この記事のポイント
 FramePackの基本構造と仕組みをわかりやすく解説
FramePackの基本構造と仕組みをわかりやすく解説- 従来の動画生成AIとの違いを明確にする
- 特徴と活用例を具体的に紹介
- Google Colabでの体験方法を初心者向けに説明

Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
近年、AIによる動画生成技術が大きな進化を遂げています。その中でも、2025年に登場した「FramePack(フレームパック)」は、多くの開発者やクリエイターの注目を集めています。
従来の動画生成AIは、高性能なGPUや大量のVRAMを必要とするため、一般ユーザーが気軽に扱うのは困難でした。
しかしFramePackは、一般的なノートPCの6GB GPUメモリでも、長尺の高品質動画を生成できるという特長を持ち、「軽量かつ高精度」なAIモデルとして一線を画しています。
目次
FramePackとは?|軽いPCやColabでも高品質なAI動画が作れる注目モデル
Google ColabでFramePackを実際に動かしてみる
FramePackとは?|軽いPCやColabでも高品質なAI動画が作れる注目モデル
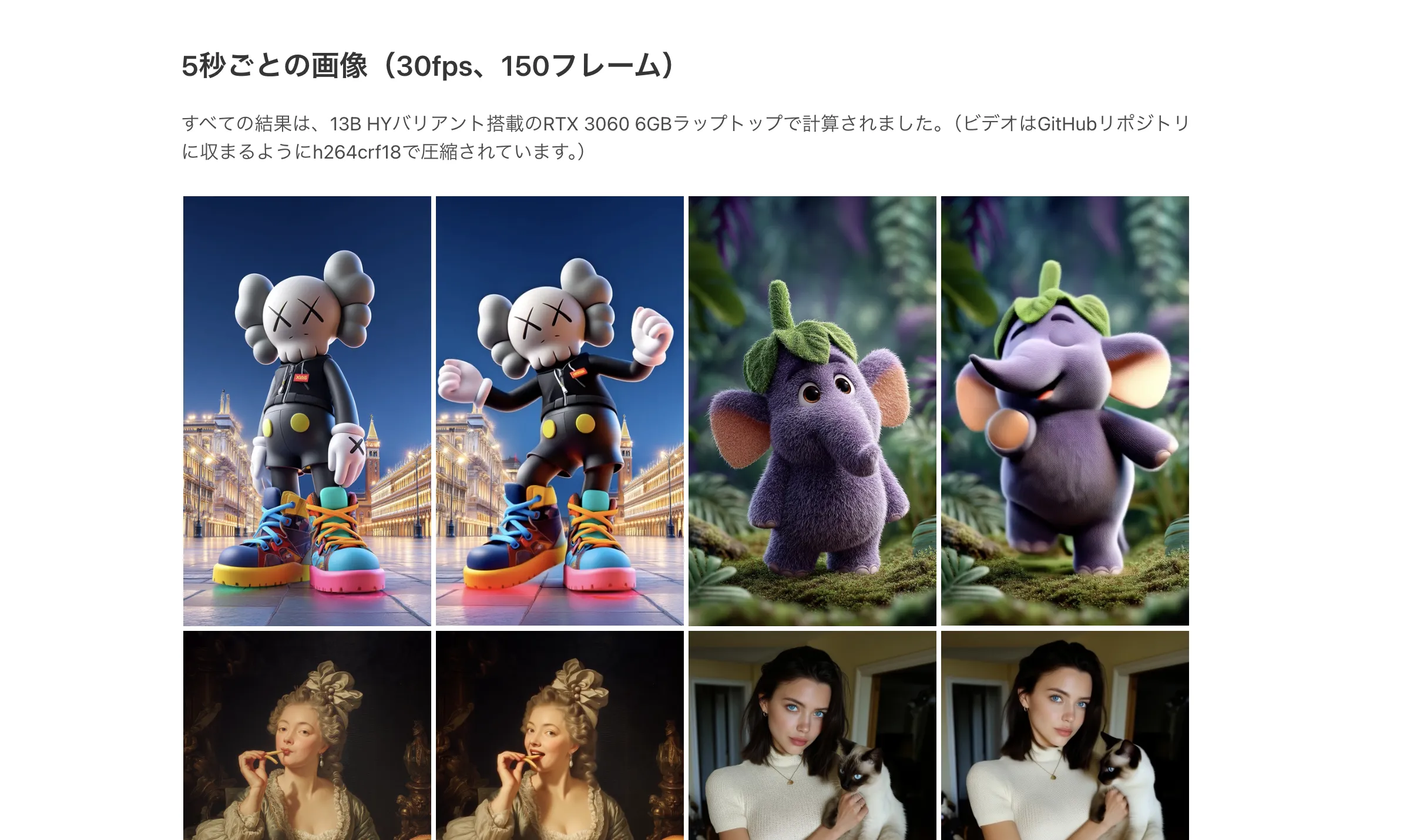
FramePackプロジェクトページ(参考)
FramePackとは、1枚の画像とテキストから高品質な長尺動画を生成できる、軽量・高効率な次世代AI動画生成モデルです。
従来のAI動画生成モデルは、GPUの性能やVRAMの容量に依存するため、一般ユーザーが気軽に扱うのは難しいものでした。
「画像1枚とテキストを入れるだけで、AIが動画を作ってくれる」そんな夢のような仕組みを、一般的なノートPCやGoogle Colabでも実現します。
たとえば:
- イラストからアニメのような動きを作りたい
- 商品写真とキャッチコピーからSNS広告用の動画を自動生成したい
- デバイスのスペックが高くなくても高精度な動画生成を試したい
こういったニーズに対して、FramePackは非常に強力な選択肢となります。
特に注目されているポイントは次の3点です:
| 特徴 | 内容 |
|---|---|
| ✅ 軽量 | VRAM 6GB程度でも動作可能(ColabでもOK) |
| ✅ 長尺対応 | 数千フレームの動画でも破綻しにくい設計 |
| ✅ 高品質 | 最新の双方向フレーム予測技術で映像がなめらか |
では、なぜこんなことができるのか?
ここからはFramePackの仕組みや開発背景について、もう少し詳しく解説していきます。
開発者と技術的背景
FramePackは、スタンフォード大学のLvmin Zhang氏とManeesh Agrawala教授によって開発されました。2025年4月に発表された研究成果であり、GitHub上でもコードが公開されています。
開発の目的は、「軽量かつ安定した動画生成を、誰もが扱える形にすること」です。
従来のAI動画生成モデルは、生成対象のフレーム数が多くなるほど負荷も増え、映像の品質が劣化する傾向にありました。FramePackはこの問題を、**“次に来るフレームを予測する”というアプローチ(Next-Frame Prediction)**と、圧縮されたコンテキスト管理により解決しています。
FramePackの特徴
次に、FramePackの主な技術的特徴を具体的に見ていきましょう。
FramePackの基本的な動作は以下の通りです:
- 静止画像(1枚)と、**どんな動画にしたいかの説明文(テキスト)**を入力
- AIが、次に来るフレームを1枚ずつ予測して生成
- それらを連結して自然な動画として出力
このような仕組みのため、動画の「続き」を非常に自然につなぐことができます。
しかも、必要な情報だけをコンパクトに保持しながら計算する設計となっており、長尺の動画でも速度・品質ともに安定しているのが特徴です。
詳細を見ていきましょう。
1. 軽量な計算で長尺動画が生成できる
最大の魅力は「6GB程度のGPUでも、長尺かつ高品質な動画が作れる」という点です。一般的なノートPCやGoogle Colabの無料プランでも、最大1800フレーム(約1分間)の動画を生成することができます。
これは、コンテキストを圧縮・再構成するという新しいアーキテクチャによって、フレームが多くなってもメモリ消費量を一定に保てることに起因しています。
2. ドリフト(劣化)を防ぐ仕組み
動画生成においては、「フレームが進むにつれて内容がぼやけてくる(ドリフト)」という問題がよく発生します。
FramePackでは、双方向(bidirectional)コンテキストを活用して前後のつながりを強く保つため、時間が進んでも映像品質が崩れにくくなっています。
3. 生成の進捗をリアルタイムで確認できる
生成はフレームごとに行われるため、リアルタイムに動画の進行をプレビューすることが可能です。これにより、「最後まで生成してみたら思っていた動画と違った」という無駄なリソースの消費を防ぐことができます。
また、生成されたフレームを途中で差し替えたり、調整したりすることも可能です。
FramePackの持つこれらの特徴は、単なる研究用途にとどまらず、一般ユーザーが日常的に使えるAI動画ツールとしての可能性を広げています。
Google ColabでFramePackを実際に動かしてみる
FramePackの魅力は、無料のGoogle Colab上でも動作可能な点にもあります。
以下では、実際にColabでFramePackを動かす手順を、初心者でも迷わず進められるようステップ形式で紹介します。
Step 1:ColabのランタイムをGPUに切り替える
まず、Google Colabにアクセスし、上部メニューから次のように設定してください:
- メニュー「ランタイム」→「ランタイムのタイプを変更」
- 「ハードウェア アクセラレータ」で「GPU」を選択(流石に足りない時は追加で購入をお勧めします)
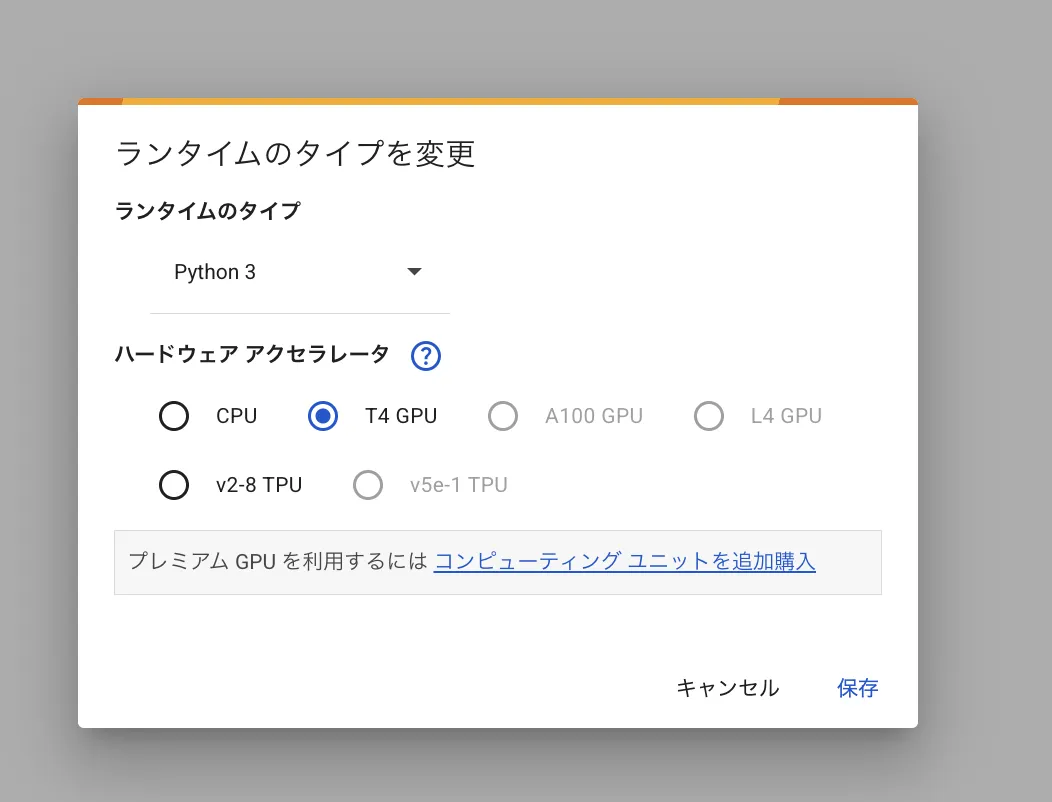
ランタイムタイプの変更
✅ Step 2:FramePackのインストール
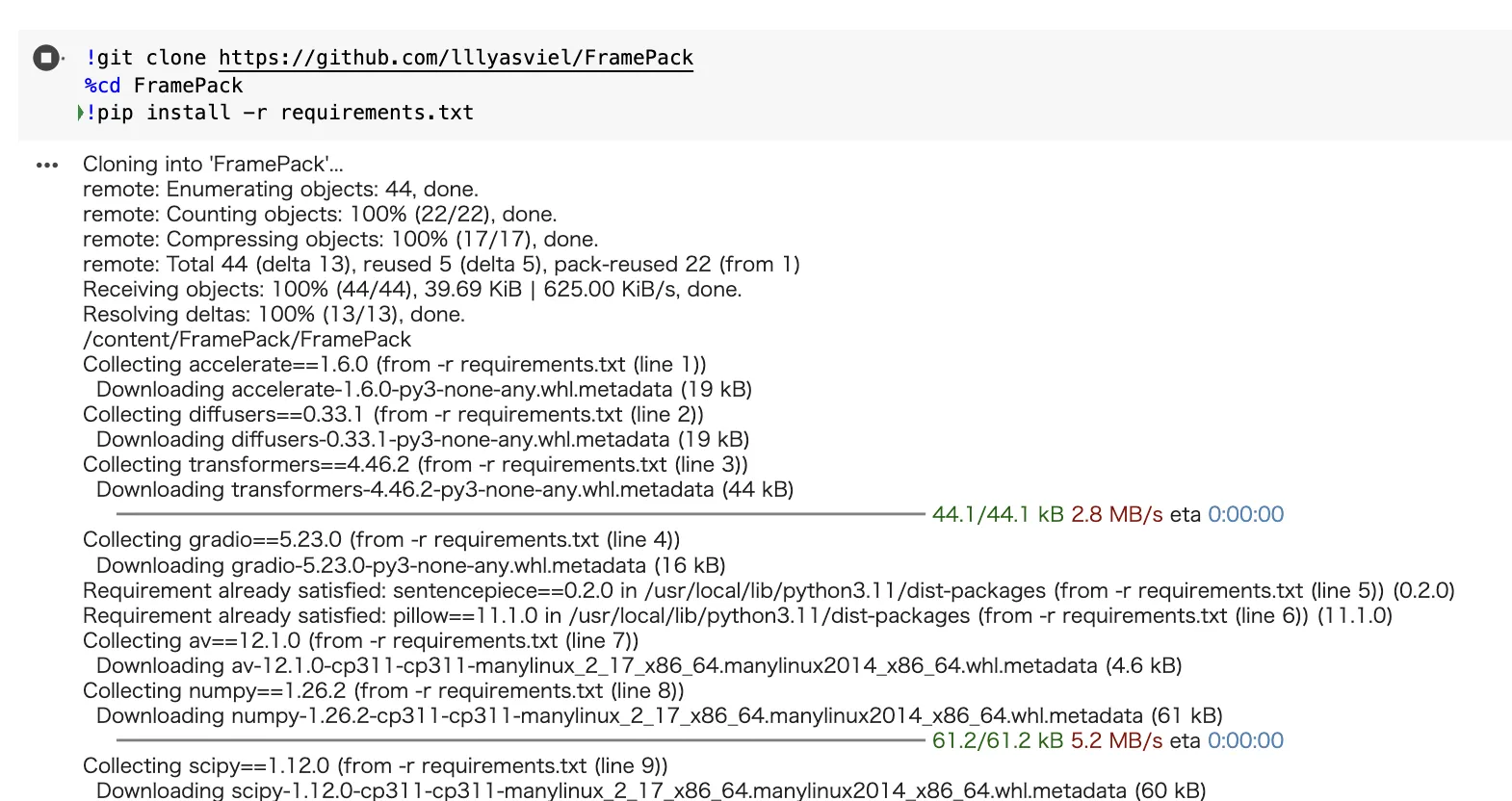
実行中画面
以下のコードをセルに貼り付けて、実行してください。
!git clone https://github.com/lllyasviel/FramePack
%cd FramePack
!pip install -r requirements.txt
これで、FramePackの本体と必要なライブラリが揃います。
✅ Step 3:Gradioアプリを起動
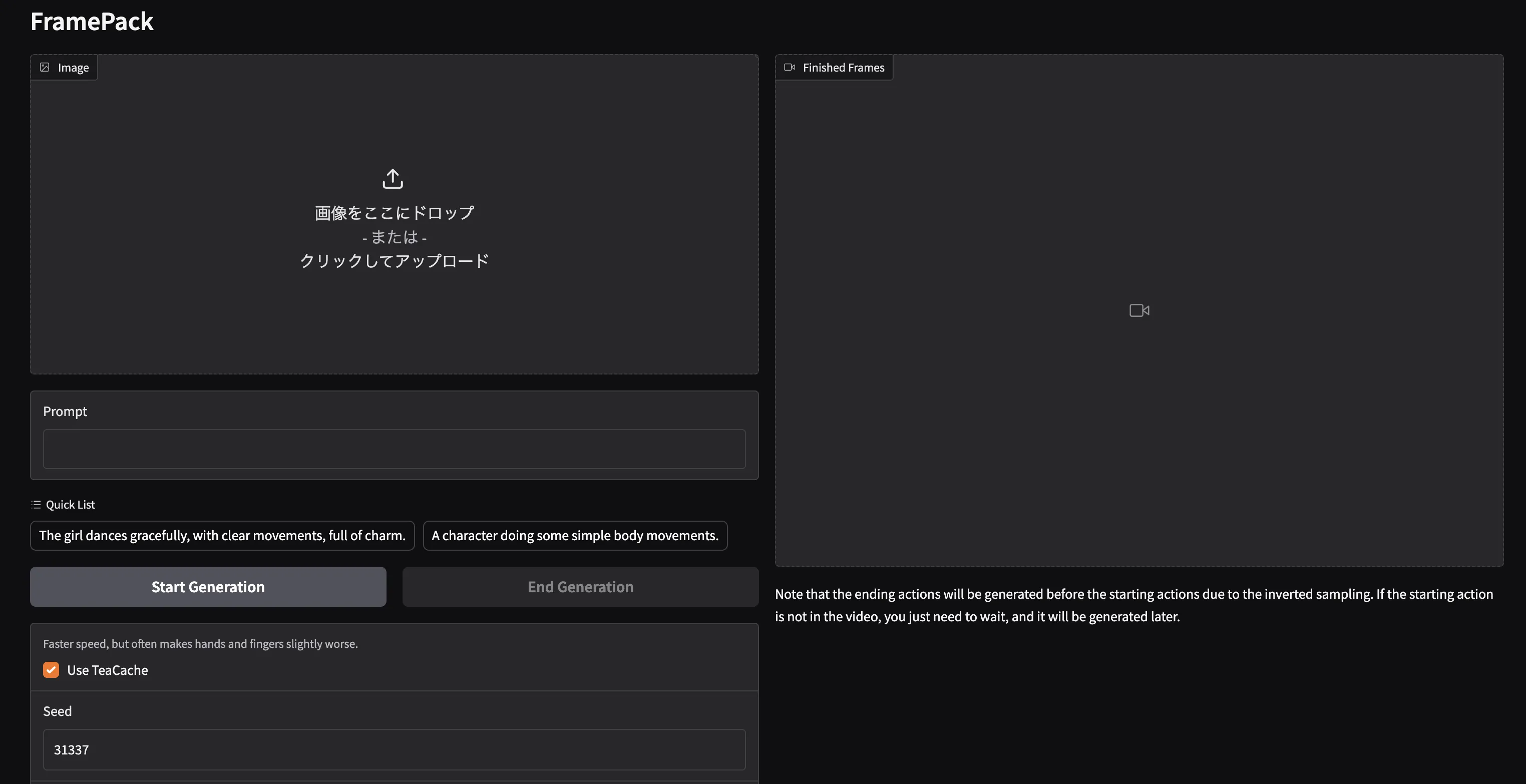
アプリの起動画面
次に、下記コマンドでGradioベースのユーザーインターフェース(UI) を立ち上げます。
!python demo_gradio.py --share
実行すると、数十秒後に「Running on public URL: https://xxxx.gradio.live」というリンクが表示されます。これがあなた専用のUIです。
✅ Step 4:画像とテキストを入力して動画生成
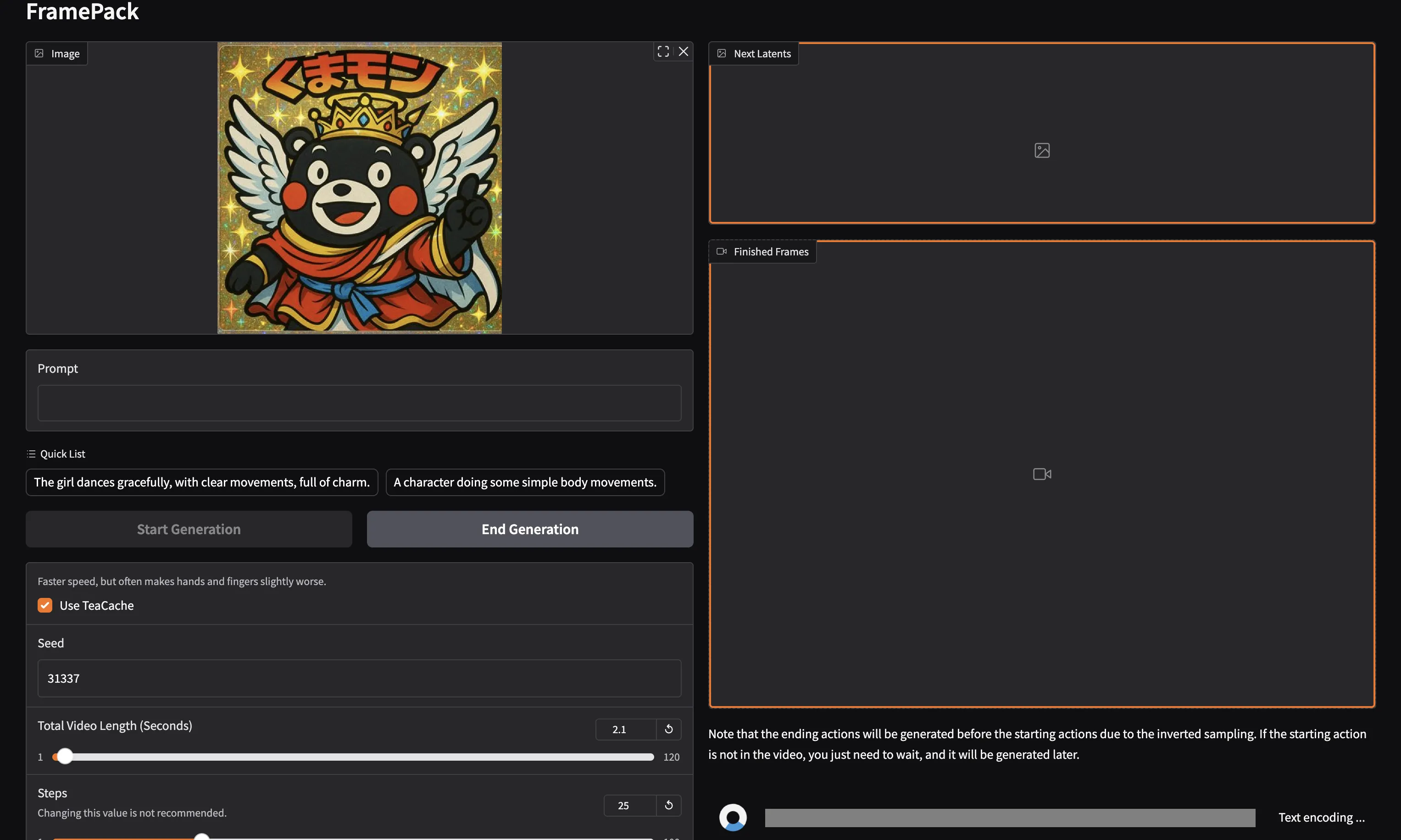
アップロード画面
Gradioの画面では、次のように操作します。
- 「Image」欄に画像(例:アニメキャラ、風景など)をアップロード
- 「Prompt」欄に生成したい動画の内容をテキストで入力
- 例:「A bear jumping into a box in anime style」
- 「Start Generation」ボタンをクリック
- 数十秒後、下に生成された動画が表示されます!
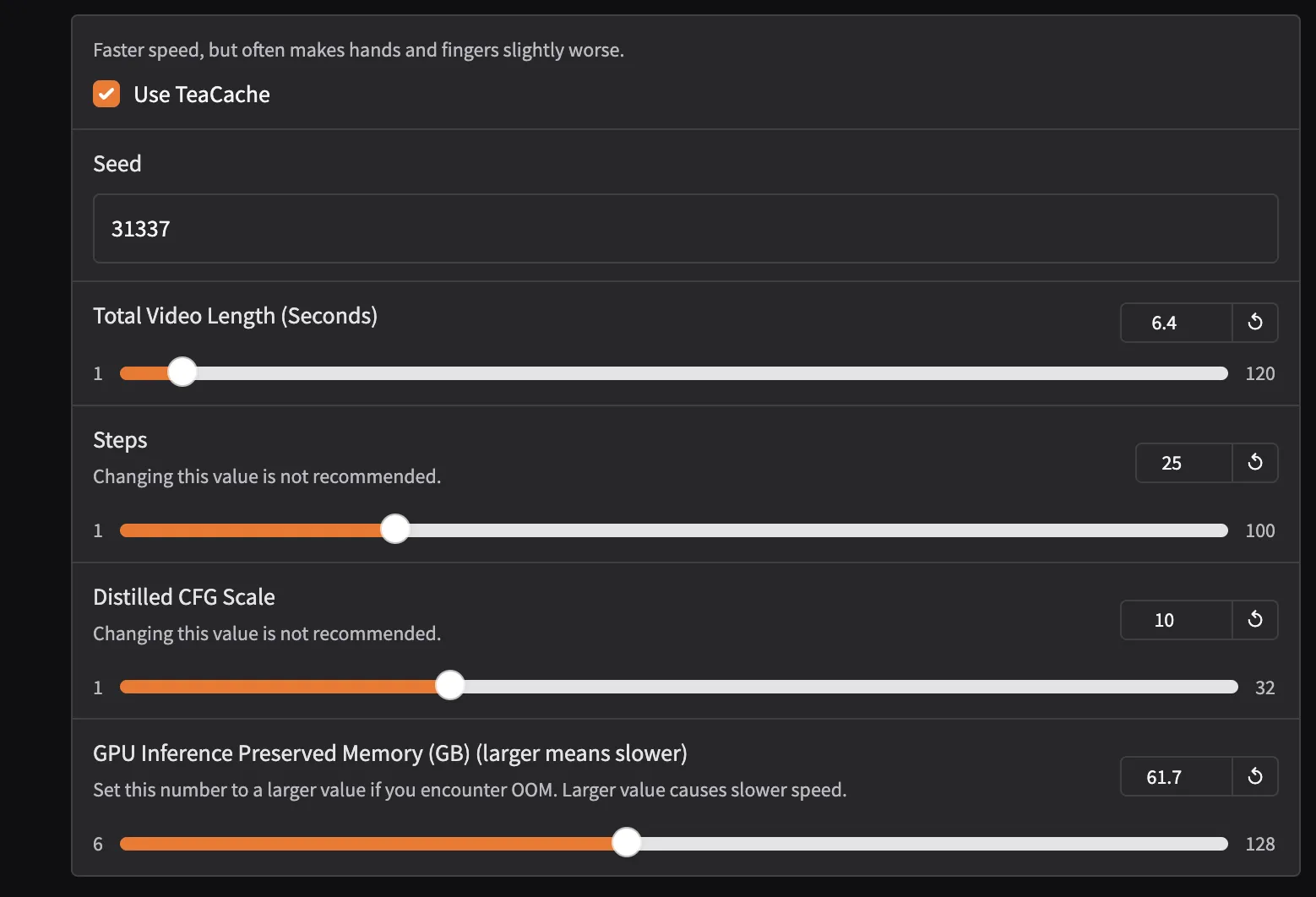
設定画面
| 項目名 | 説明 | 推奨値 / 注意点 |
|---|---|---|
| TeaCacheを使用する | 推論の高速化に使うオプション。ONにすると、手や指などの細部品質が若干落ちる可能性があります。 | ✅ デフォルトONでOK(高速化重視) |
| シード(Seed) | 生成のランダム性を制御するための数値。毎回同じ動画を再現したい場合に固定すると便利。 | 任意の整数(例:31337) |
| 動画の合計時間(秒) | 生成される動画の長さ。秒数が長いほどフレーム数が増え、時間もメモリも多く必要。 | 通常は 3〜10秒程度が現実的(Colabなら最大15秒程度) |
| 手順(Steps) | AIが生成を繰り返す回数。多いほど品質が上がるが、時間もかかる。 | 20〜30前後が一般的。調整非推奨と明記あり |
| 蒸留CFGスケール(CFG Scale) | プロンプト(テキスト)の影響度をどれだけ強く反映させるか。高すぎると不自然になる。 | デフォルトの10がバランス良好(変更は非推奨) |
| GPU推論保存メモリ(GB) | 推論中にどれだけGPUメモリを使うか。数値を上げるとメモリ使用量が増えるがOOM(メモリ不足)に強くなる。 | 無料Colabなら6〜8GB推奨。RTX 4090では16GB以上もOK |
手順とCFGスケールは「この値を変更することはお勧めしません」と記載されているため、基本はそのままで使いましょう。動画の長さや推論メモリは自分の環境や目的に応じて調整してもOKです。
ぜひ試してみてください!
よくあるエラーと解決法
FramePackを使っていると、いくつかのエラーや問題に直面することがあります。以下は、よくあるエラーとその解決法です。
| 問題 | 解決法 |
|---|---|
| モデルが読み込めない | URLやファイルパスが間違っていないか確認 |
| VRAM不足エラーが出る | フレーム数や解像度を小さくして試す |
| 生成が途中で止まる | Colabのセッションが切れた可能性。再起動して再実行 |
| 生成に時間がかかりすぎる | Colab Proへのアップグレード or ローカル実行を検討 |
技術的背景:なんでこんなに軽いの?わかりやすく解説
FramePackのコアとなる技術は、「次のフレームをどう予測するか」と、「どうやって品質を落とさずに長い動画を作るか」です。以下の2つの仕組みがポイントです:
① 次のフレームを効率よく予測する仕組み(FramePack Scheduling)
動画生成AIでは、何十枚ものフレームを元に「次に来るフレーム」を予測して作ります。でも、すべてのフレームを同じように処理すると、GPUメモリを大量に消費して非効率です。
FramePackの工夫
FramePackでは、以下のような優先度のある処理を行います:
| フレームの役割 | どう処理するか | なぜ? |
|---|---|---|
| 最新フレーム(F0) | 一番丁寧に(多くの情報で)処理 | 次に出すフレームに最も関係が深いから |
| 古いフレーム | 少ない情報で圧縮して処理 | あまり影響が少ないから |
これを GPU上のメモリ配置(メモリレイアウト) として整理し、重要なフレームに多くの計算資源を割り当てることで、GPUを賢く使えるようにしています。
.webp)
GPU上のメモリ配置(メモリレイアウト)イメージ(参考)
さらに、画像サイズや圧縮度合いもパターンで調整可能なので、たとえば:
- 最初のフレームを「特に重要」にする(画像→動画のときに便利)
- 全フレームを均等に扱う(全体が滑らかになる)
といったスケジューリングのカスタマイズも可能です。
② ドリフトを防ぐ「アンチドリフトサンプリング」
ドリフトとは、通常の動画生成では、「前のフレーム」を元に「次のフレーム」を作るので、間違いがどんどん蓄積されていき、最初は綺麗でも後半になるほど映像が崩れてくる(=ドリフト) という現象がよく起きます。
FramePackはこの問題を解決するために、一方向だけでなく前後のフレームを参照して生成する「双方向サンプリング」を採用しています。
代表的な3つの方式:
| サンプリング方式 | 特徴 | 向いている用途 |
|---|---|---|
| Vanilla(従来) | 一方向だけ(因果関係あり) | 精度は低いが軽い |
| Anti-Drift | 双方向を参照して生成 | 長い動画の安定性が高い |
| Reverse Anti-Drift | 常に最初のフレームを基準にする | 画像→動画変換に最適! |
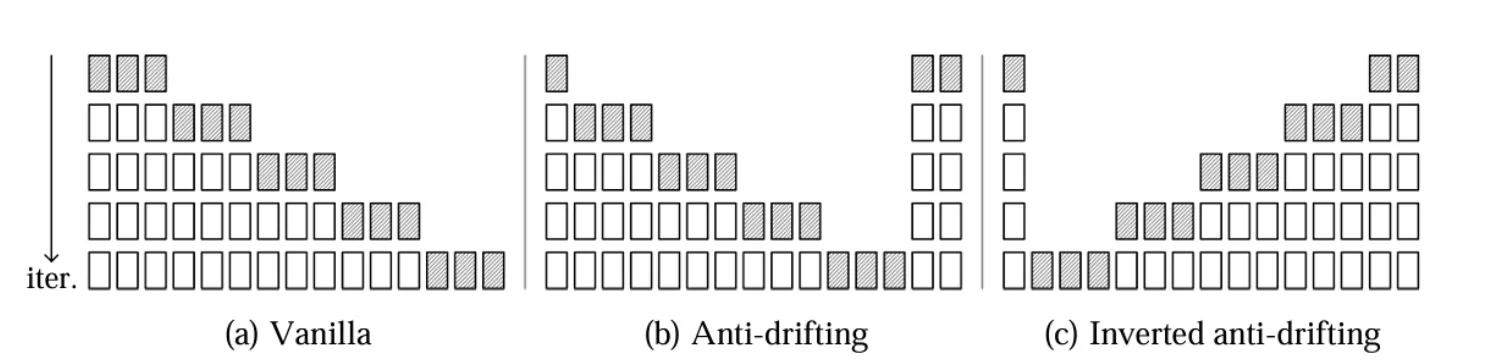
サンプリング方式(参考)
ポイント:
初期フレームとの一貫性を保ち続けることで、「最初と印象が違う動画になってしまう」問題を根本から解決しています。
FramePackの活用シーン
FramePackはその軽量性と高い柔軟性から、さまざまな用途での活用が期待されています。以下は、特に注目されているユースケースです。
1. 動画広告やSNS投稿の自動生成
企業やクリエイターがSNS向けの短尺動画を量産するニーズに、FramePackは非常に適しています。
静止画とプロンプト(例:「春のセールを知らせる元気な雰囲気の映像」)を与えるだけで、AIが数秒~数十秒の動画を生成してくれます。
- Instagram Reels
- TikTokショート
- YouTube Shorts などに最適。
2. アニメーションの草案・プロトタイプ生成
手描きアニメーションや3DCGの事前ビジュアルとして、AIによる「動きの草案」を作成する用途でも注目されています。
FramePackは、動きの整合性を保ちながらシーンを構築できるため、アニメーターや映像ディレクターが初期段階で方向性を掴むのに役立ちます。
3. 研究・教育用途
AIモデルや物理シミュレーションのビジュアル化にもFramePackは使われ始めています。
複雑な現象の視覚化を自動で生成することで、研究成果の伝達や教育資料としての活用が広がっています。
まとめ|軽量×高品質の動画生成はここまで進化した
FramePackは、「重い・高性能なGPUがないと動画生成は無理」という従来の常識を覆す革新的なモデルです。
特にGoogle Colabでも動く手軽さは、これからAI動画制作を試してみたい初心者にとっても大きな魅力と言えるでしょう。
本記事で紹介した手順をもとに、ぜひご自身でもFramePackの性能を体感してみてください。










