この記事のポイント
 TensorRTは、NVIDIA製のAIモデル推論を最適化するツール
TensorRTは、NVIDIA製のAIモデル推論を最適化するツール- 学習済みAIモデルをGPU上で高速・効率的に実行可能にする
- レイヤー融合、精度調整、カーネル自動選択等で推論を高速化
- 導入はDocker, Python(pip/conda), CUDA環境に対応
- 画像分類、物体検出、自然言語処理など幅広い分野で活用

Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
AIの活用が広がる一方で、「AIモデルの処理が重い」「リアルタイムで応答できない」といった悩みを抱えていませんか?特に、画像認識や自然言語処理など、高度なAIモデルを実用化するには、推論(学習済みモデルを使って予測すること)の高速化が不可欠です。
その課題を解決し、AIの可能性を最大限に引き出すのが、NVIDIAの「TensorRT」です。しかし、「TensorRT」が具体的に何をしてくれるのか、どうやって使うのか、疑問に思う方もいるかもしれません。
本記事では、この「TensorRT」について、基礎から応用までをわかりやすく解説します。
TensorRTの仕組み、導入方法、具体的な活用事例、そして今後の展望まで、幅広く網羅的に説明します。
目次
NVIDIA TensorRTとNVIDIA GPUとの関係
1. レイヤーとテンソルの融合 – 無駄な処理を減らして高速化
2. FP16とINT8の精度調整 – 計算量を減らして処理を高速化
3.カーネルの自動チューニング – GPUの性能を最大限に活かす
4. 動的メモリ管理 – メモリを効率的に使用し、大規模モデルもスムーズに実行
5. マルチストリーム実行 – 複数のリクエストを並列処理し、応答速度を向上
TensorRTとは
TensorRT は、NVIDIAが提供する 「ディープラーニング推論を最適化するツール 」です。
学習済みのAIモデルを NVIDIA GPU上で高速かつ効率的に実行 できるように最適化し、レイテンシ(応答時間)の短縮、スループット(処理能力)の向上、消費電力の削減 を実現します。
NVIDIA TensorRT を活用することで、AI推論のパフォーマンスを劇的に向上させることができます。特に、リアルタイム推論が求められるアプリケーション において、計算コストを削減しながら高速な処理を実現します。
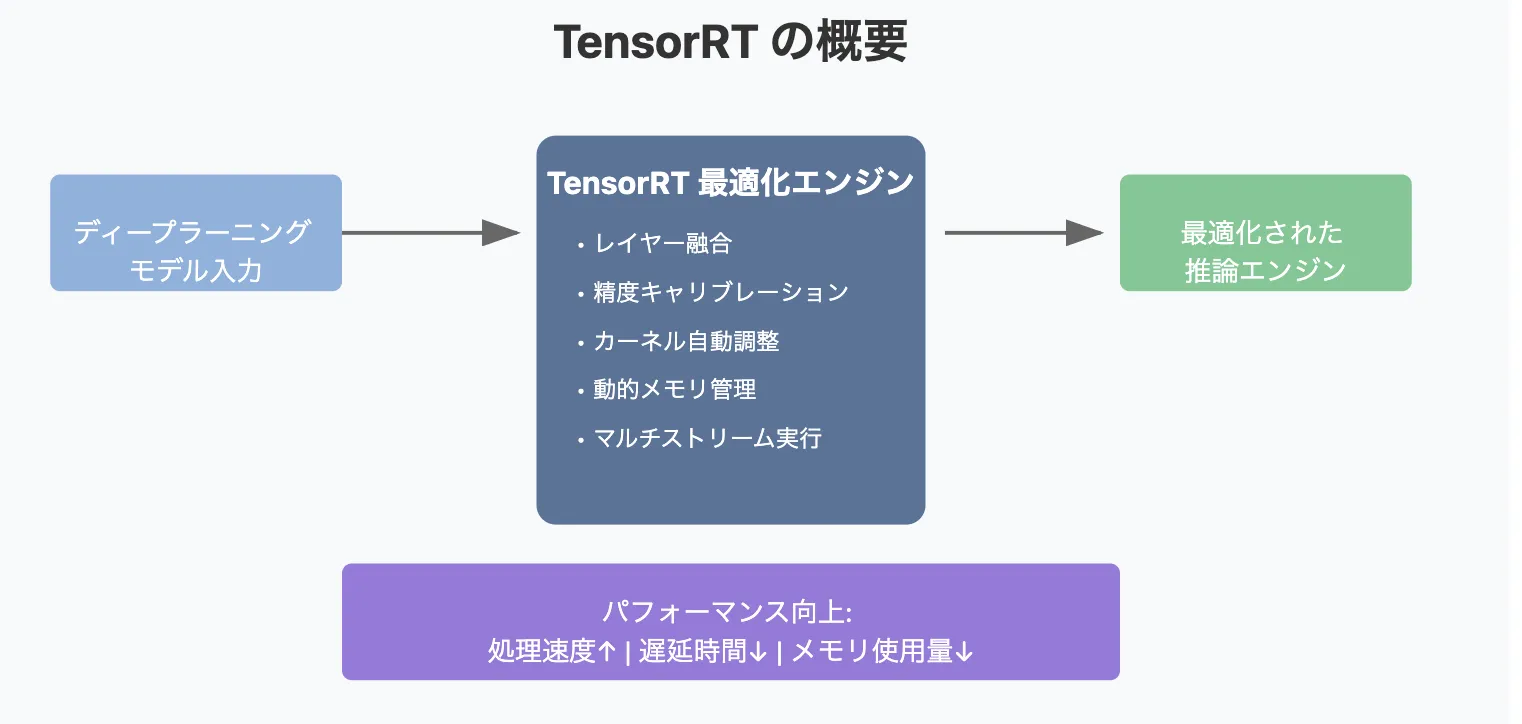
TensorRTイメージ
近年、AIの活用は 画像認識、自然言語処理、自動運転、ロボティクス など多岐にわたります。
しかし、AIモデルの推論(Inference)には高い計算リソースが必要であり、特に リアルタイム処理が求められるアプリケーション では、推論の高速化が重要な課題となります。
この問題を解決するために、TensorRTは モデルの量子化やレイヤーの最適化 などを行い、GPU推論のパフォーマンスを最大化します。
リアルタイムAI処理が必要なシーンにおいて、TensorRTは 高性能な推論を実現する重要なツール となっています。
NVIDIA TensorRTの利用メリット
では、NVIDIA TensorRTを用いるメリットは具体的にどういったものになるのでしょうか。
その特徴をご紹介します。

NVIDIA TensorRT のメリット
| メリット | 詳細 |
|---|---|
| 推論を最大36倍高速化 | TensorRTを使用することで、CPUのみのプラットフォームと比較して 最大36倍の推論速度向上 を実現。低精度最適化(FP8/INT8/INT4)を活用し、データセンター、ワークステーション、ラップトップ、エッジデバイスに展開可能。 |
| 推論パフォーマンスの最適化 | CUDA®並列プログラミングモデル を活用し、推論最適化を実施。 - 量子化(FP8/INT8/INT4) による演算効率向上 - レイヤーとテンソルの融合(Layer & Tensor Fusion) による計算最適化 - カーネルチューニング による最適処理 |
| あらゆるワークロードの高速化 | ポストトレーニングおよび量子化対応のトレーニング手法により、リアルタイムサービス・自律型アプリケーション・組み込みAI などの分野でレイテンシを最小化。 |
| NVIDIA Tritonによるスムーズなデプロイ | TensorRTに最適化されたモデルは NVIDIA Triton™ 推論サービス を使用して展開・実行・スケーリング可能。 - 動的バッチ処理 による高スループット - 複数モデルの同時実行 によるリソース最適化 - モデルアンサンブル による精度向上 - ストリーミングオーディオ・ビデオ入力のサポート |
このように、NVIDIA TensorRTを活用することで、推論の高速化・パフォーマンス最適化・ワークロードの効率化 が可能になり、リアルタイムAI処理の大幅な向上が期待できます。
TensorRTエコシステムとは?4つのコンポーネント
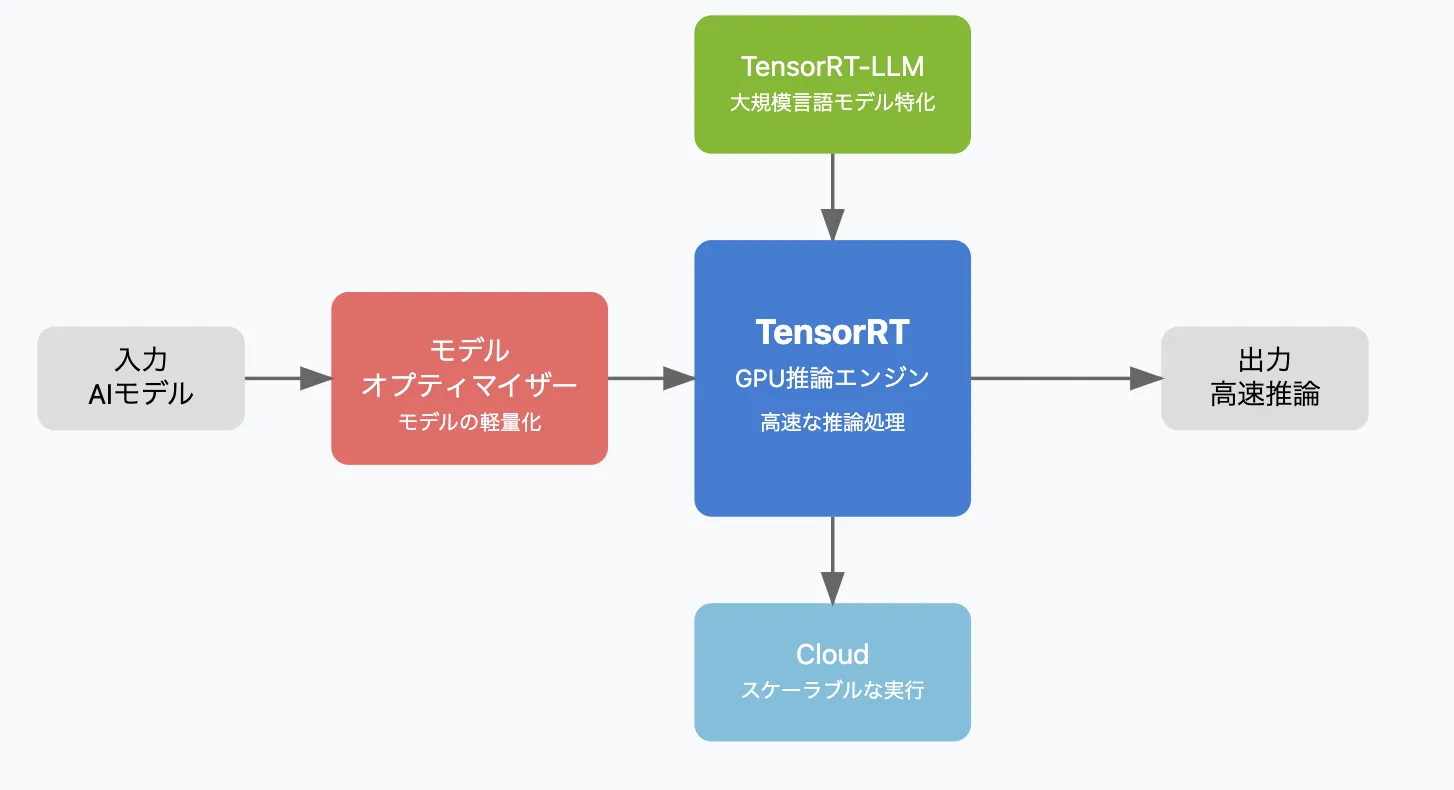
TensorRTエコシステムイメージ
TensorRTエコシステム は、AI推論を高速化し、効率的に運用するための TensorRTを含む最適化「ツール群」です。
特に、大規模な言語モデル(LLM)やディープラーニングモデルの推論において、パフォーマンス向上とリソース効率化を実現します。
以下に、コンポーネント特徴をまとめました。
| コンポーネント | 概要 | 主なメリット |
|---|---|---|
| TensorRT | GPU向けの推論最適化ライブラリ | 推論速度を最大化し、レイテンシを削減 |
| TensorRT-LLM | 大規模言語モデル(LLM)専用の最適化ツール | GPTやLlamaなどのLLMの推論を効率化 |
| TensorRT モデルオプティマイザー | モデルの圧縮・最適化を行うツール | メモリ使用量を削減し、軽量化を実現 |
| TensorRT Cloud | クラウド上で推論最適化を行うプラットフォーム | スケーラブルなAI推論をクラウドで実行 |
TensorRTエコシステムを活用することで、AI推論のパフォーマンス向上と運用コスト削減 の両立が可能になります。
NVIDIA TensorRTとNVIDIA GPUとの関係
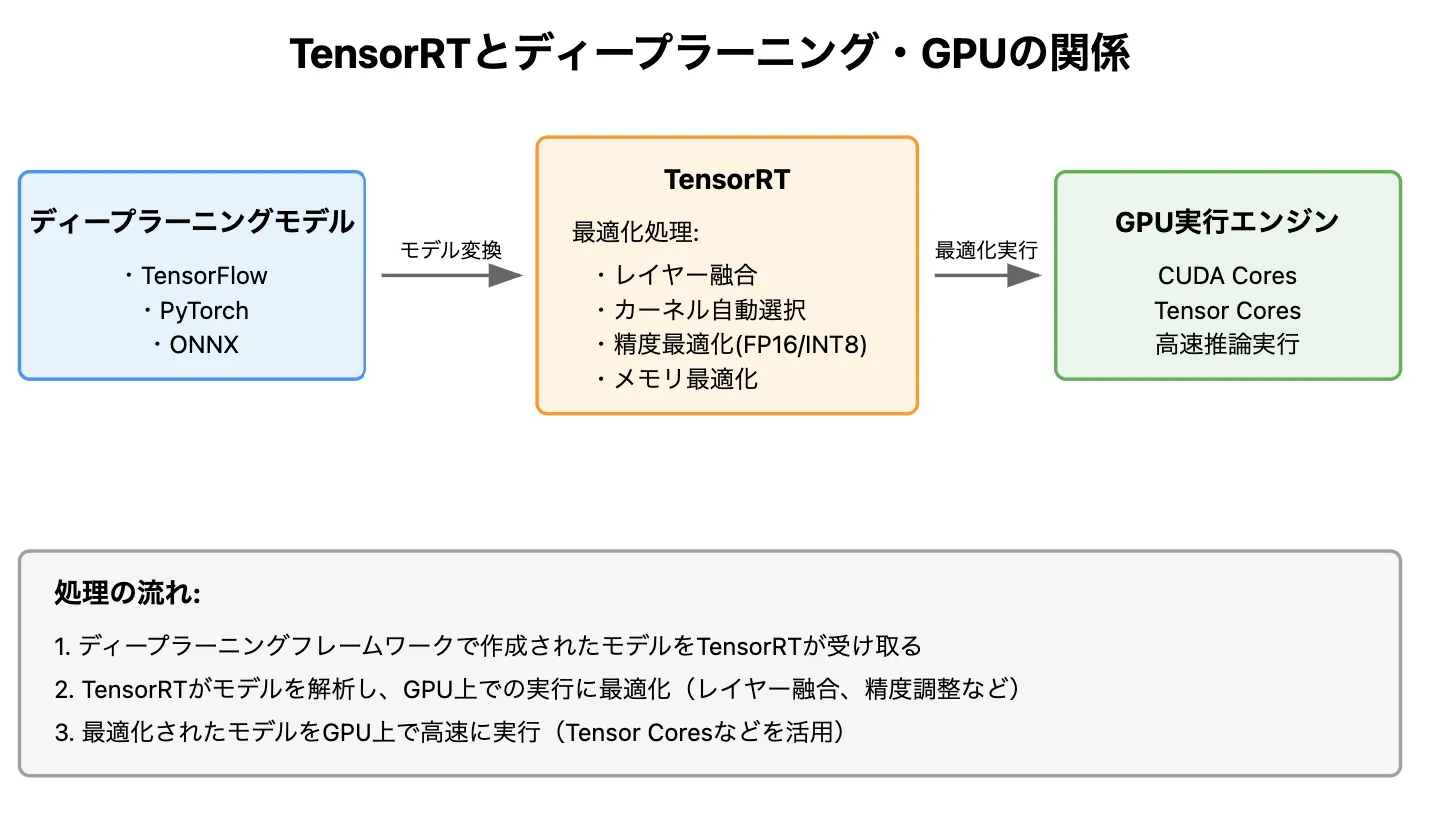
NVIDIA TensorRTとNVIDIA GPUとの関係
NVIDIAといえば GPU(グラフィックス処理ユニット) を思い浮かべる方が多いでしょう。
では、NVIDIA GPUとTensorRTの違い は何でしょうか?
この疑問を持つ方のために、両者の役割を明確に解説します。
NVIDIA GPUとTensorRTの違い
-
NVIDIA GPU
並列処理に優れたアーキテクチャ を持ち、AI推論やディープラーニングの処理を効率的に実行します。
特に、最新のNVIDIA GPUには Tensor Core という専用ユニットが搭載され、深層学習向けの演算が高速化されています。
-
TensorRT
NVIDIA GPUの性能を最大限に引き出すために開発された推論最適化ツール** です。
TensorRTを使用することで、AIモデルの推論処理が劇的に高速化 され、リアルタイムAIアプリケーションに最適な環境を構築できます。
TensorRTによるGPU最適化の具体例
TensorRTは、GPUの計算リソースを無駄なく活用し、以下の最適化を行います。
| 最適化手法 | 内容 |
|---|---|
| CUDAコアの並列処理最適化 | GPUの膨大な演算能力を活用 し、高速な推論処理を実現 |
| Tensor Coreを活用した高速行列演算 | FP16・INT8の低精度演算 を活用し、計算速度を向上 |
| GPUメモリの最適管理 | キャッシュの最適化・レイヤー統合 により、メモリ使用効率を向上 |
| カーネルチューニング | GPUごとに最適な計算カーネルを自動調整し、推論速度を最大化 |
結論として、NVIDIA GPUは強力な並列処理能力を持つハードウェア であり、TensorRTはその能力を最大限に引き出す専用のチューニングツール です。
TensorRT対応GPU一覧
TensorRTは、NVIDIAのさまざまなGPUアーキテクチャに対応しており、推論最適化を最大限に活かせる環境を提供します。
特に、最新のTensor Core搭載GPU では、FP16やINT8を活用した高速推論が可能です。
| GPUシリーズ | アーキテクチャ | 特徴 |
|---|---|---|
| H100 | Hopper | Tensor Core最適化、LLM推論に特化 |
| A100 | Ampere | データセンター向け、マルチインスタンスGPU対応 |
| L40/L4 | Ada Lovelace | クラウド推論向け、効率的なAI推論 |
| RTX 40シリーズ | Ada Lovelace | 消費者向け、FP8/INT8推論強化 |
| RTX 30シリーズ | Ampere | ゲーミング・AI推論対応 |
| T4 | Turing | クラウド・エッジAI向け、電力効率が高い |
| Jetsonシリーズ | Various | 組み込みAI・エッジデバイス向け |
特に、H100やA100などのデータセンター向けGPUを活用すれば、LLMやリアルタイムAI推論のパフォーマンスを最大化 できます。
TensorRTの主要機能
前章では、TensorRTがNVIDIA GPUの性能を最大限に引き出し、推論を最大36倍高速化できることを解説しました。
しかし、「具体的にどうやって高速化するのか?」と疑問に思う方も多いでしょう。
AI推論の処理は、単純に計算能力の高いGPUを使うだけでは最適化できません。
処理の無駄を省き、計算そのものを軽量化し、メモリを効率的に管理することが重要 です。
ここからは、TensorRTがどのようにAI推論をスムーズにし、パフォーマンスを向上させるのか、その具体的な最適化技術について解説します。
1. レイヤーとテンソルの融合 – 無駄な処理を減らして高速化
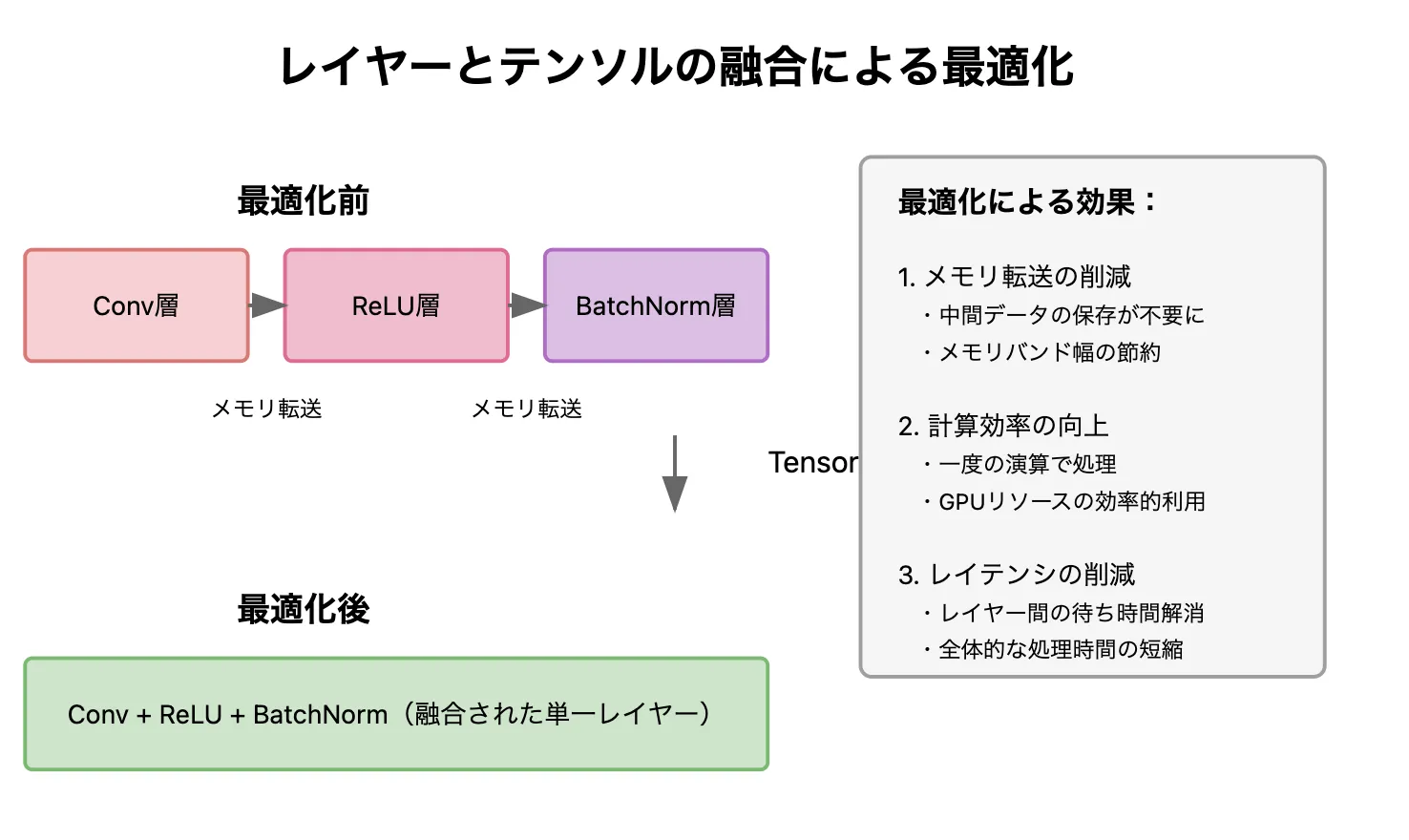
レイヤーとテンソルの融合
AIモデルの推論では、多くの計算ステップが発生します。例えば、自然言語処理や音声認識などのモデルでは、データの前処理や特徴抽出などの処理が複数の段階で行われます。通常、これらの処理は 個別に実行され、各ステップでメモリの読み書きが発生 します。このメモリのやりとりが増えると、推論速度が低下する原因になります。
TensorRTの最適化方法
TensorRTは、関連する処理を1つのカーネル(計算ユニット)に統合 し、1回の計算でまとめて処理することで、メモリへのアクセス回数を削減し、推論速度を向上させます。
例:AIチャットボットの最適化
通常、AIチャットボットは以下のような流れで処理を行います。
- テキストの前処理(単語の分割・正規化)
- 特徴抽出(埋め込みベクトルの計算)
- 推論(ニューラルネットワークによる応答生成)
通常、これらは個別の処理として行われますが、TensorRTを使用すると、これらを1つの統合カーネルでまとめて実行できます
。これにより、メモリのやり取りが減り、応答速度が向上します。
2. FP16とINT8の精度調整 – 計算量を減らして処理を高速化
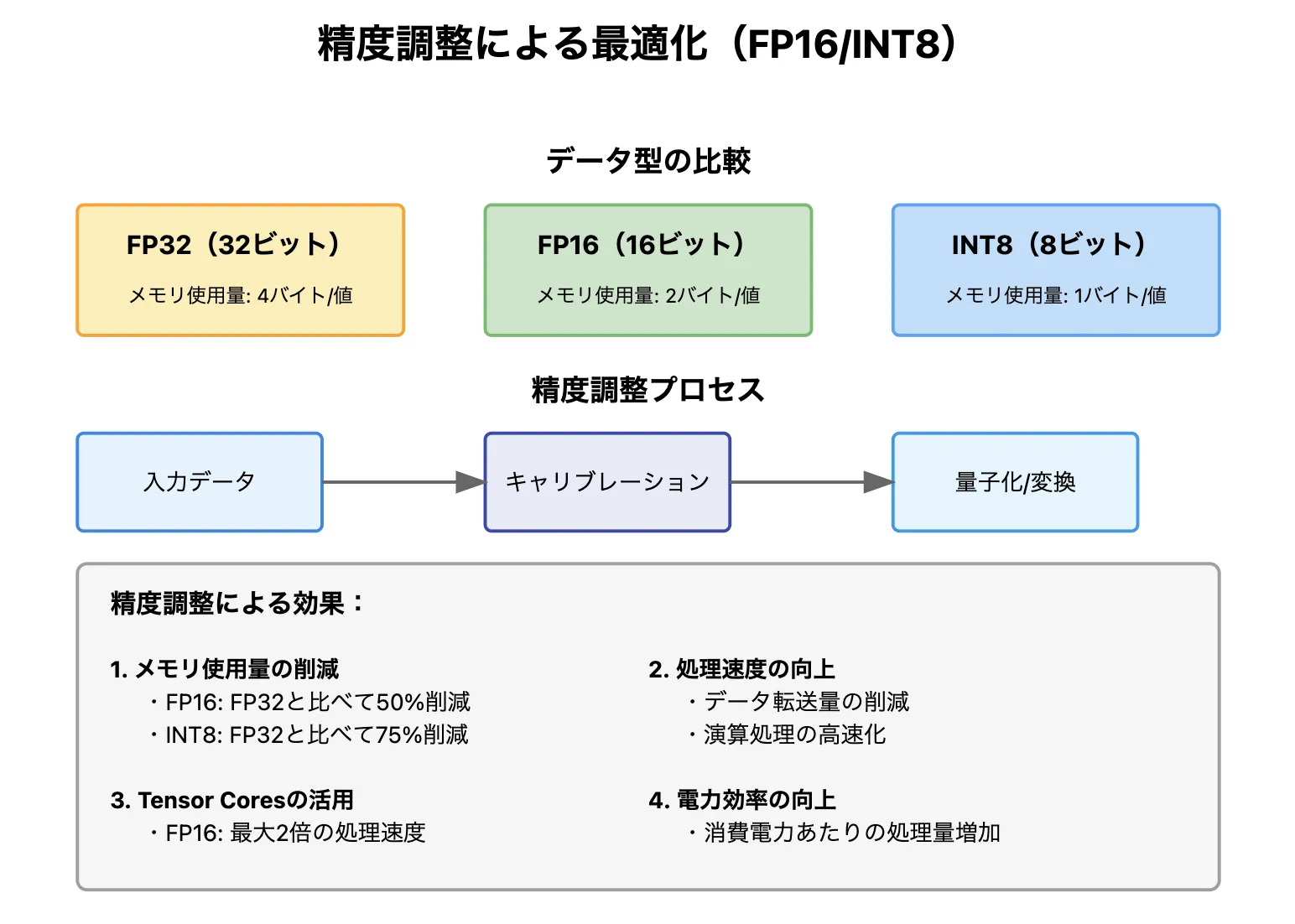
FP16とINT8の精度調整イメージ
AI推論では通常 FP32(32ビット浮動小数点数) を使用します。FP32は高精度ですが、計算負荷が大きく、処理が遅くなる という課題があります。
TensorRTは、FP16(16ビット浮動小数点数)やINT8(8ビット整数) に変換することで、計算負荷を軽減し、推論速度を大幅に向上させます。
| データ形式 | 特徴 | 推論速度の向上 |
|---|---|---|
| FP32(32ビット浮動小数点) | 高精度だが計算コストが高い | - |
| FP16(16ビット浮動小数点) | 精度を少し下げつつ、計算を約2倍高速化 | 約2倍 |
| INT8(8ビット整数) | さらに精度を落とすが、計算速度を最大4倍高速化 | 最大4倍 |
例:音声認識AIの最適化
音声アシスタントが「音楽を再生して」というリクエストを理解する場合、FP32とINT8では数値の精度が異なります。
しかし、キャリブレーションを行うことで、INT8に変換しても音声の認識精度をほぼ維持しながら、処理速度を最大4倍に向上 させることができます。
3.カーネルの自動チューニング – GPUの性能を最大限に活かす
TensorRTは、GPUごとに最適なカーネル(計算処理)を自動で選択し、AI推論のパフォーマンスを最大化します。
開発者が手動でチューニングする必要がなく、最新のNVIDIA GPUから過去のモデルまで、常に最適な処理を実行可能 です。
なぜカーネルの自動チューニングが重要なのか?
NVIDIAのGPUは、世代ごとにアーキテクチャが異なり、最適な計算方法(カーネル)も変わります。そのため、手動調整では効率が悪くなります。
- A100 GPU(Ampere世代) → Tensor Coreを最大活用するカーネルが最適
- Turing世代のGPU → アーキテクチャに適した別のカーネルを選択
TensorRTは、こうした違いを考慮し、各GPUに最適な計算処理を自動で適用 するため、AI推論の速度と効率が向上します。
4. 動的メモリ管理 – メモリを効率的に使用し、大規模モデルもスムーズに実行
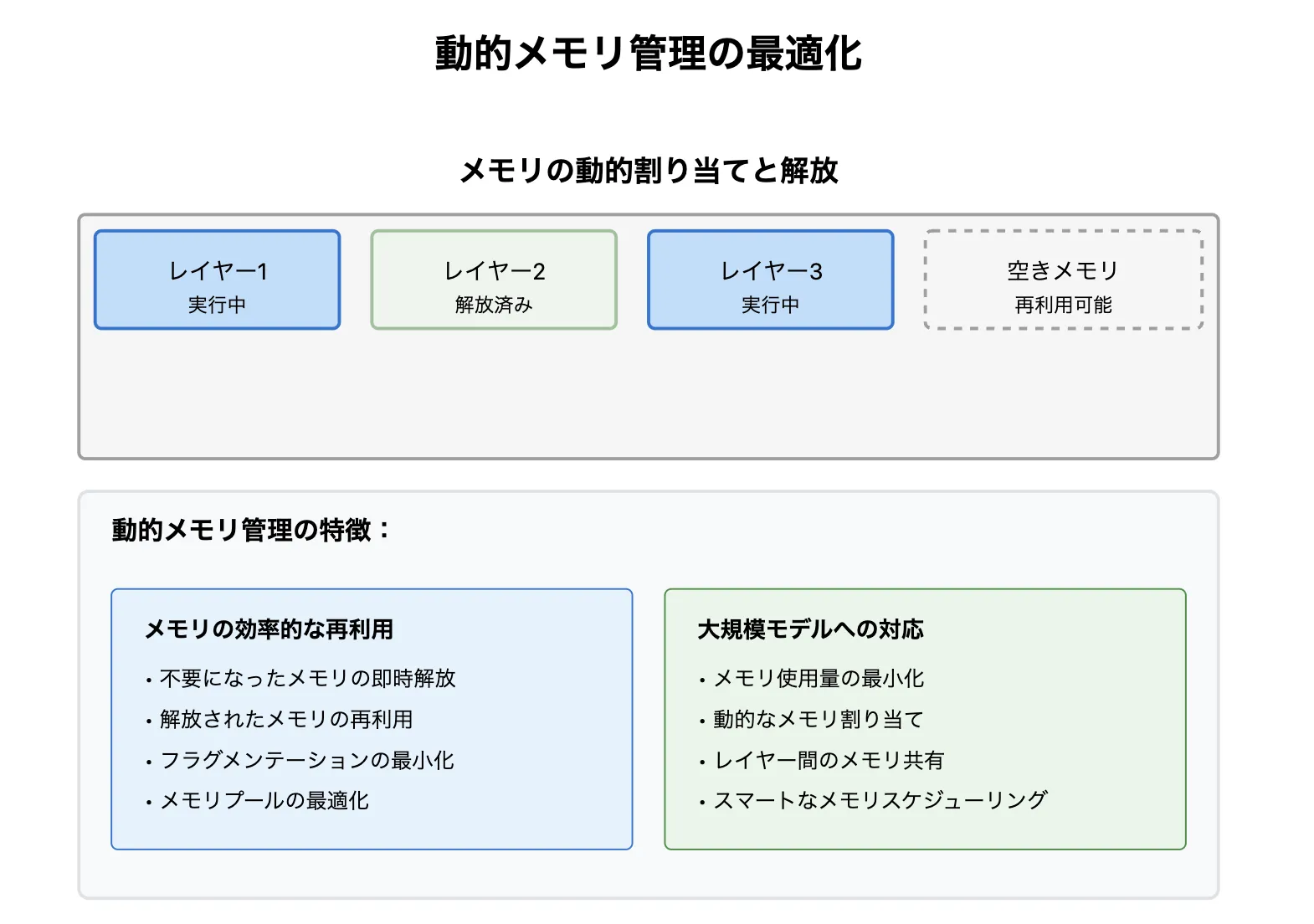
動的メモリ管理
TensorRTは、AI推論時のメモリを動的に管理し、メモリの無駄を削減することで、大規模モデルのスムーズな実行と並列処理の最適化を実現します。
メモリ管理が不十分な場合の課題
| 課題 | 問題点 |
|---|---|
| 大規模モデルが動かない | メモリ不足により処理が停止し、推論が実行できない |
| 複数の推論を同時に処理できない | リソースが最適に活用されず、スループットが低下 |
TensorRTのメモリ最適化ポイント
| 最適化 | 効果 |
|---|---|
| 必要なメモリを正確に見積もり、動的に割り当て・解放 | メモリの無駄を削減し、大規模モデルをスムーズに実行 |
| 複数の推論を並列処理 | スループット(処理能力)が向上し、リアルタイム処理が可能 |
TensorRTの動的メモリ管理により、AI推論のメモリ使用効率が最適化され、大規模モデルもスムーズに実行可能になります。
さらに、複数の推論を並列処理できるため、リアルタイム処理が求められるAIアプリケーションに最適 です。
5. マルチストリーム実行 – 複数のリクエストを並列処理し、応答速度を向上
通常のAI推論では、一度に 1つのリクエスト しか処理できない設計が一般的です。
しかし、実際のAIアプリケーションでは、複数のデータを同時に処理したいケースが多い ため、単一処理では非効率になります。
TensorRTの最適化方法
TensorRTは、「CUDAストリーム」という技術を使い、複数の推論リクエストを並列処理 できます。
- 1秒間に処理できるリクエスト数が増加
- 応答時間を短縮し、リアルタイム処理を強化
- GPUリソースを最大限活用し、効率的な処理を実現
これらの技術により、TensorRTは 推論のスピードを飛躍的に向上させ、リアルタイム処理が求められるAIシステムに不可欠なツール となっています。
TensorRTの導入方法
では実際にTensorRTを使ってみましょう。
必要環境
TensorRTを使用するには、NVIDIAのGPUとCUDAが必要です。まずは以下の環境を確認してみましょう!
- NVIDIA GPU(Pascal世代以降推奨)
- CUDAがインストールされていること(nvcc --versionで確認可能)
- cuDNNがインストールされていること(cat /usr/local/cuda/include/cudnn_version.hで確認)
- NVIDIAドライバが最新であること(nvidia-smiで確認)
TensorRTのインストール方法(Docker・Python・CUDA環境)
TensorRTは Docker環境、Python環境、またはCUDA環境 に応じて導入方法が異なります。
【パターン1】NVIDIAのDockerコンテナを使用(推奨)
最も簡単な方法は、NVIDIAのTensorRT Dockerコンテナを使うことです。
docker run --gpus all -it --rm nvcr.io/nvidia/tensorrt:latest
これで、すぐにTensorRTの環境を利用できます。
【パターン2】Conda/Pipでインストール
TensorRTをPythonで使いたい場合は、pip や conda でインストール可能です。
1. Conda環境でインストール
conda create -n tensorrt python=3.8
conda activate tensorrt
conda install -c nvidia tensorrt
2. Pipでインストール
pip install nvidia-pyindex
pip install nvidia-tensorrt
【パターン3】CUDA環境に直接インストール
- NVIDIA TensorRT公式ページから TensorRTのtarファイル をダウンロード
- 以下のようにインストール
tar -xvzf TensorRT-*.tar.gz
cd TensorRT-*
export LD_LIBRARY_PATH=$PWD/lib:$LD_LIBRARY_PATH
export PATH=$PWD/bin:$PATH
3. インストールの確認
インストール後、Pythonで動作を確認します。
import tensorrt as trt
print(trt.__version__)
正しくバージョンが表示されれば、TensorRTの導入は完了です!
TensorRTの使い方
TensorRTを使ってモデルの最適化を行う流れは以下の通りです。
- 学習済みモデルを準備(ONNX形式やTensorFlow/PyTorchモデルを使用)
- TensorRTにモデルを読み込ませる
- 最適化(FP16/INT8変換やレイヤー融合など)
- 最適化済みエンジンを使って推論を実行
簡単な例として、ONNXモデルをTensorRTで最適化する方法を紹介します。
import tensorrt as trt
# TensorRTのログ出力用
logger = trt.Logger(trt.Logger.WARNING)
# ONNXモデルをTensorRTに変換
builder = trt.Builder(logger)
network = builder.create_network(1)
parser = trt.OnnxParser(network, logger)
with open("model.onnx", "rb") as f:
if not parser.parse(f.read()):
print("ONNXモデルの読み込みに失敗しました")
config = builder.create_builder_config()
config.set_flag(trt.BuilderFlag.FP16) # FP16最適化を有効化
engine = builder.build_engine(network, config)
print("TensorRTエンジンが作成されました")
AI推論の具体的なイメージが付きましたでしょうか。
ぜひ試してみてください!
TensorRTの活用事例
では実際にTensorRTはどのような場面で使われているのでしょうか。
画像分類
画像分類の分野では、TensorRTが幅広く活用されています。
- 自動運転の分野:車載カメラが捉えた映像から歩行者や標識を瞬時に識別し、安全な運転をサポートするために使われています。
- 医療の現場:MRIやCTスキャンの画像を解析し、病変の可能性がある部位を素早く特定することで、医師の診断を助けています。
- 防犯の分野:防犯カメラの映像をリアルタイムで処理し、不審な行動をとる人物を検出するシステムにも活用されており、犯罪の予防や迅速な対応に貢献しています。
こうした場面では、高い精度はもちろんのこと、瞬時に判断を下せるスピードも求められます。
TensorRTによる推論の高速化【GMO株式会社】
【参考】エッジAI(Jetson Nano 2GB)でTensorRTを用いて推論高速化をしてみました
GMOインターネット株式会社では、Jetson Nano 2GBを用いて、TensorRTによる推論の高速化を実施しました。
具体的には、TensorFlowやPyTorchで学習済みの画像認識モデルをTensorRTに変換し、桜の写真などを用いて推論速度を比較した結果、TensorRTモデルが最も優れた性能を示しました。
実際のテストでは、OpenCVとPyTorchを組み合わせ、リアルタイム認識を行い、TensorRTを使用した場合、推論速度が約30倍向上したことを確認しています。
物体検出
物体検出は、画像や動画の中から特定のものを見つけて、その場所を特定する技術です。
- 自動運転
自動運転車は、前を横切る歩行者や隣の車、信号の色を素早く判断し、安全に走行するためにこの技術を活用しています。
- 工場
流れてくる製品をカメラでチェックし、不良品を見つけてはじく作業にも使われています。
どちらも、一瞬の判断ミスが大きな影響を与える場面だからこそ、正確で素早い処理が求められます。
ディープラーニングを活用した物体検出システム【株式会社コンピュータマインド】
Deep Learningを活用した物体検出システムを開発し、推論時間の高速化を実現しました。従来の手法では、熟練したエンジニアがターゲットごとに特徴量をプログラミングし、調整を行う必要がありましたが、Deep Learningによる物体検出では、大量のターゲット画像を学習することで、高精度な推論が可能となりました。本システムにおける物体検知の推論時間は約50ミリ秒と非常に高速であり、実際のシステムへの導入においても効果を発揮しています。
【関連サイト】
Development Stories 開発事例集 ~製品・システム開発編~
セグメンテーション
セグメンテーションとは、画像を細かく区切り、それぞれの領域を識別する技術です。
- 医療の現場
CTやMRIの画像を解析し、臓器や病変の部分を正確に識別するのに使われています。
- 自動運転の分野
カメラで撮影した道路の映像を分析し、車線や障害物を認識するために活用されています。これにより、車が状況を素早く判断し、安全に走行できるようになります。
- 衛星画像の解析
都市部や森林、農地などの土地の種類を分類し、環境の変化を追跡するのにも役立っています。
こうした分野では、高い精度が求められる一方で、大量のデータを素早く処理する必要があります。そこで活躍するのがTensorRTが用いられています。
自然言語処理
自然言語処理(NLP) は、チャットボットや音声アシスタントなど、日常のさまざまな場面で活用されています。
特に、カスタマーサポートでは自動応答システム が導入され、ユーザーの問い合わせにAIが即座に対応する仕組みが整っています。
しかし、BERTやGPT、Llamaなどの高度な言語モデル(LLM)は処理負荷が高く、リアルタイム応答が課題です。
そこでTensorRTやTensorRT-LLMを活用することで、LLMの推論を最適化し、速度と効率を大幅に向上 できます。
TensorRT-LLMによる推論最適化
TensorRT-LLMは、GPTやLlamaなどの大規模言語モデル(LLM)に特化した推論最適化ライブラリ です。
高度な最適化技術を活用し、AIのリアルタイム処理を可能にします。
- チャットボットの応答速度向上 → スムーズな会話を実現
- 機械翻訳のリアルタイム処理 → ニュースやカスタマーサポートの即時翻訳を可能に
- マルチGPU対応 → AIモデルをスケールし、さらに高速化
- 量子化対応(FP8/INT4など) → メモリ使用量を削減しつつ精度を維持
#### 大規模に実行できるAIサービスの開発【Hugging Face】

引用元:Hugging Face公式HP
オープンソースAIを手がけるHugging Face社は、テキスト分析やニューラル検索、対話型アプリケーションを大規模に実行できるAIサービスの開発にTensorRTを使用しています。
これにより、自然言語処理モデル「BERT」での推論におけるレイテンシー(遅延時間)を1ミリ秒に短縮することに成功しています。
【参考】
tensorrt community
TensorRTの将来展望
TensorRTは、より速く、より効率的にAIモデルを動作させるために、NVIDIAによって常に改良が加えられています。
今後も、新しい最適化技術や高度な機能が追加されることで、さらなる高速化が進むと考えられます。
また、NVIDIAのTriton Inference Serverのような他の推論ソフトウェアとの連携も進み、よりシームレスなAI推論環境が実現されるでしょう。
これにより、企業や開発者がAIを活用しやすくなり、さまざまな場面でのAIの導入が加速されることが期待されます。
AIの進化への貢献
TensorRTの高速な推論処理は、AIの実用化を加速させ、社会のさまざまな場面での活用を可能にします。
これにより、より高度なAIモデルが、より多くのデバイスやアプリケーションで使われるようになり、AIの影響力がますます大きくなっていくでしょう。
また、TensorRTは、AIの民主化にも貢献すると考えられます。
現在、高度なAI技術は一部の大手企業や研究機関に限られていますが、TensorRTのような最適化技術が普及すれば、より多くの企業や開発者がAIを活用できるようになります。
これにより、小規模なスタートアップや個人開発者でも、高性能なAIアプリケーションを開発しやすくなるでしょう。
まとめ
TensorRTは、AIの推論を高速化するために開発されたNVIDIAのツールで、今や多くの分野で活用されています。今後はさらに、新しいGPUアーキテクチャへの対応や、より高度な最適化が進むことで、AIの推論速度はさらに向上し、より多くのデバイスやアプリケーションでの活用が期待されます。
AI総合研究所は企業のAI導入をサポートしています。導入の構想段階から、AI開発はもちろん、研修・導入のサポートなども支援いたします。
お気軽に弊社にご相談ください。
AI技術の発展は、私たちの生活に大きな変化をもたらしています。自動運転車がより安全に走るようになり、医療現場では病気の早期発見が可能になり、スマートフォンのアシスタントはより自然な対話ができるようになりました。
こうした変化の裏側には、TensorRTのような技術が支えている部分が少なくありません。AIをより身近なものにし、より多くの人がその恩恵を受けられるようになるために、TensorRTのような最適化技術は今後も重要な役割を果たしていくでしょう。










