この記事のポイント
 過去のAzure障害事例とその原因分析を紹介
過去のAzure障害事例とその原因分析を紹介- Azure障害発生時の確認方法と対応手順を解説
- Azure利用時に遭遇しやすい7つのエラーとその対処法を提示
- Xを活用したAzure障害速報の受信方法を説明
- Azure障害への効果的な予防策3選を提案

Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
Azure運用において障害対策は極めて重要なファクターです。障害は予期せぬ形で発生するため、障害の迅速な確認方法、適切な初期対応、そして何より事前の予防策を理解しておくことが不可欠です。
本記事では、Azureサービスにおける過去の障害事例と、それらの原因を紹介しながら、障害発生時の適切な対応手順や予防策などを解説しています。
実際に起きたAzure障害の具体的な事例を取り上げ、そこから得られた教訓を振り返ります。さらに、Azure利用時に出くわしがちな典型的なエラーコード(403、500、401など)についても、わかりやすく原因と対処法をまとめています。
過去の障害事例から学び、しっかりとした障害管理スキルを身につけましょう。
Azureの基本知識や料金体系、利用方法についてはこちらの記事で詳しく解説しています。
➡️Microsoft Azureとは?できることや各種サービスを徹底解説
過去に起きたAzureの障害事例
Azureクラウドは幅広い企業に利用されているため、もし障害が起こるとその影響は計り知れないものになります。
過去に発生した障害事例を振り返り、何が問題だったのかを分析することは、将来的に同様の状況を避けるために重要です。
今回は、過去に起きた3つの障害事例を見ていきましょう。
ARMの障害
事例の詳細
2024年1月21日の01:30から08:58 UTCにかけて、Azure Resource Manager(ARM)を使用しようとしたユーザーはリソース管理操作に問題を抱える可能性がありました。
この問題はARMを介した操作に影響を及ぼし、主に米国中央、米国東部、米国南中央、米国西中央、西ヨーロッパへの影響がありましたが、ARMのグローバルな性質上、他地域にもその範囲が広がっていた可能性はあります。
この問題は、ARM(Azure Resource Manager)を基盤とする多くのAzureサービスに波及し、ストレージやキーボールトなど、最新のRBAC(Role-Based Access Control)情報の取得に障害が生じたサービスが影響を受けました。
原因
2020年6月、ARMはEntra Continuous Access Evaluationとのプライベートプレビュー統合を展開しました。
しかし、このプレビュー機能には認証失敗時に問題を引き起こす潜在的なコード欠陥がありました。
2024年1月21日、内部保守プロセスによる設定変更がこの欠陥を引き起こし、ARMノードの起動失敗を繰り返しました。
これにより、ARMはリクエスト処理能力を段階的に失い、最終的には可用性が急激に低下しました。
Azure Storageの障害
事例の詳細
2023年3月6日の未明から夕方にかけて、西ヨーロッパにあるAzure Storageを使っていた一部のユーザーは、通常よりも多くのリクエスト制限に直面しました。
この問題はAzure Storageに依存する様々なAzureサービスの断続的な障害やパフォーマンスの低下を引き起こしました。
原因
Azure Storageの制限機構を改善する新設定が展開されましたが、展開途中で問題が発覚しました。
この変更は特定のスケールユニットにおいて、予期せずストレージアカウントを制限し、健康な状態への回復を試みましたが、実際には逆効果でした。
パケットロス
事例の詳細
2023年6月16日の02:34 UTCから07:25 UTCの間、ネットワークの問題により西ヨーロッパ地域への入出トラフィックに大量のパケットロスが発生しました。これにより、この地域にホストされているリソースは可用性の低下、スループットの低下、またはレイテンシの増加を経験しました。
また、このネットワーク接続に依存するAzureサービスやMicrosoft 365などのサービスにも影響が出ました。
原因
この障害の原因は、西ヨーロッパ地域を管理するネットワーク自動化システムに新しいネットワークトポロジー記述が追加されたことにあります。
この新しいトポロジーには、まだ接続されていない、または有効化されていない物理リンクが「本番」として誤ってリストされていました。
自動化システムは、動作中の物理リンクと非動作中の「本番」リンクを含むLAGを検出し、リンクの不均衡を防ぐためにLAGをオフにする標準的な対処を開始しました。
上記はあくまでも一例です。過去の障害記録は、Azureの公式ドキュメントで公開されています。
その他の事例を知りたい方は以下の公式ドキュメントをご覧ください。
Azureの状態の履歴(Microsoft公式)
Azure障害発生の確認方法
Azure障害が発生した際の迅速な確認は、被害の拡大を防ぐ上で非常に重要です。
障害の発生状況を早期に把握し、適切な対応を行うことができれば、ダウンタイムを最小限に抑えることが可能になります。
障害発生の確認ツール
Azureには障害やサービスの異常を検出し、報告するためのAzure Service Healthというサービスがあります。
これは、以下の3つのサービスから構成されています。
| サービス | 特徴 |
|---|---|
| Azureの状態 | すべてのAzureリージョンの全Azureサービスの正常性を確認できます。ただし、現在Azureを使用しているユーザーは以下のService Healthを利用することが推奨されています。 |
| Service Health | 使用しているAzureサービスとリージョンの正常性についてのカスタマイズされたビューが提供されます。 |
| Resource Health | 特定の仮想マシンインスタンスなど、個々のクラウドリソースの正常性に関する情報を入手できます。 |
Azure障害発生の確認ステップ
-
Azureポータルにログインする
まずAzureポータルにログインし、「Service health」へアクセスします。
画像のように、ログイン時のホーム画面にService healthのアイコンが表示されていると思いますが、表示されていない方は上の検索バーに「Service health」と入力して出てきたものをクリックします。
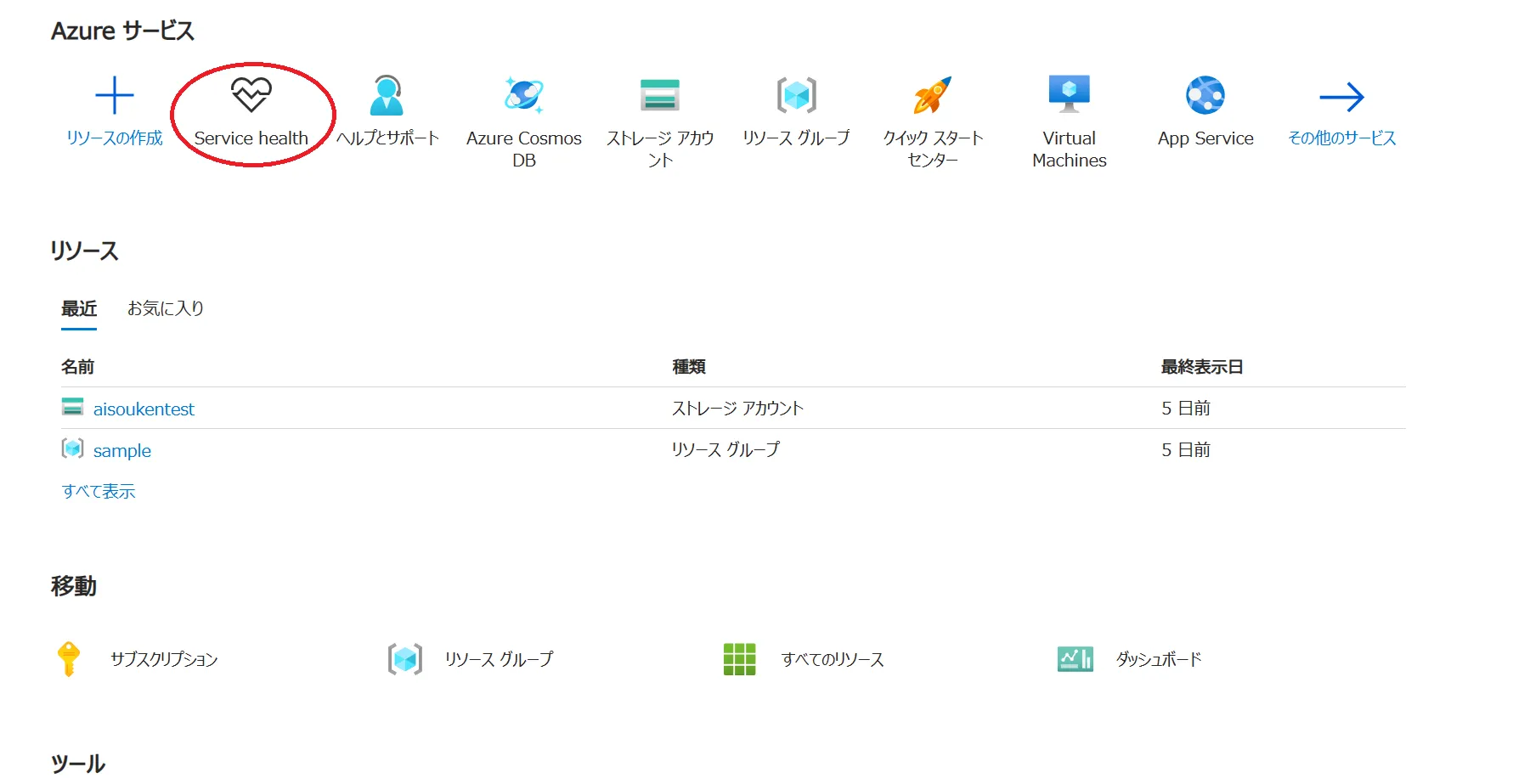
ポータルログイン後の画面
-
ダッシュボードの確認
特定のサービスや地域に影響を与える可能性のあるアドバイザリ、インシデント、メンテナンスプランを確認します。
-
リソースの状態の確認
特定のリソースの状態に関する情報が必要な場合は、Azure Resource Healthを使用して状態を確認します。
この手法により、Azureの障害を素早く正確に把握し、適切な対処ができるようになります。
障害の早期発見と迅速な対応は、サービスの機能停止時間を最小限に抑え、ビジネスの損失を防ぎます。
Azure障害発生時の対応手順
Azure環境で障害が発生を確認した後に続く対応手順は、障害の規模や影響によって異なる場合がありますが、ほとんどのケースで共通する基本的なガイドラインが存在します。
障害発生時の対応手順をしっかりと理解し、計画的に行うことで、ビジネスのダウンタイムを削減し、リカバリーの迅速化を図ることができます。
コミュニケーションプランの実施
障害の状況を関係者に透明に伝えることが求められます。顧客、従業員、パートナーへの定期的な更新は、信頼の維持に欠かせません。
インシデント対応手順の実行
既に計画されているインシデント対応手順に従って作業を開始します。トラブルシューティング、ワークアラウンドの適用、顧客への代替サービスの提案などがこれに含まれます。遭遇しやすいエラーに関しては、後ほどご紹介します。
Azureサポートチームとの連携
追加の支援が必要な場合は、Azure Supportを利用して専門家からの助言や指示を仰ぎます。
サポートリクエストを作成し、必要に応じてプライオリティを設定します。Azure portalにログインし、画像の左下の表示されている「ヘルプとサポート」をクリックします。
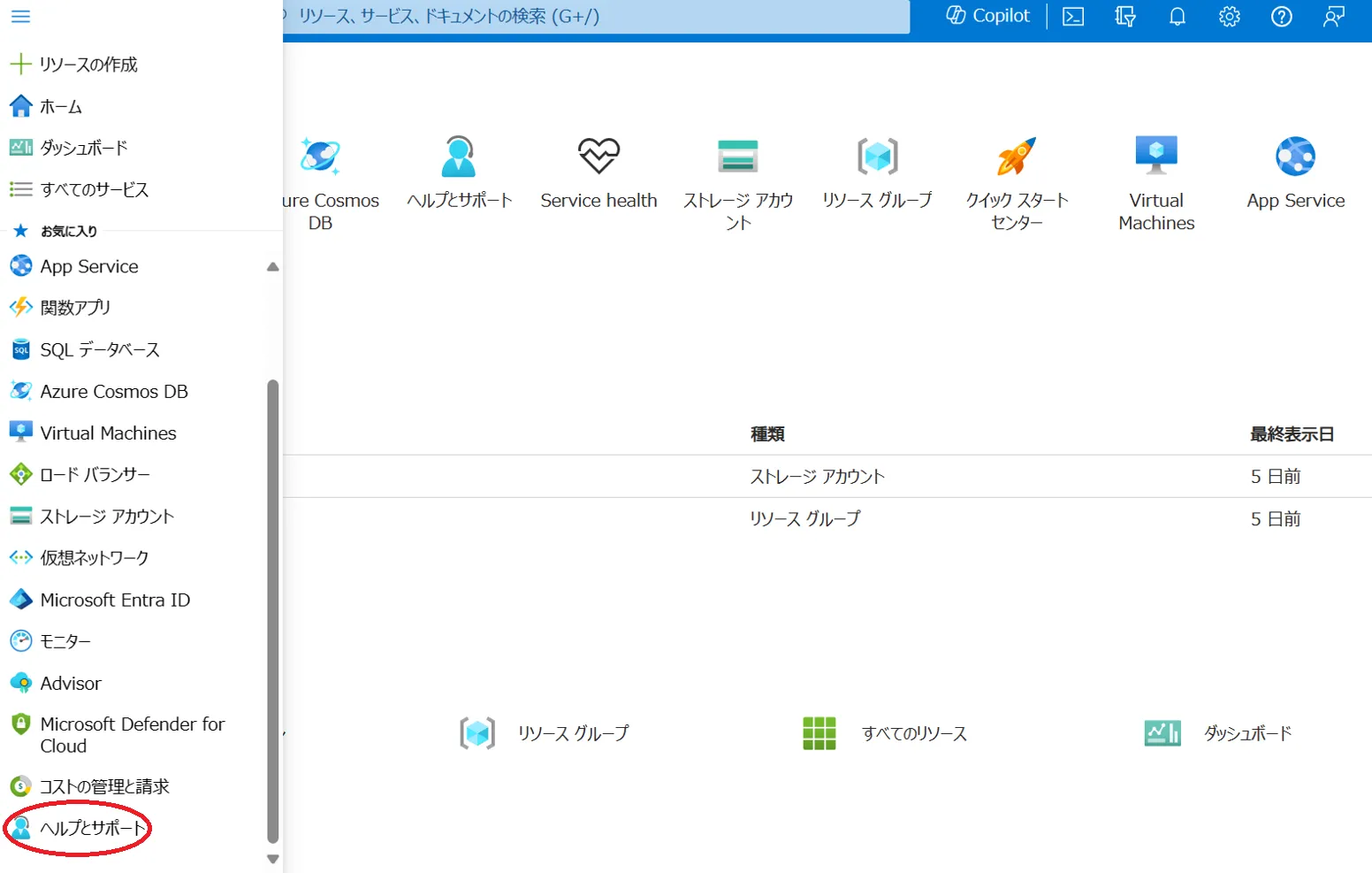
ヘルプとサポートへの移動
すると、「サポートリクエストの作成」がでてくるのでそこをクリックします。
リクエストには、障害が発生しているサービス、発生日時、症状の詳細、実施済みのトラブルシューティングの手順などを記しておくことをおすすめします。
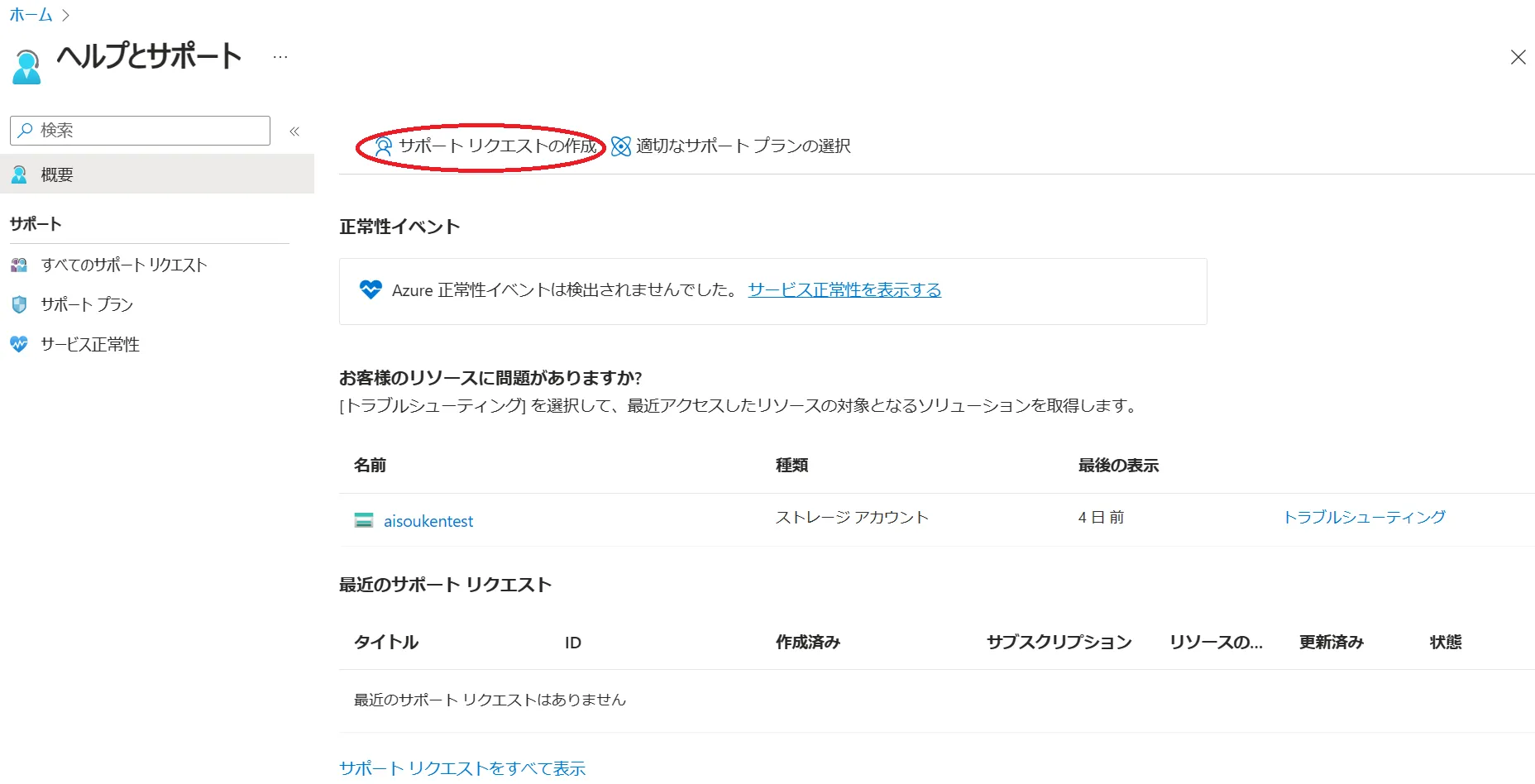
サポートリクエストの作成
Azureのサポートプランについて
サポート内容や、Azure Supportの対応速度は、加入しているAzureサポートプランによって異なります。
最も標準的なプランである「Basic サポートプラン」は、Azureのサブスクリプションに基本的に含まれているサポートレベルで、Azureサービスを使うすべてのカスタマーが対象になります。
有料プランに加入する事で、利用可能なサポートレベル、レスポンス時間、対応可能な問い合わせの範囲、専門家へのアクセスレベル等、より優れた対応が期待できます。
【関連記事】
➡️Azureのサポートプランとは?料金やサービス内容から徹底比較
対応状況の監視とアップデート
障害の修正進行状況を監視し、新たな情報が得られ次第、状況の変化を関係者に伝達します。
障害が解決した際には、すぐさま通知することが不可欠です。
リカバリープロセスの開始
障害からの回復に向け、バックアップからの復元やサービスのリスタート、設定の調整などを行います。
予め定められたリカバリープロセスに従い進行させることで、作業を効率化します。
Azure利用時に遭遇しやすいエラー7選とその対処法
Azureを利用する際、ユーザーは様々なエラーに遭遇する可能性があります。これらのエラーは、設定ミス、リソースの限界、外部からの不測による障害など、様々な要因によって発生します。
ここでは、代表的なエラーとその原因を簡単に紹介します。
Azure 401 (Unauthorized) エラー
Azure 401 (Unauthorized) エラーは、認証が必要または失敗したことを示します。
リクエストが正しい認証情報を提供せずに保護されたリソースにアクセスしようとした場合に返されます。
対処法
- 認証情報(アクセストークン、API キーなど)が正しいことを確認する
- 認証情報が期限切れになっていないことを確認する
- 認証方式が正しく実装されていることを確認する
より詳しい原因や対処法については、こちらの記事をご覧ください。
【関連記事】
➡️Azure 401エラー(Unauthorized Error)の原因と対処法を徹底解説!
Azure 403 (Forbidden) エラー
Azure 403 (Forbidden) エラーは、クライアントにリソースへのアクセス権がないことを示します。認証は成功しているが、アクセスが禁止されています。
対処法
- クライアントに適切なアクセス権限(ロール、スコープなど)が付与されていることを確認する
- リソースのアクセス制御設定が正しく構成されていることを確認する
- 条件付きアクセスポリシーが適切に設定されていることを確認する
より詳しい原因や対処法については、こちらの記事をご覧ください。
【関連記事】
➡️Azure 403 Forbiddenエラーとは?その原因と対処法を徹底解説
Azure 500 (Internal Server) エラー
Azure 500 (Internal Server) エラーは、サーバー側の問題によりリクエストを処理できないことを示します。具体的な原因は様々で、サーバーの設定ミスやプログラミング上のエラーなどが考えられます。
対処法
- エラーログとスタックトレースを確認し、根本原因を特定する
- アプリケーションコードとサーバー設定を見直し、問題を修正する
- Azureサポートに連絡し、assistance getting it resolvedを求める
より詳しい原因や対処法については、こちらの記事をご覧ください。
【関連記事】
➡️Azure 500 Internal Server Errorとは?原因と対処方法を解説!
Azure 502 (Bad Gateway) エラー
Azure 502 (Bad Gateway) エラーは、ゲートウェイまたはプロキシサーバーが不正なレスポンスを受け取ったことを示します。これは、上流サーバーとの通信問題が原因で発生することがあります。
対処法
- 上流サーバーのヘルスと応答性を確認する
- ゲートウェイまたはプロキシサーバーの設定を確認し、問題を修正する
- ネットワーク接続と構成を確認し、潜在的な問題を特定する
より詳しい原因や対処法については、こちらの記事をご覧ください。
【関連記事】
➡️Azure 502 Bad Gatewayエラーの原因と対策方法を解説!
Azure 503 (Service Unavailable) エラー
Azure 503 (Service Unavailable) エラーは、サーバーが一時的に過負荷またはメンテナンスでリクエストを処理できない状態であることを示します。後で再試行することが推奨されます。
対処法
- 指数バックオフ再試行ロジックを実装して、サーバーに負荷をかけすぎないようにする
- サーバーのスケーリングとキャパシティを確認し、適切に調整する
- メンテナンスの予定時間とアナウンスを確認する
より詳しい原因や対処法については、こちらの記事をご覧ください。
【関連記事】
➡️Azure 503エラー(Service Unavailable)の原因と対処法をわかりやすく解説
Azure 504 (Gateway Timeout) エラー
Azure 504 (Gateway Timeout) エラーは、ゲートウェイまたはプロキシサーバーが上流サーバーからのタイムリーなレスポンスを受け取れなかったことを示します。これは、ネットワーク問題が原因で発生することがあります。
対処法
- 上流サーバーのパフォーマンスと応答性を確認する
- ゲートウェイおよびプロキシサーバーのタイムアウト設定を確認し、必要に応じて調整する
- ネットワーク接続とレイテンシを監視し、問題を特定する
より詳しい原因や対処法については、こちらの記事をご覧ください。
【関連記事】
➡️Azure 504Gateway Timeoutエラーの原因は?対処法をわかりやすく解説
Azure 53003 (アクセス権がありません) エラー
Azure 53003 (アクセス権がありません) エラーは、特定の条件付きアクセスポリシーに関連するアクセス制御の問題によって引き起こされます。
対処法
- 条件付きアクセスポリシーの要件(デバイスコンプライアンス、MFA など)を満たしていることを確認する
- 条件付きアクセスポリシーの設定が適切であることを確認し、必要に応じて調整する
- ユーザーアカウントとデバイスの状態を確認し、問題を修正する
より詳しい原因や対処法については、こちらの記事をご覧ください。
【関連記事】
➡️Azure 53003エラーとは?原因と対処法をわかりやすく解説!
Azureの障害速報を受け取るためのX活用法
Xを用いた障害情報の速報受信は、障害発生時に迅速な対応を行うために非常に有用です。Azure障害発生時の通知を効率的に受け取るためには、以下の手順でXを活用します。
-
Azure関連の公式Twitterアカウントをフォローする
Microsoft Azureの公式アカウントや、特定のサービスの状態を更新するアカウント
(Microsoft 365 Status)などをフォローし、障害情報を発信する公式ソースから情報を収集します。
-
通知をオンにする
フォローした公式アカウントからの通知を受け取るように設定します。これにより、障害情報が投稿された場合にタイムリーにアラートを受けることができます。
-
関連ハッシュタグをチェックする
特定の障害やイベントに関連するハッシュタグ(例:#AzureOutage、#AzureDown)をフォローしたり、検索したりして、コミュニティからのアップデートや他のユーザーの経験を追跡します。
-
リスト機能を活用する
Azureサービスに関連したアカウントをまとめたTwitterリストを作成することで、障害情報のみをフィードで見ることが可能になります。
-
モバイル通知の活用
スマートフォンでTwitterアプリを利用している場合は、モバイル通知を有効にして、いつでもどこでも重要な障害報告を即座にチェックできるように設定します。
Azure障害速報の受け取り方を知っておくことで、障害発生時の判断材料を素早く集められるようになります。
これは、ビジネスの損失を抑え、迅速なコミュニケーションと問題解決を実現するために非常に重要です。
Azure障害発生時への予防策3選
障害が発生した時の対応について知ることは必要不可欠ですが、事前に予防策を考慮することも重要です。予防策は多岐に渡りますが、ここでは特に効果が期待できると考えられる予防策を3つ紹介したいと思います。
1. 多層的なセキュリティ対策の実施
セキュリティは障害予防の最前線です。Azureでは、物理的セキュリティからネットワーク、アプリケーション、データ層に至るまで、多層的なセキュリティ対策が推奨されています。
具体的には以下のような対策が含まれます。
- ネットワークセグメンテーションとファイアウォールの適切な設定
【関連記事】
➡️Azure Firewallとは?NSGとの違いや料金、確認方法を徹底解説
- 暗号化の適用(保存データ、転送中のデータ)
- 脆弱性スキャンと修正プロセスの確立
- 強力な認証方式(多要素認証など)の採用
【関連記事】
➡️Azureの多要素認証とは?その概要やメリット、認証方式を徹底解説
また、アクセス制御やアイデンティティ管理を通じて、不正アクセスや悪意のある活動を防ぎます。これらの措置は、セキュリティ侵害による障害を防ぐために不可欠です。
2. リージョン間での冗長性の確保
Azureのグローバルインフラストラクチャを利用して、データとアプリケーションの冗長性をリージョン間で確保することが重要です。
特に、地理的に分散した複数のリージョンにワークロードを配置することで、自然災害やリージョン単位の障害から保護することができます。
これは、Azure Traffic ManagerやAzure Front Doorなどのサービスを利用することで、トラフィックを自動的に最適なリージョンに分散させ、ユーザーに対して高可用性を提供することが可能になります。
また、以下のような冗長性戦略も検討すべきです:
- ストレージアカウントのジオレプリケーション設定
- Azure SQL DatabaseのActive Geo-Replication
- 仮想マシンの可用性セット・ゾーンの活用
【関連記事】
➡️Azureのリージョンとは?その特徴や違い、選び方を徹底解説!
3. 監視と自動応答の仕組みの整備
障害を事前に予防し、迅速に対応するためには、継続的な監視と自動化された応答メカニズムの整備が欠かせません。Azure MonitorやAzure Application Insightsといったツールを使用することで、アプリケーションとインフラストラクチャのパフォーマンスをリアルタイムで監視し、異常が検出された場合には即座に通知を受け取れます。監視対象の例としては:
- CPU、メモリ、ディスク使用率
- ネットワーク遅延とエラー率
- アプリケーションのレスポンスタイムとエラー率
- サービス正常性とSLA遵守状況
さらに、上記のツールを利用して問題に対する自動化された応答(Auto Healing)を設定することで、障害の影響を最小限に抑えることができます。自動応答アクションの例は以下の通りです:
- 仮想マシンの再起動・再デプロイ
- ロードバランサーからの異常インスタンスの除外
- 自動スケールアウト・インによるキャパシティ調整
- バックアップからのデータ復元
これらの予防策は、システムをより強固にし、予期せぬ障害からビジネスを保護するための基本的なステップです。Azure環境を利用する際には、これらのアプローチを適切に組み合わせて適用することが推奨されます。
【関連記事】
➡️Azure Monitorとは?導入目的やメリット、料金体系を解説

まとめ
本記事では、Azureにおける過去の障害事例とその原因、障害発生時の対応方法、そして効果的な障害予防策について解説してきました。
過去の障害事例から、慎重なアップデート管理、入念な事前検証、迅速な障害検知と対応などの教訓が得られました。障害発生時には、原因特定、影響評価、復旧作業の優先順位付けを速やかに行い、ステークホルダーとの適切なコミュニケーションを維持することが重要です。
また、障害予防には、多層的なセキュリティ対策、リージョン間での冗長性確保、監視と自動応答の仕組み整備など、複数の対策を組み合わせた実施が有効であり、Azureはこれらに対応する様々なサービスを提供しています。
システム障害は完全に避けられませんが、適切な予防と迅速な対応により、ビジネスへの影響を最小限に抑えることは可能です。本記事の事例と対策を参考に、皆様のAzure環境の信頼性向上に役立てていただければ幸いです。
継続的な学習と改善により、安定したクラウドサービスの提供とお客様の信頼に応えていきましょう。










