この記事のポイント
 RAGの基本概念と進化の歴史を解説し、AIモデルの最適化における位置づけを明確化
RAGの基本概念と進化の歴史を解説し、AIモデルの最適化における位置づけを明確化- リトリーバー(検索)とジェネレーター(生成)の具体的な手法と、それらの組み合わせ方を詳細に説明
- RAGを使用するメリットとデメリット、ファインチューニングとの違いを比較し、適切な活用法を提案
- RAGで効果的に使用できるデータの構造化、インデックス化、前処理方法を具体的に紹介
- ChatGPT、Microsoft Copilot、Azure AI検索など、実際のRAG実装方法と事例を詳しく解説

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
「RAG(検索拡張生成)と言う言葉を聞いたことはあるけど、その概要や実用性はよく分かっていない」という方が多いのではないでしょうか。
このRAGという技術は、ChatGPTなどのAIチャットボットなどに用いられる生成AI技術のひとつであり、ChatGPTをより賢くしたり、より自身の求めていることに適合 させる場合に非常に役立つ技術です。
本記事では、この大きな注目を集めるRAGについてもっと知りたい、わかりやすく理解したい方のために、最新論文や実例を交えながら徹底的に解説いたします。
本記事が、RAG技術を知り、活用をお考えの方の理解を深める一助となれば幸いです。
RAGとは
RAG(Retrieval-Augmented Generation)を既存のモデル、例えばChatGPTのようなAIに組み込むことで、AIの性能を向上させる技術的アプローチです。
具体的には、質問に答えたり、テキストを生成したりする際に、まず膨大な文書コーパスから関連する情報を検索するモデル を指します。
これは、既存モデルの知識ベースに、リアルタイムで情報を検索し追加する能力を付与することにより、回答の質と正確性を高めます。

RAGの進化
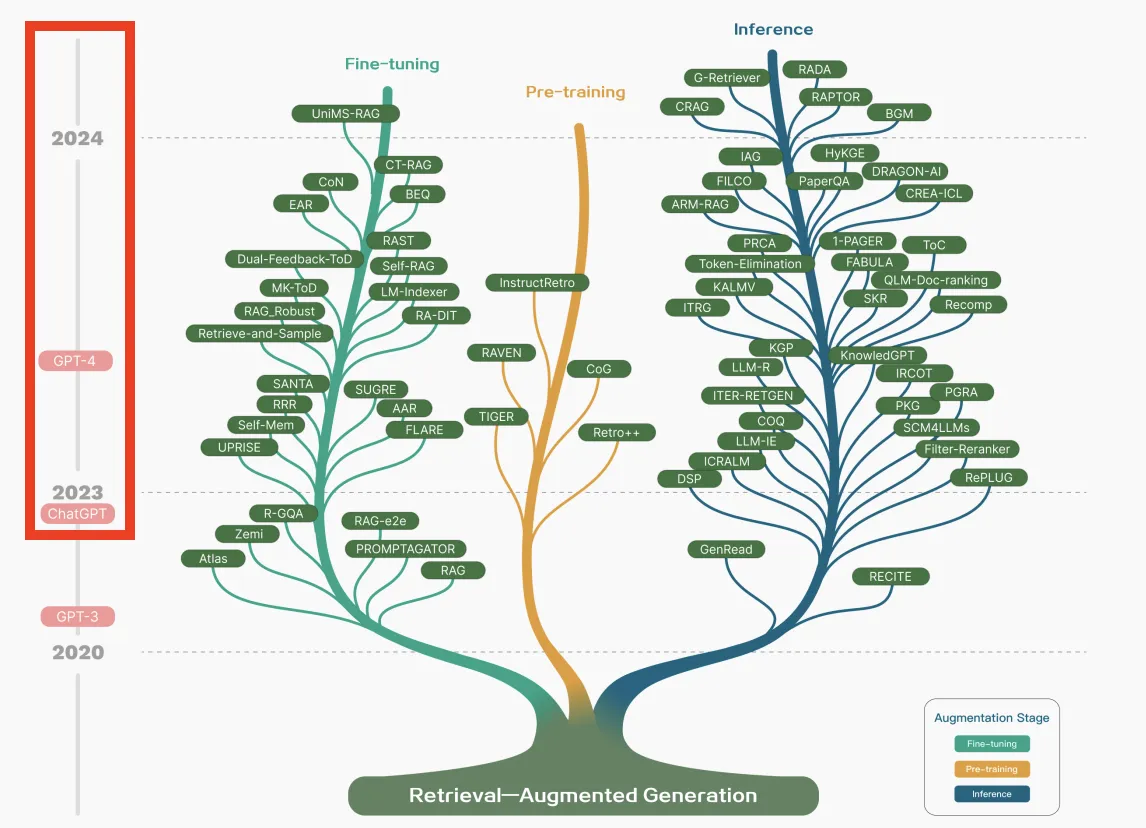
RAG研究のタイムライン
こちらは、RAG研究のタイムラインです。2023年以降大きく発展したことがわかります。
中央の木に書かれている分岐は、RAGの基づく様々なアプローチの手法を表しています。
RAGの仕組み
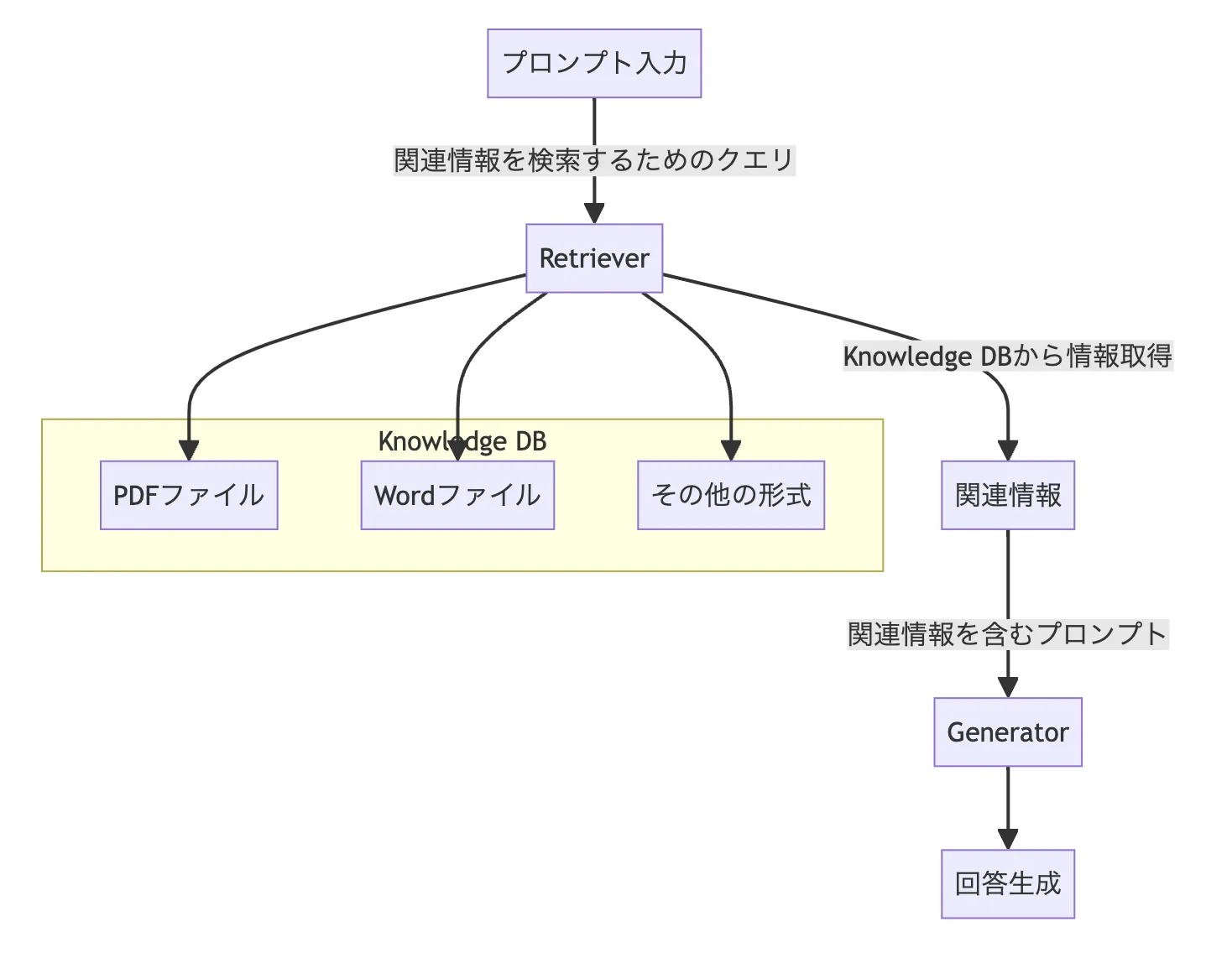
RAGの仕組み
RAGの仕組みをわかりやすく解説します。
図を参考にイメージしてみてください。
- プロンプト入力
ユーザーからの質問やコマンドが入力されます。
例)
AI総合研究所の運営会社はどこですか?
- 検索:Retriever
プロンプトを解析し、Knowledge DB(知識データベース)で関連情報を検索します。
例) このようなデータは元々のAIには含まれていない情報です。弊社の情報を読み込ませたかったら知識データベースをAIに加えて、そこを検索しにいきます。
---DB情報---
AI総合研究所の運営元:LinkX Japan株式会社
- 関連情報
Retrieverによって取得された情報です。
例)
DBから該当情報を抜き出します
- 拡張:Generator
取得された関連情報とプロンプトを基に、適切な回答を生成します。
例)
AI総合研究所の運営会社はLinkX Japan株式会社です。
- 回答生成
最終的にユーザーに回答が提供されます。
モデルの最適化とRAGの立ち位置
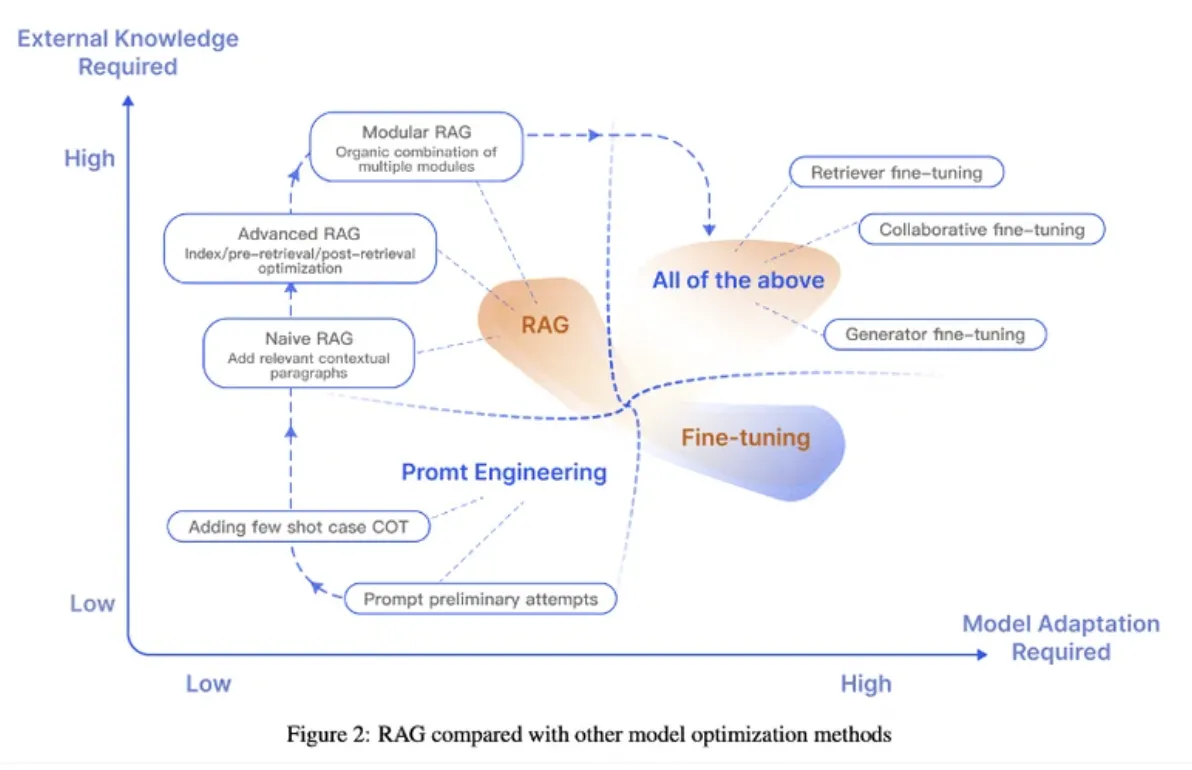
AIの最適化手法
RAGを含む様々なモデル最適化手法を、外部知識の必要度とモデル適応の必要度によって比較した図です。
ここでは4つの手法が挙げられています。
- プロンプトエンジニアリング(Prompt Engineering)
左下の「Prompt Engineering」は、比較的外部知識やモデルの適応が少なくて済む手法です。ここでは、事前学習されたモデルを使用し、入力プロンプトの工夫によって望ましい結果を引き出すことが重視されます。
【関連記事】
➡️プロンプトエンジニアリング完全ガイド!ChatGPTで使える例文も紹介
- RAG
RAGの位置は、この二つの軸の中間にあり、ある程度の外部知識(検索を通じて得られる情報)と、モデルの適応(モデルが検索情報を利用して答えを生成するための学習)の両方が必要とされます。
RAGの進化形として「Naive RAG」、「Advanced RAG」、「Modular RAG」といったバリエーションがあり、それぞれ様々な最適化手法が適用されています。これらはRAGにいくつかの改善を加えることで、より複雑なタスクに対応できるようにしたものです。
-
ファインチューニング(fine-tuning)
「Retriever fine-tuning」、「Collaborative fine-tuning」、「Generator fine-tuning」といったファインチューニングの異なる手法があります。これらは特定のタスクにおいて、モデルがより高い性能を発揮するよう適応させるための手法です。
-
組み合わせ(All of the above)
このアプローチは外部知識の利用が高いと同時に、モデル適応のための要求も高いと示されています。
つまり、多角的なアプローチを取り入れることで、モデルは複雑なタスクにおいても高度な性能を発揮できるようになるということです。
RAGの検索手法と拡張性の手法の紹介
RAGシステムの全体的なフレームワークの概要は以下の通りで、大きく検索と拡張に分類されます。RAGの検索(Retriever)部分と拡張性(Generator)の代表的な手法について解説します。
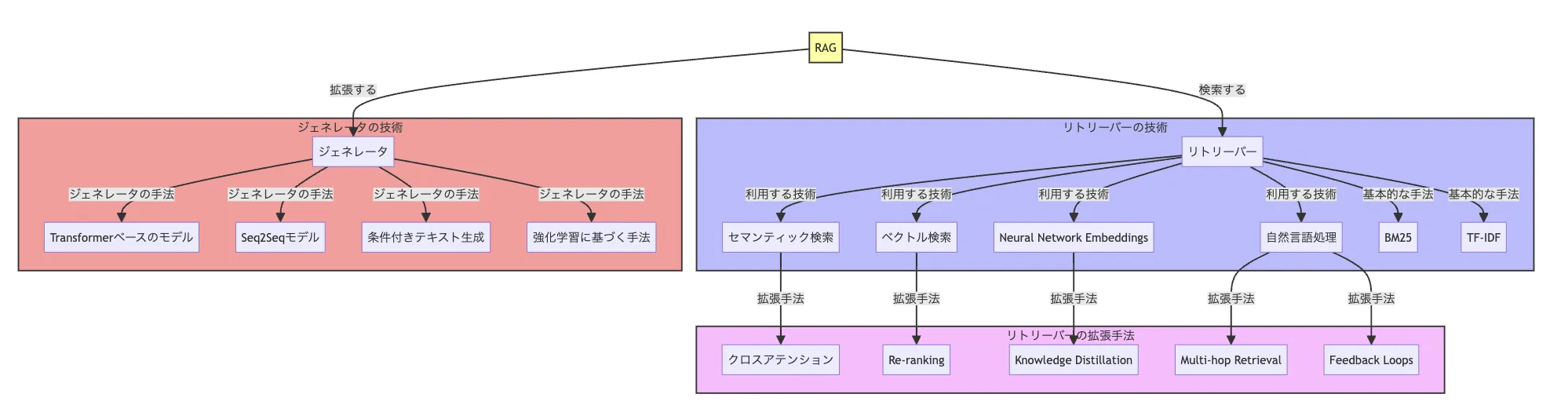
RAGの検索手法と拡張性の手法の概要図
図に描かれているのは、Retrieval-Augmented Generation(RAG)システムの構成とその機能を説明するものです。
RAGシステムは大きく分けて「リトリーバー」と「ジェネレーター」の2つの部分から構成されており、それぞれが特定のタスクを担当しています。これらの手法は組み合わせて利用されることもあり、相互補完的な役割を担います。
リトリーバー(検索)とは
リトリーバーは情報検索を担当 し、ユーザーのクエリに関連するデータを大規模なコーパスから見つけ出します。
以下の表は、それぞれの手法とその説明を示しています。
| 手法 | 説明 |
|---|---|
| セマンティック検索 | クエリの意味を理解して関連性の高い情報を検索します。 |
| ベクトル検索 | 文書とクエリをベクトル空間にマッピングして、意味的な類似性に基づいた検索を行います。 |
| Neural Network Embeddings | ディープラーニングを利用してテキストから意味的なベクトル表現を作成し、それによって検索を行います。 |
| 自然言語処理 | 言語の文法や意味構造を解析して、より効果的な検索を可能にします。 |
| BM25 | 文書検索において広く採用されている、単語の出現頻度と文書の長さを考慮したランキング関数です。 |
| TF-IDF | 各単語の重要性を評価するために「単語の出現頻度(TF)」と「逆文書頻度(IDF)」を使用し、文書内の単語の重み付けを行う手法です。 |
【関連記事】
➡️自然言語処理とは?AIが人間の言語を理解する仕組みをわかりやすく解説
リトリーバーの検索性能を向上させる拡張手法には以下が含まれます。
| 手法 | 内容 |
|---|---|
| クロスアテンション | 検索された情報とクエリとの関連を深めることで、より精度の高い検索を可能にします。 |
| Re-ranking | 検索結果を再評価して、より関連性の高い情報を上位に表示します。 |
| Knowledge Distillation | 大きなモデルから抽出した知識を小さなモデルに伝えて、効率的に検索を行います。 |
| Multi-hop Retrieval | 複数の情報源をつなげて、より複雑なクエリに回答するための情報を集めます。 |
| Feedback Loops | ユーザーフィードバックを利用してリトリーバーの検索アルゴリズムを改善します。 |
ジェネレーター(生成)とは
ジェネレーターは検索された情報をもとに、人間のような自然なテキスト を生成します。
| 手法 | 内容 |
|---|---|
| Transformerベースのモデル | 複雑な言語パターンを学習して高品質なテキストを生成する能力があります。 |
| Seq2Seqモデル | 入力されたテキストから新しいテキストを生成するために使用されます。 |
| 条件付きテキスト生成 | 特定の条件やスタイルに基づいてテキストを生成します。 |
| 強化学習に基づく手法 | 生成したテキストの品質を評価し、それに基づいてジェネレーターを改善します。 |
【関連記事】
➡️Transformer解説記事
RAGを使うメリット
RAGを使うことの最大のメリットは 学習していないはずのデータが追加できること にあります。いわゆる知識を拡張できるということであり、最新の情報やドメイン知識を用いることが可能になります。
また、生成AIのChatbotはしばしばハルシネーションと呼ばれる嘘をつくことが問題視されます。
想定される重要な内容については追加で学習しておくことでハルシネーションを抑制することが可能になるでしょう。
これらのメリットにより、結果として応答精度の向上に繋がり、使う人の使い勝手が良くなることがRAGを用いるメリットです。
RAGを使うデメリット
メリットがあるその一方で、デメリットも存在します。
- クラウド維持費に費用がかかることクラウドの維持費は計算コストが高いことにも起因します。
- RAGのデータの保守・運用が必要です。古いままのデータを用いてしまうと間違った情報が拡散されてしまいます。作って終わりではなく、情報の鮮度を保ち続ける必要があります。
- 実装の複雑さが考えられます。必要な学習データの選定、前処理、アルゴリズムの最適化などが必要になります。本当にRAGが必要であるかは検討する必要があります。
RAGとファインチューニングとの違い
追加でAIを学習する手法として比較されやすいファインチューニングとの違いをご説明します。大きく異なるところは、目的、手法が違います。
- 使われる目的
RAGは、情報検索や知識ベースの解答が得意であり、ファインチューニングは言語理解、翻訳、テキスト生成など自然言語処理の広範なタスクに利用されます。
- 手法
RAGは検索することによって回答を生成しますが、ファインチューニングはトレーニングデータをもとに回答します。
また、RAGはファインチューニングと協調して使うことも強力な手法です。プロジェクトにより最適な手法を選択しましょう。
RAGで使いやすいデータの持ち方とは

RAGで使いやすいデータの持ち方のポイント
RAG(Retrieval-Augmented Generation)システムを構築する際には、データの持ち方は精度を出す上でも非常に重要です。継続してRAGおよびAIを使っていくには、適したデータ保存方法を習得する必要もあります。
構造化データ
- 一貫性のあるフォーマットとデータ
データは構造化されたフォーマット(例えば、JSON、CSV、XML)で保存されるべきで同じ構造で保管されるべきです。データの読み込みや解析を容易にします。
- メタデータの利用
文書のタイトル、作者、発行日などのメタデータを含めることは、求めている情報や回答を検索しやすくなります。
インデックス化
- 全文検索インデックス:
データを検索エンジン(例えば、Azure AI searchやElasticsearch)にインデックス化しておくことで、効率的に情報を検索できるようになります。文書から重要なキーワードを抽出しておくことも重要です。
データの前処理
- ノイズの除去
データから不要な情報や雑音(例えば、HTMLタグ、余計なスペースや記号)を取り除くことが必要です。
- トークン化
テキストデータを意味のある単位(トークン)に分割し、検索や分析のための前処理を行います(私, は, AI総合研究所, ですのようなことです)。トークン化されたものは処理の過程でチャンク化されます(名詞句や動詞句など意味のある塊に抽出、私は、AI総合研究所ですのようなことです)。この過程をスムーズにするためにも前処理は重要です。
更新と維持
- データの更新
情報が常に最新であることを保つために、データソースを定期的に更新します。 - バージョン管理
データの変更履歴を保持し、必要に応じて以前の状態に復元できるようにします。
分散ストレージ
- スケーラビリティ
大量のデータを扱う可能性を考慮し、分散ストレージシステムを用いることで、データベースのスケーラビリティを確保します。これはクラウドやサーバーを確保します。
- 冗長性と耐障害性
データのバックアップと冗長性を確保し、障害時にもデータが失われないように配慮します。
RAGシステムでは、これらのデータの持ち方がシステムの性能に直結します。
RAGの実装方法
実際の実装方法をご紹介します。
今回は、ChatGPT、Microsoft Copilot、Azure AI 検索手法の方法をご紹介します。
ChatGPTで行う場合

知識の補填方法
RAGとはいえず、情報補填、情報理解という分類にはなりますが、ChatGPTは、有料課金をすることによりファイルの添付をすることができるようになります。
そこで簡単な、知識の補填が可能です。
また、プロンプトに情報を入力することで知識の補填をすることも可能です。
こちらは同様の方法でGPTsでも手軽に可能です。
Microsoft Copilot (Copilot Studio)で行う場合
Copilot Studioのトライアルページからすぐ試すことが可能です。
- WebサイトのURLを入力します。
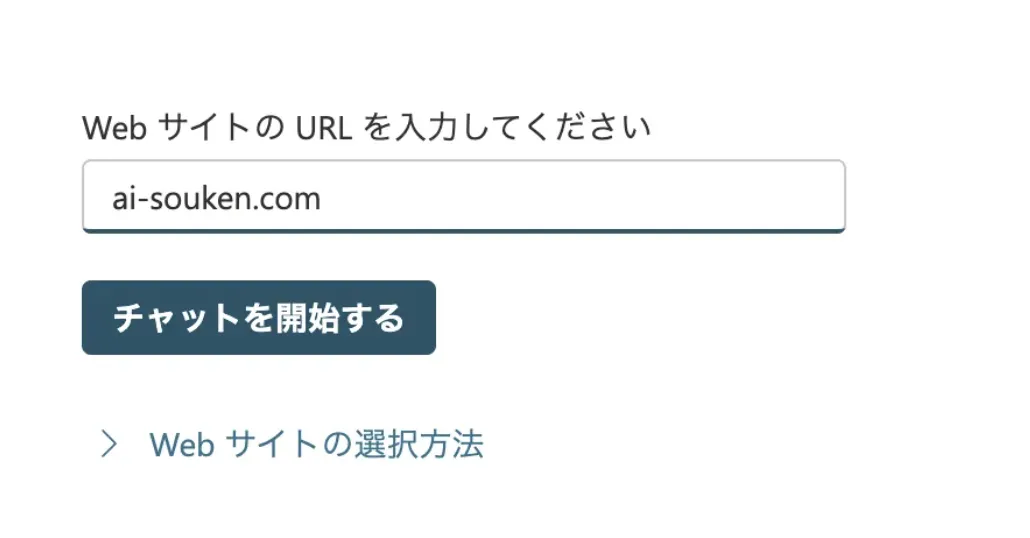
websiteのURL入力
- 簡単に情報を学習したチャットボットが作成されます
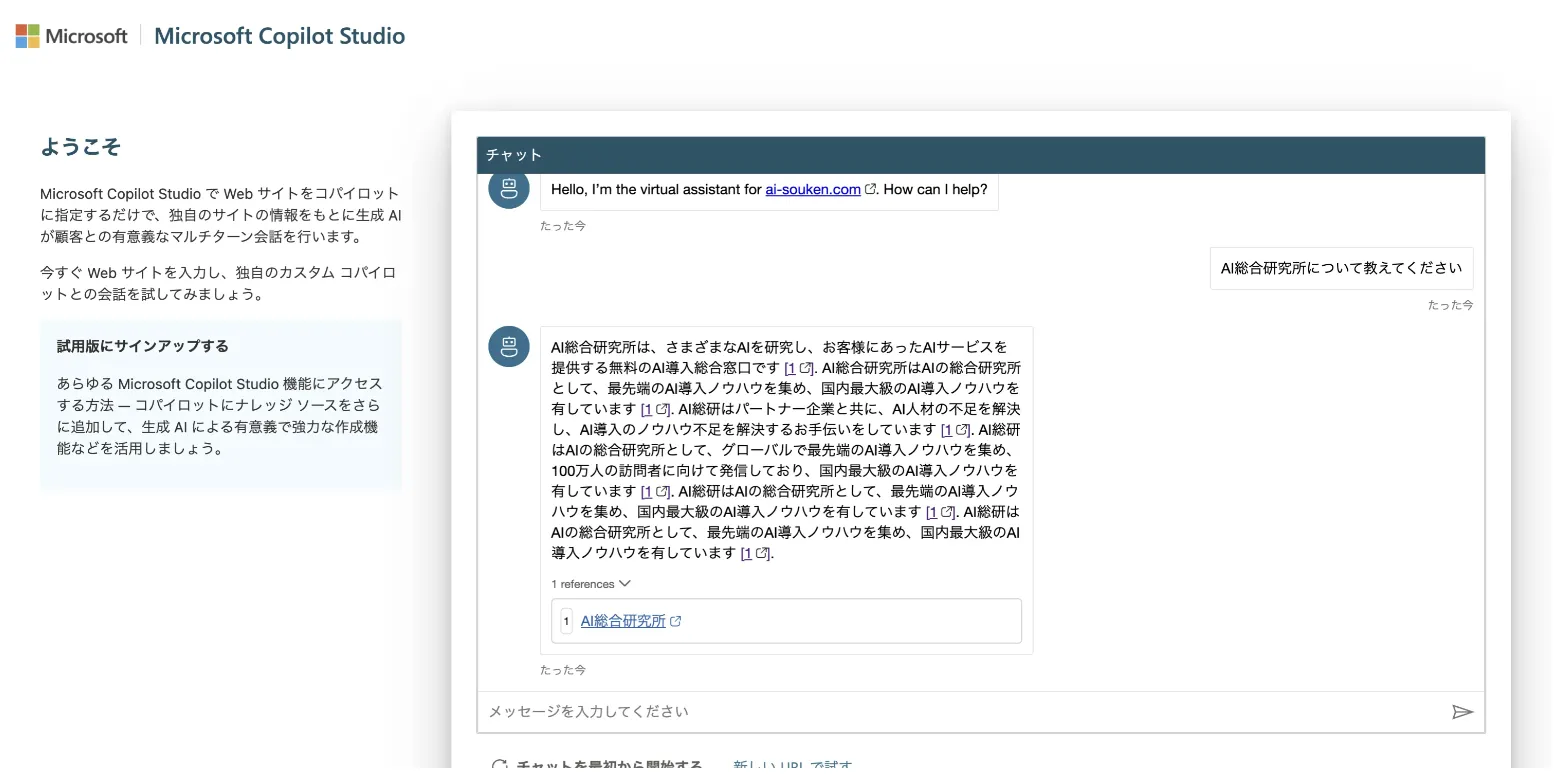
チャットbotの作成完了
【さらに詳しく知りたい方のために】
➡️本番用の作成方法も解説!Copilot studio解説記事
Azure(クラウドで行う場合)
AzureでRAGを構築するには大きく3つの工程を経ることで可能です。
- Azure OpenAI Studioを活用する
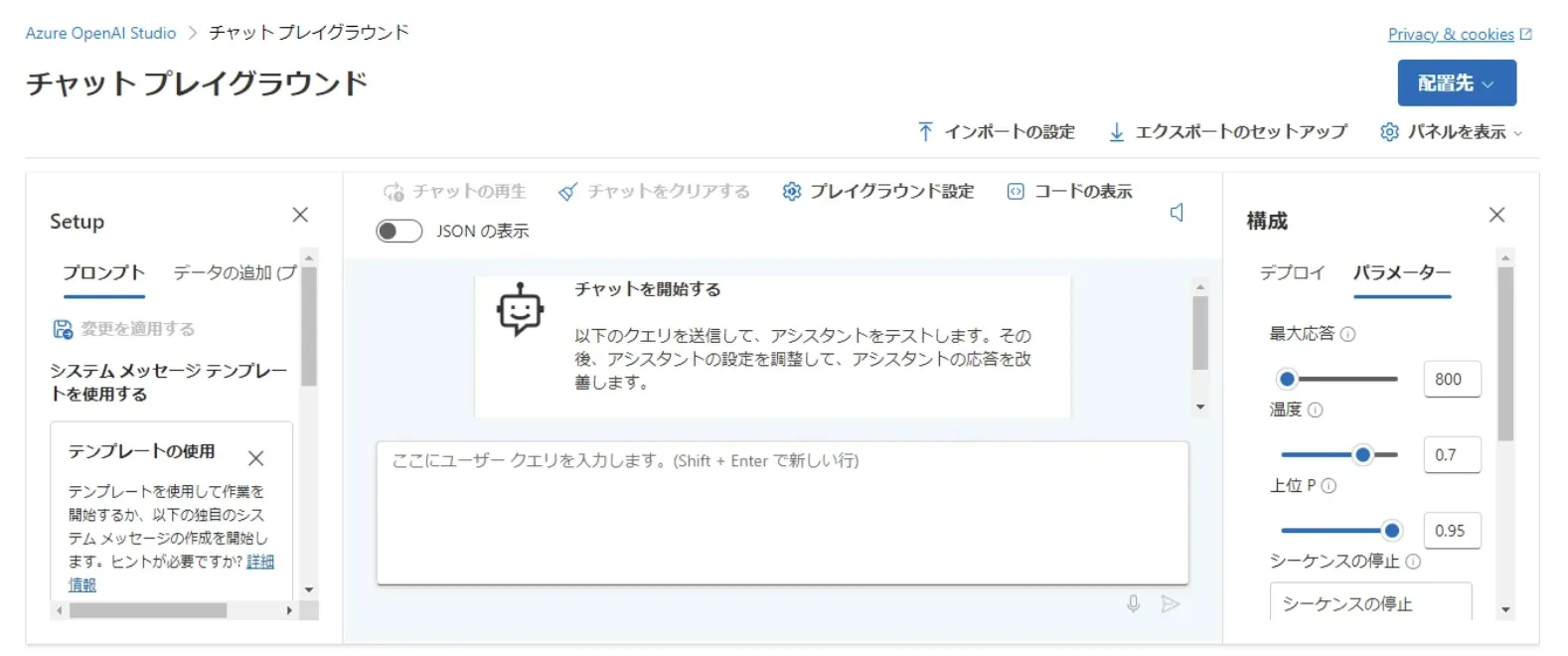
Azure OpenAI Studioのチャットボット画像
Azure OpenAI Studioは、Microsoft Azureが提供するサービスであるAzure OpenAI Serviceの、ウェブ上での統合開発環境です。
【関連記事】
➡️Azure OpenAI Studioの始め方や料金体系、デプロイ方法を徹底解説
- Azure AI StudioからOn Your Dataでデータを追加する
Azure AI Studioでデータを追加_On Your Data
Azure OpenAI Service で独自のデータをOn Your Dataを使うことで自社のデータやご自身が学習させたいデータを読み込むことができます。
- データの検索方法を実装する
Azure AI searchではRAGとして検索する手法に3つ用意されています。
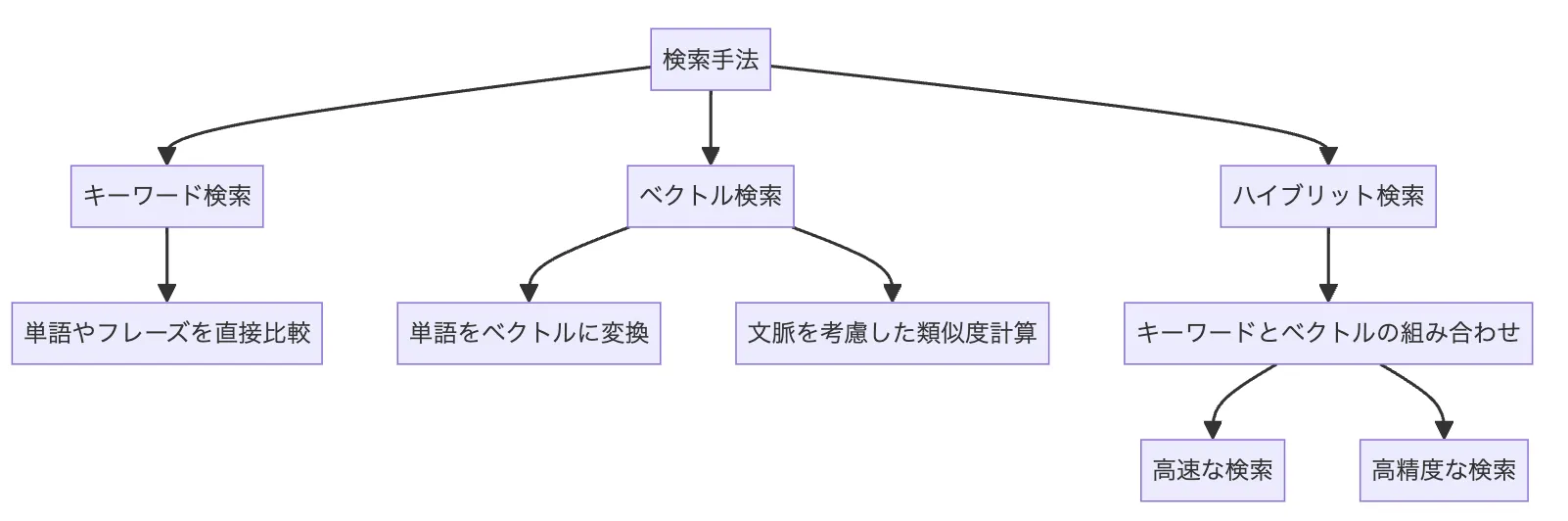
Azure AI search検索機能
- キーワード検索:キーワード検索の手法
- ベクトル検索:単語を数字に置き換えて、その類似度を見ることで単語の類似度や、文脈の考慮が可能な手法
- ハイブリット検索:キーワード検索とベクトル検索を組み合わせた検索手法
絶対ではありませんが、ハイブリット検索を用いることによって、キーワード検索だとキーワードと一致していないと返ってこない、ベクトル検索だと違うことも返ってくるという検索手法の中間が取れ、精度が高まることが多いです。
【関連記事】
➡️Azure AI Serch(旧Azure Cognitive Search)の機能と料金を徹底解説!
Iot機器などローカルにRAGを構築する場合
なぜローカルにRAGを構築したい用途があるのでしょうか。例えば、ローカル環境でのRAGの実装は、外部APIへの依存を避け、プライバシーを保護しながら、LLMの力を活用したい場合に特に有用です。
具体的には重要な機密情報を学習させたい、インターネットへの接続をしたらいけない場合などが含まれます。
ローカルでのRAG構築の手順
- 環境構築: 特にGPUを活用する場合、適切なハードウェアの準備とドライバー、必要なライブラリのインストールが必要です。
例)
NVIDIAのGPUを利用する場合、nvidia-dockerの設定を行います。
2. 環境のセットアップ:データの読み込み、インデックス化、そしてLLMとのインタフェースを設定します。これにより、データに基づくクエリの作成と応答の生成が可能になります(例えばLlamaIndex)。
-
モデルの選定とダウンロード: 使用する埋め込みモデルとLLMモデルを選定し、必要に応じてダウンロードします。多言語対応のモデルや、特定のドメインに特化したモデルを選ぶことができます。
-
質問応答システムの実装: 選択した環境を使用して、読み込んだデータに基づき、質問に対する答えを生成するシステムを実装します。
【関連記事】
➡️エッジAIとは?その概要や活用事例、クラウドAIとの違いを徹底解説!
【AIやクラウド導入の無料相談】弊社のご紹介
AI総合研究所では、AIの無料相談、RAGの構築、導入支援を行っています。自社データを含むようなRAG構築にはセキュリティも重要です。
AI総合研究所ではMicrosoftの生成AI支援パートナーであり、AIおよびセキュリティの高いクラウド構築が得意です。
ぜひご気軽にご相談ください。
【問い合わせ先】
お問い合わせ | AI総合研究所
AI導入に関するご相談はAI総合研究所へ。数名規模の企業から大手企業まで、幅広いニーズに対応します。
https://www.ai-souken.com/contact

RAG実装された事例のご紹介
RAG実装の事例をご紹介します。
【アサヒビール】社内情報検索システム
アサヒビールは、Azure OpenAI Serviceの生成AIを用いた社内情報検索システムを2023年9月上旬に試験導入しています。具体的には、Azure AI SearchやCosmos DBを利用して、多様な形式のデータ検索ができるようになっています。
ビールの画像の下にある文章は100文字程度で文章要約した結果が表示されており、使いやすさに工夫がなされています。
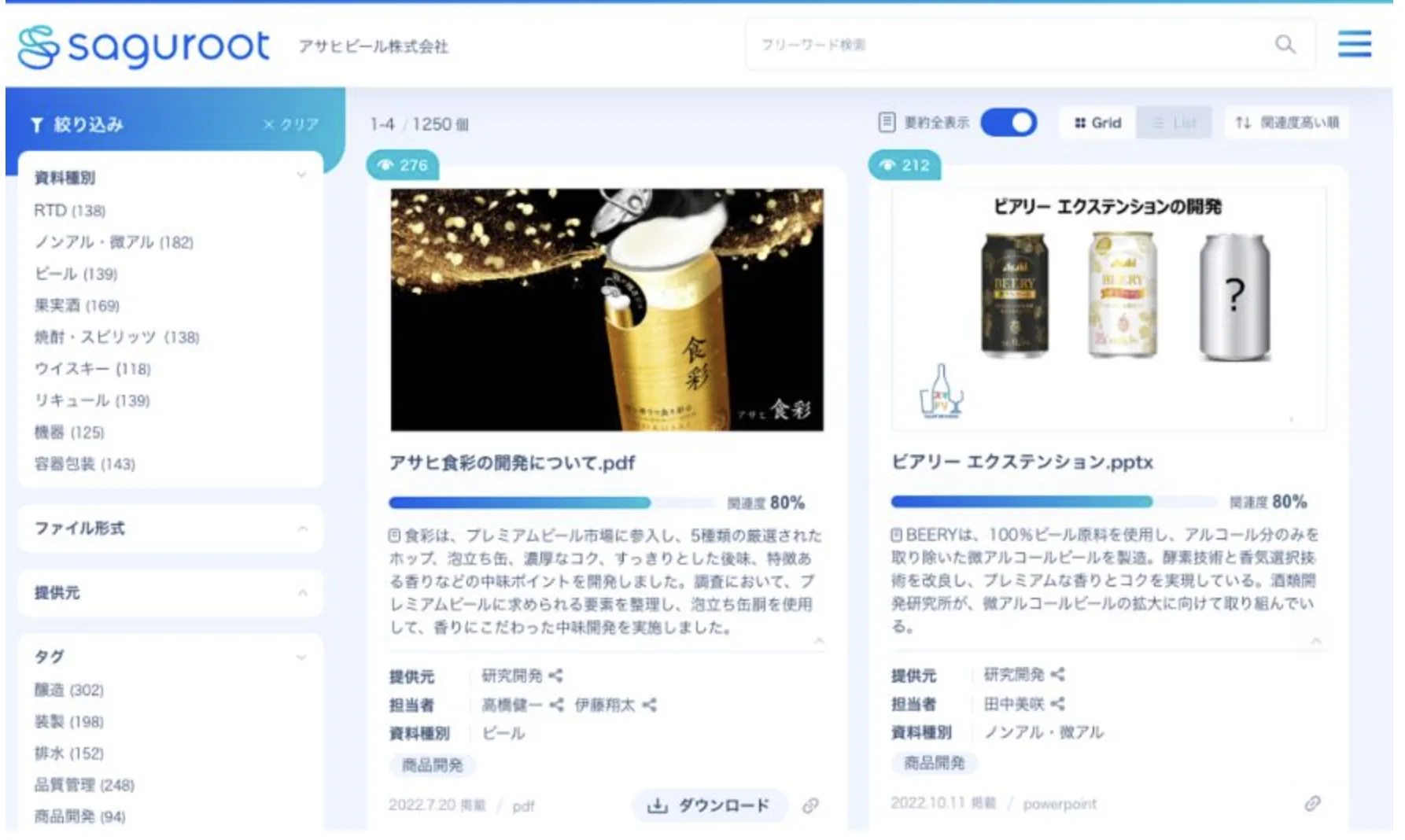
社内検索システムのデモ画面 (参考:アサヒビール)
【Beiersdorf社(スキンケア研究)】科学者向け向けデータベース
BeiersdorfはAzure AIの導入しました。
900人以上の科学者が膨大なデータを一元化し、AIによる知識探索を可能にするMicrosoft Azure Cognitive Search(現 AIsearch)を利用しています。
Azureの文書要約やセマンティック検索などの機能が、多様なデータソースからの情報検索を簡素化し、研究者がさらに効果的に作業できるよう支援しています。その結果として、情報探索の効率を大幅に向上しました。参考:Microsoft

BeiersdorfのAzure AI Search
【関連事例】
➡️導入事例特集ページ

まとめ
本記事ではRAGについて基本的な概念から、利用のメリットデメリット、実際の実装まで徹底的に解説しました。RAGは一見難しそうに聞こえますが、追加学習手法の一つであり、大規模なデータベースから関連情報を取得し、それを活用して生成品質を高めることができます。
RAGを活用することで、生成AIの性能を大きく向上させることができるでしょう。この記事が、読者の皆様にとって有益な情報源となれば幸いです。










