この記事のポイント
 機械学習(ML)とディープラーニング(DL)は、人工知能(AI)分野の重要な技術だが、その違いを正しく理解することが重要
機械学習(ML)とディープラーニング(DL)は、人工知能(AI)分野の重要な技術だが、その違いを正しく理解することが重要- MLとDLは、利用可能なデータ量、計算リソース、モデルの説明責任などの観点で異なる特徴を持つ
- MLの主要なアルゴリズムには、サポートベクターマシンや決定木などがある
- DLの主要なアーキテクチャには、畳み込みニューラルネットワーク(CNN)やリカレントニューラルネットワーク(RNN)などがある
- MLやDLをビジネスに導入する際は、適切なデータ収集、モデル選択、セキュリティ、コンプライアンスに配慮する必要がある

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
機械学習(ML)とディープラーニング(DL)は、どちらも人工知能(AI)分野の重要な技術です。しかし、その違いを正しく理解することは容易ではありません。
本記事では、MLとDLの基本概念を整理し、利用可能なデータ量、計算リソース、モデルの説明責任などの観点から、それぞれの技術の特徴と違いを明らかにします。 また、具体的な応用例や、ビジネスへの導入に向けたステップ、注意点なども解説します。
機械学習とディープラーニングの違いを理解し、適切に活用するための知識を身につけましょう。
目次
機械学習とディープラーニングの違い

AI、機械学習、ディープラーニングの概念
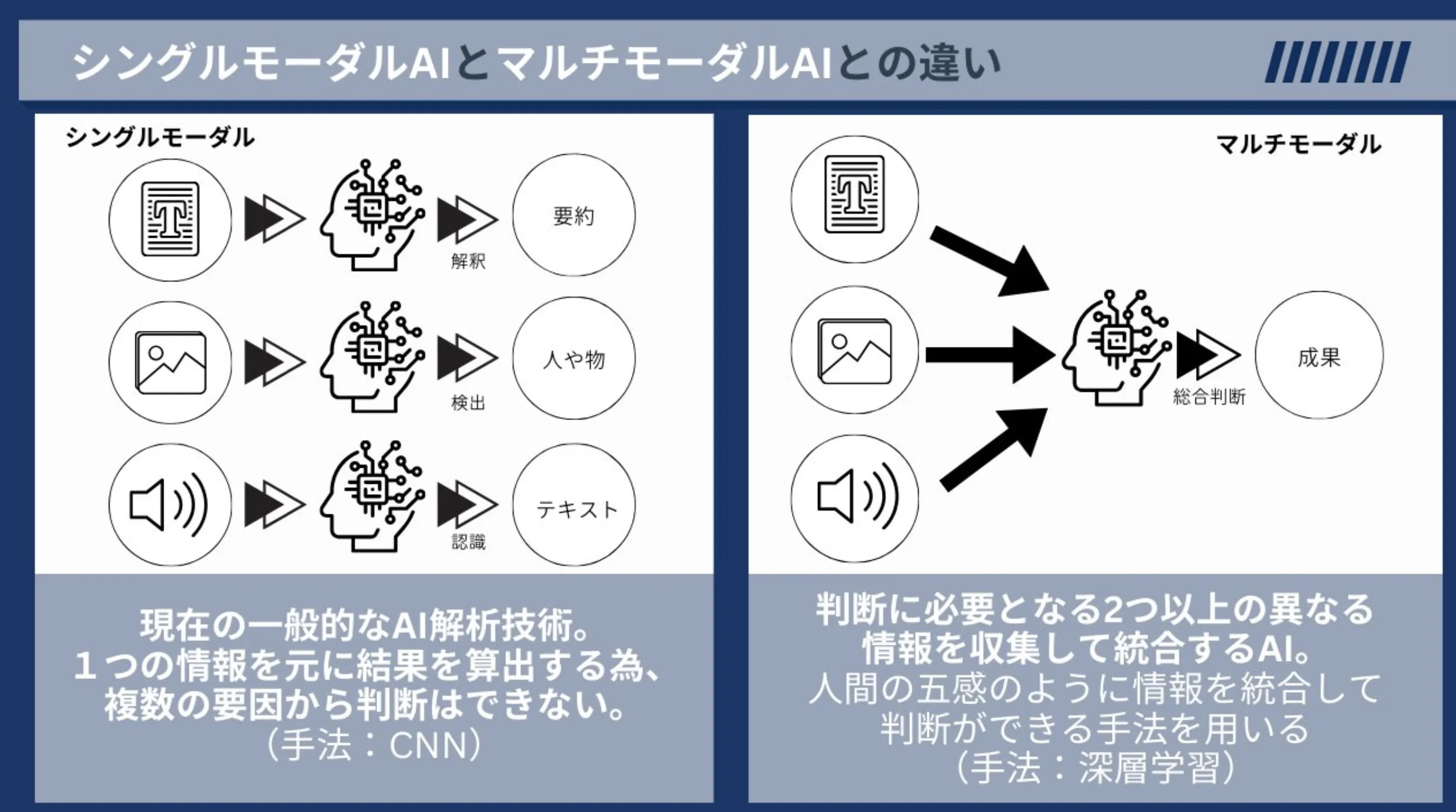
機械学習と深層学習はどちらもAI(人工知能)の分野に属していますが、そのアプローチと技術にはいくつかの重要な違いがあります。
AI(いわゆる人工知能)の中に機械学習という手法が存在し、その中のさらに一つの手法として多層の人工ニューラルネットワーク を用いて、データから複雑な表現を学習する機械学習の一種が深層学習になります。
いわゆるニューラルネットワークというものです。
以下は機械学習と深層学習の一般的な違いを表にまとめたものです。
| 特徴 | 機械学習 | 深層学習 |
|---|---|---|
| 定義 | 経験から学習し、自らを改善するアルゴリズムの開発 | 多層ニューラルネットワークを用いてデータから複雑な表現を学習 |
| 特徴抽出 | 手動で行う必要がある | 自動で特徴を抽出する |
| データ量 | 比較的少量のデータでも効果的 | 大量のデータが必要 |
| 計算リソース | 比較的少ない計算リソースで効果的 | 高い計算リソースを必要とする |
| アプローチ | 特徴抽出後、様々なアルゴリズムを用いてモデルを訓練 | 多層ニューラルネットワークを通じて自動で特徴学習と訓練を行う |
| 使用例 | 分類、回帰、クラスタリング、推薦システム等 | 画像認識、自然言語処理、音声認識等 |
| ドメイン知識 | 重要 | それほど必要ではない |
| 応用範囲 | 幅広い問題に適用可能 | 高度な認識が必要なタスクに特に有効 |
また、さらに深層学習の一分野が昨今ChatGPTが起爆剤となり、大きな注目を浴びる生成AI です。生成AIについても詳しく解説していますので関連記事をご覧ください。
︎
AIと機械学習の関係性
機械学習(ML)は、人工知能(AI)およびコンピューターサイエンス内の分野であることは既に説明をしました。
では、AIには機械学習の他にどのような分野が含まれているのでしょうか。
機械学習に含まれないAIの分野として以下のものがあります。
| 分野 | 説明 |
|---|---|
| ロボティクス | 自律的に動作する機械やロボットの開発。 |
| 知識表現と推論 | 知識をコンピュータに理解可能な形で表現し、論理的推論を行う技術。 |
| エージェントとマルチエージェントシステム | 複数の自律的なエージェントが協力または競争しながらタスクを遂行する技術。 |
| 感情認識 | 人の感情を音声、表情、テキストなどから識別する技術。 |
| コンピュータビジョン(機械学習を使用することが多いが、伝統的なアルゴリズムも含む) | 画像やビデオデータから情報を抽出し理解する技術。 |
| 音声認識(機械学習を使用することが多いが、伝統的なアルゴリズムも含む) | 音声データからテキストへの変換や音声生成などを行う技術。 |
| 強化学習(機械学習の一種と見なされることもあるが、独自のアプローチを持つ) | 試行錯誤を通じて最適な行動を学習する技術。 |
機械学習技術はこれらの分野において重要な役割を果たすことがありますが、各分野は独自の領域を持っています。
【関連記事】
➡️AIと機械学習(ML)の違いは?それぞれの仕組みを踏まえて徹底解説!
機械学習とは

機械学習(ML)は、人工知能(AI)およびコンピューターサイエンス内の分野であり、コンピューターがデータとアルゴリズムから学習できるようにすることで、人間の学習方法を模倣し、精度を徐々に向上させることに重点を置いています。
MLアルゴリズムを使用すると、コンピューターはラベル付きまたはラベルなしの入力データに基づいて予測や分類を行うことができます。
このような機械学習アルゴリズムを深く知ることで深層学習との違いがより見えてきます。
機械学習の学習プロセスには、通常、次の3つの主要なコンポーネントが含まれます。
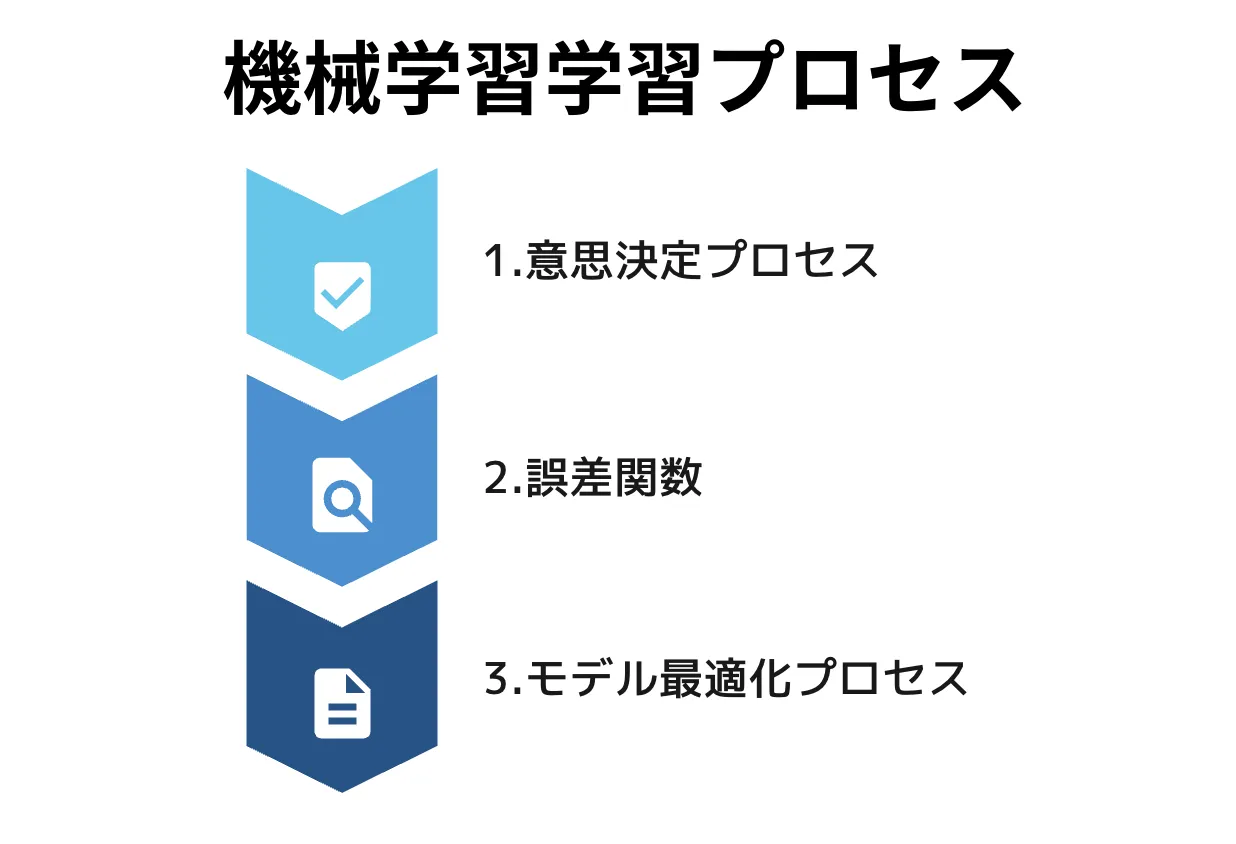
機械学習の学習プロセス
- 意思決定プロセス
MLアルゴリズムは、入力データに基づいて予測または分類を行うために使用されます。
これらの予測または分類は、データ内で特定されたパターンに基づいています。
- 誤差関数
誤差関数は、モデルの予測の精度を評価します。ラベル付きの例が利用可能な場合、誤差関数はモデルの予測を実際のラベルと比較して精度を評価します。
- モデル最適化プロセス
モデル最適化プロセスには、モデルのパラメーターまたは重みを調整して、モデルの予測と実際のデータの間の差異を最小限に抑えることが含まれます。
このプロセスは反復され、満足のいくレベルの精度が達成されるまで継続されます。
機械学習の手法と学習の種類
機械学習のアルゴリズム(手法)にはいくつかの種類が含まれます。
ここでは機械学習のアルゴリズムについてご紹介します。
教師あり機械学習
教師あり学習では、ラベル付きデータセットを使用してアルゴリズムをトレーニングし、データを分類したり結果を正確に予測したりします。
入力データには対応するラベルが付いており、アルゴリズムはこのラベル付きデータに基づいて予測を行うことを学習します。
教師なし機械学習
教師なし学習には、ラベルのないデータセットの分析とクラスタリングが含まれ、データ内の隠れたパターンやグループ化を発見します。
このタイプの学習にはラベル付きデータは必要なく、アルゴリズムがデータ内の類似点と相違点を自律的に識別します。
半教師あり学習
半教師あり学習は、教師あり学習と教師なし学習の要素を組み合わせたものです。
小さなラベル付きデータセットを使用して、より大きなラベルなしデータセットからの分類と特徴抽出をガイドします。
強化機械学習
強化学習には、試行錯誤を通じて意思決定を行うためのアルゴリズムのトレーニングが含まれます。
このアルゴリズムは、環境と対話し、報酬またはペナルティの形でフィードバックを受け取ることによって学習します。
【関連記事】
➡️機械学習の代表的な手法一覧!フローチャートを用いて選び方を解説
機械学習アルゴリズムの実例
【サポートベクターマシン(SVM)】
SVMは、分類および回帰タスクに使用される教師あり学習アルゴリズム です。
これは、特徴空間内のクラスを最もよく分離する超平面を見つけることによって機能します。
簡単なコードは以下になります。
from sklearn import svm
X_train = [[0, 0], [1, 1]]
y_train = [0, 1]
clf = svm.SVC(kernel='linear')
clf.fit(X_train, y_train)
X_test = [[2, 2]]
predicted_class = clf.predict(X_test)
print("Predicted class:", predicted_class)
この例では、線形カーネルで単純なバイナリ分類タスクにSVMを使用する方法を示します。
ただし、SVMは、多項式カーネルや放射基底関数(RBF)カーネルなど、他のさまざまなカーネルをサポートしており、分類器の初期化時にカーネルパラメーターを介して指定することもできます。
【決定木/ Decision Tree】
決定木は、分類タスクと回帰タスクに使用されるノンパラメトリック教師あり学習方法 です。
データの特徴から推測される単純な決定ルールを学習することで、ターゲット変数の値を予測するモデルを作成します。
ここでは、有名なirisのデータセットを用いて分類タスクにDecisionTreeClassifierを使用する方法を示すサンプルコードとともに説明します。
from sklearn import tree
from sklearn.datasets import load_iris
iris = load_iris()
X, y = iris.data, iris.target
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, y)
prediction = clf.predict([[2., 2.]])
print(prediction)
probabilities = clf.predict_proba([[2., 2.]])
print(probabilities)
このような仕組みは、ChatGPTに聞いてみることもできます。
以下は、上記のコードをコピーして上記の結果とグラフを算出することを依頼したものです。
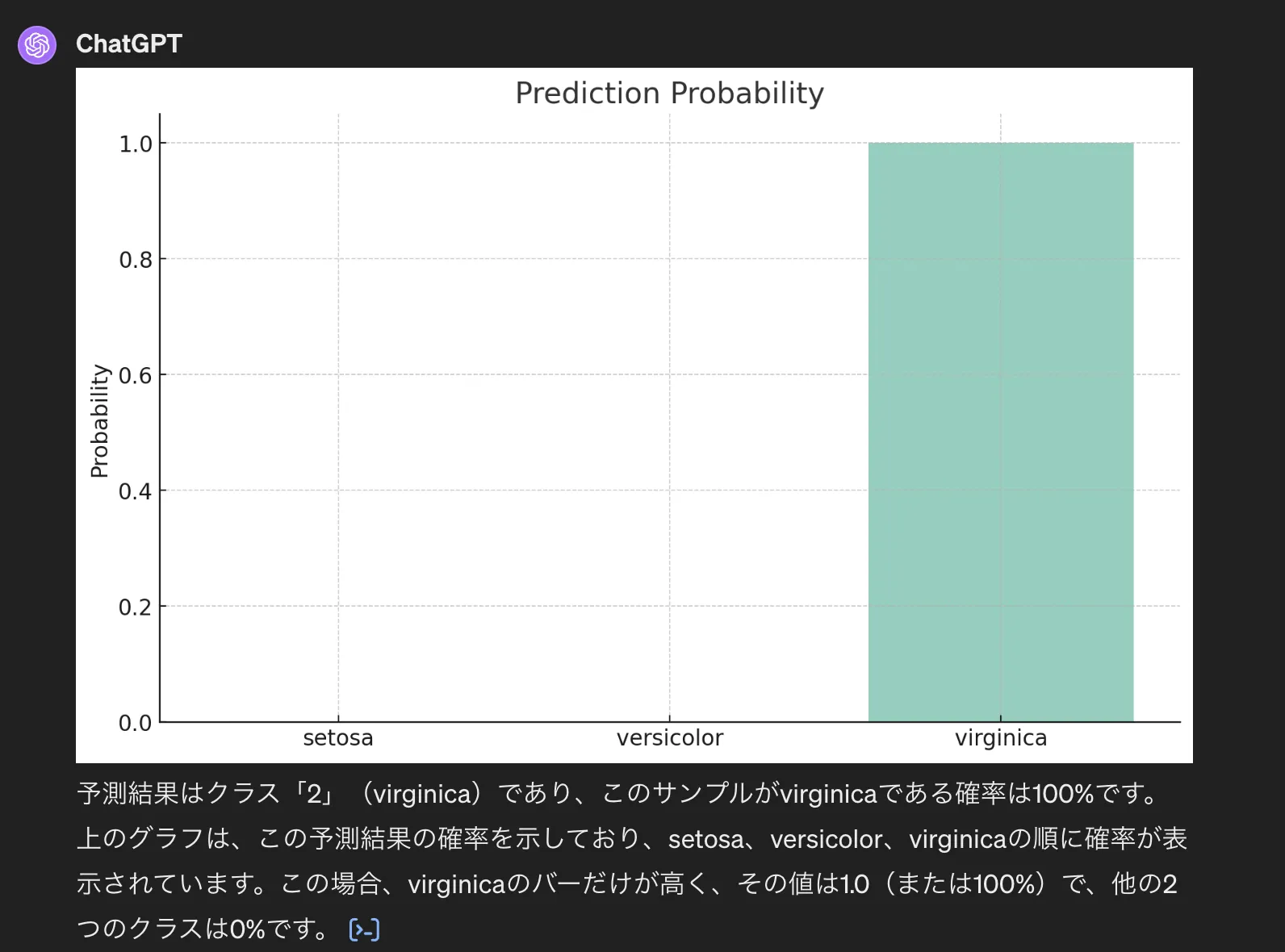
irisデータ結果
irisの花の種類の予測ですが、virginicaである確率は100%であることを示しています。このように機械学習を行うことで推論・予測が可能になります。
ディープラーニング(深層学習)とは
ディープラーニングは人工知能(AI)のサブセットであり、人間の脳にヒントを得た方法でデータを処理するようにコンピューターをトレーニングすることが含まれます。
ディープラーニングは、デジタルアシスタントや不正行為検出から自動運転車や顔認識に至るまで、数多くのアプリケーションで重要な役割を果たしています。
深層学習の種類
深層学習の主なアーキテクチャには、畳み込みニューラルネットワーク(CNN)、リカレントニューラルネットワーク(RNN)、長短期記憶ネットワーク(LSTM)があります。
CNN
画像認識やコンピュータービジョン を伴うタスクに特に効果的です。これらは、畳み込み層、プーリング層、全結合層などの複数の人工ニューロン層で構成されています。
CNNは画像から特徴を自動的に学習して抽出できるため、物体検出、画像分類、顔認識などのタスクに適しています。
RNN
時系列データや自然言語 などの順次データを処理するように設計されています。従来のニューラルネットワークとは異なり、RNNには有向サイクルを形成する接続があり、以前の入力のメモリを保持できます。
RNNは、言語翻訳、音声認識、感情分析などのアプリケーションでよく使用されます。
LSTM
長いデータシーケンスで従来のRNNをトレーニングするときに発生する可能性がある勾配消失問題に対処するRNNの一種です。
れらには、長期間にわたって情報を維持できる特殊なメモリセルが含まれているため、長距離の依存関係を持つシーケンスの学習パターンに適しています。
LSTMは、音声認識、テキスト生成、時系列予測 などのタスクで広く使用されています。
【関連記事】
➡️LSTMとは?その仕組みや使用例をわかりやすく解説!
ディープラーニングの実例︎(模擬)
ここでは先ほどの機械学習の例で使用したirisを使って簡単な深層学習の模擬を行います。
PythonのKerasライブラリを使用して、簡単なニューラルネットワークモデルを構築し、訓練するプロセスを示します。
スクリプトでは、まずIrisデータセットをロードして、入力データとターゲットデータを準備します。
次に、Sequentialモデルを構築し、中間層(隠れ層)として活性化関数ReLUを持つDenseレイヤー、そして出力層として活性化関数Softmaxを持つDenseレイヤーを追加します。
このモデルは、3つの異なるアヤメの種類を分類するために設計されています。
ステップ1:ライブラリのインポートとデータの準備
まず、必要なライブラリをインポートし、データを準備します。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
# Irisデータセットのロード
iris = load_iris()
X, y = iris.data, iris.target
# ターゲットをOne-Hotエンコーディング
encoder = OneHotEncoder(sparse=False)
y = y.reshape(-1, 1)
y_encoded = encoder.fit_transform(y)
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, test_size=0.2, random_state=42)
ステップ2:モデルの構築
次に、モデルを構築します。ここでは、入力層、隠れ層1つ、出力層からなるシンプルなネットワークを使用します。
# モデルの構築
model = Sequential()
model.add(Dense(8, input_dim=4, activation='relu')) # 隠れ層
model.add(Dense(3, activation='softmax')) # 出力層
# モデルのコンパイル
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
ステップ3:モデルの訓練
モデルを訓練データで訓練します。
# モデルの訓練
model.fit(X_train, y_train, epochs=150, batch_size=10)
ステップ4:モデルの評価
最後に、テストデータでモデルの性能を評価します。
# モデルの評価
loss, accuracy = model.evaluate(X_test, y_test)
print(f'Accuracy: {accuracy*100}')
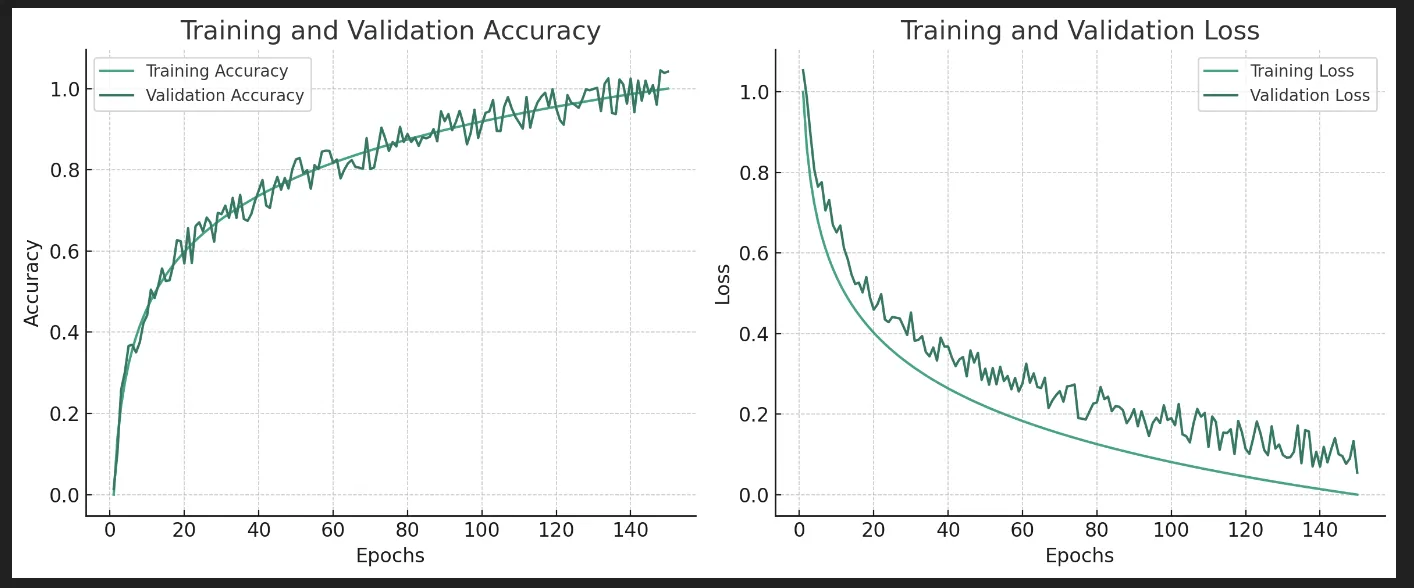
ディープラーニングのモデル学習過程の模擬
左のグラフが「どれだけ上手く学習しているか」を示し、右のグラフが「どこでつまずいているか」を示しています。
学習が進むにつれて、左のグラフの線は上に向かって(精度が上がって)、右のグラフの線は下に向かっていく(損失が減っていく)のが理想です。
訓練データと検証データでの差を確認することで、モデルが学習したことを実際にうまく使えているかどうか検証します。
利用可能なデータの重要性
データの量と種類が、機械学習と深層学習技術のアプリケーションと結果に大きな影響を与えます。
以下の表は、データが機械学習モデルの開発とパフォーマンスにどのように影響を与えるかについての概要を示しています。
| 要素 | 説明 |
|---|---|
| データ量 | データが増えると、モデルのパフォーマンスは向上します。 データセットが大きくなると、モデルはより多様なパターンを学習し、一般化能力が向上します。 |
| データの種類 | 機械学習技術は構造化データと非構造化データの両方を処理できます。 データの種類はアルゴリズムと前処理ステップの選択に影響します。 |
| 次元性 | データの次元性は、モデルの複雑さと必要な計算リソースに影響を与えます。 高次元データは、複雑な関係を捕捉できます。 |
| ドメインの特異性 | ドメインが異なれば、必要なデータの種類も異なります。 適切な種類のデータを選択することが重要です。 |
| データの品質 | データの品質(精度、完全性、一貫性)は、機械学習モデルのパフォーマンスに直接影響します。 |
適切なデータの選択、処理、そして品質管理は、成功した機械学習アプリケーションを構築するための鍵です。

ディープラーニングの導入できる活用分野
ディープラーニングの活用分野はさまざまでマルチモーダルに利用することが可能です。
深層学習の活用分野
画像認識
機械学習アルゴリズムが大規模な画像データセットから学習し、画像内の物体、顔、またはパターンを識別します。
【関連記事】
➡️画像認識AIとは?その活用事例や機械学習の仕組みをわかりやすく解説
自然言語処理 (NLP)
テキストデータからの情報抽出、テキスト生成、言語翻訳、感情分析など、言語に関連する様々なタスクを実行します。
チャットボットや仮想アシスタントの背後にある技術であり、ユーザーの質問に対する回答を生成したり、自然言語の文を理解したりすることができます。
関連記事】
➡️自然言語処理とは?AIが人間の言語を理解する仕組みをわかりやすく解説
強化学習
ゲーム、ロボット工学、推薦システムなど、環境からのフィードバックを基に最適な行動を学習するタスクに使用されます。
音声認識
自動音声認識(ASR)技術は、音声データをテキストデータに変換し、声による指示や質問に応答するシステムを可能にします。
これらの分野において、ディープラーニングは顕著な成果を上げており、今後も新たな応用が期待されています。
特に、複数のモダリティ(画像、テキスト、音声など)を組み合わせたマルチモーダルなアプローチは、さらに複雑で高度なタスクを解決する可能性を秘めています。
こちらは音声認識を活用した例です。ロボットもここまで来るとすごいですね。
<<Chat GPTの技術がロボットに搭載>>
— 坂本将磨@AI総合研究所 (@LinkX_group) March 13, 2024
これは、、、、
pic.twitter.com/TSAdEcgxQX
機械学習の導入時に注意すべきこと
テクノロジー、特に機械学習をビジネスに導入するには、いくつかの具体的な手順と考慮事項が必要になります。
AIとMLの違いを理解する
実装に入る前に、人工知能 (AI) と機械学習 (ML) の違いを理解することが重要です。MLはAIのサブセットであり、予測を行うためにデータを使用してモデルをトレーニングすることが含まれます。
AIとMLの基礎について自分自身とチームを教育し、ビジネスコンテキストでの潜在的なアプリケーションを把握します。
ビジネスプロセスを調査し、ML 対応プロセスを特定する
ビジネス内のすべてのプロセスが ML の恩恵を受けるとは限りません。
MLの実装に適切なプロセスを特定するには、どのプロセスが人力を要するのか、再現性が高いのか、または大量のデータのレビューが必要なのかを理解する必要があります。
社内のビジネスプロセスを徹底的に分析して、ML が大きな価値と効率性の向上をもたらす可能性がある領域を特定します。
ML のためのデータ収集と特徴抽出
- ML モデルは、トレーニングと正確な予測を行うために元のデータに大きく依存しています。
データ収集と特徴抽出は、ML用のデータを準備するための重要なステップです。
関連データを収集するための堅牢なデータ収集プロセスとインフラストラクチャを確立します。さらに、特徴抽出技術に投資して、データから有意義な洞察を抽出します。
最適なモデルを見つける
最適なパフォーマンスと予測精度を達成するには、適切な ML モデルを選択することが不可欠です。モデルが異なれば、特定のデータセットやビジネスニーズに基づいてパフォーマンスが異なる場合があります。
さまざまな ML モデルと手法を試して、データと目的に最適なものを見つけてください。徹底的なテストと評価を実施して、最も効果的なモデルを特定します。
またパフォーマンスを出すだけでなくセキュリティやコンプライアンスにも十分に配慮することが重要です。
【関連記事】
➡️AI導入完全ガイド!メリットや、導入プロセス、補助金について徹底解説

まとめ
本記事では、機械学習(ML)とディープラーニング(DL)の基本概念を整理し、それぞれの技術の特徴と違いを、利用可能なデータ量、計算リソース、モデルの説明責任などの観点から明らかにしました。MLのサポートベクターマシンや決定木、DLのCNNやRNNといった主要なアルゴリズムについても、具体的な応用例を交えて解説しました。
また、MLやDLをビジネスに導入する際の注意点として、適切なデータ収集、モデル選択、セキュリティ、コンプライアンスへの配慮の重要性を強調しました。機械学習とディープラーニングの違いを正しく理解し、それぞれの技術の特性を活かしながら適切に活用することが、AIを効果的にビジネスに取り入れるための鍵となるでしょう。










