この記事のポイント
 Tensorコアは、NVIDIA GPUに搭載され、AI計算(特に行列演算)を高速化する専用ユニット
Tensorコアは、NVIDIA GPUに搭載され、AI計算(特に行列演算)を高速化する専用ユニット- 汎用的なCUDAコアと異なり、混合精度計算などでAI学習・推論に特化した性能を発揮
- AIモデルの学習時間短縮やリアルタイム推論、省電力化を実現しAI発展を支える
- VoltaからBlackwellまで世代ごとに進化し、対応精度や機能、性能が向上
- AI開発、HPC、データ分析、ゲーム(DLSS)など幅広い分野で活用されている

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AIやディープラーニングの話題でよく耳にする「Tensorコア」。「なんとなくAI計算を速くするもの?」というイメージはあっても、具体的に何がすごいのか、従来のGPUコアとどう違うのか、正確に理解している人は少ないかもしれません。
しかし、Tensorコアは現代のAI技術を支える非常に重要な要素であり、その進化がAIの可能性を大きく広げています。
本記事では、この「Tensorコア」について、基礎から応用までを徹底的に解説します。
Tensorコアの基本的な仕組み、CUDAコアとの違い、世代ごとの進化、そしてAI分野からゲーム、HPCまで広がる活用事例を詳しく説明します。
目次
Tensorコアが注目される理由:AI・ディープラーニングとの関係
【第5世代】Blackwellアーキテクチャ (2024年)
ディープラーニングフレームワークでの利用(TensorFlow, PyTorch)
Tensorコアとは?
Tensorコアとは、NVIDIA GPUに搭載されている、AI計算などの特定の演算を高速化するための専用計算ユニットです。
現代のAI、特にディープラーニングでは膨大な量の計算が必要となりますが、Tensorコアはその計算負荷を劇的に軽減し、処理速度を向上させるために開発されました。
これにより、AIモデルの開発期間短縮や、より高度なAIアプリケーションの実現が可能になっています。AI技術が進化し続ける現代において、Tensorコアはそれを支えるハードウェア基盤として非常に重要な役割を担っています。
Tensorコアの基本的な役割と仕組み
Tensorコアの核心は、「特定の計算(行列演算)を超高速に実行する」 ことにあります。
AIやディープラーニングの処理では、コンピュータ内部で膨大な量の「行列」を使った計算が行われます。
Tensorコアは、この行列計算に特化した専門家のような存在で、汎用的な計算ユニット(CUDAコア)よりも遥かに効率よく、スピーディーに処理をこなします。
具体的には、例えば4x4の行列同士を掛け合わせ、その結果を別の4x4行列に足し合わせる、といった一連の計算(積和演算)を、わずか1クロックサイクルという驚異的な速さで完了させることができます。
これは、従来の計算ユニットでは何ステップも必要だった処理であり、Tensorコアがいかに特定の作業に最適化されているかを示しています。
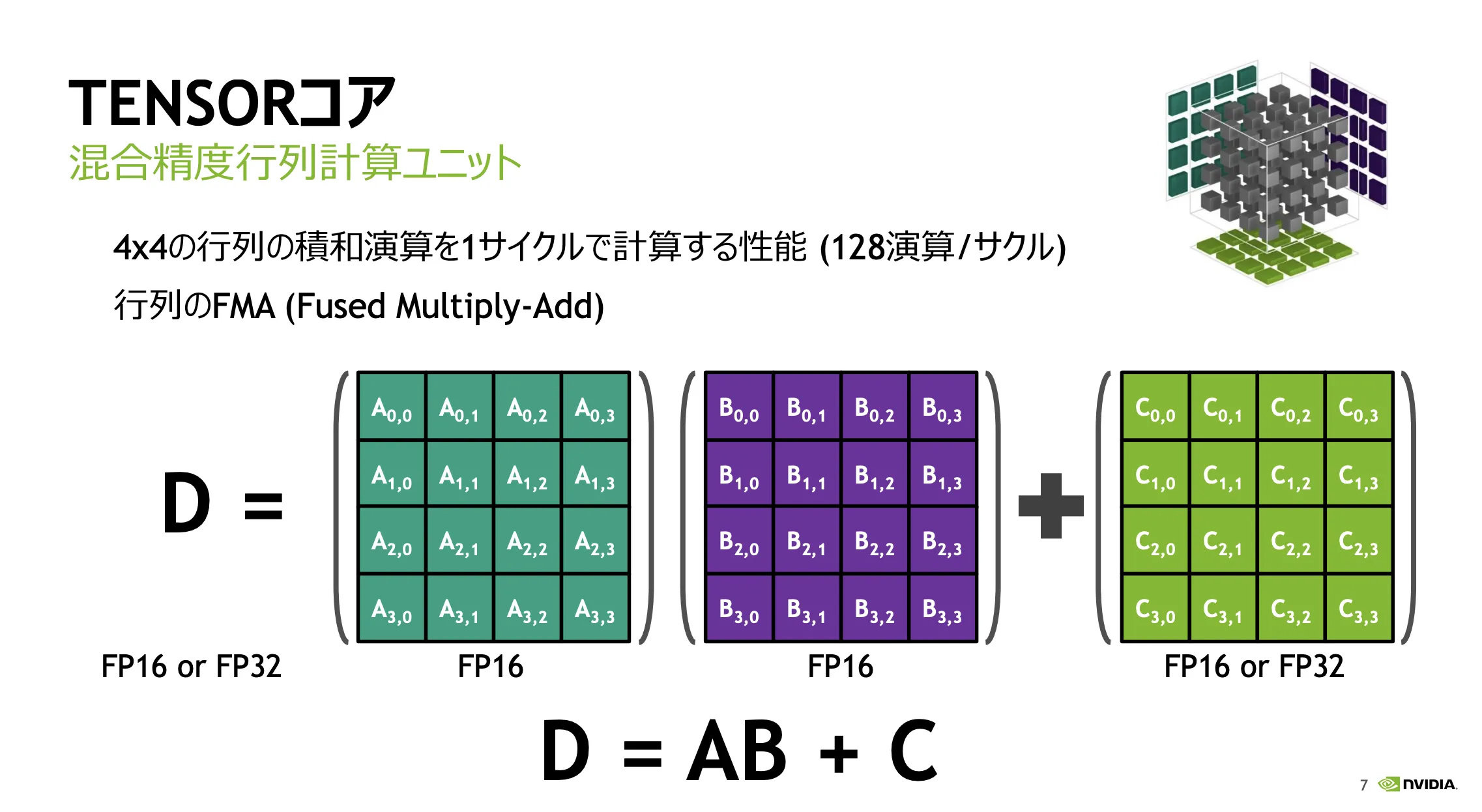
Tensorコアの仕組み (出典:CUDA 9 AND MORE」NVIDIA社、GTC Japan 2017講演資料]
従来のGPUコア(CUDAコア)との違い
NVIDIA GPUには、Tensorコアの他に「CUDAコア(クーダコア)」という汎用的な計算ユニットが多数搭載されています。最も大きな違いは、得意とする処理の種類です。
- CUDAコア
- 比較的単純な演算(整数演算や単精度浮動小数点演算など)を、多数並列に実行することに長けています。
- 3Dグラフィックスの描画処理や、物理シミュレーション、一般的な科学技術計算など、幅広い並列コンピューティングタスクに対応できる汎用性が特徴です。
- Tensorコア
- 前述の通り、AI計算で多用される行列の積和演算(特に混合精度)に特化しています。
- 特定の演算においては、CUDAコアよりも桁違いに高いスループット(処理能力)を発揮します。しかし、CUDAコアほど汎用的な計算は得意ではありません。
例えるなら、CUDAコアは「どんな道具もそこそこ使える器用な職人集団」、Tensorコアは「特定の工具(行列演算)を専門に、超高速で使いこなす熟練工」のようなイメージです。
近年のNVIDIA GPUは、これら両方のコアを搭載することで、グラフィックス処理からAI計算まで、幅広いワークロードに対応できるようになっています。
Tensorコアが注目される理由:AI・ディープラーニングとの関係
Tensorコアがこれほど注目される最大の理由は、AIおよびディープラーニングの爆発的な発展と普及にあります。
現代のAIモデル、特にディープニューラルネットワーク(DNN)は、その学習(トレーニング)と推論(インファレンス)の過程で、膨大な量の行列演算を必要とします。
- 学習(Training):
AIモデルが大量のデータからパターンや特徴を学習するプロセス。パラメータの更新に繰り返し行列演算が使われ、計算負荷が非常に高い。
- 推論(Inference):
学習済みモデルを使って、新しいデータに対して予測や分類を行うプロセス。リアルタイム性が求められる場合が多く、効率的な計算が必要。
Tensorコアは、これらの計算を劇的に高速化することで、以下のようなメリットをもたらしました。
- 学習時間の短縮: これまで数週間かかっていたような大規模モデルの学習が、数日や数時間で完了可能に。研究開発のサイクルが加速しました。
- より複雑なモデルの実現: 計算能力の向上により、より大きく、より高性能なAIモデルの開発が可能になりました。
- リアルタイム推論の実現: 自動運転、リアルタイム翻訳、AIアシスタントなど、高速な応答が求められるアプリケーションでのAI活用が進みました。
このように、Tensorコアは現代AI技術の根幹を支えるハードウェア基盤として不可欠な存在となっており、その性能向上がAIの進化を直接的に牽引していると言っても過言ではありません。
Tensorコア搭載のNVIDIA GPU世代別一覧
Tensorコアは、NVIDIAの特定のGPUアーキテクチャから導入され、世代を経るごとに進化してきました。このセクションでは、どの世代のGPUにTensorコアが搭載されているのか、その変遷を辿ります。
| アーキテクチャ | Tensorコア世代 | 主な搭載GPU (例) | 主な特徴 |
|---|---|---|---|
| Volta (2017) | 第1世代 | Tesla V100 | Tensorコア初搭載、FP16演算を高速化 |
| Turing (2018) | 第2世代 | GeForce RTX 20シリーズ, Quadro RTX, T4 | INT8, INT4演算対応、推論性能向上、RTコア搭載 |
| Ampere (2020) | 第3世代 | GeForce RTX 30シリーズ, A100, A30 | TF32対応、構造的スパース性対応、性能大幅向上 |
| Hopper (2022) | 第4世代 | H100, H200 | FP8対応、Transformer Engine搭載、さらに高性能化 |
| Blackwell(2024) | 第5世代 | B100, B200, GB200, GeForce RTX 50シリーズ(予定) | 第2世代Transformer Engine, FP4/FP6対応、性能・効率向上 |
【第1世代】Voltaアーキテクチャ (2017年)
Tensorコアが初めて搭載されたのが、2017年に発表されたVolta(ヴォルタ)アーキテクチャです。主にデータセンター向けのハイエンドGPU「Tesla V100」に実装されました。
Volta世代のTensorコアは、**FP16(半精度浮動小数点数)**の行列演算を高速化することに主眼が置かれていました。
これにより、ディープラーニングの学習において、従来のFP32演算と比較して大幅な性能向上(最大12倍のTFLOPS)を実現し、AI研究開発の現場に衝撃を与えました。
このVoltaアーキテクチャとTensorコアの登場が、GPUをAI計算の主要なプラットフォームとして確立させる大きな転機となりました。
【第2世代】Turingアーキテクチャ (2018年)
翌2018年に登場したTuring(チューリング)アーキテクチャでは、Tensorコアは第2世代へと進化しました。
Turing世代のTensorコアは、データセンター向けGPU(Tesla T4など)だけでなく、一般消費者向けのGeForce RTX 20シリーズやプロフェッショナル向けのQuadro RTXシリーズにも搭載された点が大きな特徴です。
第2世代Tensorコアは、FP16に加えて、INT8(8ビット整数)やINT4(4ビット整数)といった、さらに低精度の演算にも対応しました。これにより、特にAIの推論(Inference)処理の性能と効率が大幅に向上しました。
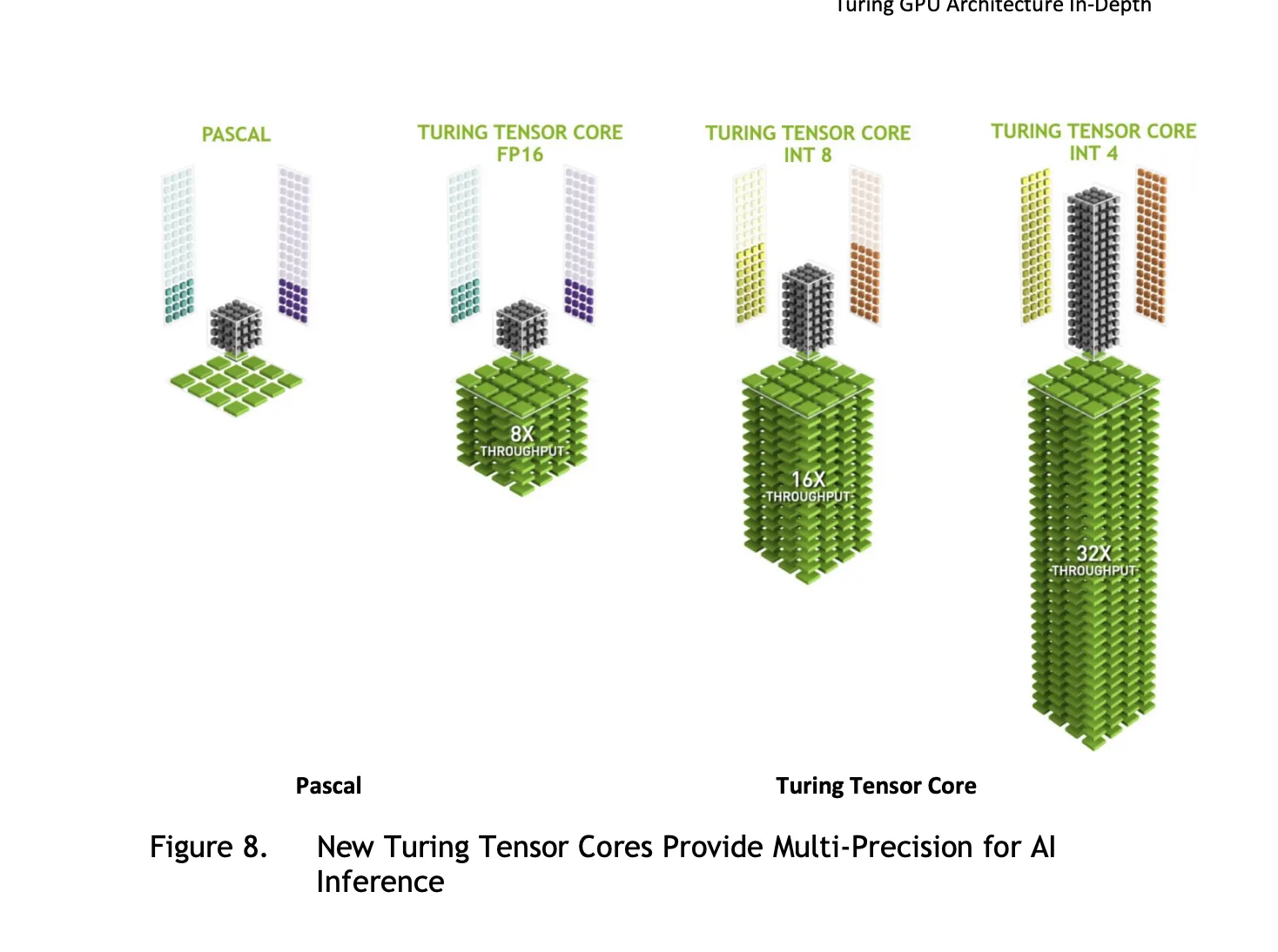
Turing世代のTensorコアは、計算の細かさ(精度)をFP16、INT8、INT4と使い分け可能に。特にINT8/INT4のような粗い(=速い)計算で、AIの推論(判断など)を大幅にスピードアップさせます (出典: NVIDIA)
また、Turingアーキテクチャでは、リアルタイムレイトレーシングを実現する「RTコア」も初めて搭載され、TensorコアはAIを活用した高画質化技術「DLSS (Deep Learning Super Sampling)」の実現にも貢献しました。
【第3世代】Ampereアーキテクチャ (2020年)
2020年発表のAmpere(アンペア)アーキテクチャでは、第3世代Tensorコアが搭載され、性能が飛躍的に向上しました。GeForce RTX 30シリーズや、データセンター向けGPUの「A100」などがこの世代にあたります。
第3世代Tensorコアの大きな特徴は以下の通りです。
- TF32 (TensorFloat-32) のサポート:
FP32の範囲(ダイナミックレンジ)を持ちながら、FP16の精度(仮数部のビット数)で計算する新しいデータフォーマットに対応。コード変更なしでFP32比最大20倍の高速化を実現します。
- BF16 (BFloat16) のサポート:
FP32とほぼ同じ範囲をカバーしつつ、FP16より計算が安定しやすいとされるフォーマットにも対応。
- 構造的スパース性 (Structural Sparsity) の活用:
ニューラルネットワーク内の重要でない接続(重みがゼロに近い)を無視して計算をスキップすることで、実効性能をさらに最大2倍に高める機能が追加されました。
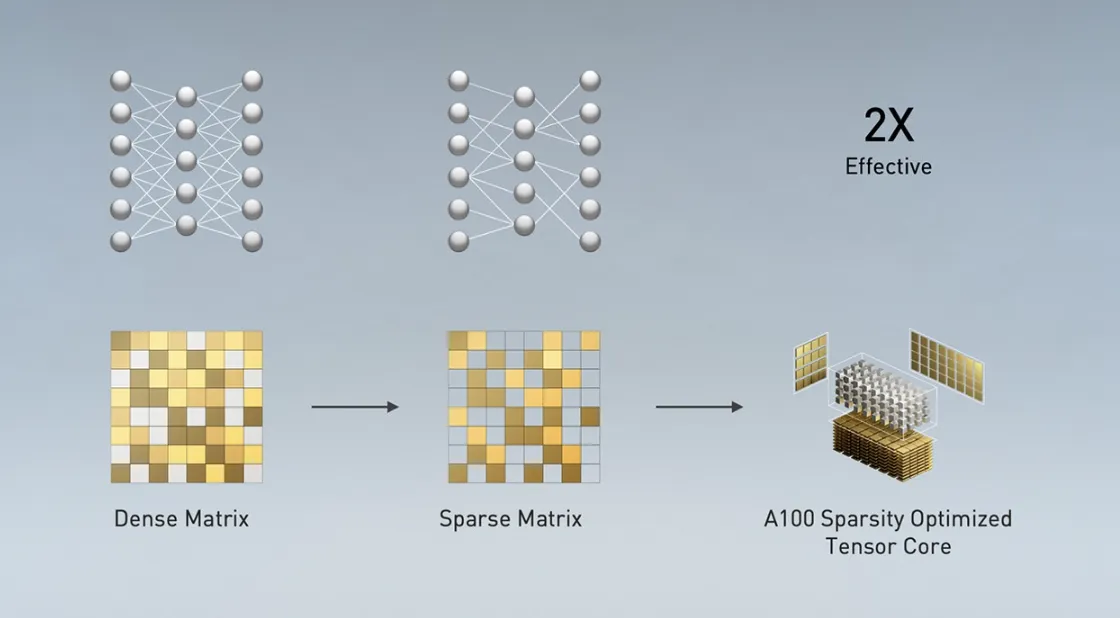
- Ampereアーキテクチャ(例: A100 GPU)のTensorコアにおけるスパース性活用の概念図 (出典:NVIDIA)
これらの強化により、Ampere世代のTensorコアは、AIの学習と推論の両方で、Turing世代から大幅な性能向上を果たしました。
【第4世代】Hopperアーキテクチャ (2022年)
データセンター向けに特化して2022年に発表されたHopper(ホッパー)アーキテクチャ(搭載GPU: H100, H200など)は、第4世代Tensorコアを搭載し、AI計算能力を新たなレベルに引き上げました。
Hopper世代の主な特徴は以下の通りです。
-
FP8 (8ビット浮動小数点数) のサポート:
FP16よりもさらにデータサイズが小さく高速なFP8フォーマットに対応。精度を維持しながら、学習・推論速度をさらに向上させます。
-
Transformer Engine:
近年主流となっているTransformerモデル(ChatGPTなどの大規模言語モデルの基礎技術)の計算を最適化する専用エンジンを搭載。FP8とFP16を動的に切り替えることで、性能と精度を両立します。
Hopper世代の「Transformer Engine」のイメージ図。速度重視の場面では高速なFP8を、精度が必要な場面ではFP16を使い分け、効率よく計算を進めます (出典:NVIDIA)
Hopperアーキテクチャは、特に大規模言語モデル(LLM)や推薦システムといった、巨大なAIモデルのトレーニングと推論をターゲットとしており、前世代のAmpereと比較しても大幅な性能向上を実現しています。
【第5世代】Blackwellアーキテクチャ (2024年)
そして2024年3月に発表され、2025年1月から一般消費者向け製品の発売が開始された最新アーキテクチャが**Blackwell(ブラックウェル)**です。
データセンター向けのB100, B200, GB200といったGPUに加え、GeForce RTX 50シリーズ(RTX 5090, 5080, 5070 Ti, 5070など) がこのアーキテクチャを採用しています。
Blackwellアーキテクチャにおける第5世代Tensorコアは、以下のような更なる進化を遂げています。
-
第2世代Transformer Engine
Hopperから進化したTransformer Engineにより、FP4やFP6といった、さらに低ビットの浮動小数点演算をサポート。
モデルサイズと計算精度に応じて最適なデータフォーマットを適用し、推論性能、学習速度、モデルサイズのスケーラビリティを向上させます。
-
性能と効率の向上
より微細化された製造プロセスやアーキテクチャの改良により、Hopper世代と比較してもAI性能(FLOPS)と電力効率が大幅に向上しています。
-
FP4/FP6 超低精度フォーマットのサポート
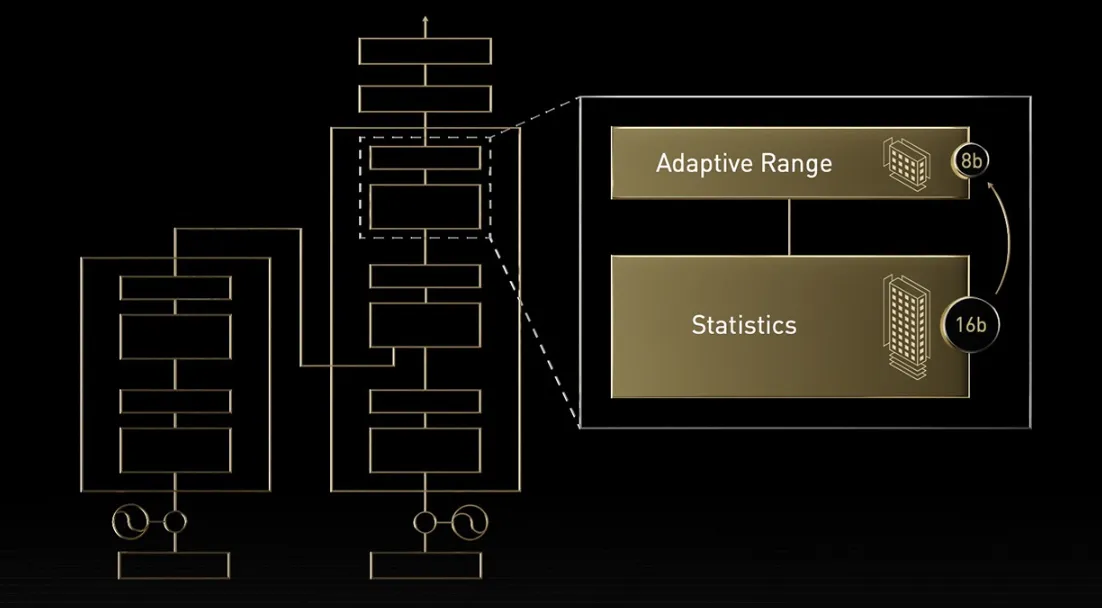
新たな数値表現方式「マイクロスケール(Microscaling)」を採用することで、わずか4ビットや6ビットで数値を表現するFP4/FP6演算に対応しました。
これにより、メモリ使用量と計算量を劇的に削減しつつ、AIモデルの精度を維持することが可能になります。
%E6%8A%80%E8%A1%93.webp)
Blackwellが採用する「マイクロスケール」技術の概念図。共通の基準値(Shared Scale)を使うことで、FP4/FP6のような超低ビットでも数値の精度を保ち、効率的な計算を実現 (出典:NVIDIA)*
Blackwellアーキテクチャは、兆パラメータ級の超巨大AIモデルの学習や推論を効率的に行うことを可能にし、生成AIをはじめとする次世代AIアプリケーションの発展を加速させることが期待されています。
Tensorコアの性能を比較:世代や設定による違い
Tensorコアの性能は、GPUの世代や、使用する演算精度によって大きく異なります。このセクションでは、ベンチマーク結果などを参考に、その性能差を見ていきましょう。
ベンチマークで見るTensorコアの処理能力
Tensorコアの性能は、一般的に**FLOPS(浮動小数点演算性能)**という指標で表されます。特に、AI計算で重要なFP16、TF32、FP8といった精度でのFLOPS値が注目されます。
例えば、NVIDIAが公開しているデータや第三者機関によるベンチマーク結果を見ると、世代を経るごとにTensorコアの理論性能(ピークFLOPS)が飛躍的に向上していることが分かります。
| アーキテクチャ (代表GPU) | 主な精度での理論性能 (ピークFLOPS) | 備考 |
|---|---|---|
| Volta (V100) | 約 125 TFLOPS (FP16) | |
| Ampere (A100) | 約 312 TFLOPS (FP16) 約 156 TFLOPS (TF32) |
スパース性 非考慮 |
| Hopper (H100) | 約 1,979 TFLOPS (FP8) 約 989 TFLOPS (FP16) |
スパース性 考慮 |
| Blackwell (B200) | 約 4.5 PFLOPS (FP4) ※1 約 2.25 PFLOPS (FP8) ※1 |
スパース性 考慮 |
これらは理論上の最大値であり、実際のアプリケーションでの性能は異なりますが、世代間の性能向上のスケールを示しています。
特定のAIモデルの学習や推論時間を比較したベンチマーク(例: MLPerf)でも、世代が進むほど大幅な性能向上が確認されています。
世代間の性能向上:VoltaからBlackwellまで
上記のFLOPS値からも分かるように、Tensorコアの性能は世代ごとに劇的に向上しています。各世代間の主な進化点は以下の通りです。
| 世代間の移行 | 主な進化・特徴 |
|---|---|
| Volta → Turing | 主に推論性能(INT8演算など)が強化され、一般消費者向けのGeForce RTXシリーズにもTensorコアが初搭載されました。 |
| Turing → Ampere | TF32対応や構造的スパース性対応により、AIの学習・推論両面で性能が大幅に向上しました。 |
| Ampere → Hopper | FP8対応とTransformer Engineの導入により、特にChatGPTのような大規模言語モデル(LLM)の性能が飛躍的に向上しました。 |
| Hopper → Blackwell | FP4/FP6対応や第2世代Transformer Engineにより、性能とエネルギー効率がさらに向上し、兆パラメータ級の超巨大モデルへの対応力が強化されました。 |
この急速な性能向上が、AI技術の進歩をハードウェア面から強力に後押ししています。
新しい世代のGPUを選ぶことは、より高度なAI開発や、より快適なゲーミング体験に直結すると言えるでしょう。
動作精度(FP16, TF32, FP8など)と性能の関係
Tensorコアは、複数の演算精度をサポートしていますが、どの精度で計算するかによって性能が大きく変わります。
一般的に、ビット数が少ない(精度が低い)フォーマットほど、計算速度は速くなり、メモリ使用量も少なくなります。
| データフォーマット | ビット数 | 主な対応世代 | 主な特徴・用途 |
|---|---|---|---|
| FP32 | 32 | (基本) | 単精度浮動小数点数。従来の標準的な精度。Tensorコアによる直接的な高速化は限定的(TF32経由などを除く)。 |
| TF32 | 19 (※1) | Ampere以降 | TensorFloat-32。FP32の範囲とFP16の精度を持つ。コード変更なしでFP32比で高速化可能。Ampere世代以降のTensorコアで内部的に利用される。 |
| FP16 | 16 | Volta以降 | 半精度浮動小数点数。速度とメモリ効率に優れる。AI学習・推論で広く利用。数値範囲が狭いためオーバーフロー/アンダーフローに注意が必要な場合がある。 |
| BF16 | 16 | Ampere以降 | BFloat16。FP16と同じビット数だが指数部が多くFP32に近い範囲を持つ。FP16より計算が安定しやすいとされる。AI学習で利用が増加。 |
| FP8 | 8 | Hopper以降 | 8ビット浮動小数点数。FP16より高速・高効率。Hopper世代以降のTransformer Engineと組み合わせることで精度低下を抑制。主に大規模モデルの学習・推論で利用。 |
| FP4 / FP6 | 4 / 6 | Blackwell以降 | 4/6ビット浮動小数点数。さらなる低ビット化により、特に推論性能や効率の向上が期待される。 |
| INT8 | 8 | Turing以降 | 8ビット整数。主に推論処理で利用。非常に高速だが、モデルの量子化(浮動小数点数を整数に変換・精度調整)が必要。 |
このように、求める精度と性能のバランスに応じて、適切なデータフォーマットを選択することが、Tensorコアの能力を最大限に引き出す鍵となります。
多くのディープラーニングフレームワークでは、混合精度学習(FP32とFP16/BF16などを組み合わせて使う)を簡単に有効にする機能が提供されています。
Tensorコアの使い方:ソフトウェアとプログラミング
Tensorコアの恩恵を受けるには、必ずしも専門的なプログラミング知識が必要なわけではありません。ここでは、ソフトウェアレベルでの利用から、より直接的なプログラミング方法まで解説します。
自動的に活用されるケース:対応ソフトウェア・ドライバ
多くの場合、ユーザーはTensorコアの存在を意識することなく、その恩恵を受けることができます。
NVIDIAドライバ
最新のGPUドライバをインストールしていれば、基本的なレベルでTensorコアの機能が有効になります。
対応アプリケーション
- ゲーム:
DLSSに対応したゲームでは、設定メニューからDLSSを有効にするだけで、Tensorコアが自動的に利用され、フレームレートが向上します。 - クリエイティブソフト
NVIDIA Studioドライバに対応した動画編集ソフトや3DCGソフトでは、AI機能(デノイズ、超解像など)を利用すると、内部的にTensorコアが活用されます。 - ディープラーニングフレームワーク
TensorFlowやPyTorchといった主要なフレームワークは、cuDNNなどのNVIDIAライブラリを通じて、Tensorコアを自動的に利用するように最適化されています。
混合精度学習などの設定を有効にするだけで、多くの場合Tensorコアによる高速化が得られます。
したがって、一般的なユーザーであれば、特別な設定やプログラミングなしにTensorコアのメリットを享受できる場面が多くあります。
プログラミングによる直接利用:CUDAとライブラリ
より高度な制御や、独自のアルゴリズムでTensorコアの性能を最大限に引き出したい場合は、プログラミングによる直接的な利用が必要になります。
これには主にNVIDIA CUDAプラットフォームと関連ライブラリを使用します。
NVIDIA CUDA Toolkit
CUDA(Compute Unified Device Architecture)は、NVIDIA GPU上で汎用計算を行うための並列コンピューティングプラットフォームおよびプログラミングモデルです。
CUDA Toolkitには、コンパイラ(NVCC)、各種ライブラリ、開発ツールが含まれており、C/C++やFortranなどからGPUプログラミングを行うことができます。
Tensorコアを直接利用するには、CUDA C++などで低レベルなプログラミング(WMMA APIやcuBLASライブラリの使用など)を行う必要がありますが、高度な知識と技術が求められます。
【関連記事】
【NVIDIA】CUDAとは?主要機能やインストール方法、使い方を解説!
cuDNN、cuBLASなどのライブラリ
より簡単にTensorコアを活用する方法として、NVIDIAが提供する最適化されたライブラリを利用する方法があります。
- cuDNN (CUDA Deep Neural Network library):
ディープラーニングの基本的な計算(畳み込み、プーリング、正規化、活性化関数など)を高速化するためのライブラリです。
内部でTensorコアを効率的に利用するように最適化されています。TensorFlowやPyTorchなどのフレームワークも、このcuDNNを利用しています。
- cuBLAS (CUDA Basic Linear Algebra Subroutines library):
行列演算などの基本的な線形代数計算を高速化するライブラリです。Tensorコアを利用した高効率な行列演算(GEMM: General Matrix Multiply)などが提供されています。
これらのライブラリを使用することで、低レベルなハードウェアの詳細を意識することなく、Tensorコアによる高速化の恩恵を受けることができます。
TensorRTによる推論の最適化
TensorRTは、NVIDIAが提供するAI推論の最適化ツールおよびランタイムライブラリです。
学習済みのAIモデルを入力すると、Tensorコアを含むターゲットGPUのアーキテクチャに合わせて、計算グラフの最適化、カーネルの自動選択、精度のキャリブレーションなどを実行し、推論処理のレイテンシ(遅延)を最小限に抑え、スループットを最大化します。
TensorRTを使用することで、多くの場合、ディープラーニングフレームワーク上で直接推論を実行するよりも大幅な性能向上が期待でき、リアルタイム性が重要なアプリケーションなどで特に有効です。
【関連記事】
▶︎TensorRTとは?対応GPUや導入方法、使い方をわかりやすく解説!
ディープラーニングフレームワークでの利用(TensorFlow, PyTorch)
現在、AI開発で最も広く使われているTensorFlowやPyTorchといったディープラーニングフレームワークでは、Tensorコアの利用が容易になっています。
これらのフレームワークは、NVIDIAのcuDNNライブラリと密接に連携しており、適切な設定(混合精度学習の有効化など)を行うだけで、内部的にTensorコアを利用した高速計算を実行してくれます。
【関連記事】
▶︎TensorFlowとは?できることや使い方、実際の使用例をわかりやすく解説!
▶︎PyTorchとは?できることや使い方、インストール方法をわかりやすく解説
Tensorコアの主な活用事例
Tensorコアの高速計算能力は、AI分野にとどまらず、様々な領域で活用されています。ここでは、その代表的な活用事例をいくつかご紹介します。
AI・ディープラーニング
これはTensorコアの最も主要な活用分野です。
-
モデル学習(Training):
画像認識、自然言語処理、音声認識、推薦システムなど、様々なAIモデルの学習時間を劇的に短縮します。
これにより、研究開発のスピードアップや、より高性能なモデルの創出が可能になります。特に、ChatGPTに代表される大規模言語モデル(LLM)の学習には、Tensorコアを搭載した高性能GPUが不可欠です。
-
推論(Inference):
学習済みモデルを使ってサービスを提供する際にもTensorコアは活躍します。
リアルタイム性が求められるAIチャットボットの応答生成、自動運転システムにおける物体認識、医療画像診断支援、スマートフォンのAI機能(カメラの高画質化など)といった場面で、高速かつ効率的な推論処理を実現しています。
Tensorコアの進化は、AIモデルの進化と密接に連携しており、今後もAI技術発展の鍵を握る存在であり続けるでしょう。
ハイパフォーマンスコンピューティング (HPC)
Tensorコアは、AIだけでなく、科学技術計算の分野(HPC: High Performance Computing)でも活用が進んでいます。
従来、HPC分野では倍精度(FP64)演算が重視されてきましたが、計算内容によっては、Tensorコアが得意とする半精度(FP16)や単精度(FP32、TF32経由)での計算を組み合わせることで、大幅な高速化が可能です。
具体的な応用例としては、以下のようなものが挙げられます。
- 分子動力学シミュレーション: 新薬開発や材料科学における分子の挙動解析
- 流体力学計算: 航空機の設計、気象予測、エンジン内部の燃焼解析
- 構造解析: 建築物や工業製品の強度シミュレーション
- ゲノム解析: 遺伝子情報の高速解析による個別化医療への貢献
AI技術とHPCシミュレーションを融合させる「AI for Science」という動きも活発化しており、Tensorコアはその両方を加速する基盤技術として重要性を増しています。
データ分析・ビッグデータ処理
膨大なデータを高速に処理・分析する必要があるデータサイエンスやビッグデータの分野でも、Tensorコアの恩恵を受けられます。
NVIDIAが提供するデータサイエンス用ソフトウェアライブラリ群「RAPIDS」は、データの前処理、機械学習モデルのトレーニング、データの可視化といった一連のワークフローをGPU上で高速化します。
RAPIDSは内部でTensorコアを活用しており、従来のCPUベースの処理と比較して、分析時間を大幅に短縮できます。
これにより、金融市場のリアルタイム分析、顧客行動の予測、大規模なセンサーデータの解析などを、より迅速かつ効率的に行うことが可能になります。
レンダリング、動画編集
3DCGのレンダリングや高解像度動画の編集といった、クリエイティブ分野のワークロードも、Tensorコアによって高速化されます。
- AIデノイジング: レンダリング時に発生するノイズをAI(Tensorコアを利用)で効率的に除去し、高品質な画像を短時間で生成します。
- 動画の超解像: 低解像度の動画をAIで高解像度化する処理(アップスケーリング)を高速化します。
- AIによる編集支援: 動画編集ソフトウェアにおいて、物体追跡、背景除去、自動字幕生成といったAI機能をTensorコアが支援し、編集作業の効率を向上させます。
NVIDIA Studioプラットフォームでは、対応するクリエイティブアプリケーションにおいて、Tensorコアを活用した様々な高速化機能が提供されており、プロのクリエイターから趣味で制作を楽しむユーザーまで、幅広い層にメリットをもたらしています。
DLSS(Deep Learning Super Sampling)による高画質・高フレームレート化
ゲーム業界にとって、Tensorコアの最も身近な恩恵は**「DLSS (Deep Learning Super Sampling)」**でしょう。DLSSは、NVIDIAが開発した革新的なAIレンダリング技術です。
DLSSの仕組みは以下の通りです。
-
ゲームのレンダリング解像度を、モニターのネイティブ解像度よりも低く設定します(例: 1440pモニターで1080pレンダリング)。
これにより、GPU負荷が軽減され、フレームレートが向上します。
-
レンダリングされた低解像度の映像と、ゲームエンジンから得られる動きのベクトル情報をTensorコアに入力します。
-
事前にNVIDIAのスーパーコンピューターで学習されたAIモデルが、Tensorコア上で高速に推論処理を実行し、入力された情報からネイティブ解像度に匹敵する、あるいはそれ以上の高品質な映像を生成(超解像)します。
結果として、DLSSを利用すると、画質を維持または向上させながら、フレームレートを大幅に向上させることができます。
特に、高解像度設定やレイトレーシングのような高負荷な設定でプレイする際に、その効果は絶大です。多くの最新ゲームがDLSSに対応しており、Tensorコア搭載のGeForce RTXシリーズGPUの大きな魅力の一つとなっています。
まとめ
本記事では、NVIDIA GPUのAI・計算性能を飛躍的に向上させる「Tensorコア」について、その核心に迫りました。
Tensorコアが、AI計算で頻繁に用いられる行列演算に特化した専用プロセッサであり、混合精度計算によって速度と効率を両立させる仕組みを解説しました。
この技術により、AIモデルの学習時間は劇的に短縮され、リアルタイムでの高度な推論処理が可能になったほか、DLSS技術を通じてゲーミング体験も大きく向上しています。
Voltaから最新のBlackwellアーキテクチャに至るまで、世代ごとに性能と機能を強化し続けてきたTensorコアは、AI分野だけでなく、HPCやコンテンツ制作など、多岐にわたる分野で不可欠な存在です。
この記事を通じて、現代のデジタル技術を支える基盤であるTensorコアへの理解が深まり、その重要性を感じていただければ幸いです。










