この記事のポイント
 この記事はPyTorchについての詳細な解説を提供しています。
この記事はPyTorchについての詳細な解説を提供しています。- PyTorchはMetaによって開発された、直感的に操作できるオープンソースのディープラーニングフレームワークです。

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
深層学習の開発において、フレキシブルかつ直感的な操作を可能にするPyTorchに関心を持たれている方は多いでしょう。
記事では、そんなPyTorchの基本から高度な使い方、TensorFlowとの比較に至るまで、幅広く解説します。
初心者の方にも分かりやすい環境構築方法や、実際にMNISTデータセットでの画像認識モデルの構築例も紹介。さらには、現実世界での課題解決にも拍車をかけるPyTorchの導入事例を通じて、その実用性の高さを実感していただけるはずです。
動的な計算グラフのメリットをはじめ、PyTorchの直感的な記法の優位性や、豊富なエコシステムを活用した開発がいかに容易かを、具体例を交えてお伝えします。
PyTorchとは
PyTorchはMeta(旧Facebook)が中心となって開発・公開するオープンソースのディープラーニングフレームワークです。Pythonとの親和性が高く、NumPyのような直感的なテンソル操作とGPU計算最適化を組み合わせることで、研究から実装までをスムーズにつなぎます。
また世界的なコミュニティサポートがあり、最新の研究成果をいち早く実装できる環境が整っています。
 公式サイトより引用
公式サイトより引用
現代の深層学習**(ディープラーニング)において、PyTorchは研究者やエンジニアにとって欠かせないフレームワークの一つです。
その理由は、**高い柔軟性や直感的な記法、そして豊富なエコシステムにあります。
PyTorchが注目される最大の要因は動的計算グラフによる自由度の高さです。これにより、コードを書きながら即時に実行し、中間結果をデバッグ可能です。
また、学術分野での利用が盛んで、トップカンファレンス論文の多くでPyTorchが用いられており、高品質なチュートリアルやドキュメントも豊富な点が魅力です。
PyTorchの特徴・メリット
PyTorchは、深層学習モデルの開発プロセスを劇的にシンプルかつ強力なものにします。
ここでは、その特徴となる「動的グラフ」「Pythonicなコード記法」「豊富な拡張ライブラリ群」「研究からプロダクションまでの一貫性」について紹介します。
これらを理解することで、なぜPyTorchが多くの開発者や研究者に選ばれるのかが明らかになります。
動的グラフによる柔軟性とデバッグ容易性
PyTorchは、コードを実行するたびに計算グラフを動的に構築します。
そのため、複雑なモデルアーキテクチャや条件分岐を直感的に実装できます。
また、中間層の出力を即座に確認できるため、デバッグやモデル改良がスムーズに行えます。
Pythonicな記法と直感的なコード記述
PyTorchはPythonで完結する開発スタイルを採用しています。
NumPyに似たテンソル操作は学習コストが低く、直感的なモデル定義やトレーニングループの記述が可能です。Pythonユーザーならすぐに馴染むことができるでしょう。
豊富なライブラリ・ツールエコシステム
PyTorchには、画像処理用のTorchVision、自然言語処理用のTorchText、オーディオ分析用のTorchAudioなど、分野別最適化ライブラリが揃っています。
これらを活用することで、多岐にわたる課題に容易に対応できます。
研究からプロダクションまでのシームレスな移行
研究段階で作成したモデルを実運用に移行する際、PyTorchはTorchScriptやONNX形式への変換が可能です。
さらに、PyTorch Lightningを用いることで、開発者はテンプレート化されたコードベースを利用し、実装スピードと可読性を高められます。
PyTorchの基本的な使い方・環境構築手順
PyTorchを活用するためには、まずは環境構築と基本的な操作手順を理解する必要があります。
このセクションでは、インストールからテンソル操作、ニューラルネットワークの定義、そしてトレーニング手順までを概観します。
基本を押さえることで、高度な応用やモデル拡張もスムーズに行えるようになります。
また、環境構築が面倒な方は、「実際にPyTorchを用いて画像認識をしてみる」まで進み、コラボラトリーで実行する事も可能です。
ステップ1:仮想環境の作成
今回は、PyTorchのテストとして、Anacondaでテスト用の新しい仮想環境を作成します。
以下のコマンドを実行して下さい。ここでは、「pytorch_test」という名前で、pythonのバージョンを3.9としています。必要に応じて、変更して下さい。
conda create -n pytorch_test python=3.9

実行すると、途中で以下のように表示されます。
「y」を入力して「Enter」をクリックして下さい。
すると、下記のように仮想環境の作成が完了です。
ステップ2:仮想環境を有効化
次に、作成した仮想環境を有効化します。以下のコマンドを実行して下さい。
conda activate pytorch_test
以下のように仮想環境を有効化することが出来ました。

ステップ3:PyTorchのインストール
PyTorchをインストールします。こちらの公式サイトに記載のインストールコマンドを使用します。
今回は、GPUの無い場合を考慮して、WindowsのCPUのみでPyTorchを動かすようにしています。GPUの用意あったり、別のOSで動かす予定の方は、上記の公式サイトから、該当のインストールコマンドを使用して下さい。
conda install pytorch torchvision torchaudio cpuonly -c pytorch
以下は、実行中の画面です。
途中で、先ほどと同様に下記のような表示が出てきます。「y」を入力して「Enter」をクリックして下さい。
すると、以下のようにインストールされていきます。

最終的に、以下のように「done」と表示されたらPyTorchのインストールが終了です。
また、後ほどの解説で使用する「matplotlib」もインストールしておきます。下記のコマンドを実行して下さい。
conda install matplotlib
実行中は先ほどと同様に、「y」を入力して「Enter」をクリックして下さい。
以下のように表示されれば、「matplotlib」のインストールも完了です。
ステップ4:テンソル操作の基本
PyTorchの基礎はテンソル(多次元配列)操作にあります。NumPyのような操作感で、加減乗除や行列演算、GPUへの転送などが簡単にできます。
ここでは、テンソル操作の基本を解説します。
テンソルの作成
以下は、テンソルを生成する基本操作です。
ゼロテンソルやランダムテンソルは、初期化やデバッグでよく使います。
import torch
# ゼロテンソル
x = torch.zeros(3, 3)
# ランダムテンソル
y = torch.randn(2, 3)
# 範囲指定テンソル
z = torch.arange(0, 10, 2)
print(x, y, z)
上記を実行すると、以下のように出力されました。

形状変換
モデル構築時に、テンソルの形を変えるのは非常に重要です。データのバッチ処理や次元操作に使います。
x = torch.randn(2, 3)
# リサイズ
y = x.view(3, 2)
# 次元を追加
z = x.unsqueeze(0)
# 次元を削除
w = z.squeeze()
print(y.shape, z.shape, w.shape)
上記を実行すると、以下のように出力されました。

GPUへの転送
PyTorchの強みであるGPU処理を活用するための基本操作です。GPUで計算する事で、学習速度が飛躍的に向上します。
if torch.cuda.is_available():
# GPUへ転送
x = torch.randn(2, 2).cuda()
print(x)
# CPUへ戻す
x = x.cpu()
print(x)
実際にPyTorchを用いて画像認識をしてみる
具体的な例として、画像認識モデル(今回は、MNIST手書き数字分類)をPyTorchで構築してみましょう。
実際のコードに触れることで、画像認識の流れが明確になります。
### モジュールファイルの作成
まずは、全体のコードを紹介します。適当なPythonファイルにコピペして保存して下さい。今回筆者は、「mnist_utils.py」という名前で保存しています。
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# データローダーを作成
def get_dataloaders(batch_size=64):
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
return train_loader, test_loader
# モデル定義
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
self.relu = nn.ReLU()
self.flatten = nn.Flatten()
self.fc = nn.Linear(32 * 26 * 26, 10)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.flatten(x)
x = self.fc(x)
return x
# モデルの学習
def train_model(model, train_loader, epochs=5, learning_rate=0.001):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
for epoch in range(epochs):
model.train()
running_loss = 0.0
for images, labels in train_loader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}/{epochs}, Loss: {running_loss/len(train_loader)}")
# モデルを保存
def save_model(model, path):
torch.save(model.state_dict(), path)
print(f"Model saved to {path}")
# モデルを読み込み
def load_model(path):
model = SimpleCNN()
model.load_state_dict(torch.load(path))
model.eval()
return model
# テスト精度の計算
def evaluate_model(model, test_loader):
correct = 0
total = 0
class_correct = [0] * 10
class_total = [0] * 10
with torch.no_grad():
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
for i in range(len(labels)):
label = labels[i].item()
if predicted[i] == label:
class_correct[label] += 1
class_total[label] += 1
# 全体精度
overall_accuracy = 100 * correct / total
# クラスごとの精度
class_accuracies = {
i: 100 * class_correct[i] / class_total[i] if class_total[i] > 0 else None
for i in range(10)
}
return overall_accuracy, class_accuracies
上記のコードは、以下のような動作を記述しています。
- 「get_dataloaders()」を呼び出してデータを準備する。
- 「SimpleCNN」クラスでモデルを定義する。
- 「train_model()」を使ってモデルを訓練する。
- 「save_model()」で学習済みモデルを保存する。
- 「load_model()」で保存済みモデルを読み込む。
- 「evaluate_model()」を使ってテストデータで精度を確認する。
ここで、上記のPythonファイルは直接実行しないので、コードを保存し終えたら、次の「### 認識精度の確認」へ進んでください。
認識精度の確認
次に、先ほど作成したモジュールファイルを使用して、MNISTデータセットへのモデルの認識精度を確認します。
同じく、適当なPythonファイルにコピペして保存して下さい。筆者は、「mnist_accuracy.py」という名前で保存しています。
import os
import torch
from mnist_utils import SimpleCNN, get_dataloaders, train_model, save_model, load_model, evaluate_model
# データローダーの準備
train_loader, test_loader = get_dataloaders()
# モデルの準備
model_path = "mnist_simplecnn.pth"
if os.path.exists(model_path):
print("Saved model found. Loading...")
model = load_model(model_path)
else:
print("No saved model found. Training the model...")
model = SimpleCNN()
train_model(model, train_loader)
save_model(model, model_path)
# モデルの評価
overall_accuracy, class_accuracies = evaluate_model(model, test_loader)
# 結果の表示
print(f"Overall Accuracy: {overall_accuracy:.2f}%")
print("Class-wise Accuracy:")
for class_id, accuracy in class_accuracies.items():
if accuracy is not None:
print(f"Class {class_id}: {accuracy:.2f}%")
else:
print(f"Class {class_id}: No samples")
上記のコードは簡単に言うと、以下のような処理を実行します。
- 「get_dataloaders()」を呼び出して、学習用とテスト用のデータローダーを準備する。
- モデルが保存されているか確認する。
- 保存済みモデルがあれば、
load_model()でモデルを読み込む。 - 保存済みモデルがなければ、「impleCNN」クラスで新しいモデルを作成し、「train_model()」で学習させ、「save_model()」で保存する。
- 保存済みモデルがあれば、
- 「evaluate_model()」を使ってテストデータでモデルの精度を計算する。
- 全体精度とクラスごとの精度を表示する。
それでは、実際に上記のコードを実行して見ます。以下のコマンドで実行できます。
python mnist_accuracy.py
実行すると、まずは以下のようにMNISTのデータセットをダウンロードします。エラー文が出ていますが、特に気にしなくて大丈夫です。

下記のように、新しく「data」という名前のディレクトリが作成され、その中にMNISTのデータセットが保存されています。

そのまま待っていると、下記のように学習が進行・完了し、学習が完了したモデルは「mnist_simplecnn.pth」という名前で保存されます。
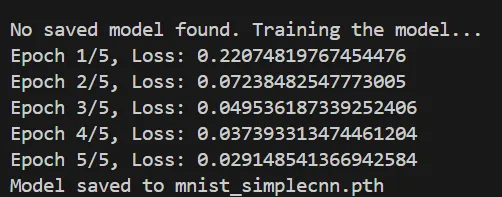
以下のように保存を確認出来ました。

さらにその後、下記のように、用意したMNISTのテストデータへの平均正答率と、各ラベル(0~9の数字)の正答率が表示されます。この正答率は、今回のモデルの精度を表しています。
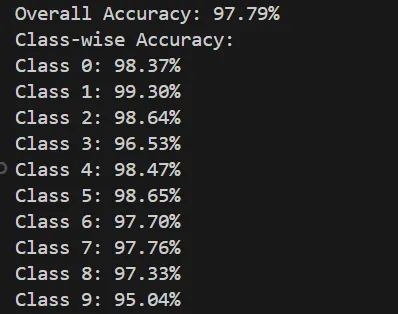
今回は、0~9の手書き数字10000枚に対して、97.79%の精度で認識できていることが分かります。
また、「1」が99.30%と最も精度良く認識できている事が分かります。
これは、数字の概形的に、「1」は他の数字だと誤認しにくいからであると考えることが出来ます。
画像認識テスト
最後に、1枚の画像を取り出し、先ほど用意した学習済みのモデルを用いて、画像認識のテストをしてみます。
筆者は、「mnist_example.py」という名前で保存しています。
import random
import torch
import matplotlib.pyplot as plt
from mnist_utils import SimpleCNN, get_dataloaders, load_model
# データローダーの準備(テストデータのみ使用)
_, test_loader = get_dataloaders()
test_dataset = test_loader.dataset
# 保存済みモデルをロード
model_path = "mnist_simplecnn.pth"
model = load_model(model_path)
# ランダムな画像を選択
random_index = random.randint(0, len(test_dataset) - 1) # ランダムインデックス
image, label = test_dataset[random_index] # ランダムな画像とラベルを取得
# モデルで予測
with torch.no_grad():
output = model(image.unsqueeze(0)) # バッチ次元を追加
_, predicted = torch.max(output, 1) # 予測クラスを取得
# 画像を表示
plt.imshow(image.squeeze(), cmap="gray")
plt.title(f"True Label: {label}, Predicted: {predicted.item()}")
plt.axis("off")
plt.show()
それでは、MNISTのデータセットからランダムに一枚の画像を取り出し、学習済みのモデルを使用して認識をチェックします。以下のコマンドを使用し、上記のコードを実行します。
python mnist_example.py
実行すると、下記のように注意喚起の文章が表示されますが、無視で大丈夫です。

すると、以下のように画像認識の結果が表示されます。
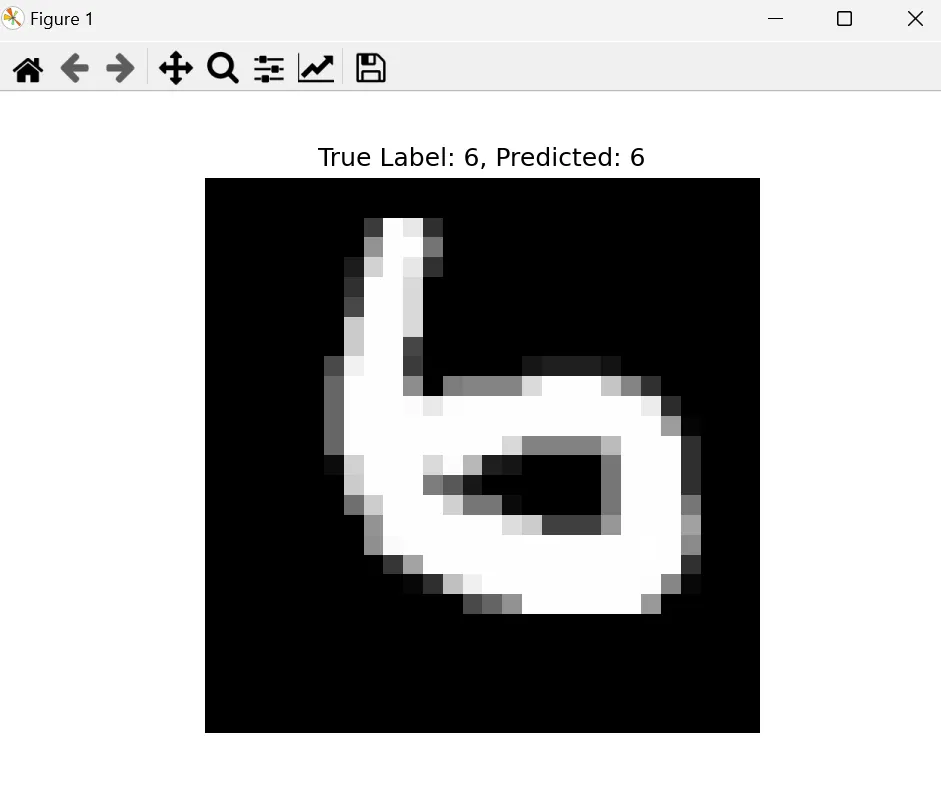
真ん中に大きく表示されている画像が、今回テストに用いた手書き画像です。
私たちが書かれている数字を「6」であると認識出来る通り、画像上部の左側には、「True Label:6」と記載されています。これは、正解が「6」であるという事です。
次に、画像上部の右側には、「Predicted:6」と記載されています。これは、先ほど作成した学習済みのモデルが、数字を「6」だと認識した事を表しています。
このように、PyTorchを用いたCNNによって、画像認識モデルを作成し、実際に画像認識を行う事が出来ました。
AIによる画像認識について詳しく知りたい方は、こちらをご覧ください。
仮想環境の削除
今回の解説に際して作成した仮想環境が不要な方は、以下のコマンドで削除する事が出来ます。
conda remove -n pytorch_test --all
PyTorchを用いた高度なトピック
基礎を押さえた後は、高度な機能やツールを活用することで、性能向上や開発効率化を図ることができます。
転移学習、分散学習、TorchScript、PyTorch Lightningといったテーマについて、それぞれ詳細を確認していきましょう。
転移学習
学習済みの大規模モデル(ResNetやBERTなど)を再利用することで、学習コストを削減しつつ高精度を目指す手法です。
事前学習済みモデルの特徴を活かし、新しいタスクに適用できます。
ファインチューニング
転移学習をさらに特化させた手法で、学習済みモデルの一部または全体を微調整して、自分の課題に最適化します。
この手法により、少ないデータでも高い精度が期待できます。
分散学習
「torch.distributed」を使用して、複数のGPUや複数のマシンにまたがる大規模データセットの学習が可能になります。
これにより、大規模モデルのトレーニング時間を短縮できます。
マルチGPUサポート
単一マシンで複数GPUを活用することで、計算負荷を分散し、学習速度をさらに向上させる手法です。
PyTorchはこれを簡単にサポートします。
TorchScript
PyTorchモデルを最適化して保存し、C++ランタイム上で動かす仕組みです。
これにより、推論速度の向上や、リソース制約のある環境でのデプロイが可能になります。
ONNX形式への変換
PyTorchモデルをONNX形式に変換すると、他のフレームワークや環境(Caffe2、TensorRTなど)での推論が可能になります。
これにより、クロスプラットフォームでの柔軟性が向上します。
PyTorch Lightningの活用
PyTorch Lightningは、コードの可読性と再利用性を高めるためのフレームワークです。
モデル定義やトレーニングループをテンプレート化し、大規模プロジェクトでも管理しやすくします。
PyTorch導入事例・活用例
PyTorchはアカデミックな研究だけでなく、ビジネスや産業界でも幅広く利用されます。
ここでは研究分野・企業・実務プロダクトでのデプロイ例を示し、PyTorchがどのように実世界で役立っているかを紹介します。
研究分野での利用例
画像・音声・自然言語処理などの最先端研究でPyTorchが採用され、トップクラスの論文や学会発表でも利用されています。研究者はPyTorchを通じてアイデアを迅速に実装し、実験できます。
例えば、以下の記事で紹介している最新技術である「ControlNet」にもPyTorchは活用されています。
ContorlNetとは?プリプロセッサ一覧やインストール方法、使い方を解説
企業での実装事例
製造業では品質検査や異常検知、医療分野では画像診断支援など、多岐にわたる領域でPyTorchモデルが実運用されています。大手企業からスタートアップまで、PyTorchは現実課題の解決に貢献しています。
以下の記事では、AIによる画像認識の活用例をご紹介しています。
おすすめのAI画像認識サービスを比較!実際の使用例や活用事例も紹介
実務プロダクトでのデプロイ
TorchServeを用いると、学習済みモデルをWeb API化し、クラウド上にスムーズにデプロイ可能です。
これによりユーザーに即時の推論サービスを提供でき、新たなビジネス価値を生み出します。
PyTorchとTensorFlowの比較
 左:PyTorchの公式サイトより引用、右:TensorFlowの公式サイトより引用
左:PyTorchの公式サイトより引用、右:TensorFlowの公式サイトより引用
PyTorchが人気を博す一方で、TensorFlowも長年にわたり広く利用されています。
本セクションでは、PyTorchとTensorFlowの比較を通じて、それぞれの特徴を整理し、自分のプロジェクトに適した選択の判断材料を提供します。
開発フローの違い
TensorFlowは元々静的計算グラフを採用しており、グラフを事前に定義してから実行する形式でした。
一方、PyTorchは動的計算グラフを採用しており、実行時にグラフを構築します。
この違いにより、PyTorchはコードの修正やデバッグが容易で、試行錯誤を繰り返す研究やプロトタイプ開発に適しています。
一方、TensorFlowも後に動的グラフモード(Eager Execution)を導入し、柔軟性を改善しています。
学習速度・性能面の差異
どちらもGPUやTPUの最適化が進んでおり、学習速度や性能はモデルや使用するハードウェアによって異なります。
TensorFlowはGoogleが開発したTPUを活用できる点で、特定の環境では非常に高い効率を発揮します。
一方、PyTorchは直感的な分散学習API(torch.distributed)が強みで、大規模なGPUクラスタを利用する環境で便利です。
コミュニティ・リソースの充実度
PyTorchとTensorFlowはどちらも大規模なコミュニティを持ち、多数のリソースが利用可能です。
TensorFlowについては、こちらで詳しく解説しています。
PyTorch利用時のよくある質問(FAQ)
PyTorchを実務で活用する際に直面しやすい課題に対する答えをQ&A形式でまとめました。学習速度、メモリ効率、モデルのデプロイ、バージョン互換性など、幅広い疑問にお答えします。
GPUメモリが不足して学習が進まない場合は?
バッチサイズを減らすのが最も簡単な対策です。また、Mixed Precision Training(「torch.cuda.amp」)を活用することで、メモリ使用量を大幅に削減できます。
さらに、高メモリ搭載のGPUを利用するか、学習コードを最適化して不要なテンソルを削除することも効果的です。
学習速度を上げるにはどうすればいいですか?
以下の方法を検討してください。
- データローダーの「num_workers」を増やしてデータローディングを並列化する
- 高速なGPU(例: RTXシリーズやA100)を利用する
- モデルのプロファイリング(「torch.profiler」)を行い、ボトルネックを特定して最適化する
GPU(グラフィックボード)については、こちらで詳しく解説しています。
学習済みモデルをどのようにデプロイすればよいですか?
学習済みモデルは「torch.jit.trace」や「torch.jit.script」でTorchScript形式に変換すると推論が高速化します。
また、PyTorch Serveを使えば、モデルをAPIとして提供できます。クラウドサービス(AWS、GCPなど)を利用することで、スケーラブルな推論環境を構築することも可能です。
モバイルデバイスでPyTorchモデルを使用できますか?
はい、PyTorch Mobileを利用することで、AndroidやiOSデバイスにモデルを展開可能です。
PyTorch Lite Interpreterを使えば、リソース制約のある環境でも効率よく動作します。
PyTorchをバージョンアップした場合、コードが動かなくなる可能性はありますか?
基本的に後方互換性が保たれていますが、新バージョンでは一部のAPIが非推奨になることがあります。
リリースノートを確認し、互換性の影響がないか確認した上でテスト環境で事前に動作確認を行うことをお勧めします。
どのPyTorchバージョンを選ぶべきですか?
安定した環境を求める場合は、最新のLTS(長期サポート版)を利用してください。一方で、最新機能を試したい場合は最新リリース版を選ぶと良いでしょう。
これらの情報を参考に、PyTorchをより効果的に活用してください。

まとめ
本記事では、深層学習フレームワークであり、研究から実務まで幅広く利用されているPyTorchについて解説しました。実際に環境構築からテンソル操作の基本、MNISTを用いた画像認識の実装例までを通じて、PyTorchの基礎を学びました。本記事を参考にして、PyTorchを活用したさらなる研究や開発に挑戦してください。










