この記事のポイント
 ChatGPTは自己注意機構を有する「Transformerモデル」に基づいて、ユーザーの入力に対する適切な応答を生成します。
ChatGPTは自己注意機構を有する「Transformerモデル」に基づいて、ユーザーの入力に対する適切な応答を生成します。- 記事ではテキストの前処理の重要性についても触れており、トークン化や埋め込みなどの概念を紹介しています。
- ChatGPTの評価方法や課題についても説明し、AIシステムの性能を測定する方法や今後の改善点を提示しています。
- ChatGPTの仕組みを理解することで、AIテクノロジーに関する知識が深まり、その可能性をより具体的に捉えることができます。

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AIと自然に会話できる時代が到来し、多くの人がチャットボット「ChatGPT」を利用し始めています。しかし、その背後で動作している仕組みを理解している人は少ないかもしれません。
本記事では、OpenAIが開発したChatGPTがどのようにして賢明な回答を生成するのかを、わかりやすく段階的に説明します。
テキストの前処理から始まり、トランスフォーマーモデルを使用した自己注意機構まで、ChatGPTの動作原理をわ解説しています。
ChatGPTの仕組みを学ぶことで、AIへの理解を深め、テクノロジーの魅力や可能性をより身近に感じることができるでしょう。ぜひ、この記事を通じてAIの世界を探求してみてください。
OpenAIが発表した最新のAIエージェント、「OpenAI Deep Research」についてはこちら⬇️
【ChatGPT】OpenAI Deep Researchとは?使い方、料金体系を徹底解説!
目次
ChatGPTの仕組み
ChatGPTは、ユーザーからの入力を自然言語処理というAI技術を用いて処理することで、的確な応答を生成しています。
AIとの会話例
ChatGPTの仕組みを理解するには、いくつかのステップに分けて考えることが有効です。
ChatGPTの仕組みを分解して順序立てて理解してみましょう。
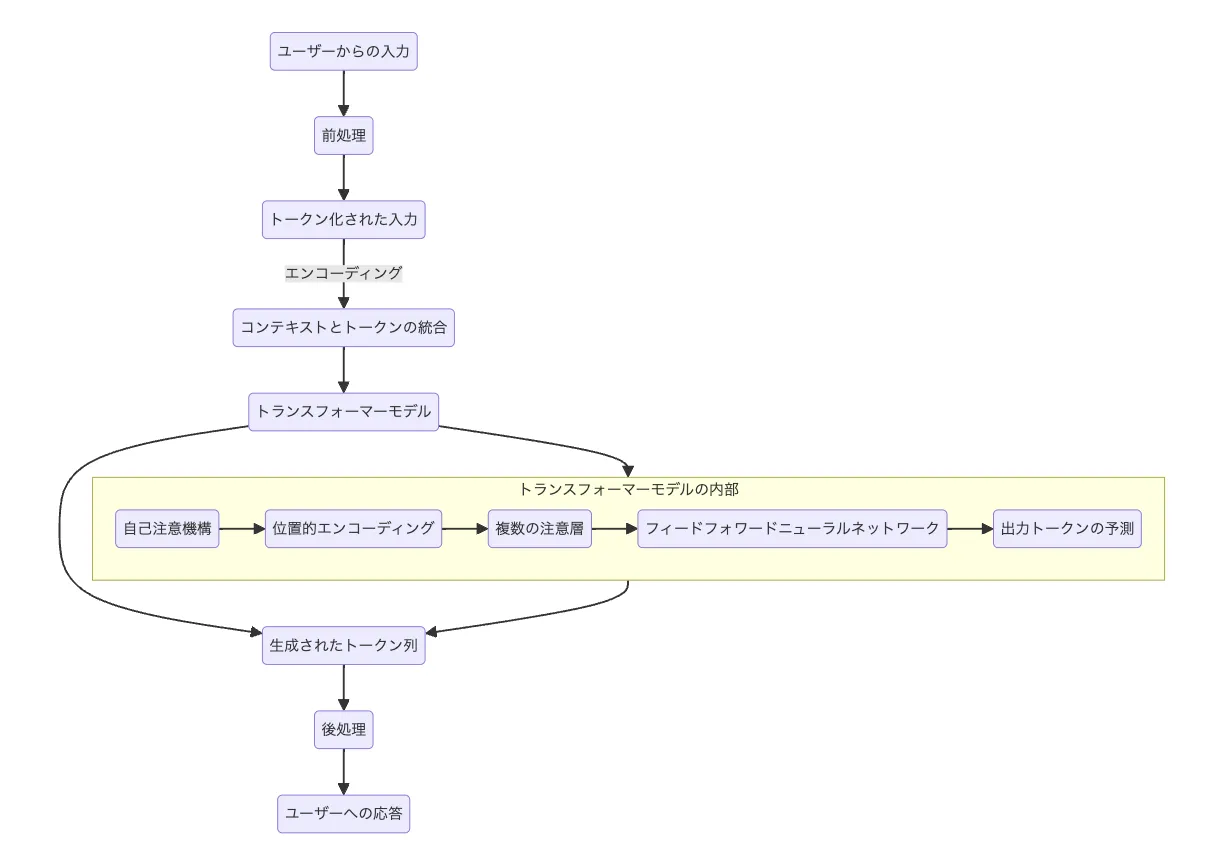
Chat GPTの仕組みフロー
- ユーザーからの入力
まず、ユーザーがテキスト入力を行います。この入力がプロセスの始まりです。
例)
最初に、ユーザーが「ChatGPTの革新性を教えてください」と入力します。
- 前処理
入力されたテキストは前処理されます。このステップでは、テキストをモデルが理解しやすい形式に変換します。
例えば、不要なスペースの削除や、特定の文字の正規化などが行われます。
例)
ユーザーが「ChatGPTの革新性を教えてください」と入力した内容が例えば「」を除いて、
ChatGPTの革新性を教えてくださいのみの入力になるようなイメージです。
- トークン化された入力
前処理されたテキストは「トークン」に分割されます。トークンとは、テキストを構成する最小単位(通常は単語や部分的な文字列)です。
このトークン化により、テキストはモデルが処理しやすい形に変換されます。
例)
テキストは「トークン」に分割されます。
この例では、"ChatGPT"、"の"、"革新性"、"を"、"教えて"、"ください"といったトークンに分割されます。
- エンコーディング/コンテキストとトークンの統合
トークン化された入力はエンコーディングされ、それぞれのトークンに意味を持たせたベクトルへと変換されます。
これにより、モデルはトークンの意味を理解しやすくなります。同時に、トークン間の関連性や文脈が統合されます。
例)
各トークンはエンコーディングされ、意味を持つベクトルに変換されます(私はが(3,5)などのベクトル表現に変換)。
そして、トークン間の関係や文脈が考慮され、トークンのベクトルが更新されます。
【関連記事】
➡️ベクトル表現も解説!Azureベクトル検索解説記事
- トランスフォーマーモデル
ここがプロセスの核心部分です。エンコーディングされたトークンは、トランスフォーマーモデルへと供給されます。
このモデル内部では、以下のサブプロセスが行われます。
- 自己注意機構: 各トークンが、他のトークンとどのように関連しているかを計算します。
- 位置的エンコーディング: トークンの順序情報を追加します。
- 複数の注意層: 複数の注意機構を通して、情報をさらに精緻化します。
- フィードフォワードニューラルネットワーク: 各トークンに対して追加の計算を行い、最終的な出力を生成する準備をします。
- 出力トークンの予測: 最終的に、次に来るべきトークンを予測します。
例)
自己注意機構: 例えば、「革新性」というトークンが「ChatGPT」と強く関連していると判断されます。
位置的エンコーディング: トークンの位置関係がエンコードされ、文章の流れが考慮されます。
複数の注意層: 情報が複数の層を通じて精緻化され、より正確な予測のための準備が整います。
フィードフォワードニューラルネットワーク: 追加の処理を経て、次のトークンの予測に必要な情報が整えられます。
出力トークンの予測: 「革新性」というトークンに基づき、それに関連する情報や文脈に合った回答が生成されます。
- 生成されたトークン列
トランスフォーマーモデルは、予測されたトークン列を生成します。これは、応答の草稿となります。
例)
モデルは「ChatGPTは、大規模なデータセットを学習することで、自然言語を理解し、人間らしい応答を生成できる点が革新的です」といった内容を含むトークン列を生成します。
-
後処理
生成されたトークン列は後処理されます。このステップでは、予測されたテキストを自然な言語に近づけるための調整が行われます。例えば、文法の修正や、不自然な表現の調整などが含まれます。
-
ユーザーへの応答
最後に、後処理されたテキストがユーザーへの応答として提供されます。これにより、ユーザーの質問やコメントに対する意味のある応答が完成します。
実際に聞いてみるとこのように返答が返ってきます。

ChatGPTの実際の返答
このような一連のステップを通じて、チャットGPTはユーザーからの入力に対して、文脈に合わせた適切な応答を生成することができます。
トランスフォーマーモデルとは
先ほどの手順(5.)で挙げたトランスフォーマーモデルは、Googleの研究者が「Attention Is All You Need」という論文で発表した、従来の自然言語処理モデルに革新的な変化をもたらしたアプローチ方法です。

トランスフォーマーモデルの処理イメージ
具体的には以下のような特徴があります。
-
アテンション機構
- トランスフォーマーモデルの核心は 「アテンション機構」 です。これにより、モデルは文中の各単語がどのように関連しているかを学習し、文の意味をより深く理解することができます。特に、文中の遠く離れた単語間の関係も捉えることができるため、長文での理解が向上します。
- トランスフォーマーモデルの核心は 「アテンション機構」 です。これにより、モデルは文中の各単語がどのように関連しているかを学習し、文の意味をより深く理解することができます。特に、文中の遠く離れた単語間の関係も捉えることができるため、長文での理解が向上します。
-
エンコーダとデコーダの構造
- トランスフォーマーモデルはエンコーダとデコーダから成り立っています。エンコーダは入力されたテキストの意味を理解し、デコーダはその理解を基に新しいテキストを生成します。この構造により、翻訳や要約などのタスクが効率的に行えます。
- トランスフォーマーモデルはエンコーダとデコーダから成り立っています。エンコーダは入力されたテキストの意味を理解し、デコーダはその理解を基に新しいテキストを生成します。この構造により、翻訳や要約などのタスクが効率的に行えます。
-
並列処理の可能性
- 従来のリカレントニューラルネットワーク(RNN)や長短期記憶(LSTM)と異なり、トランスフォーマーは入力データを並列に処理できます。これにより、学習速度 が大幅に向上しました。
【関連記事】
➡️Transformerとは?モデルの概要やBERTとの違いをわかりやすく解説
ChatGPTに追加でトレーニングする方法(追加学習)
ChatGPTは、人間のように自然で流暢な会話を行うために、インターネット上で公開されている大規模なテキストデータセットで訓練されています。
そのため、学習期間までの情報しかわからないことや、インターネット上にない情報はわからない(例えば社内情報やIoTデータなど)デメリットがあります。
例えば、ChatGPT4の場合は「2023年4月時点まで の情報」が学習されています。
そのようなデメリットを回避するために、ChatGPTに関連する「RAG」(Retrieval-Augmented Generation)とファインチューニングという方法があります。
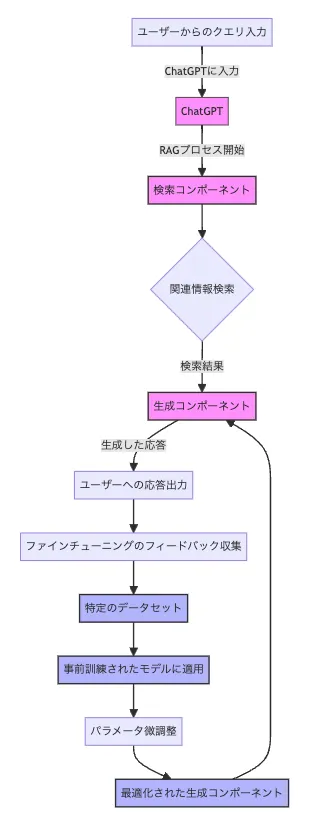
RAGとファインチューニングのChatGPTへの入力の仕組み
RAGの仕組み
RAGとは、「情報検索技術を利用することで、ChatGPTのモデル性能を向上させる技術」です。
RAGは、大きく分けて以下の二つのコンポーネントから成ります。
- 検索コンポーネント
この部分は、与えられたクエリ(例えば質問やプロンプト)に基づいて、大規模な文書データベースから関連情報を検索します。このプロセスには、通常、事前に訓練された文書埋め込みモデルが使用され、クエリと文書の間の関連性を評価します。
- *生成コンポーネント
: 検索された情報は、生成コンポーネント(例えば、GPTのような言語生成モデル)に渡されます。このコンポーネントは、検索された情報を利用して、回答や文章を生成します。この過程で、モデルは検索情報をコンテキストとして活用し、より正確で詳細な内容を生成することが可能になります。
RAGの詳しい解説や活用方法については、こちらの記事で詳しく解説しています。
【関連記事】
➡️LLMや生成AIのRAGとは?その概要や活用例をわかりやすく解説!
ファインチューニングの仕組み
ファインチューニングは、既に大規模なデータセットで事前訓練されたモデルを、特定のタスクや小規模なデータセットに対してさらに最適化するプロセスです。
- 事前訓練されたモデルの選択
ファインチューニングを行う前に、タスクに適した事前訓練されたモデルを選択します。
- 特定のデータセットの準備
ターゲットとなるタスクやデータセットに合わせて、データを前処理し、訓練用の形式に整形します。
- ファインチューニングの実行
特定のデータセットに対して、事前訓練されたモデルの重みを微調整します。このプロセスでは、学習率やエポック数などのハイパーパラメータを調整することが一般的です。
- 評価と調整
ファインチューニングされたモデルを評価し、必要に応じてさらなる調整を行います。これにより、タスクのパフォーマンスを最適化します。
RAGとファインチューニングの組み合わせ
RAGモデルを特定のタスクにファインチューニングすることで、モデルはそのタスクに特化した情報を検索し、利用して回答や文章を生成する能力を向上させることができます。
これにより、モデルの柔軟性と精度が大幅に改善され、様々な応用分野への活用ができるようになります。
つまり、RAGとファインチューニングは、「AIがより正確な情報を提供し、ユーザーの要求に応じた内容を生成することを可能にする強力なツール」です。
ChatGPTの評価モデル
自然言語処理のモデルには「ChatGPT」「Gemini」「Claude」など多岐に渡りますが、どのAIの性能が良いか評価することは重要です。
モデルの性能を考える時には、言語性能とドメイン適応性能(医療、法律、金融など)、倫理などのガバナンスの側面から考えることが求められます。
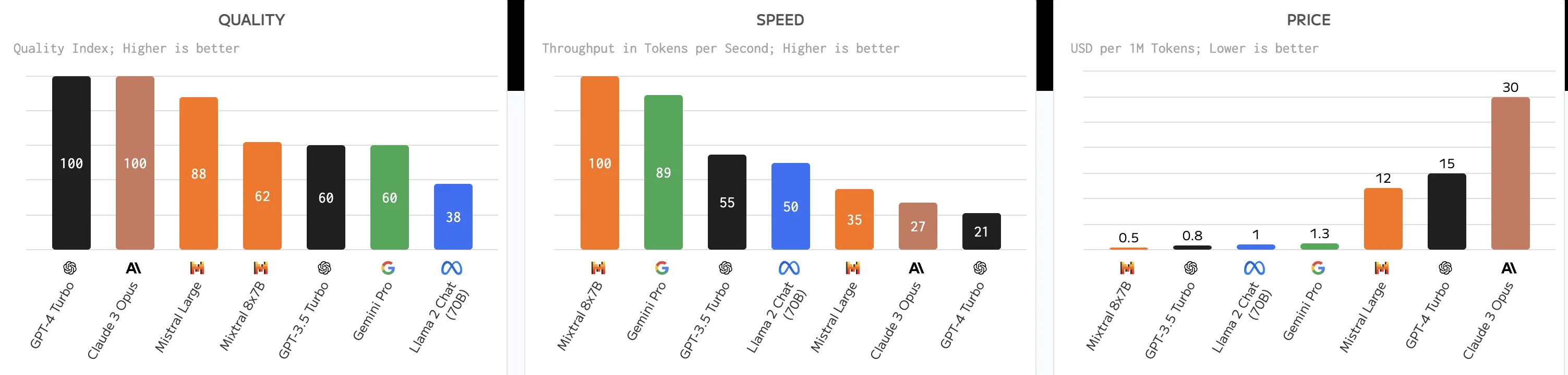
各モデルの評価グラフ 参考:Artificial Analysis
ここでは、最も一般的に用いられる言語性能に着目し、代表的な評価モデルを解説します。
自然言語処理に含まれる概念
1. 自然言語理解 (NLU)
自然言語理解は、「テキストの意味を解析し理解する能力」を指します。NLUのタスクは、テキスト分類、固有表現認識(NER)、含意予測などがあります。
これらのタスクを評価するためには、GLUEベンチマークや日本語に特化したJGLUEなどのデータセットが用いられます。
2. 自然言語生成 (NLG)
自然言語生成は、「ある入力に基づいて意味のあるテキストを生成する能力」を指します。これには、要約、機械翻訳、メール作成、ニュース記事作成などが含まれます。
評価には、CNN/DailyMail、XSUM、WMT、Leetcodeなどのデータセットが用いられます。
3. 知識集約的なタスク
これらのタスクでは、「特定のドメインに関する専門知識や一般常識」が必要です。
例えば、MMLU、NaturalQuestionsやWebQuestions、TriviaQAなどがあります。
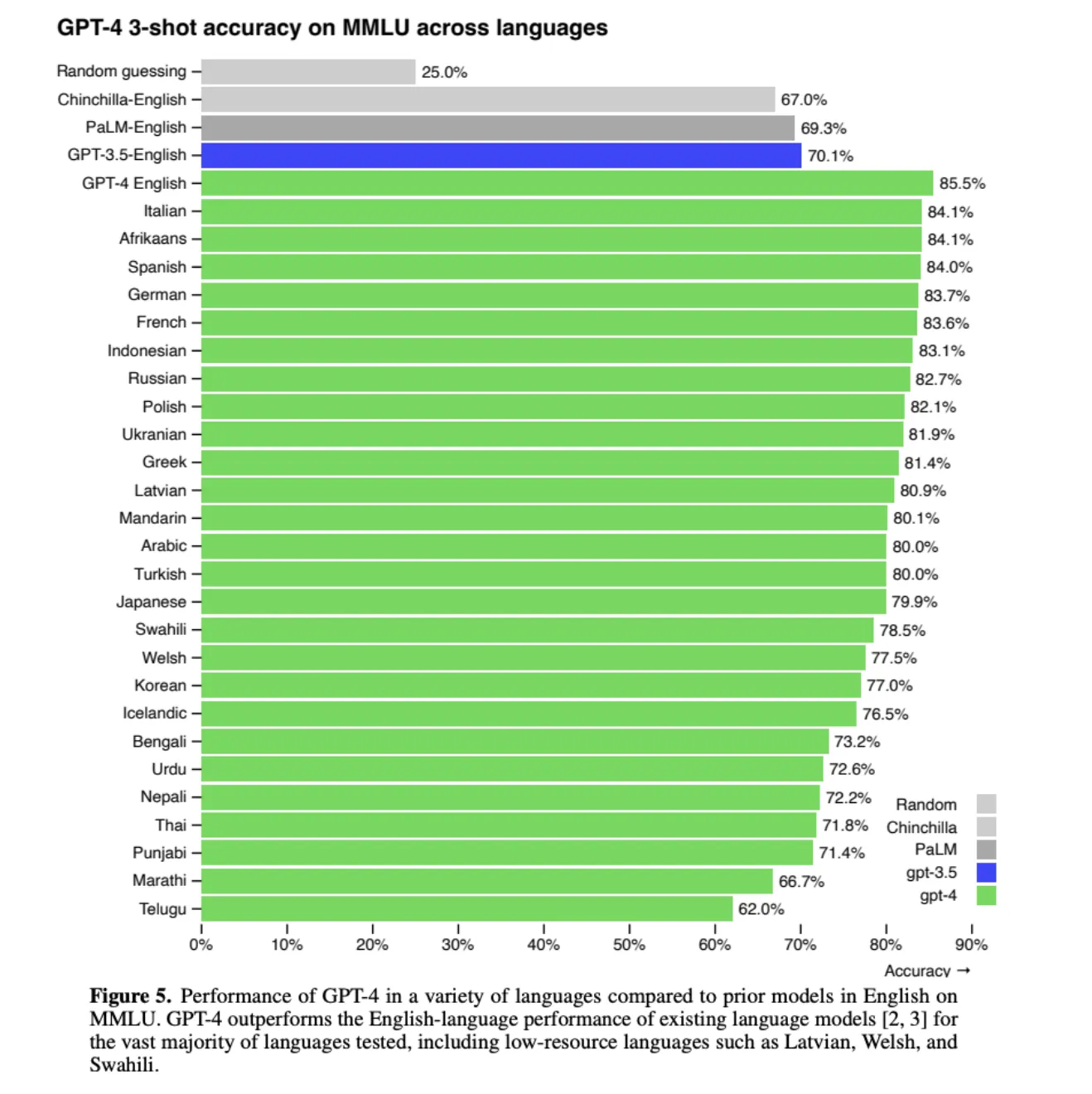
ChatGPTのMMLUの結果
Massive Multitask Language Understanding(MMLU)は、言語モデルが取得した広範な知識を測定するために設計された新しいベンチマークで、ゼロショットやフューショットの設定でのみモデルを評価します。
画像から分かる通り、ChatGPTが特に英語に強いことがわかります。
4. 推論能力
推論能力は、「与えられた情報から論理的な結論を導き出す能力」を指します。これには数学推論や常識推論が含まれ、データセットとしては、GSM8K、SVAMP、AQuAなどがあります。
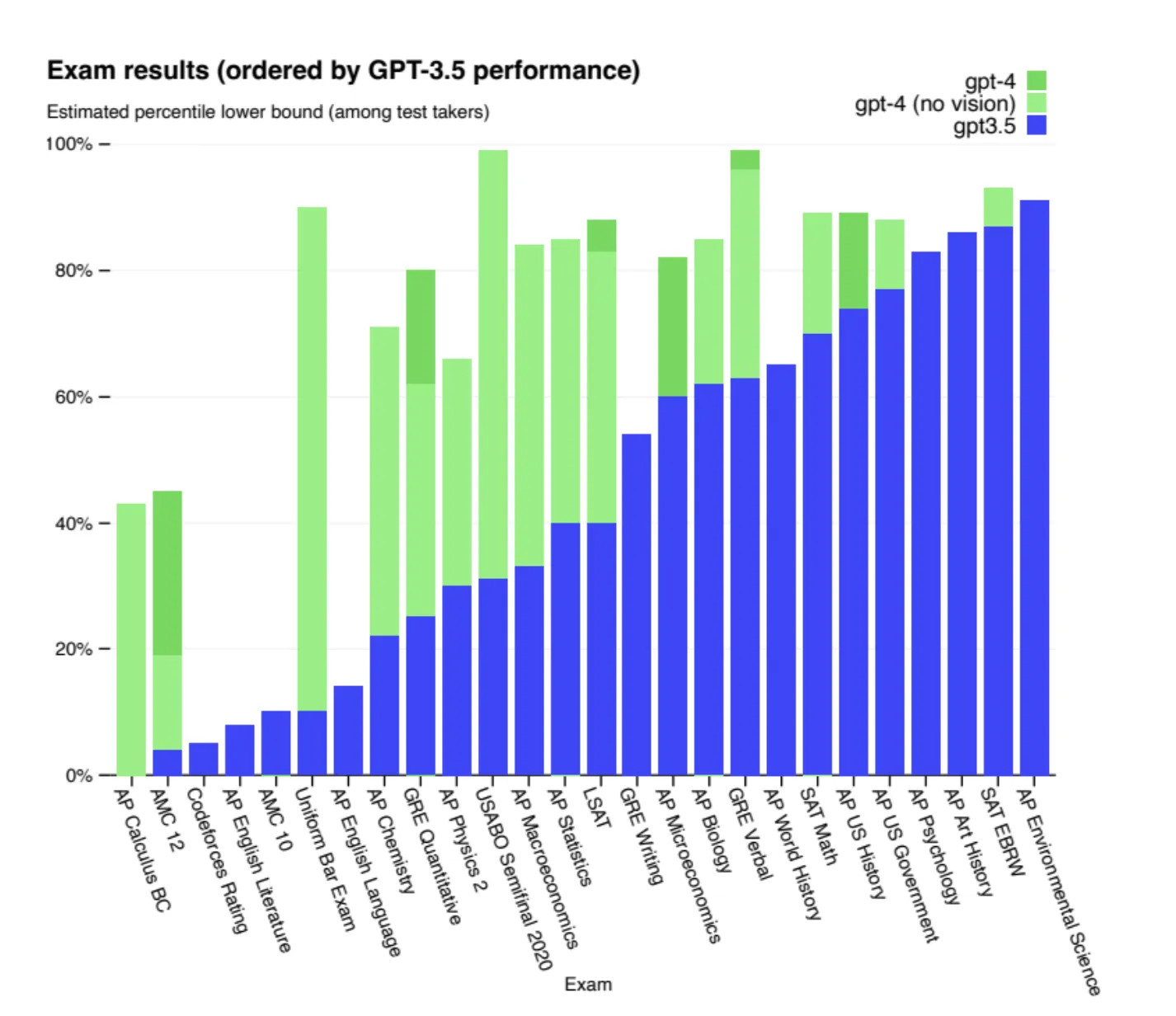
多様な学術試験のChatGPTの回答結果
この種の試験は、モデルが与えられた情報をもとに複雑な問題を解決する能力、つまり推論や問題解決スキルを評価するのに適しています。
5. 価格
こちらは論文で述べられることはありませんが、ユーザーとしては重要な情報です。
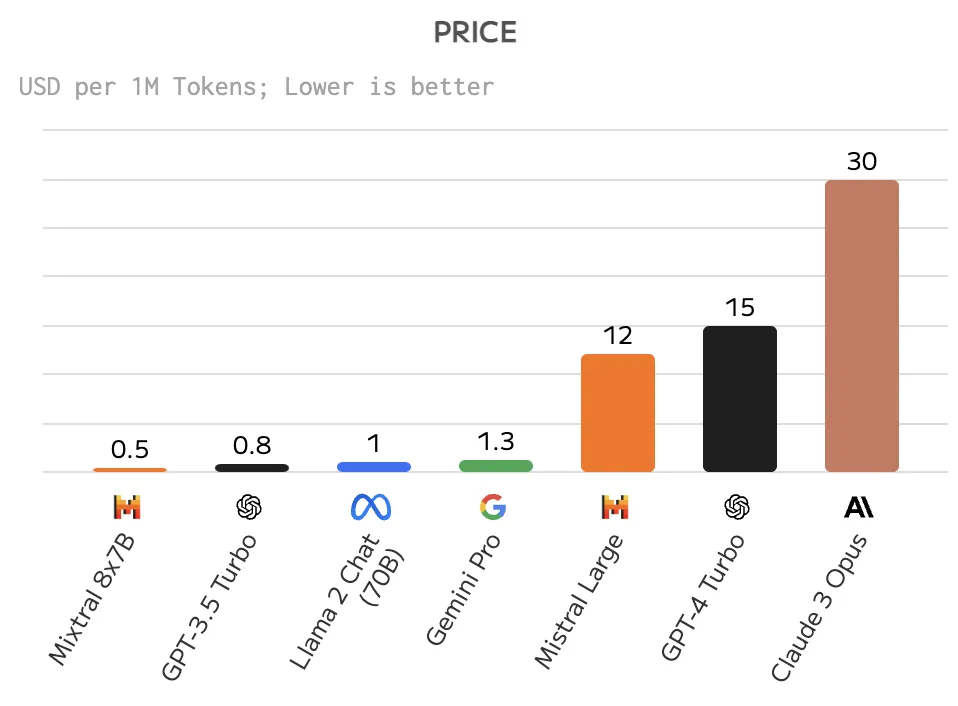
モデルごとの価格比較
6. スピード
生成スピードも速いに越したことはありません。特にIoTでの利用や、顧客と会話するチャットボットにおいて、遅延は顧客体験の低下につながります。
これらのようなタスクとデータセットで、LLMの性能を総合的に評価し、どのモデルが合っているのかを判断することは非常に有効です。
AIが優秀と言われた時に、どのような性能評価をしているのかチェックしつつみるとより理解が深まります。
また、チャットボットに焦点を当てた評価指標については、こちらの記事で解説しています。
【関連記事】
➡️チャットボットの評価指標や効果測定の手順をわかりやすく解説!
ChatGPTの課題
ChatGPTは革新的な自然言語処理モデルですが、いくつかの課題も抱えています。
ここでは、その主要な課題とそれに対する取り組みについて解説します。
誤情報の生成
ChatGPTは時として、ハルシネーションと呼ばれる、誤った情報を生成することがあります。
この問題に対処するために、より正確で信頼性の高いデータソースを用いた訓練や、ファクトチェック機能の統合が検討されています。
また、ユーザーからのフィードバックを活用して、モデルの正確性を継続的に改善するアプローチも重要です。
クリエイティブ職への影響
ChatGPTのような高度な言語生成モデルは、ライターやコンテンツクリエイターの仕事に影響を与える可能性があります。
しかし、AIを競争相手と見るのではなく、人間の能力を補完するツールとして捉える視点が大切です。
例えば、ライティングプロセスにおいて、アイデア生成や初稿作成をAIが担い、編集やブラッシュアップを人間が行うなど、協働のモデルが考えられます。
AIとの適切な役割分担を見出すことで、クリエイティブ職の生産性向上と価値創造が期待できます。
最新情報への対応不足
ChatGPTの知識は訓練データに基づいているため、最新の情報に対応できない場合があります。この課題に取り組むために、定期的なモデルの再訓練や、最新情報を取り込むためのデータ収集・更新プロセスの確立が必要です。
また、ユーザーに対して、モデルの知識が特定の時点までのものであることを明示することも重要です。
これらの課題に加えて、プライバシーの保護、偏見の軽減、倫理的な利用など、ChatGPTを含む自然言語処理モデルには様々な課題があります。
研究者、開発者、ユーザー、そして社会全体が協力して、AIの可能性を最大限に引き出しつつ、負の影響を最小限に抑えていく努力が求められています。
【関連記事】
➡️ChatGPTの問題点とは?その危険性や社会に与える影響を解説

まとめ
本記事では、ChatGPTの動作原理を詳しく解説しました。ChatGPTは、テキストの前処理から始まり、トランスフォーマーモデルの自己注意機構を活用することで、ユーザーとの自然な対話を実現しています。
また、大量のテキストデータから学習し、評価と改善を繰り返すことで、その性能を向上させています。
ChatGPTの仕組みを理解することは、AIの可能性を正しく認識し、適切に活用するために重要です。同時に、誤情報の生成や最新情報への対応不足といった課題についても認識しておく必要があります。
これらの課題に取り組みながら、ChatGPTをはじめとするAI技術の発展を促進することが求められています。
本記事がChatGPTへの理解を深め、AI全般への興味を喚起する一助となれば幸いです。AIの健全な発展のために、私たち一人一人が技術の仕組みを理解し、適切に活用していくことが重要だと言えるでしょう。









