが行われています。クリエイターは、LLMが提供する新たなアイデアや素材を基に、より洗練された作品を構築することが期待できます。
-
倫理的な使用
LLMの使用には、データの適切な管理や保護が欠かせません。アクセス制御、暗号化、匿名化などの手法を用いて、個人情報や機密情報を適切に管理し、不正アクセスやデータ漏洩のリスクを最小限に抑える必要があります。また、LLMが生成するコンテンツの信頼性を確保するため、コンテンツの生成過程が透明性を持ち、説明可能であることが重要となってきます。さらに、LLMの使用には常に人間によるチェックや評価が必要となり、意図しない結果や倫理的な問題が発生した場合には、迅速に対処する必要があります。
-
LLMに関する知識の教育
LLMを正しく活用するためには、ユーザーに対する適切な教育と訓練が必要です。モデルの機能や制限、適切な使用方法についての理解を深めることで、効果的な活用が可能です。また、倫理的な問題への対処も重要であり、ユーザーには倫理的なガイドラインや規制についても教育する必要があります。

まとめ
本記事では、大規模言語モデル(LLM)の基本的な概念や仕組み、活用方法や課題、将来の展望などについて解説しました。LLMは、膨大なデータを学習して自然な文章を生成することができ、その性能の高さから様々な分野での応用が期待されます。しかし、その利用には計算コストや応答の透明性、倫理的な問題、訓練データの質などに対して対策することが重要です。将来的には、LLMの精度を向上させることはもちろん、それを使う側の人間の教育も重要となります。
この知識を基に、読者の皆様にはLLMの機能、影響力、そして将来性についてより深い洞察を提供することを願っています。AIがもたらす無限の可能性に目を向けると共に、その責任ある使用と持続可能な発展のバランスを見極めることが、我々の未来にとって重要です。










