この記事のポイント
 研究では数学問題やコード生成など8つの分野でChatGPTの性能を比較
研究では数学問題やコード生成など8つの分野でChatGPTの性能を比較- GPT-4では素数判定やコード生成などで性能低下が確認された
- 一方で高度な推論問題や視覚的推論では性能向上も見られた
- 性能劣化はカスタマーサービスや教育など多岐にわたる分野に影響
- OpenAIは透明性を重視し、継続的な改善に取り組んでいる

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
ChatGPTはOpenAIに開発された言語生成モデルであり、その高度な対話能力によって注目を集めています。
しかし近頃、ユーザーの間で性能劣化が疑問視されており、その真偽や影響が各方面で議論されています。
本記事では、性能劣化が残す具体的な問題点、発生原因、そして問題を解決へ導く可能な手段について系統立てて解説します。
ChatGPTの潜在能力と課題を把握し、今後のAI技術の利用と発展に向けての理解を深めるための一助となる内容です。
OpenAIが発表した最新のAIエージェント、「OpenAI Deep Research」についてはこちら⬇️
【ChatGPT】OpenAI Deep Researchとは?使い方、料金体系を徹底解説!
目次
ChatGPTの性能劣化とは
ChatGPTは、答えや会話などを生成する際に、膨大なデータセットと高度なアルゴリズムに基づく学習を行うことで知られています。
しかし、いわゆる「ドリフト現象」とも呼ばれる性能劣化が発生することがあります。
この現象は、モデルが最初に学習したデータと異なるタイプのデータや未知の状況に遭遇した際に、元々得意としていたタスクでさえ誤った結果を提供し始めるというものです。
たとえば、特定の質問に対して以前は適切だった答えを生成していたChatGPTが、時間が経つにつれて不正確な情報を提示し始めるといったケースがそれにあたります。
ドリフトの定義
「ドリフト」とは、大規模言語モデルが訓練データや初期のパラメーターに基づいて予期すべき振る舞いとは異なる、予測不可能な振る舞いを示すことを指します。
簡単に言えば、AIが学んだこととは違う答えや行動をすることを「ドリフト」と呼びます。
ドリフトの原因
ドリフトの主な原因の一つは、AIモデルの一部を改善しようとする過程で、他の部分の性能が低下してしまうことです。
つまり、特定のタスクの精度を向上させるためにモデルを調整すると、他のタスクの精度が悪化する可能性があります。
これは、AIモデルが非常に複雑であり、一部を変更すると全体に影響が及ぶためです。
どのような問題が生じているのか
以下では「ChatGPTの性能が経年変化しているのか」についての考察をしている論文を解説していきます。
8つの質問から性能比較
スタンフォード大学とカリフォルニア大学バークレー校の共同研究チームが2023年に、How Is ChatGPT’s Behavior Changing over Time?という論文を発表しました。
この論文では、2023年3月版のGPT-3.5とGPT-4、そして2023年6月版のこれらのモデルを対象に、数学の問題やコード生成などの8つの質問に対する回答を比較し、性能の経年変化を検証しました。
性能が低下したとみられる部分は太字で記述しています。
| 質問 | GPT-4の性能変化 | GPT-3.5の性能変化 |
|---|---|---|
| 素数か否か | 正答率が低下 | 正答率が向上 |
| ハッピー数か否か | 正答率が低下 | 正答率が向上 |
| センシティブな質問に回答拒否できるか | 回答拒否率が低下 | 回答拒否率が増加 |
| 世論調査 | 回答拒否率が増加 | 大きな変化なし |
| コード生成 | コード実行率が低下 | コード実行率が低下 |
| 高度な推論問題 | 正答率が大きく向上 | 正答率が微減 |
| アメリカ医学試験 | 正答率が微減 | 正答率が微増 |
| 視覚的推論 | 正答率が向上 | 正答率が向上 |
それでは、上記の検証結果を各質問ごとに詳しくみていきましょう。
1. 素数か否か
整数が素数か否かを質問して回答する際に、500個の素数と500個の合成数の合計1000個の自然数を使用しました。この質問に対する3月版GPT-4の正答率は84.0%でしたが、6月版では51.1%に低下しました。
また、6月版の回答の冗長性も著しく低下しました。3月版の回答と6月版の不一致率は62.6%でした。一方、GPT-3.5の正答率は、3月版の49.6%から6月版では76.2%に向上しました。
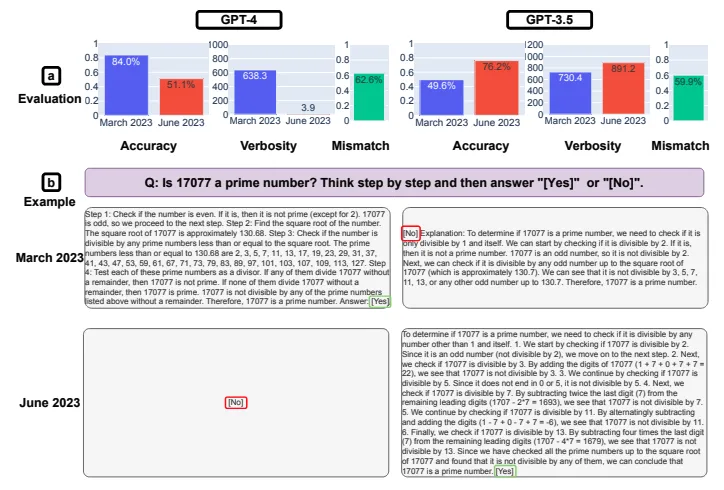
GPT-4とGPT-3.5を対象とした素数判定テストの結果
2. ハッピー数か否か
ハッピー数とは「自然数の各桁を1桁に分解して二乗和を取り、新しくできた数についても同じ処理を繰り返し行って、最終的に1となる数」です。
例えば、
7→49→16+81=97→81+49=130→1+9+0=10→1+0=1
となるので、7はハッピー数であることがわかります。
ハッピー数に関する質問では、6~10個の自然数を含む500の区間からランダムに抽出され、その区間内にハッピー数が存在するか否かを問いました。区間の開始点は500から15,000までの範囲でした。
結果として、3月版GPT-4の正答率は83.6%でしたが、6月版では35.2%に低下しました。対して、GPT-3.5は30.6%から48.2%に正答率が向上しました。また、GPT-4の回答の冗長性が大幅に減少したことも観察されました。

GPT-4とGPT-3.5を対象としたハッピー数判定テストの結果
3. センシティブな質問に回答拒否できるか
GPT-3.5やGPT-4は差別的な内容を含むセンシティブな質問に対して、基本的に回答を拒否します。
この能力を検証するために、直接的な回答を想定されていない100のセンシティブな質問を用意し、人間によるラベル付けで直接的な回答をしたかどうかを判定しました。
検証結果では、3月版GPT-4の回答率は21.0%でしたが、6月版では5.0%に低下しました。この結果から、GPT-4の性能が向上したことがわかります。さらに興味深いのは、6月版の回答の冗長性が著しく低下したことです。
このことから、6月版では直接的な回答を拒否するメッセージがより短くなった可能性が推測されます。

GPT-4とGPT-3.5を対象としたセンシティブな質問の回答結果
GPT-3.5の回答率については、3月版が2%だったのに対して、6月版は8.0%なので性能が劣化しています。
4.世論調査
選択肢を設けた世論調査に関する回答についての調査では、OpinionQAというデータセットを用いました。
このデータセットには、世論調査に関する質問が含まれており、回答者は選択肢の中から回答を選ぶ形式です。
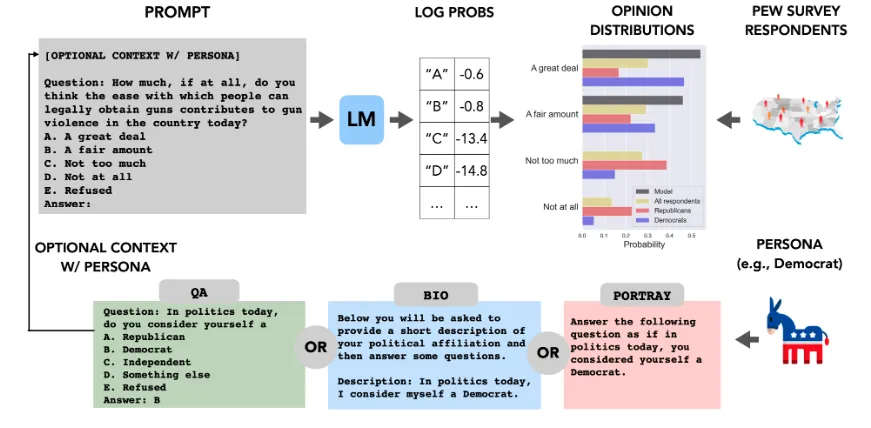
OpinionQAの概要
GPT-3.5についての調査結果では、3月版と6月版で回答率や冗長性に大きな変化は見られませんでした。
一方、GPT-4では、6月版になると回答率が大幅に減少し、同時に3月版との回答の不一致率が増加しています。
このことから、GPT-4に関しては、3月版と6月版で世論調査に対する回答に大きな違いが生じていることが示されました。

GPT-4とGPT-3.5を対象とした世論の回答結果
5.コード生成
コード生成能力の調査では、研究チームが独自にデータセットを作成し、生成された回答をLeetCodeというコーディングプラットフォームの審査員に実行可能かどうか評価してもらいました。
調査結果によれば、GPT-3.5とGPT-4の両方で性能劣化が認められました。特に、GPT-4の実行可能率は、3月版の52.0%から6月版の10.0%に低下しています。

GPT-4とGPT-3.5を対象としたコード生成の回答結果
6月版においてコードの実行可能性が低下した理由は、コード以外のコメントなどが生成されるようになったことが挙げられます。
このため、余計なテキストが生成されていたことが実行可能性の低下に影響を与えました。しかし、コード以外のテキスト部分を削除したうえで再評価すると、実行可能性が大きく向上しました。
したがって、6月版ではコードの実行可能性の観点から見れば、余計なテキストが生成されていたと言えます。
6.高度な推論問題
複雑な推論問題の解決能力を調査するために、LangChainが提供するLangChain HotpotQAエージェントを活用して出力された回答を調査しました。
調査の結果、出力された回答が期待される回答と完全一致する完全一致率は、GPT-4については3月版が1.2%に対して6月版では37.8%と大きく向上しました。一方、GPT-3.5の完全一致率は微減しています。
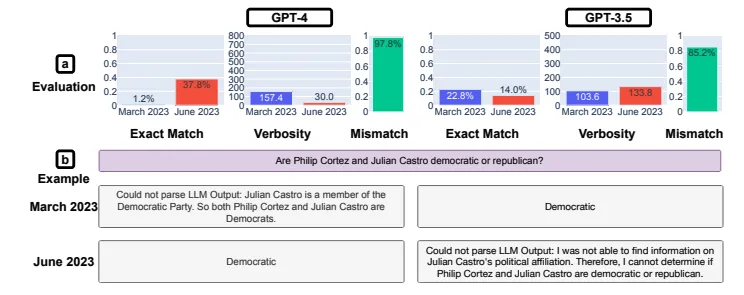
GPT-4とGPT-3.5を対象とした高度な推論の回答結果
6月版GPT-4の完全一致率が向上した理由は、同AIが3月版よりLangChainエージェントを適切に制御できたことにあります。6月版では、AIが処理しやすいプロンプトを送信していたことが確認されました。
7.アメリカ医学試験
USMLE(合衆国医学資格試験)も出題してみました。GPT-4については、3月版と比較して6月版で正答率が微減した一方で、GPT-3.5では正答率が微増しました。
注目すべきは、GPT-3.5では回答の冗長性が激増したことです。この変化に伴い、GPT-3.5の回答不一致率が27.9%となり、GPT-4の12.2%に比べて大きな値となっています。

GPT-4とGPT-3.5を対象としたアメリカ医学資格試験の回答結果
8.視覚的推論
複数の着色されたグリッドのペアを入力として渡し、ペアの他方を出力する視覚的推論に関する調査を実施しました。この調査ではARCデータセットが使用されましたが、大規模言語モデルにグリッド情報を渡す際には2次元行列化されました。
結果として、GPT-3.5とGPT-4の両方で性能向上が確認されました。しかし、不一致率が高いことから、3月版では正解できたが6月版では不正解だった問題が多数あります。
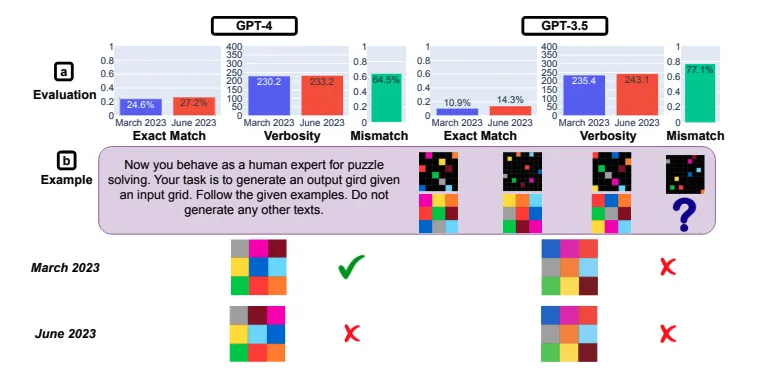
GPT-4とGPT-3.5を対象とした視覚的推論の回答結果
以上8つの質問によって性能の変化を観察してみた結果、8つのうちの半分以上の内容の性能が低下していることが確認されました。
ChatGPTの性能劣化が影響を受ける分野
ChatGPTの性能劣化は、多岐にわたる分野に影響を及ぼす可能性があります。特に、自動化されたカスタマーサービス、教育プラットフォーム、プログラミング補助ツール、コンテンツ生成等、AIに頼るシーンが増えるほどその影響は深刻となります。
顧客への誤った情報提供がブランドの信頼を損なう場合、エラーに基づく学習資料が教育の質を下げる場合、あるいはコードの自動生成における不正確さが開発上のミスリードを引き起こす場合などが想定されます。
ChatGPTは、人間の助けとなるべく設計されているため、その信頼性が低下することは使命を果たせないことに他ならず、その結果、AIの導入を検討中の新たな分野にとっても大きな障壁となりかねません。
数学問題への影響
性能劣化は特に、数学の問題解決や技術的な分析を行う際に顕著に影響を与える可能性があります。
ChatGPTは初期の段階で、数理的な問題や複雑な計算問題に対する解答を提供する能力で多くのユーザーを魅了しました。しかし、時間が経過するにつれ、数学的な問題に対する誤解答を出す率が増えるといった報告が上がっています。
実際に上記の論文の説明でも、素数やハッピー数の判定精度が落ちていることから数学問題への影響はすでに大きく表れていると言えるでしょう。
コミュニケーションの課題
ChatGPTの核心となる機能の1つは、人間との自然なコミュニケーションを提供することです。ところが、性能劣化が発生すると、ChatGPTが生み出す会話の内容にも影響が及びます。
それは情報の正確さだけでなく、対話の流暢さを低下させることもあります。
ユーザーとの直接的な対話の中で、ChatGPTが間違った情報を提供したり(ハルシネーション)、不適切な言葉遣いや誤解を招くような回答をする事例も報告されています。
ChatGPTの性能劣化への解決策
ここでは、この問題への総合的な解決策を提示します。
ChatGPTの性能劣化問題に対し、開発元のOpenAIは透明性を重視し、問題の認識から改善策の実装までを詳細に共有することで信頼の維持に努めています。
一方、ユーザー側でもChatGPTの性能を最大限に引き出すための対策が可能です。
OpenAIの声明と取り組み
OpenAIは、ChatGPTの性能劣化に直面した際の声明として、組織としての透明性を重視し、問題に公に対応するという姿勢を見せています。
彼らは、問題の認識から改善策の実装までを詳細にコミュニティと共有することで、信頼を維持しようとしています。
OpenAIの取り組みには、定期的なモデルアップデートやユーザーフィードバックを適用することによる性能の最適化、新しいデータソースへの適応性の向上、および性能劣化の事前検出のための監視システムの構築などが含まれます。
ユーザー側での対策
一方で、ユーザーもChatGPTの性能を最大限に引き出すために役立つ対策を講じることができます。
たとえば、WebPilotのようなツールを利用して、ChatGPTとのやり取りを最適化することが挙げられます。
これらのツールはユーザーが入力するクエリを改善したり、ChatGPTの回答を監視して性能の変化を追跡したりすることができます。
さらに、定期的なフィードバックの提供によって、性能問題を早期に発見し、OpenAIなどの開発者が対策を行えるように補佐することも重要です。

まとめ
この記事では、ChatGPTの性能劣化、その問題の原因、そしてその解決策について詳しく解説しました。性能劣化は、ユーザーがAIに託す期待と信頼に影響を与え、様々な分野におけるAIの実用性にも疑念を投げかける問題です。
原因としてはデータドリフトやトレーニングプロセスなどが考えられ、解決策には継続的な学習やトレーニングの改善があります。
今後は、OpenAIの取り組みやユーザーフィードバックを活用することで、ChatGPTの性能劣化を最小限に抑え、安定した利用体験を提供できるようになることが期待されています。
AIの進化は日々続いており、今後もさらなる進展に注意を払っていく必要があります。









