この記事のポイント
 主成分分析(PCA)は多変量データを少ない軸に要約する次元削減技術です。
主成分分析(PCA)は多変量データを少ない軸に要約する次元削減技術です。- 高次元データの可視化や機械学習の前処理に役立ちます。
- 分散が最大となる方向(主成分)を抽出し、データ構造を効率よく表現します。
- Pythonのscikit-learnを使えば簡単にPCAを実装して試せます。
- 情報圧縮と構造把握に強力な効果があり、ビジネスやAI分野で幅広く活用されています。

Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
主成分分析(PCA)は、多数の変数を持つデータを、情報をできるだけ失わずに少ない軸にまとめる技術です。
データを「要約」し、「圧縮」するこのアプローチは、AI・統計分析・マーケティングなど幅広い分野で活用されています。
本記事では、主成分分析の基本的な考え方から、仕組み、実例、ビジネスでの活用場面まで、わかりやすく体系的に解説していきます。
主成分分析とは?
主成分分析イメージ画像
主成分分析とは、複数の変数があるデータから、本質的な情報をできるだけ保持しながら、次元(軸)の数を減らす技術です。
たとえば「身長」と「体重」という2つの指標を、「体格」という1つの概念でまとめるようなイメージに近いです。
もともと膨大な情報を持つデータを、より少ない指標で表現することで、
- データの可視化が容易になる
- モデルの過学習リスクを減らせる
- 処理速度が向上する
といったメリットが得られます。
なぜ主成分分析が必要なのか?
次元の呪いと主成分分析
現代のデータは、多数の特徴量(変数)を持つことが一般的です。
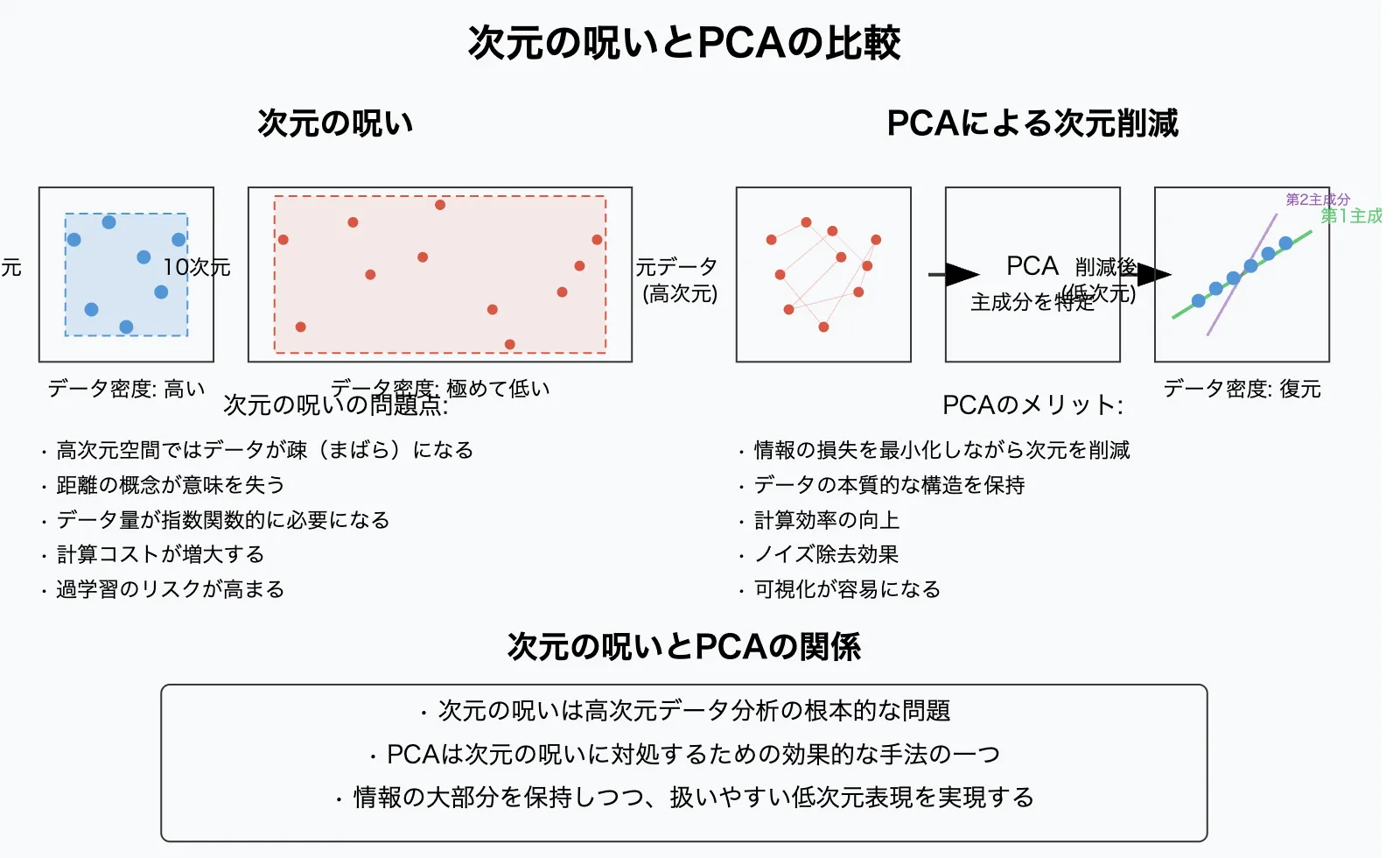
しかし、次元数が増えると、分析や学習が難しくなる「次元の呪い(Curse of Dimensionality)」 という問題が発生します。
- データが疎になり、統計的に意味のある分析が難しくなる
- モデルの学習が過学習しやすくなる
- データ可視化(グラフ化)が困難になる
こうした問題を解決するために、
「できるだけ情報を保ちつつ、次元を減らす」=主成分分析が使われるのです。
主成分分析により、
- 重要な情報は残しながら
- 冗長な情報やノイズを排除して
- シンプルで扱いやすいデータに変換できます。
主成分分析の仕組みを簡単に
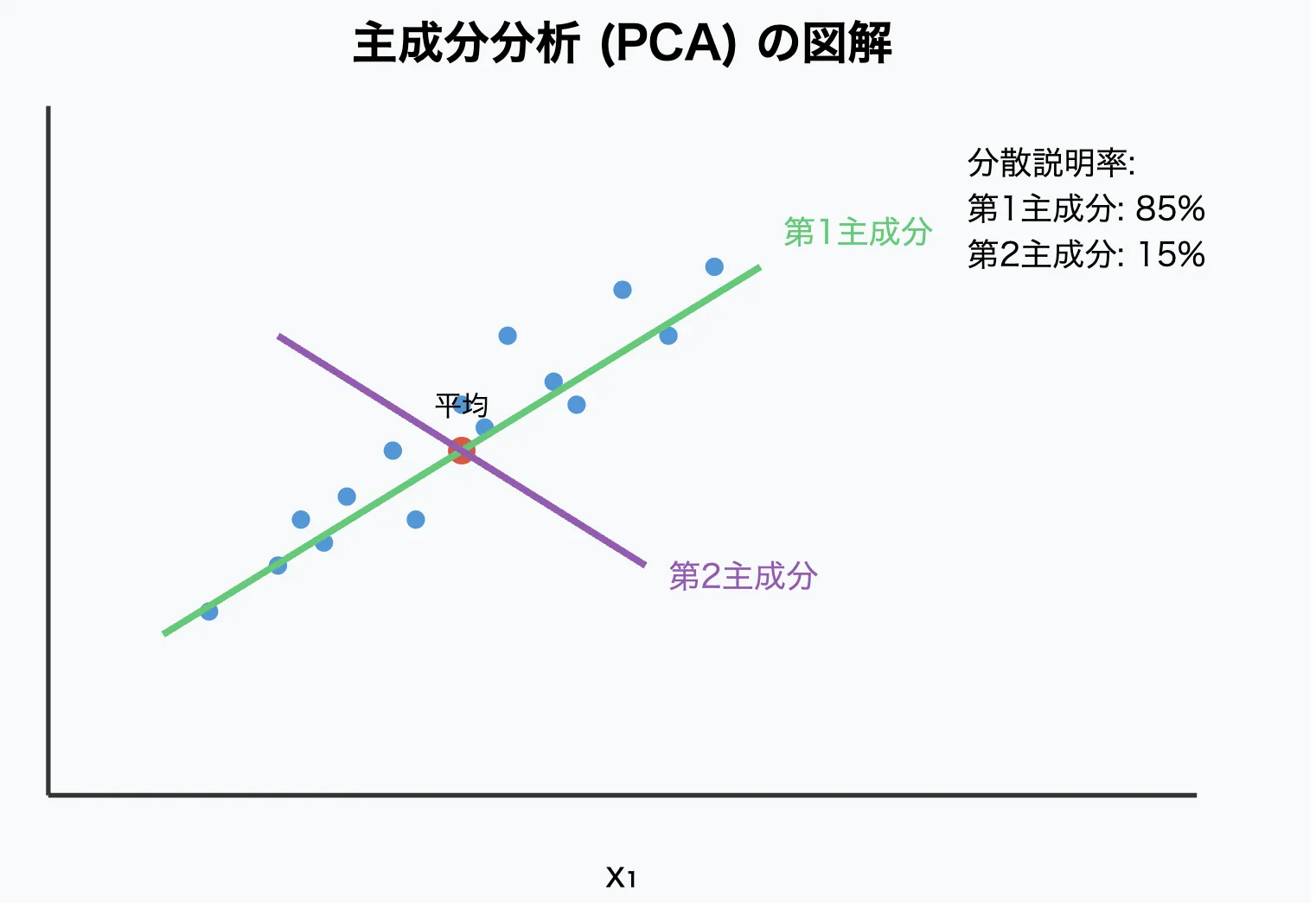
主成分分析のコアアイデアは、「データの分散(ばらつき)が最大になる方向を探す」 ことです。
つまり、データが広がっている方向に新たな軸(主成分)を取ります。
大まかな流れは以下の通りです。
- データを標準化する(スケールを揃える)
- 共分散行列を計算する(各特徴量同士の関連を測る)
- 共分散行列の固有ベクトルと固有値を求める
- 固有値の大きい順に、主成分として採用する
ここで重要なのは、
✅ 固有ベクトル=新しい軸(主成分)
✅ 固有値=その軸がどれだけデータを表現できるかの指標
ということです。
直感的には、
「ばらつきが大きい方向に新しい座標軸を取ることで、できるだけ情報を保持する」
と覚えておけば十分です。
Pythonで簡単に主成分分析を試してみよう!
実際の実行コード
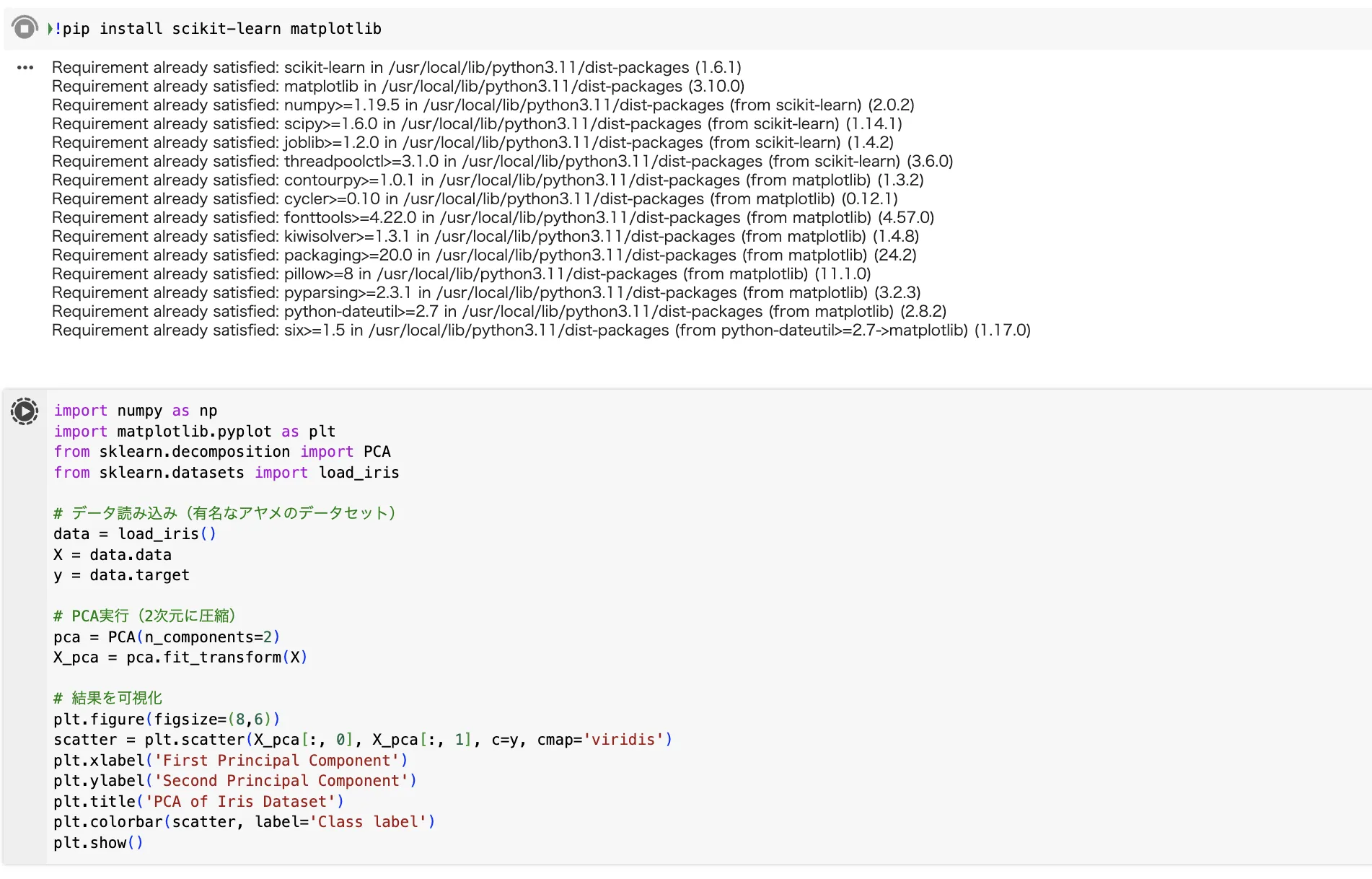
ここでは、Pythonライブラリscikit-learnを使って、簡単な主成分分析(PCA)を実装してみましょう。
✔ 必要なライブラリ
!pip install scikit-learn matplotlib
✔ コード例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
# データ読み込み(有名なアヤメのデータセット)
data = load_iris()
X = data.data
y = data.target
# PCA実行(2次元に圧縮)
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 結果を可視化
plt.figure(figsize=(8,6))
scatter = plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis')
plt.xlabel('First Principal Component')
plt.ylabel('Second Principal Component')
plt.title('PCA of Iris Dataset')
plt.colorbar(scatter, label='Class label')
plt.show()
✔ 実行結果のイメージ
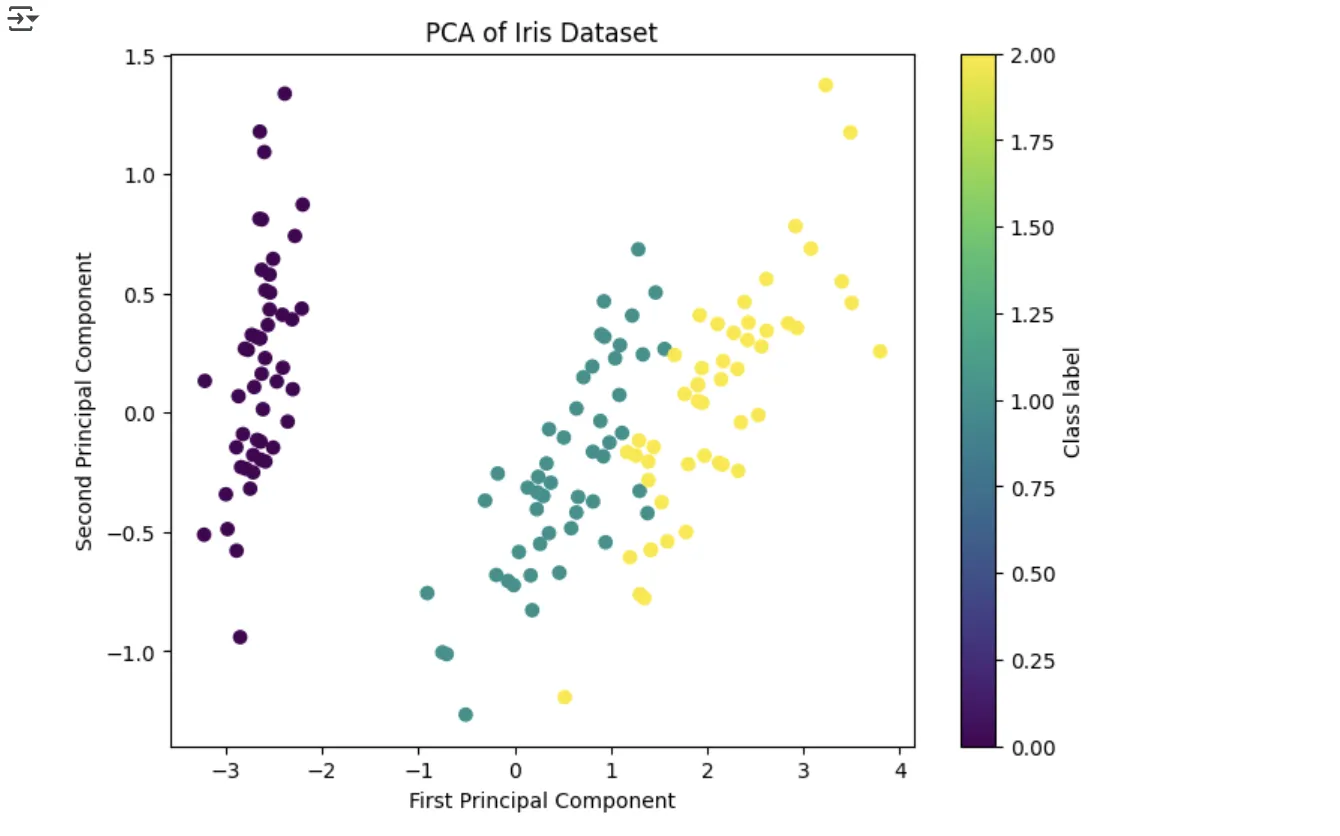
実際の出力結果
- もとの4次元データ(花びらの長さ・幅など)が2次元に圧縮され、分類パターンが可視化される
- 主成分軸に沿って、異なるクラス(花の種類)がある程度きれいに分かれる
主成分分析の実例(簡単なケーススタディ)
主成分分析がどのように役立つのか、具体例を見ていきましょう。
例①:顧客データの要約
ある企業が、顧客の「年齢」「年収」「購買回数」など多数の変数を持っているとします。
これらを主成分分析でまとめると、たとえば
- 第1主成分:顧客の購買意欲
- 第2主成分:年齢・所得水準
のように、ビジネス的に意味のある軸に要約できます。
例②:画像データの次元削減
顔写真など高次元なデータも、主成分分析によって特徴的な成分だけを抽出し、データサイズを大幅に削減することができます。
これにより、認識モデルの学習速度が向上し、精度も改善することがあります。
主成分分析の活用シーン
主成分分析(PCA)は、単なる次元削減にとどまらず、データの本質的な構造を明らかにし、意思決定やアルゴリズム性能に直接貢献する重要な役割を果たしています。
ここでは、特に実務で威力を発揮する具体的な活用シーンを深掘りして紹介します。
| 活用領域 | 主成分分析が果たす役割 |
|---|---|
| 機械学習 | 特徴量圧縮、学習高速化、汎化性能向上 |
| データ可視化 | 構造発見、仮説生成、パターン認識 |
| 異常検知 | 正常・異常の判別容易化 |
| マーケティング | 潜在指標抽出、ターゲティング精度向上 |
| リアルタイム処理 | ストリームデータ圧縮、通信・計算負荷軽減 |
1. 機械学習モデルの前処理:精度と学習効率の最適化
高次元データに対するモデル学習は、次元の呪いによりパフォーマンスが低下しやすくなります。
主成分分析を適用することで、情報を極力保持しながら特徴量を圧縮し、
- 学習スピードの向上
- 過学習リスクの低減
- モデル汎用性の向上
を同時に実現します。
特に、回帰分析、SVM、ニューラルネットワークなど次元に敏感なアルゴリズムとの相性が非常に良いです。
2. 高次元データの可視化:隠れた構造を浮かび上がらせる
PCAを用いることで、もともと人間が認識できない高次元データ(100次元、1000次元規模)を2次元または3次元に落とし込み、
- クラスタリング構造
- 異常点(外れ値)
- データ間の関係性
を直感的に把握できるようになります。
データ探索フェーズでのPCAプロットは、仮説構築や次ステップのモデリング方針決定に極めて有効です。
3. 異常検知:正常分布からの逸脱を捉える
高次元空間では、単純な距離ベースの異常検知が困難になります。
PCAによって、主要なばらつきを捉える低次元空間に射影することで、
- 正常データは主成分空間内に密集
- 異常データは外れた位置に現れる
という分離性が生まれます。
特に製造ライン監視、クレジットカード不正検知、セキュリティ分野での活用が進んでいます。
4. マーケティングデータ分析:多変量特徴の本質的要約
消費者行動データやアンケート調査データは、無数の変数(質問項目、行動ログ)を持ちます。
主成分分析により、
- 顧客関心度
- 購買意欲
- ブランド親和性
といった潜在的な構造を抽出し、少数の指標に要約することができます。
この要約結果をもとに、ターゲティング、パーソナライズ、セグメント別施策立案が可能になります。
5. 次世代データパイプラインへの組み込み:リアルタイム適応処理
近年では、PCAを単なる事後分析だけでなく、
- ストリームデータ処理
- エッジAIデバイス上での次元圧縮
- リアルタイム異常検知
といった即時処理パイプラインにも組み込む事例が増えています。
PCAを事前に適用して情報量を減らすことで、通信負荷や計算負荷を劇的に削減しつつ、即応性を損なわない設計が可能です。
主成分分析の注意点
便利な主成分分析にも注意すべきポイントがあります。
-
情報の一部損失
主成分数を減らすことで、どうしても細かな情報は失われる -
主成分の意味づけが難しい
抽出された主成分が、必ずしもビジネスで直感的にわかりやすいとは限らない -
標準化の必要性
単位やスケールが違うデータ(例:身長と収入)をそのまま扱うと、正しい主成分が得られないため、事前に標準化が必要なケースが多い
まとめ
主成分分析(PCA)は、
多変量データをコンパクトにまとめ、構造やパターンを効率よく把握するための基本技術です。
- 次元削減により、モデルの精度向上や計算負荷軽減に貢献
- 高次元データの可視化や異常検知にも広く活用
- 機械学習やビジネスデータ分析を支える必須スキルのひとつ
まずは、簡単なデータセットを使って、実際に主成分分析を試してみるところから始めましょう。
そこから、実践的なデータ活用へと応用を広げていくことができます。










