この記事のポイント
 データ分割による分類・回帰
データ分割による分類・回帰- 木構造で可視化、高解釈性
- ジニ不純度等で最適分割
- アンサンブルで精度向上
- 幅広い分野で活用可能

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
日々の業務で、大量のデータから意味のある情報を引き出し、素早く正確な判断を下すことは容易ではありません。特に、複数の要因が複雑に絡み合う状況では、人間だけでは限界があります。
そんな課題を解決する強力な手法が「決定木」です。しかし、その仕組みや具体的な活用方法を理解している人は、まだ多くありません。
本記事では、この「決定木」について、基礎から応用までをわかりやすく解説します。
決定木の仕組み、作り方、他の分析手法との使い分け、そして様々な分野での活用事例まで、幅広く網羅的に説明します。
目次
決定木とは
決定木(Decison Tree) は、入力データの特徴量に基づいてデータを繰り返し分割し、最終的に分類や回帰を行う機械学習手法です。木構造で表現されるため、直感的に「ここで分岐して、あそこで判定する」というような流れが理解しやすく、業務現場でも説明しやすいモデルとして注目されています。
具体的に、決定木はデータを「もし特徴Xがこの値以上なら右へ、未満なら左へ」というルールで分割していき、葉ノード で最終的な予測値(クラスや数値)を決定します。このような階層的分割により、データの関係性を木状に整理し、わかりやすく出力する点が特徴です。
特に、決定木の内部では どのようにデータを分割し、どの基準で最適なルールを選んでいるのか? を知ることが重要です。ここでは、決定木の構造と仕組みを詳しく解説していきます!
決定木の構造と仕組み
決定木は、内部ノードでデータを分割し、葉ノードで予測結果を出す構造を持ちます。分割基準にはジニ不純度やエントロピーなどが用いられ、これらを最小化する方向で木を成長させていきます。決定木の仕組みについて詳しく解説していきましょう!
決定木の基本構造:ノードとブランチ
決定木は 「ノード」 と 「ブランチ(枝)」 で構成されています。
決定木を構成する3種類のノード
決定木には、次の3種類のノードがあります。
- ルートノード(Root Node)
決定木の 最上部にあるノードで、最初のデータ分割を担当します。データの中から 最も重要な特徴量 を選び、それを基準に最初の分岐を行います。
- 内部ノード(Internal Node)
ルートノードの下にあり、データをさらに細かく分類する 中間の部分起点です。「この特徴が○○以上なら右へ、未満なら左へ」といったルールを提供します。
- 葉ノード(Leaf Node)
決定木の 最終的なゴール地点です。ここでは、分類問題なら「クラス(A or B)」、回帰問題なら「数値予測(売上 100万円など)」が出力されます。
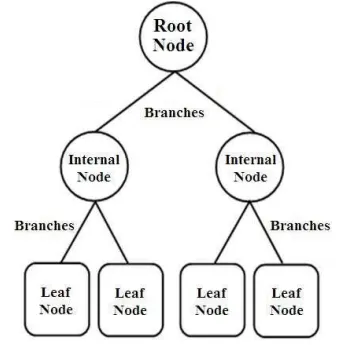
引用元:A Survey of Decision Trees: Concepts,Algorithms,and Applications
ブランチ(枝)の説明
ノード同士をつなぐ「線」の部分がブランチ(枝) です。「はい / いいえ」や「◯◯以上 / 未満」などの条件によって、次のノードへとデータが振り分けられます。
ブランチの具体例:お客さんが商品を買うかどうか?
例えば、「この人は商品を買うか?」を決定木で予測するとしたら、以下のような構造になります。
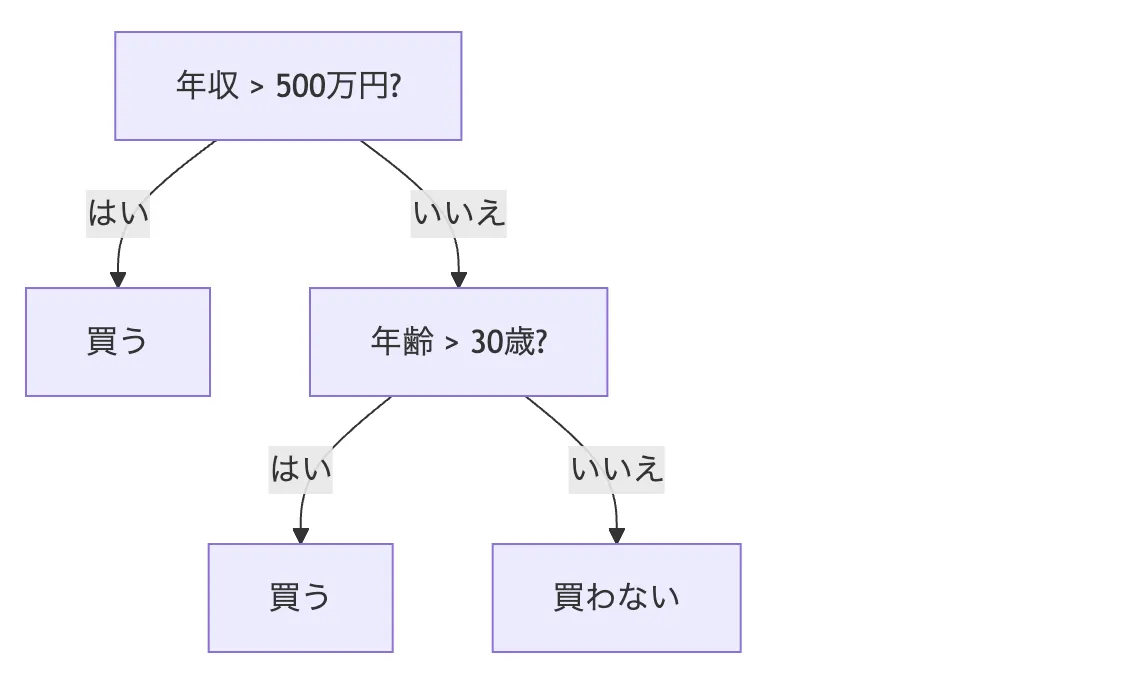
決定木イメージ
決定木がデータを分けるルール:分割基準とは?
決定木は、単に適当にデータを分けているわけではありません。「どの特徴量を使って、どの値で分割すれば、一番うまく分類できるのか?」を計算しながら作られています。
このとき使われるのが、ジニ不純度 や エントロピー などの「分割基準」です。
ジニ不純度(Gini Impurity)
データの「不純度(どれだけ混ざっているか)」を測る指標です。値が 0に近いほど、データがきれいに分類されている 状態といえます。
ジニ不純度が低くなるようにデータを分けることで、より純度の高いグループを作ることが重要です!
エントロピー(Entropy)
情報理論に基づく「データのバラつき」を測る指標です。不確実性が高いほどエントロピーも高く、均一なグループになるほどエントロピーは低くなります。
決定木では、エントロピーが 最も減る(情報が整理される)ような分割 を選びます。
決定木の構築手順
決定木を実務で用いる際は、データ準備、学習プロセス、剪定などのステップが欠かせません。ここでは、その基本的な流れを解説していきます!
データ準備と前処理
決定木は、他の機械学習アルゴリズム(例えば線形回帰やニューラルネットワーク)と比べて、データの前処理が 比較的少なくて済む という特徴があります。特に、次の点で準備が簡単になります。
1.特徴量のスケーリングが不要
一般的な機械学習では、データの数値のスケール(例えば「年収:300万円〜1000万円」と「年齢:20〜60歳」の違い)を 正規化や標準化 する必要があります。
しかし、決定木は「この値が大きいか小さいか?」を見て分岐するため、数値のスケールに左右されません。
そのため、データのスケーリングをする必要がなく、そのまま使えます!
2.欠損値への対応が柔軟
決定木は、データが多少欠けていても問題なく動作することが多いです。欠損値を持つデータは 削除する・中央値で補完する・欠損を1つのカテゴリとして扱う などの方法で対応できます。
3.カテゴリ変数(テキストデータ)は数値化が必要!
決定木は数値データを扱うため、「性別(男性・女性)」や「職業(エンジニア・営業・デザイナー)」のようなテキストデータは、そのままでは使えません。
One-hotエンコーディング や ラベルエンコーディング を使って、数値データに変換する必要があります。
実務のポイント:データの種類ごとに適切な前処理を行う!
| データの種類 | 前処理の必要性 |
|---|---|
| 数値データ(年収・年齢など) | そのまま使用可能(スケーリング不要) |
| カテゴリデータ(性別・職業など) | 数値化(One-hotエンコーディングなど) |
| 欠損値ありデータ | 削除 or 補完(中央値など) or 特殊値として処理 |
学習プロセス:決定木の作り方
決定木の学習の流れについて詳しく説明してきます!
1.ルートノードを決定する
最も情報量が多く、不純度(バラつき)が下がる特徴量を選ぶことが重要です。
2.最適な分割基準を探してノードを作る
どの特徴量(変数)を使ってデータを分けるか?、どの値(閾値)で分割すれば、クラスがきれいに分かれるか?、これらを「ジニ不純度」や「エントロピー」を使って計算していきます。
3.分割を繰り返し、葉ノードを作る
各ノードで分割を続け、データをできるだけ純粋な(=クラスが揃う)グループにします。
4.学習を止める(停止基準を設ける)
木を成長させすぎると 「過学習」 のリスクが高まるので、以下のようなルールを決めます。
木の 最大深さ(max_depth を設定します。1つのノードに 最低◯個以上のデータがないと分割しないようにします(min_samples_split)。
剪定(プルーニング)技術:過学習を防ぐ技術
決定木は、細かく分岐すればするほど「学習データにピッタリな木」が作れるけど、それが必ずしも 新しいデータ(未知のデータ)に対しても正しく予測できるとは限りません。
このように、訓練データに最適化しすぎて、新しいデータではうまく予測できなくなる現象 を 「過学習(Overfitting)」 といいます。
剪定(Pruning)とは?
剪定(プルーニング)とは、不要な枝を切り落として、よりシンプルな決定木を作る手法 のことをいいます。
木をシンプルにすることで、新しいデータにも対応できるモデルにする ことが目的です。
剪定の方法
-
事前剪定(Pre-Pruning)
決定木を作る 最初の段階で、分岐を制限 します。
-
事後剪定(Post-Pruning)
一度細かく分岐した決定木を作った後、不要なノードを後から削る方法です。
クロスバリデーション(学習データを複数回分けて検証する方法)を使い、最も良いパフォーマンスの段階でノードを削減します。
決定木を用いたアンサンブル学習
決定木は解釈しやすい機械学習アルゴリズムですが、単独では過学習しやすかったり、精度が十分でないケースがあります。しかし、アンサンブル学習(Ensemble Learning) を活用することで、これらの課題を克服し、より高精度かつ安定した予測を実現できます。
ランダムフォレスト
ランダムフォレストは、多数の決定木をランダムに学習させ、それらの結果を統合することで、精度の高いモデルを作る手法 です。この手法では、「バギング(Bagging)」というアンサンブル技術を利用します。
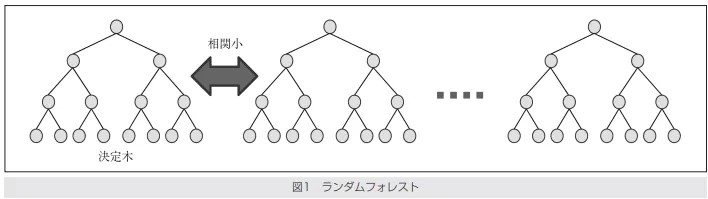
引用元:映像情報メディア学会誌 Vol.70, No.5, pp.788~791(2016)
仕組み
1.ブートストラップサンプリング(Bootstrap Sampling)
訓練データからランダムに 重複を許して サンプリングしたデータセットを複数作成します。各サンプルセットに対して、独立した決定木を学習させます。
2.特徴量のランダム選択
各決定木の分岐条件を決定する際、全特徴量の中から ランダムに選択した一部の特徴のみ を考慮します。これにより、木ごとの多様性を高め、過学習を防ぎます。
3.最終的な予測
分類問題では、各決定木の投票(多数決)で予測を決定します。回帰問題では、各決定木の出力の平均を取ります。
勾配ブースティング(XGBoost、LightGBMなど)
勾配ブースティング(Gradient Boosting) は、「ブースティング(Boosting)」という手法を利用したアンサンブル学習の一種です。
これは、前のモデルが犯した誤りを補正するように、新しいモデルを逐次的に追加していく ことで、高精度な予測を実現します。
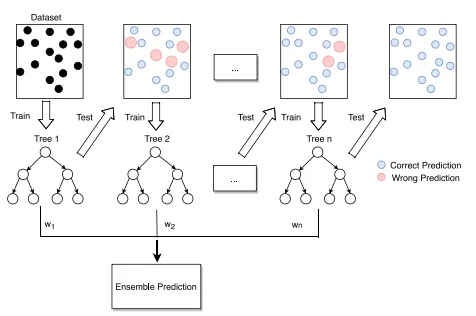
引用元:[Improving Convection Trigger Functions in Deep Convective Parameterization Schemes Using Machine Learning](file:///C:/Users/linkx/Downloads/Improving_Convection_Trigger_Functions_in_Deep_Con.pdf)
仕組み
1.初期モデルの学習
最初にシンプルな決定木(または定数値)を学習します。
2.誤差を補正するための次のモデルを追加
前の決定木が作った予測誤差を計算し、その誤差を最小化するように次の決定木を学習させます。これを繰り返し、モデルを強化していきます。
3.最終的な予測
すべての決定木の出力を合算し、最終的な予測を行います。
代表的なアルゴリズム
| アルゴリズム名 | 提案者 | 発表年 | 特徴 | 代表的な実装 |
|---|---|---|---|---|
| Gradient Boosting Machines (GBM) | Jerome H. Friedman | 2001 | 最初に提案された勾配ブースティングの基本モデル | Scikit-learn GBM |
| Stochastic Gradient Boosting | Jerome H. Friedman | 2002 | サンプリングを取り入れて過学習を抑制 | Scikit-learn GBM |
| XGBoost (eXtreme Gradient Boosting) | Tianqi Chen, Carlos Guestrin | 2016 | 並列計算、高速学習、正則化を導入 | XGBoost |
| LightGBM (Light Gradient Boosting Machine) | Microsoft Research | 2017 | Leaf-wise成長戦略で高速かつメモリ効率が良い | LightGBM |
| CatBoost | Yandex | 2017 | カテゴリカルデータの処理を最適化 | CatBoost |
決定木分析と他アルゴリズムとの比較・使い分け
決定木は、データ分析や機械学習において強力な手法の一つですが、万能ではありません。他のアルゴリズムと比較し、それぞれの特性を理解することで、適切な場面で使い分けることが重要です。
線形モデルとの比較(ロジスティック回帰など)
線形モデル(Linear Model)は、入力変数(特徴量)と出力(予測値)の間の関係が線形(直線的)である ことを前提とした機械学習アルゴリズムです。
線形モデルの特徴
- 単純で計算コストが低い
線形回帰やロジスティック回帰は数学的に単純で、計算量が少なく、解釈しやすいです。 - 解釈性が高い
係数の符号や大きさを分析することで、各特徴量の影響を直接把握できます。 - 線形関係を前提とする
説明変数と目的変数の関係が線形である場合、非常に良い予測性能を発揮します。 - 外れ値に弱い
線形モデルは極端な値(外れ値)に大きく影響を受けます。
決定木との比較
| 項目 | 線形モデル(ロジスティック回帰など) | 決定木 |
|---|---|---|
| 学習速度 | 速い(計算がシンプル) | 中程度(データ量による) |
| 解釈性 | 高い(係数の意味が明確) | 高い(ルールベースで直感的) |
| 非線形関係の表現 | 不得意(線形のみ) | 得意(分岐による非線形モデル) |
| 外れ値の影響 | 受けやすい | 受けにくい |
| 特徴量のスケーリング | 必要(標準化・正規化が推奨) | 不要 |
| 次元の影響 | 高次元での過学習が発生しやすい | 高次元でも対応可能(ランダムフォレストなら特に強い) |
| 過学習耐性 | 低い(正則化が必要) | 低い(剪定やアンサンブルが必要) |
| データ量への対応 | 小~中規模データに適している | 小~大規模データまで対応可能 |
| 特徴量の解釈 | 各変数の係数を直接解釈可能 | 特徴量の重要度を可視化しやすい |
使い分け
- 線形関係が強いデータ → 線形モデル
- 非線形関係がある場合やルールが重要な場合 → 決定木
【関連記事】
線形モデルについて詳しく知りたい人はこちらの記事も参考にどうぞ!
→機械学習の回帰とは?分類との違いや主な種類、手法をわかりやすく解説
ニューラルネットワークとの比較
ニューラルネットワーク(NN)は、人間の脳の神経細胞(ニューロン)を模倣した計算モデルであり、データのパターンを学習して予測や分類を行う機械学習アルゴリズム です。
ニューラルネットワークの特徴
- 大規模データに強い
ディープラーニング(深層学習)は数百万、数千万のデータにも対応可能です。 - 非線形関係の表現能力が非常に高い
多層のニューラルネットワークは非常に複雑なデータ構造を学習できます。 - 説明性が低い(ブラックボックス)
学習したモデルの決定プロセスを人間が理解するのが難しいです。 - 計算コストが高い
GPUを必要とする場合も多く、学習に時間がかかります。
決定木との比較
| 項目 | ニューラルネットワーク | 決定木 |
|---|---|---|
| 学習速度 | 遅い(計算コストが高い) | 速い(単体の木なら軽量) |
| 解釈性 | 低い(ブラックボックス) | 高い(ルールベースで直感的) |
| 非線形関係の学習 | 得意(層を深くすることで可能) | 得意(分岐による非線形モデル) |
| データの種類 | 画像・音声・テキスト・数値データ | 主に構造化データ向き |
| 特徴量の自動学習 | 可能(CNN, RNNなど) | 不可能(特徴量選択が必要) |
| 過学習のリスク | 高い(正則化が必要) | 高い(剪定やアンサンブルが有効) |
| 計算コスト | 高い(GPU推奨) | 低い(単純な決定木なら軽量) |
| データ量の必要性 | 大量のデータが必要 | 少量のデータでも学習可能 |
| アンサンブル活用 | なし(通常単独で使用) | あり(ランダムフォレスト, 勾配ブースティング) |
使い分け
大規模データセット、画像・音声データ、時系列データ → ニューラルネットワーク
解釈が重要なタスク(医療、法務、金融) → 決定木
【関連記事】
ニューラルネットワークについて詳しく知りたい人はこちらの記事も参考にどうぞ!
→CNN(畳み込みニューラルネットワーク)とは?仕組み・活用事例を徹底解説
SVM、k近傍法との比較
SVM(Support Vector Machine)は、データを分類するための 「最適な超平面(ハイパープレーン)」 を見つける機械学習アルゴリズムです。k-NN(k-Nearest Neighbors)は、データ間の距離を測り、近くにある「k個のデータ」の多数決で分類を決める手法 です。
SVMの特徴
- マージン最大化による分類
データのクラス境界を決める超平面(ハイパープレーン)を最適化することで、高い識別性能を持ちます。 - 高次元データにも適用可能
カーネル関数を使うことで、線形分離が難しいデータにも適用できます。 - 計算コストが高い
大規模データでは訓練に時間がかかります。
k-NN(k近傍法)の特徴
- シンプルな非パラメトリック手法
学習時にモデルを作らず、予測時に最近傍のk個のデータを参照して分類します。 - 計算コストが高い(大規模データには向かない)
全データとの距離計算が必要なため、データセットが増えると計算量が増加します。 - 特徴量のスケーリングが重要
特徴量のスケールが異なると、結果が大きく変わるため、正規化が必要です。
決定木との比較
| 項目 | SVM(サポートベクターマシン) | k-NN(k近傍法) | 決定木 |
|---|---|---|---|
| 学習速度 | 遅い(最適な超平面の計算) | 速い(モデル不要) | 速い(データ量による) |
| 予測速度 | 速い(超平面を使う) | 遅い(全データとの距離計算) | 速い(分岐の計算のみ) |
| 非線形データの対応 | カーネルを使えば可能 | 可能(距離ベース) | 可能(分岐ルールで表現) |
| 特徴量のスケーリング | 必要(標準化が推奨) | 必要(距離計算に影響) | 不要 |
| 解釈性 | 低い(ブラックボックス) | 低い(データ分布に依存) | 高い(ルールベースで直感的) |
| 過学習耐性 | 高い(マージン最大化) | 低い(kの値による) | 低い(剪定やアンサンブルが必要) |
| 計算コスト(大規模データ) | 高い(学習に時間がかかる) | 高い(予測時に計算量が増える) | 低い(単体の木なら軽量) |
| データ量への適性 | 小〜中規模データ向き | 小〜中規模データ向き | 小〜大規模データ対応可能 |
| パラメータ調整 | カーネル・正則化パラメータが必要 | k の値のみ | 剪定・最大深さなど |
使い分け
小規模データで、クラス境界を明確にしたい → SVM
データが少なく、直感的な近傍距離で分類可能な場合 → k-NN
大規模データや解釈性が求められる場合 → 決定木
決定木の実装例
実際に決定木を実装してみましょう!今回はGoogle Colab環境で試してみます。
模擬コード
# 必要なライブラリをインストール(Colabでは通常不要)
# !pip install scikit-learn matplotlib graphviz
# 1️⃣ 必要なライブラリのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import accuracy_score
# 2️⃣ ダミーデータの作成(顧客の購入予測)
np.random.seed(42) # 再現性確保
# 例:年齢・年収・過去の購入履歴を特徴量としたデータ
data_size = 200
age = np.random.randint(20, 60, data_size) # 年齢(20〜60歳)
income = np.random.randint(200, 1000, data_size) # 年収(200〜1000万円)
past_purchase = np.random.choice([0, 1], data_size) # 購入履歴(0: なし, 1: あり)
# ターゲット(購入するかどうか)
target = np.where((income > 500) & (age > 30) | (past_purchase == 1), 1, 0)
# データフレームの作成
df = pd.DataFrame({'Age': age, 'Income': income, 'Past_Purchase': past_purchase, 'Buy': target})
print(df.head())
# 3️⃣ データの分割(学習データ80% / テストデータ20%)
X = df[['Age', 'Income', 'Past_Purchase']]
y = df['Buy']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 4️⃣ 決定木モデルの構築・学習
tree_model = DecisionTreeClassifier(max_depth=4, random_state=42) # 木の深さを4に制限
tree_model.fit(X_train, y_train)
# 5️⃣ モデルの評価(精度確認)
y_pred = tree_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'✅ モデルの精度: {accuracy:.2f}')
# 6️⃣ 決定木の可視化
plt.figure(figsize=(12, 8))
plot_tree(tree_model, feature_names=X.columns, class_names=['No', 'Yes'], filled=True)
plt.show()
# 7️⃣ 新しいデータで予測
new_data = pd.DataFrame([[35, 600, 1], [25, 400, 0]], columns=["Age", "Income", "Past_Purchase"])
predictions = tree_model.predict(new_data)
print('新しい顧客の購入予測: {predictions}')
実行結果
実行すると以下のような結果が出ました!
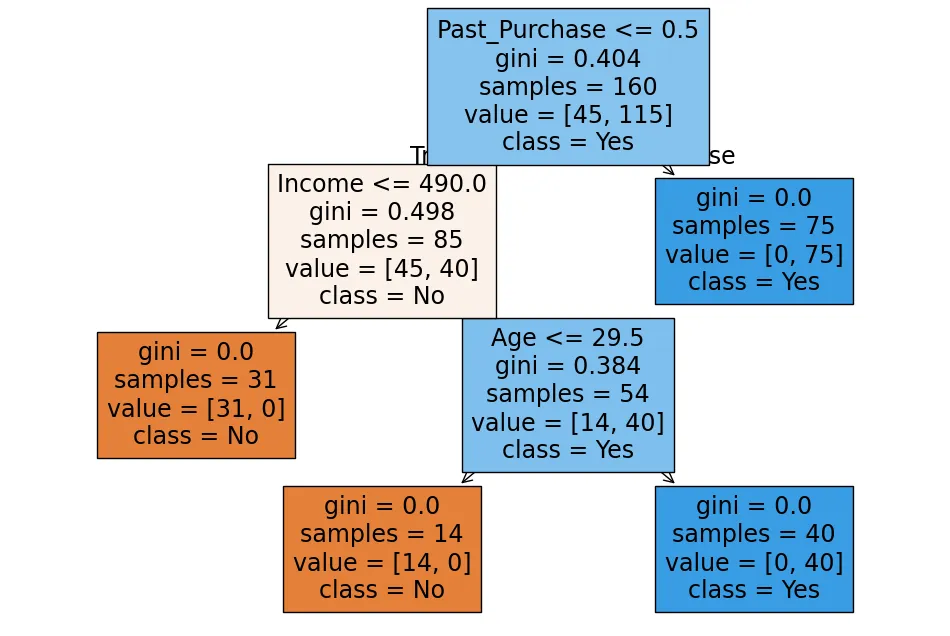
実行結果
新しい顧客の購入予測: [1 0]
このモデルの予測結果 は [1, 0](1人目は購入する、2人目は購入しない)ということを表しています。
決定木分析の活用事例
決定木分析は、その高い解釈性と柔軟性から、さまざまな業界で意思決定支援のツールとして活用されています。
顧客セグメンテーション

引用元:メットライフ生命公式HP
マーケティング分野では、顧客の属性(年齢、地域、購買履歴など)を基にセグメント化し、ターゲット顧客を特定するために決定木が利用されています。例えば、メットライフ生命保険株式会社は、顧客セグメンテーションを活用してマーケティング戦略を最適化しています。
医療診断支援

引用元:IBMソリューションブログ
医療分野では、患者の症状や検査結果から疾患リスクを判断し、医療従事者の意思決定をサポートするために決定木が活用されています。IBMは、医療統計における決定木分析の有用性を紹介しています。
信用リスク評価

引用元:三菱総合研究所公式HP
金融業界では、申込者の情報を分析し、信用度やデフォルトリスクを評価するために決定木が用いられています。三菱総合研究所は、AIを活用したリスク管理の一環として、勾配ブースティング決定木(GBDT)を用いた信用リスク予測モデルの有効性を報告しています。
異常検知・トラブルシューティング

引用元:オムロン株式会社公式HP
製造業では、センサーデータを活用して正常・異常の状態を判別し、不具合の原因特定を支援するために決定木が利用されています。オムロン株式会社は、AIを活用した外観検査システムにおいて、Isolation Forestなどの決定木ベースのアルゴリズムを採用しています。
決定気分析に関するよくある質問(FAQ)
過学習を防ぐには?
決定木は過学習しやすいため、以下の対策が有効です。
- 剪定(Pruning)
- アンサンブル学習の活用
- 正則化(Regularization)
ccp_alpha(コスト複雑度剪定)を使って、不要な分岐を削減。
カテゴリ変数はどう扱う?
決定木は数値データが前提なので、カテゴリ変数を適切に変換する必要があります。
- One-hotエンコーディング(pd.get_dummies() で実装可能)
- ラベルエンコーディング(LabelEncoder())
- 直接入力(LightGBM, CatBoost)
欠損値への対応策は?
決定木は欠損値に比較的強いが、適切な前処理が必要です。
- 欠損値補完(fillna() で実装可能)
- 欠損を新しいカテゴリーとして扱う
- 欠損フラグを作る
まとめ
決定木は、その直感的なルール構造と柔軟性から、さまざまな分野で活用される機械学習アルゴリズムです。本記事では、決定木の仕組みやアンサンブル手法、実際の活用事例について解説しました。
決定木の魅力は、データを分岐させながら分類や予測を行うシンプルな構造にあります。専門知識がなくても理解しやすく、特徴量のスケーリングや前処理がほとんど不要なため、実用性が高いのが特徴です。ただし、過学習しやすいため、剪定やアンサンブル学習を活用することが重要になります。
実際に、マーケティングの顧客分析や、医療分野の診断支援、金融業界の信用リスク評価、製造業の異常検知など、幅広い分野で決定木は活躍しています。さらに、ランダムフォレストや勾配ブースティングと組み合わせることで、より精度の高いモデルを構築することも可能です。
AI総合研究所は企業のAI導入をサポートしています。導入の構想段階から、AI開発はもちろんのこと決定木を用いたシステム開発まで一気通貫で支援いたします。お気軽に弊社にご相談ください。
機械学習にはさまざまな手法がありますが、決定木は特に解釈性が高く、実務での意思決定にも役立つ強力なツールです。データの特性に応じた適切な活用方法を選びながら、ぜひ決定木の可能性を試してみてください。










