この記事のポイント
 この記事は、Microsoftが提供するクラウドサービス「Azure Data Lake」の詳細について説明しています。
この記事は、Microsoftが提供するクラウドサービス「Azure Data Lake」の詳細について説明しています。- Azure Data Lakeは、大量のデータを保存し、アクセスしやすくするためのシステムです。
- 構造化・非構造化データを問わず、そのままの形式でデータを保管できます。
- データレイクとデータウェアハウスの違いについて明確に説明しており、それぞれの利点を比較しています。
- Azure Data Lakeの具体的な導入手順についても案内しています。

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
デジタル化が進む現代において、企業が蓄積するデータの量は飛躍的に増大しており、その管理と活用は経営上の大きな課題となっています。そこで注目されているのが、マイクロソフトが提供するクラウドサービス「Azure Data Lake」です。本記事では、Azure Data Lakeがいかにして大規模データの保存、処理、分析を効率化し、企業のビジネスインサイト獲得を支援するかを、分かりやすく解説します。データレイクとデータウェアハウスの違いから、Azure Data Lakeの具体的な構成サービス、活用シナリオ、導入方法までを網羅しています。ビッグデータの価値を最大限に引き出し、迅速で柔軟な意思決定を支えるAzure Data Lakeについて、詳しくご紹介しますのでぜひ参考にしてください。
目次
Azure Data Lakeとは
Azure Data Lakeとは、Microsoft Azureが提供する大規模なデータを効率的に保存、管理、処理するためのクラウドベースのプラットフォームです。
特にビッグデータの分析や機械学習に最適化されたサービスであり、企業が生成する膨大な量のデータを最大限に活用できるように設計されています。
Azure Data Lakeは、主に以下のサービスによって構成されています。
1. Azure Data Lake Storage:データの保存
2. Azure Synapse Analytics:データの分析
3. Azure HDInsight:データの処理
デジタル化の時代、会社や組織が扱うデータはどんどん増えています。そんな中でそのデータを「どこに保存するか」「どうやって活用するか」は大きな課題です。
Azure Data Lakeは、この課題を解決するためのクラウドサービスで、大量のデータをまとめて保存し、必要なときに簡単に活用できるようにする仕組みを提供しています。
Azure Data Lakeを使えば、データの形式に関係なくそのまま保存することができます。そして、必要なタイミングでそのデータを分析したり、AIや機械学習に使ったりすることができます。
さらに、クラウドならではの柔軟性があり、必要に応じて容量を簡単に増やせたり、コストを抑えたりできるのも特徴です。
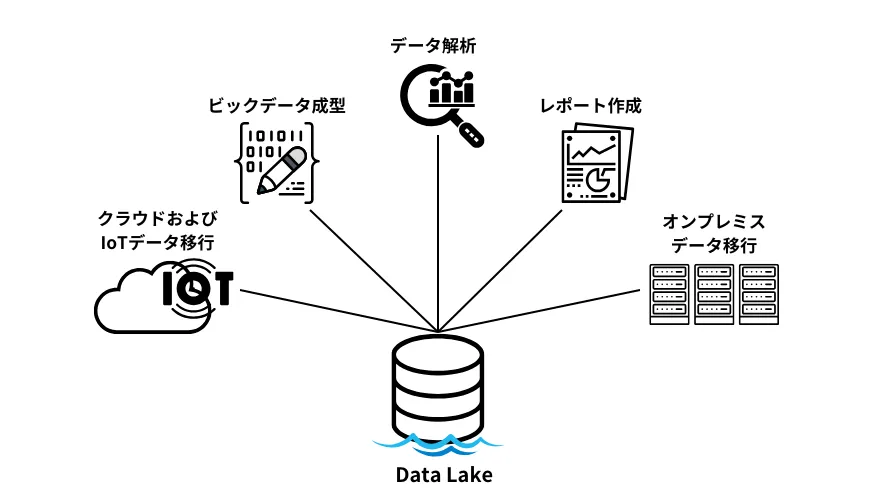
DataLakeイメージ(参考:公式ホームページ)
データレイクについて
Azure Data Lakeは、そもそもデータレイクという考え方が基となっています。しかしデータレイクとは何でしょうか。ここでは、データレイクという概念について説明します。
データレイクとデータウェアハウスの違い
Azure Data Lakeが採用しているのはデータレイクという仕組みですが、データ管理にはほかにデータウェアハウス(DWH)という仕組みもあります。両者には次のような違いがあります。
-
データウェアハウス(DWH)
主に構造化データ(データベース形式のデータ)を保存し、効率的に分析するためのシステムです。データは保存する前に整理・加工され、分析しやすい形で保存されます。
「決まった形のデータを早く分析する」用途に適しています。
-
データレイク
データをそのままの形式で保存しておき、必要になったときに分析や加工を行う仕組みです。構造化データだけでなく、画像や動画、センサーデータなどの非構造化データも一緒に保存できます。
この柔軟性により、将来どのようにデータを使うかが決まっていない場合でも、データを無駄なく保存して活用できるというメリットがあります。
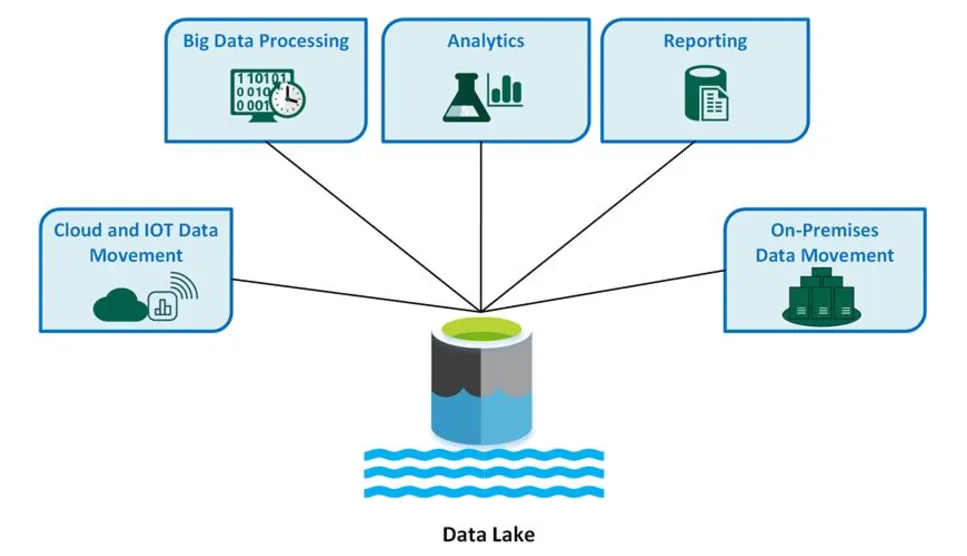 データレイクイメージ図(参考:マイクロソフト)
データレイクイメージ図(参考:マイクロソフト)
詳細な違いは次のとおりです。
| 特徴 | データウェアハウス(DWH) | データレイク |
|---|---|---|
| 対象データ形式 | 構造化データ | 構造化、半構造化、非構造化データ |
| 保存方法 | 保存前に整理・加工 | そのままの形式で保存 |
| 分析用途 | 定型的なレポート作成や高速分析 | 多様な分析・機械学習に対応 |
| 柔軟性 | 限定的 | 高い |
| ストレージコスト | 高め | 低め |
それぞれの特性を理解し、目的に応じて使い分けることが重要です。
Azure Data Lakeの特徴
Azure Data Lakeは、データレイクの考え方をクラウドベースで実現するためのMicrosoftのソリューションで、以下のような特徴があります。
1. データ形式に依存しない保存
構造化データ、半構造化データ、非構造化データをそのままの形式で保存できます。
そのため、事前にデータを加工したりスキーマを定義する必要がありません。
2. 高スケーラビリティ
データ量の増加に応じて自動的に拡張可能です。小規模なデータからペタバイト級のデータまで対応可能で、容量不足を心配する必要がありません。
-
3. 柔軟なデータ活用
保存したデータを必要に応じて加工・分析することができ、多様な分析手法(バッチ処理、リアルタイム処理、機械学習など)に対応しています。 -
4. コスト効率
データのアクセス頻度に応じたストレージ層(ホット、クール、アーカイブ)を選択することで、ストレージコストを最適化できます。
さらに、従量課金モデルを採用しているため、必要な分だけコストが発生します。
-
5. セキュリティとコンプライアンス対応
Azure Data Lakeは、データ暗号化やMicrosoft Entra IDによるアクセス管理を提供し、高いセキュリティを実現しています。
また、GDPRやHIPAAなどの業界標準に対応しているため、信頼性が高いサービスです。
Azure Data Lakeの主要機能
Azure Data Lakeは、主に以下の機能によって構成されています。
1. Azure Data Lake Storage:データの保存
2. Azure Synapse Analytics:データの分析
3. Azure HDInsight:データの処理
ここでは、それぞれのサービスについて説明します。
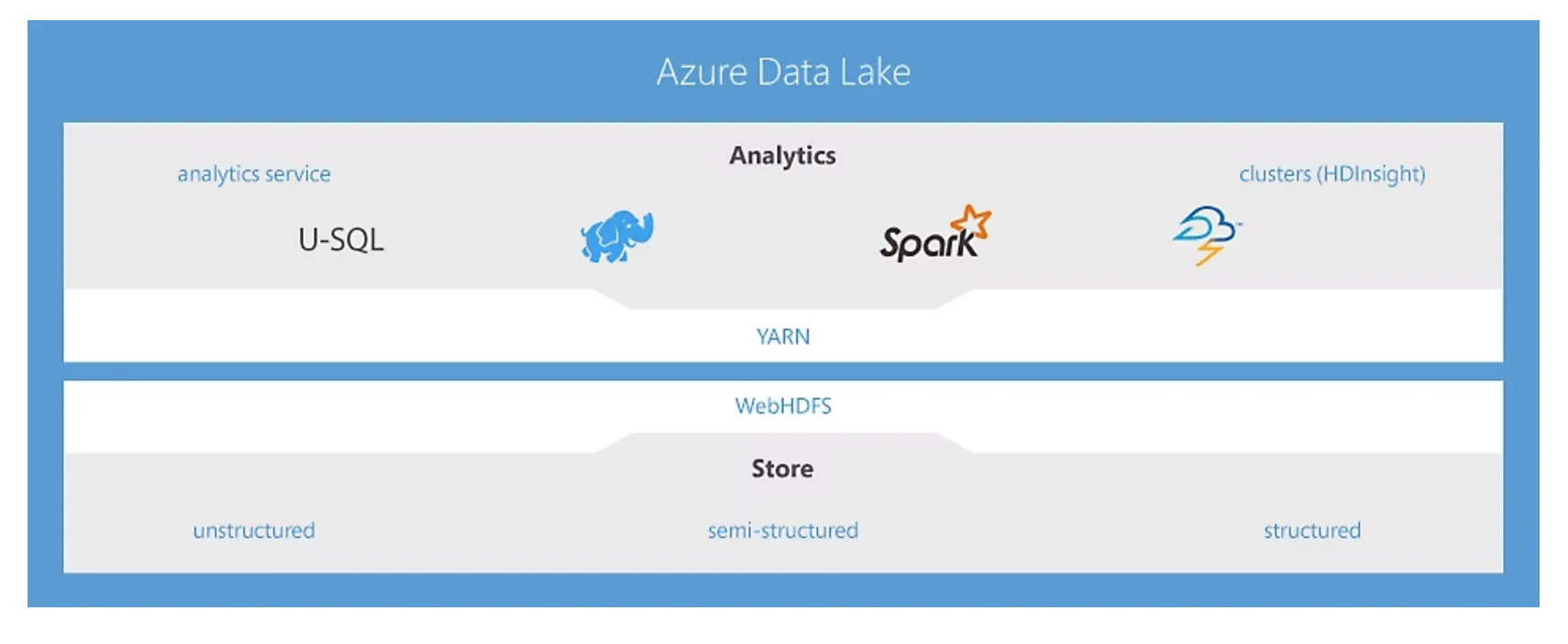 Azure Data Lakeイメージ(参考:マイクロソフト)
Azure Data Lakeイメージ(参考:マイクロソフト)
Azure Data Lake Storage
Azure Data Lake Storageは、Azure Data Lake全体の中心となるサービスで、さまざまな形式のデータを保存するための高性能なクラウドストレージです。
特に、ビッグデータの保存と管理に適しており、構造化データ、半構造化データ、非構造化データを一元的に管理できます。
 (出典元:公式ホームページ)
(出典元:公式ホームページ)
Azure Data Lake Storageの特徴は次のとおりです。
大容量スケーラビリティ
ペタバイト級のデータ保存が可能です。データが増えても自動で容量を拡張できるため、容量不足の心配がありません。
例えば、IoTデバイスからリアルタイムで送られてくるセンサーデータや、大量の画像ファイルをそのまま保存することが可能です。
柔軟な保存とアクセス
データを「そのままの形式」で保存できるため、データを加工する手間が不要です。
また、さまざまなツール(Synapse Analytics、Databricks)やプログラム(Python、R、Spark)から簡単にアクセスすることができます。
HDFS互換
Hadoop Distributed File System (HDFS) とは、大量のデータを効率的に分散して保存し、並列処理で高速にアクセスするためのファイルシステムです。
Azure Data Lake StorageはHDFSに対応しているため、HDFSを使う前提で作られたツール(例: Apache Hadoop、Apache Sparkなど)と簡単に連携することができます。
ストレージ層の選択
データの使用頻度に応じて、以下の中から最適な保存オプションを選べる仕組みになっています:
- ホット層: 頻繁にアクセスするデータ。
- クール層: 使用頻度が低いデータ。
- アーカイブ層: 長期保存用データ。
Azure Synapse Analytics
Azure Synapse Analyticsは、Microsoft Azureが提供する大規模データ分析プラットフォームです。
以前のAzure SQL Data Warehouseが進化したもので、構造化データや非構造化データを簡単に分析することができます。
 Azure Synapse Analyticsイメージ
Azure Synapse Analyticsイメージ
Azure Synapse Analyticsの主な特徴は以下のとおりです。
1. オールインワンのプラットフォーム
Azure Synapse Analyticsは、データ分析に必要なツールがすべて揃った統合プラットフォームです。
データの取り込み、保存、変換、分析、可視化まで、すべてを一つの環境で管理することができます。
2. スケーラブルな設計
このプラットフォームは、小規模なデータ分析からペタバイト規模のビッグデータ処理まで対応可能です。
必要に応じて計算リソースを拡張・縮小できるため、データ量やビジネスニーズに応じて柔軟に対応できます。
3. コスト効率の良さ
Azure Synapse Analyticsでは、サーバーレスオプションが利用できるため、使用した分だけリソース費用が発生します。
そのため、リソースを常に固定的に維持する必要がなくなり、特定の期間だけ利用する分析ジョブに対しても運用が可能です。
4. 柔軟性と既存スキルの活用
SQLをはじめ、一般的に利用されるデータ分析言語やツールをサポートしているため、既存のスキルをそのまま活用できます。
また、Azure SynapseはPower BIやAzure Machine Learningとも簡単に連携できるため、データの可視化やAIモデル構築もスムーズに行えます。
Azure HDInsightとは
Azure HDInsightとは、Microsoft Azureが提供するクラウドベースのビッグデータ処理サービスで、オープンソースのビッグデータ技術をAzure環境で簡単に活用できるプラットフォームです。
 Azure HDInsightイメージ
Azure HDInsightイメージ
Azure HDInsightの主な特徴は以下のとおりです。
1. オープンソースツールのサポート
Azure HDInsightは、Apache Hadoop、Spark、Kafka、HBase、Stormなどのオープンソーステクノロジーを活用できるクラウドベースのプラットフォームです。
既存のHadoopエコシステムをAzure上で簡単に利用できます。
2. 大規模データ処理に対応
HDInsightは、分散処理アーキテクチャを採用しており、大量のデータを効率的に処理できます。ペタバイト規模のデータ分析、リアルタイムデータ処理、ストリーミング処理など、さまざまな場面で対応可能です。
分散処理アーキテクチャとは、大量のデータを複数のコンピュータ(ノード)に分散して処理する仕組みのことです。
3. スケーラビリティとコスト効率
必要に応じてクラスターを拡張・縮小することで、データ量や処理ニーズに合わせて柔軟にリソースを調整することができます。また、従量課金モデルなので、使用した分だけ費用が発生し、運用コストを抑えることができます。
4. セキュリティと統合性
Microsoft Entra IDとの統合により、セキュアなアクセス制御を提供しています。さらに、データの暗号化機能や監査ログの記録など、エンタープライズレベルのセキュリティ要件を満たしています。
Power BIやAzure Machine Learningなどの他のAzureサービスとも簡単に連携可能です。
【関連記事】
➡️Microsoft Entra IDとは?その機能や料金体系をわかりやすく解説!
Azure Data Lakeのユースケースと活用例
Azure Data Lakeを活用することで、さまざまなデータ処理や分析ニーズに対応できます。ここでは具体的な利用シナリオを説明します。
IoTデータの収集とリアルタイム分析
工場の設備やスマートデバイスから送られる大量のセンサーデータを蓄積し、異常をリアルタイムで検知したい場合、以下のような活用例が考えられます。
例:
- Azure Data Lake Storage: IoTデバイスから送られるデータ(温度、圧力、振動など)をそのまま保存。
- Azure HDInsight: Apache Kafkaを使ってリアルタイムでデータをストリーミング処理。異常値を検知してアラートを送信。
- Azure Synapse Analytics: 蓄積されたデータを分析し、設備のトレンドや異常パターンを予測。予防保守に活用。
ソーシャルメディア分析と顧客インサイトの抽出
ソーシャルメディアでのブランド評価や顧客の声をリアルタイムで把握し、マーケティングに活用したい場合、以下のようにAzure Data Lakeが役立つでしょう。
例:
- Azure HDInsight: ソーシャルメディアから収集したストリーミングデータをApache Sparkで処理。感情分析やトレンド抽出を実施。
- Azure Data Lake Storage: 分析対象の未加工データや分析結果を保存。
- Azure Synapse Analytics: 感情スコアやトレンドデータを統合し、顧客インサイトを可視化。Power BIと連携してマーケティングチームに提供。
医療画像の保存とAI解析
医療用スキャンデータ(X線、MRIなど)を安全に保存し、AIを使って疾患を検出することも以下のような方法で可能となります。
例:
- Azure Data Lake Storage: 医療画像をそのままの形式で保存。患者データの暗号化によるセキュリティも確保。
- Azure HDInsight: Apache Sparkを使って画像データを前処理し、AIモデル用に準備。
- Azure Synapse Analytics: AI解析結果を統合し、疾患検出のレポートを作成。
Azure Data Lakeの導入手順
ここではAzure Data Lakeの導入手順についてご紹介します。
Azure Data Lake導入の流れ
主な流れは以下のとおりです。
- ステップ1 : Azure Data Lake Storageの設定
- ステップ2 : データコンテナの作成
- ステップ3 : 分析・処理ツールとの連携
Azure Data Lakeの具体的な導入手順
ここからはAzureポータルを使った具体的な手順をご説明します。
ステップ1: Azure ストレージ アカウントの作成
-
Azureポータルにアクセスし、Azureアカウントでサインインします。
Azureポータル画面
-
Azureポータル画面の「リソースの作成」で「storage account」で検索し、「ストレージ アカウント」をクリックします。
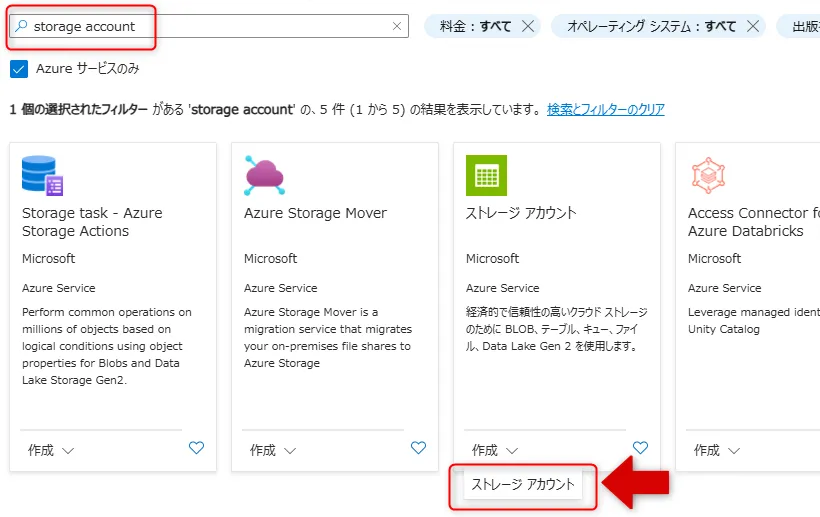
ストレージアカウント選択画面
-
「ストレージアカウントを作成する」画面、「基本」タブで適切な設定をします。ここでは「プライマリサービス」として"Azure Blob Storage または Azure Data Lake Storage Gen 2"を設定します。
「次へ」をクリックします。
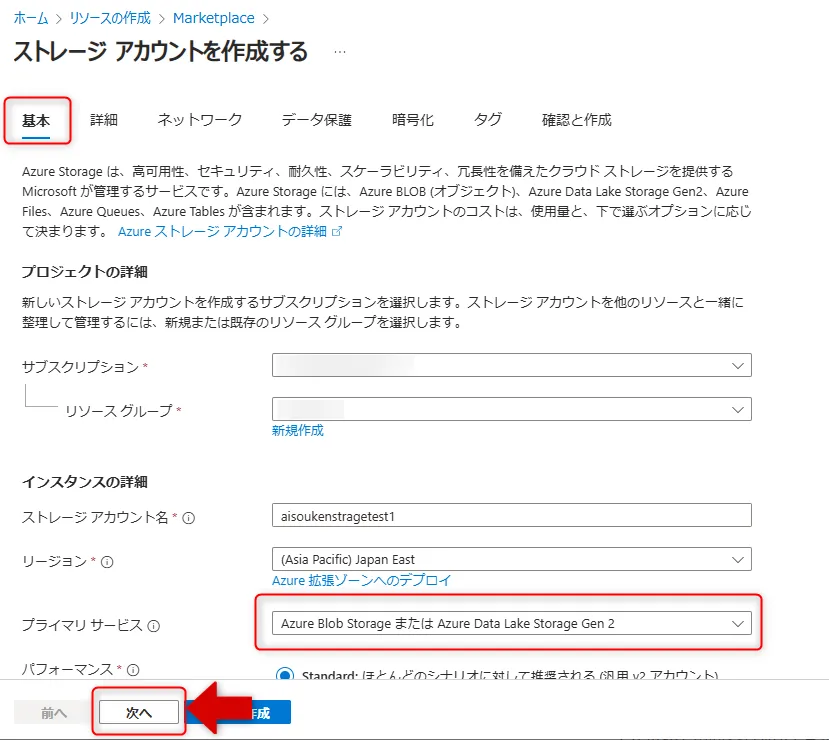
基本タブ画面
- 「詳細」タブで適切な設定をします。
「次へ」をクリックします。
詳細タブ画面
- 「ネットワーク」タブで適切な設定をします。
「次へ」をクリックします。
ネットワークタブ画面
- 「データ保護」タブで適切な設定をします。
「次へ」をクリックします。
データ保護タブ画面
- 「暗号化」タブで適切な設定をします。
「確認と作成」をクリックします。
暗号化画面
- 「確認と作成」タブで適切な設定がされていることを確認します。
「作成」をクリックします。
確認と作成画面
- デプロイ完了後「リソースに移動」をクリックします。
デプロイ完了画面
ステップ2: データコンテナの作成
- 作成したストレージアカウントにおいて、「データストレージ」→「コンテナー」→「+ コンテナー」をクリックします。
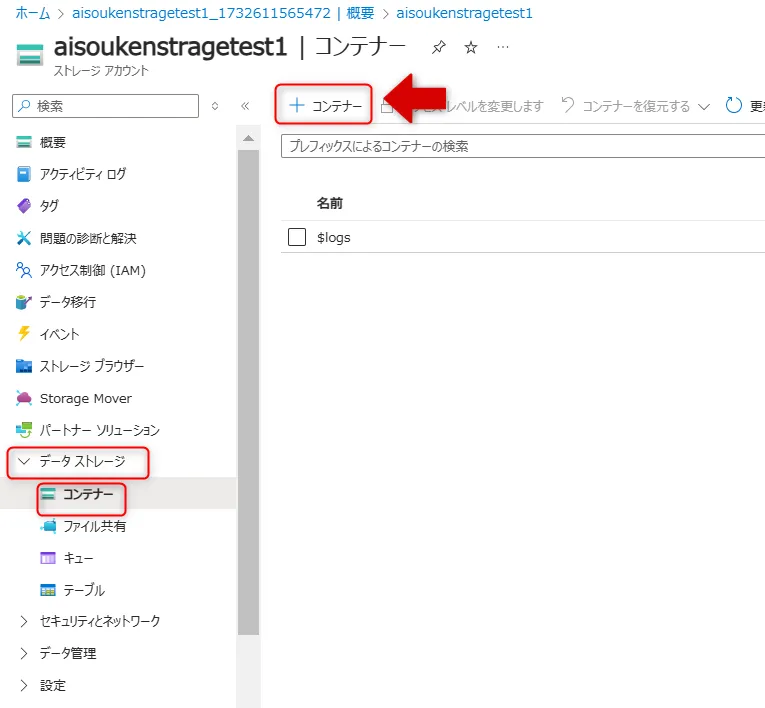
コンテナー選択画面
- 「新しいコンテナー」画面で適切な設定をします。
「作成」をクリックします。
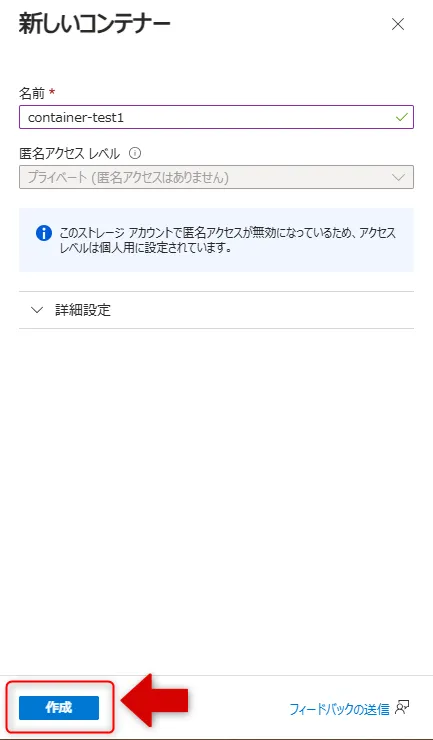
コンテナー作成画面
- コンテナーが作成されたことを確認します。

コンテナー作成確認画面
ステップ3 : 各種システムとの連携
Azure Synapse Analytics、Databricks、HDInsightなどと連携して、データ処理や分析を開始します。
Azure Data Lakeの料金体系
Azure Data Lakeのそれぞれのサービスは料金体系が異なっています。詳細は以下のリンク先をご参照ください。

まとめ
この記事は、Microsoftが提供するクラウド型ビッグデータ分析プラットフォームAzure Data Lakeについて解説しました。
Azure Data Lakeは、大規模データを効率的に保存、処理、分析できるクラウドベースのシステムです。データの形式に関係なくデータを保存し、必要なタイミングでそのデータを分析したり、AIや機械学習に使ったりすることができるので、企業がデータを最大限に活用し、ビジネスインサイトを迅速に得るための強力な基盤となります。ビッグデータ時代において、複雑なデータ処理をシンプルにし、スピードとコスト効率を兼ね備えた柔軟なプラットフォームを提供してくれるでしょう。
ぜひAzure Data Lakeを導入して、データ保存から分析、統合までを効率的に行えるデータ基盤を構築してみてください。これにより、膨大なデータを活用した迅速な意思決定が可能となり、ビジネスの競争力向上や業務効率化が実現することでしょう。
本記事が皆様のお役に立てたら幸いです。










