この記事のポイント
 DNNの基本概念、仕組み、メリットを、AI初心者にもわかりやすく解説
DNNの基本概念、仕組み、メリットを、AI初心者にもわかりやすく解説- CNN、RNN、Transformerなど、主要なDNNアーキテクチャの特徴と違いを理解できる
- 画像認識、音声認識、自然言語処理など、DNNの幅広い活用事例を紹介
- TensorFlow、PyTorchを用いたDNNの実装方法を具体的なコード付きで説明
- DNNの学習方法(誤差逆伝播法、勾配降下法)や過学習対策など、実践的な知識を提供

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AI技術が急速に進化する中で、特に注目を集めているのが「DNN(ディープニューラルネットワーク)」です。
しかし、その複雑な仕組みや活用方法について、理解が追いついていない方も多いのではないでしょうか?
あるいは、DNNの概要は理解していても、実際にどのようにビジネスや研究に活かせるのか、具体的なイメージが湧かないという課題をお持ちかもしれません。
本記事では、そんな方々に向けて、DNNの基礎から応用までを徹底解説します。DNNとは何か、どのような仕組みで動作するのか、そして他の機械学習手法とどう違うのか、といった基本的な疑問に答えていきます。
さらに、代表的なアーキテクチャであるCNNやRNN、Transformerの解説、TensorFlowやPyTorchを用いたDNNの実装方法、さらには学習を効率化するテクニックまで、具体的な内容を網羅的に紹介します。また、画像認識、音声認識、自然言語処理など、DNNが実際に活用されている事例も取り上げ、その可能性を明らかにします。
この記事を読むことで、DNNに関する包括的な知識を身につけ、AI技術への理解を深めることができるでしょう。また、DNNを活用した新しいプロジェクトのアイデア創出や、既存の課題解決へのヒントを得られるはずです。
目次
DNN(Deep Neural Network)とは
DNNの学習方法を表した図 参考:論文
DNN(Deep Neural Network:深層ニューラルネットワーク)は、機械学習の一分野である 深層学習(Deep Learning) を支えるモデルで、多層構造のニューラルネットワークを用いて、複雑なパターンや表現を自動的に学習する機械学習モデルの一種です。
各層は「ニューロン」や「ノード」と呼ばれる計算単位で構成され、データの特徴を抽出し、複雑なパターンを学習します。
従来の浅いニューラルネットワークを拡張したもので、複数の中間層を積み重ねることで、入力データから段階的に抽象度の高い特徴を獲得できます。
この手法は、ビッグデータの活用とGPUなどの高速演算環境の普及によって飛躍的な性能向上を遂げ、画像認識、音声処理、自然言語処理など多岐にわたる分野で卓越した成果を上げています。
なぜDNNが注目されるのか
DNNは、人手で特徴を設計する必要があった従来の手法とは異なり、データから直接特徴を学習できる点が特徴です。
その結果、従来は困難だった高度なパターン認識や予測が可能になり、多くの領域でトップレベルの精度を実現しています。
特に、バックプロパゲーションと活性化関数の選択がDNNの成功を支える重要な要素です。
CNNとの違い
DNNとCNNはどちらもディープラーニングで用いられる重要な技術ですが、それぞれ得意とするタスクや構造が異なります。
CNN (Convolutional Neural Network:畳み込みニューラルネットワーク) は、主に画像認識の分野で発展してきた、DNNの一種です。
CNNは、畳み込み層 (Convolutional Layer) と プーリング層 (Pooling Layer) を持つことが大きな特徴です。
- 畳み込み層
画像から局所的な特徴を抽出する役割を担います。例えば、画像のエッジやテクスチャなどの情報を捉えることができます。
- プーリング層
畳み込み層で抽出された特徴の位置ずれに対するロバスト性(頑健性)を高め、かつ、特徴マップのサイズを削減することで、計算量を抑制する役割を担います。
一方、DNNは、複数の隠れ層を持つニューラルネットワークの総称であり、CNNのような特定の構造に限定されません。
DNNとCNNの主な違いは、以下の表の通りです**
| 特徴 | DNN | CNN |
|---|---|---|
| 主な用途 | 画像認識、自然言語処理、音声認識など、幅広い分野 | 主に画像認識 |
| ネットワーク構造 | 複数の隠れ層を持つ。層の種類や接続方法は限定されない | 畳み込み層とプーリング層を持つことが特徴 |
| 得意なタスク | 様々なタスクに対応可能 | 画像認識、物体検出、画像分類など |
| 入力データ | 様々な形式のデータ | 主に画像データ |
| 特徴抽出 | データ全体から特徴を学習 | 局所的な特徴を捉え、それらを組み合わせて学習 |
まとめると、CNNは画像認識に特化した構造を持つDNNの一種です。一方、DNNはより汎用的なモデルであり、CNNを含む様々なアーキテクチャの総称と言えます。
このように、DNNとCNNは密接に関連していますが、異なる特性を持っています。
それぞれの特徴を理解することで、解決したい課題に対して、どちらの技術が適しているかを判断できるようになります。
DNNの基本構造
DNNの基本構造 参考:論文
DNNは、入力層、中間層(隠れ層)、出力層から構成されます。
特徴的なのは中間層が多層化されている点で、層が増えるほどモデルはより複雑な概念を表現できると考えられています。
DNNは主に以下の構成要素から成ります。
入力層(Input Layer)
入力データ(例:画像のピクセル値、テキストの数値化された表現など)を受け取る層です。モデルにデータを渡します。
- 注意点:
- 入力データは通常、正規化やスケーリング(例:0-1に正規化)が施されます。
- データは「正規化」(例えば、0~1の範囲に変換)されることが多いです。
隠れ層(Hidden Layers)
中間計算を行う層です。入力データを処理して次の層に渡します。 たくさんの隠れ層があると、モデルはより複雑なパターンを学ぶことができます。
各層のノードは、前層のノードとの結合を持ち、活性化関数を通じて非線形変換を適用、特徴の抽出を行います。
初期層は入力の基本的特徴(エッジや音素など)を捉え、後続層はこれらを組み合わせてより抽象的な概念(オブジェクト、文脈)を表現します。
- 階層の種類
- 全結合層(Fully Connected Layer): すべてのノードが互いに繋がっています。
- 畳み込み層(Convolutional Layer): 画像データから部分的な特徴(エッジ、パターン)を抽出します。
- リカレント層(Recurrent Layer): 時系列データや文章のような順番が重要なデータを処理します。
- 計算の仕組み
- データをまず「線形変換」して(例:
z = Wx + b W b - 次に「活性化関数」を使って非線形に変換。これで複雑なデータ構造も表現可能になります。
- データをまず「線形変換」して(例:
出力層(Output Layer)
モデルが最終的な結果を出力する部分です。タスクに応じた出力(例:分類問題の場合はクラス確率、回帰問題の場合は実数値)を生成します。
- 出力される結果例
- 分類タスク: クラスの確率。Softmax関数を使うことが多いです。
- 回帰タスク: 実際の数値(例:家の価格)。
活性化関数(Activation Function)
シグモイドやReLU(Rectified Linear Unit)、tanhなど、各種活性化関数が用いられます。
活性化関数は非線形性をネットワークに導入し、単純な線形モデルでは捉えられない複雑なパターンを表現可能にします。
活性化関数(Activation Function):
データを非線形に変換して、複雑なパターンを学習できるようにします。
- 目的:
- 非線形性を導入し、複雑な問題を解けるようにする。
- 種類:
- ReLU(Rectified Linear Unit):
f(x) = \max(0, x) - Sigmoid:
f(x) = \frac{1}{1 + e^{-x}} - Tanh:
f(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}
- ReLU(Rectified Linear Unit):
パラメータ(重み・バイアス)
DNNは、各接続(ニューロン間の結合)に重みパラメータを持ち、適切な重み値を学習することで正確な予測を行います。
学習は、これらパラメータを訓練データに対して最適化する過程に相当します。
パラメータ(重みとバイアス):
学習を通じて更新されるネットワークの内部変数です。学習を通じて最適な値に更新されます。
- 学習の仕組み:
- データを入力し、出力が正解に近づくように「誤差」を計算します。
- 誤差を元に「バックプロパゲーション」という方法で、重みとバイアスを少しずつ調整します。
- 勾配降下法(Gradient Descent)という仕組みで最適化を行います。
D具体的な使用例
DNNは様々な分野で活用され、人間を超える性能や新たな価値創造を可能にします。

具体的な使用例
-
画像認識:
画像分類、物体検出、セグメンテーション、医療画像診断など、多彩な応用が行われています。自動運転(車線認識や障害物検知)、監視システム(顔認識)、画像検索エンジン(Pinterestのビジュアル検索)などで活用されています。- 例: ResNetを用いた画像分類や、YOLOを利用したリアルタイム物体検出。
- 参考: YOLO公式ページ
-
音声認識:
音声指令認識、音楽レコメンド、音声合成などにDNNが利用され、高度な音声理解と生成が可能になりました。スマートスピーカー(例: Amazon Alexa、Google Home)やリアルタイム通訳デバイス(例: Pocketalk)がその代表例です。- 例: LSTMを用いた音声からテキストへの変換や、WaveNetを用いた高品質な音声合成。
- 参考: WaveNetの詳細
-
自然言語処理:
文章理解、要約、機械翻訳、対話生成など、多言語・多領域タスクでDNNが威力を発揮します。顧客対応チャットボット、コンテンツ生成(例: Jasper、ChatGPT)、検索最適化(例: Googleの検索アルゴリズム)など幅広い分野で利用されています。- 例: BERTを用いた検索エンジン最適化や、GPTを利用した文章生成。
- 参考: BERTに関するGoogleの説明
-
医療:
医療画像診断、疾患リスク予測などにDNNが用いられています。特にCTスキャンやMRI画像の解析では、異常検出や診断支援に大きな効果を発揮しています。また、薬剤開発や患者ケアの最適化にも活用されています。- 例: Google HealthのAIを活用した乳がん診断補助システム。
- 参考: Google Healthの事例
代表的なDNNアーキテクチャ
DNNは用途に応じて多様な構造が考案され、特定タスクに特化したアーキテクチャが生まれています。
畳み込みニューラルネットワーク(CNN)
画像認識に特化した構造で、畳み込み層とプーリング層を用いて、画像中の局所特徴を効率的に抽出します。
ResNetやVGG、Inceptionなどのモデルが代表例です。
より詳細を知りたい場合は関連記事をご参照ください。
関連記事:CNN(畳み込みニューラルネットワーク)とは?仕組み・活用事例を徹底解説
再帰型ニューラルネットワーク(RNN)
時系列データや自然言語処理に適した構造で、系列依存関係を捉えます。
LSTMやGRUといった改良版RNNは、文章理解や音声解析で成果を上げています。
RNN(Recurrent Neural Network): 時系列データや文章の処理に強み。
より詳細を知りたい場合は関連記事をご参照ください。
関連記事:ディープラーニングとは?その仕組みや種類、機械学習との違いを解説の一部
トランスフォーマー(Transformer)
自己注意機構(Self-Attention)を活用した構造で、長い文脈も効率的に扱えます。
BERTやGPTなどのモデルは大規模言語モデルとしてNLP領域で大きなブレークスルーをもたらしました。
Transformer: 自然言語処理や大規模モデル(例:GPT)の基盤技術。
より詳細を知りたい場合は関連記事をご参照ください。
関連記事:Transformerとは?モデルの概要やBERTとの違いをわかりやすく解説
DNNの学習方法
DNNの学習は、誤差逆伝播(Backpropagation)と勾配降下法(Gradient Descent)の組み合わせが一般的です。
大量データを用いてミニバッチ単位で学習を進め、反復的にパラメータを更新して誤差を低減します。
-
誤差逆伝播(Backpropagation)
モデルの予測と正解との誤差を定量化する関数です。
出力層と教師データとの差分(誤差)を後ろから前へ伝播し、各層のパラメータに対する勾配を計算します。
これにより、どのパラメータをどの方向に更新すべきかが明確になります。 -
勾配降下法(Gradient Descent)
勾配降下法は、誤差を最小化する方向にパラメータを徐々に更新する最適化手法です。
学習率や最適化アルゴリズム(SGD、Adamなど)を調整することで収束速度や安定性を改善します。
DNNの実装
DNNの実装は以下の5ステップで行います。
-
フレームワークの選択:
- TensorFlow, PyTorch, Kerasなどのフレームワークを使用。
-
データ準備:
- データの前処理(正規化、分割、拡張)。
-
ネットワーク構築:
- 必要な層(Dense, Convolutional, Recurrentなど)を追加。
-
モデルの訓練:
- 損失関数と最適化アルゴリズムを選択し、訓練を開始。
-
評価とテスト:
- テストデータを用いて性能を確認。
ここからは、PythonのTensorFlow/Kerasを使用してDNNを実装する方法をコードと合わせてご紹介します。
実際にDNNの学習を行ってみましょう
以下は、上記のステップをそれぞれを実現するためのコード例です。
今回は、Pythonのフレームワーク「TensorFlow」と「Keras」を使用したシンプルな例を基に説明します。この例では、手書き数字認識データセット(MNIST)を使用します。
実際に使ってみて、理解を深めていきましょう!
- 必要なライブラリのインポート
以下のコードでライブラリをインポートします。
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
- データセットの準備
学習で使用するデータセットを用意します。今回は以下のような形で準備しました。
# データセットのロード
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# データのスケーリング
x_train = x_train / 255.0
x_test = x_test / 255.0
# ラベルをone-hotエンコーディング
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
データの形状を確認しておきます。
print(x_train.shape)
print(y_train.shape)
出力結果例:
(60000, 28, 28)
(60000, 10)
- モデルの定義
DNNモデルを構築します。ここでは、3層のネットワークを作成しました。
model = Sequential([
Flatten(input_shape=(28, 28)), # 入力層:28x28ピクセルを1次元に展開
Dense(128, activation='relu'), # 隠れ層1:128ユニット、ReLU活性化
Dense(64, activation='relu'), # 隠れ層2:64ユニット、ReLU活性化
Dense(10, activation='softmax') # 出力層:10クラスの確率を出力
])
- モデルのコンパイル
損失関数、最適化アルゴリズム、評価指標を指定します。
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
- モデルの訓練
モデルを訓練データで実際に訓練してみましょう。
model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
訓練にはある程度時間がかかります。今回は90秒ほどかかりました。
最終的に以下のように出力されれば問題ないです。
出力結果例:
Epoch 1/10
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 6s 4ms/step - accuracy: 0.8659 - loss: 0.4672 - val_accuracy: 0.9607 - val_loss: 0.1369
Epoch 2/10
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 10s 3ms/step - accuracy: 0.9653 - loss: 0.1187 - val_accuracy: 0.9643 - val_loss: 0.1210
Epoch 3/10
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 11s 4ms/step - accuracy: 0.9770 - loss: 0.0782 - val_accuracy: 0.9678 - val_loss: 0.1086
Epoch 4/10
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 11s 5ms/step - accuracy: 0.9820 - loss: 0.0559 - val_accuracy: 0.9694 - val_loss: 0.1040
Epoch 5/10
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 8s 4ms/step - accuracy: 0.9871 - loss: 0.0414 - val_accuracy: 0.9737 - val_loss: 0.0942
Epoch 6/10
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 7s 5ms/step - accuracy: 0.9898 - loss: 0.0310 - val_accuracy: 0.9753 - val_loss: 0.0950
Epoch 7/10
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 10s 5ms/step - accuracy: 0.9922 - loss: 0.0250 - val_accuracy: 0.9736 - val_loss: 0.1044
Epoch 8/10
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 5s 4ms/step - accuracy: 0.9922 - loss: 0.0231 - val_accuracy: 0.9752 - val_loss: 0.1026
Epoch 9/10
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 12s 5ms/step - accuracy: 0.9950 - loss: 0.0162 - val_accuracy: 0.9750 - val_loss: 0.1043
Epoch 10/10
1500/1500 ━━━━━━━━━━━━━━━━━━━━ 5s 4ms/step - accuracy: 0.9945 - loss: 0.0176 - val_accuracy: 0.9745 - val_loss: 0.1141
<keras.src.callbacks.history.History at 0x78a0b848bc10>
- モデルの評価
学習後、テストデータでモデルの性能を評価します。
test_loss, test_accuracy = model.evaluate(x_test, y_test)
print(f"Test Accuracy: {test_accuracy:.2f}")
以下のように出力されます。
出力結果例:
Test Accuracy: 0.97
- 予測を行う
新しいデータに対して予測を行います。
import numpy as np
# テストデータから1つのサンプルを使用
sample = x_test[0].reshape(1, 28, 28)
prediction = np.argmax(model.predict(sample), axis=-1)
print(f"Predicted Label: {prediction[0]}")
以下のように出力されると、完了です。
出力結果例:
Predicted Label: 7
これで基本的なDNNの実装は完了です。用途に応じて、ネットワークの層やパラメータを調整してみてください!
過学習対策と正則化手法
DNNはパラメータ数が膨大で過学習しやすいため、ドロップアウトやL2正則化、早期終了(Early Stopping)などで汎化性能を確保します。
勾配を計算し、ネットワーク全体のパラメータを調整することで、新規データに対する予測精度を維持します。
以下では、その具体的なコードもご紹介します。
- ドロップアウトを追加する
ドロップアウト(Dropout)は、学習中にランダムに一部のノードを無効化することで、モデルの汎化性能を向上させます。
from tensorflow.keras.layers import Dropout
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dropout(0.5), # 50%のノードを無効化
Dense(64, activation='relu'),
Dropout(0.5), # 50%のノードを無効化
Dense(10, activation='softmax')
])
- 早期終了を導入する
早期終了(Early Stopping)は、検証データの損失が一定回数改善しなくなった時点で学習を終了する手法です。
from tensorflow.keras.callbacks import EarlyStopping
# EarlyStoppingを設定
early_stopping = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True)
# モデルの訓練時にコールバックを追加
model.fit(x_train, y_train,
epochs=50, # エポック数は多めに設定
batch_size=32,
validation_split=0.2,
callbacks=[early_stopping])
- L2正則化(ウェイトのペナルティ)を追加
L2正則化(Weight Decay)は、重みが大きくなりすぎることを防ぎ、モデルの複雑さを抑制します。
from tensorflow.keras.regularizers import l2
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu', kernel_regularizer=l2(0.001)), # L2正則化を適用
Dense(64, activation='relu', kernel_regularizer=l2(0.001)), # L2正則化を適用
Dense(10, activation='softmax')
])
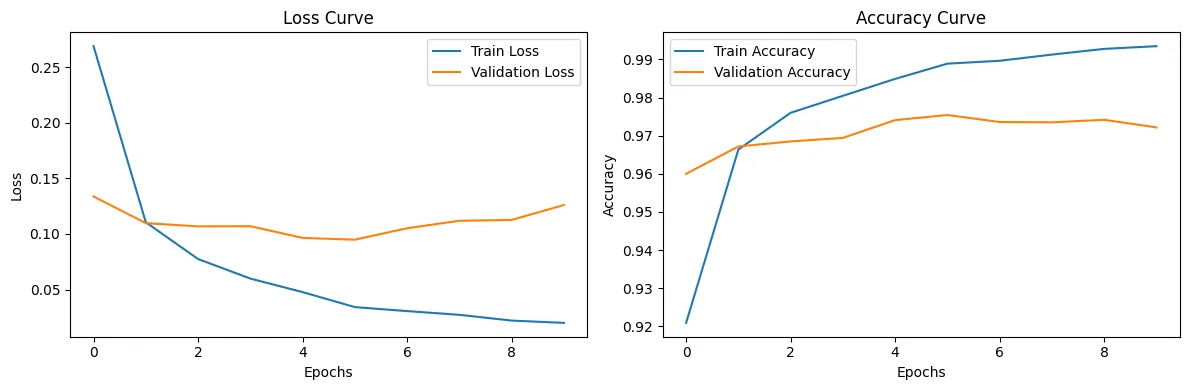
学習の進行状況の可視化
学習中の損失や精度を可視化するには、学習時の履歴データ(history)を取得し、それをプロットします。
可視化することで、モデルの収束状態の確認することができます。
以下の手順で、追加してみてください!
- 学習履歴を保存
モデルのfitメソッドの戻り値であるhistoryオブジェクトに、学習中の損失や精度が記録されます。このデータをプロットするために利用します。
以下の部分を変更します。
model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
変更後
history = model.fit(x_train, y_train,
epochs=10,
batch_size=32,
validation_split=0.2)
- 損失と精度をプロット
学習曲線を描画するための関数plot_learning_curveを追加します。
この関数では、historyから学習中の損失(lossとval_loss)と精度(accuracyとval_accuracy)を取得してプロットします。
import matplotlib.pyplot as plt
# 学習曲線をプロット
def plot_learning_curve(history):
# 損失をプロット
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1) # 1行2列の1つ目のグラフ
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Loss Curve')
# 精度をプロット
plt.subplot(1, 2, 2) # 1行2列の2つ目のグラフ
plt.plot(history.history['accuracy'], label='Train Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Accuracy Curve')
plt.tight_layout()
plt.show()
# プロット関数を呼び出す
plot_learning_curve(history)
- プロット関数の呼び出し
訓練後にplot_learning_curve関数を呼び出して、グラフを描画するコードを追加しました。
以下の部分を変更します。
test_loss, test_accuracy = model.evaluate(x_test, y_test)
print(f"Test Accuracy: {test_accuracy:.2f}")
変更後
plot_learning_curve(history)
test_loss, test_accuracy = model.evaluate(x_test, y_test)
print(f"Test Accuracy: {test_accuracy:.2f}")
完全版のコードは以下に示しています。
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
# データセットのロード
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# データのスケーリング
x_train = x_train / 255.0
x_test = x_test / 255.0
# ラベルをone-hotエンコーディング
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# モデル定義
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
# モデルコンパイル
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# モデルの訓練
history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
# 学習曲線をプロット
def plot_learning_curve(history):
plt.figure(figsize=(12, 4))
# 損失をプロット
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Loss Curve')
# 精度をプロット
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='Train Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Accuracy Curve')
plt.tight_layout()
plt.show()
plot_learning_curve(history)
:::
実際に可視化してみると以下のように表示されます。
他の機械学習手法との比較
他の手法との比較を簡単に表にまとめました。
| 特徴 | DNN | 従来の機械学習 | SVM, KNNなど |
|---|---|---|---|
| 特徴抽出 | 自動(特徴量エンジニアリングが不要) | 手動(専門知識が必要) | 手動 |
| 非線形性 | 高い | 限定的 | あるが表現力は限定的 |
| 性能 | ビッグデータにおいて優位 | データが少ない場合に有利 | 小規模データに適する |
| 計算コスト | 高い | 比較的低い | 低い |
DNNは高表現力を備える一方で、膨大なデータ・計算資源が必要で、解釈性が低いことが課題です。
従来の機械学習手法との差異
線形モデルや決定木ベースモデルは少量データでも動作し解釈性が高い半面、複雑な特徴抽出は苦手です。
DNNは膨大なデータで非線形かつ複雑なパターンを自動学習できるため、高性能ですがハードルは高めと言えます。
ハイブリッドアプローチ
DNNと他手法を組み合わせて利用する戦略も有効です。
前処理で教師なし学習による特徴抽出を行い、その上でDNNを用いたり、DNNの出力を他のモデルに入力するなど、ケースバイケースのアプローチが可能です。
よくある質問(FAQ)
DNNを始めるには何が必要?
Python、TensorFlowやPyTorchなどのフレームワークと、GPU環境が一般的な開始点です。初めは小規模なデータセットで基礎的なモデルを学習し、徐々にモデル規模や応用範囲を拡大しましょう。
すべての問題にDNNが有効なのか?
データ量や問題性質によります。小規模データや高い説明可能性が求められる場合は、他の手法が適することも多いです。DNNを選ぶ際は、リソース・データ特性・ビジネス要件を考慮しましょう。
DNNの学習時間短縮は可能?
GPUやTPUの活用、分散学習、バッチサイズ・最適化手法の工夫で学習時間を短縮できます。近年はクラウド環境でGPUを手軽に利用可能なため、実用ハードルは下がっています。

まとめ
本記事では、DNN(Deep Neural Network)の基本概念、多層構造による特徴学習、学習方法(誤差逆伝播・勾配降下法)、様々な派生アーキテクチャ(CNN、RNN、Transformer)、応用事例(画像・音声・言語処理)、他手法との比較、実装例まで幅広く解説しました。
DNNはデータから高度なパターンを自動学習し、多くの分野で劇的な性能向上をもたらした技術です。深層構造を活用して非線形かつ複雑なデータの処理を可能にし、多くの分野で革命を起こしました。
その応用範囲は広く、画像認識や自然言語処理だけでなく、医療や自動運転など、社会のさまざまな課題解決に寄与しています。一方で、計算コストやデータ依存性が高いため、効率的なアルゴリズムやハードウェアの進化が求められています。
今後も研究・開発が進展し、新たなアルゴリズム最適化やモデル設計により、より多様な問題への適用と利便性向上が期待されます。
AI総合研究所は企業のAI導入をサポートしています。
最新のAIの知見、事例、開発技術を保有していますので、AI導入の疑問や問いなど、
お気軽にご相談ください。










