この記事のポイント
 マルチモーダルAIは、テキスト、画像、音声など異なる種類のデータを統合して処理するAI技術
マルチモーダルAIは、テキスト、画像、音声など異なる種類のデータを統合して処理するAI技術- Azure OpenAI ServiceやGoogle Geminiなど、主要なマルチモーダルAIプラットフォームを紹介
- 教育、ヘルスケア、顧客サービスなど、様々な分野での具体的な活用事例を解説
- プライバシーと倫理的問題が主要な課題であり、適切な対策が必要
- AI搭載メガネ「Frame」など、革新的なデバイスの登場により、生活への影響が拡大

監修者プロフィール
坂本 将磨
Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
マルチモーダルAIは、テキスト、画像、音声など異なる種類のデータを統合して処理できるAI技術です。例えば、医療や教育分野での利用を通じて、より精度の高い診断や個別化された学習経験の提供が可能になっています。
本記事では、マルチモーダルAIの基本概念から最新の活用事例まで、幅広く解説します。同時に、この技術の発展に伴って生じるプライバシーや倫理的な課題についても言及し、バランスの取れた発展の必要性を訴えます。
本記事を通じて、読者の皆様にマルチモーダルAIの可能性と課題について理解を深めていただければ幸いです。
目次
マルチモーダルAIとは
マルチモーダルAI(multimodal AI)は、複数の異なるモーダリティ(音声や画像、テキスト)を組み合わせて情報を処理し、理解する人工知能(AI)のことです。
例えば、会話の中で言葉だけでなく相手の表情や声のトーン、場の雰囲気などを考慮して意味を理解するように、マルチモーダルAIも複数の情報を統合してより深い理解を得ることができます。
そのため、現実世界での複雑な状況に適応し、活動する上で非常に重要な技術となっています。
マルチモーダルAIとシングルモーダルAIの違い
マルチモーダルAIは複数の情報源に対応していますが、シングルモーダルAIは対照的に1種類の情報(画像のみ、音源のみなど)を処理します。
以下はマルチモーダルAIとシングルモーダルAIの違いを比較した表です。
| 特徴 | マルチモーダルAI | シングルモーダルAI |
|---|---|---|
| データの扱い | 複数の異なる種類のデータを統合。 | 一つの種類のデータに特化。 |
| 使用例 | テキスト、音声、画像、動画、センサ情報など。 | テキスト、音声、画像、動画などの一つの種類のデータ。 |
| 情報の処理方法 | 複数のモダリティを統合して処理。 | 単一のモダリティを対象として処理。 |
| 応用分野 | 自動運転、ロボティクス、医療など。 | 音声認識、画像認識、自然言語処理など。 |
このように、マルチモーダルAIとシングルモーダルAIは使用目的によって使い分けることが出来ます。
マルチモーダルAIの多次元的なアプローチは、AIが人のように感じ、学び、理解することを目指す、より高度な人工知能への道を示しています。
《遂にChatGPT Plusユーザーに解放された”DALL-E3”が区分されるマルチモーダルAIとは?》数値/音声/テキスト/画像など複数種類のデータを組み合わせて、処理する AIモデル。人間のようなインプット情報の多様性がシングルモーダルAIとの大きな違いです。では、マルチモーダルAIの代表例は?↓ pic.twitter.com/n5edYs70PD
— 坂本将磨@AI導入をもっと身近に (@LinkX_group) October 20, 2023
代表的なマルチモーダルAIプラットフォーム
このセクションでは、マルチモーダルAIを利用できるプラットフォームやサービスについて詳しく解説しています。
これらのプラットフォームは、開発者が複雑なAIモデルを独自に設計・トレーニングする手間を省き、ビジネスや研究目的でのAI導入を促進しています。
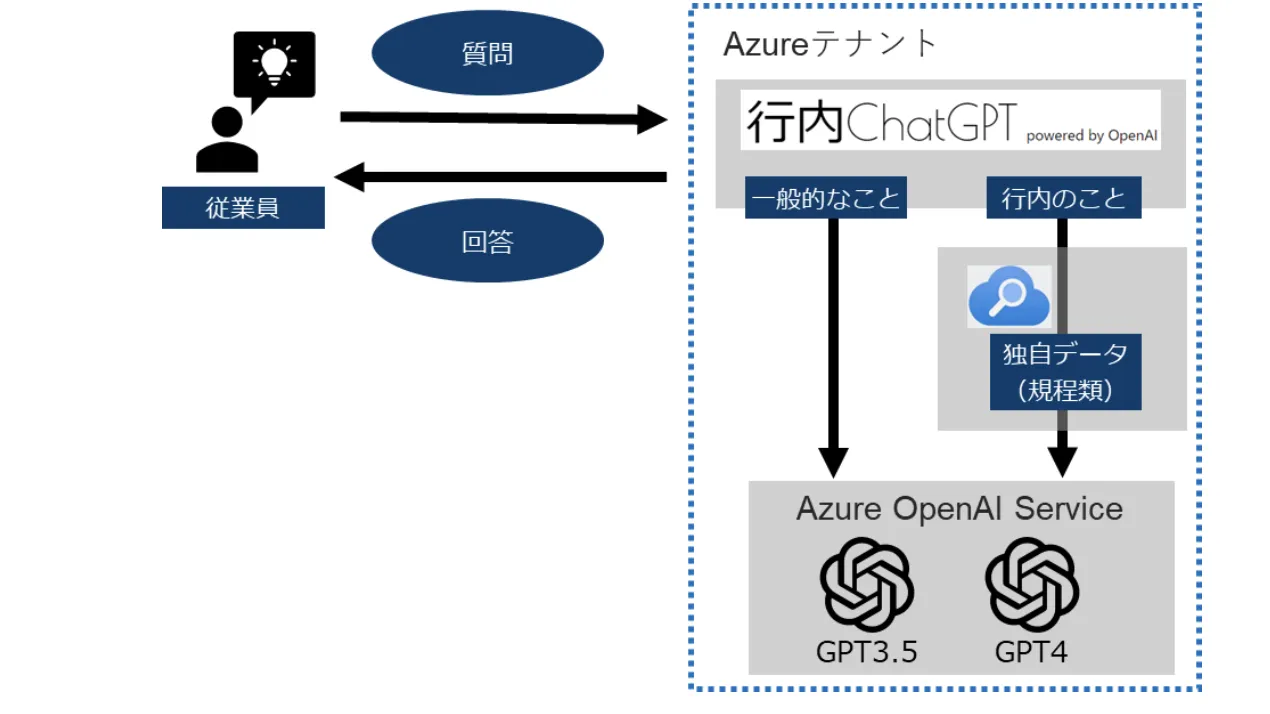
Azure OpenAI Service
Azure OpenAI ServiceとはMicrosoft Azureプラットフォーム上で提供されるOpenAIのサービスです。
最近 周りで「AOAI」(エーオーエーアイ) ってよく聞く👂
— ちょまど@育休中エンジニア (@chomado) September 13, 2023
「Azure OpenAI」の略なんだね💡
(OpenAI の ChatGPTやGPT-4をはじめとする多様な生成AIモデルを、
Microsoft Azure のクラウドプラットフォーム上で利用できるサービス。
Azure のセキュリティの機能が使えたりなどとても便利)
これにより、開発者や企業はOpenAIの強力な人工知能モデルやツールを利用して、さまざまなAIプロジェクトを構築し、展開することができます。
Azure OpenAI Service 主な特徴
オンデマンドの AI モデル
- GPT-4 などの最新の AI モデルにアクセス可能。
API ベースのアクセス
- REST APIを使用して簡単にアクセス可能。
カスタムモデルの構築
- ユーザー独自のモデルを構築し、展開するための機能。
Azure OpenAI Service を使用すると、"微調整" と呼ばれるプロセスを使用して、個人用データセットに合わせてモデルを調整できます。(公式ホームページより引用)

カスタマイズすることで得られる機能 (参考:Microsoft)
多様な言語サポート
- 多言語での自然な文章生成や理解が可能です。
-
Azure OpenAI Serviceは広く使用されている言語(英語、スペイン語、中国語、フランス語、ドイツ語など)を含む幅広い言語を扱うことができます。
-
Azure OpenAI サービスのサポートされているプログラミング言語
Azure OpenAI サービスの対応言語
- Python
- C#
- JavaScript
- PHP
- Perl
リアルタイム処理サポート
- リアルタイムでの応答が必要なアプリケーションに適した処理をサポート。
Azure OpenAI Serviceは、チャットボットを活用して顧客との対話を改善し、リアルタイムでの問題解決を支援しています。
セキュリティとプライバシー
- 高度なセキュリティ機能とプライバシー保護が提供されている。
ユーザーのトレーニングデータは、そのユーザーのモデルのファインチューニングにのみ使用されます。
つまり、ユーザーのデータはそのユーザーのためにのみ利用され、他の目的には使用されません。
シンプルな料金体系
- 利用量に応じた従量課金制で、柔軟な料金プランが提供されています。
以下は2024年3月28日現在の料金体系です。
| モデル | コンテキスト | Input (Per 1,000 tokens) | Output (Per 1,000 tokens) |
|---|---|---|---|
| GPT-3.5-Turbo-0125 | 16K | ❌ 該当なし | ❌ 該当なし |
| GPT-3.5-Turbo-Instruct | 4K | ❌ 該当なし | ❌ 該当なし |
| GPT-4-Turbo | 128K | ❌ 該当なし | ❌ 該当なし |
| GPT-4-Turbo-Vision | 128K | ❌ 該当なし | ❌ 該当なし |
| GPT-4 | 8K | 💡 ¥4.513 | 💡 ¥9.026 |
| GPT-4 | 32K | 💡 ¥9.026 | 💡 ¥18.052 |
【関連記事】
➡️Azure OpenAI Serviceとは?その機能や料金、活用方法を解説
Google Gemini
Google Gemini(旧Goggle Bard)は、Googleが開発したマルチモーダルAIです。
この技術は、自然言語処理(NLP)、音声認識、画像認識などの複数のモーダルを統合し、より人間らしい対話型インタラクションを可能にします。
Google Geminiの主な特徴
多言語サポート
- Azure OpenAI Serviceと同様、Geminiも複数の言語に対応しており、世界中のユーザーにとってアクセスしやすいです。
3種類のモデル
- Geminiは、「Gemini Nano」「Gemini Pro」「Gemini Ultra」の3種類のモデルが用意されています。
高度なマルチモーダル技術
- Geminiはマルチモーダルなアプローチを採用しており、テキストだけでなく、画像などの複数のモーダルに対応しています。
マルチモーダルのGemini 1.5は英語の動画をあげ、日本語でざっと説明してもらう時も大変便利✨。マルチモーダルなので、動画にあるソースコードまで引っ張ってきて解説をしてくれる😮。Python講義動画の日本語ガイドを書いてもらった時の様子↓。Gemini 1.5はこれからの学びの形を大きく変えます🚀。 https://t.co/hTpjSRJjjA pic.twitter.com/VVvRDqVhg7
— sangmin.eth | Dify Ambassador (@gijigae) February 29, 2024
性能向上
- Geminiは連続的な改良を重ね、性能が向上しています。
最新のバージョンでは大幅な性能向上が実現されています。
従来のマルチモーダルが複数モデルを組み合わせて作られたのに対し、Geminiは最初からマルチモーダルの生成AIとして設計+学習されてる📺↓。ゆえに、上述したPythonの講義動画も音声に加え、画像まで完璧に処理できる。2024年、多くの人の働き方や生活の仕方が本格的に変わります。 pic.twitter.com/BlJhJjCNvO
— sangmin.eth | Dify Ambassador (@gijigae) February 29, 2024
【関連記事】
➡️Geminiとは?その概要や日本語での使い方、料金体系を徹底解説
マルチモーダルAIの活用事例【業界別】
ここではマルチモーダルAIが実際の業務や日常生活のさまざまなシーンで具体的にどのように活用されているかの事例をご紹介します。
教育分野
教育分野においてマルチモーダルAIは、学生がテキスト、画像、音声など異なるフォーマットの教材を活用する際に、個々の学習スタイルに合わせたカスタマイズされた経験を提供することができます。
実例としては、英語教育におけるマルチモーダルAIの活用が挙げられます。
世界中で高い人気を誇る語学学習アプリのDuolingoはGPT-4使った新サービスDuolingo Max発表しました。
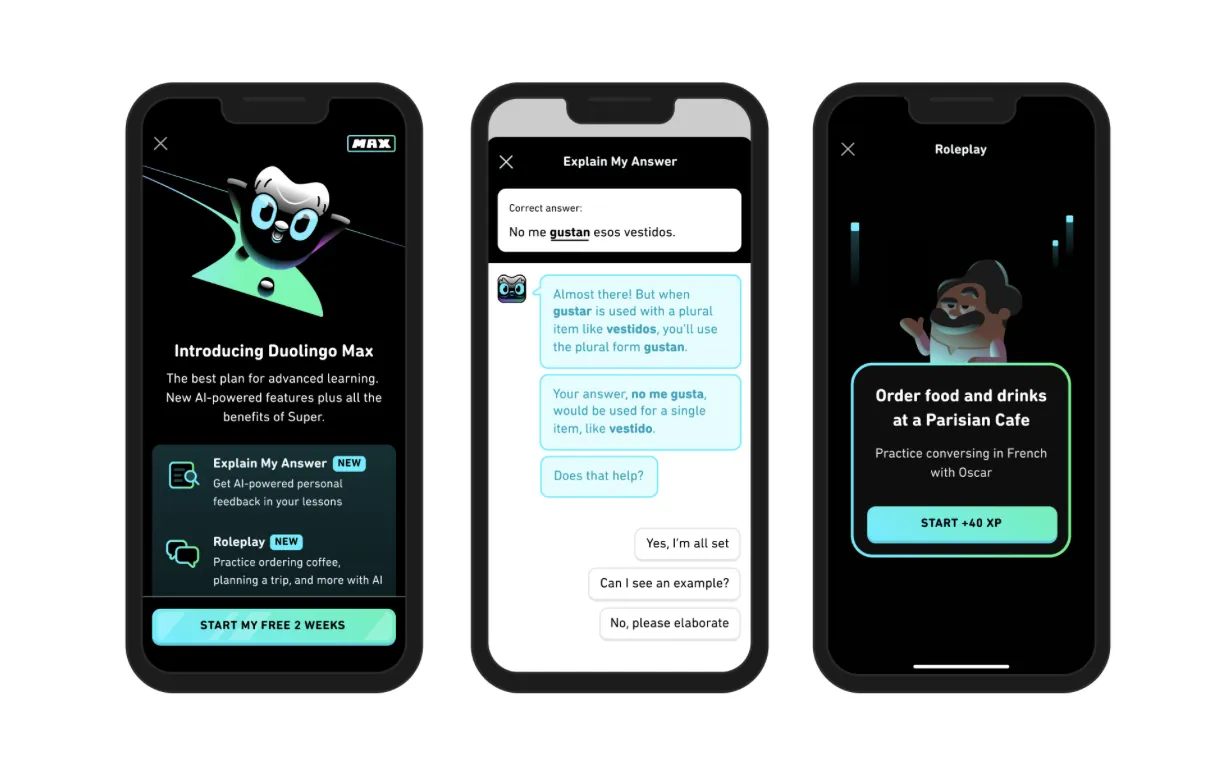
Duolingo Max (参考:Duolingo)
Duolingo Maxは、言語学習をゲーム感覚で楽しく、効果的に行えるように設計されており、ユーザーは、テキスト、音声、画像などの複数のモーダルを使用して、言語を学ぶことができます。
また、ユーザーの進捗状況に応じてカスタマイズされた学習プランを提供し、継続的なモチベーションを促進しています。
ヘルスケア分野
次にヘルスケア業界でのマルチモーダルAIの活用方法をご紹介します。
ヘルスケア業界では、複数の情報源からデータを収集し、マルチモーダルAIを活用して診断精度を向上させています。
これにより、症状の詳細な分析が可能になり、個別化された治療計画の策定が実現可能です。
2023年の日本医科大の事例
2023年6月13日、日本医科大は前立腺がん検査で画期的なマルチモーダルAIを導入。
従来の検査では個々のデータが分析され統合されなかったが、マルチモーダルAIはMRI画像、血液検査結果、臨床データなどを同時に統合解析し、前立腺がんの診断精度向上が期待される。
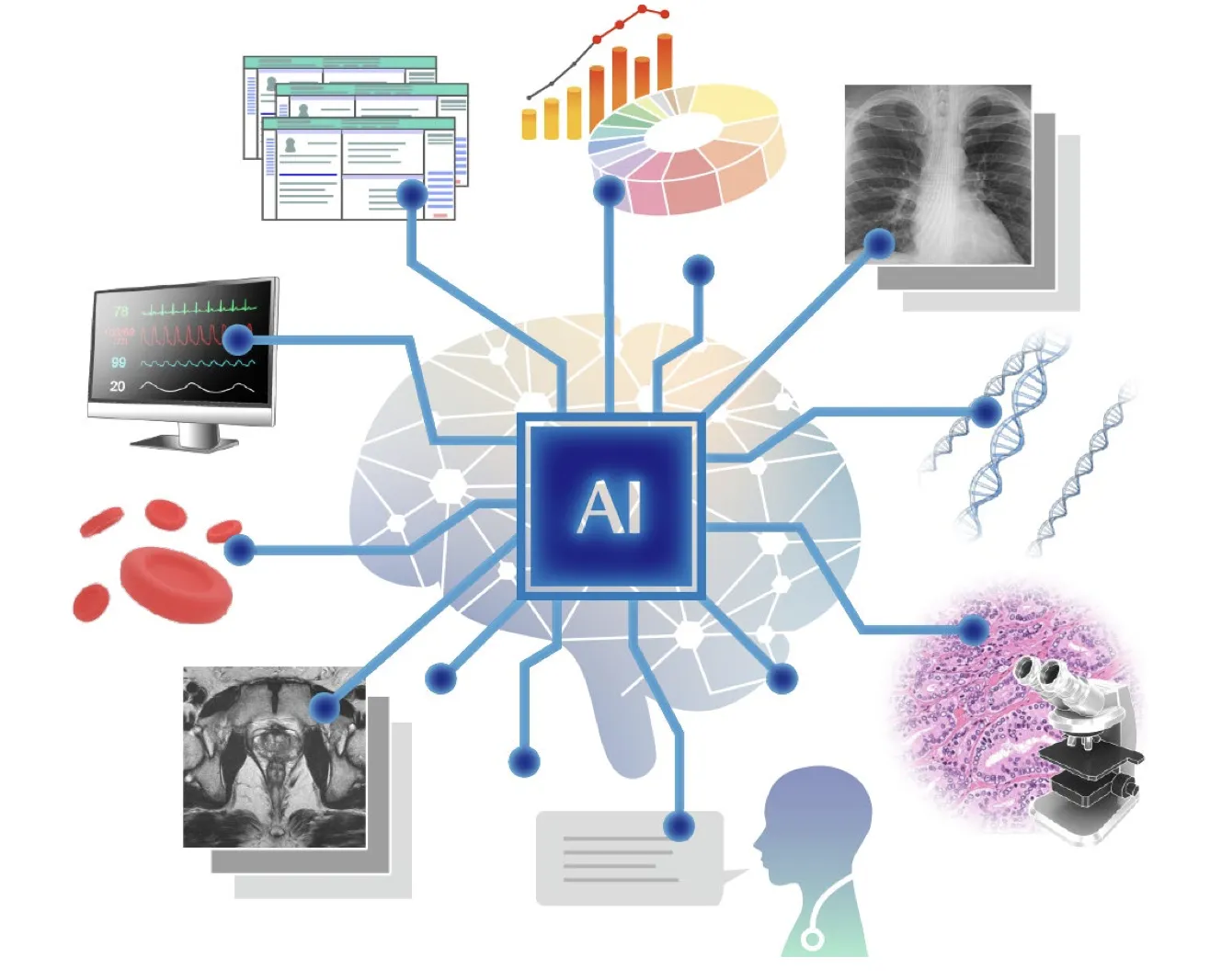
医療ビッグデータを多角的に解析 (引用:日本医科大学)
このようなAIの統合解析は、最適な治療法の選択や病気の進行予測にも役立つと期待できます。
NEC、理化学研究所、日本医科大学が、前立腺がんの医療ビッグデータを多角的に構築するマルチモーダルAIを構築!
— ヒロシズ💊製薬事業開発 (@Hiro_health_biz) June 20, 2023
✓複数のデータ形式を統合して高度な認識や理解を実現するAI
✓既存手法よりも再発予測精度を10%向上
こんな解析手法があるのか…勉強になります🤔https://t.co/XZNtVIuf2F pic.twitter.com/r5znXtv7am
顧客サービス分野
顧客サービスでは、音声認識と自然言語理解を組み合わせたチャットボットや仮想アシスタントが利用され、より自然で効果的なユーザー対話を実現しています。
また、顧客の感情を分析することにより、そのフィードバックをより正確に捉え、サービス改善に役立てることができます。
例えば、AimeHotelは、ホテルのさまざまなタスク(チェックイン、チェックアウト、部屋の予約、レストランの予約など、)を自動化できるバーチャルAI受付ソフトウェアを開発しました。
このようにして、マルチモーダルAIは人々の生活や仕事の質を向上させるために日々活用されており、その潜在的な活用シナリオは無限に広がっています。
マルチモーダルAIの課題と今後の展望
マルチモーダルAIは多くの可能性を秘めていますが、依然として克服すべき課題が存在します。
これらの技術的な障壁は、今後の研究と開発の重要な焦点となっています。
プライバシーと倫理
マルチモーダルAIの急速な進化は、私たちの生活を変える可能性を秘めていますが、同時にプライバシーの侵害や倫理的な問題も浮上しています。
実際に、2022年4月8日に日本空港ビルデングが発表した顔認証システムの個人情報流出事件は、この問題の深刻さを浮き彫りにしました。
特に、顔認識技術や音声認識技術は、個人を特定するのに十分な情報を含んでおり、これらのデータが不正に収集または利用される可能性を否定できません。
これらの挑戦に対処するために、技術の開発者や政府はデータセキュリティの強化、規制の導入、個人情報の厳格な保護など、さまざまな対策を講じる必要があります。
透明性と倫理的なアプローチが重視される中、私たちは技術の発展と個人の権利のバランスを保つために努めるべきです。
研究と技術の進歩
世界中でマルチモーダルAIに関する研究が進行中であり、新しいアルゴリズムの開発、コンピューティングパワーの増強、より効率的なデータ統合の方法など、さまざまな技術革新が期待されています。
最近では、AIデバイス企業 Brilliant Labsが、世界初のマルチモーダルAI搭載グラス「Frame」を発表しました。
このメガネをかけると目に見えるものを解析し、ウェブ検索、文字翻訳、画像生成が可能です。
Just tried on a prototype pair of Frame glasses from Brilliant Labs, an upcoming pair of smart glasses that can do image recognition, translation, text overlay, but in a very, very light and thin frame. pic.twitter.com/cRIo8xO59w
— ben sin (@bencsin) February 27, 2024
今後の展望に目を向けると、マルチモーダルAIは自然言語処理、コンピュータビジョン、感情分析などの分野がさらに発展することで、より人間と相互作用し、私たちの生活を豊かにするパートナーとなることが期待されています。
まとめ
本記事では、マルチモーダルAIについて基本的な情報から、代表的なプラットフォーム、そして課題と展望について幅広く解説しました。
マルチモーダルAIは、テキスト、画像、音声など複数のデータモードを統合することで、AI技術の新たな可能性を開拓しています。
また、マルチモーダルAIの応用例として、AI搭載メガネの「Frame」が紹介されました。これは目の前の情報を解析し、ウェブ検索や文字翻訳、画像生成などを行う画期的なデバイスです。
多くの研究者がマルチモーダルAIに取り組んでおり、今後はさらなる技術革新が期待されます。マルチモーダルAIの発展は、私たちの生活をより便利に、より豊かにすることが期待されます。