この記事のポイント
 機械学習は、データから規則やパターンを自動的に学習する技術
機械学習は、データから規則やパターンを自動的に学習する技術- 教師あり学習、教師なし学習、強化学習など、多様な学習手法が存在
- 線形モデル、決定木、SVM、ディープラーニングなど、問題に応じた手法選択が重要
- 画像認識、自然言語処理、レコメンデーションなど、幅広い分野で活用
- データ品質、モデル評価、運用・更新が、機械学習導入のポイント

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
現代社会は、日々生成される膨大なデータに溢れています。しかし、そのデータを有効活用できている企業は多くありません。「データはあるけど、どう活かせば…」と悩んでいませんか?
その悩みを解決し、データから新たな価値を生み出す鍵となるのが「機械学習」です。しかし、その仕組みや具体的な活用方法を理解するのは容易ではありません。
本記事では、「機械学習」について、基礎から応用までをわかりやすく解説します。
機械学習の種類、主要な手法、ディープラーニングとの関係、そして様々な分野での活用事例まで、幅広く網羅的に説明します。
目次
【ステップ2】データセット (CIFAR-10) の読み込み
【ステップ5】 CNN(畳み込みニューラルネットワーク)の構築
これらの事例は、機械学習がさまざまな分野で実用化され、私たちの生活やビジネスに大きな影響を与えていることを示しています。
機械学習とは

機械学習(Machine Learning)は、データから規則性やパターンを学び、自動的に精度を高めていくアルゴリズムや手法の総称です。
人間が明示的なルールを記述しなくても、コンピュータが経験(データ)を通じて改良を重ねることで、高度な予測や分類を実行できる点が特徴です。
この技術は、インターネット検索、画像認識、音声アシスタント、レコメンデーションなど、私たちの日常生活からビジネスの高度化まで、幅広く活用が進んでいます。
なぜ機械学習が重要なのか?
近年、ビッグデータや計算資源の増加に伴い、人間が処理しきれない膨大な情報から有用な知見を引き出す必要が生じました。
機械学習は、その膨大なデータを活用し、効率的・自動的にパターンを見抜くための強力なツールとして欠かせない存在となっています。
機械学習と統計学・データマイニングの違い
機械学習は統計学やデータマイニングにルーツがありますが、データから汎用的な予測モデルを自動構築し、精度向上を目指す点で実装指向が強いと言えます。
統計学が厳密な仮説検定やモデル解釈に重点を置く一方、機械学習は汎用的な予測性能やモデル適用性にフォーカスするケースが多く見られます。
【関連記事】
機械学習と統計学の違いとは?データサイエンスにおける役割を解説
機械学習の主要な学習パラダイム
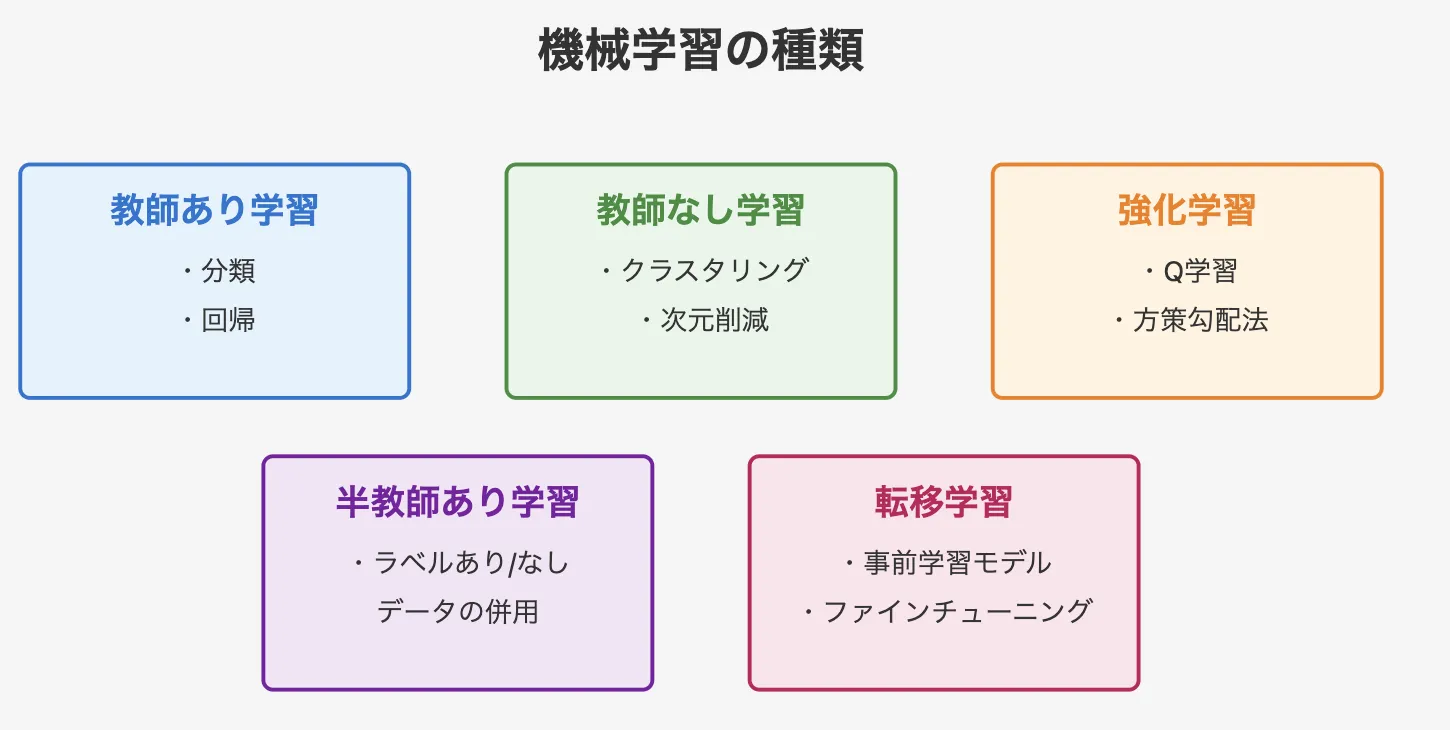
機械学習の種類
機械学習には、データとラベルの有無や目的に応じて、いくつかの学習パラダイムが存在します。これらを理解することで、課題に適した手法を選びやすくなります。
教師あり学習(Supervised Learning)
教師あり学習は、入力データに対して正解ラベル(例:画像に対するカテゴリ)が与えられている状態でモデルを学習します。
- 分類問題:メールがスパムか否か、画像が犬か猫か
- 回帰問題:不動産価格予測、売上予測など
教師あり学習は、正解データが存在するため、精度評価やモデル改善が明確に行いやすい点が特徴です。
【関連記事】
教師あり学習とは?その種類やアルゴリズム、実装方法をわかりやすく解説
教師なし学習(Unsupervised Learning)
教師なし学習は、データに正解ラベルがなく、モデルが自力でパターンや構造を探し出すアプローチです。
- クラスタリング:顧客データを似たグループに分類
- 次元削減:高次元データをコンパクトな要約に圧縮
未知構造の探索や特徴抽出に役立ち、データ理解や新たな知見発見を支援します。
【関連記事】
教師なし学習とは?その仕組みや教師あり学習との違い、実装方法を解説
強化学習(Reinforcement Learning)
強化学習は、エージェント(AI)が環境との相互作用を通じて試行錯誤しながら、最大の報酬を得るように学習するアプローチです。
教師あり学習のように正解ラベルが存在せず、エージェント自身が経験を通じて最適な行動を見つけていきます。
- 行動の最適化:ゲームAIが最善手を学ぶ、ロボットが歩行を習得する
- 意思決定の強化:自動運転の経路選択、株式取引の戦略最適化
エージェントは、状態を観察し、行動を選択し、その結果として報酬を受け取ります。このサイクルを繰り返すことで、長期的に最も高い報酬を得られる行動を学習 します。
強化学習は、明確な正解がない状況でも最適な判断を行う能力を持ち、ゲームAIや自動運転、ロボティクスなど、試行錯誤を重ねて学ぶ必要のある分野で活用されています。
【関連記事】
強化学習とは?その仕組みや主要アルゴリズム、実装方法を解説
機械学習の主な手法
transformerのアーキテクチャ 参考:論文
機械学習の主な手法には、線形モデル、決定木、サポートベクターマシン、ディープラーニングがあります。それぞれの特徴を表にまとめました。
| 手法 | 特徴 | メリット | デメリット |
|---|---|---|---|
| 線形モデル (ロジスティック回帰・線形回帰) |
特徴量と出力の関係を線形でモデル化 | シンプルで解釈しやすい、計算が軽い | 複雑なパターンの学習が苦手 |
| 決定木・ランダムフォレスト | 条件分岐を用いた分類・回帰手法 | 解釈しやすく、少ない前処理で利用可能 | 過学習しやすい(特に単体の決定木) |
| サポートベクターマシン(SVM) | 境界線(ハイパープレーン)による分類 | 高次元データにも適用可能 | 計算コストが高い、パラメータ調整が必要 |
| ディープラーニング | 多層ニューラルネットワークによる特徴抽出 | 複雑なデータから高精度な予測が可能 | 計算負荷が高く、大量データが必要 |
- 線形モデル(ロジスティック回帰・線形回帰)
シンプルで解釈しやすく計算コストも低いですが、複雑な関係を学習するのは苦手です。
- 決定木・ランダムフォレスト
データの条件分岐による直感的な分類が可能で、前処理も少なくて済みますが、過学習しやすい傾向が見られます。
- サポートベクターマシン(SVM)
高次元データに強く分類性能も高い一方、計算コストが大きく、パラメータ調整が難しい部分もあります。
ディープラーニングは、複雑なデータを高精度で処理が可能ですが、大量のデータと計算資源が必要で、モデルの解釈性に難点があるケースも見られます。
これらの特徴を踏まえた上で、どの手法を使うのかを検討する必要があります。
また、機械学習の種類や手法については以下の記事で詳しく解説しています。上記に挙げた手法以外主要な方法の解説はもちろん、選び方についても解説していますのでぜひご覧ください。
参考記事:機械学習の代表的な手法一覧!フローチャートを用いて選び方を解説
ディープラーニングと機械学習の関係
ディープラーニングは機械学習の一分野ですが、その高い表現力と学習能力により、多くの分野で劇的な性能向上を実現しています。
特に、大量のデータと高性能な計算環境(GPUなど)を活用することで、従来の機械学習手法では困難だった課題を解決できるようになりました。
強みとしては、特徴抽出を自動化し、高次元データを扱える点が挙げられます。
一方、課題としては計算資源の確保、モデルの説明性の低さが考えられます。この課題に関しては技術の進歩により徐々に完全が見られる部分もあります。
実際に機械学習を手元で実装して動かしてみる
Google Colab を使って機械学習を実装する方法を、出力例と合わせて解説します。
画像分類を CIFAR-10 データセット を使って、CNN(畳み込みニューラルネットワーク)による画像分類を行います。
CIFAR-10 とは、10種類のクラス(飛行機、車、鳥、猫、鹿、犬、カエル、馬、船、トラック)を含む カラー画像データセット です。
以下は完成したコードの全貌です。
完成したコード
import tensorflow as tf
print("TensorFlow バージョン:", tf.__version__)
print("GPU 使用可能:", tf.config.list_physical_devices('GPU'))
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
# 日本語フォントをインストール(Google Colab 用)
!apt-get -y install fonts-ipafont-gothic > /dev/null
# Matplotlib に日本語フォントを設定
plt.rcParams['font.family'] = 'IPAGothic'
# CIFAR-10 データセットをロード
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
# データの形状を確認
print(f"訓練データ: {x_train.shape}, ラベル: {y_train.shape}")
print(f"テストデータ: {x_test.shape}, ラベル: {y_test.shape}")
# CIFAR-10のクラス名
class_names = ["飛行機", "自動車", "鳥", "猫", "鹿", "犬", "カエル", "馬", "船", "トラック"]
# 画像を表示
plt.figure(figsize=(10, 5))
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(x_train[i])
plt.title(class_names[y_train[i][0]])
plt.axis('off')
plt.show()
# 画像データを 0〜1 に正規化
x_train = x_train / 255.0
x_test = x_test / 255.0
model = keras.Sequential([
# 畳み込み層1 + プーリング層
keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(32, 32, 3)),
keras.layers.MaxPooling2D((2,2)),
# 畳み込み層2 + プーリング層
keras.layers.Conv2D(64, (3,3), activation='relu'),
keras.layers.MaxPooling2D((2,2)),
# 畳み込み層3
keras.layers.Conv2D(64, (3,3), activation='relu'),
# 全結合層
keras.layers.Flatten(),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(10, activation='softmax') # 出力層(10クラス分類)
])
# モデルの概要を表示
model.summary()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(x_train, y_train, epochs=10, validation_data=(x_test, y_test))
# テストデータで評価
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f"テスト精度: {test_acc * 100:.2f}%")
# 最初の10個のテスト画像で予測
predictions = model.predict(x_test[:10])
# 予測結果を表示
plt.figure(figsize=(10, 5))
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(x_test[i])
plt.title(f"予測: {class_names[np.argmax(predictions[i])]}")
plt.axis('off')
plt.show()
ここからは、各ステップに分けながら解説していきます!
---
### 【ステップ1】環境の準備
まず、Google Colab で新しいノートブックを作成し、ランタイムの設定を **GPU** にします。
GPU の確認:
```python
import tensorflow as tf
print("TensorFlow バージョン:", tf.__version__)
print("GPU 使用可能:", tf.config.list_physical_devices('GPU'))
出力例
TensorFlow バージョン: 2.18.0
GPU 使用可能: [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
ステップ 2: 必要なライブラリをインポート
必要なライブラリのインポートを行います。また、Google colabでは日本語の設定がされていないため、日本語表示用の設定も行います。
!pip install japanize-matplotlib
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
# Matplotlib に日本語フォントを設定
plt.rcParams['font.family'] = 'IPAGothic'
【ステップ2】データセット (CIFAR-10) の読み込み
# CIFAR-10 データセットをロード
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
# データの形状を確認
print(f"訓練データ: {x_train.shape}, ラベル: {y_train.shape}")
print(f"テストデータ: {x_test.shape}, ラベル: {y_test.shape}")
出力例
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170498071/170498071 ━━━━━━━━━━━━━━━━━━━━ 5s 0us/step
訓練データ: (50000, 32, 32, 3), ラベル: (50000, 1)
テストデータ: (10000, 32, 32, 3), ラベル: (10000, 1)
【ステップ3】データの可視化
# CIFAR-10のクラス名
class_names = ["飛行機", "自動車", "鳥", "猫", "鹿", "犬", "カエル", "馬", "船", "トラック"]
# 画像を表示
plt.figure(figsize=(10, 5))
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(x_train[i])
plt.title(class_names[y_train[i][0]])
plt.axis('off')
plt.show()
出力例

出力された画像
10枚の画像と、それぞれのラベルが表示されています。
【ステップ4】データの前処理
# 画像データを 0〜1 に正規化
x_train = x_train / 255.0
x_test = x_test / 255.0
【ステップ5】 CNN(畳み込みニューラルネットワーク)の構築
model = keras.Sequential([
# 畳み込み層1 + プーリング層
keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(32, 32, 3)),
keras.layers.MaxPooling2D((2,2)),
# 畳み込み層2 + プーリング層
keras.layers.Conv2D(64, (3,3), activation='relu'),
keras.layers.MaxPooling2D((2,2)),
# 畳み込み層3
keras.layers.Conv2D(64, (3,3), activation='relu'),
# 全結合層
keras.layers.Flatten(),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(10, activation='softmax') # 出力層(10クラス分類)
])
# モデルの概要を表示
model.summary()
出力例(モデルの構造)
Model: "sequential_2"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ conv2d_6 (Conv2D) │ (None, 30, 30, 32) │ 896 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ max_pooling2d_4 (MaxPooling2D) │ (None, 15, 15, 32) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ conv2d_7 (Conv2D) │ (None, 13, 13, 64) │ 18,496 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ max_pooling2d_5 (MaxPooling2D) │ (None, 6, 6, 64) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ conv2d_8 (Conv2D) │ (None, 4, 4, 64) │ 36,928 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ flatten_2 (Flatten) │ (None, 1024) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_4 (Dense) │ (None, 64) │ 65,600 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_5 (Dense) │ (None, 10) │ 650 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 122,570 (478.79 KB)
Trainable params: 122,570 (478.79 KB)
Non-trainable params: 0 (0.00 B)
【ステップ6】モデルのコンパイル
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
【ステップ7】モデルの学習
history = model.fit(x_train, y_train, epochs=10, validation_data=(x_test, y_test))
出力例(学習ログ)
モデルの実行には少し時間がかかります。ローカルの環境にもよるので、少し気長に待ってみてください。
Epoch 1/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 14s 6ms/step - accuracy: 0.3578 - loss: 1.7236 - val_accuracy: 0.5615 - val_loss: 1.2427
Epoch 2/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 5s 3ms/step - accuracy: 0.5914 - loss: 1.1663 - val_accuracy: 0.6261 - val_loss: 1.0592
Epoch 3/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 11s 4ms/step - accuracy: 0.6481 - loss: 1.0012 - val_accuracy: 0.6590 - val_loss: 0.9739
Epoch 4/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 8s 5ms/step - accuracy: 0.6857 - loss: 0.8969 - val_accuracy: 0.6688 - val_loss: 0.9326
Epoch 5/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 6s 4ms/step - accuracy: 0.7114 - loss: 0.8240 - val_accuracy: 0.6767 - val_loss: 0.9312
Epoch 6/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 10s 4ms/step - accuracy: 0.7345 - loss: 0.7597 - val_accuracy: 0.6796 - val_loss: 0.9241
Epoch 7/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 11s 4ms/step - accuracy: 0.7482 - loss: 0.7087 - val_accuracy: 0.6931 - val_loss: 0.8984
Epoch 8/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 10s 4ms/step - accuracy: 0.7652 - loss: 0.6588 - val_accuracy: 0.7087 - val_loss: 0.8462
Epoch 9/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 7s 4ms/step - accuracy: 0.7779 - loss: 0.6260 - val_accuracy: 0.7095 - val_loss: 0.8549
Epoch 10/10
1563/1563 ━━━━━━━━━━━━━━━━━━━━ 6s 4ms/step - accuracy: 0.7950 - loss: 0.5818 - val_accuracy: 0.7136 - val_loss: 0.8793
【ステップ8】モデルの評価
# テストデータで評価
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f"テスト精度: {test_acc * 100:.2f}%")
出力例
テスト精度: 71.35%
【ステップ9】予測の実行
# 最初の10個のテスト画像で予測
predictions = model.predict(x_test[:10])
# 予測結果を表示
plt.figure(figsize=(10, 5))
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(x_test[i])
plt.title(f"予測: {class_names[np.argmax(predictions[i])]}")
plt.axis('off')
plt.show()
出力例 →

出力結果
画像と「予測されたラベル」が表示されています。
しっかりと予測できていますね。
今回は、手描き文字を使うよりもさらに高度な画像分類の方法を簡単にお伝えしました。
この基礎的な流れを応用することでさらに複雑な機械学習の内容を実装することができるので、ぜひ試してみてくださいね。
機械学習の実用例

機械学習は私たちの実生活の多くの場面に活用されています。以下は簡単な機械学習の活用例です。
| 分野 | 活用例 | 具体的な用途 |
|---|---|---|
| レコメンデーション | ECサイト、動画配信サービス | ユーザーの行動履歴をもとに商品・コンテンツを推薦 |
| 画像認識 | 自動運転、医療診断 | 物体検出、医療画像解析 |
| 音声認識・自然言語処理 | スマートスピーカー、翻訳アプリ | 音声アシスタント、テキスト解析 |
| 需要予測・異常検知 | 在庫管理、設備監視 | 需要予測、故障予兆検知 |
具体的な機械学習の活用事例は以下のようになっています。
1. レコメンデーション
- Netflixのコンテンツ推薦システム
ユーザーの視聴履歴や評価データを基に、個々の嗜好に合った映画やドラマを推薦しています。ユーザーエンゲージメントの向上と視聴時間の増加を実現しています。
参考:Netflix Research – Recommender Systems
2. 画像認識
- Googleの皮膚疾患診断AI
ユーザーがスマートフォンで撮影した皮膚の画像を解析し、AIが病変を認識して診断を行います。医療アクセスの向上と早期診断が可能となります。
参考:Google Health – AI-powered dermatology tool
3. 音声認識・自然言語処理
- スマートスピーカー(例:Amazon Echo、Google Home)
音声コマンドを認識し、音楽再生、天気情報の提供、スマートホームデバイスの制御など、多彩な機能を提供しています。
ユーザーは音声だけで日常生活の多くのタスクを効率的にこなすことができます。
参考:Amazon Echo – Alexa
参考:Google Home – Google Nest
4. 需要予測・異常検知
- 小売業における需要予測
過去の販売データや市場動向を分析し、将来の需要を予測することで、在庫管理の最適化や欠品防止を実現しています。販売機会の損失を防ぎ、在庫コストの削減にも寄与しています。
参考:Google Cloud – Demand Forecasting
参考:Amazon Forecast – Machine Learning for Time Series Forecasting
これらの事例は、機械学習がさまざまな分野で実用化され、私たちの生活やビジネスに大きな影響を与えていることを示しています。
機械学習導入のポイントと課題
① データ品質と前処理
- 欠損値処理、外れ値除去、正規化などが不可欠です。
- 悪いデータでは良いモデルは作れないため、データの質や量が重要になってきます。
② 評価指標の選択
- 分類問題:精度、再現率、F1スコア
- 回帰問題:RMSE(平均二乗誤差)、MAE(平均絶対誤差)
実務ではビジネス目標に直結した指標を設定することが重要になります。
③ モデルの運用と更新
- 環境の変化に応じたモデルの再学習が必要です。
- モデルの監視と継続的な改善が求められる場合も多くあります。
機械学習と他分野の関係
機械学習は独立し、利用されるだけではありません。以下のような分野と関連させることで更なる新たな可能性を見出すことができます。
| 分野 | 関連性 | 具体的な関係性 |
|---|---|---|
| ビッグデータ・クラウド | 機械学習のデータ基盤 | クラウド環境でのデータ保存・処理、大規模計算 |
| AI倫理・規制 | 説明可能性、公平性 | 差別的予測やプライバシー問題の回避 |
| UI/UX設計 | ユーザーとの接点 | AIを活用した直感的なインターフェース設計 |
このように、機械学習は単なる技術ではなく、社会やビジネスの中で幅広く活用される存在となっています。
よくある質問(FAQ)
機械学習とAIは同じなのか?
タイトル
AI(人工知能)は包括的な概念であり、機械学習はその一部の技術領域です。機械学習は、AI実現のための有力な手段の一つと理解されます。
ディープラーニングがあれば他手法は不要か?
タイトル
ディープラーニングは強力ですが、すべてのケースで最適とは限りません。データ量や計算リソース、問題特性に応じて、線形モデルや決定木、SVMなどが有効な場合もあります。
機械学習を学ぶにはどうすればいい?
タイトル
Pythonなどのプログラミング言語、NumPyやscikit-learnといったライブラリを学び、実際のデータセットで試行錯誤することが有効です。また、オンラインコースや実践的なプロジェクトで経験を積むと理解が深まります。
まとめ
本記事では、機械学習の基本的な定義や重要性、教師あり・教師なし・強化学習といった学習パラダイム、代表的なアルゴリズム(線形モデル、決定木、SVM、ディープラーニング)、実用例、導入時のポイント、他分野との関係、FAQまで包括的に解説しました。
機械学習は膨大なデータから価値を生み出す中核技術であり、今後もさらなる発展と社会実装が見込まれます。ビジネスや研究、日常生活まで影響を及ぼし続けるこの技術を理解し、有効活用することで、新たなイノベーションの創出が期待されます。
AI総合研究所では、多彩な実績と知見を活かして企業のAI導入をサポートいたします。
企業規模や業種に合わせたカスタムプランもご用意しておりますので、ぜひお気軽にご相談ください。
【関連論文】
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012): ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems, 25.
🔗 論文リンク
概要:
畳み込みニューラルネットワーク(CNN)を用いた大規模画像分類手法を提案。ImageNetデータセットを用いた学習により、従来の手法を大きく上回る精度を達成。非飽和型活性化関数やドロップアウトを導入し、計算効率と汎化性能を向上させた。深層学習の発展に大きく貢献した研究。
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017): Attention Is All You Need. Advances in Neural Information Processing Systems, 30.
🔗 論文リンク
概要:
リカレントニューラルネットワーク(RNN)を使用せずにシーケンス処理を行うTransformerアーキテクチャを提案。自己注意機構(Self-Attention)とマルチヘッドアテンション(Multi-Head Attention)を活用し、並列計算を可能にすることで計算効率と性能を向上。WMT 2014の英独・英仏翻訳タスクにおいて最先端の性能を達成し、従来の手法を超えるBLEUスコアを記録。BERTやGPTなどの大規模言語モデルの基盤となり、自然言語処理だけでなく、画像や音声処理にも影響を与えた。










