この記事のポイント
 クラスタリングは似たデータを自動でグループ化する教師なし学習手法です。
クラスタリングは似たデータを自動でグループ化する教師なし学習手法です。- データの構造を発見し、パターン把握やターゲティングに活用されます。
- 代表的な手法にはK-means、DBSCAN、階層型クラスタリングなどがあります。
- マーケティング分析や異常検知、医療データ解析など幅広い応用先があります。
- クラスタ数設定や初期値依存などの注意点を理解した上で使うことが重要です。

Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
クラスタリングは、データを「似たもの同士」でグループ化する教師なし学習の代表的な手法です。
膨大なデータの中から自然なパターンや構造を発見し、ビジネス、医療、マーケティングなど多様な分野で活用されています。
この記事では、クラスタリングの基本概念、代表的な手法、実例、そして活用方法についてわかりやすく解説します。
目次
例①:顧客データのクラスタリング ― 購買パターンの発見とターゲティング最適化
例②:Webアクセスログのクラスタリング ― 訪問者意図の分類とパーソナライズ
1. クラスタ数の設定問題 ― 最適な「K」は簡単にはわからない
クラスタリングとは?
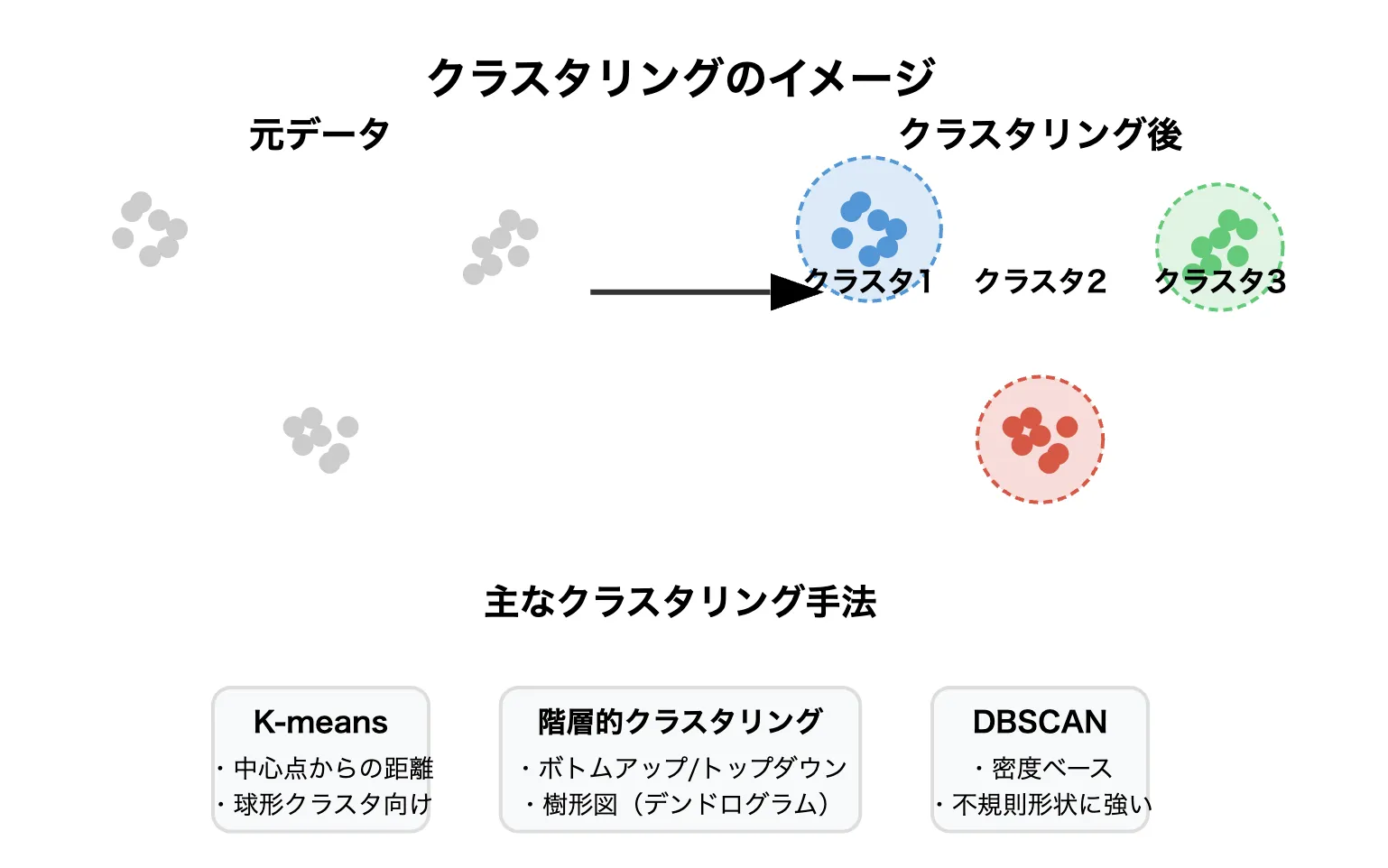
クラスタリングイメージ
クラスタリングとは、データをラベルなしの状態から、自動的に「似たグループ」に分類する手法です。
「教師なし学習(Unsupervised Learning)」に属し、あらかじめ答え(ラベル)が与えられていないデータに対して自然な構造を見つけ出します。
例えば、ユーザーの購買履歴やWebサイトのアクセスパターンをクラスタリングすることで、
- 似た傾向を持つ顧客層
- 共通した行動パターン
などを発見できます。
クラスタリング手法の代表例
代表的なクラスタリング手法は次の通りです。
| 手法 | 特徴 |
|---|---|
| K-means | データをK個のグループに分けるシンプルな手法。各グループの中心(重心)をもとに分類。 |
| 階層型クラスタリング | データ間の距離に基づき、木構造(デンドログラム)を作りながら統合・分割する。 |
| DBSCAN | データの密度に基づき、クラスタを形成。異常検知(ノイズデータの検出)にも強い。 |
| Gaussian Mixture Model (GMM) | クラスタを確率分布(ガウス分布)で表現し、柔軟な分類を実現する。 |
【関連記事】
主成分分析とは?意味・仕組み・活用方法をわかりやすく解説
AIアルゴリズムとは?その一覧やモデルごとの違い、活用例を徹底解説
なぜクラスタリングが重要なのか?
現代のデータは非常に多様かつ膨大です。
その中から有益なパターンを見つけるために、クラスタリングは大きな役割を果たします。
-
隠れたパターンの発見
目視では気づかないデータのグループを自動で見つけることができる。 -
ターゲティングの効率化
マーケティング施策や顧客対応を、クラスタ単位で最適化できる。 -
前処理としての活用
機械学習モデルの特徴量エンジニアリングにも役立つ。
このように、クラスタリングはデータ理解を深め、ビジネスや科学研究での意思決定を支えます。
Pythonで簡単なクラスタリングを試してみよう!
実際の実行画面
ここでは、Pythonのscikit-learnライブラリを使って、K-meansクラスタリングを実装してみます。
✔ 必要なライブラリ
!pip install scikit-learn matplotlib
✔ コード例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# サンプルデータ作成
X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# K-meansクラスタリング実行
kmeans = KMeans(n_clusters=4, random_state=0)
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
# 結果を可視化
plt.figure(figsize=(8,6))
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
# クラスタ中心を描画
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.75, marker='X')
plt.title("K-means Clustering Example")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()
✔ 実行結果のイメージ
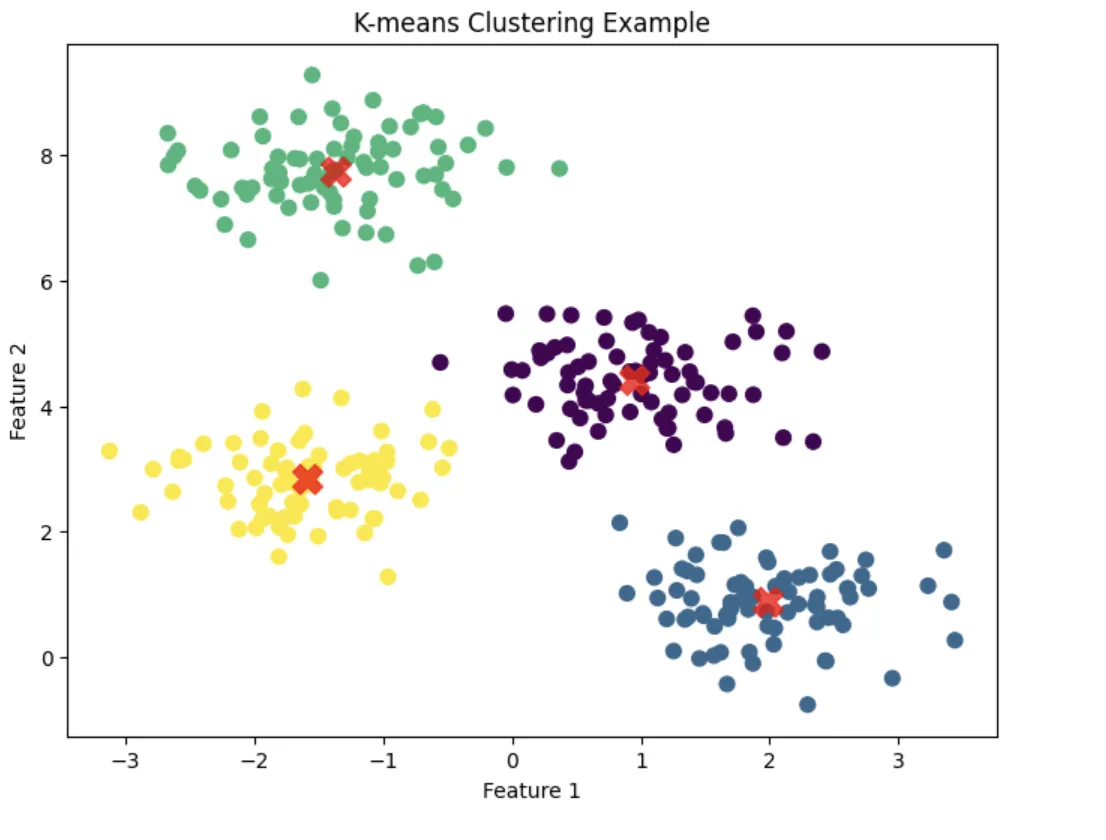
出力結果
- データ点が4つのグループに自動的に分類される。
- 各クラスタの中心(重心)が赤い×マークで表示される。
クラスタリングの実例(現場感のあるケーススタディ)
クラスタリングは、単なるデータ分割ではなく、未知のパターン発見や業務プロセス最適化に直結します。
ここでは、実際の活用イメージに即したリアルなケースを紹介します。
例①:顧客データのクラスタリング ― 購買パターンの発見とターゲティング最適化
- 顧客の「年齢」「購買頻度」「平均購入単価」「訪問頻度」などを特徴量に設定。
- K-meansや階層型クラスタリングを適用し、似た購買行動を持つ顧客群を自動抽出。
- 【発見例】
- 若年層・低頻度・高単価層(プレゼント需要型)
- 中年層・高頻度・低単価層(日常消費型)
➡︎ クラスタごとに異なる訴求(例:プレゼント向けキャンペーン、まとめ買い割引など)を実施し、CVR(コンバージョン率)を最大化。
例②:Webアクセスログのクラスタリング ― 訪問者意図の分類とパーソナライズ
- ページ閲覧履歴、滞在時間、クリックパターンをベクトル化しクラスタリング。
- 【発見例】
- 短時間・商品ページ直行型(購入意図強め)
- 長時間・比較ページ滞在型(検討段階)
➡︎ 各クラスタに応じて動的に表示コンテンツを切り替え(例:検討層には比較表を強調、購入層にはレビューとCTAボタンを最適表示)、LTV(ライフタイムバリュー)向上に貢献。
例③:異常検知への応用 ― 正常データから外れるものを検出
- IoTセンサー、製造ラインログ、ネットワークトラフィックなどを特徴空間にマッピング。
- 正常データクラスタの分布を学習し、それから大きく逸脱したサンプルを異常値とみなす。
【活用例】
- 製造業:ライン異常による不良品の早期検出
- サイバーセキュリティ:通常パターンから外れた通信を検出してインシデント対応を迅速化
➡︎ ラベルなしでも未知の異常パターンをリアルタイムで捕捉可能。
クラスタリングの活用シーン(業界別の具体化)
クラスタリングは業界や用途を問わず、パターン認識・構造発見・プロセス最適化に応用されています。
マーケティング領域
- 顧客セグメンテーション:自動的にグループを抽出し、パーソナライズ施策を高度化。
- キャンペーン最適化:クラスタごとにメッセージ、チャネル、タイミングを最適化し、ROI向上。
医療・ライフサイエンス領域
- 患者タイプ分類:症状・検査値・遺伝子情報などをクラスタリングし、新たな疾患サブタイプを特定。
- 治療最適化:クラスタごとに治療反応を分析し、パーソナライズドメディスン(個別化医療)推進。
製造業・インダストリー4.0
- プロセス最適化:製造条件や製品特性をクラスタリングし、最適工程を導出。
- 異常品検知:生産中のリアルタイムデータをクラスタリングし、即座に異常兆候を検出。
検索エンジン・情報検索
- コンテンツクラスタリング:類似記事や商品をグループ化し、レコメンデーション精度を向上。
- 検索クエリ意図推定:類似クエリをクラスタリングし、ユーザー意図を高精度で把握。
クラスタリングの注意点
クラスタリングは強力な手法ですが、特有の課題を理解していないと、
誤った解釈や非効率な施策につながるリスクがあります。
ここでは、代表的な注意点とその背景、対策までを整理します。
| 注意点 | 具体的な背景 | 実務での対策 |
|---|---|---|
| クラスタ数設定問題 | 最適な数はデータ次第 | エルボー法、シルエットスコア、ドメイン知識 |
| 初期値依存問題 | 初期中心で結果が変わる | 複数回初期化、K-means++使用 |
| スケール依存問題 | 単位・尺度の影響大 | 標準化・特徴量選定 |
| 評価の難しさ | ラベルがない | 内部・外部指標、ビジネス妥当性評価 |
1. クラスタ数の設定問題 ― 最適な「K」は簡単にはわからない
多くのクラスタリング手法(特にK-means)は、
クラスタ数(K)をあらかじめ決めなければならないという制約があります。
【問題点】
- 適切なKを設定できないと、過剰分割(オーバークラスタリング)または過少分割(アンダークラスタリング)になる
- 結果が解釈しづらくなり、施策精度が低下する
【実務での対策】
- エルボー法(SSE曲線) で膝点を探す
- シルエットスコアなどクラスタの凝集性・分離性を定量評価
- ドメイン知識と組み合わせて「ビジネス的に意味のある数」を優先する
2. 初期値依存問題 ― クラスタリング結果の不安定さ
K-meansでは、クラスタ中心の初期位置がランダムに決まるため、
初期値によって最終結果が変わる という問題が発生します。
【問題点】
- 異なる初期値で実行すると、クラスタの分割パターンがばらつく
- 最適解(グローバルミニマム)ではなく局所解に収束するリスクがある
【実務での対策】
- 複数回初期化(n_initパラメータ) して最良結果を採用(例:sklearnのデフォルトは10回)
- K-means++ など初期位置を賢く決めるアルゴリズムを使用
- 複数クラスタリング実行後、安定性を評価する(コンセンサスクラスタリング)
3. スケール依存問題 ― 距離ベースのアルゴリズムに致命的影響
クラスタリング手法の多く(K-means, 階層型など)は、特徴量間の距離(ユークリッド距離など) を基準にクラスタを形成します。
【問題点】
- 特徴量の単位やスケールが異なると、距離計算が歪み、特定特徴量が不当に支配的になる
- 例:年収(単位:万円)と年齢(単位:歳)では、年収が圧倒的に影響する
【実務での対策】
- 事前に標準化(平均0、分散1へ変換) を行う(StandardScalerなど)
- 特徴量選択・エンジニアリング段階でスケール感を意識する
- まれにドメイン知識で意図的に重みを変えることもある(重要度に応じた調整)
4. 評価の難しさ ― 教師なし学習ならではの課題
クラスタリングは正解ラベルが存在しないため、結果の良し悪しを絶対的に判断する基準が存在しません。
【問題点】
- 何をもって「良いクラスタリング」とするかが曖昧
- 主観的判断に依存しやすく、客観評価が難しい
【実務での対策】
- 内部評価指標(シルエットスコア、ダビース・ボルディン指数など)で定量評価
- 外部評価指標(もしラベルが一部存在するならARI、NMIなど)
- ビジネス指標との関連で最終評価する(例:「このクラスタ分けで売上が上がるか」)
まとめ
クラスタリングは、膨大なデータから自然なパターンや構造を発見するための強力な手法です。
適切な手法を選び、データ特性を理解した上で活用すれば、ビジネス、医療、研究など幅広い領域で大きな価値をもたらします。
まずは基本的なクラスタリング手法から試して、徐々に応用範囲を広げていきましょう。










