この記事のポイント
 CUDAは、NVIDIAが開発したGPUを汎用計算に利用するためのプラットフォーム。
CUDAは、NVIDIAが開発したGPUを汎用計算に利用するためのプラットフォーム。- CUDAの活用により、ディープラーニング、数値シミュレーション、画像処理などの分野で高速化を実現。
- CUDAプログラミングの学習には、サンプルコードを用いた実践と最適化手法の理解が重要。

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AI、ビッグデータ解析、科学技術計算など、現代のコンピューティングにおいて、高速な並列処理は不可欠です。その鍵を握るのが、NVIDIAが開発した「CUDA」です。
CUDAは、GPUの計算能力を汎用的な目的で活用するためのプラットフォームであり、その登場は、GPUコンピューティングという新たな時代の幕開けとなりました。
この記事では、CUDAの基本概念から、その特徴、プログラミングの基礎、開発環境の構築方法、さらには性能を最大限に引き出すための最適化手法までを、初心者にも分かりやすく解説します。
また、実際に手を動かしながら学べるサンプルプログラムも用意しています。
さらに、CUDAがどのように社会に役立っているのか、ディープラーニングや数値シミュレーション、画像処理などの具体的な活用事例を通して、CUDAの可能性に迫ります。
NVIDIA CUDAとは
CUDA(Compute Unified Device Architecture)は、NVIDIAが2006年にリリースしたGPUを汎用計算に利用するためのNVIDIA独自のプラットフォームです。
それ以前は、GPUは主に「グラフィックス描画」に特化していました。
しかし、CUDAの登場により、GPUを利用した並列計算(GPGPU:General-Purpose computing on GPUs)が可能になり、科学技術計算やAI、ビッグデータ解析といった多くの分野で革新が進みました。

引用元:NVIDIA
昨今では、CUDAは単なるプログラミングツールを超え、GPUコンピューティングの事実上の標準プラットフォームとして広く認識されています。
NVIDIAの継続的な開発とエコシステムの拡充により、CUDAは高性能計算、機械学習、シミュレーション、3Dレンダリングなど、数多くの用途において最適な選択肢となっています。
GPUの基礎知識
【CPUとGPUの違い】
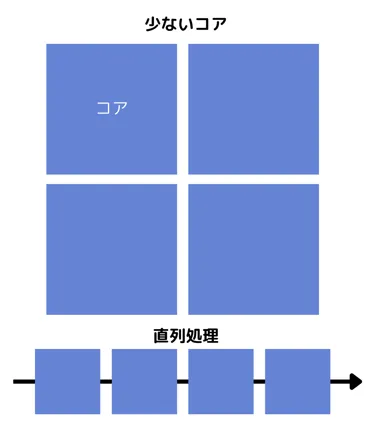
- CPU(中央処理装置)の特徴
CPUは数個から数十個の高性能なコアを持ちます。
各コアは非常に高いクロック速度を持ち、複雑なタスクを順番に(シリアルに)処理するのが得意です。
オペレーティングシステムの制御や日常のタスク(例:ブラウザ、文書作成など)などの計算負荷が軽い、もしくは順次処理が必要なタスクに使われます。
- GPU(グラフィックス処理装置)の特徴
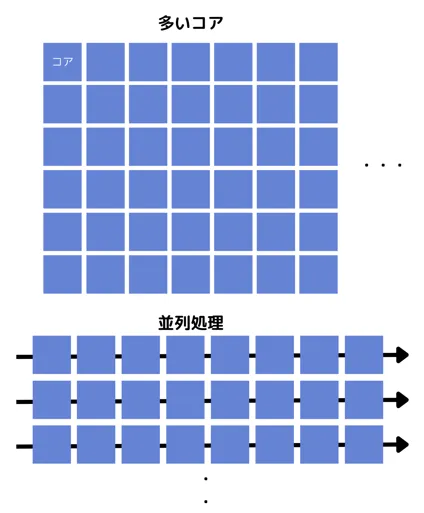
GPUは数千ものシンプルなコアで構成されます。
これにより、数千~数百万のデータ単位を同時に処理する「並列処理」が可能です。
元々は画像や映像を描画するために設計されましたが、現在では汎用計算(GPGPU: General-Purpose computing on GPUs)にも広く利用されています。
GPUが並列処理に優れる理由
GPUが並列処理に優れる理由は、大きく3つに分けられます。
- 膨大なコア数
GPUは、CPUと比べて圧倒的に多いコア数を持ちます。例えば、最新のNVIDIA GPUには数千のコアが搭載されています。
これにより、データを「分割して同時に処理」することができます。
- 高いスループット
GPUは、処理効率(スループット)を最大化するように設計されています。CPUよりも処理を高速に終わらせることが可能です。
- シンプルなコア設計
GPUのコアはCPUほど複雑ではありません。その代わり、単純な計算を大量に同時実行できるように最適化されています。
GPUが活躍する分野
GPUが活躍する分野は、いわゆる「AI」や「画像処理」の分野でその威力を発揮します。
- データ解析
ビッグデータを扱う分野では、大量のデータを一括で処理する必要があります。GPUの並列処理能力を活用することで、従来の計算よりも大幅に短時間で解析が可能です。
- ディープラーニング
ディープラーニングでは、ニューラルネットワークのトレーニングに大量の行列演算が必要です。
GPUは、このような行列演算を並列に処理することで、モデルの学習時間を大幅に短縮します。
3. CGレンダリング
映画やゲームに使用されるCGレンダリング(3Dグラフィックス生成)は、膨大なピクセルの計算を含みます。
GPUの並列処理は、この計算を効率的に行い、美しいリアルタイムグラフィックスを可能にします。
4. 科学技術計算
流体シミュレーションや天体物理学のシミュレーションなど、膨大な計算を必要とする科学分野で利用されています。
:::
CUDAの主な特徴
CUDAの特徴をまとめました。以下、3つの特徴を押さえておきましょう。
1.NVIDIA専用のGPUプログラミング拡張
CUDAは、CやC++などの一般的なプログラミング言語に対するNVIDIA独自の拡張を提供します。
開発者は、複雑な並列計算タスクを簡単に記述し、GPUの性能をフル活用できます。
2.主導的なGPUプラットフォーム
CUDAは、GPUを汎用計算に利用するための最初の大規模プラットフォームです。
ディープラーニングや科学技術計算の分野では、事実上の業界標準として広く採用されています。
3.豊富なエコシステムとサポート
- NVIDIAの公式ライブラリ
高速行列計算用のcuBLASやディープラーニング用のcuDNNなど、分野特化型のライブラリを提供。
- 開発ツール
NVIDIA Nsight ComputeやCUDA Toolkitなど、GPU最適化に特化したツールが揃っています。
- コミュニティの支援
世界中の開発者による豊富なドキュメントやフォーラムがあり、初心者から上級者まで広く活用できます。
CUDAプログラミングモデルの基本
Kernel, Grid, Block, Threadの概念
CUDAでは、並列計算をスレッド(Thread)という単位で処理します。
これらのスレッドはBlockにグループ化され、さらに複数のBlockが集まってGridを形成します。この構造により、GPU上で大規模なデータ処理を効率的に並列化できます。
1.Kernel関数
CUDAプログラムでは、GPU上で実行される関数を Kernel関数(カーネル関数) と呼びます。
通常、ホスト(CPU)側から呼び出され、デバイス(GPU)上で並列に実行されます。
__global__ void myKernelFunction(int *data) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
data[idx] = idx * 2; // 各スレッドが異なる計算を担当
}
【関連記事】
Kernel関数については、こちらの記事で詳しく解説しています。
→サポートベクターマシン(SVM)とは?その種類や利点、実装方法を解説
2.Grid, Block, Threadの階層構造
CUDAの並列計算は、以下の3つの階層構造で管理されます。
| 要素 | 役割 |
|---|---|
| Grid | すべてのBlockをまとめた構造。処理全体を指す。 |
| Block | いくつかのスレッドをグループ化した単位。 |
| Thread | 実際に計算を行う最小単位。個々のデータを処理する。 |
3. CUDAのスレッドインデックス計算
各スレッドは、threadIdx を使用して、自分のインデックスを特定できます。
例えば、1次元のデータを扱う場合、スレッドのインデックスは次のように計算できます。
int idx = threadIdx.x + blockIdx.x * blockDim.x;
例えば、blockDim.x = 256 の場合、Blockごとに256個のスレッドが割り当てられ、スレッドのインデックスは0~255(1つのBlock内)になります。
異なるBlockのスレッドは、全体のインデックスを求めるために blockIdx.x * blockDim.x を考慮する必要があります。
ホスト(CPU)とデバイス(GPU)の関係
1.CUDAにおけるCPUとGPUの役割
CUDAプログラムは、ホスト(CPU)とデバイス(GPU)の2つの側面を持ちます。それぞれの役割を明確にすることで、効率的なコードを書くことができます。
| コンポーネント | 役割 |
|---|---|
| ホスト(CPU) | プログラムの管理・制御を担当し、GPUの計算処理を指示 |
| デバイス(GPU) | 大量のデータ処理を並列で実行する |
2.ホストからデバイスへのデータ転送
CPU(ホスト)からGPU(デバイス)へデータを転送し、GPUで計算を実行した後、結果をCPUに戻す流れが一般的です。
int *d_data; // GPU側のポインタ
cudaMalloc((void**)&d_data, size); // GPUメモリ確保
cudaMemcpy(d_data, h_data, size, cudaMemcpyHostToDevice); // CPU→GPUにデータ転送
myKernelFunction<<<numBlocks, threadsPerBlock>>>(d_data); // Kernel関数を実行
cudaMemcpy(h_data, d_data, size, cudaMemcpyDeviceToHost); // GPU→CPUにデータ転送
cudaFree(d_data); // GPUメモリの解放
このデータ転送はオーバーヘッドになるため、できるだけ転送回数を減らすことがCUDAプログラムの最適化の鍵となります。
CUDAプログラムを書く際の制約
1.スレッド並列数の制約
| 制約項目 | 内容 |
|---|---|
| 1 Block内の最大スレッド数 | 最大1024(通常は256または512が推奨) |
| GridのBlock数 | 理論上は制限なし(ハードウェアに依存) |
2.メモリ使用量の制限
- **各GPUの共有メモリ(Shared Memory)**のサイズ制限。
- **グローバルメモリ(Global Memory)**の使用量が多いと性能が低下。
- テクスチャメモリやコンスタントメモリを活用して最適化可能。
NVIDIA CUDA Toolkitの構成とインストール手順
CUDA Toolkitの構成要素を理解し、スムーズにインストールを進めるための手順を詳しく解説します。
これからCUDAを用いた開発を始める方は最初の一歩を踏み出しましょう!
CUDA Toolkitに含まれる主要コンポーネント
GPUコンピューティングを効率的に実現するために、NVIDIAが提供する CUDA Toolkit は、開発者に必要なツールとリソースを一つにまとめた強力なパッケージです。
このセクションでは、CUDA Toolkitに含まれる主要なコンポーネントを紹介し、その機能や活用方法について詳しく解説します。
1.コンパイラ
nvcc(NVIDIA CUDA Compiler)は、CUDAコードをGPUで実行可能なバイナリにコンパイルするためのツールです。
nvccの特徴:
C/C++に対するCUDAの拡張構文を処理します。
CPUとGPUのコードを統合してコンパイル可能。
2.CUDA Toolkitのインストール
Windowsと同様CUDA Toolkit公式ページにアクセスしてLinux用のインストーラーをダウンロードします。
ダウンロードしたファイルを実行し、インストール時のオプションに従って進めます。
sudo sh cuda_<バージョン番号>_linux.run
3.環境変数の設定
まず、.bashrcまたは.zshrcファイルを編集します。
nano ~/.bashrc
以下を追加して
export PATH=/usr/local/cuda-<バージョン>/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-<バージョン>/lib64:$LD_LIBRARY_PATH
設定を反映します。
source ~/.bashrc
4.インストール確認
以下のコマンドでCUDA Toolkitが正しく動作しているか確認します。
nvcc --version
インストール時の注意点
インストール時の注意点をご紹介します。
ドライバとCUDAのバージョン互換性
使用するCUDA Toolkitのバージョンが、インストールしたNVIDIAドライバのバージョンと互換性があるか確認する必要があります。
互換性のリストは、NVIDIAの公式ドキュメントから確認しましょう!
GPUの対応モデルの確認
お使いのGPUがCUDA対応である必要があります。
対応しているモデルは、CUDA対応GPUリストから確認しましょう!
CUDA開発環境構築の実例
CUDAプログラミングを行うためには、適切な開発環境を整えることが重要です。
本では、「CUDA 開発環境」 の構築手順や、Visual Studio Code CUDA設定方法、nvccを使ったコンパイル、CMakeによるビルド設定、そしてデバッグやプロファイリングツールの活用方法について詳しく解説します。
CUDA開発環境に適したIDEの選択
CUDAプログラミングでは、C/C++の開発環境が必要になります。以下のIDE(統合開発環境)を使用すると、効率的に開発が行えます。
| 開発環境 | 特徴 |
|---|---|
| Visual Studio Code (VSCode) | 軽量で拡張機能が豊富、CUDAプラグインやCMake拡張が利用可能 |
| Visual Studio | WindowsでのCUDA開発に最適、NVIDIAが公式にサポート |
| Eclipse | クロスプラットフォーム開発向け、CUDAプラグインあり |
| CLion | CMakeベースの開発に強く、CUDAと組み合わせやすい |
特に、**「Visual Studio Code CUDA」**の組み合わせは、拡張機能を利用することで非常に快適な開発環境を構築できておすすめです!
CMakeを使ったCUDAプロジェクト設定
CUDAプロジェクトでは、CMakeを利用すると、異なるプラットフォームでのビルドが容易になります。以下は、CMakeLists.txtを使ってCUDAプロジェクトを設定する方法です。
CMakeとは?
CMake(シーメイク)は、C/C++のプログラムを簡単にビルド(コンパイル&リンク)できるツールです。
通常、C/C++のプログラムを実行可能なファイルにするには、手動でコンパイラ(gcc や clang など)を呼び出したり、複雑なMakefileを書いたりする必要があります。
CMakeを使うと、プロジェクトのビルドを簡単に管理できるようになります!
cmake_minimum_required(VERSION 3.18)
project(MyCUDAProject LANGUAGES CXX CUDA)
set(CMAKE_CUDA_STANDARD 14)
# CUDAアーキテクチャの設定
set(CMAKE_CUDA_ARCHITECTURES 75)
# 実行ファイルを作成
add_executable(my_cuda_program main.cu)
# CUDAコンパイラオプションを設定
set_target_properties(my_cuda_program PROPERTIES
CUDA_SEPARABLE_COMPILATION ON)
CMakeを使ったビルド手順は以下のようになります。
mkdir build
cd build
cmake ..
make -j$(nproc)
nvccコマンドを使ったコンパイル
CUDAのコンパイラnvccを直接使用して、CUDAコードをビルドする方法を解説します。
1.nvcc での基本的なコンパイル
nvcc -o my_cuda_program my_cuda_code.cu
2.nvcc のオプション例
nvcc -arch=sm_75 -O3 -Xcompiler "-Wall" -o optimized_program my_cuda_code.cu
ビルドエラーへの対処方法
CUDA開発では、以下のようなビルドエラーに遭遇することがあります。その時の対処法とともにまとめました。
| エラー | 原因 | 対処法 |
|---|---|---|
nvcc: command not found |
CUDA Toolkitが正しくインストールされていない | export PATH=/usr/local/cuda/bin:$PATH を追加 |
cuda_runtime.h: No such file or directory |
ヘッダーファイルが見つからない | export CPLUS_INCLUDE_PATH=/usr/local/cuda/include:$CPLUS_INCLUDE_PATH を設定 |
unsupported gpu architecture 'compute_86' |
nvccのバージョンが古い |
最新のCUDA Toolkitにアップデート |
fatal error: cudnn.h: No such file or directory |
cuDNNライブラリが見つからない | export CUDNN_INCLUDE_DIR=/usr/local/cuda/include を確認 |
nvcc fatal : Unsupported gpu architecture 'sm_90' |
使用しているGPUがCUDA Toolkitのバージョンに未対応 | 最新のCUDA Toolkitにアップデート |
Error: identifier "__shfl_down" is undefined |
旧バージョンのCUDAで新しいAPIを使用している | -arch=sm_xx を適切な値に変更 |
relocation R_X86_64_32 against '.rodata' can not be used |
ホストとデバイスのメモリ管理の設定ミス | -Xcompiler -fPIC をコンパイルオプションに追加 |
undefined reference to '__cudaRegisterFatBinary' |
CMake設定のミス、またはCUDAライブラリが適切にリンクされていない | target_link_libraries に cuda を追加 |
デバッグ・プロファイリングツールの活用
CUDAプログラムの最適化やデバッグには、NVIDIAの公式ツールが非常に有用です。ここではツールをいくつか紹介します!
1.Nsight Systems(プロファイリングツール)
**「Nsight Systems」**は、CUDAプログラムの全体的なパフォーマンスを解析するためのツールです。
Nsight Systemsを使ったプロファイリング手順
nsys profile -o my_profile_report ./my_cuda_program
2.Nsight Compute(カーネルプロファイラ)
**「Nsight Compute」**は、CUDAカーネルごとの詳細な実行パフォーマンスを分析するツールです。
Nsight Computeの基本的な実行
nv-nsight-cu-cli ./my_cuda_program
GPUメモリの使用状況や、スレッドの実行効率を可視化します。
CUDAのメモリモデルと最適化の考え方
CUDAを使ってGPUプログラムを高速化する際、メモリの使い方がパフォーマンスを大きく左右します。
特に、適切なメモリを選択し、効率的なメモリアクセスを実装することで、計算速度を飛躍的に向上させることができます。
CUDAのメモリモデルを解説し、最適なメモリアクセスの設計、バンク競合の回避、データ転送の効率化といった最適化手法について詳しく説明していきます!
CUDAのメモリ種類と特徴
CUDAには、さまざまな種類のメモリがあり、それぞれ異なる特性を持っています。以下の表に、それぞれのメモリの特徴をまとめました!
| メモリ種類 | アクセス可能範囲 | 遅延(レイテンシ) | 特徴 |
|---|---|---|---|
| グローバルメモリ (Global Memory) | GPU全体で共有 | 高 (400~600サイクル) | メインメモリ、サイズが大きいが遅い |
| シェアードメモリ (Shared Memory) | 各ブロック内のみ | 低 (~30サイクル) | 高速だが、各SM内で共有(48KB~96KB) |
| レジスタ (Register Memory) | 各スレッド専用 | 非常に低 (1サイクル) | 最高速だが、数に制限あり |
| テクスチャメモリ (Texture Memory) | GPU全体で共有 | 中 (キャッシュ付き) | 画像処理向け、2Dキャッシュを持つ |
| コンスタントメモリ (Constant Memory) | GPU全体で共有 | 低 (キャッシュ付き) | 読み取り専用、キャッシュを持つ |
メモリアクセスパターンと最適化手法
CUDAでは、メモリアクセスの最適化が非常に重要です。特に、グローバルメモリへのアクセスを最適化することで、大幅なパフォーマンス向上が期待できます。
1.Coalesced Access(協調アクセス)
グローバルメモリは 128バイト単位でデータをフェッチするため、連続したメモリアドレスにアクセスすることで転送の無駄を減らす ことができます。
スレッドが 連続したメモリアドレスを順番にアクセスする ように設計することが重要。
int idx = threadIdx.x + blockIdx.x * blockDim.x;
data[idx] = input[idx]; // 連続アクセス → 高速
悪いメモリアクセス
int idx = threadIdx.x;
data[idx] = input[idx * STRIDE]; // 非連続アクセス → 非効率
2.バンク競合(Bank Conflicts)の回避策
シェアードメモリ(Shared Memory) は、スレッド間でデータを共有できるため、グローバルメモリよりもアクセスが高速です。
しかし、適切に設計しないと バンク競合(Bank Conflicts) が発生し、スレッドが同時にアクセスできずに処理が遅くなることがあります。
【バンク競合の発生条件】
- シェアードメモリは、32個の バンク(Bank) に分かれており、スレッドが同じバンクの異なるアドレスに同時アクセスすると競合が発生。
- 競合すると、メモリアクセスがシリアル化 され、遅延が発生する。
バンク競合を回避する方法はパディング(Padding) を使い、各スレッドが異なるバンクを使うように調整することです。
__shared__ float sharedData[32 + 1]; // 1つ余分に確保し、バンクをずらす
int idx = threadIdx.x;
sharedData[idx] = input[idx]; // 競合を回避!
バンク競合が発生する例
__shared__ float sharedData[32]; // 32スレッドが1つのバンクに集中
int idx = threadIdx.x;
sharedData[idx] = input[idx]; // 同じバンクにアクセス → 競合発生!
3.メモリコピー (cudaMemcpy) と転送帯域幅の最適化
CPUとGPU間のメモリ転送は、大きなボトルネック になり得ます。以下の最適化手法を活用することで、転送時間を短縮できます。
デバイスメモリ(GPU)⇔ホストメモリ(CPU)間のデータ転送には、cudaMemcpy を使用します。
cudaMemcpy(device_data, host_data, size, cudaMemcpyHostToDevice); // CPU → GPU
cudaMemcpy(host_data, device_data, size, cudaMemcpyDeviceToHost); // GPU → CPU
プログラムのボトルネックになりやすいため、以下の方法で最適化すると、データ転送のオーバーヘッドを減らし、処理速度を向上できます。
| 最適化手法 | 効果 |
|---|---|
| ピン留めメモリ(pinned memory)を使う | cudaHostAlloc() を使用し、CPU-GPU間のデータ転送を高速化 |
| 非同期コピーを活用 | cudaMemcpyAsync() を使い、データ転送とカーネル実行を並行処理 |
| ページロックメモリを利用 | cudaMallocHost() でページロックメモリを確保し、転送効率を向上 |
| 転送回数を減らす | 大きなデータを一括転送し、小さな転送回数を減らす |
| ゼロコピー(Zero-Copy)を活用 | cudaHostRegister() を使い、ホストメモリを直接GPUで利用(低レイテンシ) |
統合メモリ(Unified Memory, cudaMallocManaged)を使用 |
自動的にデータを管理し、明示的なcudaMemcpyを削減 |
CUDA実践例:簡単なサンプルプログラム
CUDAを使ったGPUプログラミングの基本を学ぶには、実際のコードを書いて動かしてみるのが最も効果的です。
ここでは、CUDAの基本を理解するために、ベクトル加算、行列積、画像のグレースケール変換という3つの簡単なサンプルプログラムを紹介します。
それぞれのプログラムで、CUDAの基本構文 (<<<>>>)、スレッドとブロックの割り当て、メモリ管理のコツを学びながら、GPUを活用する方法を身につけましょう。
ベクトル加算のサンプルコード
ベクトル加算とは?
ベクトル加算は、2つのベクトル(配列)の各要素を加算し、結果を新しいベクトルに格納する処理です。各要素の加算は独立しているため、CUDAの並列処理に適しています。
以下のサンプルコードを実際に実行してみましょう!
#include <cuda_runtime.h>
#include <iostream>
// __global__ を使ってGPU上で実行するカーネル関数
__global__ void vectorAdd(const float* A, const float* B, float* C, int N) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) {
C[idx] = A[idx] + B[idx];
}
}
int main() {
int N = 1000;
size_t size = N * sizeof(float);
// ホストメモリの割り当て
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
float* h_C = (float*)malloc(size);
// データの初期化
for (int i = 0; i < N; i++) {
h_A[i] = i;
h_B[i] = i * 2;
}
// デバイスメモリの割り当て
float *d_A, *d_B, *d_C;
cudaMalloc(&d_A, size);
cudaMalloc(&d_B, size);
cudaMalloc(&d_C, size);
// ホストからデバイスへデータを転送
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// スレッドとブロックの設定
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
// カーネル関数の実行
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
// 結果をホストにコピー
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// 結果の確認
for (int i = 0; i < 10; i++) {
std::cout << "C[" << i << "] = " << h_C[i] << std::endl;
}
// メモリの解放
free(h_A); free(h_B); free(h_C);
cudaFree(d_A); cudaFree(d_B); cudaFree(d_C);
return 0;
}
実際に以下のような出力が出たでしょうか?
| Index | A | B | C (GPU Expected) |
|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 |
| 1 | 1.0 | 2.0 | 3.0 |
| 2 | 2.0 | 4.0 | 6.0 |
| 3 | 3.0 | 6.0 | 9.0 |
| 4 | 4.0 | 8.0 | 12.0 |
| 5 | 5.0 | 10.0 | 15.0 |
| 6 | 6.0 | 12.0 | 18.0 |
| 7 | 7.0 | 14.0 | 21.0 |
| 8 | 8.0 | 16.0 | 24.0 |
| 9 | 9.0 | 18.0 | 27.0 |
行列積(Matrix Multiplication)のサンプルコード
行列積とは?
行列積は、2つの行列AとBを乗算し、新しい行列Cを作成する計算です。CUDAではスレッドごとに1つの行列要素を計算するように設計することで、効率的に処理できます。
以下のサンプルコードを実際に実行してみましょう!
#include <cuda_runtime.h>
#include <iostream>
#define TILE_SIZE 16
// シェアードメモリを利用した行列積
__global__ void matrixMulShared(const float* A, const float* B, float* C, int N) {
__shared__ float Asub[TILE_SIZE][TILE_SIZE];
__shared__ float Bsub[TILE_SIZE][TILE_SIZE];
int row = blockIdx.y * TILE_SIZE + threadIdx.y;
int col = blockIdx.x * TILE_SIZE + threadIdx.x;
float sum = 0.0f;
for (int tile = 0; tile < (N + TILE_SIZE - 1) / TILE_SIZE; tile++) {
Asub[threadIdx.y][threadIdx.x] = A[row * N + tile * TILE_SIZE + threadIdx.x];
Bsub[threadIdx.y][threadIdx.x] = B[(tile * TILE_SIZE + threadIdx.y) * N + col];
__syncthreads();
for (int k = 0; k < TILE_SIZE; k++)
sum += Asub[threadIdx.y][k] * Bsub[k][threadIdx.x];
__syncthreads();
}
C[row * N + col] = sum;
}
以下のような結果はでましたか?
| Col 0 | Col 1 | Col 2 | Col 3 | |
|---|---|---|---|---|
| Row 0 | 4.0 | 4.0 | 4.0 | 4.0 |
| Row 1 | 4.0 | 4.0 | 4.0 | 4.0 |
| Row 2 | 4.0 | 4.0 | 4.0 | 4.0 |
| Row 3 | 4.0 | 4.0 | 4.0 | 4.0 |
画像をグレースケールに変換する簡単なサンプルコード
画像のグレースケール変換とは?
カラー画像(RGB)を、1つの輝度値(グレースケール)に変換する処理です。各ピクセルのRGB値を、Y = 0.299R + 0.587G + 0.114B の式で変換します。
以下のサンプルコードを実際に実行してみましょう!
__global__ void rgbToGrayscale(unsigned char* rgbImage, unsigned char* grayImage, int width, int height) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < width && y < height) {
int idx = (y * width + x) * 3;
unsigned char r = rgbImage[idx];
unsigned char g = rgbImage[idx + 1];
unsigned char b = rgbImage[idx + 2];
grayImage[y * width + x] = static_cast<unsigned char>(0.299f * r + 0.587f * g + 0.114f * b);
}
}
【内容例】
- ベクトル加算プログラムでGPUの基本的な動かし方を実践
<<<>>>構文によるスレッドの割り当て、__global__関数の書き方など
- 行列積(matrix multiplication)のサンプルでBlock・Threadの割り当て方のコツを説明
- 画像をグレースケールに変換する簡単なサンプルコードを紹介
以下のような結果はでましたか?
| R | G | B | Grayscale (GPU Expected) |
|---|---|---|---|
| 73 | 113 | 221 | 113 |
| 114 | 129 | 132 | 124 |
| 190 | 208 | 0 | 178 |
| 140 | 49 | 247 | 98 |
| 69 | 151 | 59 | 115 |
CUDAのユースケース
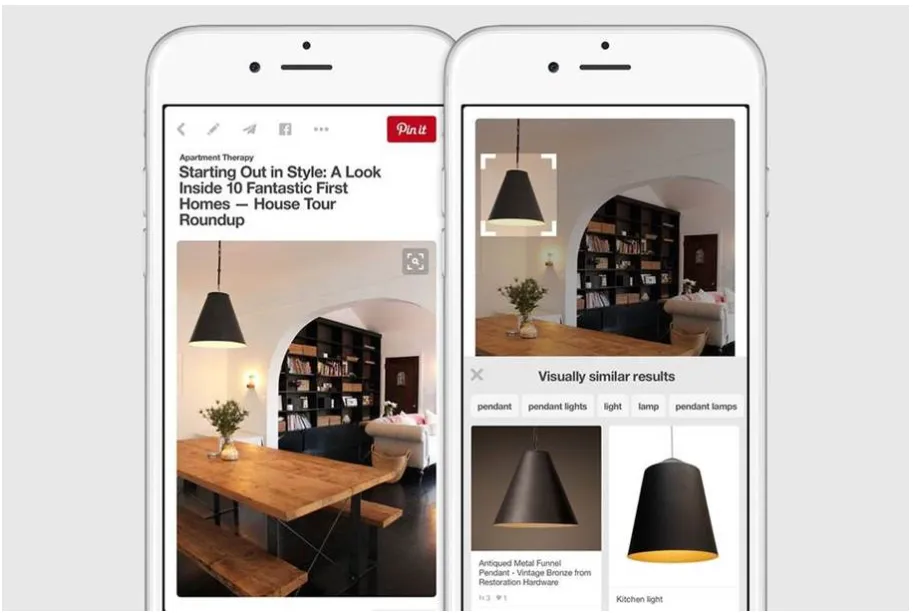
ディープラーニング(例:Pinterest)
引用元:NVIDIA
ディープラーニングや機械学習の分野では、大量のデータを高速に処理する必要があります。
CUDAを活用することで、GPUの並列処理能力を最大限に引き出し、モデルのトレーニング時間を大幅に短縮できます。
例えば、PinterestはGPUを活用したディープラーニングで大量の画像を認識し、ユーザーがピンを作成し、注釈をつける際の支援を行っています。
数値シミュレーション

引用元:NVIDIA
科学技術計算、流体解析、分子動力学などの数値シミュレーションでは、膨大な計算量が求められます。
CUDAを用いることで、これらの計算を効率的に並列処理し、シミュレーションの精度と速度を向上させることが可能です。
具体的な企業事例として、カナダのフィンテック企業 Wealthsimple が、機械学習モデルのデプロイと推論のパフォーマンス向上のために NVIDIA Triton Inference Server を活用しています。
Wealthsimpleは、CUDAを活用することで、モデル推論のスループットを向上させ、運用コストを削減しました。特に、金融市場の動向分析やユーザー向けのカスタマイズサービスの改善に貢献しています。
画像処理

引用元:NVIDIA
映像編集ソフトや3Dレンダリングなどの分野でも、CUDAは重要な役割を果たしています。
GPUの並列処理能力を活用することで、リアルタイムでの高品質なレンダリングやエフェクトの適用が可能となり、クリエイティブな作業の効率化が図れます。
例えば、AdobeのDeepFontは、GPUを活用してキャプチャした画像の曲線やその他の特性を調べ、20,000種類ものフォントを抱えるデータベースと照合することで、デザイナーを支援しています。
まとめ
CUDAは、GPUの並列処理能力を活用することで、ディープラーニング、数値シミュレーション、画像処理、自動運転、ゲーム開発などの分野で計算速度を飛躍的に向上させます。特に、TensorFlowやPyTorchといったフレームワークとの統合により、AIモデルのトレーニングや推論を効率的に行うことが可能になります。
また、CUDAプログラムを開発する際には、適切なメモリアクセスの設計や最適化が重要であり、共有メモリの活用や協調アクセス(coalesced access)によって、処理性能を最大限に引き出すことができます。さらに、開発環境の構築、コンパイルエラーやGPUドライバの問題解決についても理解を深めることで、スムーズな開発が可能になります。
もしCUDAに興味を持ったら、次は実際にコードを書いてみることをおすすめします。まずは簡単なベクトル加算や行列積のプログラムからスタートし、徐々に最適化や実践的なアプリケーションにチャレンジしていきましょう!
また、AI総合研究所は企業のAI導入をサポートしています。導入の構想段階から、AI開発はもちろんのことRPAなどのシステム開発まで一気通貫で支援いたします。お気軽に弊社にご相談ください。
CUDAをマスターすれば、あなたのプログラムはもっと速く、もっとパワフルになります。ぜひ、GPUの可能性を最大限に活かして、新しいチャレンジを楽しんでください!











