この記事のポイント
 ComfyUIは、ノードベースの直感的なインターフェースでAI画像生成を効率化できるオープンソースツール
ComfyUIは、ノードベースの直感的なインターフェースでAI画像生成を効率化できるオープンソースツール- ノードベースのインターフェースで、画像生成プロセスを視覚的に構築・管理可能
- Stable Diffusion、VAE、LoRAなど、多様なモデルを柔軟に組み合わせて高品質な画像を生成
- txt2img、img2imgなど、様々な画像生成手法に対応し、豊富なカスタムノードで機能拡張が可能
- ComfyUI Managerを使用することで、必要な拡張機能を簡単にインストール・管理可能

Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
クリエイティブな画像生成の需要が高まる中、より使いやすく柔軟なAIツールが求められています。
そんな中で注目を集めているのが、ノードベースの直感的なインターフェースを特徴とする「ComfyUI」です。
しかし、その豊富な機能や設定方法について、どこから始めればよいか迷われている方も多いのではないでしょうか。
本記事では、ComfyUIの基本概念から実践的な使い方まで、詳しく解説します。インストール手順や基本的な画像生成の方法はもちろん、モデルやVAEの効果的な活用法、カスタムノードによる機能拡張まで、具体的な例を交えて紹介します。
特に、2024年10月にリリースされた最新バージョン「ComfyUI V1」の新機能や、テキストから画像生成(txt2img)、画像から画像生成(img2img)といった実践的な活用シーンについても詳しく説明していきます。
AI画像生成ツールの導入を検討されている方々に、本記事がComfyUIを理解し効果的に活用するための手引きとなれば幸いです。
ComfyUIとは
ComfyUI(コンフィユーアイ)は、AIを活用した画像生成に特化したユーザーインターフェイスで、特に「Stable Diffusion」などの生成モデルを簡単に操作できるよう設計されています。
このツールは、直感的なインターフェイスを提供し、技術的なバックグラウンドがなくても、誰でも手軽に高品質な画像を生成することが可能です。
ComfyUIの魅力は、その使いやすさと、ユーザーが必要とする調整や指示を自然言語で簡単に行える点にあります。これにより、AI画像生成のプロセスがより身近で効果的なものとなっています。

ComfyUI V1のリリースについて
2024年10月21日に、ComfyUIを開発、メンテナンスしているComfy Orgより、最新アップデートとしてComfyUI V1のリリースがアナウンスされました。
ComfyUI V1になることで、主に以下のようなアップデートが行われます。
新しいユーザーインターフェース
UIが一新され、より使いやすくなりました。
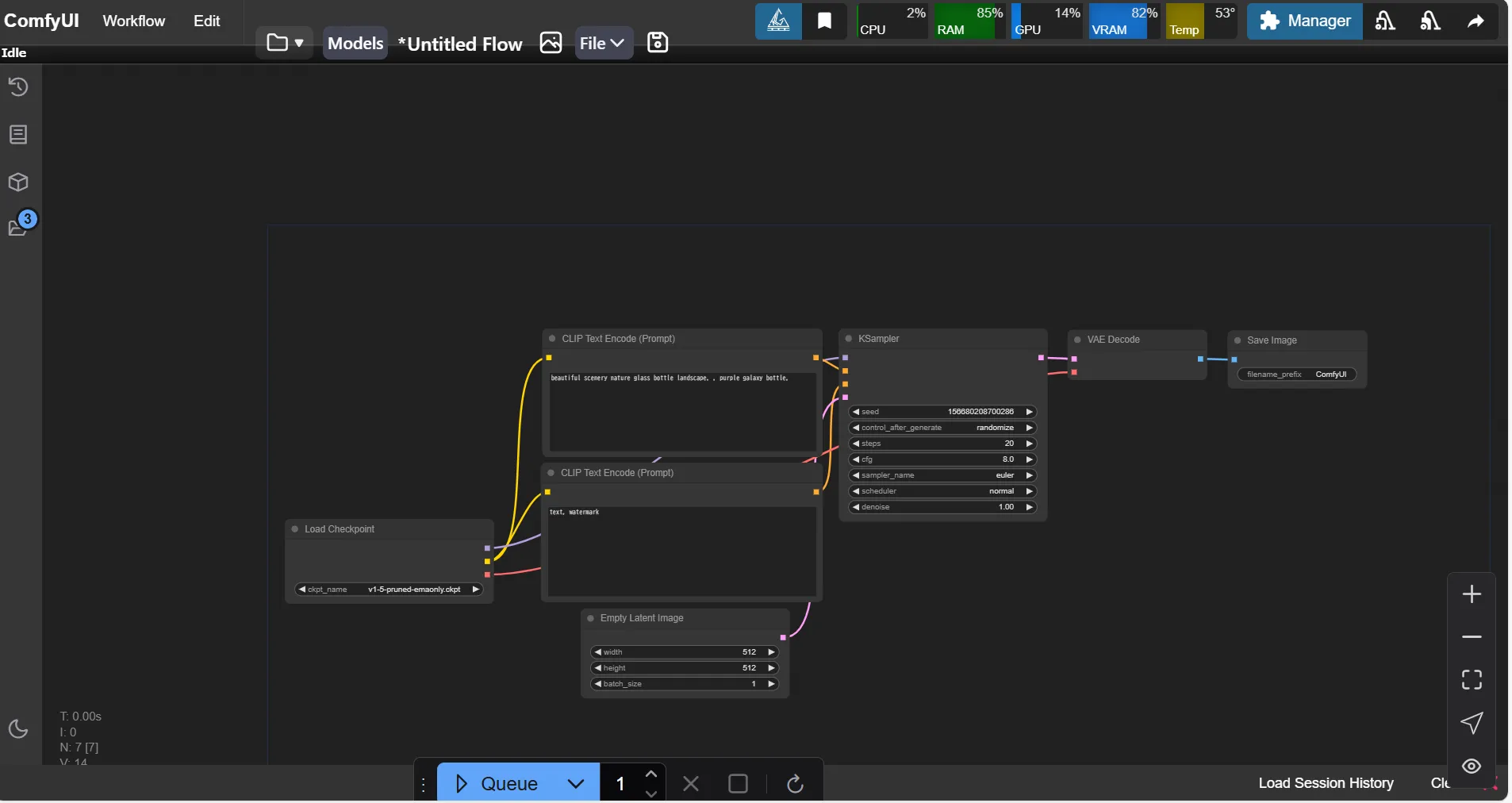
ComfyUI V1のUI
新しいUIには、以下のような特徴があります。
| 機能 | 説明 |
|---|---|
| トップメニューバー | 多くの操作をメニューバーに統合、カスタムメニュー追加が容易 |
| モデルやログへの簡単アクセス | トレイアイコン右クリックで迅速にアクセス |
| モデルライブラリ | モデルのブラウズとドラッグ&ドロップが可能 |
| ワークフローブラウザ | ワークフローの保存・管理が簡単に |
| 自動モデルダウンロード | 不足しているモデルの自動ダウンロード機能 |
完全にパッケージ化されたデスクトップバージョン
ComfyUIのデスクトップバージョンがリリースされます。このデスクトップバージョンには、以下のような特徴があります。
| 機能 | 説明 |
|---|---|
| コード署名とセキュリティ | ComfyUIはセキュリティ警告なしで起動し、コード署名済み |
| クロスプラットフォーム | Windows、macOS、Linux対応 |
| 自動更新 | 常に最新バージョンに自動更新 |
| 軽量パッケージ | 200MBの小サイズ |
| 推奨Python環境同梱 | 簡単インストール |
| ComfyUIマネージャー搭載 | 最新ノードを簡単インストール |
| タブ機能 | 複数ワークフロー管理 |
| カスタムキーバインド | 自由に設定可能 |
| リソース自動インポート | 既存データを自動インポート |
| 統合ログビューア | デバッグ用ログ表示 |
このデスクトップバージョンは、クローズドベータとして既にリリースされています。今後は、オープンベータ版をリリースし、その際にソースコードもオープンソース化する予定だそうです。
以上が、ComfyUI V1の主な新機能と改善点です。このリリースにより、ユーザー体験が大幅に向上し、技術的な知識がない方でも簡単に利用できるようになりました。
公式のアナウンスに関してはこちらをご覧下さい。

ComfyUIの主要機能
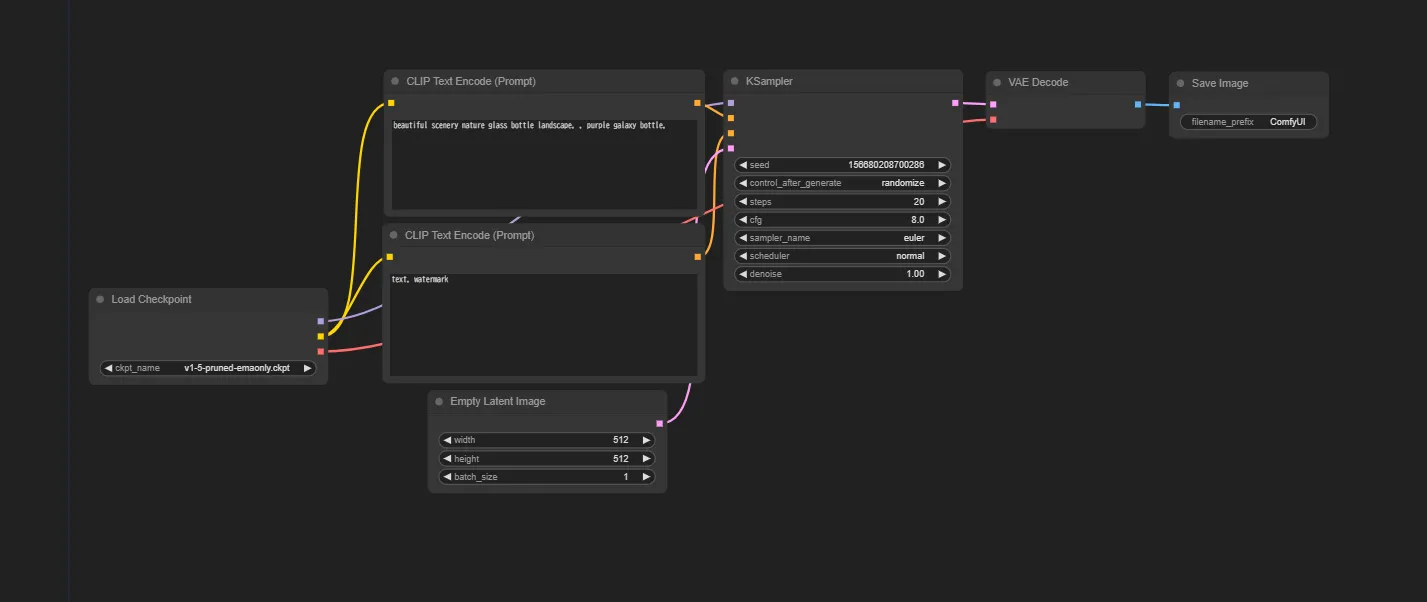 ComfyUIの画面
ComfyUIの画面
ノードベースのワークフロー
ComfyUIは、ノードベースのインターフェイスを採用しており、ユーザーは視覚的にワークフローを構築することができます。こ
れにより、複雑な画像生成プロセスをシンプルに理解し、操作することが可能です。
カスタマイズ可能なフィルターとエフェクト
色調整やエフェクト、フィルターの適用など、多彩なオプションが用意されており、ユーザーは自分のニーズに合わせて画像を微調整できます。
多言語対応の指示入力
自然言語での指示入力をサポートしており、日本語や英語など、ユーザーが慣れ親しんだ言語でAIに指示を与えることができます。
高度な設定オプション
上級者向けに、より細かいパラメータ設定や、複数のモデルを組み合わせた生成プロセスのカスタマイズも可能です。
これにより、ユーザーはより専門的な結果を得ることができます。
リアルタイムプレビュー
操作内容をリアルタイムでプレビューできるため、生成結果を確認しながら効率的に作業を進めることができます。
ComfyUIの導入方法
今回は、Azureの仮想マシン(Linux)上でComfyUIをインストールする手順をご紹介します。
ComfyUIのリポジトリをクローン
まずは、ComfyUIのリポジトリをクローンしていきます。仮想マシンのターミナルを開き、以下のコマンドを実行して下さい。
git clone https://github.com/comfyanonymous/ComfyUI.git

クローンのコマンド入力
すると、以下のようにリポジトリがインストールされます。
 ComfyUIリポジトリのインストール完了画面
ComfyUIリポジトリのインストール完了画面
以下のコマンドで、ComfyUIのディレクトリに移動しておきます。
cd ComfyUI
 ComfyUIディレクトリへの移動
ComfyUIディレクトリへの移動
仮想環境の立ち上げ
仮想環境を使用することで、ComfyUI専用の環境を作成し、他のPythonプロジェクトとの依存関係の競合を防ぐことができます。また、問題が発生した場合も環境を簡単にリセットできます。
ComfyUIを動作させるツールをPythonの仮想環境内にインストールし、それを用いてComfyUIを起動させます。
まずは、以下のコマンドを用いて、「comfy」という名前のComfyUI用の仮想環境を作成します。
python -m venv comfy
 仮想環境の作成画面
仮想環境の作成画面
次に以下を実行し、今作成した仮想環境をアクティベートして下さい。
source ./comfy/bin/activate
 仮想環境のアクティベート
仮想環境のアクティベート
ツールのインストール
仮想環境内でTorchをインストールします。以下を実行して下さい。
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121
 ツールインストールコマンドの入力
ツールインストールコマンドの入力
以下のようにインストールが進んで行きます。
 ツールインストール中の画面
ツールインストール中の画面
最終的に下記のような表示されたら、インストールは完了です。
 ツールインストール完了画面
ツールインストール完了画面
次に、必要な依存関係をインストールします。
下記のコマンドを実行して下さい。
pip install -r requirements.txt
 依存関係インストールのコマンド入力
依存関係インストールのコマンド入力
以下のような表示が出てきたら、依存関係のインストールが完了です。
 依存関係インストールの完了画面
依存関係インストールの完了画面
起動方法の選択
今回は、仮想マシンでComfyUIを起動します。
仮想マシンの性質上、ComfyUIにアクセスする方法は以下の2種類に分けられます。
選択した方の項目をご覧下さい。
ComfyUIを公開して様々なデバイスからアクセスする
ComfyUIを公開できるように、設定項目を編集します。
まずは、ComfyUIのディレクトリにいる事を確認し、以下の項目を実行して下さい。
rm main.py
 mainファイルの削除
mainファイルの削除
これによって、main.pyという名前のファイルが削除されます。
次に、以下のコマンドを実行し、同じ「main.py」という名前のファイルを作成・編集します。
nano main.py
 編集画面起動のコマンド入力
編集画面起動のコマンド入力
コマンドを実行すると、以下のように編集画面が立ち上がります。
 編集画面の起動
編集画面の起動
そこに、以下のコードを貼り付けて下さい。
なお、もともと用意されていた「main.py」ファイルのコードを、ComfyUIを公開するように修正したものとなります。
import comfy.options
comfy.options.enable_args_parsing()
import os
import importlib.util
import folder_paths
import time
from comfy.cli_args import args
from app.logger import setup_logger
setup_logger(verbose=args.verbose)
def execute_prestartup_script():
def execute_script(script_path):
module_name = os.path.splitext(script_path)[0]
try:
spec = importlib.util.spec_from_file_location(module_name, script_path)
module = importlib.util.module_from_spec(spec)
spec.loader.exec_module(module)
return True
except Exception as e:
print(f"Failed to execute startup-script: {script_path} / {e}")
return False
if args.disable_all_custom_nodes:
return
node_paths = folder_paths.get_folder_paths("custom_nodes")
for custom_node_path in node_paths:
possible_modules = os.listdir(custom_node_path)
node_prestartup_times = []
for possible_module in possible_modules:
module_path = os.path.join(custom_node_path, possible_module)
if os.path.isfile(module_path) or module_path.endswith(".disabled") or module_path == "__pycache__":
continue
script_path = os.path.join(module_path, "prestartup_script.py")
if os.path.exists(script_path):
time_before = time.perf_counter()
success = execute_script(script_path)
node_prestartup_times.append((time.perf_counter() - time_before, module_path, success))
if len(node_prestartup_times) > 0:
print("\nPrestartup times for custom nodes:")
for n in sorted(node_prestartup_times):
if n[2]:
import_message = ""
else:
import_message = " (PRESTARTUP FAILED)"
print("{:6.1f} seconds{}:".format(n[0], import_message), n[1])
print()
execute_prestartup_script()
# Main code
import asyncio
import itertools
import shutil
import threading
import gc
import logging
if os.name == "nt":
logging.getLogger("xformers").addFilter(lambda record: 'A matching Triton is not available' not in record.getMessage())
if __name__ == "__main__":
if args.cuda_device is not None:
os.environ['CUDA_VISIBLE_DEVICES'] = str(args.cuda_device)
logging.info("Set cuda device to: {}".format(args.cuda_device))
if args.deterministic:
if 'CUBLAS_WORKSPACE_CONFIG' not in os.environ:
os.environ['CUBLAS_WORKSPACE_CONFIG'] = ":4096:8"
import cuda_malloc
if args.windows_standalone_build:
try:
import fix_torch
except:
pass
import comfy.utils
import yaml
import execution
import server
from server import BinaryEventTypes
import nodes
import comfy.model_management
def cuda_malloc_warning():
device = comfy.model_management.get_torch_device()
device_name = comfy.model_management.get_torch_device_name(device)
cuda_malloc_warning = False
if "cudaMallocAsync" in device_name:
for b in cuda_malloc.blacklist:
if b in device_name:
cuda_malloc_warning = True
if cuda_malloc_warning:
logging.warning("\nWARNING: this card most likely does not support cuda-malloc, if you get \"CUDA error\" please run ComfyUI with: --disable-cuda-malloc\n")
def prompt_worker(q, server):
e = execution.PromptExecutor(server, lru_size=args.cache_lru)
last_gc_collect = 0
need_gc = False
gc_collect_interval = 10.0
while True:
timeout = 1000.0
if need_gc:
timeout = max(gc_collect_interval - (current_time - last_gc_collect), 0.0)
queue_item = q.get(timeout=timeout)
if queue_item is not None:
item, item_id = queue_item
execution_start_time = time.perf_counter()
prompt_id = item[1]
server.last_prompt_id = prompt_id
e.execute(item[2], prompt_id, item[3], item[4])
need_gc = True
q.task_done(item_id,
e.history_result,
status=execution.PromptQueue.ExecutionStatus(
status_str='success' if e.success else 'error',
completed=e.success,
messages=e.status_messages))
if server.client_id is not None:
server.send_sync("executing", { "node": None, "prompt_id": prompt_id }, server.client_id)
current_time = time.perf_counter()
execution_time = current_time - execution_start_time
logging.info("Prompt executed in {:.2f} seconds".format(execution_time))
flags = q.get_flags()
free_memory = flags.get("free_memory", False)
if flags.get("unload_models", free_memory):
comfy.model_management.unload_all_models()
need_gc = True
last_gc_collect = 0
if free_memory:
e.reset()
need_gc = True
last_gc_collect = 0
if need_gc:
current_time = time.perf_counter()
if (current_time - last_gc_collect) > gc_collect_interval:
comfy.model_management.cleanup_models()
gc.collect()
comfy.model_management.soft_empty_cache()
last_gc_collect = current_time
need_gc = False
async def run(server, address='', port=8188, verbose=True, call_on_start=None):
await asyncio.gather(server.start(address, port, verbose, call_on_start), server.publish_loop())
def hijack_progress(server):
def hook(value, total, preview_image):
comfy.model_management.throw_exception_if_processing_interrupted()
progress = {"value": value, "max": total, "prompt_id": server.last_prompt_id, "node": server.last_node_id}
server.send_sync("progress", progress, server.client_id)
if preview_image is not None:
server.send_sync(BinaryEventTypes.UNENCODED_PREVIEW_IMAGE, preview_image, server.client_id)
comfy.utils.set_progress_bar_global_hook(hook)
def cleanup_temp():
temp_dir = folder_paths.get_temp_directory()
if os.path.exists(temp_dir):
shutil.rmtree(temp_dir, ignore_errors=True)
def load_extra_path_config(yaml_path):
with open(yaml_path, 'r') as stream:
config = yaml.safe_load(stream)
for c in config:
conf = config[c]
if conf is None:
continue
base_path = None
if "base_path" in conf:
base_path = conf.pop("base_path")
for x in conf:
for y in conf[x].split("\n"):
if len(y) == 0:
continue
full_path = y
if base_path is not None:
full_path = os.path.join(base_path, full_path)
logging.info("Adding extra search path {} {}".format(x, full_path))
folder_paths.add_model_folder_path(x, full_path)
if __name__ == "__main__":
if args.temp_directory:
temp_dir = os.path.join(os.path.abspath(args.temp_directory), "temp")
logging.info(f"Setting temp directory to: {temp_dir}")
folder_paths.set_temp_directory(temp_dir)
cleanup_temp()
if args.windows_standalone_build:
try:
import new_updater
new_updater.update_windows_updater()
except:
pass
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
server = server.PromptServer(loop)
q = execution.PromptQueue(server)
extra_model_paths_config_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), "extra_model_paths.yaml")
if os.path.isfile(extra_model_paths_config_path):
load_extra_path_config(extra_model_paths_config_path)
if args.extra_model_paths_config:
for config_path in itertools.chain(*args.extra_model_paths_config):
load_extra_path_config(config_path)
nodes.init_extra_nodes(init_custom_nodes=not args.disable_all_custom_nodes)
cuda_malloc_warning()
server.add_routes()
hijack_progress(server)
threading.Thread(target=prompt_worker, daemon=True, args=(q, server,)).start()
if args.output_directory:
output_dir = os.path.abspath(args.output_directory)
logging.info(f"Setting output directory to: {output_dir}")
folder_paths.set_output_directory(output_dir)
#These are the default folders that checkpoints, clip and vae models will be saved to when using CheckpointSave, etc.. nodes
folder_paths.add_model_folder_path("checkpoints", os.path.join(folder_paths.get_output_directory(), "checkpoints"))
folder_paths.add_model_folder_path("clip", os.path.join(folder_paths.get_output_directory(), "clip"))
folder_paths.add_model_folder_path("vae", os.path.join(folder_paths.get_output_directory(), "vae"))
folder_paths.add_model_folder_path("diffusion_models", os.path.join(folder_paths.get_output_directory(), "diffusion_models"))
if args.input_directory:
input_dir = os.path.abspath(args.input_directory)
logging.info(f"Setting input directory to: {input_dir}")
folder_paths.set_input_directory(input_dir)
if args.quick_test_for_ci:
exit(0)
call_on_start = None
if args.auto_launch:
def startup_server(scheme, address, port):
import webbrowser
if os.name == 'nt' and address == '0.0.0.0':
address = '127.0.0.1'
webbrowser.open(f"{scheme}://{address}:{port}")
call_on_start = startup_server
# ここで listen アドレスを 0.0.0.0 に設定
args.listen = '0.0.0.0'
try:
loop.run_until_complete(server.setup())
loop.run_until_complete(run(server, address=args.listen, port=args.port, verbose=not args.dont_print_server, call_on_start=call_on_start))
except KeyboardInterrupt:
logging.info("\nStopped server")
cleanup_temp()
 コードの貼り付け完了
コードの貼り付け完了
コードを貼り付ける事が出来たら、「Ctrl + O」>「Enter」>「Ctrl + X」でエディタを抜けます。
これで、ComfyUIを公開して様々なデバイスからアクセスする準備が出来ました。ComfyUIの起動へと移動して下さい。
VMのバーチャルデスクトップで起動
何もせず、次のComfyUIの起動に進んで大丈夫です。
ComfyUIの起動
それでは、ComfyUIを起動してみましょう。以下のコマンドを実行して下さい。
python main.py
 ComfyUIの起動コマンドの入力
ComfyUIの起動コマンドの入力
以下のように出力されます、一番下に表示されている赤枠で囲んだURLを控えて下さい。
 ComfyUIの起動完了
ComfyUIの起動完了
VMのバーチャルデスクトップで起動する方は、バーチャルデスクトップ上で、控えたURLにアクセスすることで、ComfyUIを開くことが出来ます。
ComfyUIを公開して様々なデバイスからアクセスする方は、控えたURLが「http://〇:△」のような形になっていると思います。〇部分を仮想マシンのパブリックIPアドレスに変更し、それを検索バーに入力することで、ComfyUIへとアクセスすることが出来ます。
「http:// {パブリックIPアドレス}:△」
URLにアクセスしてみると、以下のようにCompyUIの起動が確認出来ました。
 CompyUIの起動完了
CompyUIの起動完了
ComfyUIでは上記のように、画像生成のプロセスをノードベースで直感的に組み立てることが出来ます。
ComfyUIの使い方
それでは、ComfyUIの実際の使い方についてご紹介します。
用語解説
まずは具体的な使い方の前に、ComfyUIの核となるノードとワークフローの2つの用語について解説します。
ノード
ノードは、画像生成プロセスの各ステップを実行する基本単位です。
各ノードは、特定のタスク(例:テキストのエンコード、画像の生成、画像のデコードなど)を担当し、それぞれが独立して機能します。
ワークフロー
ワークフローは、複数のノードをつなぎ合わせて、画像生成の一連のプロセスを構成するものです。
ワークフローを作成することで、ノード同士のデータフローを視覚的に定義し、複雑な画像生成プロセスを管理できます。
つまり、下記の画像において、いくつもあるグレーの四角形の部品のようなものをノードと呼び、それらが繋がりあっている全体をワークフローと呼びます。
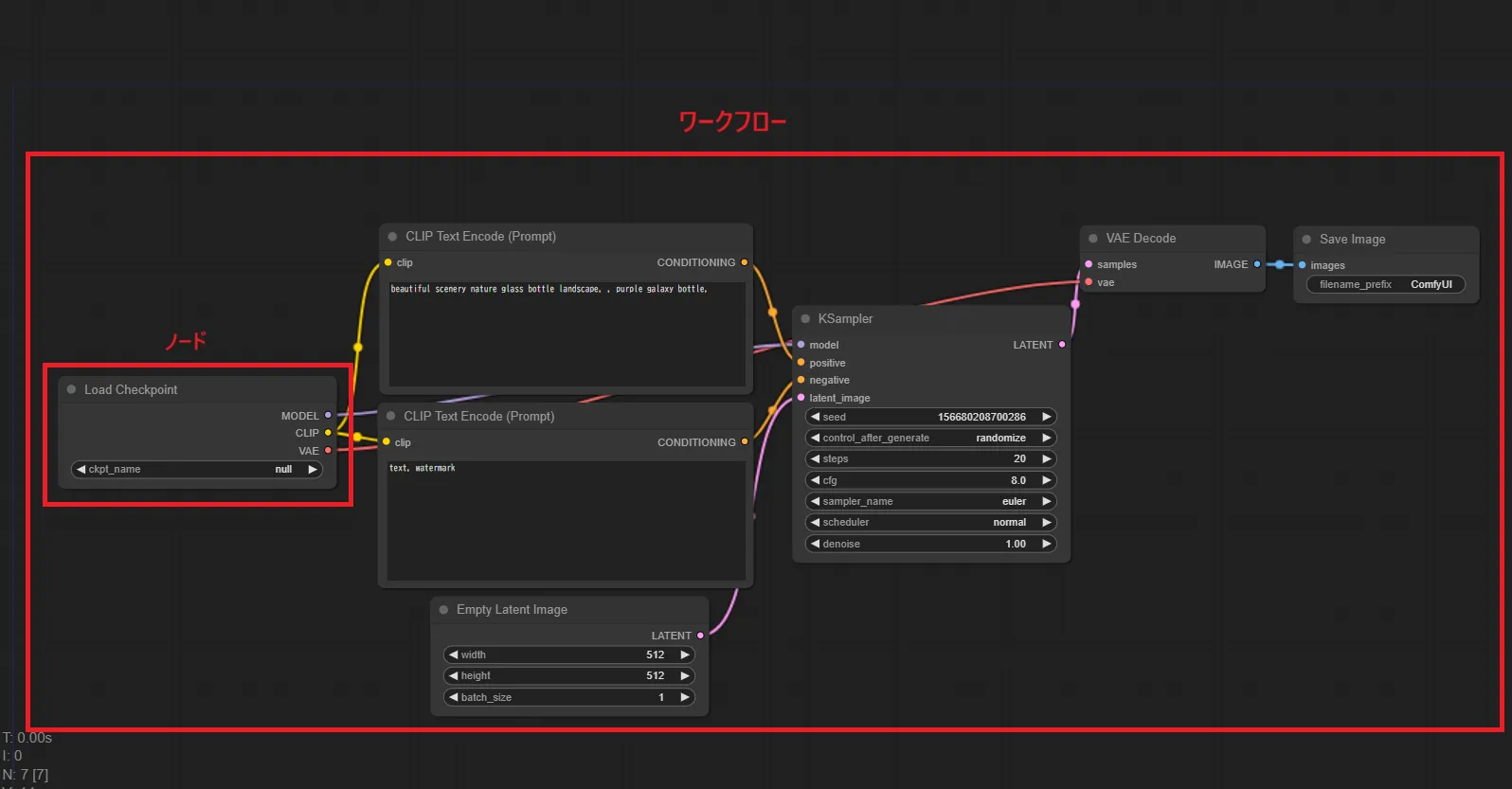 用語解説
用語解説
モデルのダウンロード
実際に画像を生成するには、モデルやVAEを用意する必要があります。
そのため、一旦ComfyUI上ではなく、仮想マシンのターミナル上で作業します。
モデル等の用意には主に以下の2種類の方法があります。
- ComfyUI上に直接ダウンロードする方法
- 既にあるStable diffusion webuiのモデルと共有する方法です。
ComfyUI上に直接ダウンロードする方法
CompyUIのディレクトリの中には、以下のように「models」というフォルダがあります。
 CompyUIのディレクトリの中身
CompyUIのディレクトリの中身
そして、「models」の中には、以下のように様々なフォルダが用意されています。
 modelsの中身
modelsの中身
モデル等の用意をするには、これらの中の該当フォルダに保存して下さい。
例えば、モデルをダウンロードするなら「checkpoints」に、VAEをダウンロードするなら「vae」に保存するという具合です。
Stable Fiffusion WebUIのモデルと共有する方法
ComfyUI専用でモデル等をダウンロードしていると、ストレージを圧迫してしまいます。
そこで、既にStable diffusion webuiを使用しており、そこにモデル等が保存されている場合、ComfyUIにもそのモデルを共有する事が出来ます。
まずは、forgeのパスを取得します。以下のコマンドを順に実行して下さい。
cd ~/stable-diffusion-webui-forge
pwd
すると、下記のようにforgeのパスを取得出来ました。
 forgeのパス取得
forgeのパス取得
次は、順に以下のコマンドを実行して下さい。
cd ~/ComfyUI
nano extra_model_paths.yaml.example
編集画面起動のコマンド入力
すると、編集画面が起動します。
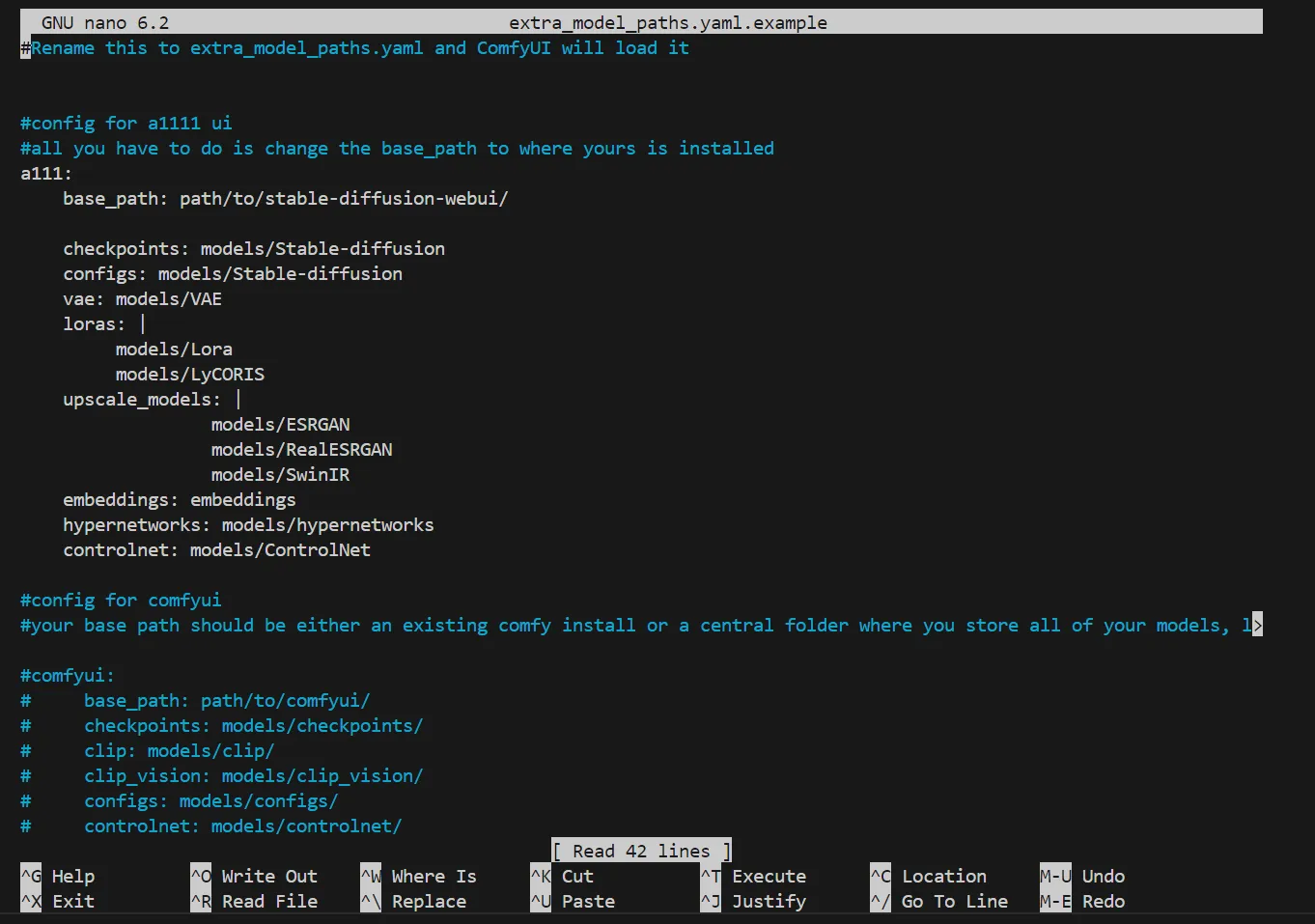 パス編集画面の起動
パス編集画面の起動
赤枠で囲んだ部分を削除し、先ほど取得したforgeのパスを取得します。
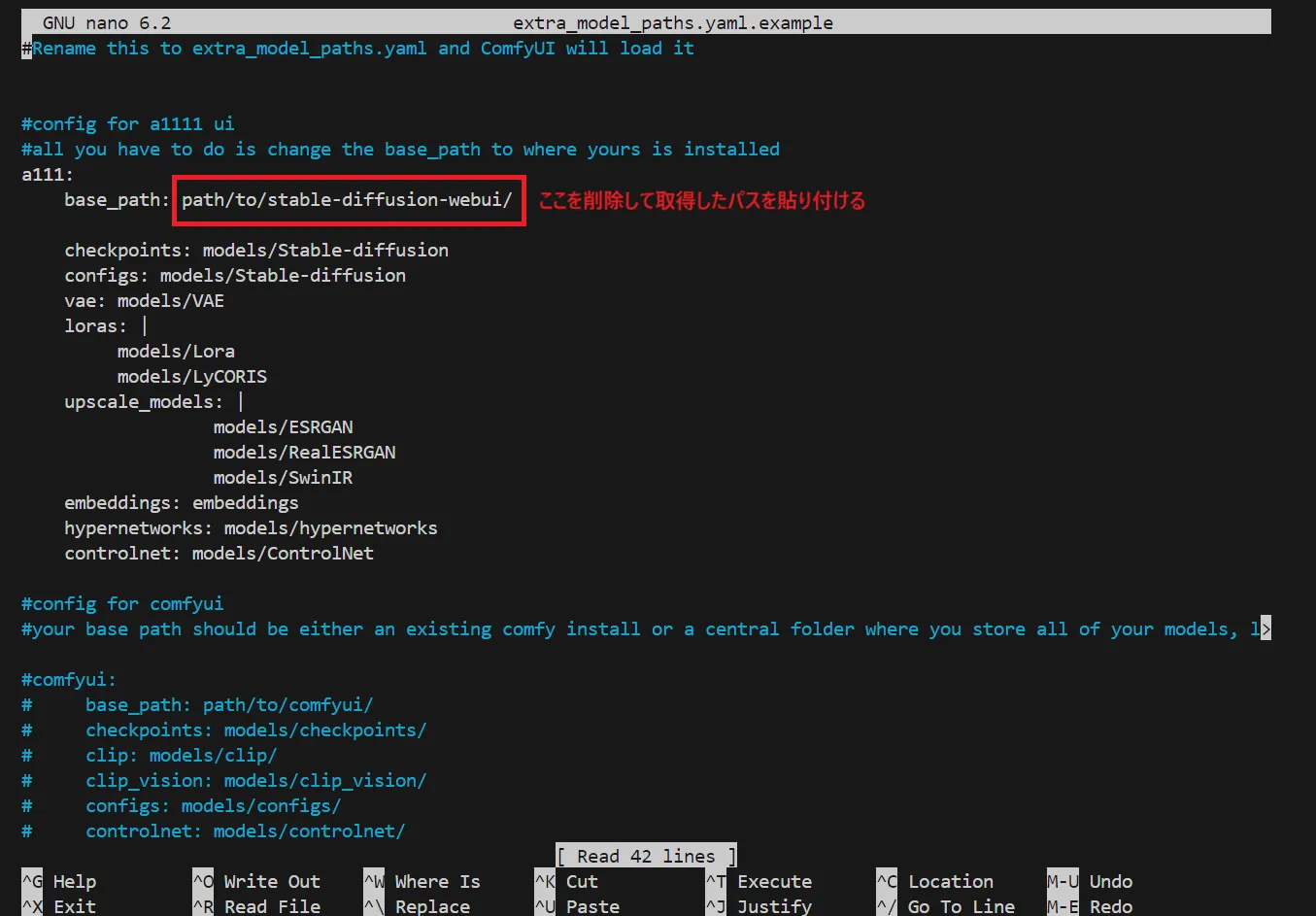 パスの編集内容
パスの編集内容
以下のように貼り付けることが出来ました。
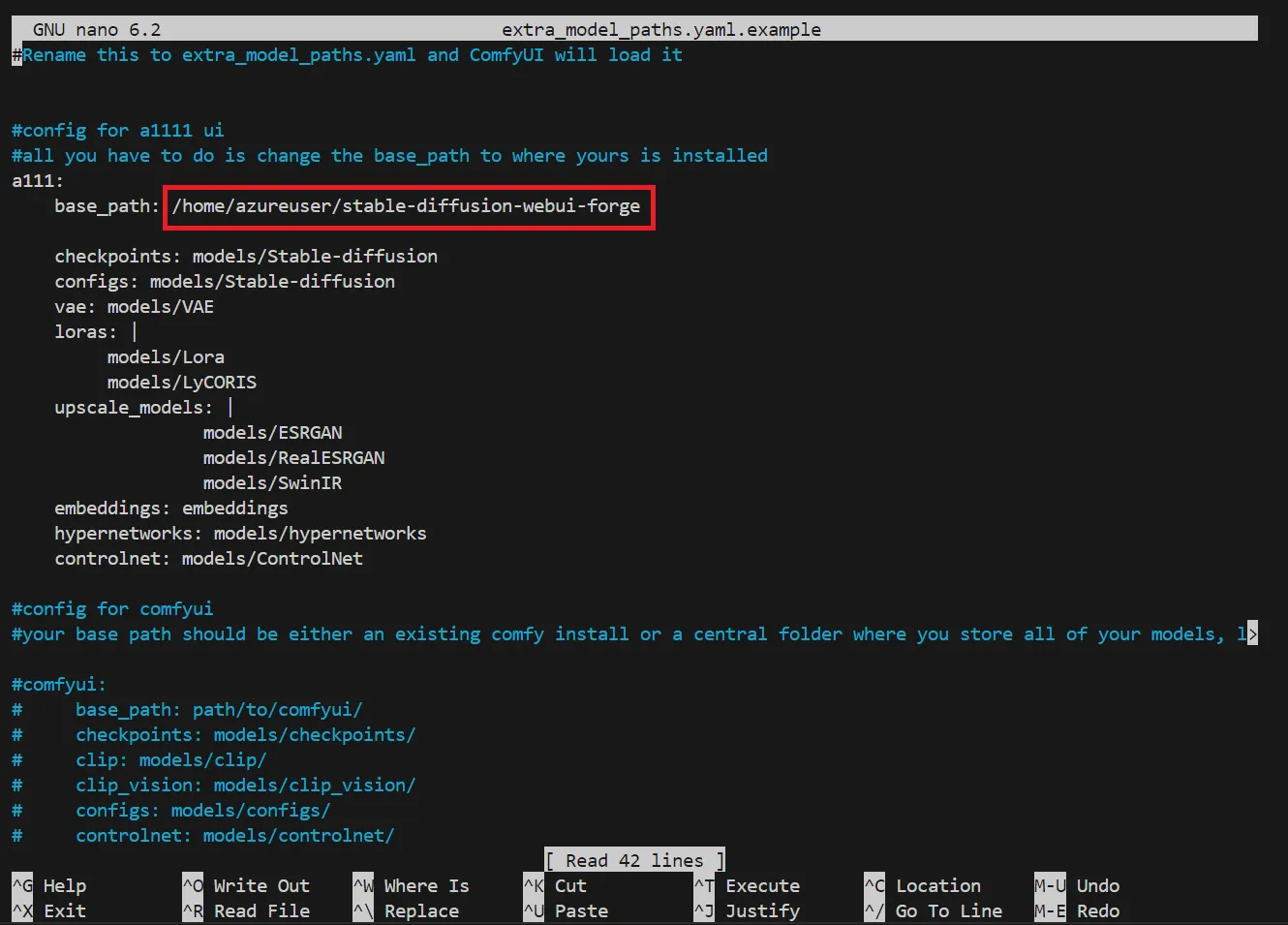 forgeのパス貼り付け完了
forgeのパス貼り付け完了
「Ctrl + O」>「Enter」>「Ctrl + X」でエディタを抜けます。
次に、以下のコマンドを実行し、ファイル名を変更します。
mv extra_model_paths.yaml.example extra_model_paths.yaml
 ファイルの名称変更
ファイルの名称変更
これで、モデルを共有して使用することが出来るようになりました。
基本操作
画面の移動
ダブルクリックしてスクロール
右クリック > 「Add Node」 > 追加したいノードの選択
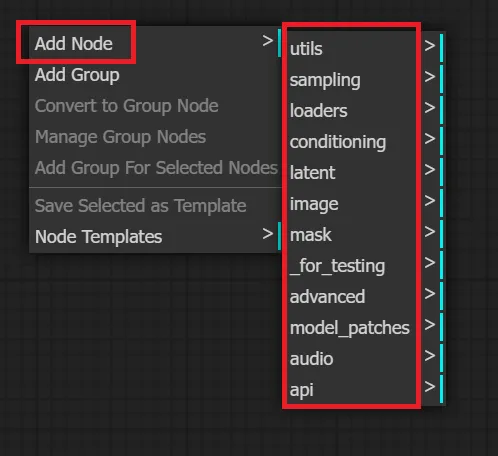 右クリックによるノードの追加
右クリックによるノードの追加
- ダブルクリックの場合
ダブルクリック > 検索バーに名前を入力 > 表示された中から追加したいノードを見つけてクリック
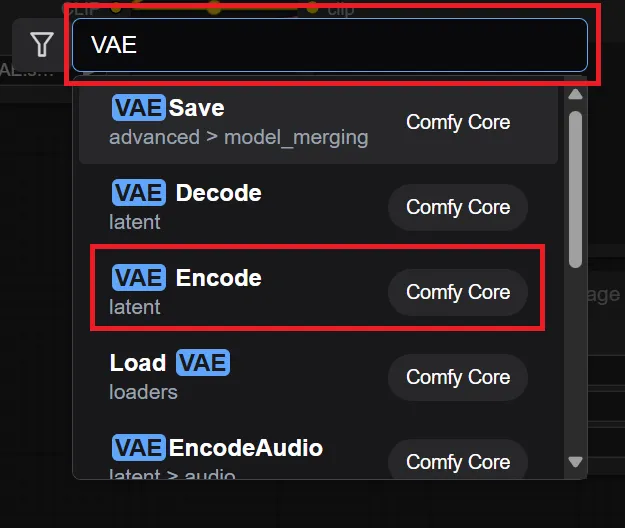 ダブルクリックによるノードの追加
ダブルクリックによるノードの追加
ノードの接続
接続元のポートをドラッグし、接続先のポートにドロップ
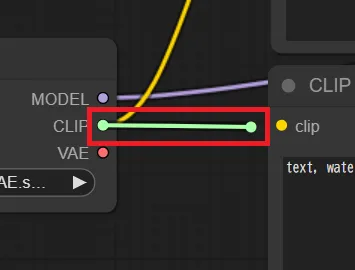 ドラッグ中
ドラッグ中
ドラッグして
 ドロップ後
ドロップ後
ドロップする
ノードの削除
ノードを選択し、「Delete」または「Backspace」
 ノードの削除1
ノードの削除1
ノードを選択すると、白い枠線が出る。
この状態で、「Delete」または「Backspace」をすると、以下のように削除できる
 ノードの削除2
ノードの削除2
作成したワークフローの保存
右バーの「Save」をクリック > 任意の名前を入力 > 「OK」をクリック
まずは、右バーにある「Save」をクリックします。
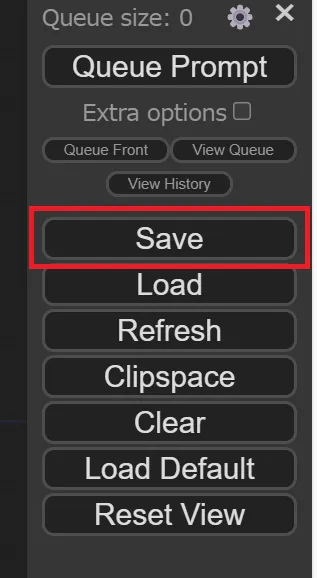 Saveのクリック
Saveのクリック
以下のような表示が出てくるので、お好きな名前を入力し、その後「OK」をクリックします。
 名前の入力
名前の入力
なお、ご自身のローカルPCにjsonファイルが保存されます。
ダウンロードしたワークフローの利用方法
右バーの「Load」をクリック > 使用するワークフローを選択 > 「開く」をクリック
右バーの「Load」をクリックします。
 Loadのクリック
Loadのクリック
ローカルPC内のファイル一覧が表示されるので、使用したいワークフローを選択して下さい。なおここで選択するファイルの形式は、jsonファイル以外にも、pngファイルで動作することが確認出来ました。
 使用するワークフローの選択
使用するワークフローの選択
ワークフローを選択したら、右下の「開く」をクリックします。
 使用するワークフローの起動
使用するワークフローの起動
ComfyUIの各機能の使い方
ノードを組み合わせてワークフローを構築していくという流れになります。ワークフローを構築することで、自由に画像生成の処理を行うことが出来ます。
例えば、入力を画像にしたり、はじめに画像が生成された後に解像度を上げたり、ノイズの除去をすることで、さらに良い出力を狙うといった事が出来るようになります。
ここで、ワークフローはネット上で公開されているものがあり、基本的にはそれらをダウンロードして利用する事が多いです。
テキストから画像生成(txt2img)
まずは最も基本的な、テキストから画像を生成(txt2imgという)する事を試してみましょう。
ComfyUIの初期起動時には、txt2imgのワークフローの大枠が用意されているので、これを活用していきます。
まずは、「Load Checkpoint」でモデルを選択します。
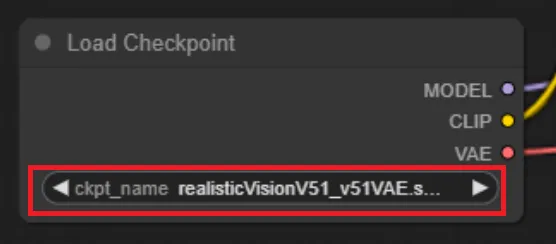 モデルの選択
モデルの選択
次に、プロンプトを入力します。「CLIP Text Encode(Prompt)」に入力していく事になります。
なお、下記のようにノードに注目すると、上が「positive」、下が「negative」に接続されている事が分かります。
従って、上にはプロンプトを、下にはネガティブプロンプトを入力します。
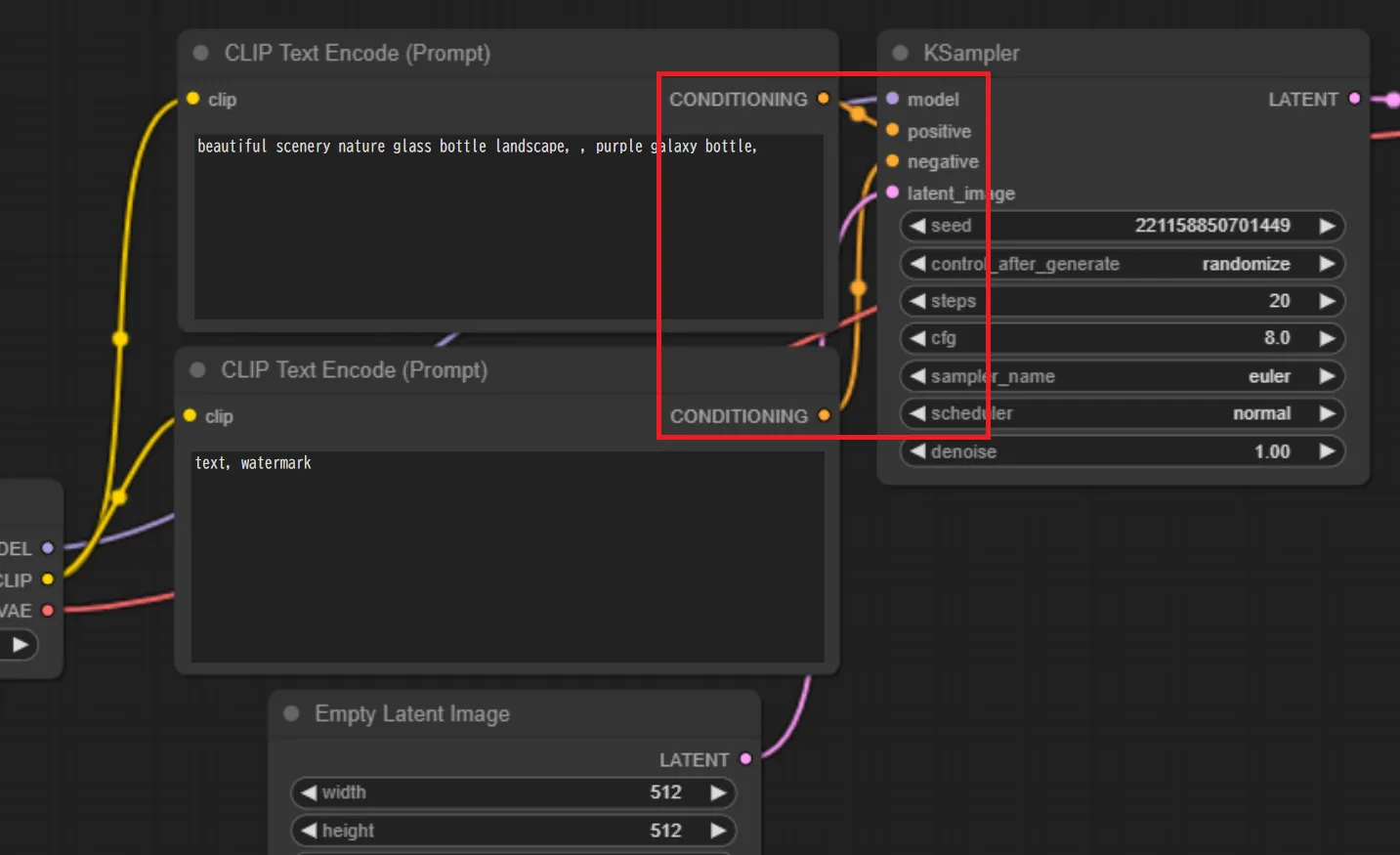 プロンプトの入力
プロンプトの入力
最後に、右バーの「Queue Prompt」をクリックすることで画像を生成することが出来ます。
 画像生成の実行
画像生成の実行
すると以下のように、生成された画像が表示されました。
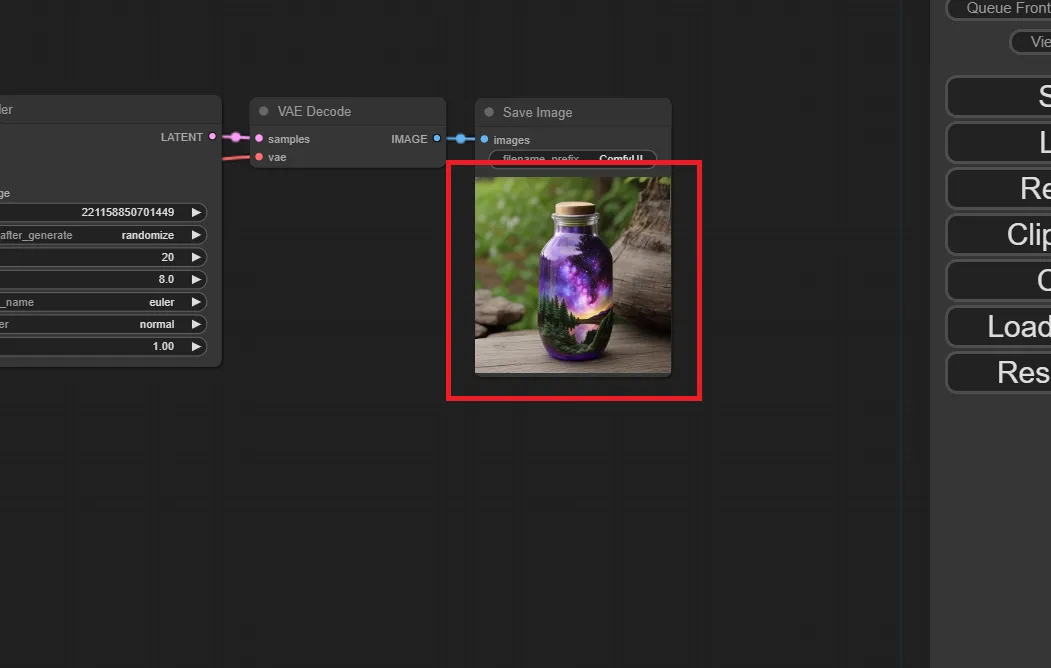 生成された画像1
生成された画像1
なお生成された画像は、「ComfyUI」ディレクトリの中の「output」フォルダの中に保存されていきます。
 ComfyUIで生成した画像の保存場所
ComfyUIで生成した画像の保存場所
VAEの追加
次は、任意のVAEを追加してみましょう。なお、先程のモデルも変えています。
まずは、「Load VAE」のノードを追加します。
 VAEノードの追加
VAEノードの追加
次に、「Load VAE」と「VAE Decode」を接続します。この際、「Load Checkpoint」との接続は自動で解除されます。
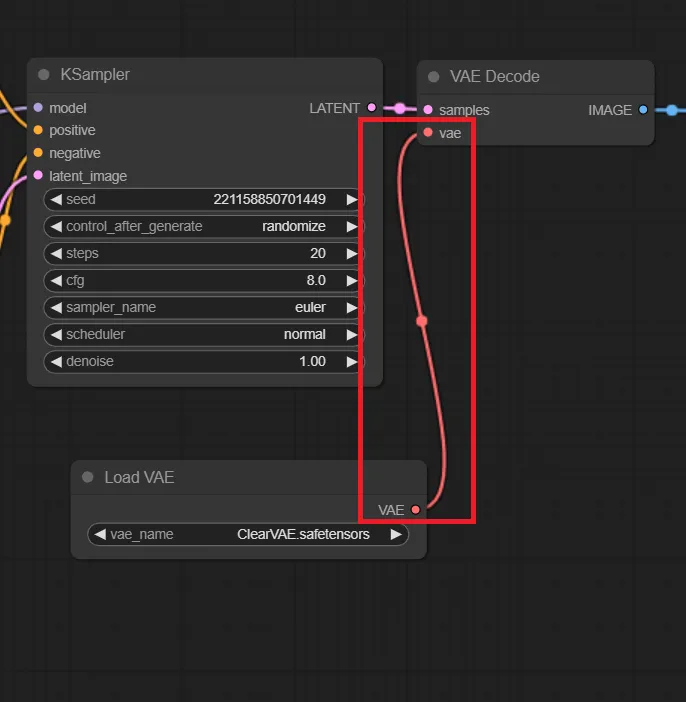 VAEノードの接続
VAEノードの接続
「Load VAE」で任意のVAEを選択し、画像を生成してみましょう。
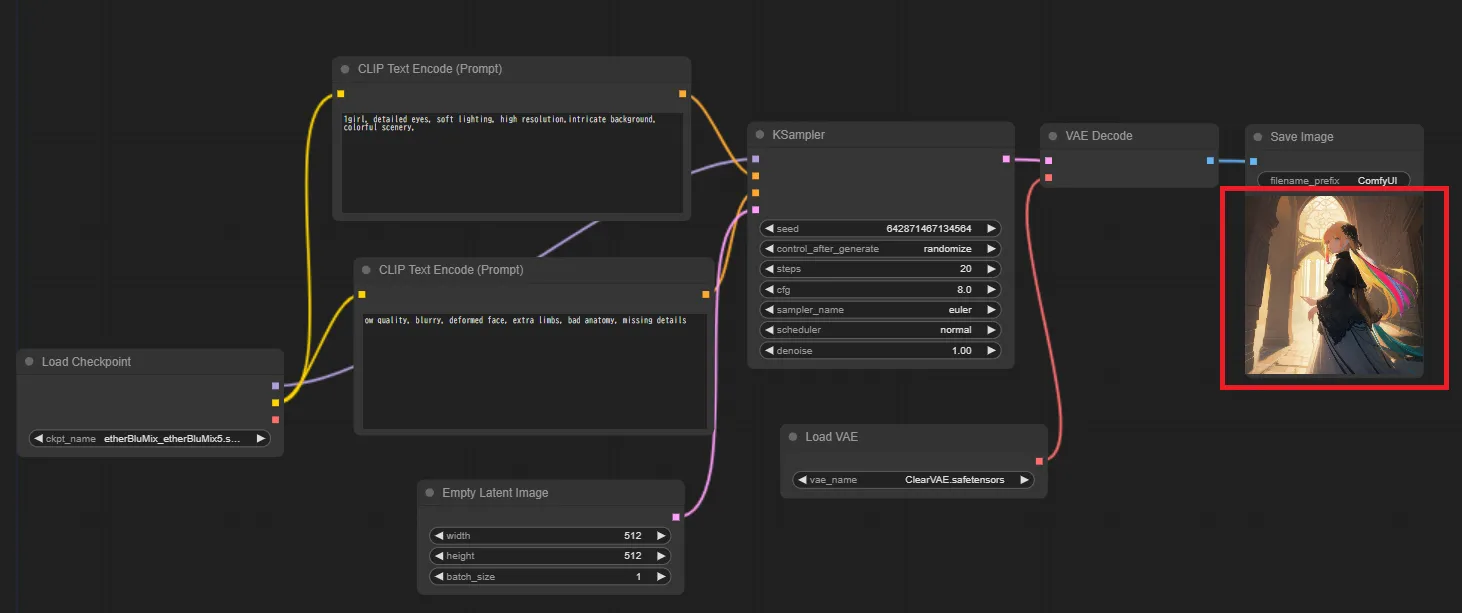 VAE導入後に生成された画像1
VAE導入後に生成された画像1
解説したワークフローでしっかり画像を生成することが出来ました。
プロンプトに活用するモデルの変更
ここで、プロンプトとネガティブプロンプトに使用するモデルを異なるものにしてみます。
先ほどVAEを追加したワークフローの中で、ネガティブプロンプトに使用するモデルを以下のように変更しました。
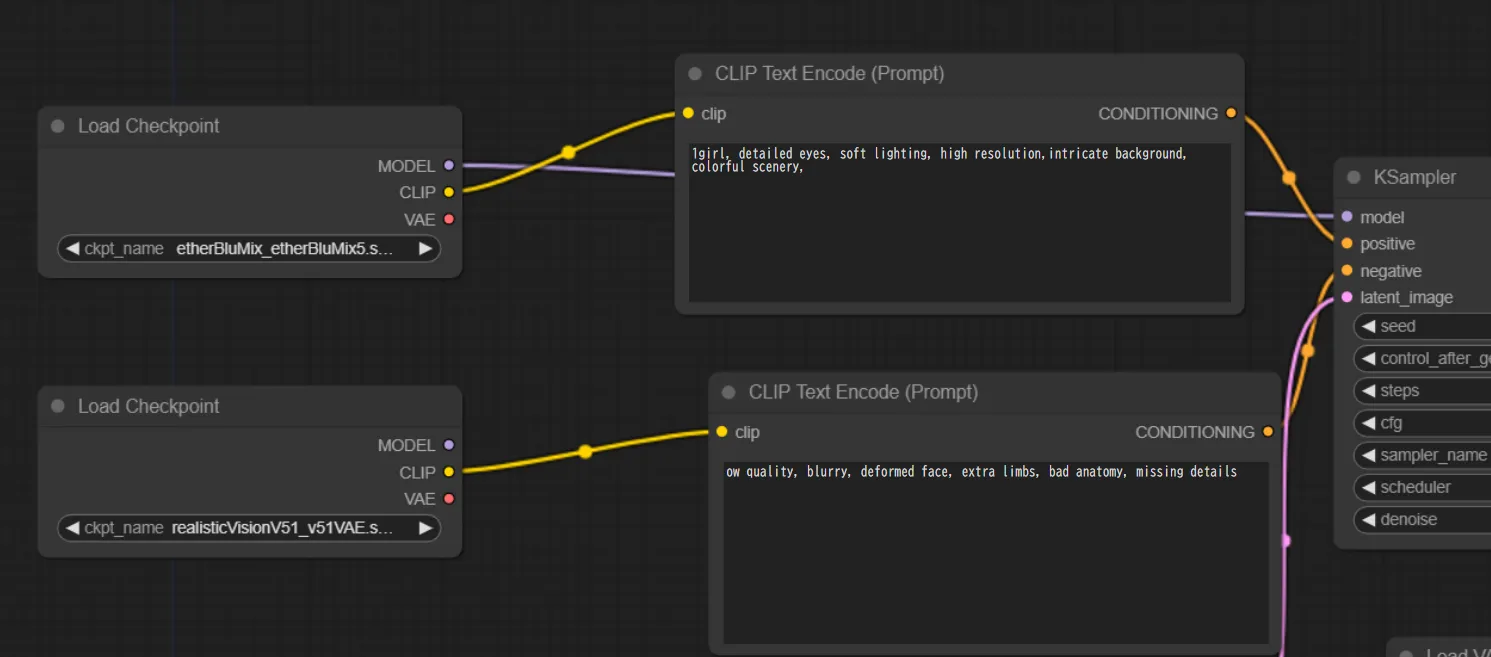 プロンプトに活用するモデルの変更
プロンプトに活用するモデルの変更
以下が、生成された画像です。
 プロンプトに活用するモデルを変更して生成された画像
プロンプトに活用するモデルを変更して生成された画像
画像から画像生成(img2img)
それでは、既存の画像に対して何らかの変換を施し、新しい画像を生成する事を試してみましょう。
ワークフローは、こちらからダウンロードしたものを使用します。
サイトにアクセスすると、以下のような画面が表示されます。
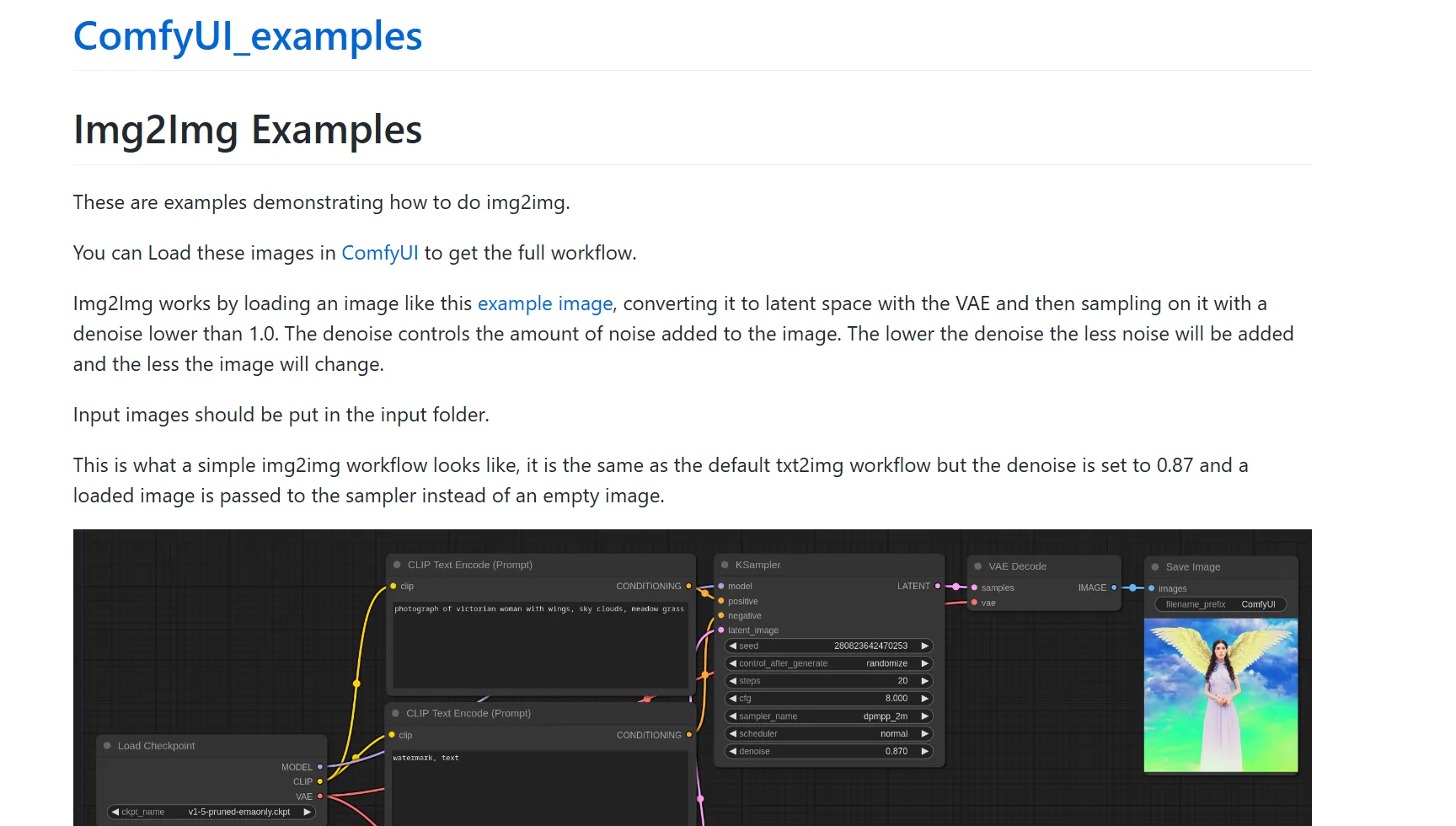 ワークフローの参照先
ワークフローの参照先
下部にある画像を右クリックし、任意の名前を付けて保存します。
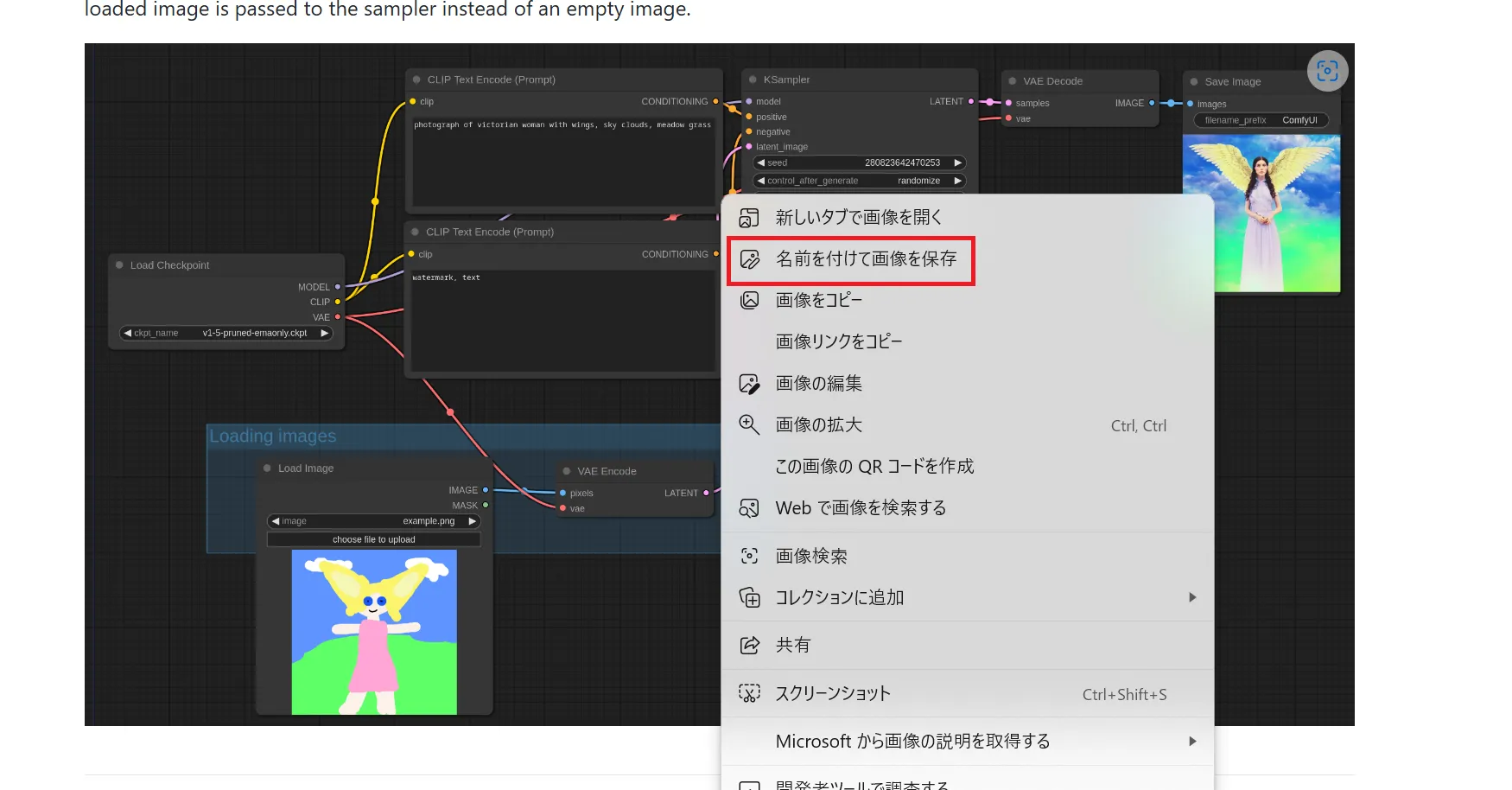 img2img画像の保存
img2img画像の保存
ComfyUI内の「Load」にて、先ほど保存したファイルを選択します。
 img2imgの選択
img2imgの選択
以下のように、img2imgのワークフローが読み込まれました。
 img2imgワークフローの起動
img2imgワークフローの起動
「開く」をクリックしても、反映されない場合は、何回か繰り返したり、ComfyUIに入り直してLoadし直すことで上手く行く場合があります。
img2imgを使用する際は、下記のように「choose file to upload」をクリックし、入力したい画像を選択します。
 入力画像のアップロード
入力画像のアップロード
以下のような画像を設定してみました。
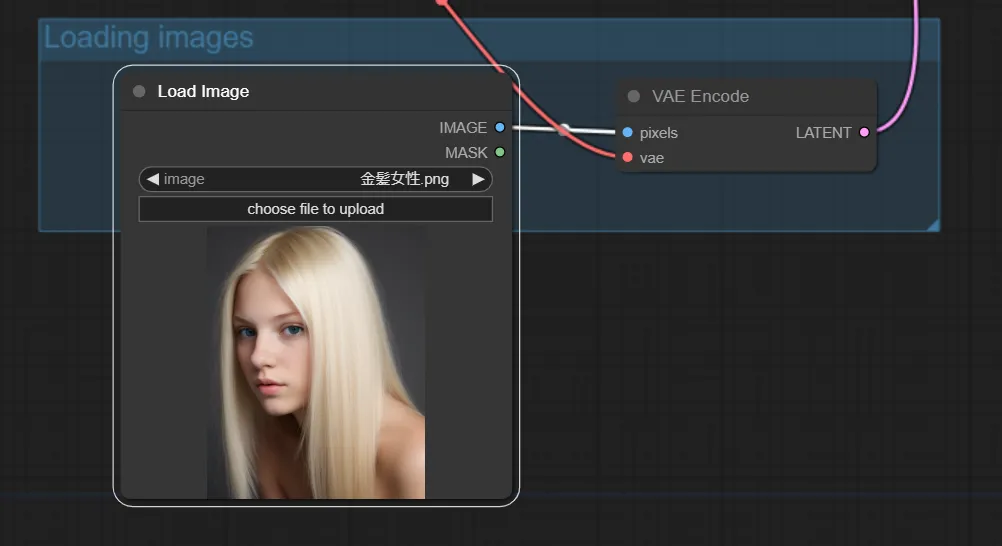 入力画像のアップロード完了
入力画像のアップロード完了
モデルを選択し、以下のプロンプトを入力しました。金髪を青髪にするのが狙いです。
1girl, blue hair
以下が、生成された画像です。
 img2img生成画像
img2img生成画像
以下が元画像です。
 img2img元画像
img2img元画像
適当にパラメータを設定したので、完全に髪色だけ変更できた訳ではありませんが、なかなか良い出力だと思います。
各種ノードの解説
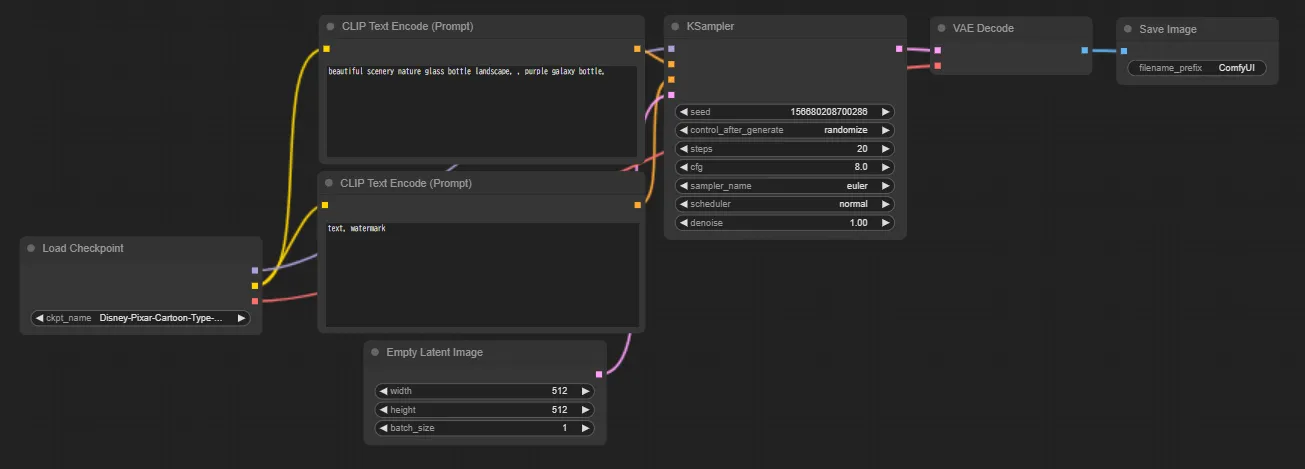 デフォルトのワークフロー
デフォルトのワークフロー
簡単に、デフォルトのワークフローにあるノードを解説して行きたいと思います。各ノードが参照しているフォルダは、モデル等のダウンロードセクションにて設定したパスを参照しています。
Load Checkpoint
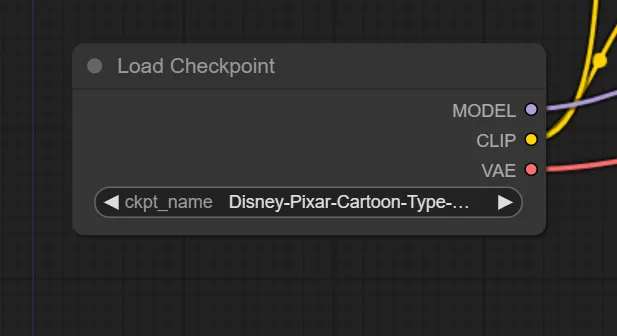 Load Checkpoint
Load Checkpoint
「Load Checkpoint」では、チェックポイントを選択します。つまり、使用するAIモデルを指定します。
CLIP Text Encode
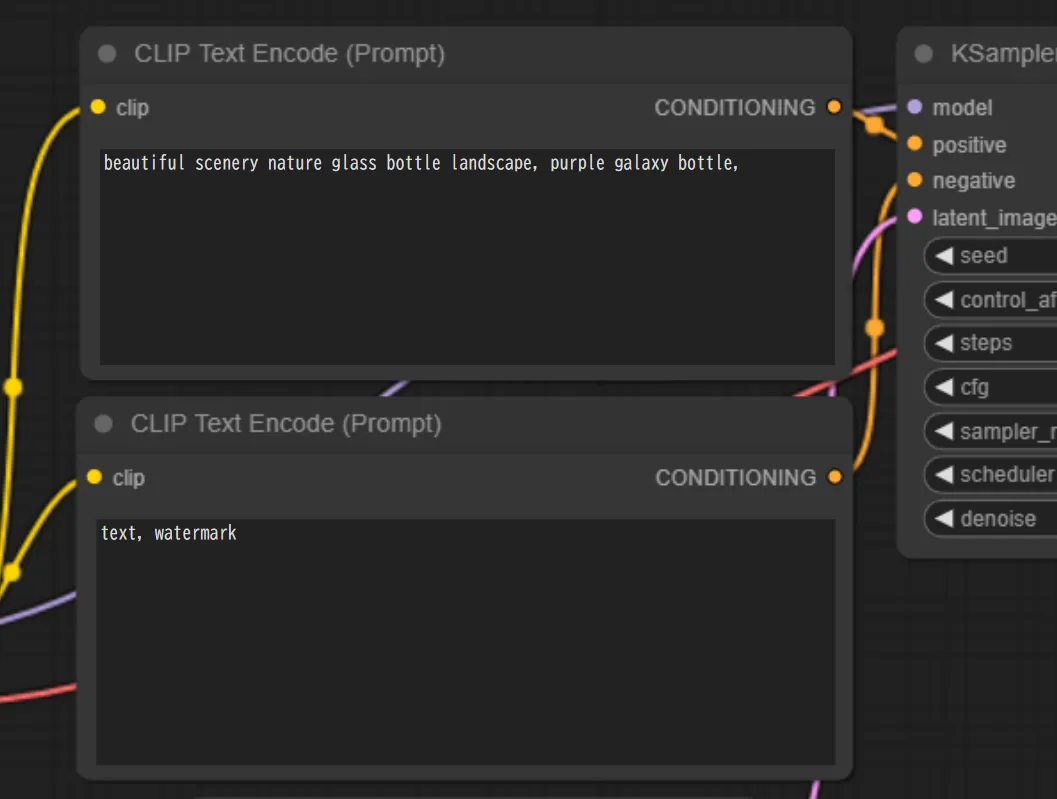 CLIP Text Encode
CLIP Text Encode
「CLIP Text Encode」では、プロンプトを入力します。ノ
ードの接続先を確認してみると、上がpositive、下がnegativeへと接続されています。
これは、上のノードがポジティブプロンプト、下のノードがネガティブプロンプトであることを表しています。
Empty Latent Image
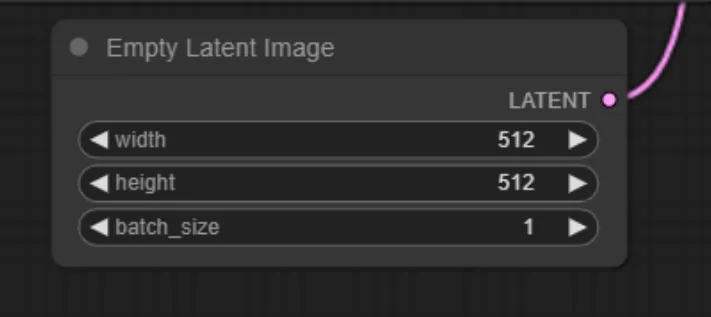 Empty Latent Image
Empty Latent Image
「Empty Latent Image」では、生成される画像のサイズと、バッチ処理の数を決める事が出来ます。バッチ処理の数を大きくすることで、効率的に処理を行うことが出来ます。
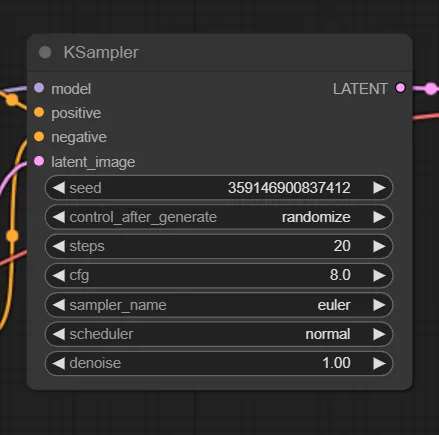 KSampler
KSampler
KSampler
KSamplerでは、画像生成プロセスで使用されるサンプリングアルゴリズムを選択し、パラメータを決定します。また、ここで生成される画像は、潜在空間の画像であり、人間の目で直接見ることができる形ではありません。
VAE Decode
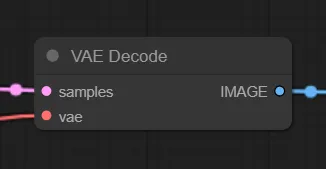 VAE Decode
VAE Decode
「VAE Decode」では、潜在空間の画像をピクセル空間の画像、つまり私たちが視覚的に認識できる画像に変換しています。
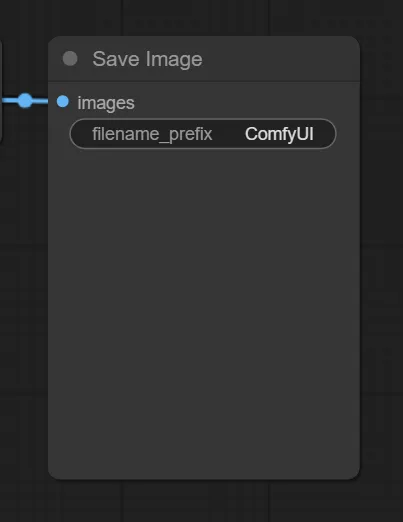 Save Image
Save Image
Save Image
「Save Image」では、画像をフォルダに保存します。
実用上は、カスタムノードといって、ComfyUIのワークフローに新たな機能や処理を追加するための拡張モジュールを使用する事が多いです。
これにより、標準ノードでは実現できない独自の処理や特定のニーズに対応することが可能になります。
拡張機能
カスタムノードを管理するのに便利な「ComfyUI Manager」のインストール方法を解説します。
以下のコマンドを実行して下さい。
cd ~/ComfyUI/custom_nodes
git clone https://github.com/ltdrdata/ComfyUI-Manager.git
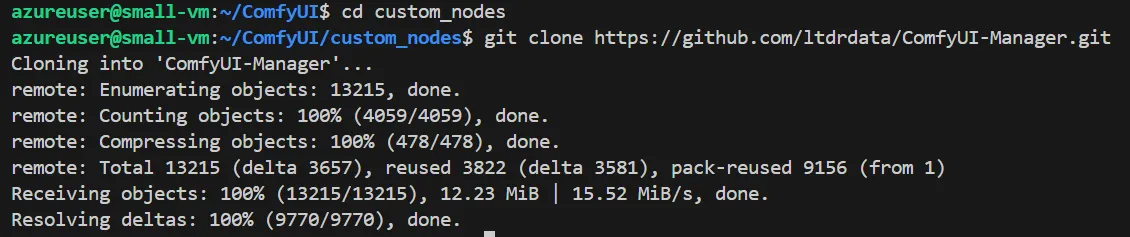
これでインストールが完了です。ComfyUIを開くと、以下のように「Manager」と「Share」のタブが追加されていることが確認できます。
これを使用することで、カスタムノードを簡単に管理することが出来ます。
「Maneger」をクリックしてみると、以下のような表示が出てきます。
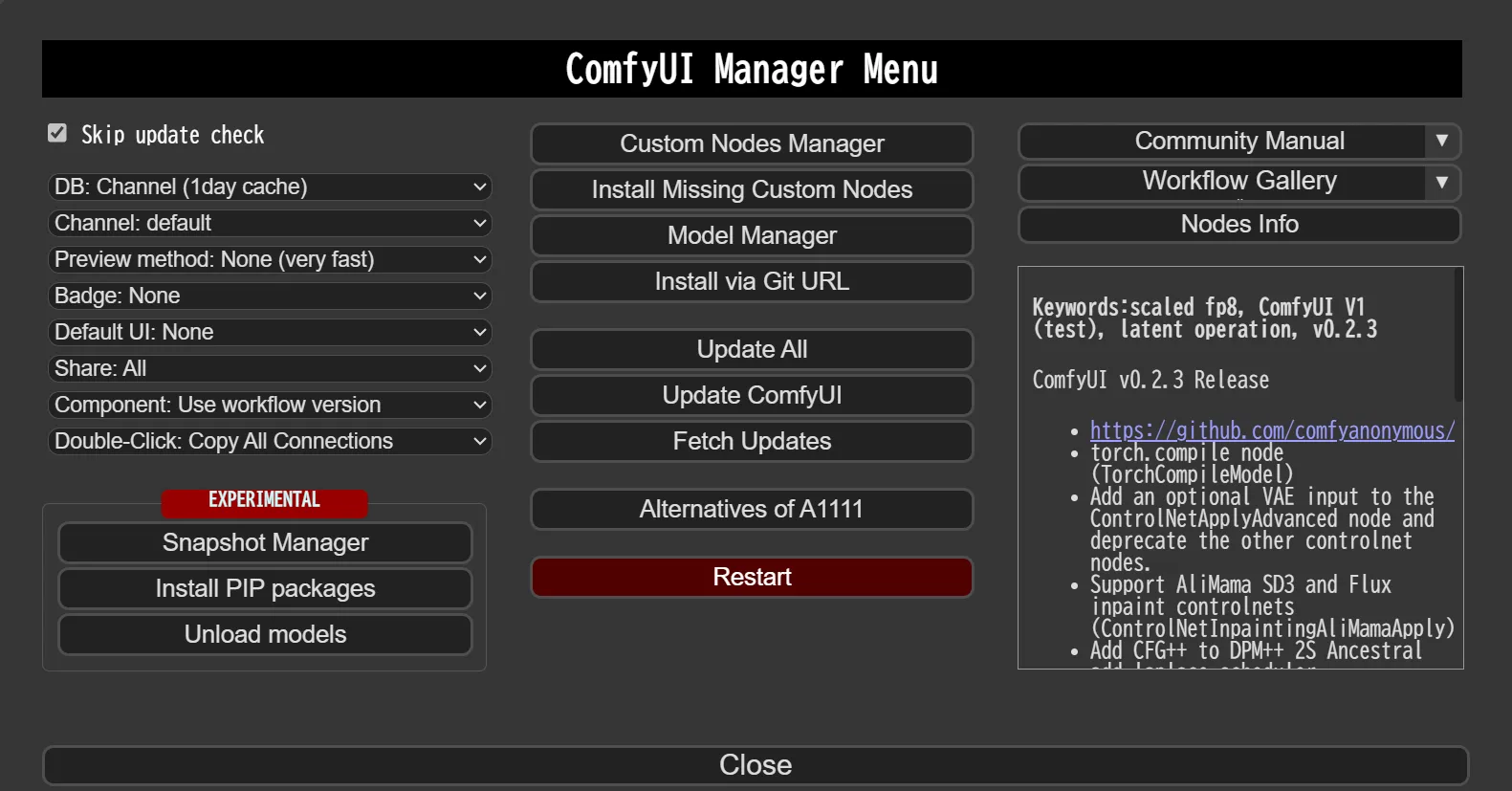 ComfyUIManagerの表示
ComfyUIManagerの表示
例えば、ネットから持って来た何かしらのワークフローを使用しようとした時に、そのワークフローがカスタムノードを使用していた場合、その時点でのあなたのComfyUIは持ってきたワークフローを使用することが出来ません。
そんな時は、以下の「Install Missing Custom Nodes」を使用することで、数クリックで足りないカスタムノードをインストールすることが出来ます。
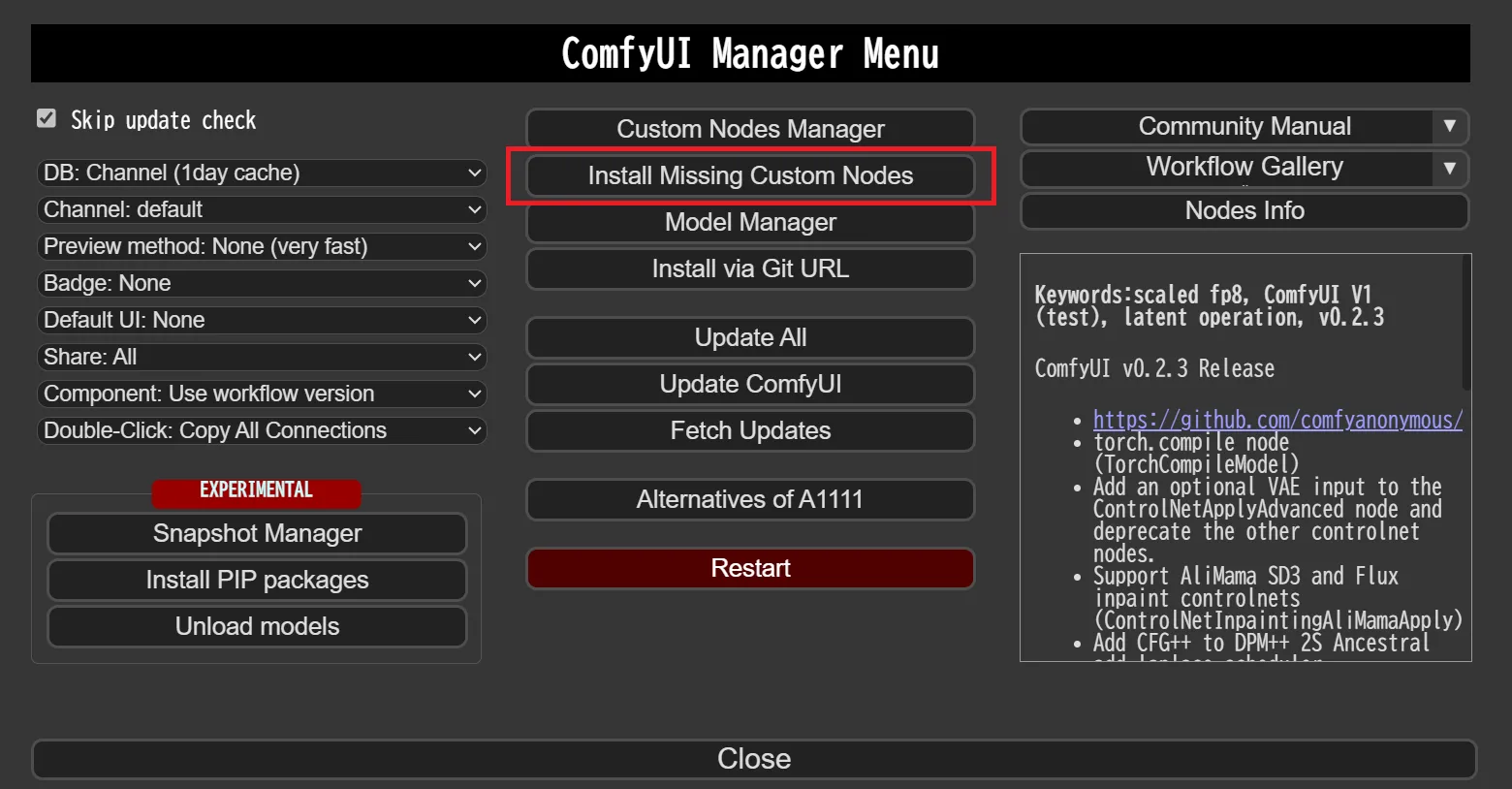 Install Missing Custom Nodes
Install Missing Custom Nodes
2回目以降の起動方法
2回目以降は、以下を実行する事で、ComfyUIを起動出来ます。
source ./comfy/bin/activate
cd ~/ComfyUI
python main.py
ComfyUIの商用利用について
ComfyUI自体はオープンソースであり、商用利用も可能です。
しかし、ComfyUIを使って画像を生成し、それを商用利用する場合、いくつかの注意点があります。
1.使用するモデルのライセンス
ComfyUIはStable Diffusionなどの画像生成モデルを利用しますが、モデルごとにライセンスが異なります。商用利用可能なモデルとそうでないモデルがあるので、使用するモデルのライセンスをよく確認する必要があります。
例えば、Stable Diffusion 1.5はCreativeML Open RAIL-Mライセンスで、商用利用が可能です。しかし、Stable Diffusion 2.1はCreativeML Open RAIL++-Mライセンスで、商用利用が制限されています。
2.生成画像の著作権
生成された画像の著作権は、一般的にその画像を生成した人に帰属するとされています。しかし、著作権に関する法律や解釈は国や地域によって異なる場合があり、まだ明確に定まっていない部分もあります。
そのため、生成画像を商用利用する場合は、法的なリスクを理解しておく必要があります。
3. 倫理的な問題*
生成AI技術は急速に発展しており、倫理的な問題も議論されています。例えば、他人の著作物を無断で学習データとして使用することや、差別的な画像を生成することなどが問題視されています。
ComfyUIを商用利用する場合は、これらの倫理的な問題にも配慮する必要があります。
より詳しく知りたい場合は、以下の情報を参考にしてください。
- ComfyUIのGitHubリポジトリ: https://github.com/comfyanonymous/ComfyUI
- Stable Diffusionのライセンス: https://huggingface.co/spaces/CompVis/stable-diffusion-license
ComfyUIを商用利用する場合は、上記の点に注意し、責任を持って使用してください。

まとめ
本記事では、ノードベースのAI画像生成インターフェース「ComfyUI」について、基本的な概念から実践的な使い方まで解説しました。特に2024年10月にリリースされたComfyUI V1は、デスクトップアプリケーション化やUI改善により、より直感的な操作性を実現しています。
インストール手順から始まり、テキストから画像生成(txt2img)や画像から画像生成(img2img)といった基本機能、さらにはStable DiffusionモデルやVAEの効果的な活用方法まで、具体例を交えて紹介しました。また、ComfyUI Managerを使用した拡張機能の管理方法についても説明し、より高度な画像生成を可能にする方法を示しました。
ComfyUIの特徴である視覚的なワークフロー構築により、複雑な画像生成プロセスも直感的に理解・管理できます。カスタムノードによる機能拡張や、充実したモデル管理機能を活用することで、よりクリエイティブな画像生成が可能となります。AIを活用した画像生成に興味がある方々にとって、ComfyUIは強力なツールとなるでしょう。










