この記事のポイント
 この記事は教師あり学習について詳しく解説しています。
この記事は教師あり学習について詳しく解説しています。- 教師あり学習の基本的な概念やメリット、デメリットについて理解を深めることができます。

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
教師あり学習は、AIと機械学習を理解する上で基本かつ重要なアプローチの一つです。
この記事では、画像認識やスパムメールのフィルタリング、需要予測といった多様な応用例を持つ教師あり学習について、基本原理からアルゴリズム例、応用分野、他手法との比較まで、わかりやすく解説します。
また、線形回帰やロジスティック回帰、決定木など代表的なアルゴリズムの特徴と使い方を紹介し、教師あり学習がビジネスや研究にどのように貢献しているかを具体的な事例を交えて説明します。
さらに、実際に教師あり学習を体験するためのプログラミング実践例も提供し、理論だけでなく実践的なスキルも身につけることができます。
AI技術の理解と実践のための入門として、初学者から経験者まで広くお読みいただける内容となっております。
教師あり学習とは?
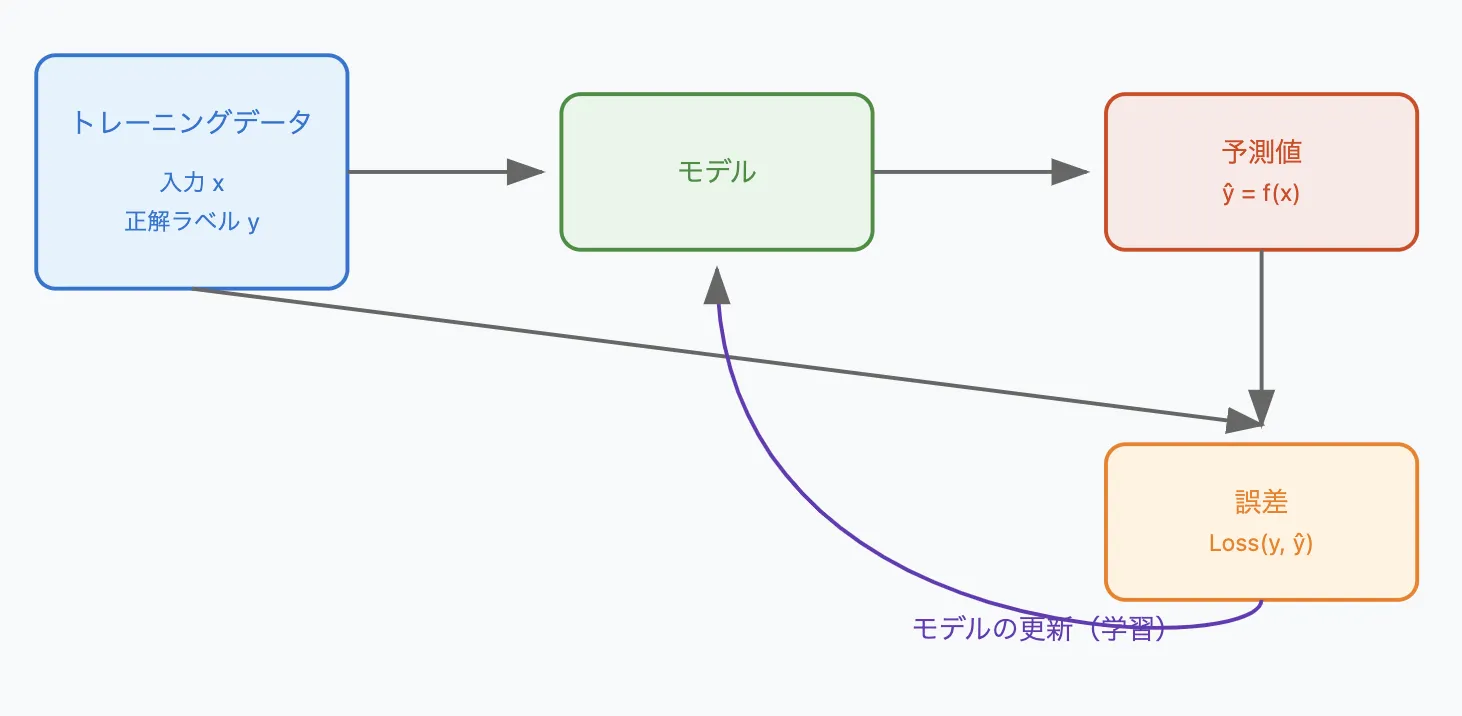
教師あり学習の基盤となった概念図
教師あり学習とは、入力データとそれに対応する正解ラベル(出力データ)をセットで学習させることで、未知の入力データに対する予測モデルを構築する機械学習の手法です。
例えるなら、問題と解答がセットになった問題集を使って勉強するようなものです。
モデルは、入力データと正解ラベルの関係性を学習し、新しい入力データが与えられたときに、それに対応する正解ラベルを予測できるようになります。
教師データとは?
教師あり学習で用いる、入力データと正解ラベルがセットになったデータを「教師データ」と呼びます。
例えば、メールの文章(入力)と、それがスパムかどうか(正解ラベル)をセットにしたデータなどが、教師データの一例です。
他にも、画像データとその画像に写っている物体の名前、過去の株価データと翌日の株価など、様々な種類の教師データが存在します。
教師データの質と量が、モデルの性能を大きく左右します。
他の学習手法との違い
機械学習には、教師あり学習以外にも、「教師なし学習」や「強化学習」といった学習手法があります。
| 学習手法 | 教師データ | 目的 | 例 |
|---|---|---|---|
| 教師あり学習 | 必要 | 入力データから出力データを予測 | スパムメール判定、画像認識、株価予測 |
| 教師なし学習 | 不要 | データに潜む構造やパターンを発見 | クラスタリング、次元削減、異常検知 |
| 強化学習 | 不要 | 試行錯誤を通じて最適な行動を学習 | ロボット制御、ゲームAI、リソース管理 |
※ 上記は一般的な比較表です。
- 教師なし学習: 教師なし学習は、正解ラベルを用いずに、データに潜む構造やパターンを発見する手法です。データのクラスタリングや次元削減などに用いられます。
- 強化学習: 強化学習は、エージェント(学習する主体)が環境との相互作用を通じて、報酬を最大化するように行動を学習する手法です。ゲームAIやロボット制御などに用いられます。
教師あり学習は、これらの学習手法の中でも、特に予測精度の高さと、幅広いタスクへの適用可能性から、広く活用されています。
強化学習や教師なし学習については以下の記事で解説しています。ぜひご覧ください。
関連記事:強化学習とは?その種類や理論一覧、具体例をわかりやすく解説
関連記事:RLHF(人間のフィードバックによる強化学習)とは?仕組み・実装方法を解説
関連記事:機械学習の代表的な手法一覧!フローチャートを用いて選び方を解説
教師あり学習のメリット
教師あり学習には、他の学習手法と比べて、いくつかの明確なメリットがあります。ここでは、そのメリットについて具体的に説明します。
高い予測精度
教師あり学習では、正解ラベル付きのデータを用いて学習するため、一般的に高い予測精度を実現できます。
モデルは、入力データと正解ラベルの関係性を正確に学習することで、未知のデータに対しても精度の高い予測を行うことができるようになります。
明確な評価指標
教師あり学習では、モデルの性能を評価するための明確な指標が存在します。学習データとは別の検証用データを用意し、そのデータを用いてモデルの予測精度を評価します。
精度(Accuracy)、再現率(Recall)、適合率(Precision)、F値(F1-score)など、様々な評価指標を用いることが可能です。これらの指標を用いることで、モデルの性能を客観的に評価し、改善することができます。
比較的シンプルな実装
他の学習手法に比べて、アルゴリズムの実装が比較的容易な場合が多いです。多くのライブラリやフレームワークが提供されており、これらを活用することで、効率的にモデルを開発することができます。
教師あり学習のデメリット
メリットがある一方で、教師あり学習にはいくつかのデメリットも存在します。
ここでは、そのデメリットと、それを克服するための方法について考察します。
教師データの準備が大変
教師あり学習では、大量の教師データを準備する必要があります。多くの場合、人間がデータに正解ラベルを付与する必要があるため、その準備には多くの時間とコストがかかります。
例えば、画像認識モデルを学習させるためには、何千、何万もの画像データに、それぞれ正しいラベルを付与する必要があります。
過学習のリスク
モデルが学習データに過剰に適合しすぎてしまうと、未知のデータに対する予測精度が低下する「過学習」と呼ばれる現象が発生するリスクがあります。
過学習を防ぐためには、学習データの量を増やす、モデルの複雑さを調整する、正則化を行うなどの対策が必要です。
教師データにないパターンは予測困難
学習データに含まれないような、全く新しいパターンの入力データに対しては、適切な予測を行うことが困難です。
例えば、過去に例のないような異常気象が発生した場合、過去の気象データから学習したモデルでは、正確な予測を行うことができない可能性があります。
教師あり学習の種類
教師あり学習は、解きたいタスクによって、さらに「回帰」と「分類」の2つに分けられます。ここでは、その2つの種類について、具体的な例を交えながら解説します。
回帰 - 連続値を予測
回帰とは、入力データから連続する数値(例:売上、株価、気温)を予測するタスクです。
例:
- 過去の売上データから将来の売上を予測する
- 部屋の広さや築年数などの情報から家賃を予測する
- 過去の気温データから明日の気温を予測する
これらの例では、入力データ(過去の売上、部屋の情報、過去の気温)から、出力データ(将来の売上、家賃、明日の気温)という連続する数値を予測しています。
分類 - カテゴリを予測
分類とは、入力データが属するカテゴリ(例:スパム/非スパム、犬/猫、正常/異常)を予測するタスクです。
例:
- メールの内容からスパムメールかどうかを判定する
- 画像に写っている動物が犬か猫かを判定する
- 製造ラインのセンサーデータから製品の異常を検知する
これらの例では、入力データ(メールの内容、画像、センサーデータ)から、出力データ(スパム/非スパム、犬/猫、正常/異常)というカテゴリを予測しています。
代表的なアルゴリズム
教師あり学習には、様々なアルゴリズムが存在し、それぞれ異なる特徴を持っています。ここでは、代表的なアルゴリズムの概要と、その使い分けについて解説します。
以下の表に、教師あり学習の代表的なアルゴリズムの概要をまとめました。
| アルゴリズム名 | タスク | 特徴 | メリット | デメリット |
|---|---|---|---|---|
| 線形回帰 (Linear Regression) | 回帰 | 入力と出力の間に線形関係を仮定 | シンプルで解釈しやすい | 非線形な関係は表現できない |
| ロジスティック回帰 (Logistic Regression) | 分類 | 確率を用いて分類を行う | 計算が軽く、実装しやすい | 複雑なデータの分類は難しい |
| 決定木 (Decision Tree) | 分類・回帰 | 木構造を用いた階層的な分類 | 直感的に理解しやすい | 過学習しやすい |
| ランダムフォレスト (Random Forest) | 分類・回帰 | 複数の決定木を組み合わせるアンサンブル学習 | 高精度で過学習しにくい | モデルの解釈が難しい |
| サポートベクターマシン (SVM) | 分類・回帰 | 高次元データでも効果的に分類可能 | 少ないデータでも高精度 | 計算コストが高い |
| k近傍法 (k-Nearest Neighbors, kNN) | 分類・回帰 | 近傍のデータ点を基に分類・回帰 | シンプルで直感的に理解しやすい | 計算コストが高く、kの選択が重要 |
| ニューラルネットワーク (Neural Network) | 分類・回帰 | 多層のネットワークで複雑なパターンを学習 | 非線形の関係を高精度で学習可能 | 計算リソースが必要で、解釈が難しい |
ここからは各手法について具体例を用いながら解説していきます。
線形回帰 (Linear Regression)
線形回帰は、入力変数と出力変数の間に線形な関係を仮定し、その関係を直線で表す回帰アルゴリズムです。
例えば、部屋の広さと家賃の関係をモデル化する際に用いられます。シンプルで解釈しやすいことがメリットですが、複雑な関係性を表現できないというデメリットもあります。
ロジスティック回帰 (Logistic Regression)
ロジスティック回帰は、分類問題を扱うためのアルゴリズムで、確率を用いてデータの分類を行います。
例えば、メールがスパムかどうかを判定する際に用いられます。線形回帰と名前は似ていますが、こちらは分類アルゴリズムです。
具体的には、入力データから、データがあるクラスに属する確率を計算し、その確率に基づいて分類を行います。
決定木 (Decision Tree)
決定木は、木構造を用いてデータを分類・回帰するアルゴリズムです。条件分岐を繰り返すことで、データを段階的に分類していきます。
例えば、顧客の属性情報から、商品を購入するかどうかを予測する際に用いられます。直感的に理解しやすく、結果の解釈も容易です。
また、非線形な関係も表現できることがメリットです。一方で、過学習しやすいというデメリットもあります。
ランダムフォレスト (Random Forest)
ランダムフォレストは、複数の決定木を組み合わせることで、より高い精度を実現する「アンサンブル学習」と呼ばれる手法の一つです。
個々の決定木の予測結果を多数決などで統合することで、過学習を抑え、汎化性能を高めることができます。
ランダムフォレストは、多くの場合、高い予測精度を発揮しますが、モデルの解釈が難しいというデメリットもあります。
サポートベクターマシン (SVM)
SVMは、データ点を最もよく分離する境界線(超平面)を見つけることで分類を行うアルゴリズムです。
特に、高次元データや、データ点が少ない場合でも高い性能を発揮します。また、カーネルトリックと呼ばれる手法を用いることで、非線形なデータの分類も可能です。
ただし、学習データの量が多いと計算コストが高くなるというデメリットもあります。
k近傍法 (k-Nearest Neighbors)
k近傍法は、未知のデータ点に最も近いk個の学習データ点を参照し、それらの多数決によって分類を行うアルゴリズムです。
シンプルで直感的に理解しやすいですが、計算コストが高いというデメリットがあります。また、適切なkの値を選ぶことが重要です。
ニューラルネットワーク
ニューラルネットワークは、人間の脳の神経回路を模したモデルで、多層のネットワーク構造を用いて複雑なパターンを学習できます。
画像認識や自然言語処理など、様々な分野で高い性能を発揮しています。近年では、ディープラーニングと呼ばれる、多層のニューラルネットワークを用いた手法が注目を集めています。
ただし、学習に時間がかかり、多くの計算リソースを必要とするというデメリットもあります。また、モデルの解釈が難しいことも課題です。
実際に教師あり学習を体験してみましょう
教師あり学習はお手元で再現することができます。
Pythonの機械学習ライブラリ(例: scikit-learn, TensorFlow, PyTorch)を使用すれば、分類や回帰モデルを数行のコードで動作させることが可能です。
今回は、Google colaboratoryを用いて、簡単な実装を行なっていきます。scikit-learn を使用して手書き数字データセット (MNIST の簡易版) を ロジスティック回帰 で分類してみましょう!
ここからは、実装手順をステップバイステップで具体的な出力例と合わせて解説します。
最終的に完成したコード
# 必要なライブラリをインストール(Colabでは通常不要)
!pip install -q numpy pandas scikit-learn matplotlib
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, ConfusionMatrixDisplay
# データセットのロード
digits = load_digits()
# 画像データ(特徴量)とラベル(ターゲット)の取得
X, y = digits.data, digits.target
# データの形状を確認
print("データの形状:", X.shape)
print("ラベルの種類:", np.unique(y))
# 最初の5つの画像を可視化
fig, axes = plt.subplots(1, 5, figsize=(10, 3))
for i, ax in enumerate(axes):
ax.imshow(digits.images[i], cmap='gray')
ax.set_title(f"Label: {digits.target[i]}")
ax.axis("off")
plt.show()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f"訓練データの数: {len(X_train)}")
print(f"テストデータの数: {len(X_test)}")
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
model = LogisticRegression(max_iter=5000)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 正解率を表示
accuracy = accuracy_score(y_test, y_pred)
print(f"分類精度: {accuracy:.4f}")
# 詳細な分類レポート
print("分類レポート:")
print(classification_report(y_test, y_pred))
ConfusionMatrixDisplay.from_estimator(model, X_test, y_test)
plt.show()
📌 ステップ 1: Colab 環境の準備
Google Colab を開き、新しいノートブックを作成します。
以下のコードを入力して実行してください。
# 必要なライブラリをインストール(Colabでは通常不要)
!pip install -q numpy pandas scikit-learn matplotlib
このコマンドは、Colab 環境にすでにあるライブラリを更新する際に役立ちます。
ステップ 2: 必要なライブラリのインポート
以下のコードを Colab に入力して、実行してください。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, ConfusionMatrixDisplay
ステップ 3: データセットの読み込み
教師あり学習のデータとして 手書き数字データ(MNIST の簡易版) を使用します。
# データセットのロード
digits = load_digits()
# 画像データ(特徴量)とラベル(ターゲット)の取得
X, y = digits.data, digits.target
# データの形状を確認
print("データの形状:", X.shape)
print("ラベルの種類:", np.unique(y))
✅ 予想される出力例
データの形状: (1797, 64)
ラベルの種類: [0 1 2 3 4 5 6 7 8 9]
(8×8 ピクセルの手書き数字データが 1,797 枚あります)
ステップ 4: データの可視化**
データセットの中身を確認するため、最初の画像を表示します。
# 最初の5つの画像を可視化
fig, axes = plt.subplots(1, 5, figsize=(10, 3))
for i, ax in enumerate(axes):
ax.imshow(digits.images[i], cmap='gray')
ax.set_title(f"Label: {digits.target[i]}")
ax.axis("off")
plt.show()
✅ 予想される出力例
このような画像が表示されます。
ステップ 5: 訓練データとテストデータの分割
教師あり学習では、データを 訓練用 (train) と テスト用 (test) に分割します。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f"訓練データの数: {len(X_train)}")
print(f"テストデータの数: {len(X_test)}")
✅ 予想される出力例
訓練データの数: 1437
テストデータの数: 360
ステップ 6: データの標準化
教師あり学習では、データのスケールを揃えることで学習の精度を向上させます。
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
ステップ 7: モデルの訓練
ロジスティック回帰を使って手書き数字を分類するモデルを学習させます。
model = LogisticRegression(max_iter=5000)
model.fit(X_train, y_train)
ステップ 8: モデルの評価
訓練済みのモデルを使ってテストデータの分類精度を確認します。
y_pred = model.predict(X_test)
# 正解率を表示
accuracy = accuracy_score(y_test, y_pred)
print(f"分類精度: {accuracy:.4f}")
# 詳細な分類レポート
print("分類レポート:")
print(classification_report(y_test, y_pred))
✅ 予想される出力例
分類精度: 0.9611
分類レポート:
precision recall f1-score support
0 1.00 1.00 1.00 35
1 0.90 1.00 0.95 37
2 1.00 0.97 0.99 32
3 1.00 0.97 0.99 38
4 0.97 1.00 0.99 36
5 0.95 1.00 0.98 35
6 1.00 1.00 1.00 37
7 1.00 1.00 1.00 36
8 0.92 0.89 0.91 36
9 0.97 0.89 0.93 38
accuracy 0.96 360
macro avg 0.97 0.97 0.97 360
weighted avg 0.97 0.96 0.97 360
ステップ 9: 混同行列の可視化
どの数字がどの数字と間違えやすいかを可視化します。
ConfusionMatrixDisplay.from_estimator(model, X_test, y_test)
plt.show()
✅ 予想される出力例
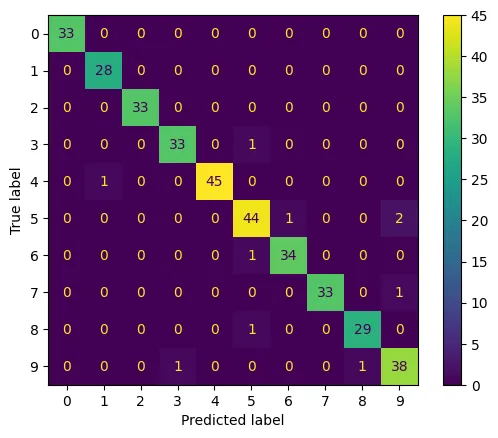
ヒートマップの形で表示されています。
今回は精度をAccuracyのみで評価しましたが、機械学習に使われるF1 Scoreを使うとさらに詳細な精度の比較ができます。
他のアルゴリズム(SVM, ランダムフォレスト, ニューラルネットワーク)にも簡単に応用できますので、試してみてください!
教師あり学習の活用事例
教師あり学習は、様々な分野で実際に活用されています。ここでは、その具体的な活用事例を紹介し、教師あり学習がどのように社会に貢献しているかを明らかにします。
スパムメールフィルタリング
メールの内容や送信元などの情報から、スパムメールかどうかを自動的に判定します。
多くのメールサービスで、この技術が活用されており、ユーザーを有害なスパムメールから守っています。
-
Gmail: Googleのメールサービスで、高精度なスパムフィルタリング機能を提供しています。
- リンク: Gmail
-
Outlook: Microsoftのメールサービスで、スパムメールの自動検出機能があります。
- リンク: Outlook
画像認識
画像に写っている物体を認識し、分類します。例えば、医療画像の診断や、自動運転における障害物検知などに活用されています。
近年では、スマートフォンのカメラアプリにも、この技術が搭載されていることが多く、写真の自動整理などに役立てられています。
- Google フォト: 写真の自動分類や検索機能に画像認識技術を活用しています。
- Apple 写真: iOSの写真アプリで、画像認識を用いて人物や風景の分類を行っています。
需要予測
過去の販売データや天候などの情報から、将来の需要を予測します。
在庫管理の最適化や、販売戦略の立案などに役立ちます。例えば、小売業では、過去の販売データと天候データを組み合わせることで、将来の商品の需要を予測し、適切な在庫量を確保することができます。
- Amazon Seller Central: 需要予測に基づき、在庫の最適化を行っています。
- SAP Integrated Business Planning : 需要予測と供給計画を統合的に管理するソリューションを提供しています。
医療診断
患者の検査データや症状などから、病気の診断や予後予測を行います。
例えば、がんの診断や、再発リスクの予測などに活用されています。この技術により、医師の診断を支援し、より正確で迅速な診断が可能になります。
- IBM Watson for Oncology: がんの診断と治療法の提案を支援するAIシステムです。
- Aidoc: 医療画像の解析を行い、異常検出を支援するAIプラットフォームです。
金融リスク管理
顧客の属性や取引履歴などの情報から、貸し倒れリスクなどを予測します。
例えば、銀行では、融資の審査において、顧客の属性や過去の取引履歴から、貸し倒れリスクを予測し、融資の可否や金利を決定しています。
教師あり学習は、さまざまな分野で実際に活用されています。以下に具体的なサービスとそのリンクを添えて、教師あり学習の活用事例を紹介します。
- FICO Score: 個人の信用リスクを評価するスコアリングシステムで、多くの金融機関で利用されています。
- Zest AI: 機械学習を用いて信用リスクモデルを構築し、融資判断を支援するプラットフォームです。
ここに紹介したサービスを身近に使っている方も多いのではないでしょうか。
教師あり学習を用いたサービスは、私たちの生活やビジネスに大きな影響を与えています。
まとめ
本記事では、機械学習の基本的な学習手法である「教師あり学習」について、その仕組み、メリット・デメリット、代表的なアルゴリズム、そして活用事例まで、幅広く解説しました。
教師あり学習は、データから価値を生み出す強力なツールであり、今後ますますその重要性が増していくと考えられます。
この記事が、教師あり学習の理解を深め、AI技術の活用を検討する一助となれば幸いです。
AI総合研究所合研究所では、<<記事に合わせて多彩な実績と知見を活かしたカリキュラム設計から実機演習、研修後のフォローアップまで一貫してサポートいたします。
企業規模や業種に合わせたカスタムプランもご用意しておりますので、ぜひお気軽にご相談ください。
【参考文献】
Rosenblatt, F. (1958): The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain
🔗 論文リンク
- 生物の神経ネットワークを模倣した確率的モデル「パーセプトロン」を提案。学習則を定式化し、単純な分類問題を解く能力を示した。後のニューラルネットワーク研究の基盤を築いた。










