この記事のポイント
 転移学習は、学習済みのモデルを新しい課題に応用する機械学習の手法
転移学習は、学習済みのモデルを新しい課題に応用する機械学習の手法- 特徴抽出、ファインチューニング、ドメイン適応などのアプローチがある
- ゼロからの学習やマルチタスク学習と比較して、効率的なモデル構築が可能
- 画像認識、自然言語処理、音声処理など、様々な分野で応用されている
- 適切なモデル選定、ハイパーパラメータ調整、データセットの適合性が重要

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AIモデルの開発には、大量のデータと時間、そして高度な専門知識が必要…そう思っていませんか?実は、その常識を覆す画期的な手法があります。それが「転移学習」です。
しかし、「転移学習」は、その可能性の大きさにも関わらず、具体的な仕組みや活用方法については、まだ十分に理解されていません。
本記事では、この「転移学習」について、基礎から応用までをわかりやすく解説します。
転移学習の仕組み、具体的な手順、メリット・デメリット、他の機械学習手法との比較、そして様々な分野での活用事例まで、幅広く網羅的に説明します。
転移学習とは
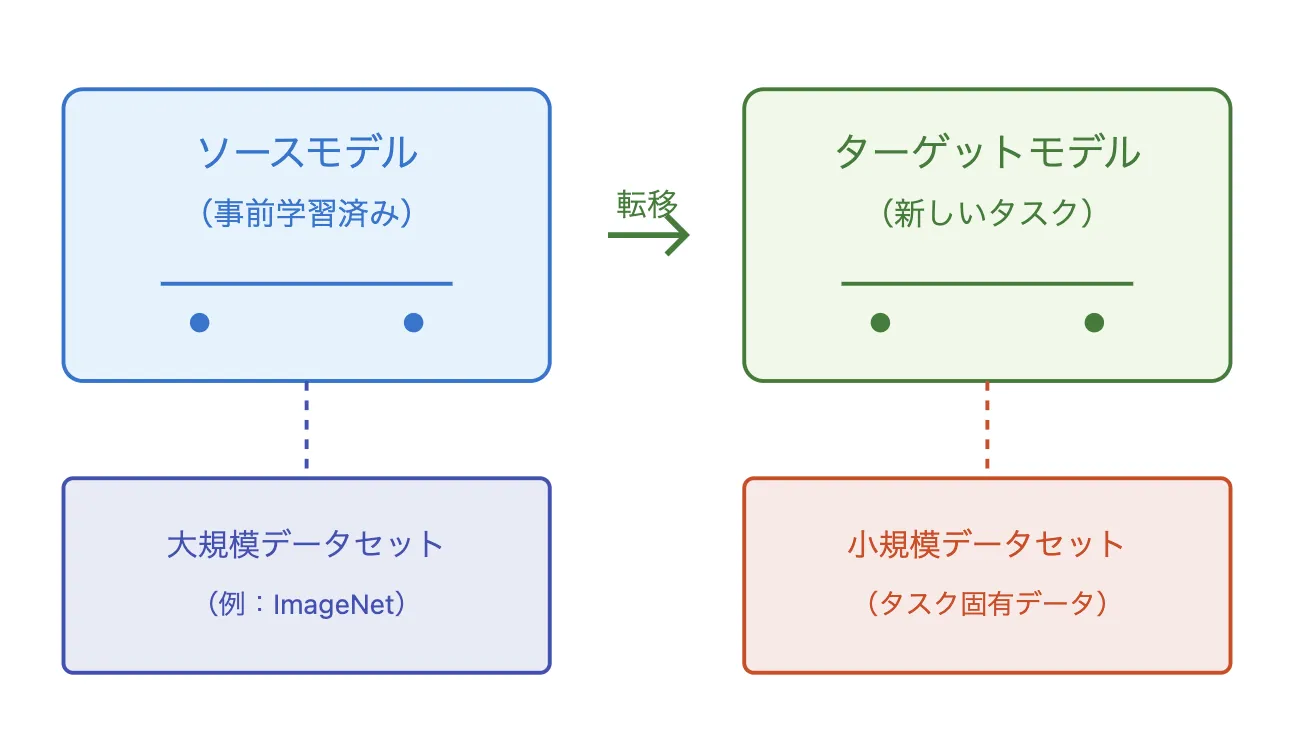
転移学習イメージ
転移学習(Transfer Learning) は、すでに学習済みの知識を別の問題に応用できる機械学習の方法です。これは、人が一度学んだことを新しい状況で活かすのと同じ考え方です。
これまでの機械学習では、新しい課題ごとにゼロからモデルを作成し、膨大なデータを使って学習させる必要がありました。しかし、これは時間がかかる上、大量のデータを集めるのが難しいこともあります。転移学習を使えば、すでに学習済みのモデルを使って新しい課題に適応させることができ、データが少なくても良い結果を得やすくなります。
転移学習の一般的な手順
転移学習の一般的な手順は以下の通りです
- すでに大規模なデータで学習済みの「ベースモデル」を取得する。
- そのモデルを新しい課題に合わせて調整(ファインチューニング)する。
- 必要に応じて、特定の部分だけを再学習することで適応させる。
この方法により、ゼロから学習を始めるよりも短時間で高精度なモデルを作ることができます。
転移学習はなぜ使われるようになったのか?
転移学習が広く使われるようになった理由の一つは、すでに学習されたモデルが多く公開されるようになったことです。
例えば、画像認識のための「ImageNet」や、文章を理解する「BERT」などのモデルは、研究者や企業が自由に利用できます。これにより、特にデータが少ない場合でも、高度なAI技術を活用しやすくなりました。
【関連記事】
➡️BERTとは?その仕組みやGPTとの違い、活用例を徹底解説!
転移学習の基本的なアプローチと種類
転移学習には、特徴抽出(Feature Extraction)、ファインチューニング(Fine-tuning)、ドメイン適応(Domain Adaptation) など、いくつかの主要な手法があります。
これらの手法を適切に理解し選択することで、データ量や計算リソースなどの制約を考慮しつつ、効率的に高性能なモデルを構築できます。
Feature Extraction(特徴抽出)手法
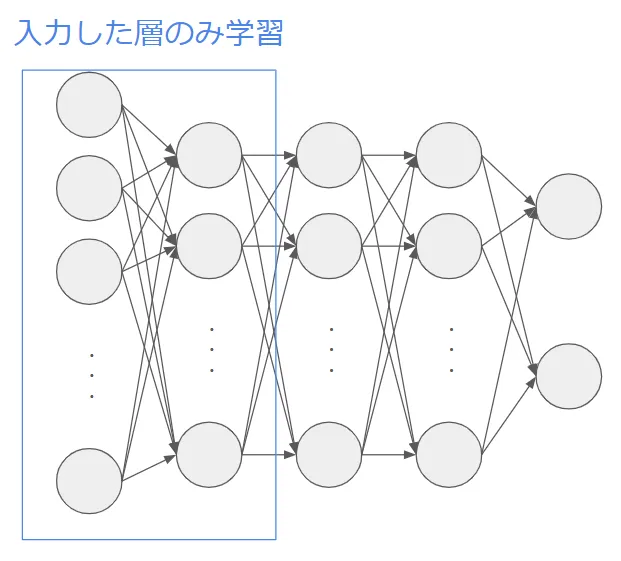
Feature Extraction(特徴抽出)手法
特徴抽出手法では、事前学習済みモデルの中間層が持つ高次の特徴表現を活用し、新しいタスクへ適応させます。具体的には、事前学習済みモデルの畳み込み層や埋め込み層などを固定し、その上に新しい分類器を追加して学習させます。この方法により、学習時間を短縮しつつ、汎用的な特徴を活かすことが可能です。
主なステップ
以下が特徴抽出法のステップとなります。
- 事前学習済みモデルをロードする。
- 中間層のパラメータを固定(フリーズ)する。
- 新しい分類層を追加する。
- 新しいデータで分類層のみを学習させる。
- モデルを評価し、必要に応じて調整する。
主な事前学習済みモデルの例
- 画像認識: ResNet、VGG、EfficientNet
- 自然言語処理(NLP): BERT、GPT、T5
- 音声認識: Wav2Vec
Fine-tuning(ファインチューニング)手法
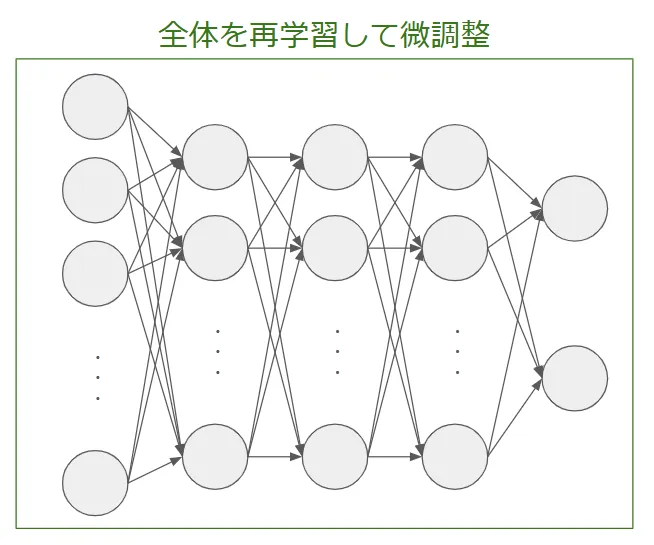
Fine-tuning(ファインチューニング)手法
ファインチューニングでは、事前学習済みモデルの一部または全体の層を再学習し、新しいタスクに適応させます。特徴抽出と異なり、モデルのパラメータを更新することで、より専門的なデータに最適化できます。
主なステップ
以下が特徴抽出法のステップとなります。
- 事前学習済みモデルをロードする。
- 一部または全層のパラメータを学習可能に設定する。
- 新しい分類層を追加する。
- 新しいデータでモデル全体を微調整する。
- モデルを評価し、適切なハイパーパラメータを調整する。
主な事前学習済みモデルの例
- 画像認識: MobileNet、Inception、DenseNet
- 自然言語処理(NLP): ALBERT、XLNet
- 音声認識: WaveNet
Domain Adaptation / Domain Generalization
Domain Adaptation / Domain Generalization
ドメイン適応(Domain Adaptation)は、ソースタスクとターゲットタスクのデータ分布が異なる場合に適用される手法です。例えば、ある医療機関のX線画像で学習したモデルを、別の医療機関のデータに適用する際に、ドメイン適応を行うことで精度低下を防ぐことができます。
主なステップ
以下が特徴抽出法のステップとなります。
- ソースドメインのデータで事前学習を行う。
- ターゲットドメインのデータを取得する。
- ドメイン適応手法(例: Adversarial Training)を適用する。
- モデルをターゲットドメインに適応させる。
- 新しいデータセットで性能を評価する。
主な事前学習済みモデルの例
- 画像認識: Self-Supervised Learning Models(SimCLR、MoCo)
- 自然言語処理(NLP): Domain-Specific BERT(BioBERT、ClinicalBERT)
- 音声認識: Adversarial Speech Recognition Models
他手法との比較(ゼロからの学習、マルチタスク学習など)
転移学習の価値をより深く理解するには、他の機械学習手法との比較が有効です。特に、ゼロからの学習(スクラッチトレーニング)、マルチタスク学習、ドメイン適応手法との違いを理解することで、各手法の適用シナリオを明確にし、最適な手法を選択できます。
ゼロからの学習(スクラッチトレーニング)との比較
スクラッチからモデルを学習する場合、ニューラルネットワークの重みをランダムに初期化し、大量のデータと計算リソースを使用してゼロから最適なパラメータを探索します。これに対し、転移学習では、事前学習済みモデルの重みを活用することで、学習時間の短縮や精度向上が容易になります。
特徴の違い
| 項目 | ゼロからの学習(スクラッチ) | 転移学習 |
|---|---|---|
| データ量の必要性 | 大量のデータが必要 | 少量のデータでも可能 |
| 学習時間 | 非常に長い | 短縮可能 |
| 精度の安定性 | 不安定(初期値の影響が大) | 事前学習済みの重みで安定 |
| 計算コスト | 高い | 低減可能 |
| 適用シナリオ | 新規のユニークなタスク | 既存の知識を活用できるタスク |
マルチタスク学習(Multitask Learning)との比較
マルチタスク学習は、複数の関連するタスクを同時に学習し、パラメータを共有することでモデルの性能向上を図ります。これに対し、転移学習は一つのタスクで学習済みの知識を別のタスクへ応用する点が異なります。
特徴の違い
| 項目 | マルチタスク学習 | 転移学習 |
|---|---|---|
| 学習対象 | 複数のタスクを同時に学習 | 一つのタスクの知識を別タスクへ転用 |
| データの必要量 | 各タスクに十分なデータが必要 | ターゲットタスクのデータは少量でも可 |
| モデルの適応性 | タスク間の情報共有で相乗効果 | 新しいタスクへの適応が容易 |
| 適用シナリオ | 画像分類+物体検出など | 画像認識→医療画像分類の適応 |
ドメイン適応(Domain Adaptation)との比較
ドメイン適応は、異なるデータ分布(ソースドメインとターゲットドメイン)のギャップを調整する技術です。転移学習と異なり、ラベル付きデータが少ないターゲットドメインに適用することを主目的とする点が特徴です。
特徴との違い
| 項目 | ドメイン適応 | 転移学習 |
|---|---|---|
| データ分布 | 異なるドメイン間の適応 | 既存の知識を新タスクへ適用 |
| ラベル付きデータ | ターゲット側にラベルが少ない | ターゲットタスクにある程度のラベルあり |
| 適用シナリオ | 英語→日本語の分類モデル適応 | 一般画像分類→医療画像分類 |
ケースバイケースでの使い分け指針
各手法は目的やデータの状況によって適用が異なります。以下の指針を参考に最適な手法を選択できます。
| シナリオ | 適用すべき手法 |
|---|---|
| 十分なデータがあり、一から学習可能 | ゼロからの学習(スクラッチトレーニング) |
| 類似したタスクへの適用が必要 | 転移学習(Feature Extraction / Fine-Tuning) |
| 複数のタスクを同時最適化 | マルチタスク学習(Multitask Learning) |
| データ分布が異なる場合の適応 | ドメイン適応(Domain Adaptation) |
このように、それぞれの手法には異なる強みがあり、タスクの特性やデータの状況に応じて柔軟に選択することが重要です!
転移学習の具体的な手順・環境構築
転移学習を実践する際には、適切な事前学習済みモデルの選択、実装フローの理解、評価指標の選定が重要です。ここでは基本的な実装プロセスと、使い方のポイントを紹介します。
前提となる事前学習済みモデルの選択
転移学習の第一歩は、ターゲットタスクに近い特性を持つ事前学習モデルを選ぶことです。画像認識ならImageNetで学習されたResNetやVGG、NLPならBERTやGPT、音声なら事前学習済みのWave2Vec2.0などが候補となります。また、PyTorchのtorchvision.modelsやHugging Faceのtransformersライブラリを活用すれば、高品質なモデルを簡単に取得できます。
実装フローとコード例
実務では、PyTorchやTensorFlowでファインチューニングを行うことが一般的です。
例:PyTorchでの簡易コードフロー
- 事前学習モデル読み込み(
models.resnet18(pretrained=True)など) - 出力層をターゲットタスク用に再定義
- レイヤー凍結設定、オプティマイザ・損失関数設定
- トレーニングループ実行、評価指標で性能確認
評価指標と検証方法
転移学習結果の評価には、精度、F1スコア、BLEUスコア、ROUGEなどタスク依存の指標を用います。必ずベースライン(ゼロから学習したモデル)との比較を行い、転移の有効性を検証します。
模擬コード
# Google Colab 環境用
import tensorflow as tf
import numpy as np
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.optimizers import Adam
# GPU利用の確認
print("Num GPUs Available:", len(tf.config.experimental.list_physical_devices('GPU')))
# データセットのロード(CIFAR-10)
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
# 訓練データをサブセット化(10,000 サンプル)
x_train, y_train = x_train[:10000], y_train[:10000]
x_test, y_test = x_test[:2000], y_test[:2000] # テストデータも縮小
# 画像サイズを 96x96 にリサイズ(MobileNetV2 の計算負荷削減)
IMG_SIZE = 96
x_train = tf.image.resize(x_train, (IMG_SIZE, IMG_SIZE)) / 255.0
x_test = tf.image.resize(x_test, (IMG_SIZE, IMG_SIZE)) / 255.0
# クラス数
num_classes = 10
# 事前学習済みのMobileNetV2をロード(Feature Extractorとして利用)
base_model = MobileNetV2(weights='imagenet', include_top=False, input_shape=(IMG_SIZE, IMG_SIZE, 3))
base_model.trainable = False # すべての層を固定
# カスタム分類層の追加
x = GlobalAveragePooling2D()(base_model.output)
x = Dense(128, activation='relu')(x) # ニューロン数を削減
x = Dense(num_classes, activation='softmax')(x)
# 特徴抽出モデル
feature_extraction_model = Model(inputs=base_model.input, outputs=x)
# モデルのコンパイル(学習率を調整)
feature_extraction_model.compile(optimizer=Adam(learning_rate=0.0005),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 特徴抽出による学習(エポック数を削減)
print("Feature Extraction Model Training...")
feature_extraction_model.fit(x_train, y_train, epochs=5, batch_size=64, validation_data=(x_test, y_test))
# --------------------------------------
# ファインチューニング
# --------------------------------------
# MobileNetV2の最後の5層を学習可能にする
for layer in base_model.layers[-5:]:
layer.trainable = True
# 再コンパイル(低い学習率で微調整)
feature_extraction_model.compile(optimizer=Adam(learning_rate=0.0001),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# ファインチューニングによる学習(エポック数を削減)
print("Fine-Tuning Model Training...")
feature_extraction_model.fit(x_train, y_train, epochs=5, batch_size=64, validation_data=(x_test, y_test))
# モデルの評価
test_loss, test_acc = feature_extraction_model.evaluate(x_test, y_test)
print(f"\nTest Accuracy: {test_acc:.4f}")
実行結果
Test Accuracy: 0.7755
モデルのテストデータに対する分類精度が 77.55% であることを示しています。これは、CIFAR-10 の 10 クラス分類タスクにおいて、モデルが約78%の確率で正しいクラスを予測できていることを意味します。
転移学習の応用事例
転移学習は、さまざまな分野・タスクで効果を発揮します。特に画像分類や物体検出、自然言語処理、音声処理など、多彩な領域で実用化が進んでいます。
画像分類・物体検出への応用
ImageNet上で学習済みのResNetを利用し、医療画像診断や製造業の品質検査を行うケースは典型例です。限られたデータでも高精度を実現でき、専門家が少ない分野でもモデル開発が容易になります。
株式会社VAAK

引用元:VAAK公式HP
防犯やマーケティング向けの映像解析AIを開発しており、転移学習を用いた物体検出技術で異常行動の検知や人流分析を行っています。
【関連記事】
三菱地所株式会社と「VAAKEYE」実証実験を実施
自然言語処理(NLP)タスクでの活用
BERTやGPTなどの大規模言語モデルが、テキスト分類、要約、質問応答タスクに適用されています。わずかなドメイン固有データでファインチューニングすれば、リソース不足の領域でも高品質なモデルが実現します。
株式会社リクルートの例

引用元:リクルート公式HP
リクルートのAI研究機関であるMegagon Labsは、自然言語処理(NLP)分野において、転移学習を活用した高度な技術開発を行っています。特に、日本語の自然言語処理ライブラリ「GiNZA」の開発を通じて、転移学習の応用を推進しています。
「GiNZA」は、機械学習を利用した日本語の自然言語処理に関心を持つ研究者やエンジニア、データサイエンティスト向けに開発されたオープンソースライブラリです。最新のバージョンである「GiNZA version 5.0」では、20億文以上のWebテキストで事前学習を行ったTransformersモデルを組み込むことで、解析精度を飛躍的に向上させています。
【関連記事】
リクルートのAI研究機関が、高速・高精度な日本語の解析を実現する日本語自然言語処理ライブラリ「GiNZA version 4.0」を公開
音声処理・時系列分析への展開
音声認識や感情判定、時系列データ分析でも、汎用的な特徴抽出モデルを再利用することで、少ないデータで高精度な予測を行うことが可能です。
GMOインターネット

引用元:GMOインターネット公式HP
GMOインターネットは、音声分類タスクにおいて転移学習を活用しています。具体的には、既存の学習済みモデルの一部を新しいモデルに転移し、音声データの分類精度を向上させる取り組みを行っています。
【関連記事】
転移学習(Transfer learning)の紹介:音声分類版で山での池と滝の音を当ててみました~
転移学習のよくある質問(FAQ)
以下に、転移学習に関するよくある質問とその回答を具体的に記載します。実務の現場で役立つ情報を提供し、モデル選びやファインチューニング、問題発生時の対応について理解を深める一助とします。
モデル選定に関する疑問
「どの事前学習モデルを選ぶべきか?」
転移学習でのモデル選定は、解決したいタスクやデータの性質に大きく依存します。以下の指針を参考にしてください!
- 画像認識:一般的な画像分類タスクでは、ResNetやEfficientNetなどImageNetで事前学習されたモデルが広く使用されます。細かい特徴を捉える必要がある場合は、最新のビジョントランスフォーマーモデル(Vision Transformers, ViT)も有効です。
- 自然言語処理 (NLP): テキストデータを扱う場合、タスクに応じてBERT、RoBERTa、GPTなどが選ばれます。たとえば、質問応答や文書分類ではBERT系が、生成タスクではGPT系が適しています。
- その他のドメイン:音声データならWav2Vec、時系列データにはTransformerやLSTMなどの時系列向けモデルが推奨されます。
微調整(Fine-tuning)時のハイパーパラメータ設定
「どのようにハイパーパラメータを設定すべきか?」
ファインチューニングでは以下のポイントに注意することが必要です!
- 学習率
- 小さな学習率(例:1e-5 ~ 1e-4)を採用し、過学習を防ぎつつモデルの微調整を行います。
- 特定のレイヤーだけを更新する場合は、レイヤーごとに異なる学習率を設定することも効果的です。
- 凍結(Freeze)設定
- 初期段階では、低層のレイヤー(一般的な特徴を捉える部分)を固定(フリーズ)し、高層レイヤーのみを微調整します。
- 必要に応じて、全レイヤーを解凍して微調整を続行します。
- エポック数とバッチサイズ
- 少数エポック(例:3~10)から始め、性能の改善が見られる場合は増やします。
- バッチサイズは計算資源やデータサイズに応じて調整します。
転移学習が効果を発揮しないケース
「なぜ効果が出ないのか、どう対処すべきか?」
以下の要因が考えられます!
- ドメイン間の類似性が低い
- 元の事前学習タスクと目的のタスクのデータ分布が大きく異なると、負の転移が生じる可能性があります。
- 対策: より汎用性の高い事前学習モデル(例:基礎的な特徴抽出に特化したモデル)を試す。
- データ不足
- 転移学習で使用するラベル付きデータが少なすぎる場合、モデルの微調整が不十分となる可能性があります。
- 対策:データ拡張手法(Data Augmentation)を活用し、訓練データを増やします。また、追加データを収集することも検討してください。
- 不適切なハイパーパラメータ
- 学習率やエポック数が適切でないと、モデルが過学習または未学習となる場合があります。
- 対策:ハイパーパラメータを再検討し、適切な範囲で実験を繰り返します。
まとめ
転移学習は、機械学習の世界において、すでに学習された知識を新しい課題へ応用する強力な手法です。本記事では、転移学習の基本概念、主要なアプローチ、他手法との比較、具体的な活用事例について詳しく解説しました。
近年のAIの発展により、事前学習済みのモデルが多く公開され、画像認識や自然言語処理、音声処理など、さまざまな分野で活用されています。これにより、データが少なくても高精度なモデルを構築できるようになり、研究者や企業が効率的にAIの力を活用できる環境が整いました。
また、転移学習は単なる技術的な進歩にとどまらず、社会に大きな影響を与えています。医療診断の精度向上、カスタマーサポートの自動化、異常検知システムの強化など、その応用範囲は日々広がっています。
しかし、転移学習の成功には適切なモデルの選択、ハイパーパラメータの調整、データセットの適合性を考慮することが重要です。
AI総合研究所は企業のAI導入をサポートしています。導入の構想段階から、AI開発はもちろんのこと転移学習を用いたなどのシステム開発まで一気通貫で支援いたします。お気軽に弊社にご相談ください。










